Video那些事--H.264学习笔记
一、H.264编码标准的背景:
视频编码标准的发展已经有近40年的历史了,在视频编码标准的发展中,国际电信联盟(ITU)和运动图像专家组(MPEG)这两个组织具有举足轻重的地位。
最早是视频编码标准H.120和H.261就是ITU在上个世纪80年代所制定,然后MPEG制定了MPEG-1,MPEG-1是以VCD之名被大家所熟知的编码标准。
接下来两大组织联手成立了联合视频专家组(JVET),联合视频专家组定了MPEG-2中的视频部分,也被称为H.262。MPEG-2是以DVD之名被大家所了解,可以说MPEG-2是迄今为止最成功的视频标准之一。
后来ITU又制定了H.263标准,MPEG制定了MPEG-4,这两个标准都没有取得像MPEG-2这样的成功。
然后两大组织再次联手(JVET)制定了H.264-AVC标准。H.264-AVC制定于2003-2006,到现在已经近20年,却依然在行业应用占据了绝对的领先地位,是视频编码的首先标准。
一段30秒的简单视频的原始数据大概是1.24GByte,采用H.264 High Profile编码后数据量减少到6MByte左右。压缩比可达到1/200,在不降低太多主现质量的前提下,大大减少了视频的体积,节省了网络传输流量消耗,减少了传输时延。


二、H.264的三大标准:
- H.264 AVC 高级视频编码 (Advanced Video Coding),又称为MPEG-4第10部分(MPEG-4 Part 10,缩写为MPEG-4 AVC)是一种面向块,基于运动补偿的视频编码标准 。到2014年,它已经成为高精度视频录制、压缩和发布的最常用格式之一。第一版标准的最终草案于2003年5月完成,是由ITU-T视频编码专家组(VCEG)和ISO/IEC动态图像专家组(MPEG)联合组成的联合视频组(JVT,Joint Video Team)提出的高度压缩数字视频编解码器标准。
标准各主要部分有Access Unit delimiter(访问单元分割符),SEI(附加增强信息),primary coded picture(基本图像编码),Redundant Coded Picture(冗馀图像编码)。还有Instantaneous Decoding Refresh(IDR,即时解码刷新)、Hypothetical Reference Decoder(HRD,假想参考解码)、Hypothetical Stream Scheduler(HSS,假想码流调度器)。
- H.264 SVC 可适性视频编码(Scalable Video Coding, SVC)是传统H.264/MPEG-4 AVC编码的延伸,可提升更大的编码弹性,并具有时间可适性(Temporal Scalability)、空间可适性(Spatial Scalability)及信噪比可适性(SNR Scalability)三大特性,使视频传输更能适应在异质的网络带宽。
实际应用中,存在不同的网络和不同的用户终端,各种情况下对视频质量的需求不一样,利用可分级视频编码技术实现一次性编码产生具有不同帧率、分辨率的视频压缩码流,然后根据不同网络带宽、不同的显示屏幕和终端解码能力选择需要传输的视频信息量,以此实现视频质量的自适应调整。为了能够实现从单一码流中解码得到不同帧率(时间可分级)、分辨率(空间可分级)和图像质量(SNR可分级)的视频数据的编码技术,H.264 SVC以H.264 AVC视频编解码器标准为基础,在编码产生的编码视频时间上(帧率)、空间上(分辨率)可扩展,并且是在视频质量方面可扩展的,可产生不同帧速率、分辨率或质量等级的解码视频。H264可分级视频编码采用分层编码方式实现,由一个基本层(Base Layer)和多个增强层(Enhancement Layer)组成,增强层依赖基本层的数据来解码。其中,基本层(base layer)编码了基本的视频信息,实现了最低图像分辨率、帧率,并且基本层的编码是兼容H264/AVC编码标准的,能够采用H264/AVC解码器进行解码。
在实时通迅中,SVC的落地有一定的困难,尤其server端的逻辑会变的更复杂。一般采用Simulcast+AVC(SAVC)的方式来实现可适性编码,使业务更简单化。
- H.264 MVC 多视角视频编码(Multiview video coding)
是在H.264标准当中新增的内容,其历史渊源和概况可以参照《Overview of Multi-view Video Coding》这篇论文。在双目3D视频中,通常需要提供left/right view两个视点的图像,这两个视点的图像是有相关性的,同样,对于多view视图之间也是有一定相关性的,因此很自然的想法就是要利用view之间的相关性来提高压缩效率,这就是MVC的目的。
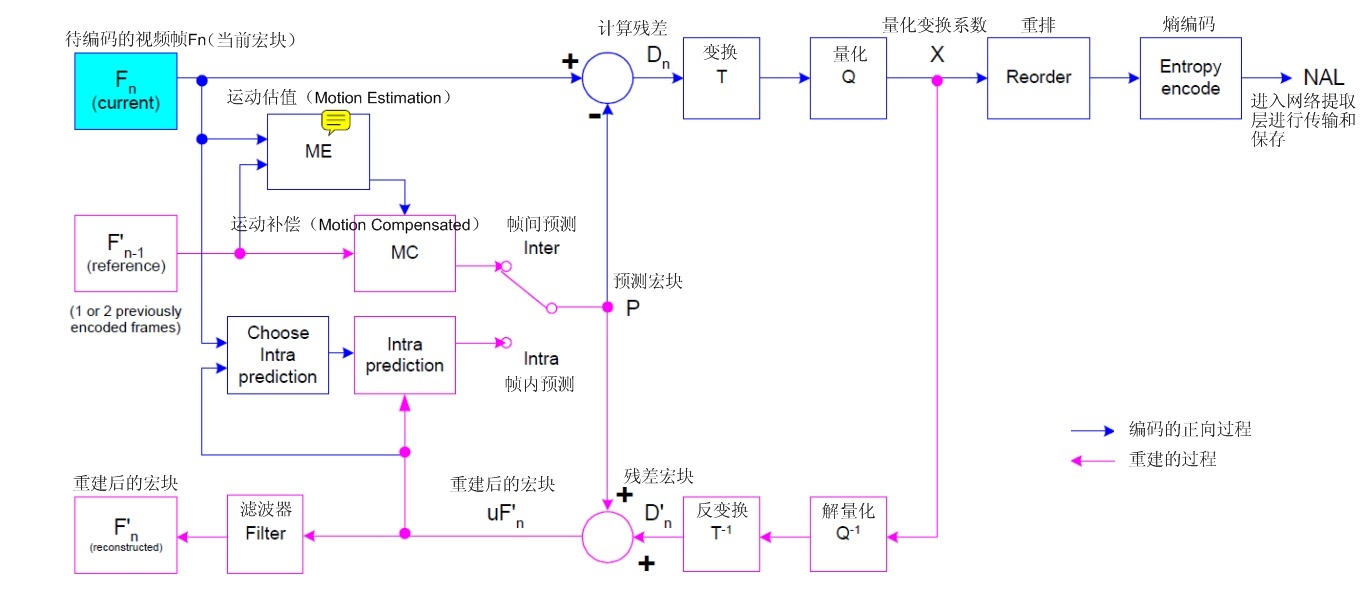
三、H264算法流程
- H.264 编解码流程主要分为 5 部分:
- 帧间和帧内预测(Estimation)
- 变换(Transform)和反变换
- 量化(Quantization)和反量化
- 熵编码(Entropy Coding)
- 环路滤波(Loop Filter)主要用于滤除方块效应

四. H.264 AVC里的 I、B、P帧
在H.264 AVC编码的过程中,部分视频帧序列压缩成为I帧,部分压缩成P帧,还有部分压缩成B帧。
- I帧又称为内部画面 (Intra picture),I 帧通常是每个 GOP(Group of Pictures)的第一个帧,经过适度地压缩,做为随机访问的参考点,可以当成图像。
I帧法是帧内压缩法,也称为“关键帧”压缩法。 I帧法是基于离散余弦变换DCT(Discrete Cosine Transform)的压缩技术,这种算法与JPEG压缩算法类似。采用I帧压缩可达到1/6的压缩比而无明显的压缩痕迹。
I帧特点:
1.它是一个全帧压缩编码帧。它将全帧图像信息进行JPEG压缩编码及传输;
2.解码时仅用I帧的数据就可重构完整图像;
3.I帧描述了图像背景和运动主体的详情;
4.I帧不需要参考其他画面而生成;
5.I帧是P帧和B帧的参考帧(其质量直接影响到同组中以后各帧的质量);
6.I帧是帧组GOP的基础帧(第一帧),在一组中只有一个I帧;
7.I帧不需要考虑运动矢量; 8.I帧所占数据的信息量比较大。
- P帧:前向预测编码帧。 P帧的预测与重构:P帧是以I帧为参考帧,在I帧中找出P帧“某点”的预测值和运动矢量,取预测差值和运动矢量一起传送。
在接收端根据运动矢量从I帧中找出P帧“某点”的预测值并与差值相加以得到P帧“某点”样值,从而可得到完整的P帧。
P帧特点:
1.P帧是I帧后面相隔1~2帧的编码帧;
2.P帧采用运动补偿的方法传送它与前面的I或P帧的差值及运动矢量(预测误差);
3.解码时必须将I帧中的预测值与预测误差求和后才能重构完整的P帧图像;
4.P帧属于前向预测的帧间编码。它只参考前面最靠近它的I帧或P帧;
5.P帧可以是其后面P帧的参考帧,也可以是其前后的B帧的参考帧;
6.由于P帧是参考帧,它可能造成解码错误的扩散 (error propagation) ; 7.由于是差值传送,P帧的压缩比较高。
- B帧:双向预测内插编码帧。 B帧的预测与重构 B帧以前面的I或P帧和后面的P帧为参考帧,“找出”B帧“某点”的预测值和两个运动矢量,并取预测差值和运动矢量传送。
接收端根据运动矢量在两个参考帧中“找出(算出)”预测值并与差值求和,得到B帧“某点”样值,从而可得到完整的B帧。
B帧特点:
1.B帧是由前面的I或P帧和后面的P帧来进行预测的;
2.B帧传送的是它与前面的I或P帧和后面的P帧之间的预测误差及运动矢量;
3.B帧是双向预测编码帧;
4.B帧压缩比最高,因为它只反映丙参考帧间运动主体的变化情况,预测比较准确;
5.B帧不是参考帧,不会造成解码错误的扩散
因为B帧会增加传输的时延,实时通讯一般不用B帧,Openh264里也没有实现B帧。
五. IDR帧 (Instantaneous Decoding Refresh)
IDR 一个序列的第一个图像叫做 IDR 图像(立即刷新图像),IDR 图像都是 I 帧图像。 I和IDR帧都使用帧内预测。I帧不用参考任何帧,但是之后的P帧和B帧是有可能参考这个I帧之前的帧的。
IDR会导致DPB(DecodedPictureBuffer 参考帧列表)清空, 在IDR帧之后的所有帧都不能引用任何IDR帧之前的帧的内容。 其核心作用是,是为了解码的重同步,当解码器解码到 IDR 图像时,立即将参考帧队列清空,将已解码的数据全部输出或抛弃,重新查找参数集,开始一个新的序列。这样,如果前一个序列出现重大错误,在这里可以获得重新同步的机会。IDR图像之后的图像永远不会使用IDR之前的图像的数据来解码。
六. OpenH264 SVC里的 T0, T1,T2,T3帧
在码流中,T0帧 61开头, T1帧 01开头,61优先级最高。

七、H.264的码率控制模式
- CBR(Constant Bit Rate)是固定码率,在视频会议中我们主要使用CBR模式
CBR需要设置一个固定码率。CBR会在压缩输出的时候就把会每一秒的画面都计算为固定的大小,运算量小,编码时间短而且解码算法也简单,缺点是在画面剧烈运动的时候会由于码率不够而丢失部分画面信息。从视觉上来看就是画面波纹严重,图像不清晰,VBR的出现就是为了解决这个问题。
- VBR(Variable Bit Rate)是可变码率
采用VBR压缩视频时,Encoder会先逐帧扫描一下,把运动量大的帧码率调高,运动量小或是静止的画面码率调低,保证平均后的码率等于ARG值。
此外,在MPEG4级压缩的应用还出现了Bitrate VBR和Quality VBR即码率控制与质量控制,前者是单纯的调整码率达到平均值,后者复杂一些是根据图像质量而定所以并不能先给出一个平均值来,只是保证每一帧画面的质量达到要求,至于这一帧画面为了保证质量会达到什么样的码率值并不是提前知道的,当然这种运算就更复杂了。还有更高级的保持质量的压缩方式Two-pass即Two-pass Encoding 的先对影片作一次分析,即First-pass。此时整个影片档案会被先作扫描,定义影片中的影格是动态或是静态,所以再决定相应的每一帧画面的码率来进行压缩。
- X264的码率控制模式:
X264 中对于码率控制方法有三种:X264_RC_CQP、X264_RC_CRF、X264_RC_ABR,默认情况是选择 CRF 方法。这几个模式都属于可变码率,即VBR(Variable Bitrate);
-
CQP(Constant QP),恒定QP(Quantization Parameter),追求量化失真的恒定,瞬时码率会随场景 复杂度而波动,该模式基本被淘汰(被 CRF 取代),只有用”-pq 0”来进行无损编码还有价值。
-
CRF(Constant Rate Factor),恒定质量因子,与恒定 QP 类似,但追求主观感知到的质量恒定,瞬时码率也 会随场景复杂度波动。对于快速运动或细节丰富的场景会适当增大量化失真(因为人眼不易注意到),反之 对于静止或平坦区域则减少量化失真。
-
ABR(Average Bitrate),平均码率,追求整个文件的码率平均达到指定值(对于流媒体有何特殊之处?)。 瞬时码率也会随着场景复杂度波动,但最终要受平均值的约束。
X264并没有直接提供 CBR 这种模式,但可以通过在 VBR 模式的基础上做进一步限制来达到恒定码率的目标。 CRF 和 ABR 模式都能通过--vbv-maxrate --vbv-bufsize来限制码率波动。
八. QP(quantization parameter)量化参数
量化参数qp_max过小,导致固定码率控制失效。 Webex 360p QP取值范围为 22~30。
QP值对应量化步长的序号,为了避免在较高量化步长时的出现颜色量化人工效应, H.264 规定,亮度 QP 的最大值是 51,而色度 QP 的最大值是 39。
值越小,量化步长越小,量化的精度就越高,意味着同样画质的情况下,产生的数据量可能会更大。QP值每增加6,量化步长就增加一倍。其对应关系如下表1。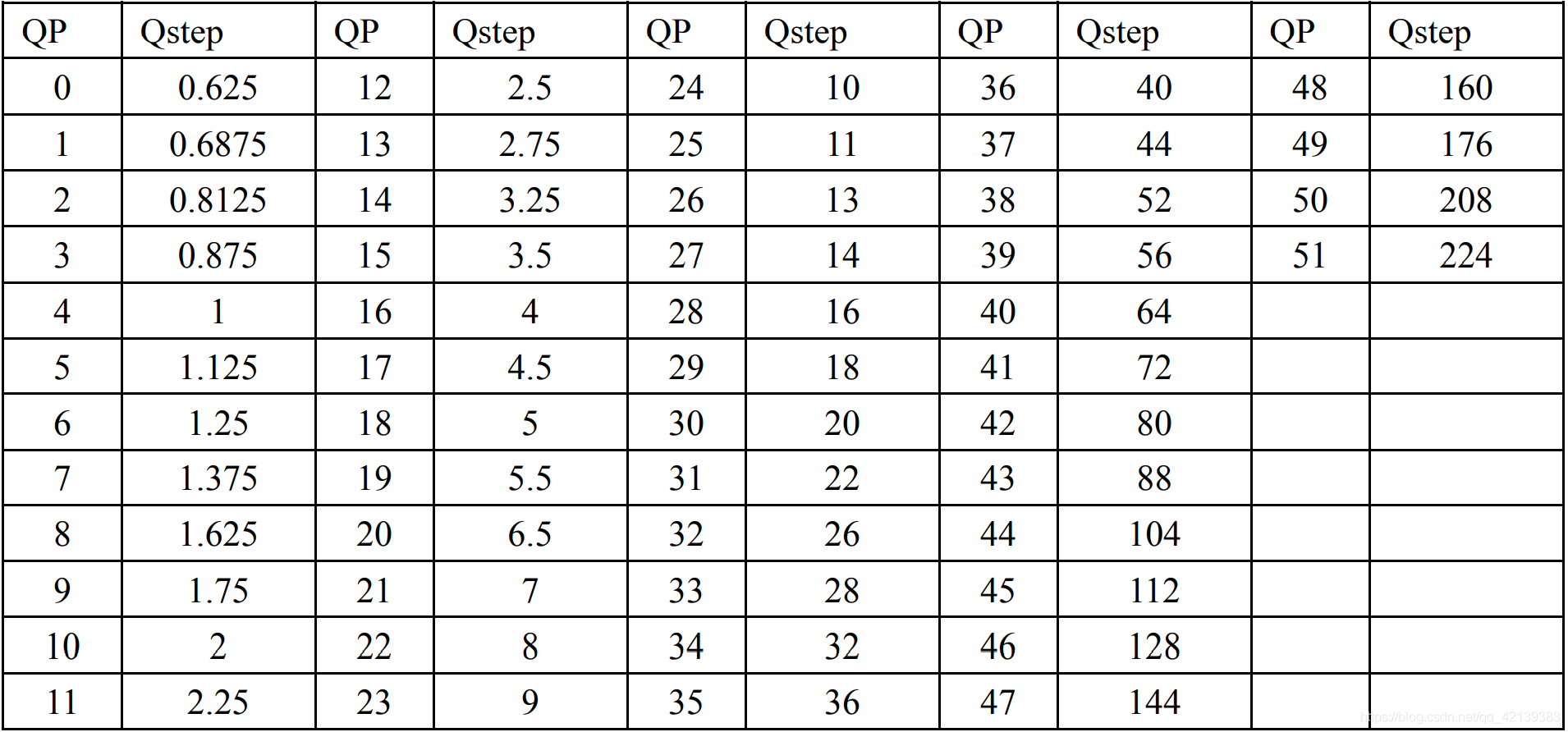
九、H.264码流的RTP分包格式 (参考RFC-3984)
- packetization-mode: SDP中的packetization-mode字段表示支持的封包模式.
packetization-mode = 0 一个NAL打成一个RTP包
packetization-mode = 1 多个NAL组合成一个RTP包 (SCR中,Cisco Teams都是用这个的)
packetization-mode = 2 一个NAL包可以分成多个RTP包
- H.264 RTP Payload格式分单NAL包和聚合包,参考:https://blog.csdn.net/yongkai0214/article/details/88872076
- Single NAL Unit Packet

- Aggregation packet

H.264 720p will use 4 slices which means 4 NALs per frame.
Effectively, fragmentation. A frame (or more generally, a Temporal Unit) is made up of a number of different OBUs (similar to NALUs).
These can be split across packets, including in the middle of an OBU, but not across frame boundaries.
十. 码流分析的方法和工具
- H.264编码格式 可参考https://www.cnblogs.com/jiayayao/p/7086711.html
- Wireshark H.264 插件,可从RTP包中提出H.264码流。插件地址 https://github.com/volvet/h264extractor
- 分析码流的工具:收费的推荐 Elecard Stream Eye,好用但价格比较贵。免费的有VLC和FFplay,可以播放码流。
- SPS PPS:SPS/PPS里包含的信息,可以参考 https://www.cnblogs.com/wainiwann/p/7477794.html
- 码流的解析 参考https://www.cnblogs.com/zoneofmine/p/10784276.html
SODB(String of Data Bits,数据比特串):最原始,未经过处理的编码数据
RBSP(Raw Byte Sequence Payload,原始字节序列载荷):在SODB的后面填加了结尾bit(RBSP trailing bits 一个bit ‘1’)若干bit ‘0’,以便字节对齐。
EBSP(Encapsulated Byte Sequence Payload, 扩展字节序列载荷):
NALU的起始码为0x000001或0x00000001(起始码包括两种:3 字节(0x000001) 和 4 字节(0x00000001),在 SPS、PPS 和 Access Unit 的第一个 NALU 使用 4 字节起始码,其余情况均使用 3 字节起始码。)
同时H264规定,当检测到0x000000时,也可以表示当前NALU的结束。那这样就会产生一个问题,就是如果在NALU的内部,出现了0x000001或0x000000时该怎么办?
在RBSP基础上填加了仿校验字节(0x03)它的原因是:在NALU加到Annexb上时,需要填加每组NALU之前的开始码StartCodePrefix,如果该NALU对应的slice为一帧的开始则用4位字节表示,0x00000001,否则用3位字节表示0x000001.为了使NALU主体中不包括与开始码相冲突的,在编码时,每遇到两个字节连续为0,就插入一个字节的0x03。解码时将0x03去掉。也称为脱壳操作。

十一、展望
H.264是目前实时通迅中使用的首选的编码方案,绝大多数硬件编解码芯片都支持H.264 High Profile编解码。在未来相当长的一段时间内,视频会议仍然会主要使用H.264视频压缩技术,所以我们有必要学好H.264标准,最大程度的去发挥它的作用。
与此同时,我们也要时刻关注着AV1的发展。以Google为代表的开放媒体联盟(AOM),AOM制定的AV1标准,展示出超过H.265-HEVC的编码性能,拥有丰富的编码工具支持,可以极大地提高视频的压缩比,节省大量带宽。同时,AV1 作为开放媒体联盟 AOM 制定的第一代标准,除了有非常好的生态支持,还提供了免费的专利政策,相比 H.265 / H.266 等知识产权政策不明确的视频标准,有巨大的优势。清晰明确的专利政策也是 AV1 在产业界被推崇的一大优势。
在1080p、4k分辨率的视频编码上,AV1比H.264的Rate-distortation性能有明显的提升,但代价是其算法复杂度也有数倍的增涨。目前Cisco Webex已经将AV1用在桌面分享上,随着AV1算法的不断优化和硬件算力的不断提升,AV1会得到更广泛的应用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号