Mustache.js前端模板引擎源码解读
mustache是一个很轻的前端模板引擎,因为之前接手的项目用了这个模板引擎,自己就也继续用了一会觉得还不错,最近项目相对没那么忙,于是就抽了点时间看了一下这个的源码。源码很少,也就只有六百多行,所以比较容易阅读。做前端的话,还是要多看优秀源码,这个模板引擎的知名度还算挺高,所以其源码也肯定有值得一读的地方。
本人前端小菜,写这篇博文纯属自己记录一下以便做备忘,同时也想分享一下,希望对园友有帮助。若解读中有不当之处,还望指出。
如果没用过这个模板引擎,建议 去 https://github.com/janl/mustache.js/ 试着用一下,上手很容易。
摘取部分官方demo代码(当然还有其他基本的list遍历输出):
数据: { "name": { "first": "Michael", "last": "Jackson" }, "age": "RIP" } 模板写法: * {{name.first}} {{name.last}} * {{age}} 渲染效果: * Michael Jackson * RIP
OK,那就开始来解读它的源码吧:
首先先看下源码中的前面多行代码:
var Object_toString = Object.prototype.toString; var isArray = Array.isArray || function (object) { return Object_toString.call(object) === '[object Array]'; }; function isFunction(object) { return typeof object === 'function'; } function escapeRegExp(string) { return string.replace(/[\-\[\]{}()*+?.,\\\^$|#\s]/g, "\\$&"); } // Workaround for https://issues.apache.org/jira/browse/COUCHDB-577 // See https://github.com/janl/mustache.js/issues/189 var RegExp_test = RegExp.prototype.test; function testRegExp(re, string) { return RegExp_test.call(re, string); } var nonSpaceRe = /\S/; function isWhitespace(string) { return !testRegExp(nonSpaceRe, string); } var entityMap = { "&": "&", "<": "<", ">": ">", '"': '"', "'": ''', "/": '/' }; function escapeHtml(string) { return String(string).replace(/[&<>"'\/]/g, function (s) { return entityMap[s]; }); } var whiteRe = /\s*/; //匹配0个或以上空格 var spaceRe = /\s+/; //匹配一个或以上空格 var equalsRe = /\s*=/; //匹配0个或者以上空格再加等于号 var curlyRe = /\s*\}/; //匹配0个或者以上空格再加}符号 var tagRe = /#|\^|\/|>|\{|&|=|!/; //匹配 #,^,/,>,{,&,=,!
这些都比较简单,都是一些为后面主函数准备的工具函数,包括
· toString和test函数的简易封装
· 判断对象类型的方法
· 字符过滤正则表达式关键符号的方法
· 判断字符为空的方法
· 转义字符映射表 和 通过映射表将html转码成非html的方法
· 一些简单的正则。
一般来说mustache在js中的使用方法都是如下:
var template = $('#template').html(); Mustache.parse(template); // optional, speeds up future uses var rendered = Mustache.render(template, {name: "Luke"}); $('#target').html(rendered);
所以,我们接下来就看下parse的实现代码,我们在源码里搜索parse,于是找到这一段
mustache.parse = function (template, tags) { return defaultWriter.parse(template, tags); };
再通过找defaultWriter的原型Writer类后,很容易就可以找到该方法的核心所在,就是parseTemplate方法,这是一个解析器,不过在看这个方法之前,还得先看一个类:Scanner,顾名思义,就是扫描器,源码如下
/** * 简单的字符串扫描器,用于扫描获取模板中的模板标签 */ function Scanner(string) { this.string = string; //模板总字符串 this.tail = string; //模板剩余待扫描字符串 this.pos = 0; //扫描索引,即表示当前扫描到第几个字符串 } /** * 如果模板被扫描完则返回true,否则返回false */ Scanner.prototype.eos = function () { return this.tail === ""; }; /** * 扫描的下一批的字符串是否匹配re正则,如果不匹配或者match的index不为0; * 即例如:在"abc{{"中扫描{{结果能获取到匹配,但是index为4,所以返回"";如果在"{{abc"中扫描{{能获取到匹配,此时index为0,即返回{{,同时更新扫描索引 */ Scanner.prototype.scan = function (re) { var match = this.tail.match(re); if (!match || match.index !== 0) return ''; var string = match[0]; this.tail = this.tail.substring(string.length); this.pos += string.length; return string; }; /** * 扫描到符合re正则匹配的字符串为止,将匹配之前的字符串返回,扫描索引设为扫描到的位置 */ Scanner.prototype.scanUntil = function (re) { var index = this.tail.search(re), match; switch (index) { case -1: match = this.tail; this.tail = ""; break; case 0: match = ""; break; default: match = this.tail.substring(0, index); this.tail = this.tail.substring(index); } this.pos += match.length; return match; };
扫描器,就是用来扫描字符串,在mustache用于扫描模板代码中的模板标签。扫描器中就三个方法:
eos:判断当前扫描剩余字符串是否为空,也就是用于判断是否扫描完了
scan:仅扫描当前扫描索引的下一堆匹配正则的字符串,同时更新扫描索引,注释里我也举了个例子
scanUntil:扫描到匹配正则为止,同时更新扫描索引
看完扫描器,我们再回归一下,去看一下解析器parseTemplate方法,模板的标记标签默认为"{{}}",虽然也可以自己改成其他,不过为了统一,所以下文解读的时候都默认为{{}}:
function parseTemplate(template, tags) { if (!template) return []; var sections = []; // 用于临时保存解析后的模板标签对象 var tokens = []; // 保存所有解析后的对象 var spaces = []; // 保存空格对象在tokens里的索引 var hasTag = false; var nonSpace = false; // 去除保存在tokens里的空格标记 function stripSpace() { if (hasTag && !nonSpace) { while (spaces.length) delete tokens[spaces.pop()]; } else { spaces = []; } hasTag = false; nonSpace = false; } var openingTagRe, closingTagRe, closingCurlyRe; //将tag转成正则,默认的tag为{{和}},所以转成匹配{{的正则,和匹配}}的正则,已经匹配}}}的正则(因为mustache的解析中如果是{{{}}}里的内容则被解析为html代码) function compileTags(tags) { if (typeof tags === 'string') tags = tags.split(spaceRe, 2); if (!isArray(tags) || tags.length !== 2) throw new Error('Invalid tags: ' + tags); openingTagRe = new RegExp(escapeRegExp(tags[0]) + '\\s*'); closingTagRe = new RegExp('\\s*' + escapeRegExp(tags[1])); closingCurlyRe = new RegExp('\\s*' + escapeRegExp('}' + tags[1])); } compileTags(tags || mustache.tags); var scanner = new Scanner(template); var start, type, value, chr, token, openSection; while (!scanner.eos()) { start = scanner.pos; // Match any text between tags. // 开始扫描模板,扫描至{{时停止扫描,并且将此前扫描过的字符保存为value value = scanner.scanUntil(openingTagRe); if (value) { //遍历{{前的字符 for (var i = 0, valueLength = value.length; i < valueLength; ++i) { chr = value.charAt(i); //如果当前字符为空格,则用spaces数组记录保存至tokens里的索引 if (isWhitespace(chr)) { spaces.push(tokens.length); } else { nonSpace = true; } tokens.push([ 'text', chr, start, start + 1 ]); start += 1; // 如果遇到换行符,则将前一行的空格去掉 if (chr === '\n') stripSpace(); } } // 判断下一个字符串中是否有{[,同时更新扫描索引至{{后一位 if (!scanner.scan(openingTagRe)) break; hasTag = true; //扫描标签类型,是{{#}}还是{{=}}还是其他 type = scanner.scan(tagRe) || 'name'; scanner.scan(whiteRe); //根据标签类型获取标签里的值,同时通过扫描器,刷新扫描索引 if (type === '=') { value = scanner.scanUntil(equalsRe); //使扫描索引更新为\s*=后 scanner.scan(equalsRe); //使扫描索引更新为}}后,下面同理 scanner.scanUntil(closingTagRe); } else if (type === '{') { value = scanner.scanUntil(closingCurlyRe); scanner.scan(curlyRe); scanner.scanUntil(closingTagRe); type = '&'; } else { value = scanner.scanUntil(closingTagRe); } // 匹配模板闭合标签即}},如果没有匹配到则抛出异常,同时更新扫描索引至}}后一位,至此时即完成了一个模板标签{{#tag}}的扫描 if (!scanner.scan(closingTagRe)) throw new Error('Unclosed tag at ' + scanner.pos); // 将模板标签也保存至tokens数组中 token = [ type, value, start, scanner.pos ]; tokens.push(token); //如果type为#或者^,也将tokens保存至sections if (type === '#' || type === '^') { sections.push(token); } else if (type === '/') { //如果type为/则说明当前扫描到的模板标签为{{/tag}},则判断是否有{{#tag}}与其对应 // 检查模板标签是否闭合,{{#}}是否与{{/}}对应,即临时保存在sections最后的{{#tag}},是否跟当前扫描到的{{/tag}}的tagName相同 // 具体原理:扫描第一个tag,sections为[{{#tag}}],扫描第二个后sections为[{{#tag}} , {{#tag2}}]以此类推扫描多个开始tag后,sections为[{{#tag}} , {{#tag2}} ... {{#tag}}] // 所以接下来如果扫描到{{/tag}}则需跟sections的最后一个相对应才能算标签闭合。同时比较后还需将sections的最后一个删除,才能进行下一轮比较 openSection = sections.pop(); if (!openSection) throw new Error('Unopened section "' + value + '" at ' + start); if (openSection[1] !== value) throw new Error('Unclosed section "' + openSection[1] + '" at ' + start); } else if (type === 'name' || type === '{' || type === '&') { nonSpace = true; } else if (type === '=') { compileTags(value); } } // 保证sections里没有对象,如果有对象则说明标签未闭合 openSection = sections.pop(); if (openSection) throw new Error('Unclosed section "' + openSection[1] + '" at ' + scanner.pos); //在对tokens里的数组对象进行筛选,进行数据的合并及剔除 return nestTokens(squashTokens(tokens)); }
解析器就是用于解析模板,将html标签即内容与模板标签分离,整个解析原理为遍历字符串,通过最前面的那几个正则以及扫描器,将普通html和模板标签{{#tagName}}{{/tagName}}{{^tagName}}扫描出来并且分离,将每一个{{#XX}}、{{^XX}}、{{XX}}、{{/XX}}还有普通不含模板标签的html等全部抽象为数组保存至tokens。
tokens的存储方式为:

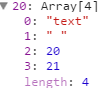
token[0]为token的type,可能值为:# ^ / & name text等分别表示{{#XX}}、{{^XX}}、{{/XX}}、{{&XX}}、{{XX}}、以及html文本等
token[1]为token的内容,如果是模板标签,则为标签名,如果为html文本,则是html的文本内容
token[2],token[3]为匹配开始位置和结束位置,后面将数据结构转换成树形结构的时候还会有token[4]和token[5]
具体的扫描方式为以{{}}为扫描依据,利用扫描器的scanUtil方法,扫描到{{后停止,通过scanner的scan方法匹配tagRe正则(/#|\^|\/|>|\{|&|=|!/)从而判断出{{后的字符是否为模板关键字符,再用scanUtil方法扫描至}}停止,获取获取到的内容,此时就可以获取到tokens[0]、tokens[1]、tokens[2],再调用一下scan更新扫描索引,就可以获取到token[3]。同理,下面的字符串也是如此扫描,直至最后一行return nestTokens(squashTokens(tokens))之前,扫描出来的结果为,模板标签为一个token对象,如果是html文本,则每一个字符都作为一个token对象,包括空格字符。这些数据全部按照扫描顺序保存在tokens数组里,不仅杂乱而且量大,所以最后一行代码中的squashTokens方法和nestTokens用来进行数据筛选以及整合。
首先来看下squashTokens方法,该方法主要是整合html文本,对模板标签的token对象没有进行处理,代码很简单,就是将连续的html文本token对象整合成一个。
function squashTokens(tokens) { var squashedTokens = []; var token, lastToken; for (var i = 0, numTokens = tokens.length; i < numTokens; ++i) { token = tokens[i]; if (token) { if (token[0] === 'text' && lastToken && lastToken[0] === 'text') { lastToken[1] += token[1]; lastToken[3] = token[3]; } else { squashedTokens.push(token); lastToken = token; } } } return squashedTokens; }
整合完html文本的token对象后,就通过nestTokens进行进一步的整合,遍历tokens数组,如果当前token为{{#XX}}或者{{^XX}}都说明是模板标签的开头标签,于是把它的第四个参数作为收集器存为collector进行下一轮判断,如果当前token为{{/}}则说明遍历到了模板闭合标签,取出其相对应的开头模板标签,再给予其第五个值为闭合标签的开始位置。如果是其他,则直接扔进当前的收集器中。如此遍历完后,tokens里的token对象就被整合成了树形结构
function nestTokens(tokens) { var nestedTokens = []; //collector是个收集器,用于收集当前标签子元素的工具 var collector = nestedTokens; var sections = []; var token, section; for (var i = 0, numTokens = tokens.length; i < numTokens; ++i) { token = tokens[i]; switch (token[0]) { case '#': case '^': collector.push(token); sections.push(token); //存放模板标签的开头对象 collector = token[4] = []; //此处可分解为:token[4]=[];collector = token[4];即将collector指向当前token的第4个用于存放子对象的容器 break; case '/': section = sections.pop(); //当发现闭合对象{{/XX}}时,取出与其相对应的开头{{#XX}}或{{^XX}} section[5] = token[2]; collector = sections.length > 0 ? sections[sections.length - 1][4] : nestedTokens; //如果sections未遍历完,则说明还是有可能发现{{#XX}}开始标签,所以将collector指向最后一个sections中的最后一个{{#XX}} break; default: collector.push(token); //如果是普通标签,扔进当前的collector中 } } //最终返回的数组即为树形结构 return nestedTokens; }
经过两个方法的筛选和整合,最终出来的数据就是精简的树形结构数据:

至此,整个解析器的代码就分析完了,然后我们来分析渲染器的代码。
parseTemplate将模板代码解析为树形结构的tokens数组,按照平时写mustache的习惯,用完parse后,就是直接用 xx.innerHTML = Mustache.render(template , obj),因为此前会先调用parse解析,解析的时候会将解析结果缓存起来,所以当调用render的时候,就会先读缓存,如果缓存里没有相关解析数据,再调用一下parse进行解析。
Writer.prototype.render = function (template, view, partials) { var tokens = this.parse(template); //将传进来的js对象实例化成context对象 var context = (view instanceof Context) ? view : new Context(view); return this.renderTokens(tokens, context, partials, template); };
可见,进行最终解析的renderTokens函数之前,还要先把传进来的需要渲染的对象数据进行处理一下,也就是把数据包装成context对象。所以我们先看下context部分的代码:
function Context(view, parentContext) { this.view = view == null ? {} : view; this.cache = { '.': this.view }; this.parent = parentContext; } /** * 实例化一个新的context对象,传入当前context对象成为新生成context对象的父对象属性parent中 */ Context.prototype.push = function (view) { return new Context(view, this); }; /** * 获取name在js对象中的值 */ Context.prototype.lookup = function (name) { var cache = this.cache; var value; if (name in cache) { value = cache[name]; } else { var context = this, names, index; while (context) { if (name.indexOf('.') > 0) { value = context.view; names = name.split('.'); index = 0; while (value != null && index < names.length) value = value[names[index++]]; } else if (typeof context.view == 'object') { value = context.view[name]; } if (value != null) break; context = context.parent; } cache[name] = value; } if (isFunction(value)) value = value.call(this.view); console.log(value) return value; };
context部分代码也是很少,context是专门为树形结构提供的工厂类,context的构造函数中,this.cache = {'.':this.view}是把需要渲染的数据缓存起来,同时在后面的lookup方法中,把需要用到的属性值从this.view中剥离到缓存的第一层来,也就是lookup方法中的cache[name] = value,方便后期查找时先在缓存里找
context的push方法比较简单,就是形成树形关系,将新的数据传进来封装成新的context对象,并且将新的context对象的parent值指向原来的context对象。
context的lookup方法,就是获取name在渲染对象中的值,我们一步一步来分析,先是判断name是否在cache中的第一层,如果不在,才进行深度获取。然后将进行一个while循环:
先是判断name是否有.这个字符,如果有点的话,说明name的格式为XXX.XX,也就是很典型的键值的形式。然后就将name通过.分离成一个数组names,通过while循环遍历names数组,在需要渲染的数据中寻找以name为键的值。
如果name没有.这个字符,说明是一个单纯的键,先判断一下需要渲染的数据类型是否为对象,如果是,就直接获取name在渲染的数据里的值。
通过两层判断,如果没找到符合的值,则将当前context置为context的父对象,再对其父对象进行寻找,直至找到value或者当前context无父对象为止。如果找到了,将值缓存起来。
看完context类的代码,就可以看渲染器的代码了:
Writer.prototype.renderTokens = function (tokens, context, partials, originalTemplate) { var buffer = ''; var self = this; function subRender(template) { return self.render(template, context, partials); } var token, value; for (var i = 0, numTokens = tokens.length; i < numTokens; ++i) { token = tokens[i]; switch (token[0]) { case '#': value = context.lookup(token[1]); //获取{{#XX}}中XX在传进来的对象里的值 if (!value) continue; //如果不存在则跳过 //如果为数组,说明要复写html,通过递归,获取数组里的渲染结果 if (isArray(value)) { for (var j = 0, valueLength = value.length; j < valueLength; ++j) { //获取通过value渲染出的html buffer += this.renderTokens(token[4], context.push(value[j]), partials, originalTemplate); } } else if (typeof value === 'object' || typeof value === 'string') { //如果value为对象,则不用循环,根据value进入下一次递归 buffer += this.renderTokens(token[4], context.push(value), partials, originalTemplate); } else if (isFunction(value)) { //如果value是方法,则执行该方法,并且将返回值保存 if (typeof originalTemplate !== 'string') throw new Error('Cannot use higher-order sections without the original template'); // Extract the portion of the original template that the section contains. value = value.call(context.view, originalTemplate.slice(token[3], token[5]), subRender); if (value != null) buffer += value; } else { buffer += this.renderTokens(token[4], context, partials, originalTemplate); } break; case '^': //如果为{{^XX}},则说明要当value不存在(null、undefine、0、'')或者为空数组的时候才触发渲染 value = context.lookup(token[1]); // Use JavaScript's definition of falsy. Include empty arrays. // See https://github.com/janl/mustache.js/issues/186 if (!value || (isArray(value) && value.length === 0)) buffer += this.renderTokens(token[4], context, partials, originalTemplate); break; case '>': //防止对象不存在 if (!partials) continue; //>即直接读取该值,如果partials为方法,则执行,否则获取以token为键的值 value = isFunction(partials) ? partials(token[1]) : partials[token[1]]; if (value != null) buffer += this.renderTokens(this.parse(value), context, partials, value); break; case '&': //如果为&,说明该属性下显示为html,通过lookup方法获取其值,然后叠加到buffer中 value = context.lookup(token[1]); if (value != null) buffer += value; break; case 'name': //如果为name说明为属性值,不作为html显示,通过mustache.escape即escapeHtml方法将value中的html关键词转码 value = context.lookup(token[1]); if (value != null) buffer += mustache.escape(value); break; case 'text': //如果为text,则为普通html代码,直接叠加 buffer += token[1]; break; } } return buffer; };
原理还是比较简单的,因为tokens的树形结构已经形成,渲染数据就只需要按照树形结构的顺序进行遍历输出就行了。
不过还是大概描述一下,buffer是用来存储渲染后的数据,遍历tokens数组,通过switch判断当前token的类型:
如果是#,先获取到{{#XX}}中的XX在渲染对象中的值value,如果没有该值,直接跳过该次循环,如果有,则判断value是否为数组,如果为数组,说明要复写html,再遍历value,通过递归获取渲染后的html数据。如果value为对象或者普通字符串,则不用循环输出,直接获取以value为参数渲染出的html,如果value为方法,则执行该方法,并且将返回值作为结果叠加到buffer中。如果是^,则当value不存在或者value是数组且数组为空的时候,才获取渲染数据,其他判断都是差不多。
通过这堆判断以及递归调用,就可以把数据完成渲染出来了。
至此,Mustache的源码也就解读完了,Mustache的核心就是一个解析器加一个渲染器,以非常简洁的代码实现了一个强大的模板引擎。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号