.Net使用ElasticSearch原理及入门
1、Elasticsearch简介
Elasticsearch 是一个基于Lucene,开源的高扩展分布式全文检索引擎,它不会将信息储存为列数据行,而是储存已序列化为 JSON 文档的复杂数据结构。
当文档被储存时,它将建立索引并且近实时(1s)被搜索。 Elasticsearch 使用一种被称为倒排索引的数据结构,该结构支持快速全文搜索。在倒排索引里列出了所有文档中出现的每一个唯一单词并分别标识了每个单词在哪一个文档中。
索引可以被认为是文档的优化集合,每个文档索引都是字段的集合,这些字段是包含了数据的键值对。默认情况下,Elasticsearch 为每个字段中的所有数据建立倒排索引,并且每个索引字段都有专门的优化数据结构。例如:文本字段在倒排索引里,数值和地理字段被储存在 BKD 树中。正是因为通过使用按字段数据结构组合,才使得 Elasticsearch 拥有如此快速的搜索能力。
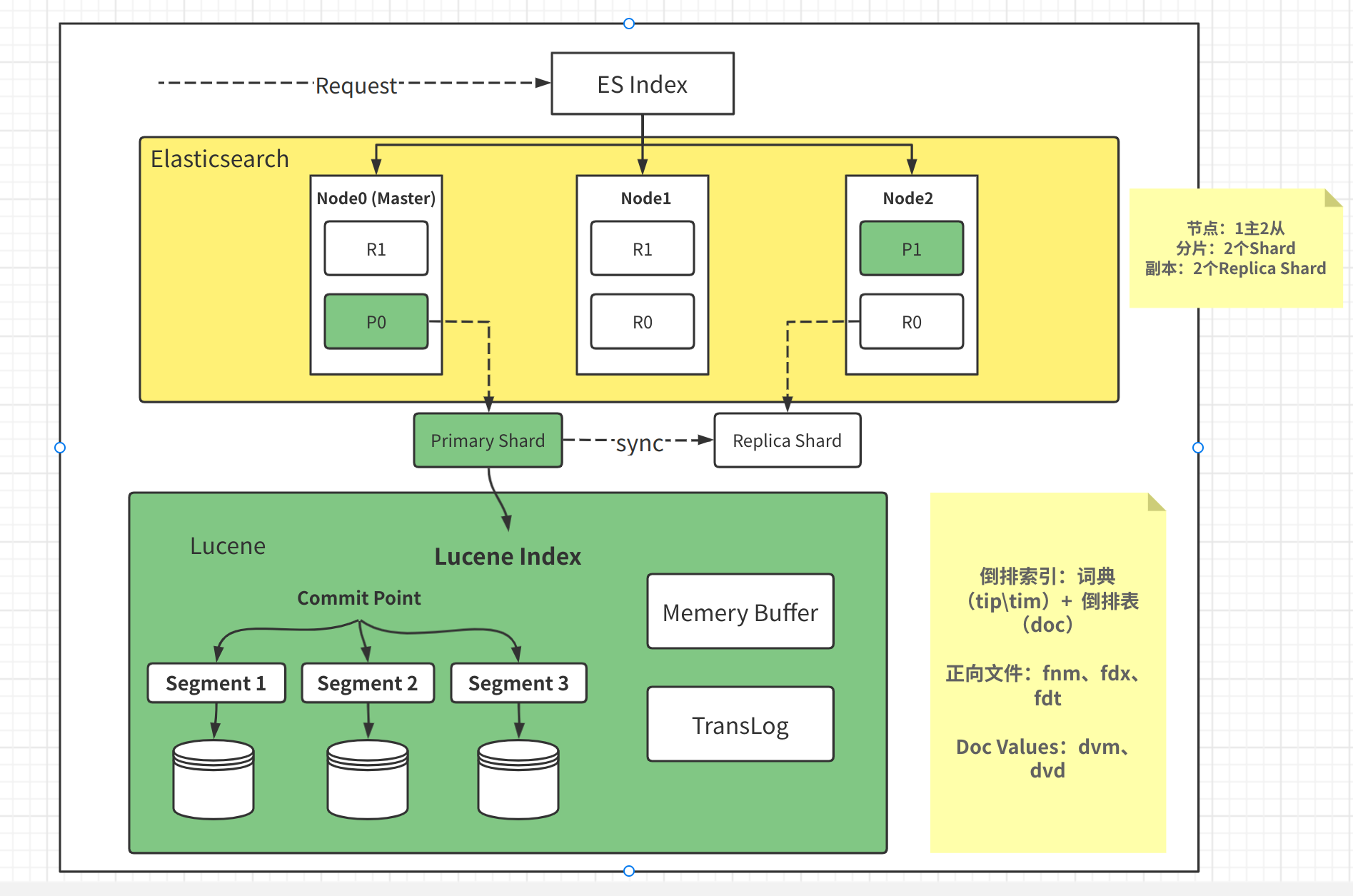
2、Elasticsearch常见使用场景
1、日志和事件管理:ElasticSearch常被用于日志和事件数据的集中存储和搜索,通过将日志数据导入ElasticSearch,用户可以快速检索和分析日志信息,定位问题和异常,提高运维效率。
2、电商搜索:在电商领域,ElasticSearch可以帮助商家实现商品信息的快速搜索和推荐,通过构建复杂的查询语句和排序规则,ElasticSearch可以根据用户的搜索意图和偏好返回最相关的商品结果。
3、数据分析与可视化:ElasticSearch不仅支持搜索功能,还提供了丰富的数据分析工具,用户可以利用ElasticSearch对数据进行聚合、统计和分析,并通过可视化工具展示结果,帮助决策者更好地理解数据背后的故事。
4、实时监控系统:ElasticSearch可以实时收集和处理各种监控数据,如服务器性能指标、网络流量等,通过构建实时仪表盘和告警机制,ElasticSearch可以帮助用户及时发现潜在问题并采取相应措施。
3、安装
3.1、安装Elasticsearch和Kibana
Docker-Compose安装自行搜索
新建docker-compose.yml文件,执行docker-compose up -d,
version: '3.2'
services:
elasticsearch:
image: elasticsearch:7.8.0
container_name: elk-es
restart: always
environment:
# 开启内存锁定
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
# 指定单节点启动
- discovery.type=single-node
ulimits:
# 取消内存相关限制 用于开启内存锁定
memlock:
soft: -1
hard: -1
volumes:
- ./data:/usr/share/elasticsearch/data
- ./logs:/usr/share/elasticsearch/logs
- ./plugins:/usr/share/elasticsearch/plugins
ports:
- 9200:9200
kibana:
image: kibana:7.8.0
container_name: elk-kibana
restart: always
environment:
ELASTICSEARCH_HOSTS: http://elk-es:9200
I18N_LOCALE: zh-CN
ports:
- 5601:5601
networks:
default:
external:
name: elk
3.2、安装分词器
安装分词器版本需要和elasticsearch版本对应,并且安装完插件后需重启Es,才能生效,插件安装其实就是下载 zip 包然后解压到 plugins 目录下
./elasticsearch-plugin install {分词器的下载地址}
安装 ik 分词器
./elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.8.0/elasticsearch-analysis-ik-7.8.0.zip
常用分词器列表
IK 分词器 https://github.com/medcl/elasticsearch-analysis-ik
拼音分词器 https://github.com/medcl/elasticsearch-analysis-pinyin
Docker安装的话可以通过 Volume 的方式放在宿主机,或者进入容器用命令行安装也是一样的
3.3、Kibana测试
在 Kibana 中通过 Dev Tools 可以方便的执行各种操作。
#ik_max_word 会将文本做最细粒度的拆分
#ik_smart 会做最粗粒度的拆分
#pinyin 拼音
POST _analyze
{
"analyzer": "ik_max_word",
"text": ["关注点赞点一点,走过路过别错过"]
}
其他Elasticsearch实用工具
- 在线sql转DSL网站
- es-client: 在线连接elasticsearch网站扩展
- 使用grafana连接Elasticsearch,可以使用
w958660278/grafana-cn:latest中文镜像创建功能强大的Dashboard看板
4、.Net接入Elasticsearch的简单增删改查操作
4.1、新建项目
新建一个webapi项目,引用这两个Nuget包 NEST和Swashbuckle.AspNetCore
4.2、添加实体类
添加商品实体类:
[ElasticsearchType(RelationName = "good")]
public class Good : ElasticsearchEntity
{
/// <summary>
/// 商品Id
/// </summary>
[Keyword(Name = "good_id")]
public string GoodId { get; set; }
/// <summary>
/// 商品编码
/// </summary>
[Keyword(Name = "good_bn")]
public string GoodBn { get; set; }
/// <summary>
/// 商品名称
/// </summary>
[Keyword(Name = "good_name")]
public string GoodName { get; set; }
/// <summary>
/// 商品状态
/// </summary>
[Number(NumberType.Long, Name = "good_status")]
public int GoodStatus { get; set; }
/// <summary>
/// 商品价格
/// </summary>
[Number(NumberType.Double, Name = "price")]
public decimal Price { get; set; }
/// <summary>
/// 用户ID
/// </summary>
[Number(NumberType.Long, Name = "user_id")]
public long UserId { get; set; }
/// <summary>
/// 创建时间
/// </summary>
[Date(Name = "create_datetime")]
public DateTimeOffset CreateDateTime { get; set; }
}
4.3、添加Elasticsearch中间件
添加ElasticsearchExtension.cs
public static class ElasticsearchExtension
{
/// <summary>
/// NEST
/// </summary>
/// <param name="services"></param>
/// <param name="option"></param>
public static void AddElasticsearch(this IServiceCollection services, IConfiguration configuration)
{
var option = configuration.GetSection("Elasticsearch").Get<ElasticsearchOption>();
var nodes = option.Uris.Select(a => new Node(new Uri(a)));
var pool = new StaticConnectionPool(nodes);
var settings = new ConnectionSettings(pool);
settings.BasicAuthentication(option.UserName, option.Password);
var client = new ElasticClient(settings);
services.AddSingleton(client);
}
}
public class ElasticsearchOption
{
public string[] Uris { get; set; }
public string UserName { get; set; }
public string Password { get; set; }
}
在Program.cs中添加服务
services.AddSwaggerGen(c =>
{
c.SwaggerDoc("v1",
new OpenApiInfo
{
Title = "Elasticsearch测试API",
Version = "v1",
});
var xmlFilename = $"{Assembly.GetExecutingAssembly().GetName().Name}.xml";
c.IncludeXmlComments(Path.Combine(AppContext.BaseDirectory, xmlFilename));
});
services.AddElasticsearch(Configuration);
4.4、添加一个GoodControllerAPI控制器,代码如下:
namespace Demo.Controllers
{
[Route("api/[controller]")]
[ApiController]
public class GoodController : ControllerBase
{
private readonly ElasticClient _elasticClient;
public GoodController(ElasticClient elasticClient)
{
_elasticClient = elasticClient;
}
[HttpGet]
public async Task<IActionResult> QueryAsync(GoodSearchRequest request)
{
var mustQuerys = new List<Func<QueryContainerDescriptor<Good>, QueryContainer>>();
if (request.UserId.HasValue)
mustQuerys.Add(a => a.Term(t => t.Field(f => f.UserId).Value(request.UserId.Value)));
if (!request.GoodName.IsNullOrWhiteSpace())
mustQuerys.Add(a => a.Term(t => t.Field(f => f.EventName.Suffix("keyword")).Value(request.GoodName)));
if (request.BeginDateTime.HasValue)
mustQuerys.Add(a => a.DateRange(dr =>
dr.Field(f => f.CreateDateTime).GreaterThanOrEquals(request.BeginDateTime.Value).TimeZone(EsConst.TimeZone)));
if (request.EndDateTime.HasValue)
mustQuerys.Add(a =>
a.DateRange(dr => dr.Field(f => f.CreateDateTime).LessThanOrEquals(request.EndDateTime.Value).TimeZone(EsConst.TimeZone)));
var searchResult = _elasticClient.Search<Good>(a =>
a.Index(typeof(Good).GetRelationName())
.Query(q => q.Bool(b => b.Must(mustQuerys))));
var apiResult = searchResult.GetApiResult<Good, List<GoodSearchItem>>();
if (apiResult.Success)
{
return ApiResult<NovelSearchResponse>.IsSuccess(new GoodSearchResponse
{
Item = apiResult.Data
});
}
return ApiResult<GoodSearchResponse>.IsSuccess("空集合数据", new GoodSearchResponse
{
Item = new List<GoodSearchItem>()
});
}
[HttpPost]
public async Task<IActionResult> InsertAsync([FromBody] Good good)
{
await _elasticClient.IndexAsync(good, x => x.Index(IndexName));
return Ok("新增成功");
}
[HttpDelete]
public async Task<IActionResult> DeleteAsync([Required] string id)
{
await _elasticClient.DeleteAsync<Good>(id, x => x.Index(IndexName));
return Ok("删除成功");
}
[HttpPut]
public async Task<IActionResult> UpdateAsync([FromBody] Good good)
{
await _elasticClient.UpdateAsync<VisitLog>(visitLog.Id, x => x.Index(IndexName).Doc(good));
return Ok("修改成功");
}
}
}
5、.Net接入Elasticsearch的插入和查询原理
5.1、.Net插入elasticsearch过程:
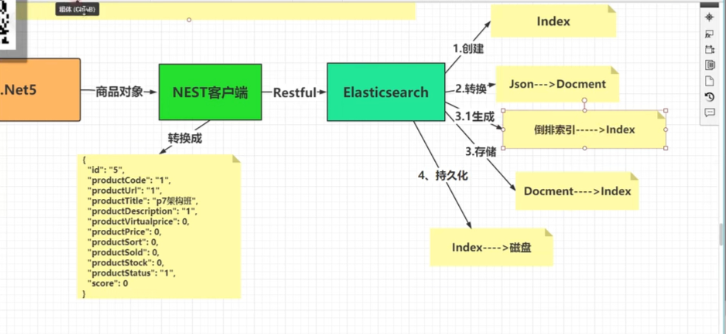
在数据进入ES 中时,分词器会对数据进行分词,将其划分出多个Terms,然后建立 Terms 到 Document ID 的映射,然后将 Terms加入了字典树Term index中。使用Nest客户端将对应的模型类转换成json;
调用elasticsearch的restfult Api
1、创建elssticsearch的Index(类似于数据库)
2、将Josn转换成Docment(类似于数据库表)
3、将Docment存储在对应的Index中,并使用fst树算法生成倒排索引
4、将index持久化到磁盘
5.2、.Net查询elasticsearch过程:
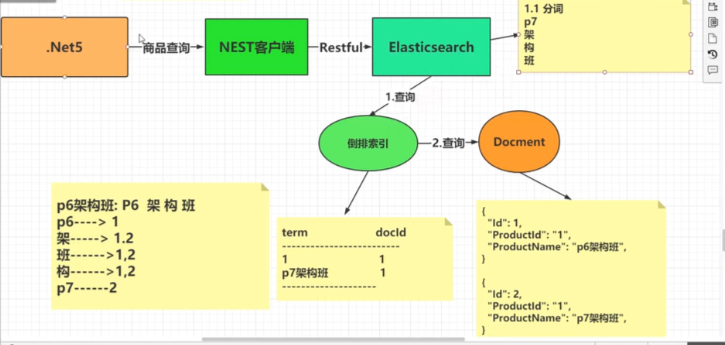
使用Nest客户端调用elasticsearch的restfult Api 进行分词后再根据分词查询出对应的倒排索引,最后根据索引查出对应的Docment返回
6、Elasticsearch查询为什么快?
6.1、倒排索引
倒排索引是整个 ES 的核心,正常的搜索以一本书为例,应该是由 “目录 -> 章节 -> 页码 -> 内容” 这样的查找顺序,这样是正排索引的思想。
但是设想一下,我在一本书中快速查找 “elasticsearch” 这个关键字所在的页面该怎么办?
倒排索引的思路是通过单词到文档ID的关系对应。
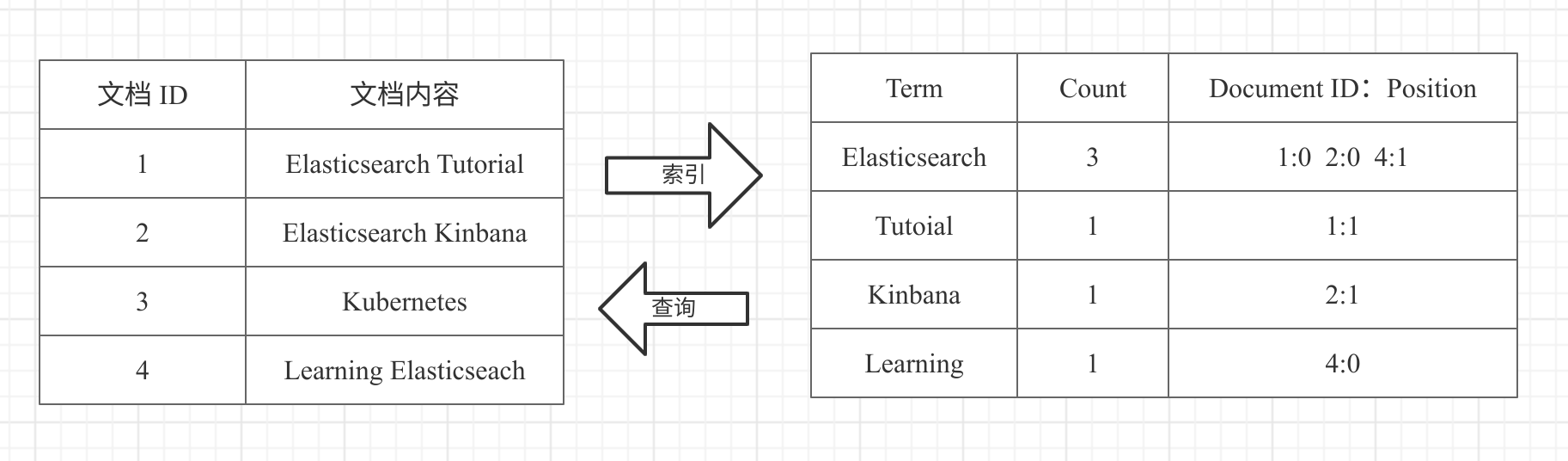
倒排索引包含两个部分:
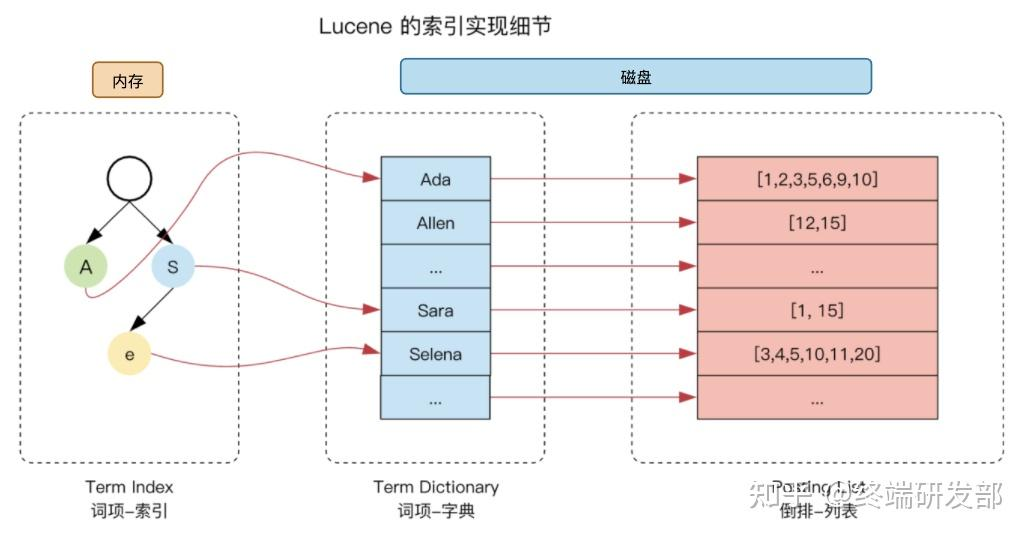
- 单词词典(Term Dictionary):记录所有文档的单词,记录单词到倒排列表的关联关系(单词词典一般比较大,通过 B+ 树或哈希拉链法实现,以满足高性能的插入与查询)
- 倒排表(Posting List):记录了单词对应的文档结合,由倒排索引组成。
- 文档ID
- 词频 TF - 该单词在文档中分词的位置。用于语句搜索
- 位置(Position)- 单词在文档中分词的位置,用于语句搜索
- 偏移(Offset)- 记录单词的开始结束位置,实现高亮显示。
6.2、使用FST(Finite State Transducer) 结构构建单词词典(Term Dictionary)
倒排索引的核心在于如何快速的依据查询词快速的查找到所有的相关文档,我们可以采用 HashMap、TRIE、Binary Search Tree等数据结构来实现。
而 Lucene 采用了一种称为 FST(Finite State Transducer) 的结构来构建词典,这个结构保证了时间和空间复杂度,是Luene的核心功能之一。
关于FST(Finite State Transducer)
FST 是一种类似 TRIE 树的算法。
Trie树,又叫字典树、前缀树(Prefix Tree)。
前缀树路由Router
浅谈Trie树
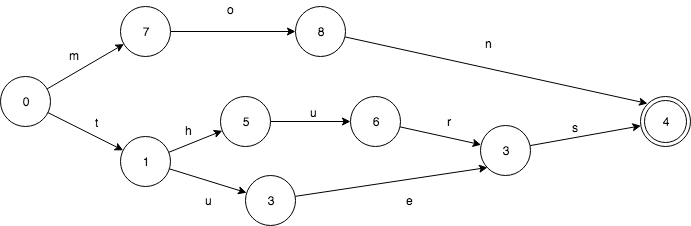
那为什么不直接使用 Trie 树这种现成的搜索树算法呢?
假设我们有这样一个 Set: mon、thues、thurs。FSA 是这样的(终点节点4):
相对应的 Trie 则是这样的:
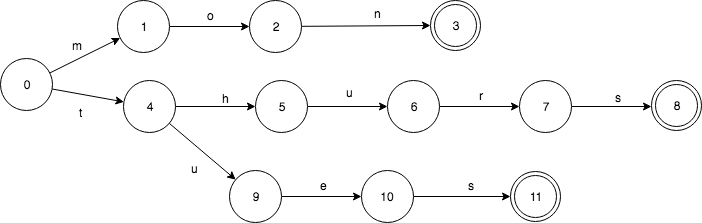
使用有限状态转换器在内存消耗上远比 SortedMap 要少,但是在查询过程中需要更多的CPU资源。另外,ES中有一种查询叫做模糊查询(fuzzy query),根据搜索词和字段之间的编辑距离来判断是否匹配。
6.3、针对倒排表(Posting List)进行索引压缩法(FOR)
倒排表记录了对应单词(Term Dictionary)所出现的的文档ID等信息。并且为了搜索的时延肯定需要放在内存中,面对海量的文档必然会存在更多量级的倒排表,为了节约空间,肯定是需要一定的压缩算法。
FOR:(Frame Of Reference)
假设某个包含某个 单词 (Term Dictionary)的文档出现了100W次,那么其对应的倒排表就会非常的大,按1个int占用空间为 4 Byte 计算,仅这么倒排表中的一项就要消耗 3.8MB 空间。
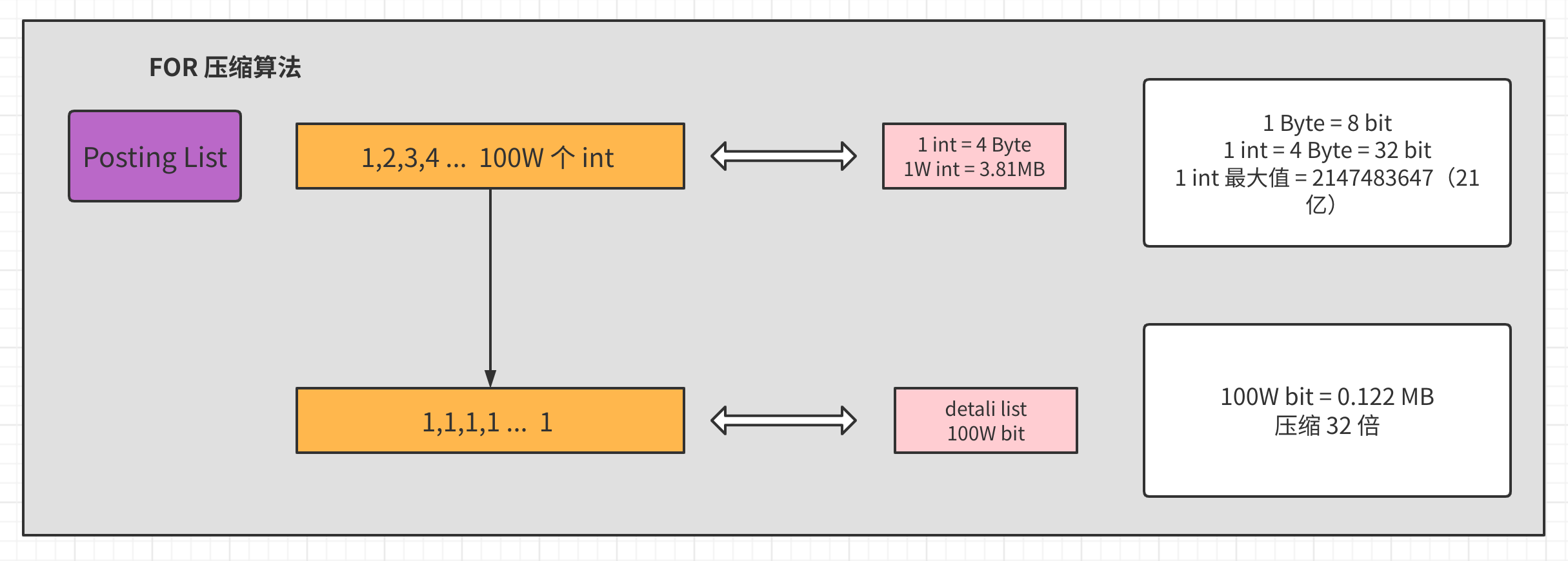
如上图所示,我们知道一个1个int是4字节,一个字节最大可以存正21亿,1个bit可以存2个数,2个bit可以存4个数(0,1,2,3)。那么假设我们存的都是非常小的数字能否将存储所占空间压下来呢。如果我们只取 posting list 中的数字差值,这将是一个非常小的数字,比如上图是100W个1。这样我们通过只取差值,得到了一个100W个1的列表,并将每个元素只耗费1bit存储了下来。这样可以压缩32倍存储空间。
但事实是,一般没有这么理想的状态。
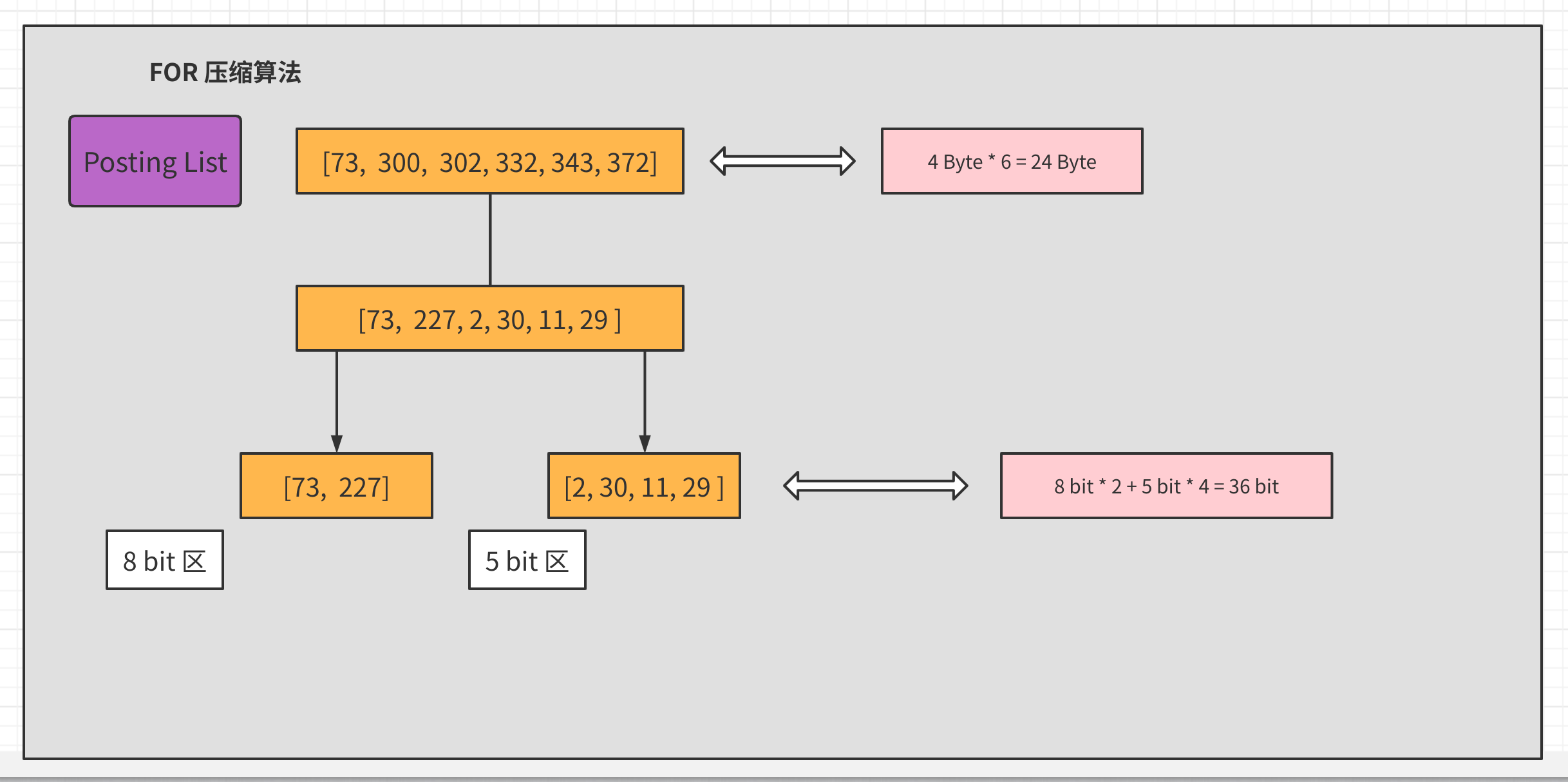
6.3.1、 增量编码(Delta-encode):只记录Posting List(有序)中各元素的增量:
比如现在有 id 列表[73, 300, 302, 332, 342, 372],转化成每一个 id 相对于前一个 id 的增量值(第一个 id 的前一个 id 默认是 0,增量就是它自己)列表是 [73, 227, 2, 30, 11, 29 ]。在这个新的列表里面,所有的 id 都是小于 255 的,所以每个 id 只需要一个字节存储。

进过最后的位压缩之后,整型数组的类型从固定大小 (8,16,32,64 位)4 种类型,扩展到了[1-64] 位共 64 种类型。
通过以上的方式可以极大的节省 posting list 的空间消耗,提高查询性能。不过 ES 为了提高 filter 过滤器查询的性能,还做了更多的工作,那就是缓存。
将原数据转换成为只保留第一项值,然后通过累加方式获取后面的值:
原数据转换后为:73 227 2 30 11 29
即:73 73+227=300 73+227+2=302 …
这样做的原因是因为字节存储位数的原因:
int32 需要4个字节(byte)
int64 需要8个字节(byte)
转换后,除了第一个数字后面的数字可以使用更少的字节存储数据
6.3.2、 分割成块(Split into blocks):将 Posting List 分割成每个最大256元素的小块,分块是为了降低各块的步长,以最小的成本存储数据
将增量编码后的list再进行分割成每个最大256元素的小块,可以防止再次出现后续还有大于步长的数据,比如原数据为的情况:73 300 302 332 343 672增量到672时已经大于300步长了,需要占用够多的空间
这些数中227是最大的,需要8bit(227 < 2^8)来盛装,那么每个数值都不会超过8bit,所以需要的大小是6 * 8bit=48bit。因为相比较于原数组,我们引入了一个箱子的概念,那么除了箱子数,我们还需要记录每个箱子的大小,所以需要有一个数来记录箱子大小(假设 8 bit 用来声明 8 bit 区)。那么总共的大小是 48 bit + 8 bit = 56 bit。
可以看到压缩后大小由192bit降到了56bit,已经有很大改善了,但是这还不是FOR算法的终点,观察这组数中最大值227,后一位最小值是2,两者相差很大,2实际上只需要1bit来盛装,那么能不能进一步压缩呢?答案是可以,只是不再需要做差值,直接将数组分组,分为:
8 bit 区:[73, 227]
5 bit 区:[2, 30, 11, 29]
那么占用空间就变成了73,227箱子大小8bit,2,30,11,29中最大30,箱子大小为5bit 因此数组总大小为28bit + 45bit = 36bit,另外不要忘记这里因为分成两组,还需要单独记录两组箱子的大小值,所以总大小是36bit+2*8bit= 52bit
6.3.3、 按位压缩(Bit packing):将十进制整型(假设是int32需要有32个bit)转换为二进制(1个字节(byte)=8个位(bit))
按照占用位数最长的数据存储如:73 227 2十进制整数转换为二进制后分别为1001001 11100011 10,转换后占用最长的bit长度为8,所以使用3个bit[8]即24个bit=3个字节存储数据即可,原本73 227 2需要使用3个bit[32]即96个bit=12个字节存储数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号