深层神经网络
深层神经网络

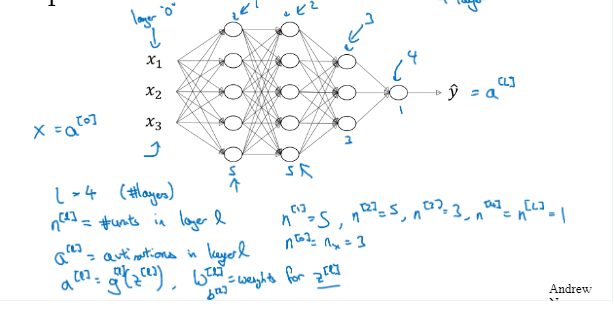
以下是一个四层的三个隐层的神经网络,隐层中的单元数目是553
然后我们用l表示层数,用n[l]表示节点数据或者是单元数量,例如:n[1]=5,表示的就是第一个隐层,单元数等于5
我们对于各个第l层都会用a[l]表示l层中的激活函数,以后就会遇到a[l]是激活函数g(z[l]),激活函数也会用层数l来标注。用W[l]表示在a[l]中计算z[l]值的权重,b[l]也一样
总结一下符号,输入特征用x表示,而x也是第0层的激活函数,x=a[0]
最后一层的激活函数a[L]等于y帽
深层网络中的前向传播
先一个例子来说,在第一层里需要计算z[1]=w[1]*x+b[1] ,而w[1]和b[1]就是会影响在第一层的激活单元的参数;然后计算第一层的激活函数:a[1]=g(z[1]),那么激活函数g的指标取决于所在层数。第二层亦是如此。
直到计算到输出层的时候,这里是z[4]=w[4]a[z]+b[4],a[4]=g[4](z[4])=y帽。
由于第0层输入层,x=a[0],我们可以将x替换。
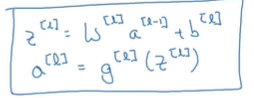
那我们继续看一下向量化训练整个训练集。公式其实都是差不多,只是把它们来写成列向量叠在一起
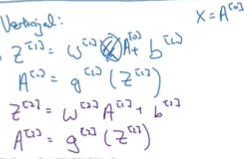
现在我们需要将所有的z或者a向量叠起来
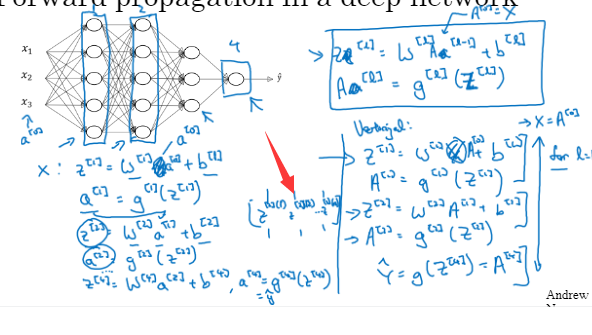
像这样子,a的做法也是如此。最后写出y帽
核对矩阵的维数
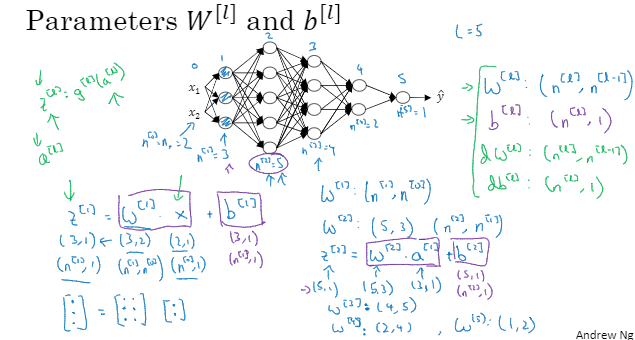
这个神经网络,l=5,也就是除去输入层以外数下来,总共有5层。那我们如果想实现正向传播的话。公式为
这里我们先关注W。在这个神经网络中,第一隐层有三个隐藏单元,也就是n[1]=3
然后我们来看看w、x、b的维数。z是第一个隐层的激活函数向量。这里z的维度是3*1,也就是一个三维的向量也可以写成(n[1],1)维向量;接下来看输入特征x,这里有两个输入特征,所以x的维度是2*1。然后通过公式知道z与x的维度,根据乘法法则可得出w的维度3*2,即(n[1],n[0]),总结下来w的维度就是(n[l],n[l-1]),剩下的几个也是如此。
然后我们回头看b[1],在这个神经网络中,b[1]的维度就是(3,1)的向量。要做向量加法,加上这个(3,1)。
一般来说b[l]的维度就是(n[l],1)
当我们做反向传播的时候,dw的维度应与w的维度一样,db的维度应与b的维度一样
由于z[l]等于对应元素的g[l](a[l]),那么这类网络中z和a的维度应该相等。
当你进行向量化后,z、a都会有一些改变
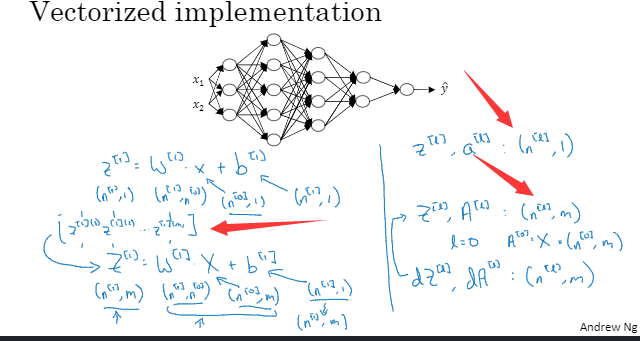
而当我们反向传播之后,dz和da的维度是和z、a一样的。所需要用代码实现的各个矩阵的维度,如果你想做深度神经网络的反向传播,写代码的时候一定要确认所有的矩阵维数前后一致
为什么使用深层表示
首先我们需要了解深度网络空间在计算什么。
当我们在建一个人脸识别或是人脸检测系统,神经网络需要做的就是在你输入一张脸部照片,我们可以把神经网络第一层当成一个特征探测器或者边缘探测器。
在这个例子中,大概会有20个隐藏单元的深度神经网络,那是怎么针对 这张图计算的,隐藏单元就是这些图里这些小方块,一个小方块就是一个隐藏单元,它会去找这个图片的边缘方向,那么这个隐藏单元可能是在找水平向的边缘在哪里。我们可以把照片组成边缘的像素放在一起看。

然后它可以把被探测到的边缘组合成面部的不同部分,比如说可能 有一个神经元会去找眼睛的部分,另外还有别的在找鼻子的部分 ,然后把这些部分组合在一起,意思可能要开始检测人脸的不同部分,最后再把这些部分放在一起,比如鼻子眼睛下巴,就可以识别或是探测不同的人脸。
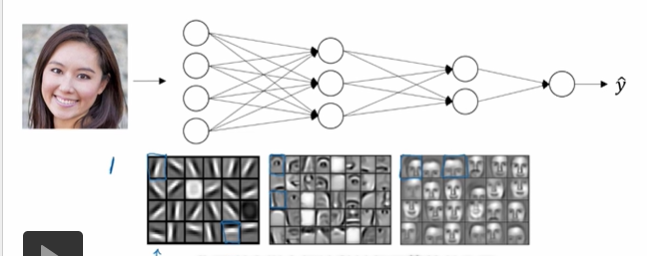
我们暂时可以把这种神经网络的前几层,当做探测简单的函数,比如边缘,之后 把它们跟后几层结合在一起。
当你想建立 一个语音识别系统 的时,需要解决的就是如何可视化语音,比如你输入一个音频片段,那么神经网络的第一层可能就会先去开始试卷探测比较低层次的音频波形的一些特征,比如音调是高了还是低了,可以选择些相对程度比较低的波形特征,然后把这些波形组成一个单元,就能去探测声音的基本单元,然后就可以从一个字母到一个单词到整个句子

搭建深层神经网络块
有一个层数较少的神经网络,我们先选择其中一层,从这一层的计算着手。在第l层你有参数W[l]和b[l],正向传播里有输入的激活函数,输入的是前一层a[l-1],输出是a[l]
然后z[l]=w[l]a[l-1]+b[l] a[l]=g[l](z[l])所以这就是你如何从输入a[l-1]走到输出的,然后我们就可以把z[l]的值缓存起来;然后反向传播步骤同样也是第l层的计算,你会需要实现一个函数输入为da[l],输出为da[l-1]的函数。
总结起来就是在l层你会有正向函数输入a[l-1]并且输出a[l] 为了计算结果 以及输出到缓存的z[l],然后用作反向传播的反向函数,输入da[l]输出da[l-1],你就会得到激活函数的导数,a[l-1]是会变的,前一层算出的激活函数导数,在这个里你需要w[l]和b[l],最后要算dz[l],这个反向函数可计算输出dw[l]和db[l]
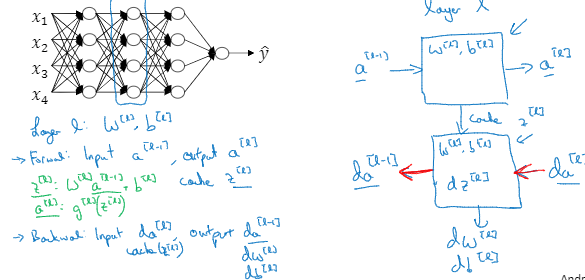
正向传播步骤
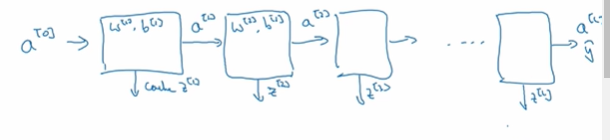
反向传播的话,我们需要算一系列的反向迭代,就是反向计算梯度,一开始是da[l]的值,然后是da[l-1]的值,一直到da[2]、da[1],每个方块也会输出dw[l] db[l]

w和b也会在每一层被更新
反向传播计算完毕,这是神经网络一个梯度下降循环
前向和反向传播



总结

当你用logistic回归做二分分类时,da[l]=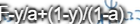 ,相对于y帽的损失函数的导数,可以得出等于da[l]的这个式子
,相对于y帽的损失函数的导数,可以得出等于da[l]的这个式子
参数VS超参数
在学习算法中还有其他参数需要输入到学习算法中,比如学习率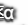 ,它决定参数如何进化;还有梯度下降法循环的数量;隐层数L;隐藏单元数;激活函数。这些都是超参数,这些参数都控制着最后参数W和b的值。
,它决定参数如何进化;还有梯度下降法循环的数量;隐层数L;隐藏单元数;激活函数。这些都是超参数,这些参数都控制着最后参数W和b的值。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号