最全的Spark基础知识解答
最全的Spark基础知识解答
原文:http://www.cnblogs.com/sanyuanempire/p/6163732.html
一. Spark基础知识
1.Spark是什么?
UCBerkeley AMPlab所开源的类HadoopMapReduce的通用的并行计算框架。
dfsSpark基于mapreduce算法实现的分布式计算,拥有HadoopMapReduce所具有的优点;但不同于MapReduce的是Job中间输出和结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的map reduce的算法。
2.Spark与Hadoop的对比(Spark的优势)
1、Spark的中间数据放到内存中,对于迭代运算效率更高
2、Spark比Hadoop更通用
3、Spark提供了统一的编程接口
4、容错性– 在分布式数据集计算时通过checkpoint来实现容错
5、可用性– Spark通过提供丰富的Scala, Java,Python API及交互式Shell来提高可用性
3.Spark有那些组件
1、Spark Streaming:支持高吞吐量、支持容错的实时流数据处理
2、Spark SQL, Data frames: 结构化数据查询
3、MLLib:Spark 生态系统里用来解决大数据机器学习问题的模块
4、GraphX是构建于Spark上的图计算模型
5、SparkR是一个R语言包,它提供了轻量级的方式使得可以在R语言中使用 Spark
二. DataFrame相关知识点
1.DataFrame是什么?
DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。
2.DataFrame与RDD的主要区别在于?
DataFrame带有schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型。这使得SparkSQL得以洞察更多的结构信息,从而对藏于DataFrame背后的数据源以及作用于DataFrame之上的变换进行了针对性的优化,最终达到大幅提升运行时效率的目标。
反观RDD,由于无从得知所存数据元素的具体内部结构,Spark Core只能在stage层面进行简单、通用的流水线优化。
3.DataFrame 特性
1、支持从KB到PB级的数据量
2、支持多种数据格式和多种存储系统
3、通过Catalyst优化器进行先进的优化生成代码
4、通过Spark无缝集成主流大数据工具与基础设施
5、API支持Python、Java、Scala和R语言
三 .RDD相关知识点
1.RDD,全称为?
Resilient Distributed Datasets,意为容错的、并行的数据结构,可以让用户显式地将数据存储到磁盘和内存中,并能控制数据的分区。同时,RDD还提供了一组丰富的操作来操作这些数据。
2.RDD的特点?
-
它是在集群节点上的不可变的、已分区的集合对象。
-
通过并行转换的方式来创建如(map, filter, join, etc)。
-
失败自动重建。
-
可以控制存储级别(内存、磁盘等)来进行重用。
-
必须是可序列化的。
-
是静态类型的。
3.RDD核心概念
Client:客户端进程,负责提交作业到Master。
Master:Standalone模式中主控节点,负责接收Client提交的作业,管理Worker,并命令Worker启动分配Driver的资源和启动Executor的资源。
Worker:Standalone模式中slave节点上的守护进程,负责管理本节点的资源,定期向Master汇报心跳,接收Master的命令,启动Driver和Executor。
Driver: 一个Spark作业运行时包括一个Driver进程,也是作业的主进程,负责作业的解析、生成Stage并调度Task到Executor上。包括DAGScheduler,TaskScheduler。
Executor:即真正执行作业的地方,一个集群一般包含多个Executor,每个Executor接收Driver的命令Launch Task,一个Executor可以执行一到多个Task。
4.RDD常见术语
DAGScheduler: 实现将Spark作业分解成一到多个Stage,每个Stage根据RDD的Partition个数决定Task的个数,然后生成相应的Task set放到TaskScheduler中。
TaskScheduler:实现Task分配到Executor上执行。
Task:运行在Executor上的工作单元
Job:SparkContext提交的具体Action操作,常和Action对应
Stage:每个Job会被拆分很多组任务(task),每组任务被称为Stage,也称TaskSet
RDD:Resilient Distributed Datasets的简称,弹性分布式数据集,是Spark最核心的模块和类
Transformation/Action:SparkAPI的两种类型;Transformation返回值还是一个RDD,Action返回值不少一个RDD,而是一个Scala的集合;所有的Transformation都是采用的懒策略,如果只是将Transformation提交是不会执行计算的,计算只有在Action被提交时才会被触发。
DataFrame: 带有Schema信息的RDD,主要是对结构化数据的高度抽象。
DataSet:结合了DataFrame和RDD两者的优势,既允许用户很方便的操作领域对象,又具有SQL执行引擎的高效表现。
5.RDD提供了两种类型的操作:
transformation和action
1,transformation是得到一个新的RDD,方式很多,比如从数据源生成一个新的RDD,从RDD生成一个新的RDD
2,action是得到一个值,或者一个结果(直接将RDD cache到内存中)
3,所有的transformation都是采用的懒策略,就是如果只是将transformation提交是不会执行计算的,计算只有在action被提交的时候才被触发
6.RDD中关于转换(transformation)与动作(action)的区别
transformation会生成新的RDD,而后者只是将RDD上某项操作的结果返回给程序,而不会生成新的RDD;无论执行了多少次transformation操作,RDD都不会真正执行运算(记录lineage),只有当action操作被执行时,运算才会触发。
7.RDD 与 DSM的最大不同是?
DSM(distributed shared memory)
RDD只能通过粗粒度转换来创建,而DSM则允许对每个内存位置上数据的读和写。在这种定义下,DSM不仅包括了传统的共享内存系统,也包括了像提供了共享 DHT(distributed hash table) 的 Piccolo 以及分布式数据库等。
8.RDD的优势?
1、高效的容错机制
2、结点落后问题的缓和 (mitigate straggler)
3、批量操作
4、优雅降级 (degrade gracefully)
9.如何获取RDD?
1、从共享的文件系统获取,(如:HDFS)
2、通过已存在的RDD转换
3、将已存在scala集合(只要是Seq对象)并行化 ,通过调用SparkContext的parallelize方法实现
4、改变现有RDD的之久性;RDD是懒散,短暂的。
10.RDD都需要包含以下四个部分
a.源数据分割后的数据块,源代码中的splits变量
b.关于“血统”的信息,源码中的dependencies变量
c.一个计算函数(该RDD如何通过父RDD计算得到),源码中的iterator(split)和compute函数
d.一些关于如何分块和数据存放位置的元信息,如源码中的partitioner和preferredLocations0
11.RDD中将依赖的两种类型
窄依赖(narrowdependencies)和宽依赖(widedependencies)。
窄依赖是指父RDD的每个分区都只被子RDD的一个分区所使用。相应的,那么宽依赖就是指父RDD的分区被多个子RDD的分区所依赖。例如,map就是一种窄依赖,而join则会导致宽依赖
依赖关系分类的特性:
第一,窄依赖可以在某个计算节点上直接通过计算父RDD的某块数据计算得到子RDD对应的某块数据;
第二,数据丢失时,对于窄依赖只需要重新计算丢失的那一块数据来恢复;
Spark Streaming相关知识点
1.Spark Streaming的基本原理
Spark Streaming的基本原理是将输入数据流以时间片(秒级)为单位进行拆分,然后以类似批处理的方式处理每个时间片数据
RDD 基本操作
常见的聚合操作:
-
count(*) 所有值不全为NULL时,加1操作
-
count(1) 不管有没有值,只要有这条记录,值就加1
-
count(col) col列里面的值为null,值不会加1,这个列里面的值不为NULL,才加1
sum求和
-
sum(可转成数字的值) 返回bigint
-
avg求平均值
-
avg(可转成数字的值)返回double
-
distinct不同值个数
-
count(distinct col)
按照某些字段排序
select col1,other... from table where conditio order by col1,col2 [asc|desc]
Join表连接
join等值连接(内连接),只有某个值在m和n中同时存在时。
left outer join 左外连接,左边表中的值无论是否在b中存在时,都输出;右边表中的值,只有在左边表中存在时才输出。
right outer join 和 left outer join 相反。
Transformation具体内容:
reduceByKey(func, [numTasks]) : 在一个(K,V)对的数据集上使用,返回一个(K,V)对的数据集,key相同的值,都被使用指定的reduce函数聚合到一起。和groupbykey类似,任务的个数是可以通过第二个可选参数来配置的。
join(otherDataset, [numTasks]) :在类型为(K,V)和(K,W)类型的数据集上调用,返回一个(K,(V,W))对,每个key中的所有元素都在一起的数据集
groupWith(otherDataset, [numTasks]) : 在类型为(K,V)和(K,W)类型的数据集上调用,返回一个数据集,组成元素为(K, Seq[V], Seq[W]) Tuples。这个操作在其它框架,称为CoGroup
cartesian(otherDataset) : 笛卡尔积。但在数据集T和U上调用时,返回一个(T,U)对的数据集,所有元素交互进行笛卡尔积。
flatMap(func) :类似于map,但是每一个输入元素,会被映射为0到多个输出元素(因此,func函数的返回值是一个Seq,而不是单一元素)
Case 1将一个list乘方后输出
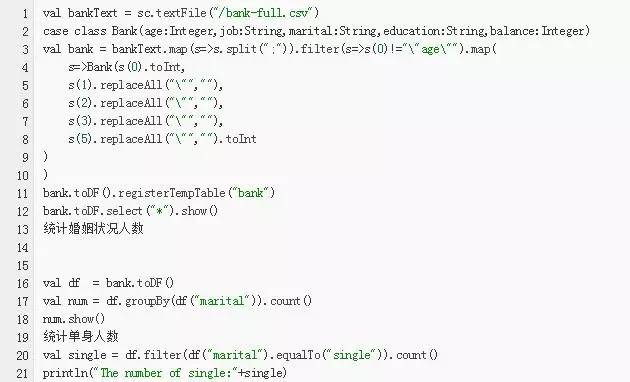
val input = sc.parallelize(List(1,2,3,4))
val result = input.map(x => x*x)
println(result.collect().mkString(","))
Case 2 wordcount
val textFile = sc.textFile(args(1))
val result = textFile.flatMap(line => line.split("\\s+")).map(word => (word, 1)).reduceByKey(_ + _)
println(result.collect().mkString(","))
result.saveAsTextFile(args(2))
Case 3 打印rdd的元素
rdd.foreach(println) 或者 rdd.map(println).
rdd.collect().foreach(println)
rdd.take(100).foreach(println)
spark SQL
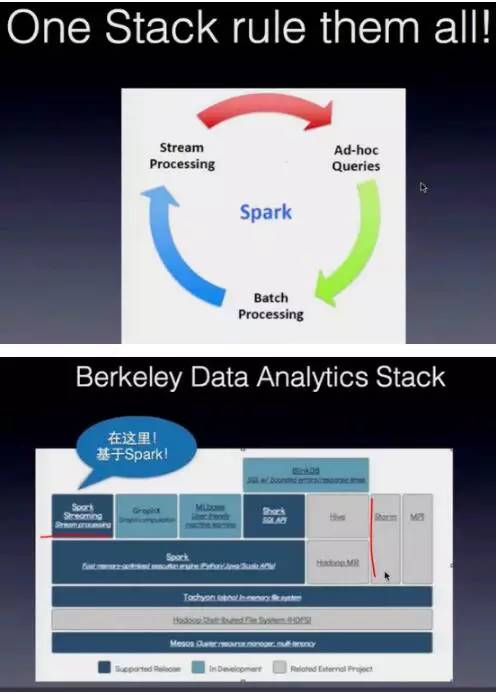
Spark Streaming优劣
优势:
1、统一的开发接口
2、吞吐和容错
3、多种开发范式混用,Streaming + SQL, Streaming +MLlib
4、利用Spark内存pipeline计算
劣势:
微批处理模式,准实时
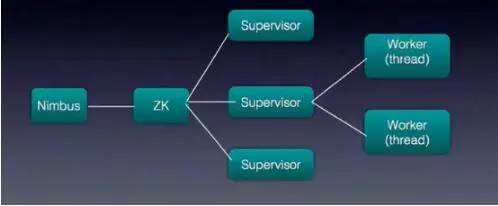
Storm结构:
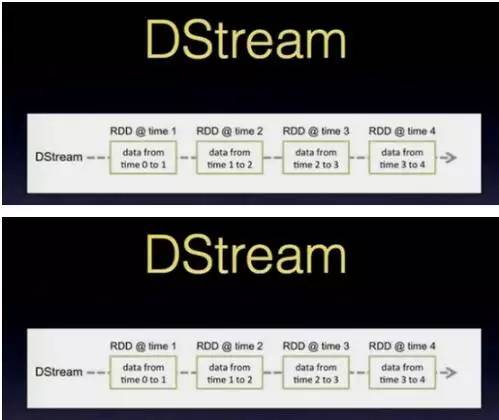
DStream
1.将流式计算分解成一系列确定并且较小的批处理作业
2.将失败或者执行较慢的任务在其它节点上并行执行,执行的最小单元为RDD的partition
3.较强的容错能力
spark stream example code

四. 日志系统
1.Flume
Flume是一个分布式的日志收集系统,具有高可靠、高可用、事务管理、失败重启等功能。数据处理速度快,完全可以用于生产环境。
Flume的核心是agent。
Agent是一个java进程,运行在日志收集端,通过agent接收日志,然后暂存起来,再发送到目的地。
Agent里面包含3个核心组件:source、channel、sink。
Source组件是专用于收集日志的,可以处理各种类型各种格式的日志数据,包括avro、thrift、exec、jms、spoolingdirectory、netcat、sequencegenerator、syslog、http、legacy、自定义。source组件把数据收集来以后,临时存放在channel中。
Channel组件是在agent中专用于临时存储数据的,可以存放在memory、jdbc、file、自定义。channel中的数据只有在sink发送成功之后才会被删除。
Sink组件是用于把数据发送到目的地的组件,目的地包括hdfs、logger、avro、thrift、ipc、file、null、hbase、solr、自定义。
Apache Kafka是分布式发布-订阅消息系统。
它最初由LinkedIn公司开发,之后成为Apache项目的一部分。Kafka是一种快速、可扩展的、设计内在就是分布式的,分区的和可复制的提交日志服务。
Apache Kafka与传统消息系统相比,有以下不同:
1、它被设计为一个分布式系统,易于向外扩展;
2、它同时为发布和订阅提供高吞吐量;
3、它支持多订阅者,当失败时能自动平衡消费者;
4、它将消息持久化到磁盘,因此可用于批量消费
五. 分布式搜索
搜索引擎是什么?
搜索引擎是指根据一定的策略、运用特定的计算机程序从互联网上搜集信息,在对信息进行组织和处理后,为用户提供检索服务,将用户检索相关的信息展示给用户的系统。搜索引擎包括全文索引、目录索引、元搜索引擎、垂直搜索引擎、集合式搜索引擎、门户搜索引擎与免费链接列表等。
Lucene是什么?
Lucene一个高性能、可伸缩的信息搜索库,即它不是一个完整的全文检索引擎,而是一个全检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎。
Elasticsearch是什么?
Elasticsearch一个高可扩展的开源的全文本搜索和分析工具。
它允许你以近实时的方式快速存储、搜索、分析大容量的数据。Elasticsearch是一个基于ApacheLucene(TM)的开源搜索引擎。无论在开源还是专有领域,Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。
ElasticSearch 有4中方式来构建数据库
最简单的方法是使用indexAPI,将一个Document发送到特定的index,一般通过curltools实现。
第二第三种方法是通过bulkAPI和UDPbulkAPI。两者的区别仅在于连接方式。
第四种方式是通过一个插件-river。river运行在ElasticSearch上,并且可以从外部数据库导入数据到ES中。需要注意的是,数据构建仅在分片上进行,而不能在副本上进行。
ELK是一套常用的开源日志监控和分析系统
包括一个分布式索引与搜索服务Elasticsearch,一个管理日志和事件的工具logstash,和一个数据可视化服务Kibana,logstash 负责日志的收集,处理和储存,elasticsearch 负责日志检索和分析,Kibana 负责日志的可视化。
六. 分布式数据库
1.Hive是什么?
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。本质是将HQL转换为MapReduce程序
2.Hive的设计目标?
1、Hive的设计目标是使Hadoop上的数据操作与传统SQL相结合,让熟悉SQL编程开发人员能够轻松向Hadoop平台迁移
2、Hive提供类似SQL的查询语言HQL,HQL在底层被转换为相应的MapReduce操作
3、Hive在HDFS上构建数据仓库来存储结构化的数据,这些数据一般来源与HDFS上的原始数据,使用Hive可以对这些数据执行查询、分析等操作。
3.Hive的数据模型
-
Hive数据库
-
内部表
-
外部表
-
分区
-
桶
-
Hive的视图
Hive在创建内部表时,会将数据移动到数据仓库指向的路径,若创建外部表,仅记录数据所在的路径,不对数据位置做任何改变,在删除表的时候,内部表的元数据和数据会被一起删除,外部表只会删除元数据,不删除数据。这样来说,外部表要比内部表安全,数据组织液更加灵活,方便共享源数据。
4.Hive的调用方式
1、Hive Shell
2、Thrift
3、JDBC
4、ODBC
5.Hive的运行机制
1、将sql转换成抽象语法树
2、将抽象语法树转化成查询块
3、将查询块转换成逻辑查询计划(操作符树)
4、将逻辑计划转换成物理计划(M\Rjobs)
6.Hive的优势
1、并行计算
2、充分利用集群的CPU计算资源、存储资源
3、处理大规模数据集
4、使用SQL,学习成本低
7.Hive应用场景
1、海量数据处理
2、数据挖掘
3、数据分析
4、SQL是商务智能工具的通用语言,Hive有条件和这些BI产品进行集成
8.Hive不适用场景
1、复杂的科学计算
2、不能做到交互式的实时查询
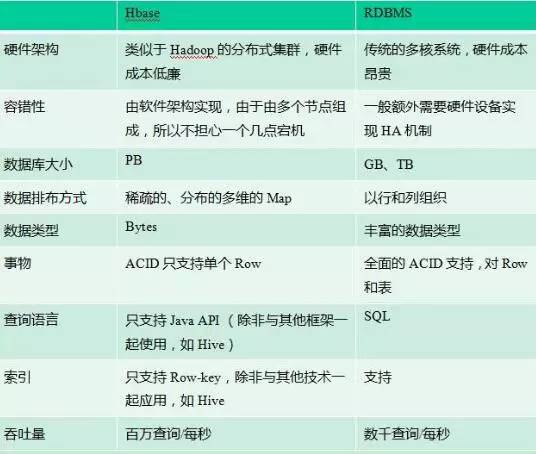
9.Hive和数据库(RDBMS)的区别
1、数据存储位置。Hive是建立在Hadoop之上的,所有的Hive的数据都是存储在HDFS中的。而数据库则可以将数据保存在块设备或本地文件系统中。
2、数据格式。Hive中没有定义专门的数据格式,由用户指定,需要指定三个属性:列分隔符,行分隔符,以及读取文件数据的方法。数据库中,存储引擎定义了自己的数据格式。所有数据都会按照一定的组织存储。
3、数据更新。Hive的内容是读多写少的,因此,不支持对数据的改写和删除,数据都在加载的时候中确定好的。数据库中的数据通常是需要经常进行修改。
4、执行延迟。Hive在查询数据的时候,需要扫描整个表(或分区),因此延迟较高,只有在处理大数据是才有优势。数据库在处理小数据是执行延迟较低。
5、索引。Hive没有,数据库有
6、执行。Hive是MapReduce,数据库是Executor
7、可扩展性。Hive高,数据库低
8、数据规模。Hive大,数据库小
hive代码简单例子:
创建一个名为”test“的table
create table students (name string,age int,city string,class string) row format delimited fields terminated by ‘,‘;
load data local inpath "/opt/students.txt" into table students;
create EXTERNAL table IF NOT EXISTS studentX (name string,age int,city string,class string) partitioned by (grade string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,‘;
alter table studentX add partition (grade=‘excellent‘) location ‘/testM/excellent/‘;
alter table studentX add partition (grade=‘good‘) location ‘/testM/good/‘;
alter table studentX add partition (grade=‘moderate‘) location ‘/testM/moderate/‘;
#加载数据
load data inpath "/testtry/studentsm.txt" into table studentX partition (grade=‘excellent‘);
load data inpath "/testtry/students.txt" into table studentX partition (grade=‘good‘);
show partitions studentX;
select * from studentX where grade=‘excellent‘;
表删除操作:drop table students;
创建一个名为”test“的table
create table students (name string,age int,city string,class string) row format delimited fields terminated by ‘,‘;
load data local inpath "/bin/students.txt" into table students;
###
练习:创建外部表,指定数据存放位置
create EXTERNAL table IF NOT EXISTS studentX (name string,age int,city string,class string) partitioned by (class string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,‘;
alter table test add partition (class=‘one‘) location ‘/testmore/one‘;
对表进行查询
Select * from students;
分区表操作
hive>create table students (name string,age int,city string,class string) partitioned by (class string) row format delimited fields terminated by ‘,‘;
hive>load data local inpath "students.txt" into table students partition (class=‘one‘);
hive>show partitions students;
hive>select * from students where grade=‘two‘;
查询操作
group by、 order by、 join 、 distribute by、 sort by、 clusrer by、 union all
hive常见操作

Hbase 的模块:
原子性(是指不会被线程调度机制打断的操作,这种操作一旦开始,就一直运行到结束,中间不会有任何contextswitch(切换到领一个线程)),一致性,隔离性,持久性
Region- Region用于存放表中的行数据
Region Server

Master

Zookeeper

HDFS
![]()
API
![]()
列式存储格式 Parquet
Parquet 是面向分析型业务的列式存储格式,由 Twitter 和 Cloudera 合作开发, 2015 年 5 月从 Apache 的孵化器里毕业成为 Apache 顶级项目,最新的版本是 1.8.0 。
列式存储和行式存储相比的优势 :
-
可以跳过不符合条件的数据,只读取需要的数据,降低 IO 数据量。
-
压缩编码可以降低磁盘存储空间。由于同一列的数据类型是一样的,可以使用更高效的压缩编码(例如 Run Length Encoding 和 DeltaEncoding )进一步节约存储空间。
-
只读取需要的列,支持向量运算,能够获取更好的扫描性能。
Hive操作
Hive

其他知识点
MLlib是spark的可以扩展的机器学习库,由以下部分组成:通用的学习算法和工具类,包括分类,回归,聚类,协同过滤,降维。
数据分析常见模式:
1、Iterative Algorithms,
2、Relational Queries,
3、MapReduce,
4、Stream Processing
Scala的好处:
1、面向对象和函数式编程理念加入到静态类型语言中的混合体
2、Scala的兼容性—-能够与Java库无缝的交互
3、Scala的简洁性—-高效,更不容易犯错
4、Scala的高级抽象
5、Scala是静态类型—-类型推断
6、Scala是可扩展的语言
ElasticSearch 基础代码:

基础问答题
Q:你理解的Hive和传统数据库有什么不同?各有什么试用场景。
A:1、数据存储位置。Hive是建立在Hadoop之上的,所有的Hive的数据都是存储在HDFS中的。而数据库则可以将数据保存在块设备或本地文件系统中。
2、数据格式。Hive中没有定义专门的数据格式,由用户指定,需要指定三个属性:列分隔符,行分隔符,以及读取文件数据的方法。数据库中,存储引擎定义了自己的数据格式。所有数据都会按照一定的组织存储。
3、数据更新。Hive的内容是读多写少的,因此,不支持对数据的改写和删除,数据都在加载的时候中确定好的。数据库中的数据通常是需要经常进行修改。
4、执行延迟。Hive在查询数据的时候,需要扫描整个表(或分区),因此延迟较高,只有在处理大数据是才有优势。数据库在处理小数据是执行延迟较低。
5、索引。Hive没有,数据库有
6、执行。Hive是MapReduce,数据库是Executor
7、可扩展性。Hive高,数据库低
8、数据规模。Hive大,数据库小
Q:Hive的实用场景
A:1、Data Ingestion (数据摄取)
2、Data Discovery(数据发现)
3、Data analytics(数据分析)
4、Data Visualization & Collaboration(数据可视化和协同开发)
Q:大数据分析与挖掘方法论被称为CRISP-DM方法是以数据为中心迭代循环进行的六步活动
A:它们分别是:商业理解、数据理解、数据准备、建立模型_、模型评估、结果部署_。
Q:数据分析挖掘方法大致包含 ( ):
A:1.分类 Classification
2.估计Estimation
3.预测Prediction
4. 关联规则Association Rules
5. 聚类Cluster
6. 描述与可视化Description and Visualization
Q:在数据分析与挖掘中对数据的访问性要求包括
交互性访问、批处理访问_、迭代计算、数据查询,HADOOP仅仅支持了其中批处理访问,而Spark则支持所有4种方式。
Q:Spark作为计算框架的优势是什么?
A:1、Spark的中间数据放到内存中,对于迭代运算效率更高
2、Spark比Hadoop更通用
3、Spark提供了统一的编程接口
4、容错性– 在分布式数据集计算时通过checkpoint来实现容错
5、可用性– Spark通过提供丰富的Scala, Java,Python API及交互式Shell来提高可用性
End.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号