HBase的入门与介绍
第 1 章 HBase 简介
1.1 HBase 定义
HBase 是一种分布式、可扩展、支持海量数据存储的 NoSQL 数据库。
主要用途:
- 推荐画像:特别是用户的画像,是一个比较大的稀疏矩阵,蚂蚁的风控就是构建在HBase之上
- 对象存储:我们知道不少的头条类、新闻类的的新闻、网页、图片存储在HBase之中,一些病毒公司的病毒库也是存储在HBase之中
- 时序数据:HBase之上有OpenTSDB模块,可以满足时序类场景的需求
- 时空数据:主要是轨迹、气象网格之类,滴滴打车的轨迹数据主要存在HBase之中,另外在技术所有大一点的数据量的车联网企业,数据都是存在HBase之中
- CubeDB OLAP:Kylin一个cube分析工具,底层的数据就是存储在HBase之中,不少客户自己基于离线计算构建cube存储在hbase之中,满足在线报表查询的需求
- 消息/订单:在电信领域、银行领域,不少的订单查询底层的存储,另外不少通信、消息同步的应用构建在HBase之上
- Feeds流:典型的应用就是xx朋友圈类似的应用
- NewSQL:之上有Phoenix的插件,可以满足二级索引、SQL的需求,对接传统数据需要SQL非事务的需求。
1.2 存储结构
1 : Table:表,一个表中包含多行数据
2: Rowkey:一行数据的唯一标示,在HBase中,一张表中所有row都按照rowkey的字典序由小到大排序。
3: Column:列,每个列都由 Column Family(列族)和 Column Qualifier(列限定符)进行限定,column family在表创建的时候需要指定,用户不能随意增减。一个column family下可以设置任意多个qualifier,因此可以理解为HBase中的列可以动态增加,理论上甚至可以扩展到上百万列。
5 : timestamp:时间戳,每个cell在写入HBase的时候都会默认分配一个时间戳作为该cell的版本,当然,用户也可以在写入的时候自带时间戳。HBase支持多版本特性,即同一rowkey、column下可以有多个value存在,这些value使用timestamp作为版本号,版本越大,表示数据越新。
6: value:存储真实的数值
7:Cell 由{rowkey, column Family:column Qualifier, time Stamp} 唯一确定的单元。cell 中的数
据是没有类型的,全部是字节码形式存贮

1.3 HBase 基本架构
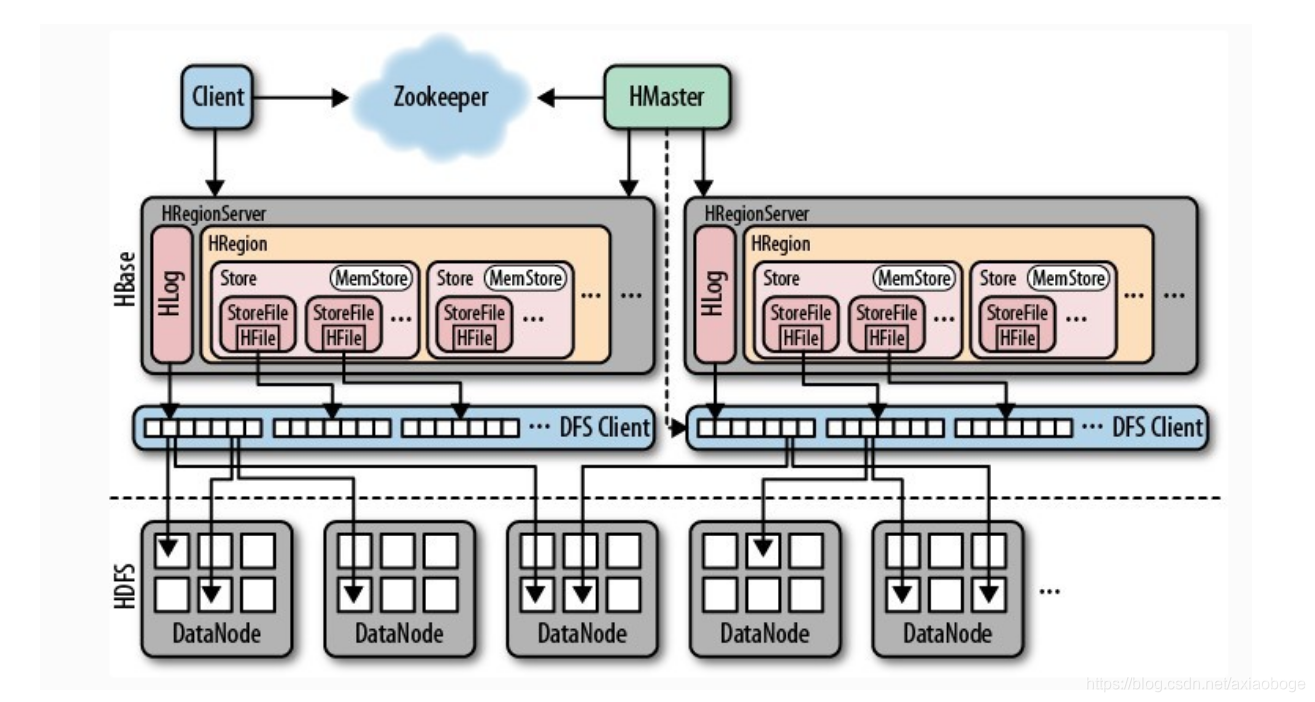
架构组件
1: Zookeeper
实现Master高可用:通常情况下系统中只有一个Master工作,一旦Active Master由于异常宕机,ZooKeeper会检测到该宕机事件,并通过一定机制选举出新的Master,保证系统正常运转。
·管理系统核心元数据:比如,管理当前系统中正常工作的RegionServer集合,保存系统元数据表hbase:meta所在的RegionServer地址等。
·参与RegionServer宕机恢复:ZooKeeper通过心跳可以感知到RegionServer是否宕机,并在宕机后通知Master进行宕机处理。
2: Master
Master主要负责HBase系统的各种管理工作:
·处理用户的各种管理请求,包括建表、修改表、权限操作、切分表、合并数据分片以及Compaction等。
·管理集群中所有RegionServer,包括RegionServer中Region的负载均衡、RegionServer的宕机恢复以及Region的迁移等。
·清理过期日志以及文件,Master会每隔一段时间检查HDFS中HLog是否过期、HFile是否已经被删除,并在过期之后将其删除。
3:Region Server
RegionServer主要用来响应用户的IO请求,是HBase中最核心的模块,由WAL(HLog)、BlockCache以及多个Region构成。
·WAL(HLog):HLog在HBase中有两个核心作用——
其一,用于实现数据的高可靠性,HBase数据随机写入时,并非直接写入HFile数据文件,而是先写入缓存,再异步刷新落盘。为了防止缓存数据丢失,数据写入缓存之前需要首先顺序写入HLog,这样,即使缓存数据丢失,仍然可以通过HLog日志恢复;
其二,用于实现HBase集群间主从复制,通过回放主集群推送过来的HLog日志实现主从复制。
·BlockCache:HBase系统中的读缓存。客户端从磁盘读取数据之后通常会将数据缓存到系统内存中,后续访问同一行数据可以直接从内存中获取而不需要访问磁盘。对于带有大量热点读的业务请求来说,缓存机制会带来极大的性能提升。
BlockCache缓存对象是一系列Block块,一个Block默认为64K,由物理上相邻的多个KV数据组成。BlockCache同时利用了空间局部性和时间局部性原理,前者表示最近将读取的KV数据很可能与当前读取到的KV数据在地址上是邻近的,缓存单位是Block(块)而不是单个KV就可以实现空间局部性;后者表示一个KV数据正在被访问,那么近期它还可能再次被访问。当前BlockCache主要有两种实现——LRUBlockCache和BucketCache,前者实现相对简单,而后者在GC优化方面有明显的提升。
4:Region
数据表的一个分片,当数据表大小超过一定阈值就会“水平切分”,分裂为两个Region。Region是集群负载均衡的基本单位。通常一张表的Region会分布在整个集群的多台RegionServer上,一个RegionServer上会管理多个Region,当然,这些Region一般来自不同的数据表。
一个Region由一个或者多个Store构成,Store的个数取决于表中列簇(column family)的个数,多少个列簇就有多少个Store。HBase中,每个列簇的数据都集中存放在一起形成一个存储单元Store,因此建议将具有相同IO特性的数据设置在同一个列簇中。
每个Store由一个MemStore和一个或多个HFile组成。MemStore称为写缓存,用户写入数据时首先会写到MemStore,当MemStore写满之后(缓存数据超过阈值,默认128M)系统会异步地将数据flush成一个HFile文件。显然,随着数据不断写入,HFile文件会越来越多,当HFile文件数超过一定阈值之后系统将会执行Compact操作,将这些小文件通过一定策略合并成一个或多个大文件
5: HDFS
HBase底层依赖HDFS组件存储实际数据,包括用户数据文件、HLog日志文件等最终都会写入HDFS落盘。HDFS是Hadoop生态圈内最成熟的组件之一,数据默认三副本存储策略可以有效保证数据的高可靠性。HBase内部封装了一个名为DFSClient的HDFS客户端组件,负责对HDFS的实际数据进行读写访问。
1.4 HBase系统特性
优点:
1> 容量巨大:HBase的单表可以支持千亿行、百万列的数据规模,数据容量可以达到TB甚至PB级别。传统的关系型数据库,如Oracle和MySQL等,如果单表记录条数超过亿行,读写性能都会急剧下降,在HBase中并不会出现这样的问题。
2> 良好的可扩展性:HBase集群可以非常方便地实现集群容量扩展,主要包括数据存储节点扩展以及读写服务节点扩展。HBase底层数据存储依赖于HDFS系统,HDFS可以通过简单地增加DataNode实现扩展,HBase读写服务节点也一样,可以通过简单的增加RegionServer节点实现计算层的扩展。
3> 稀疏性:HBase支持大量稀疏存储,即允许大量列值为空,并不占用任何存储空间。这与传统数据库不同,传统数据库对于空值的处理要占用一定的存储空间,这会造成一定程度的存储空间浪费。因此可以使用HBase存储多至上百万列的数据,即使表中存在大量的空值,也不需要任何额外空间。
4> 高性能:HBase目前主要擅长于OLTP场景,数据写操作性能强劲,对于随机单点读以及小范围的扫描读,其性能也能够得到保证。对于大范围的扫描读可以使用MapReduce提供的API,以便实现更高效的并行扫描。
5> 多版本:HBase支持多版本特性,即一个KV可以同时保留多个版本,用户可以根据需要选择最新版本或者某个历史版本。
6> 支持过期:HBase支持TTL过期特性,用户只需要设置过期时间,超过TTL的数据就会被自动清理,不需要用户写程序手动删除。
缺点:
1 > HBase本身不支持很复杂的聚合运算(如Join、GroupBy等)。如果业务中需要使用聚合运算,可以在HBase之上架设Phoenix组件或者Spark组件,前者主要应用于小规模聚合的OLTP场景,后者应用于大规模聚合的OLAP场景。
2 > HBase本身并没有实现二级索引功能,所以不支持二级索引查找。好在针对HBase实现的第三方二级索引方案非常丰富,比如目前比较普遍的使用Phoenix提供的二级索引功能。
3 > HBase原生不支持全局跨行事务,只支持单行事务模型。同样,可以使用Phoenix提供的全局事务模型组件来弥补HBase的这个缺陷。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号