hiveSQL和sparkSQL使用整形数字与字符串数字不等于比较表现不一致的行为记录。
Hive版本:2.3.4
Spark版本:2.4.0
问题:在线上查看数据时,数据平台跑出的数据与外部平台不一致。使用的SQL一样,经排查发现是使用 WHERE value <> 0,导致的。value 为字符串格式的数字id。
样例SQL如下:
DROP TABLE IF EXISTS test.zero_test;
CREATE TABLE test.zero_test TBLPROPERTIES ("orc.compress" = "SNAPPY")
AS
SELECT
'0' AS value
UNION ALL
SELECT
'000000000000001234' AS value
UNION ALL
SELECT
'000000000000001235' AS value
UNION ALL
SELECT
'000000000000001236' AS value
UNION ALL
SELECT
'123231410120391845' AS value
UNION ALL
SELECT
'123235656453391845' AS value
UNION ALL
SELECT
'1232334279892211845' AS value
;
进行查询
SELECT *
FROM test.zero_test
WHERE value <> 0
;
Hive结果:
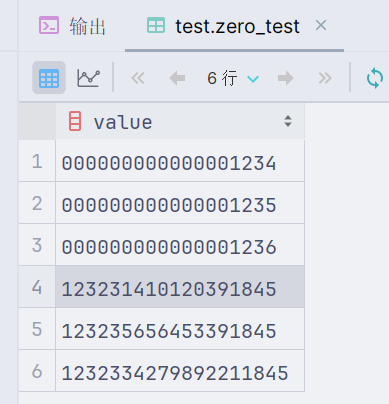
SparkSQL结果:
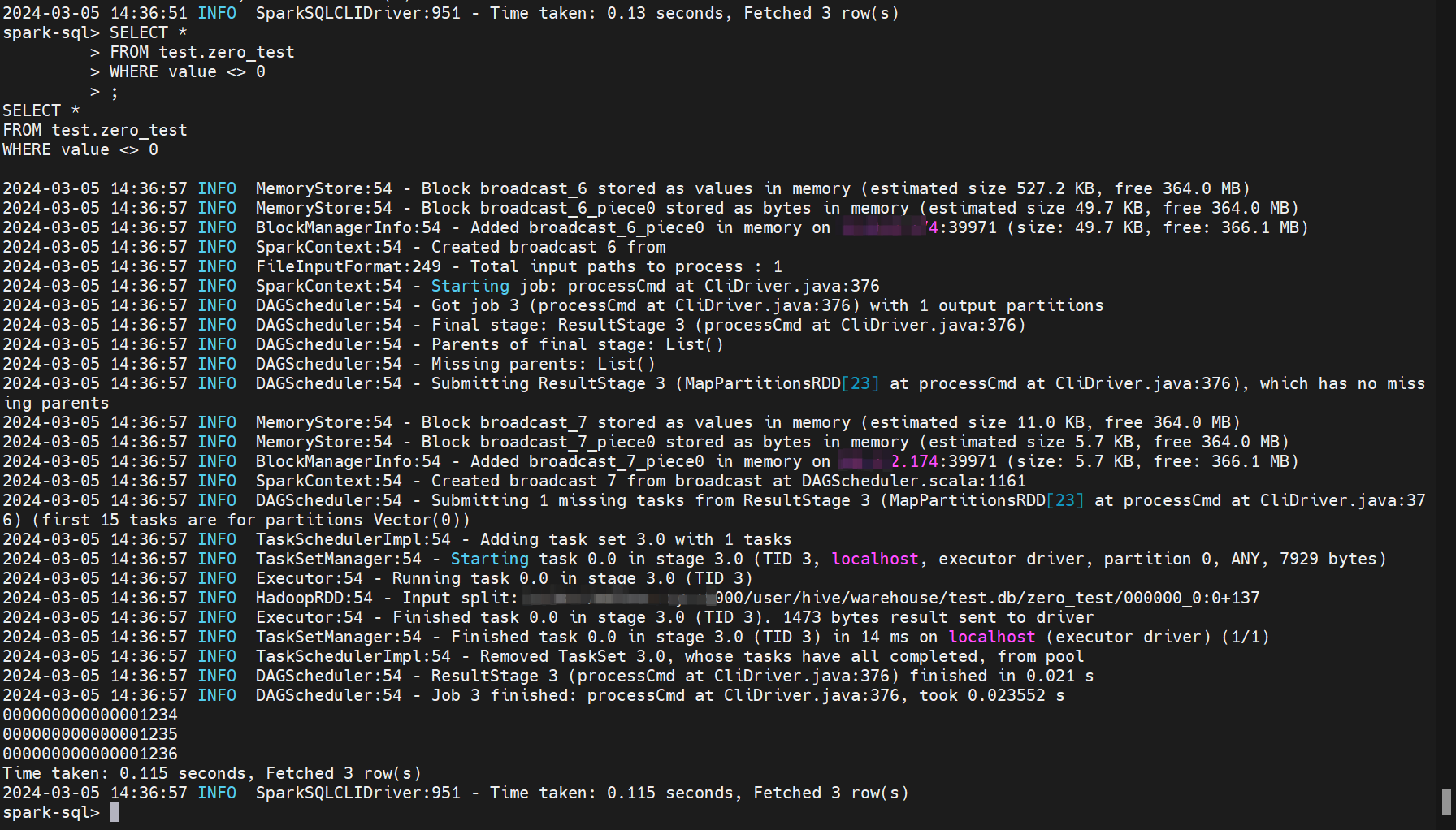
查看Hive执行计划:
可以看到Hive比较0时,强转为了Double。
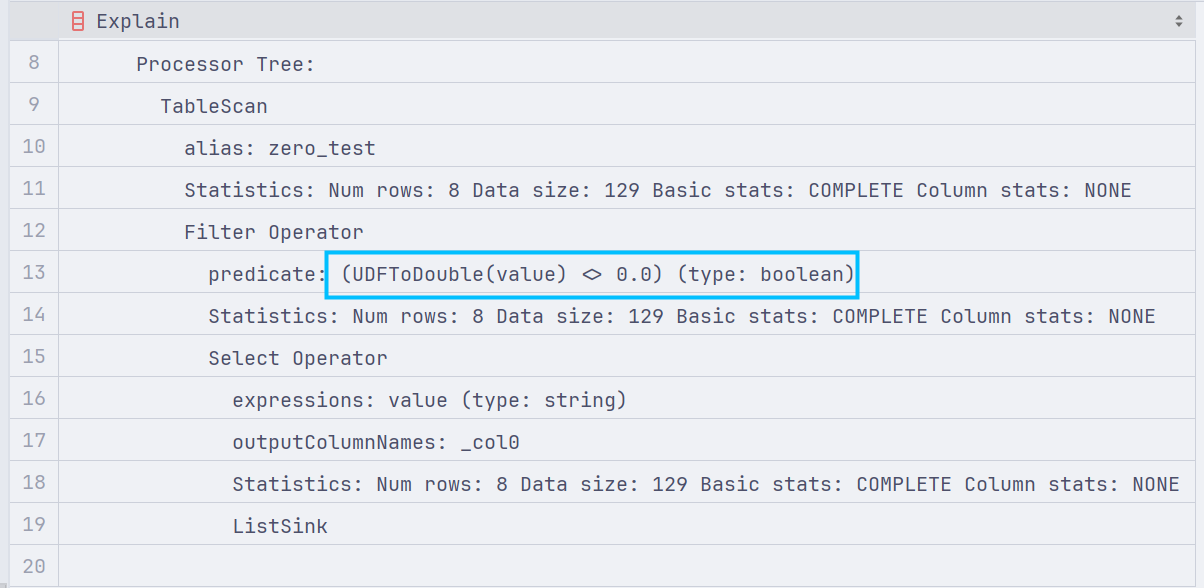
查看SparkSQL执行计划:
可以看到SparkSQL,将字段强转为了Int

那么构建测试用例:
DROP TABLE IF EXISTS test.zero_test;
CREATE TABLE test.zero_test TBLPROPERTIES ("orc.compress" = "SNAPPY")
AS
SELECT
'0' AS value
UNION ALL
SELECT
'2147483647' AS value
UNION ALL
SELECT
'2147483648' AS value
UNION ALL
SELECT
'9223372036854775807' AS value
UNION ALL
SELECT
'9223372036854775808' AS value
UNION ALL
SELECT
'AA32334279892211845' AS value
UNION ALL
SELECT
'A123' AS value
UNION ALL
SELECT
'123A' AS value;
;
推测:强转为了Int类型,比较没有结果的原因就是强转失败导致返回false,如果推测准确那么就是只会出现2147483647(Int.MAX_VALUE)这一个数字。
结果:
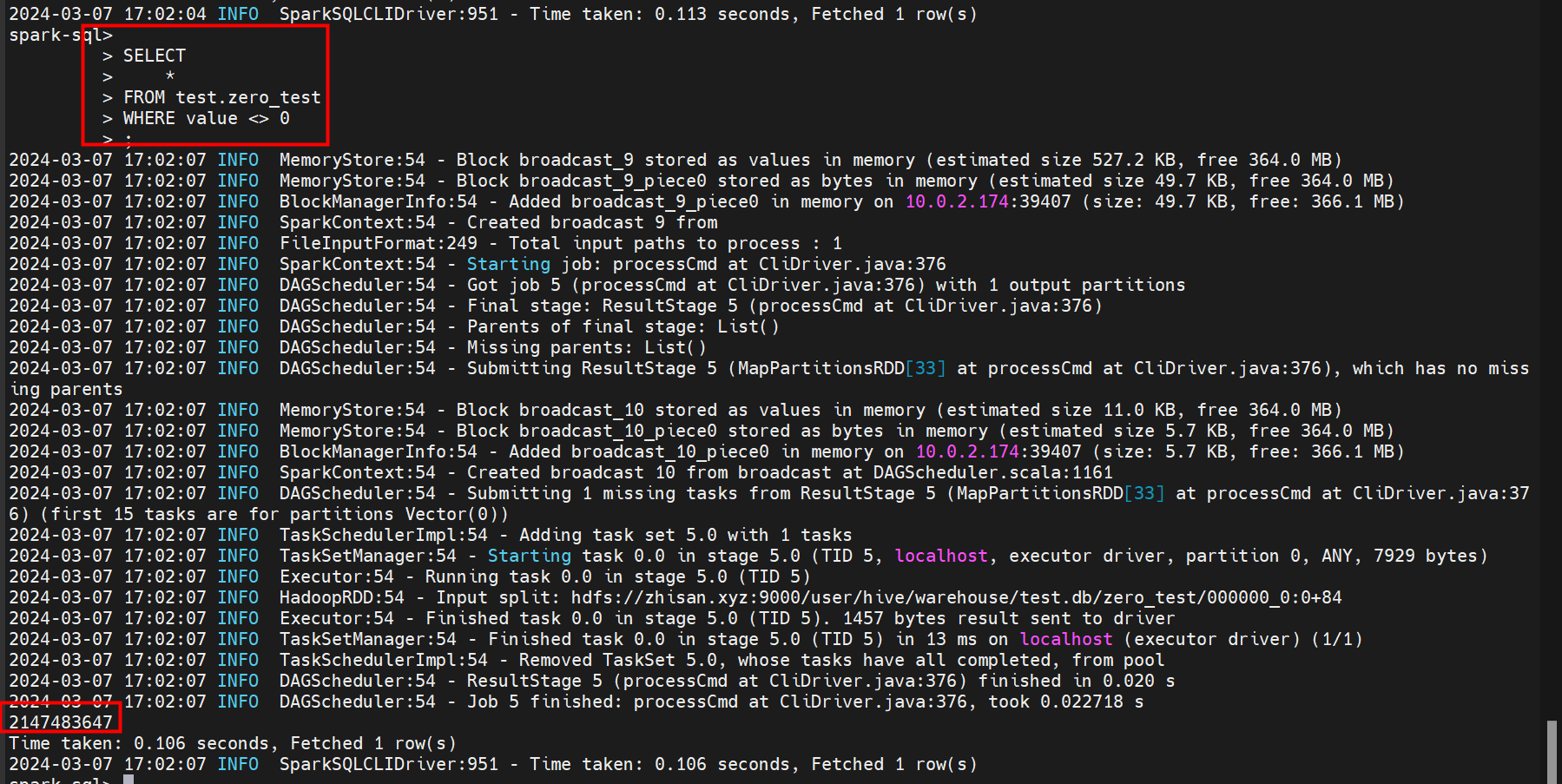
推测目前看起来是没问题的,导致这种现象的原因就是与0比较时强转为了Int类型,而Hive使用Double类型。
注:因为在使用分区时使用以数字的形式与yyyyMMdd的分区日期进行比较(例如:date_time=20220304),能够正常比较,同时也在多个关系型数据库中使用整形与数字字符串进行比较正常,所以在线上看到Hive的预览结果与平台SparkSQL的不一致时,并未第一时间往数字与字符串比较异常这方面想。所以,写严谨点,使用字符串进行比较。
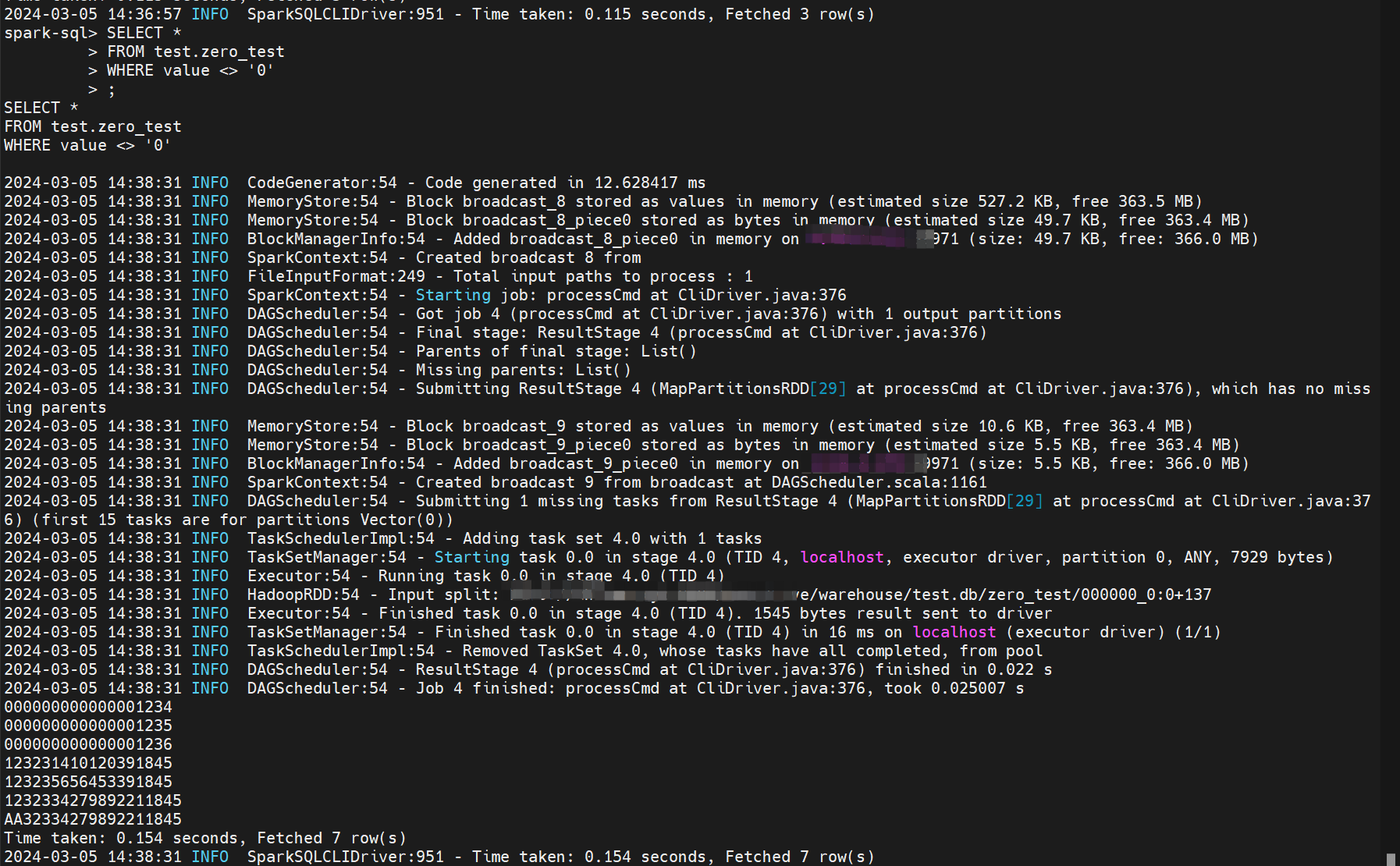
SELECT *
FROM test.zero_test
WHERE value <> '0'
;



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 2025年我用 Compose 写了一个 Todo App
· 张高兴的大模型开发实战:(一)使用 Selenium 进行网页爬虫