RNN循环神经网络
1. 为什么提出RNN
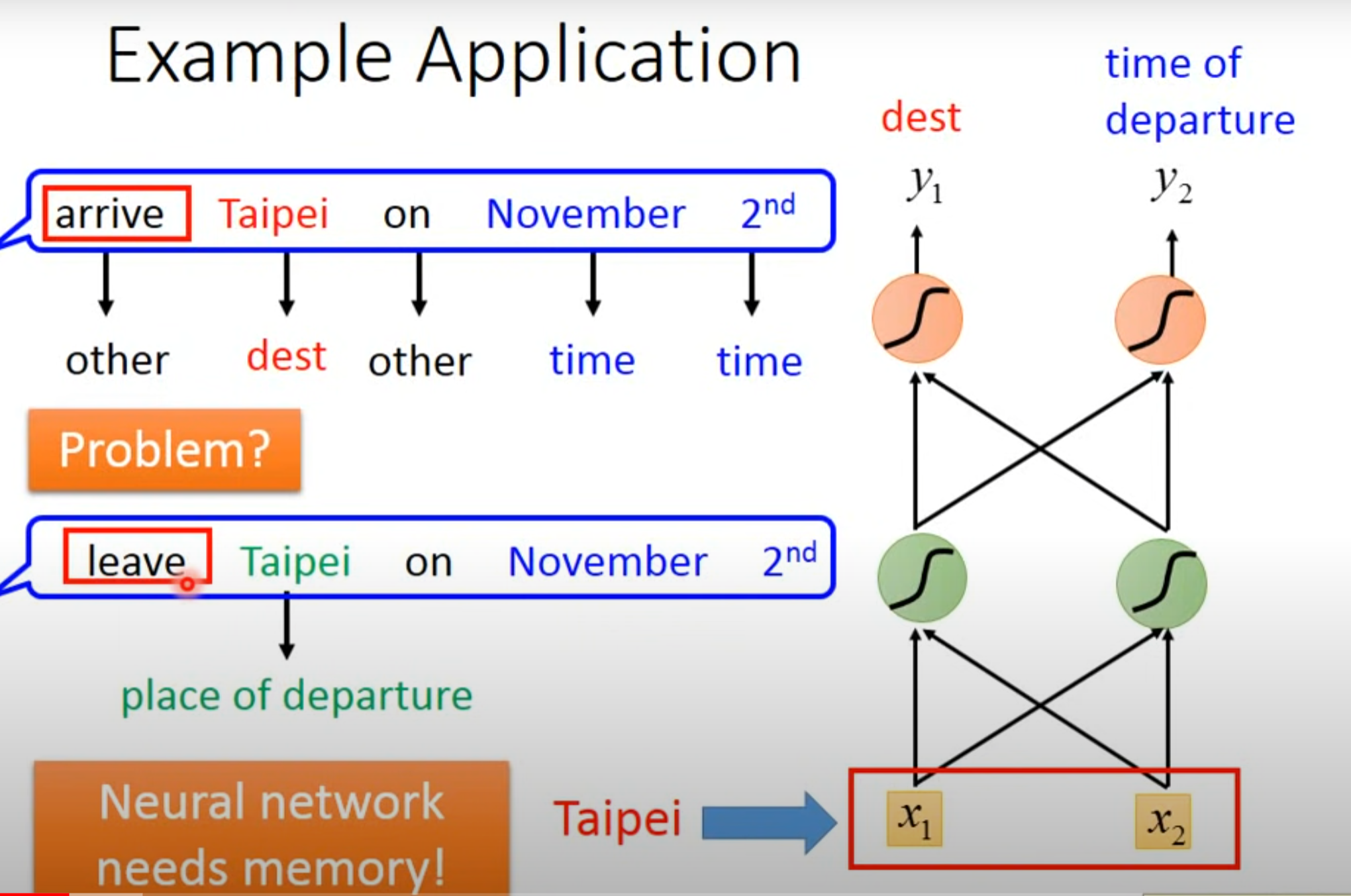
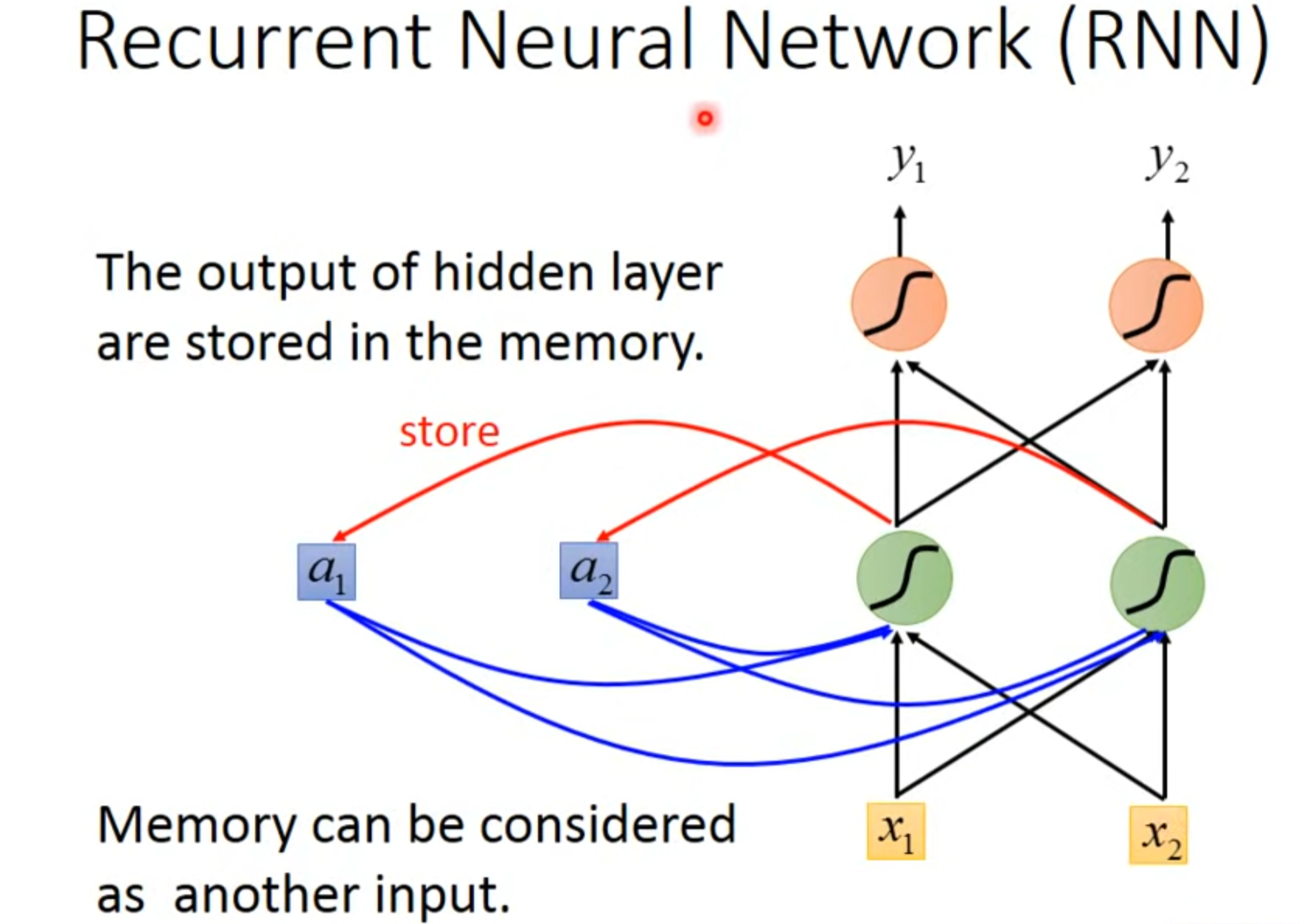
- 要联系上下文对于同样的输入(Taipei)要输出不同的,要求神经网络需要记忆,这种有记忆的神经网络就叫做RNN,循环神经网络(Recurrent Neural Network)
2. RNN常见算法分类
- 完全递归网络(Fully recurrent network)
- Hopfield网络(Hopfield network)
- Elman networks and Jordan networks
- 回声状态网络(Echo state network)
- 长短记忆网络(Long short term memory network)
- 双向网络(Bi-directional RNN)
- 持续型网络(Continuous-time RNN)
- 分层RNN(Hierarchical RNN)
- 复发性多层感知器(Recurrent multilayer perceptron)
- 二阶递归神经网络(Second Order Recurrent)
- 波拉克的连续的级联网络
3. RNN实现
3.1 例子
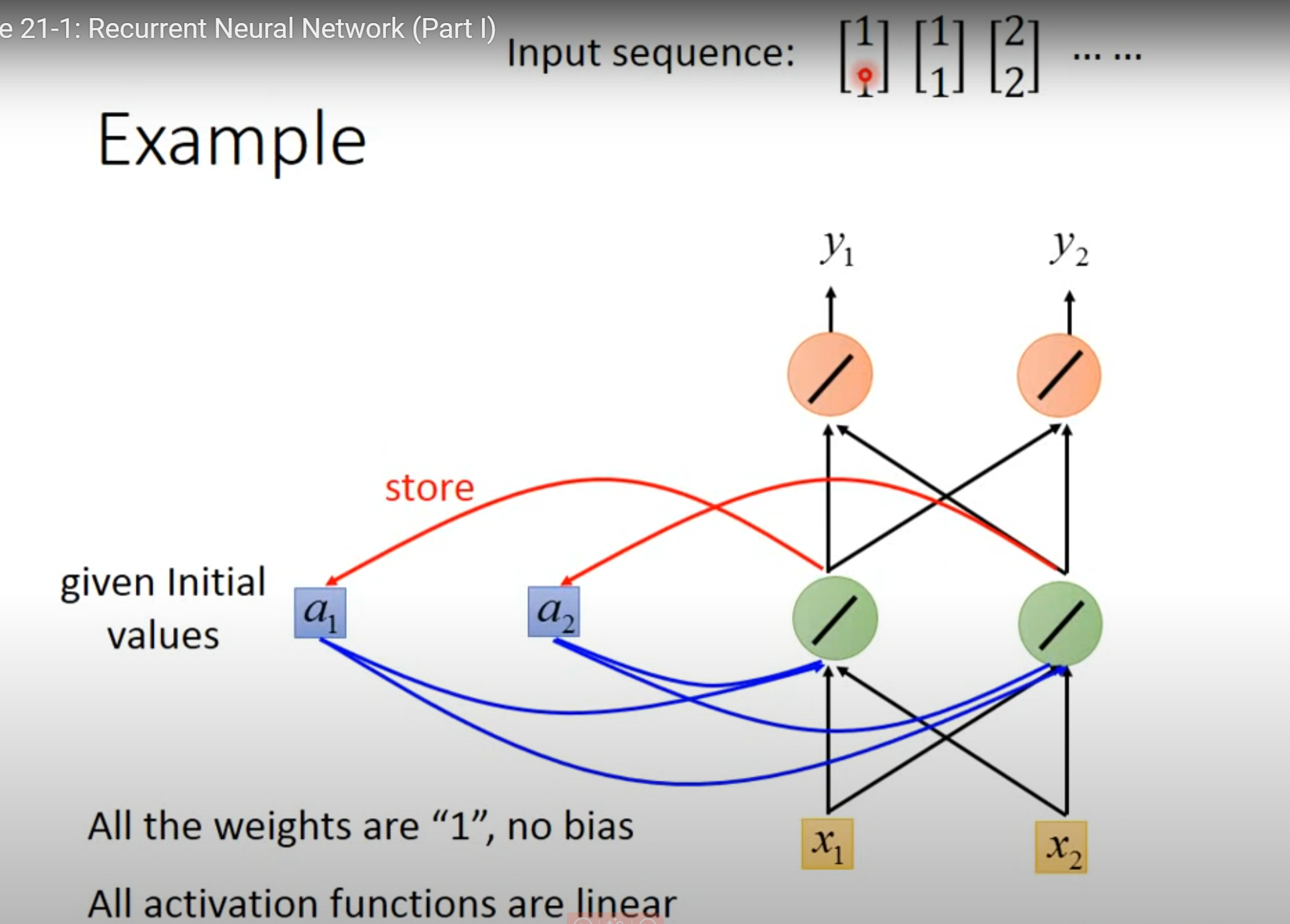
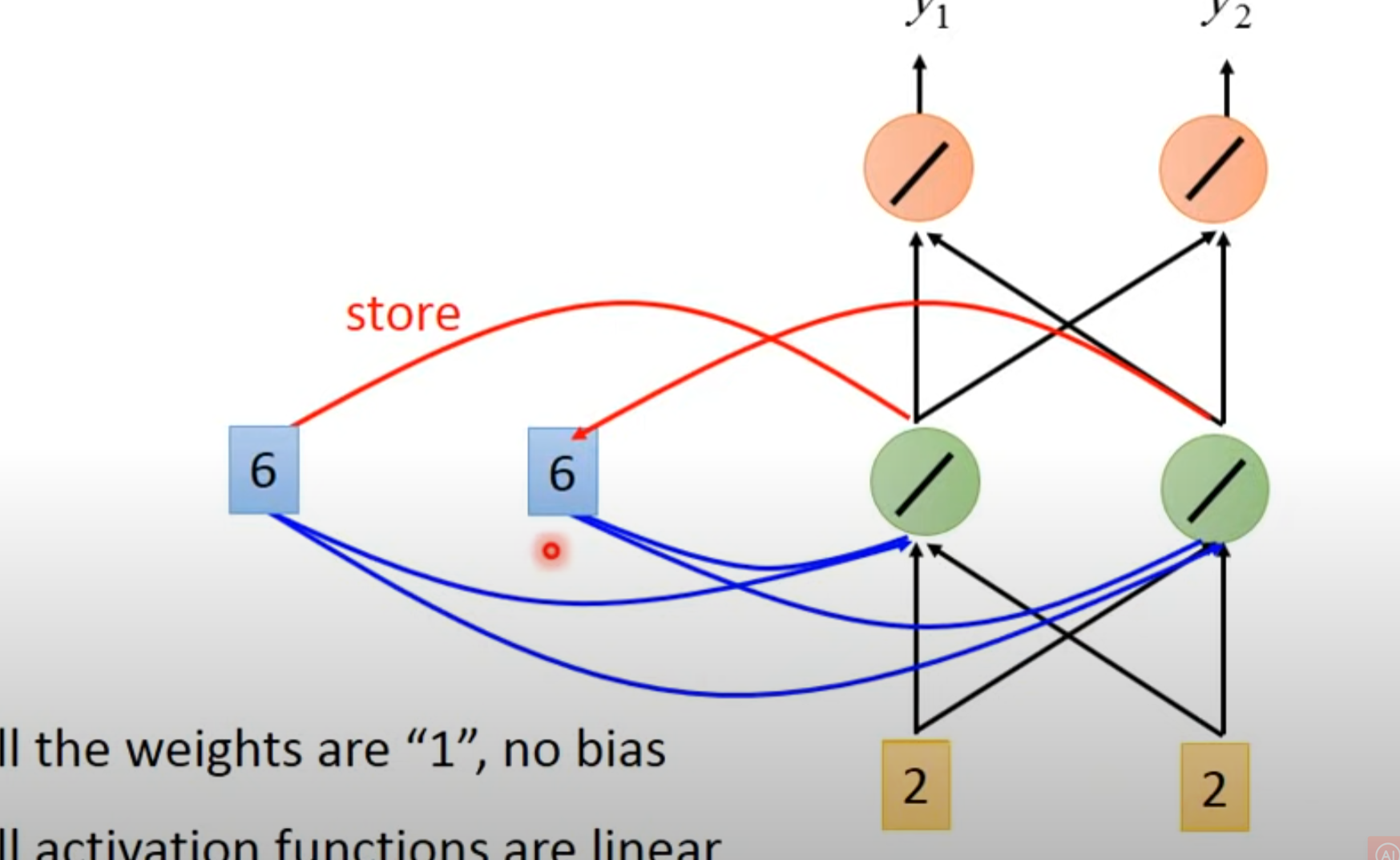
- 假设没有bias,weight均为1
-
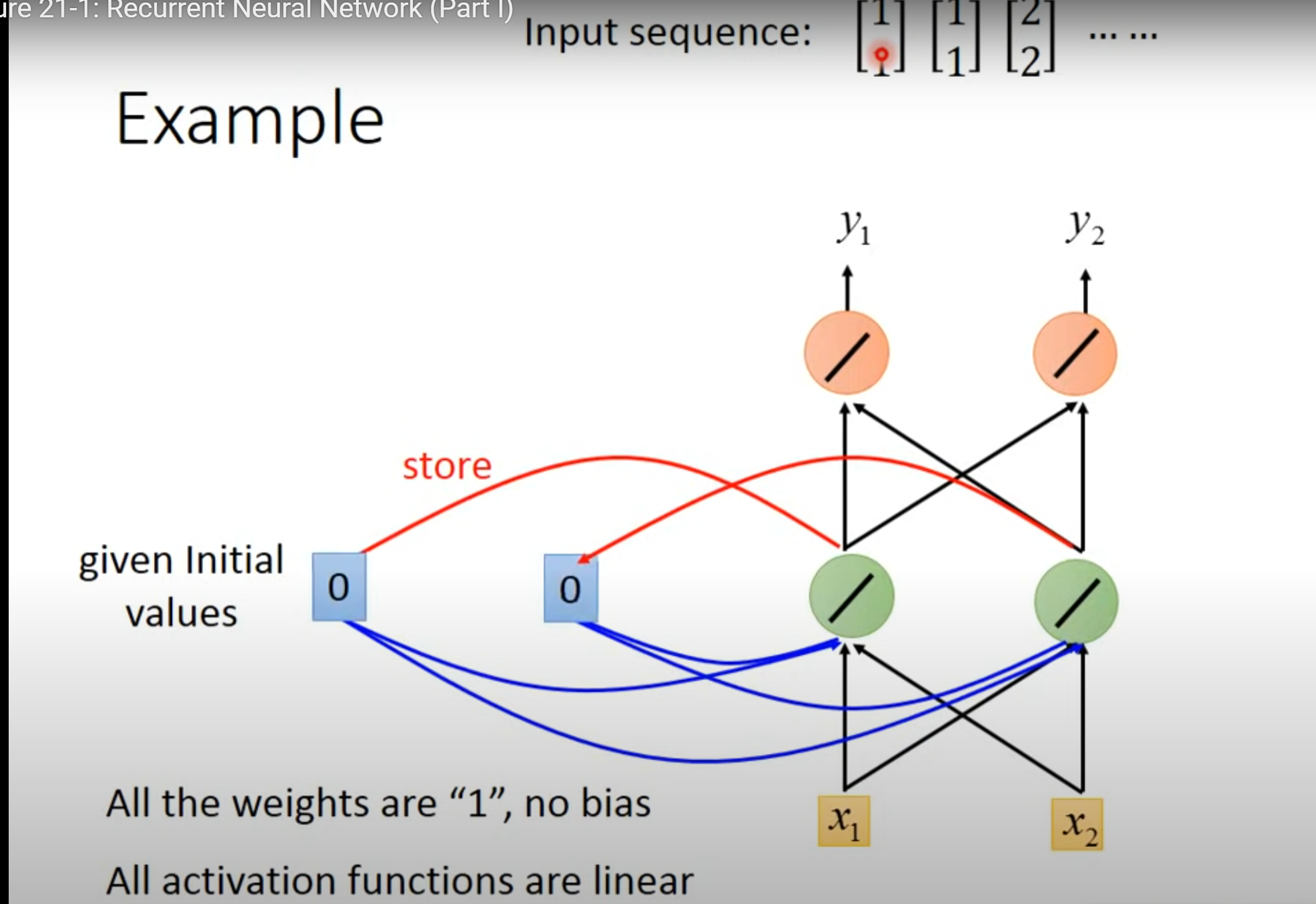
赋予memory初始值
-
输入第一个向量[1 1]并更新memory
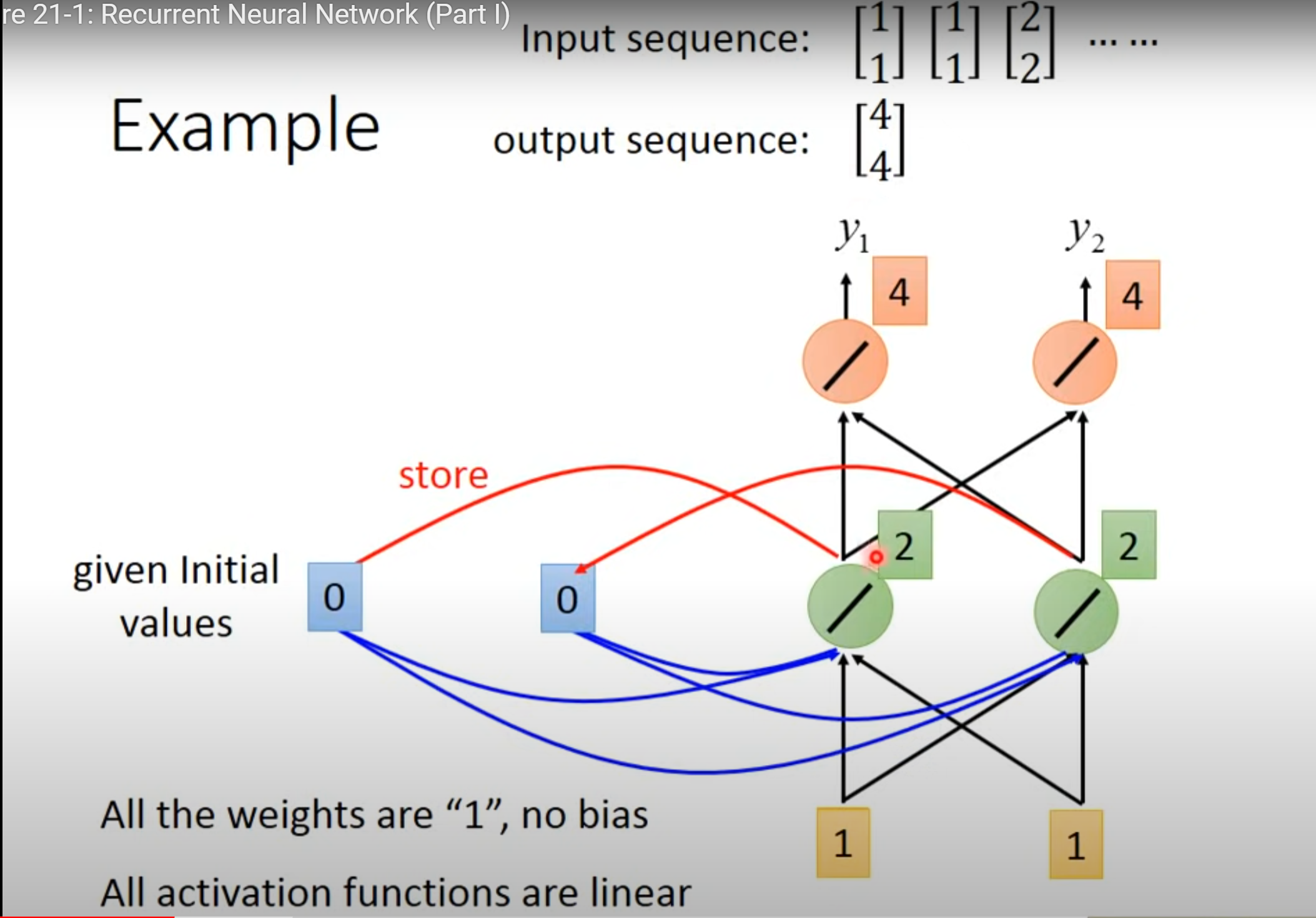
- 将绿色里面的值存到memory里面
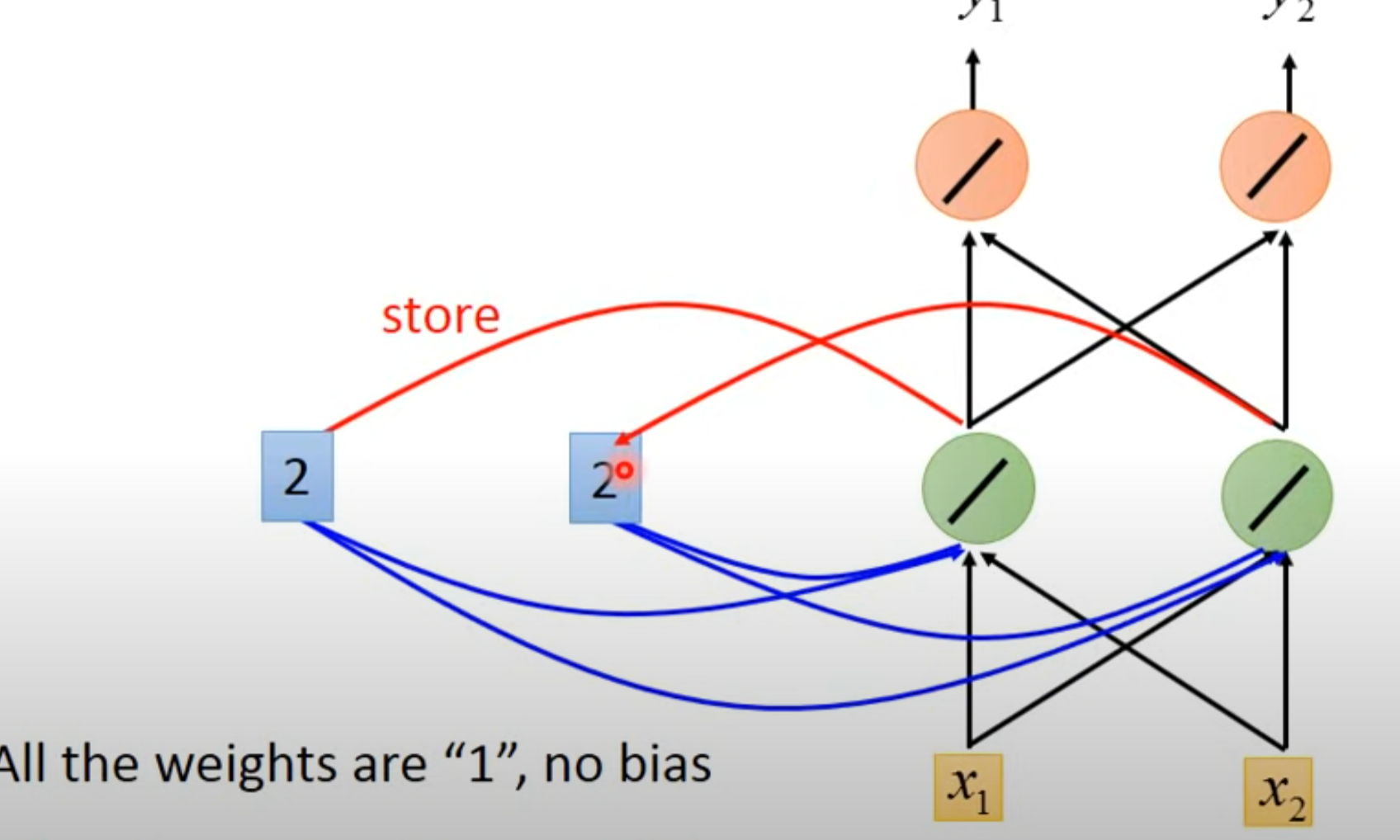
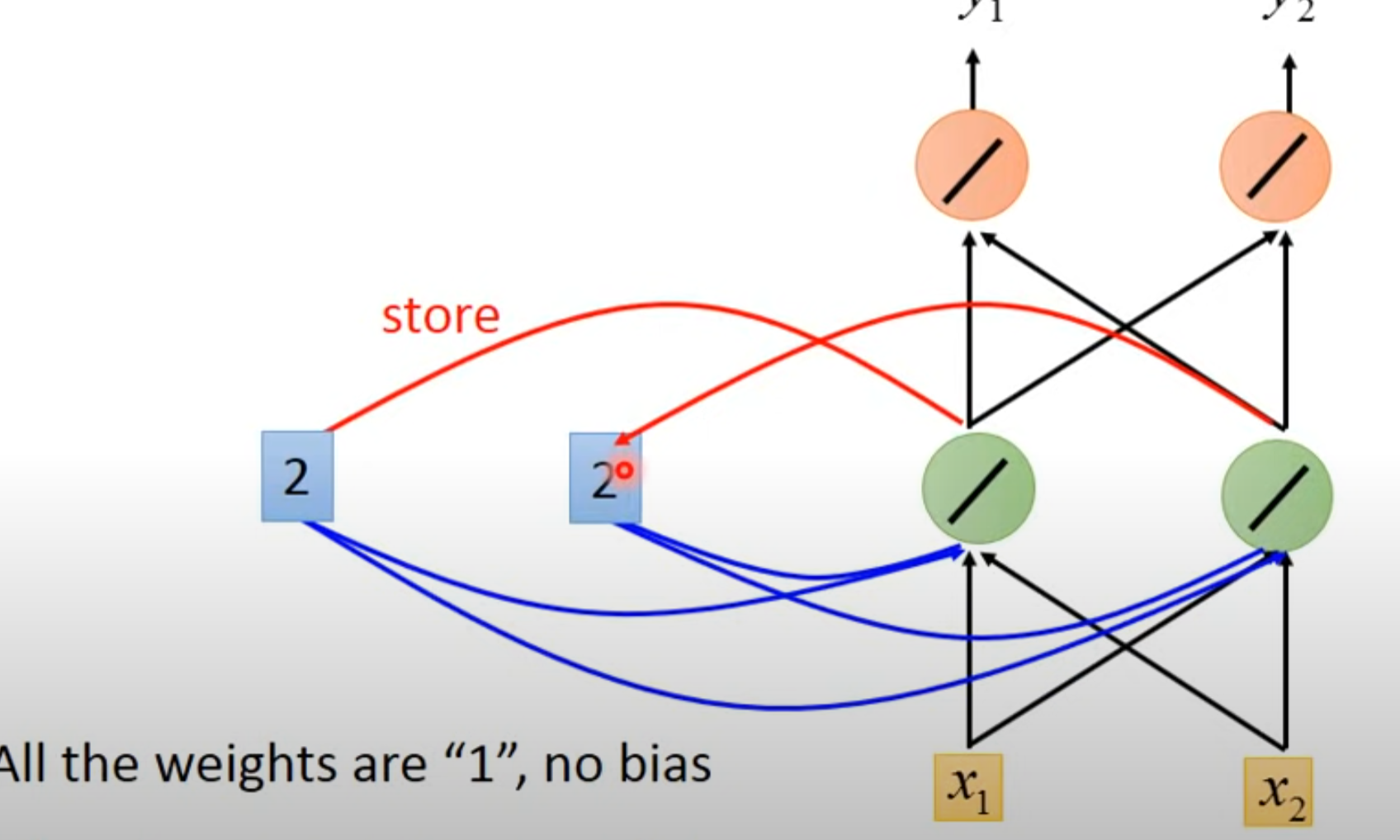
- 输入第二个向量[1 1]并更新memory
- 1 * 1 + 1 * 1 + 2 + 2 = 6
- 输出 6 * 1 + 6 * 1 = 12
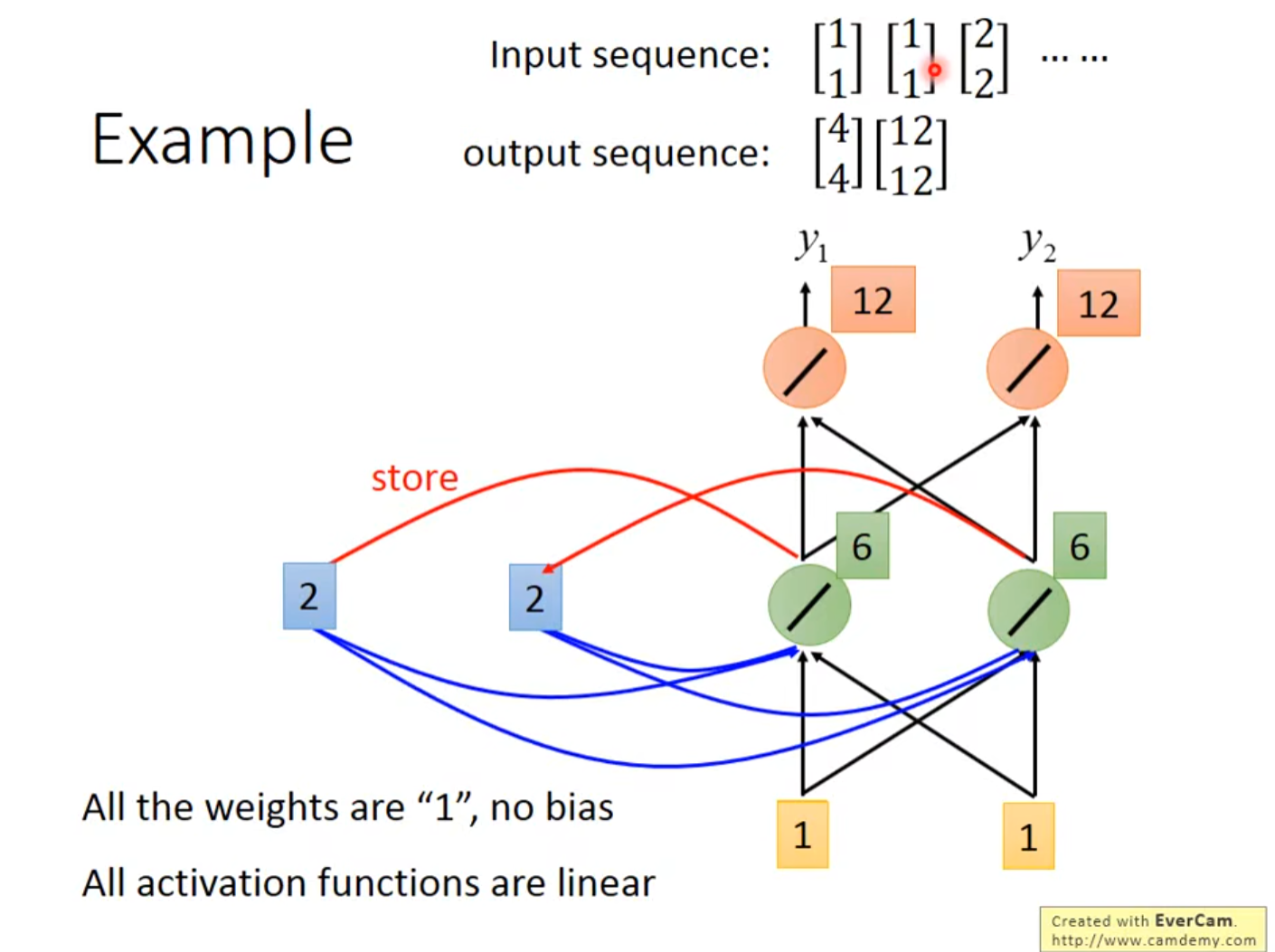
- 将绿色数值6写回到memory里面
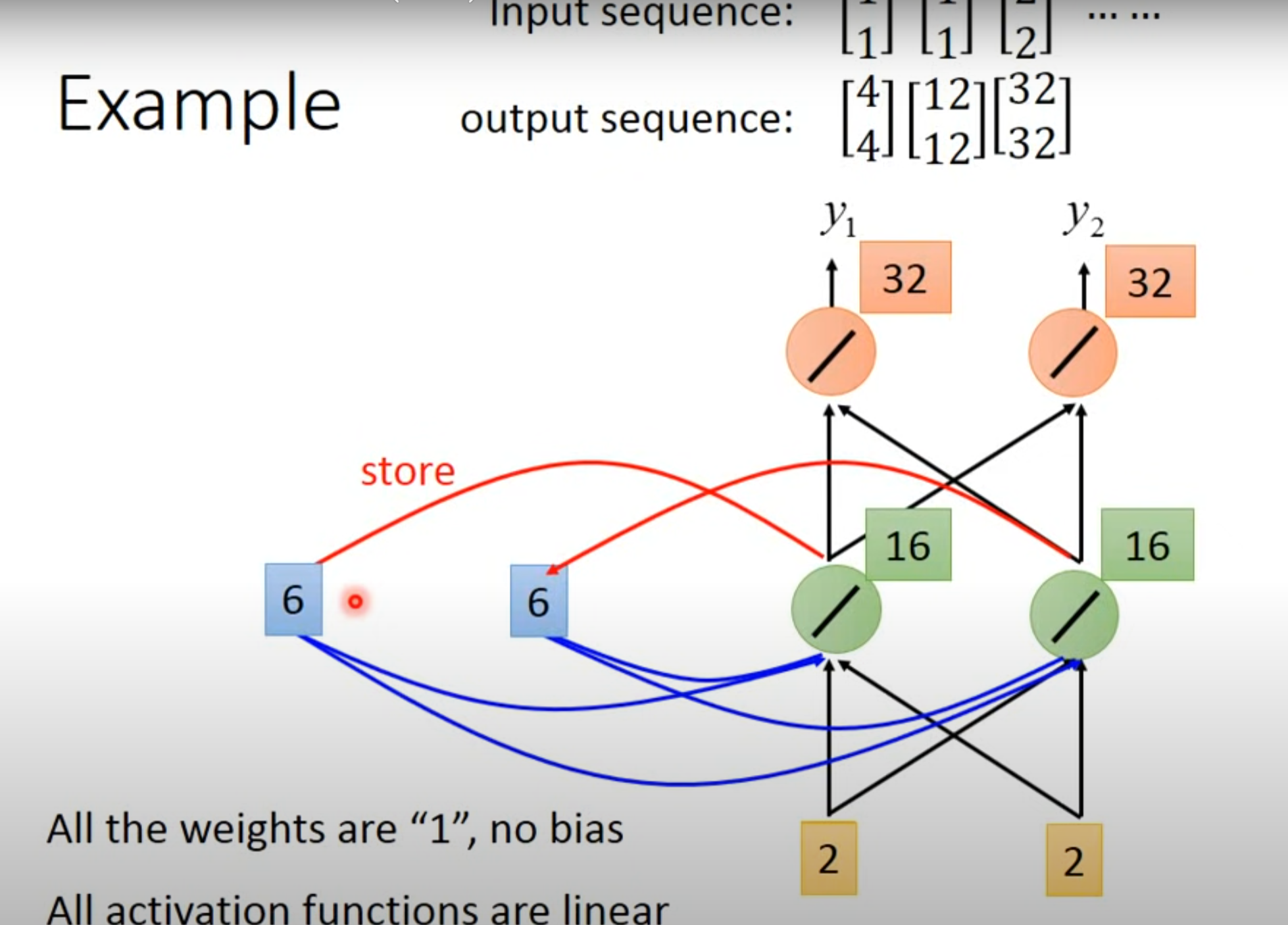
- 输入第三个向量……
- 可以看到,memory会导致输出不同,所以改变顺序会导致输出不同
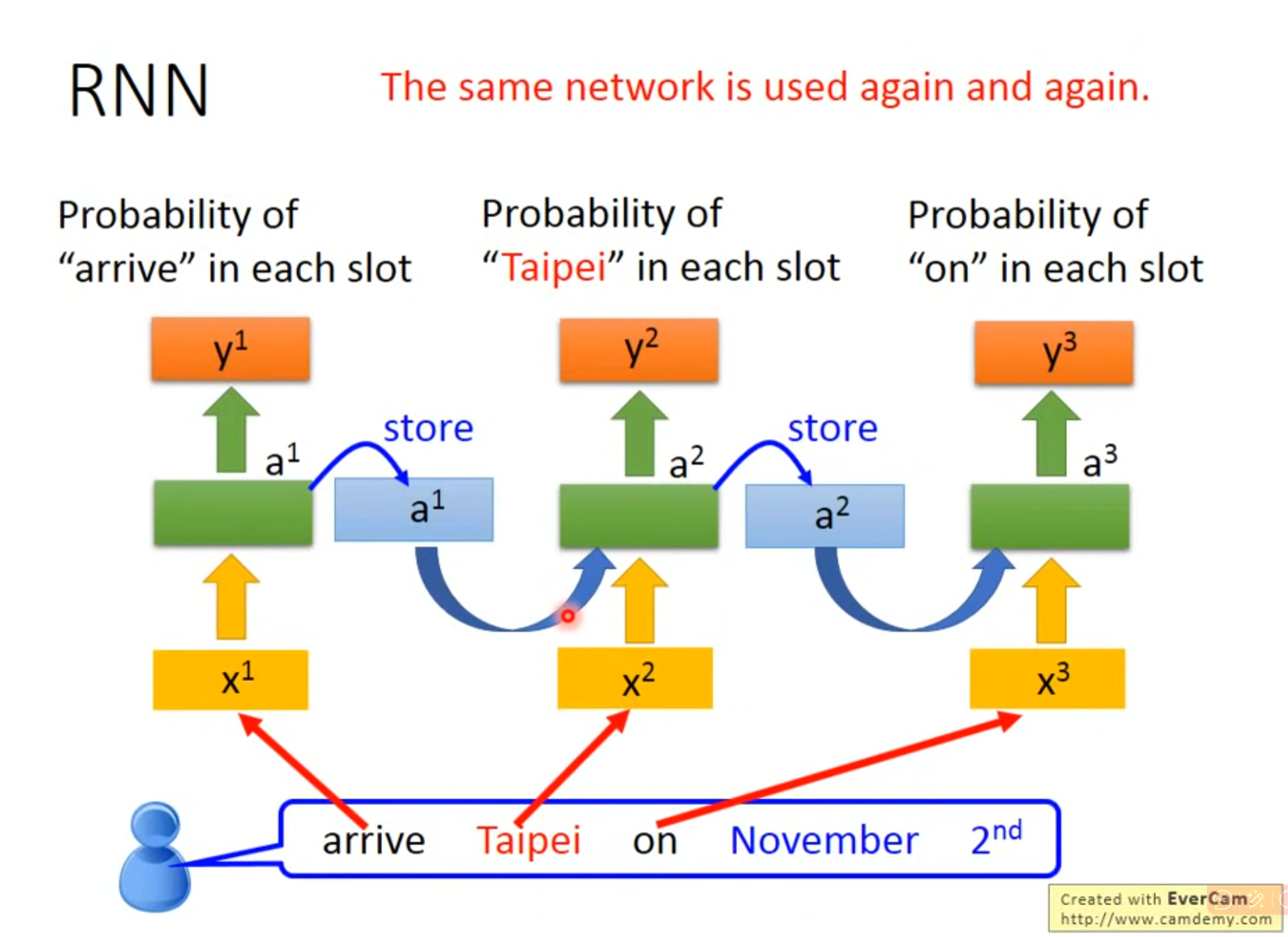
3.2 实现
- 并不是使用了三个network,而是指同一个network在不同的时间点使用了三次
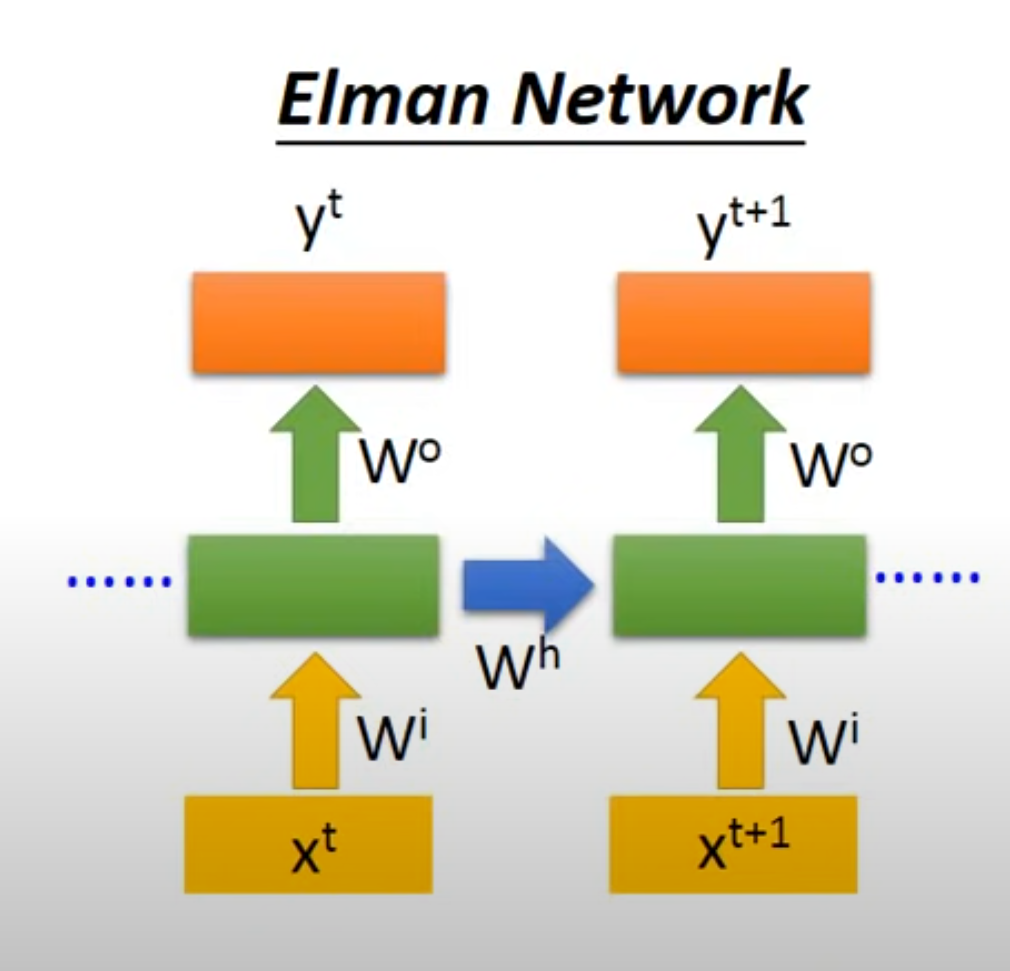
4. Elman 和 Jordan
4.1 Elman Network
- 存储hidden layer层的值
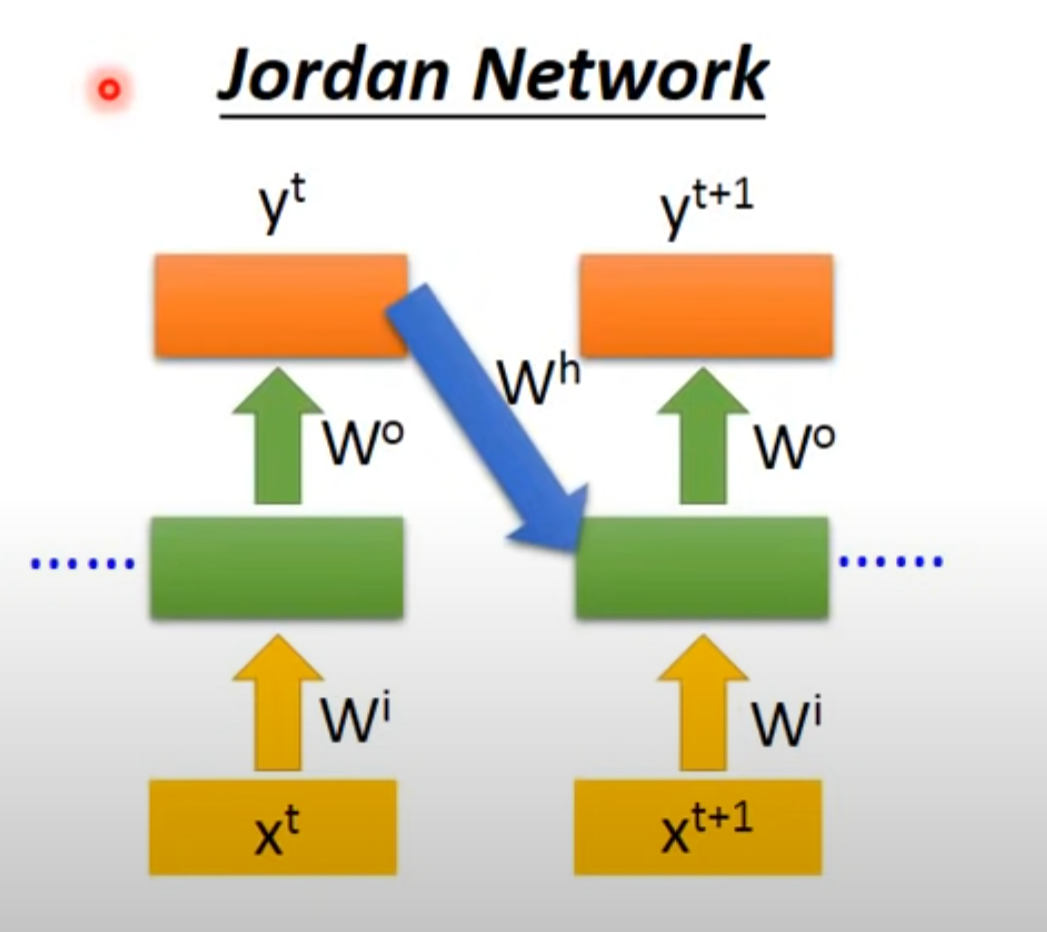
4.2 Jordan Network
- 存储整个network的output的值
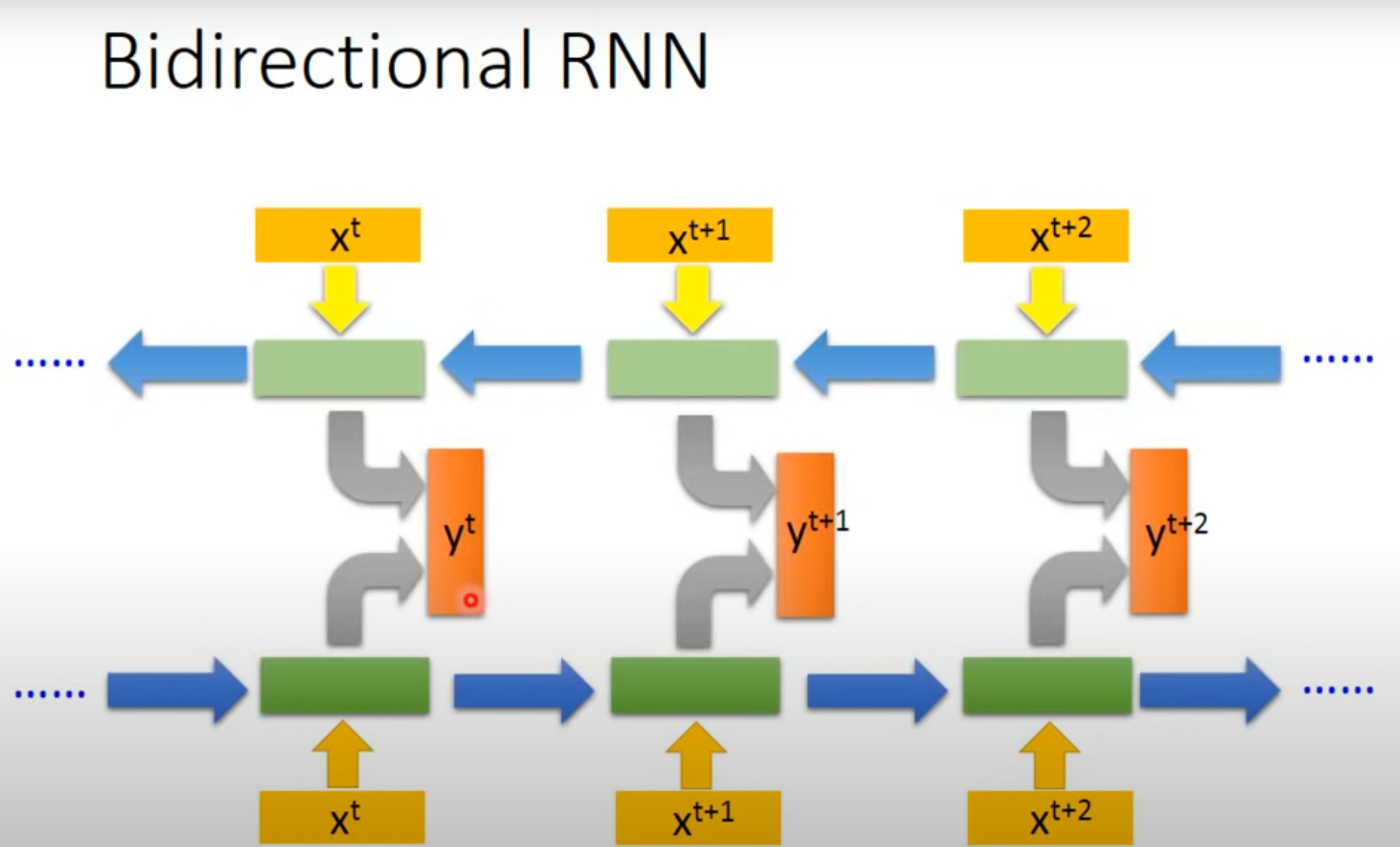
5. 双向(Bidirectional)RNN
- 只是单向RNN的话,只是看了部分而不是整体,故可以使用双向
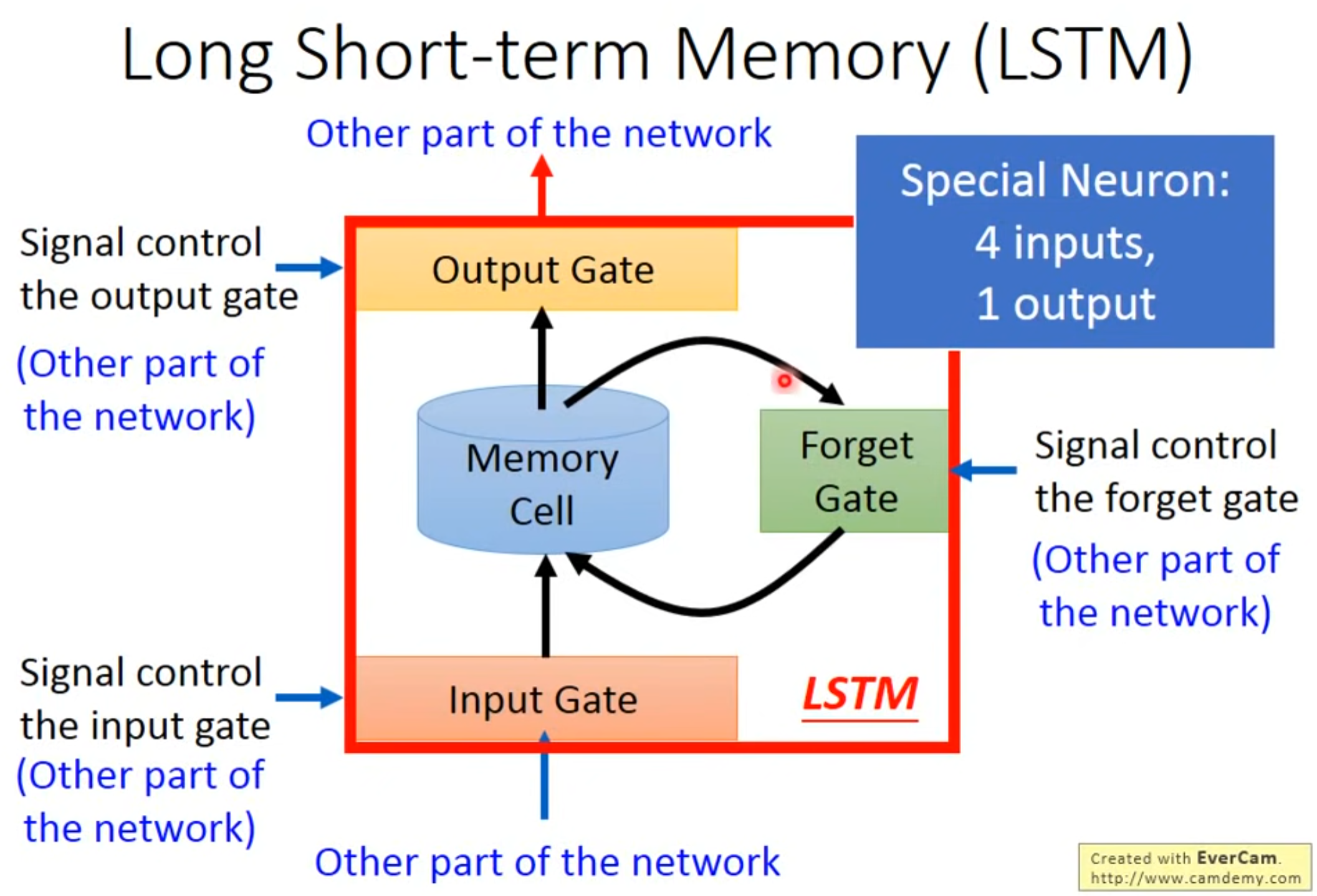
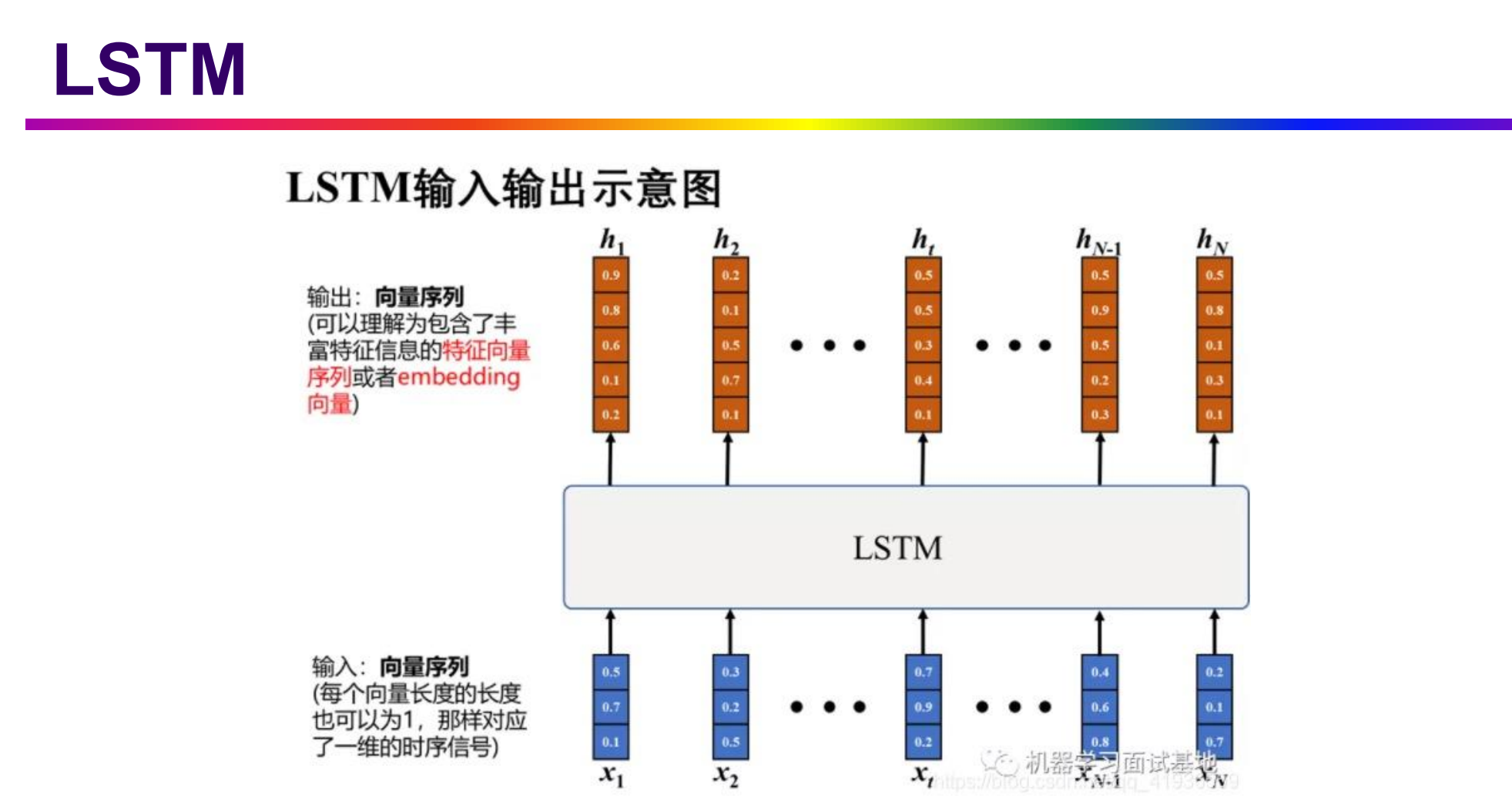
6. LSTM(Long Short-term Memory)
- 长短期记忆(Long Short-Term Memory,LSTM)是一种时间循环神经网络(RNN)
6.1 简介
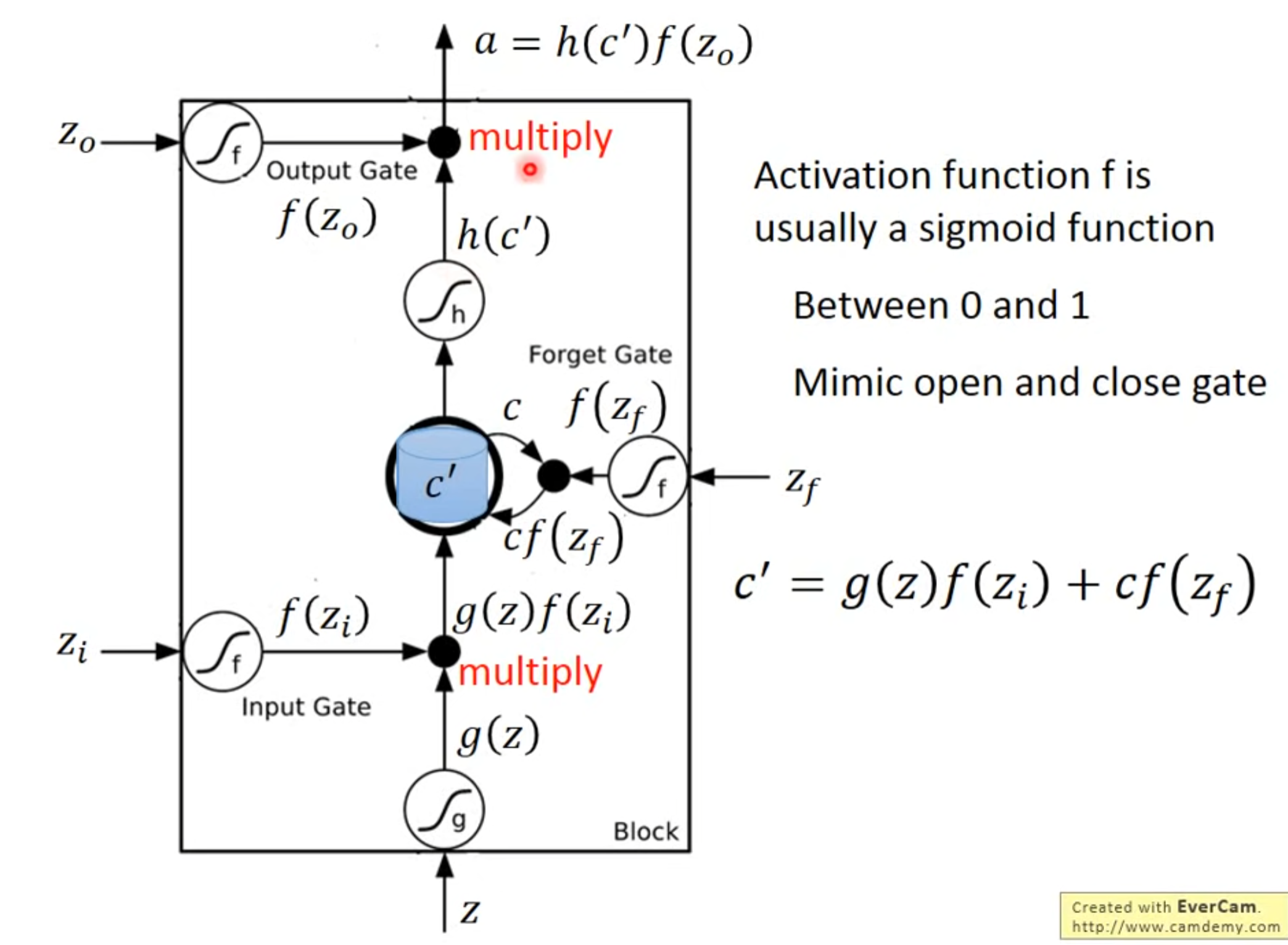
- input gate决定是否可以输入,output gate决定是否可以输出,forget gate 决定什么时候可以清空(都是训练得到)
- 4 个输入指的是操纵Output Gate的信号,操作Input Gate的信号,操作Forget Gate的信号和输入
- $ f(Z_{i}) = 1,相当于不改变输入,f(Z_{i}) = 0,相当于输入无效 $
- $ f(Z_{f}) = 1,相当于不改变Cf(Z_{f}),f(Z_{f}) = 0,相当于Cf(Z_{f})无效 $。forget gate打开时候不清空,关闭时候才清空
6.2 简介LSTM例子
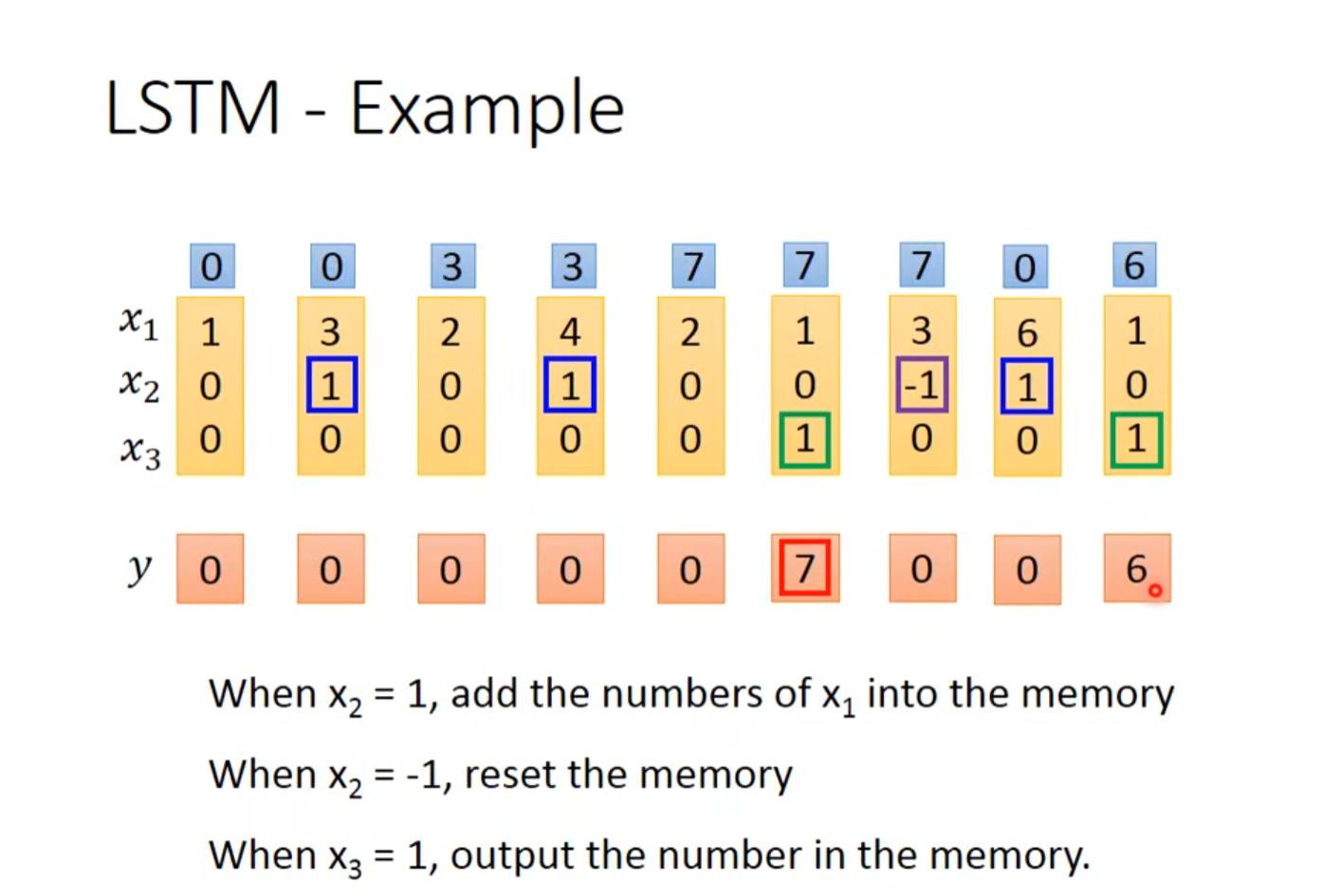
6.3 LSTM实现
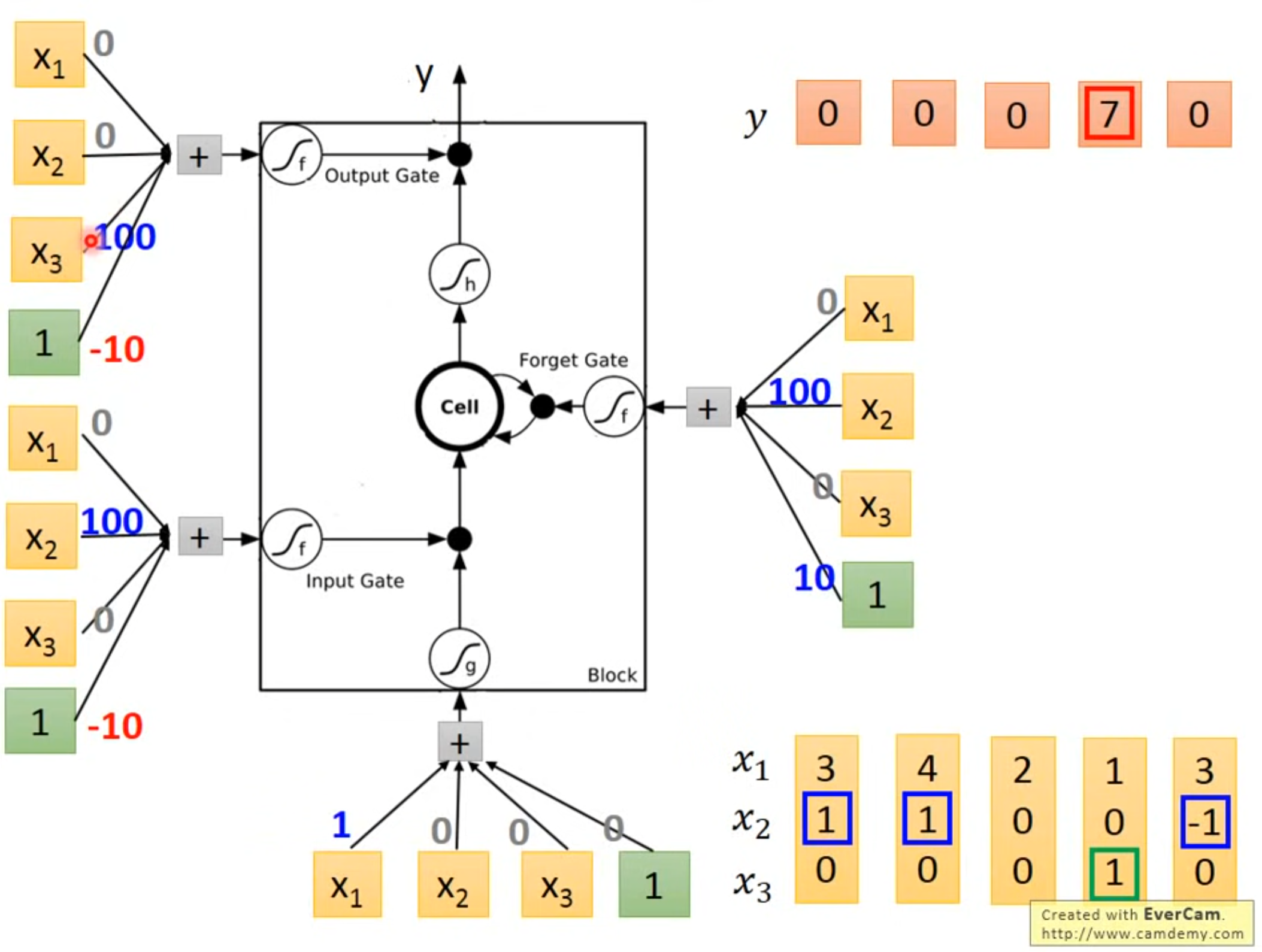
-
输入[3, 1, 0]\(^{T}\)
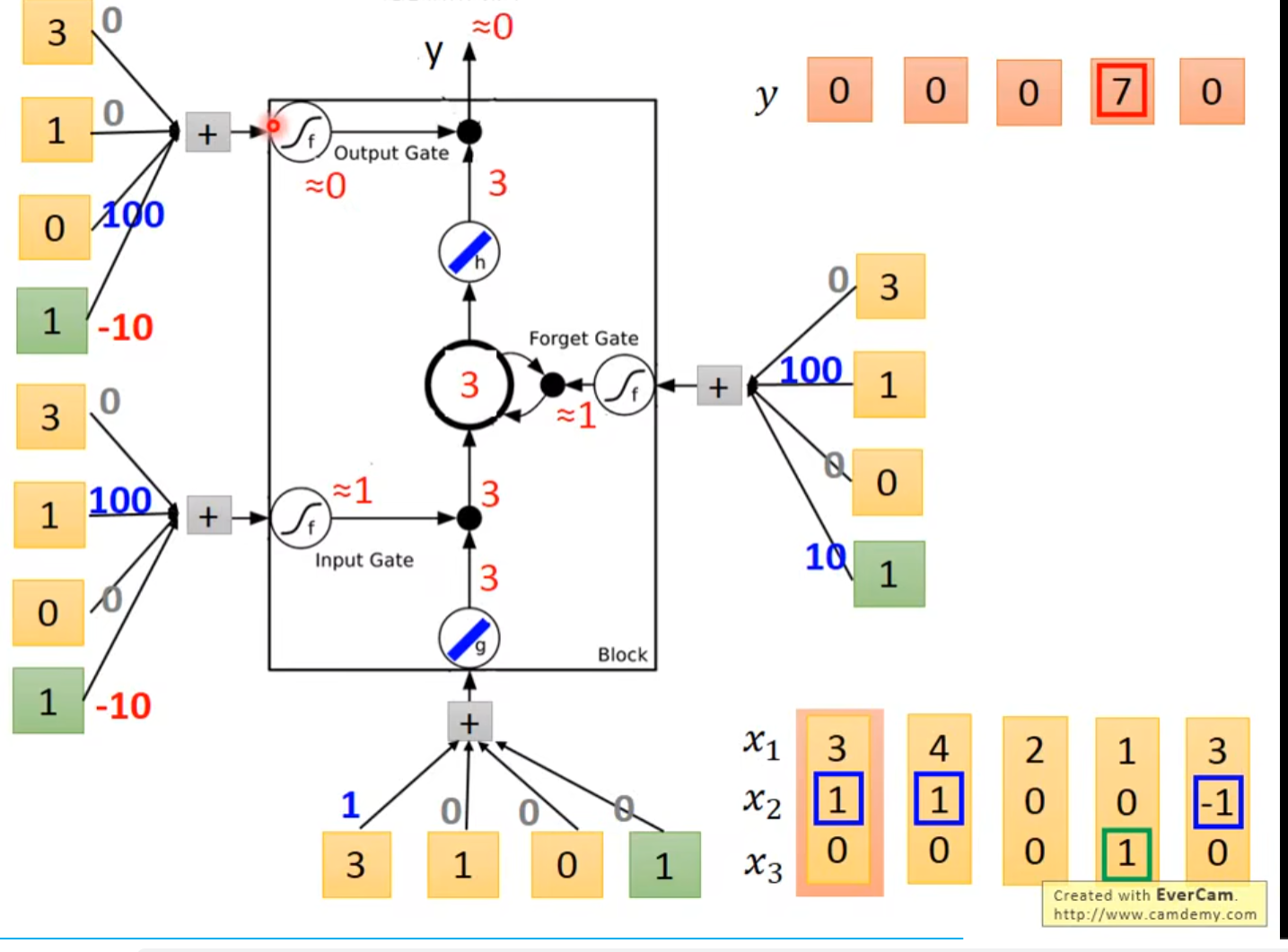
-
输入[4, 1, 0]\(^{T}\)
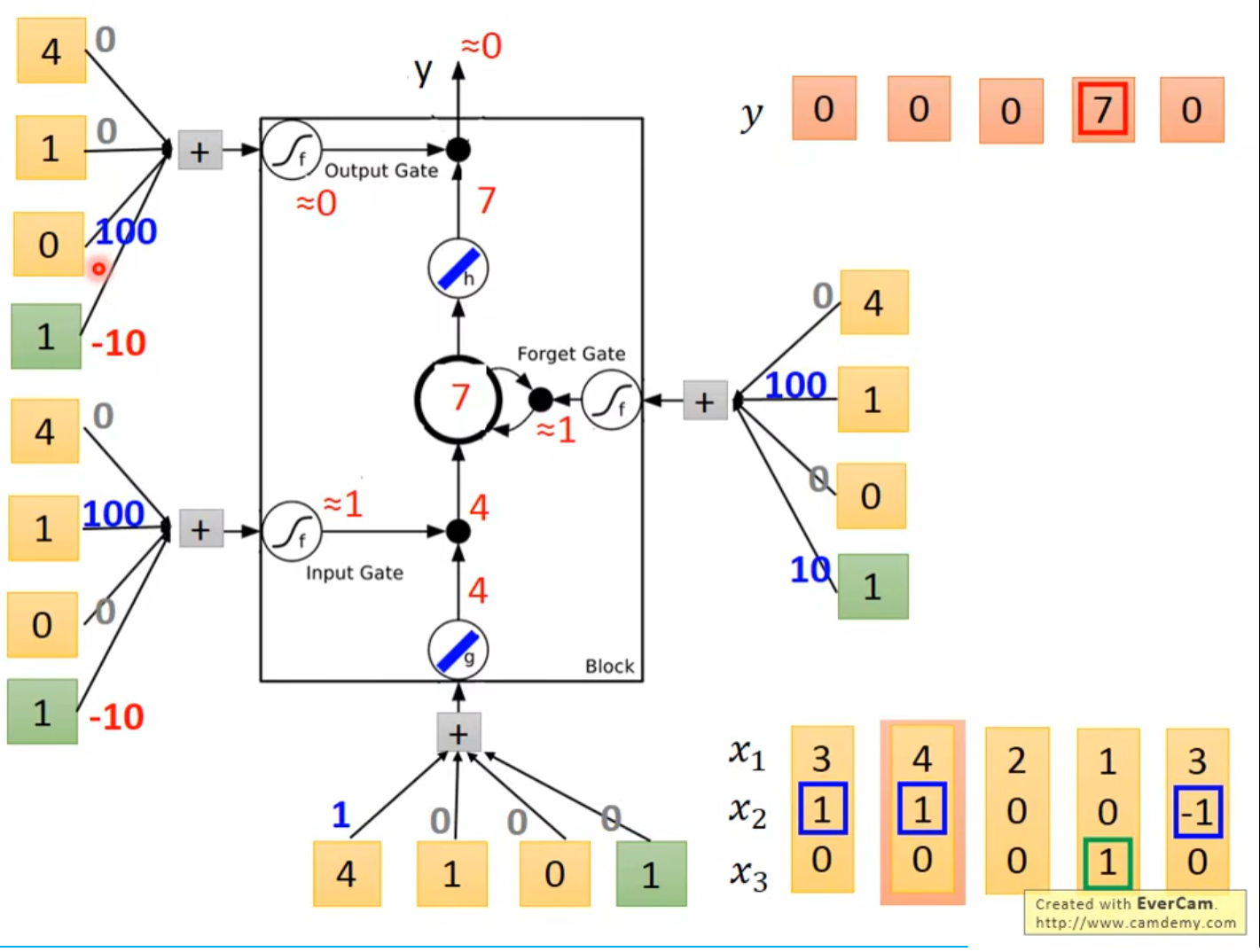
-
输入[2, 0, 0]\(^{T}\)
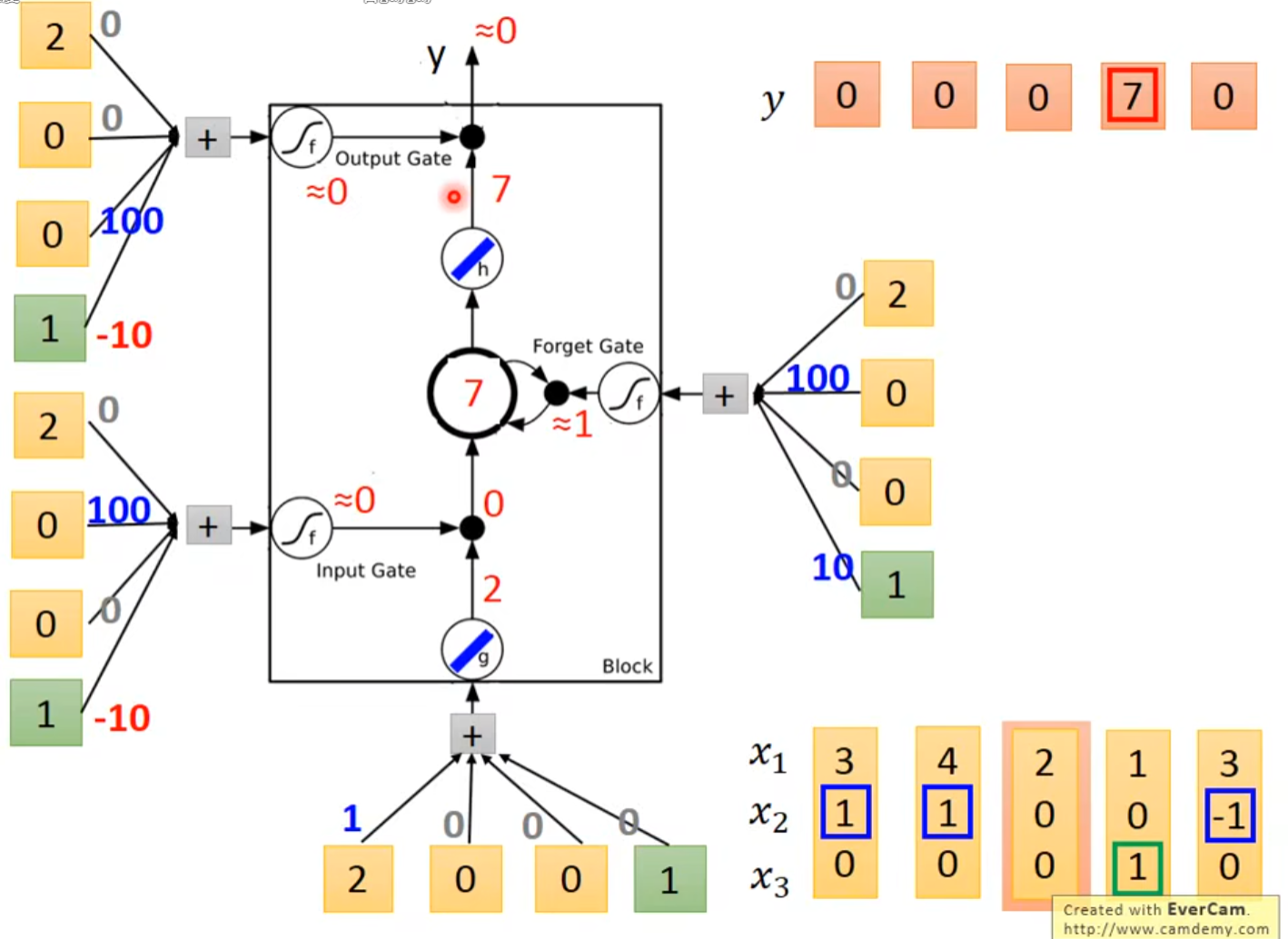
-
输入[1, 0, 1]\(^{T}\)
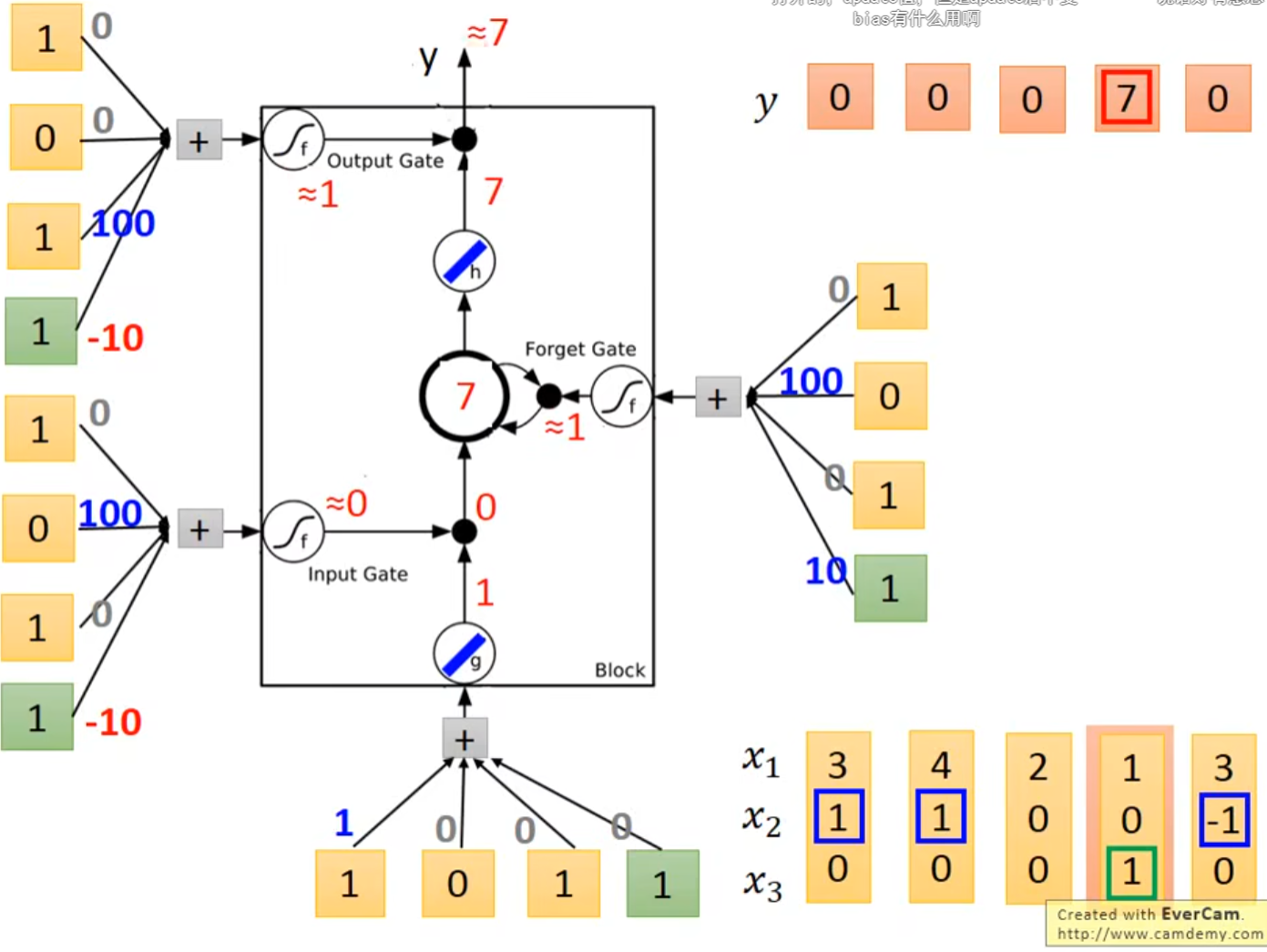
-
输入[3, -1, 0]\(^{T}\)
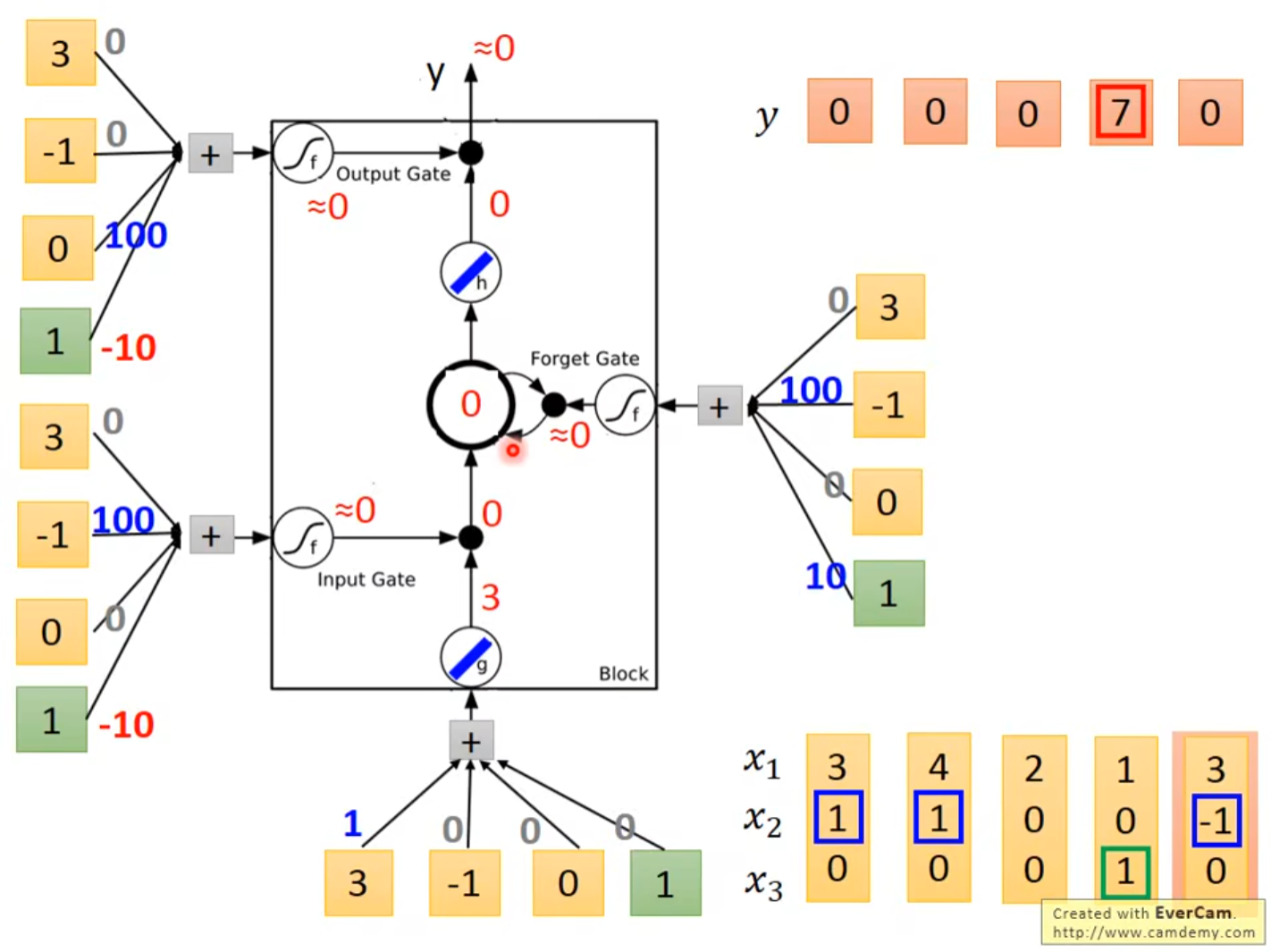

5.3 LSTM VS 普通神经元
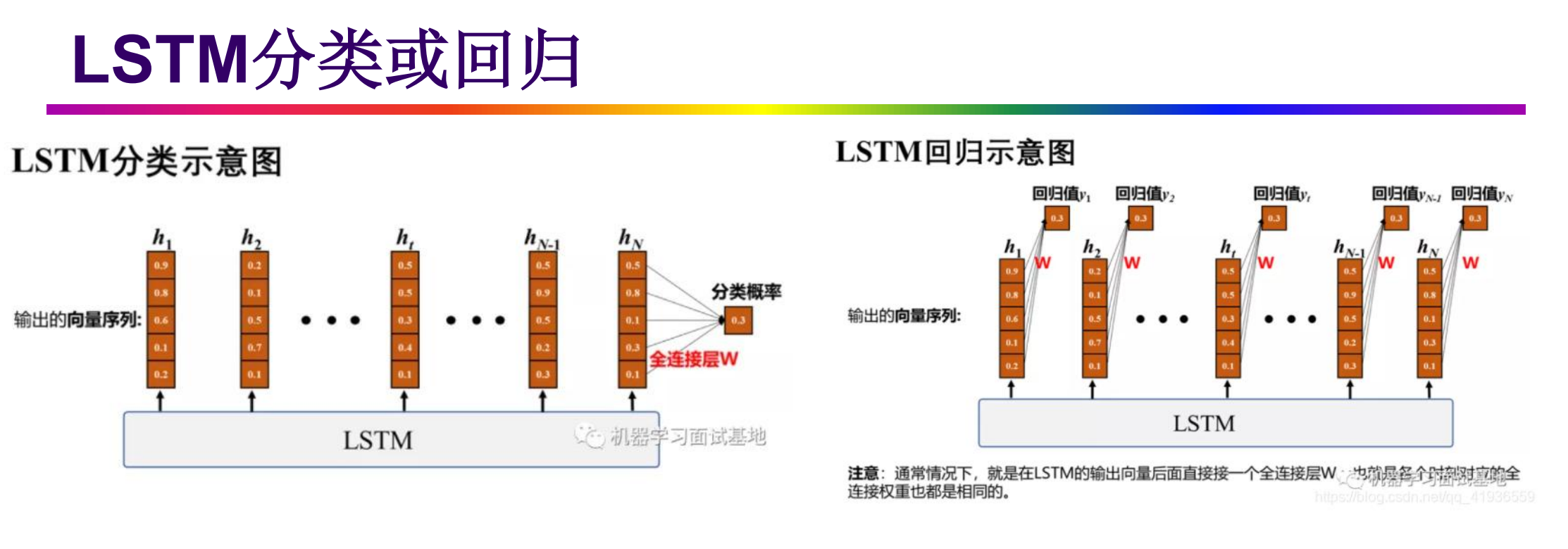
- 把LSTM当作一个特殊的神经元,从下图我们可以看出,由于LSTM多出了三个门,所以输入需要额外地与LSTM进行3次连接,即LSTM需要4个Input,这也就意味着LSTM的参数量是普通神经元的4倍
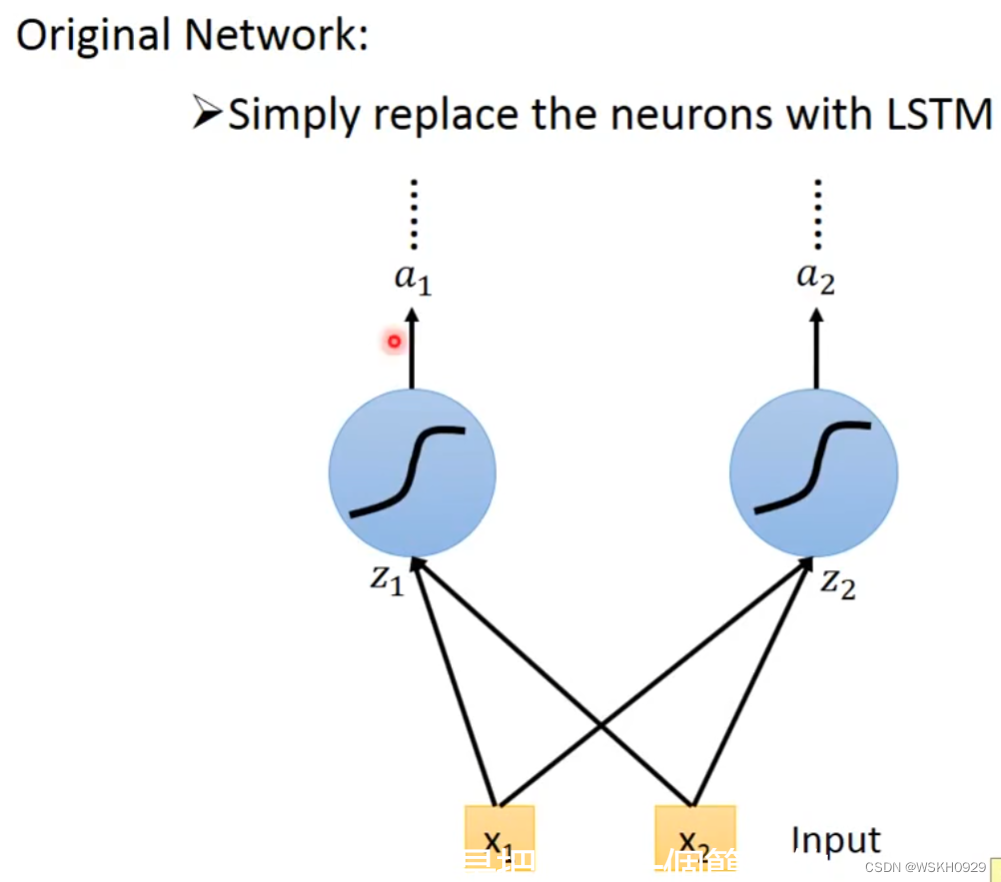
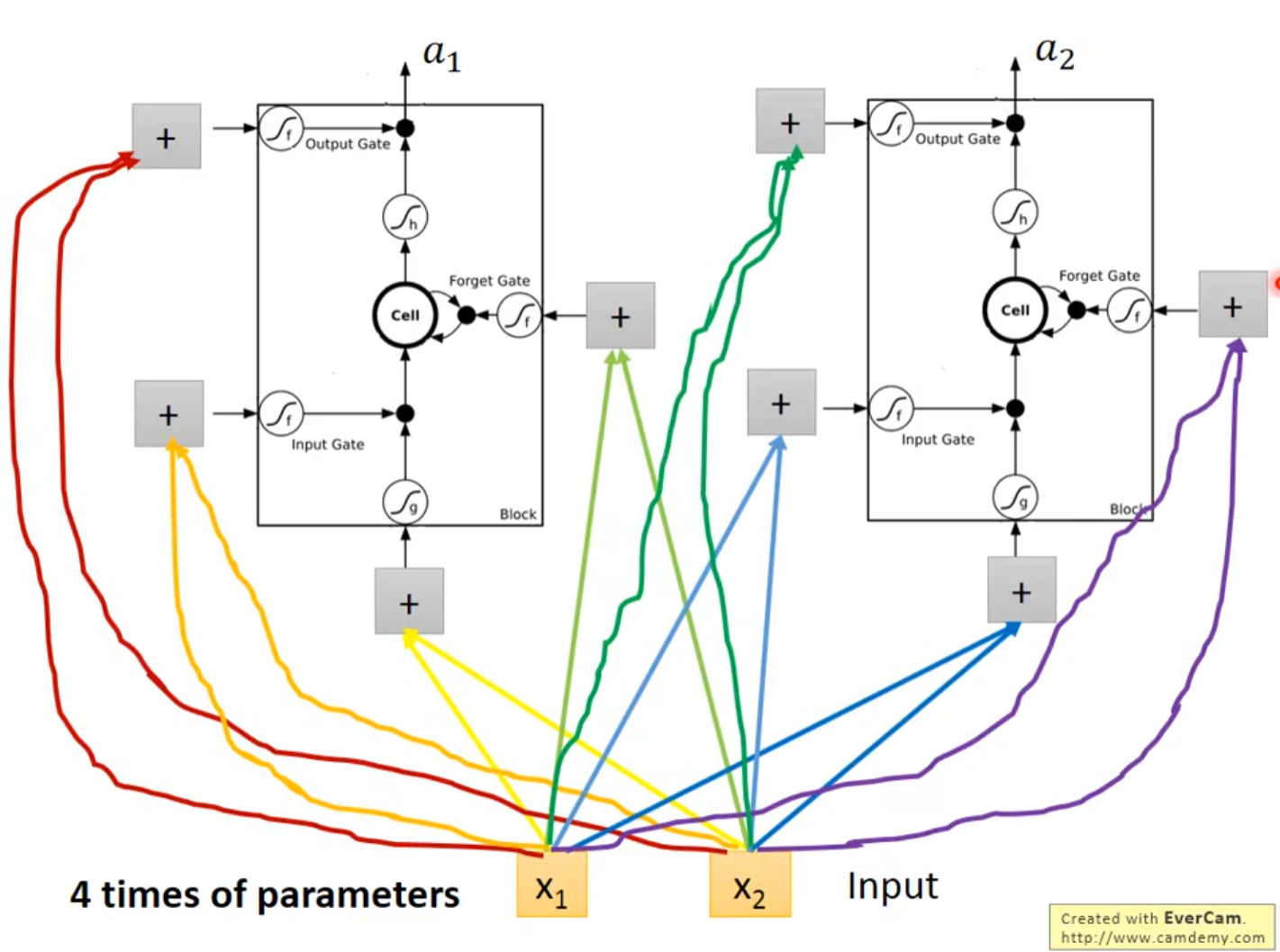
6. LSTM
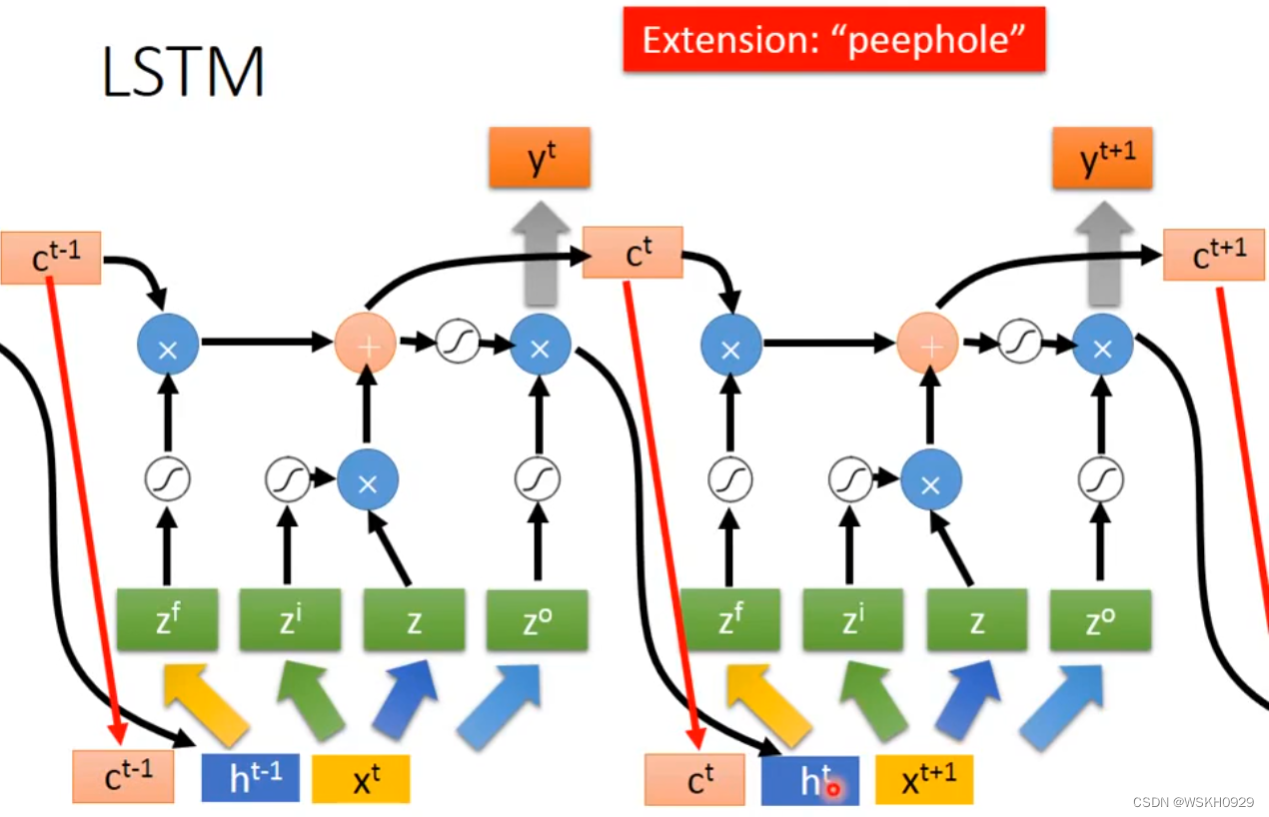
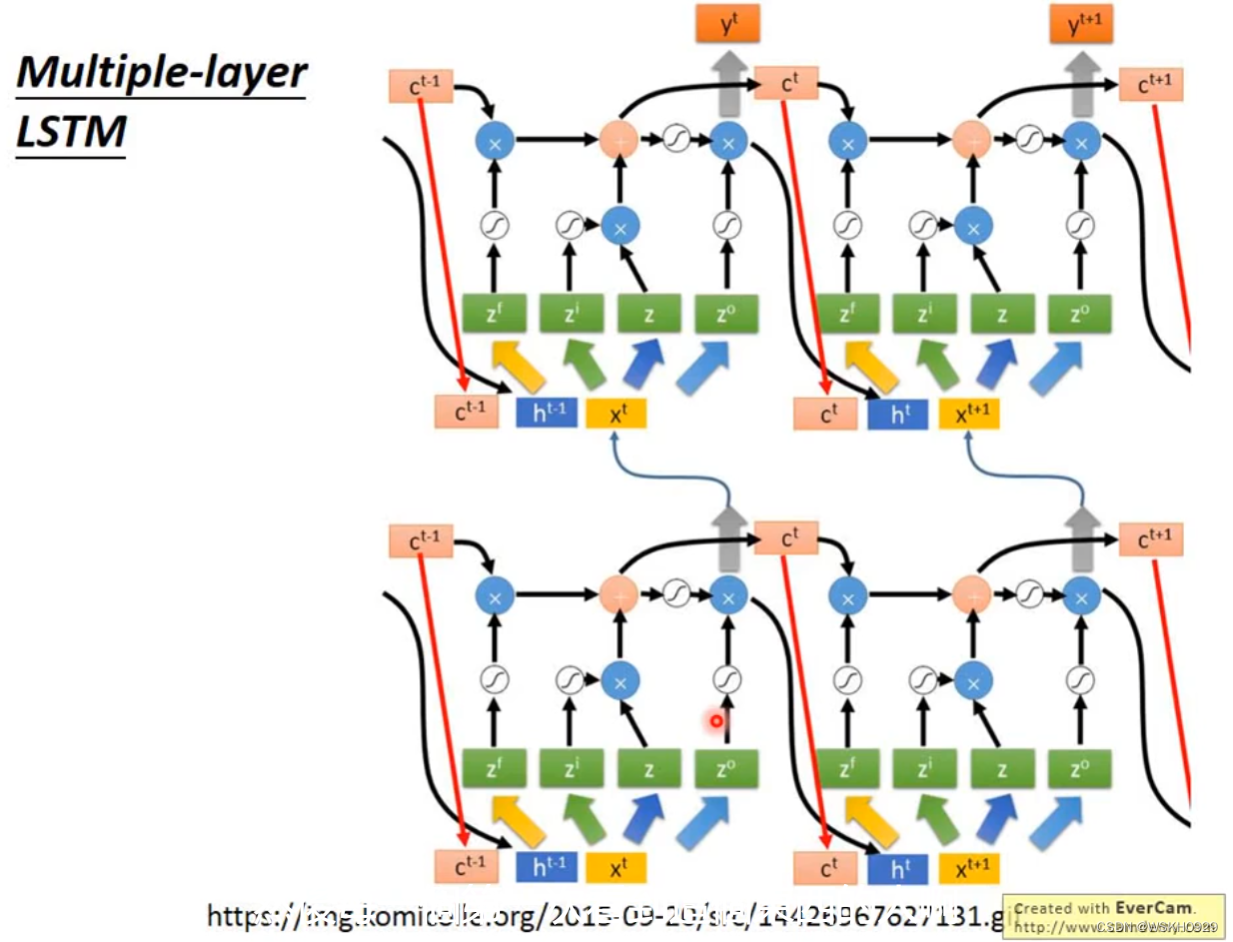
7. RNN缺点
- 梯度消失和梯度爆炸:对于较长的序列数据,在反向传播过程中会出现梯度消失或梯度爆炸的问题,导致模型难以训练和优化
- RNN 有短期记忆问题,无法处理很长的输入序列
- 训练 RNN 需要投入极大的成本
- 导致RNN难以捕捉和利用序列中的长期依赖关系,从而限制了其在处理复杂任务时的性能
7.1 RNN很难训练
7.1.1 原因
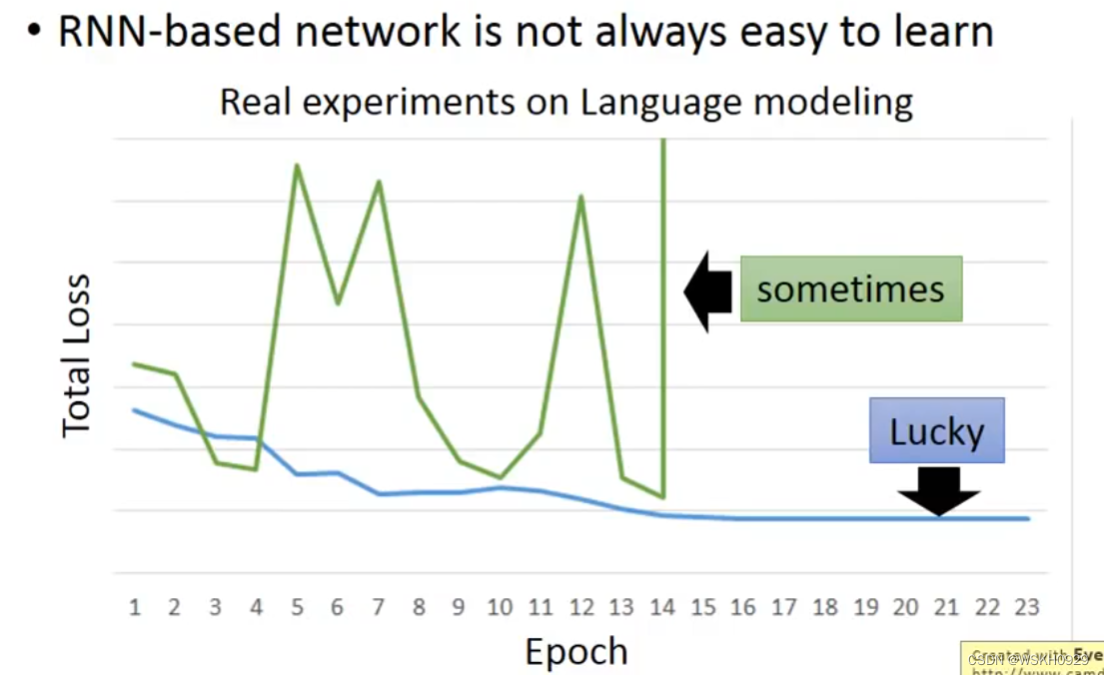
-
RNN是很难Train的,在RNN刚被提出时,很少有人能Train起来。其Loss曲线通常如下图绿线所示,蓝线是正常的Loss曲线。
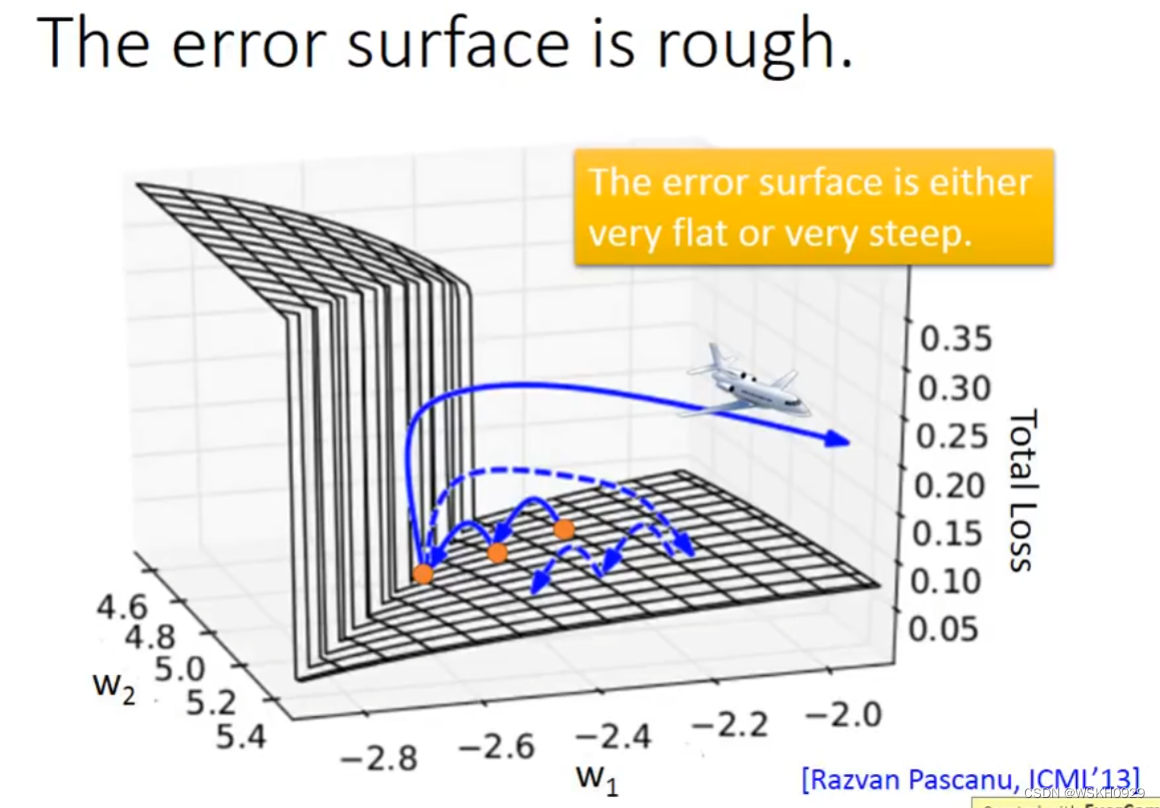
-
为什么RNN如此难 Train ? 有人做了相关研究,发现是因为RNN的error surface的某些区域非常陡峭,在陡峭的区域,就可能导致参数只改动一点,却使得Loss产生巨大的变化。假设从橙色的点用gradient decent 开始调整参数两次,正好跳过悬崖,loss暴增;有时可能正好踩在悬崖上,悬崖上的gradient 很大,之前的都很小,可能learning rate就很大,很大的gradient和learning rate就导致参数飞出去了
7.1.2 小技巧
- Tips:可以采用clipping策略,当gradient 大于某个值的时候,直接令梯度等于该值,防止梯度过大。同样的方法可以用来防止梯度过小。
7.1.3 例子
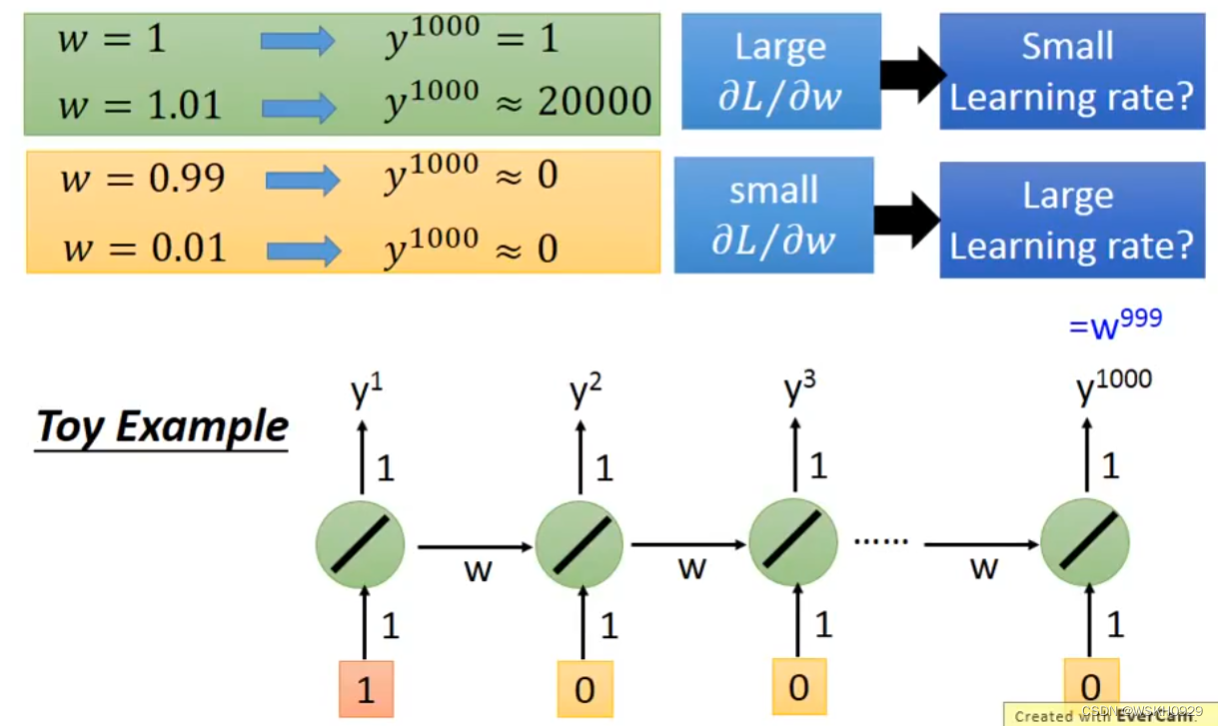
- 下面用一个详细的例子。假设有一个包含1000个RNN的单层神经网络,假设除了第一个RNN单元的输入为1,其余均为0,假设所有RNN单元均没有偏置b。当所有RNN单元的w为1时,
$ y^{1000} = 1 ,当所有RNN单元的w为1.01时, y^{1000} ≈ 20000,可以看出,w仅仅改变了0.01,就导致 y^{1000} 的输出相差近20000倍。 $
7.1.4 解决办法
7.1.4.1 LSTM
- 使用LSTM就可以解决这个问题,它可以让error surface不要那么陡峭,从而缓解该问题
- 问:为什么LSTM可以让梯度变小呢?(梯度变小的意思就是不那么陡峭)
答:RNN中,每个时间点,Memory里的咨询会被覆盖。但是在LSTM中,它的Memory是加权叠加性的,所以原来存在Memory里的值基本都会有所残留。(这也是因为,遗忘门很少情况为0)
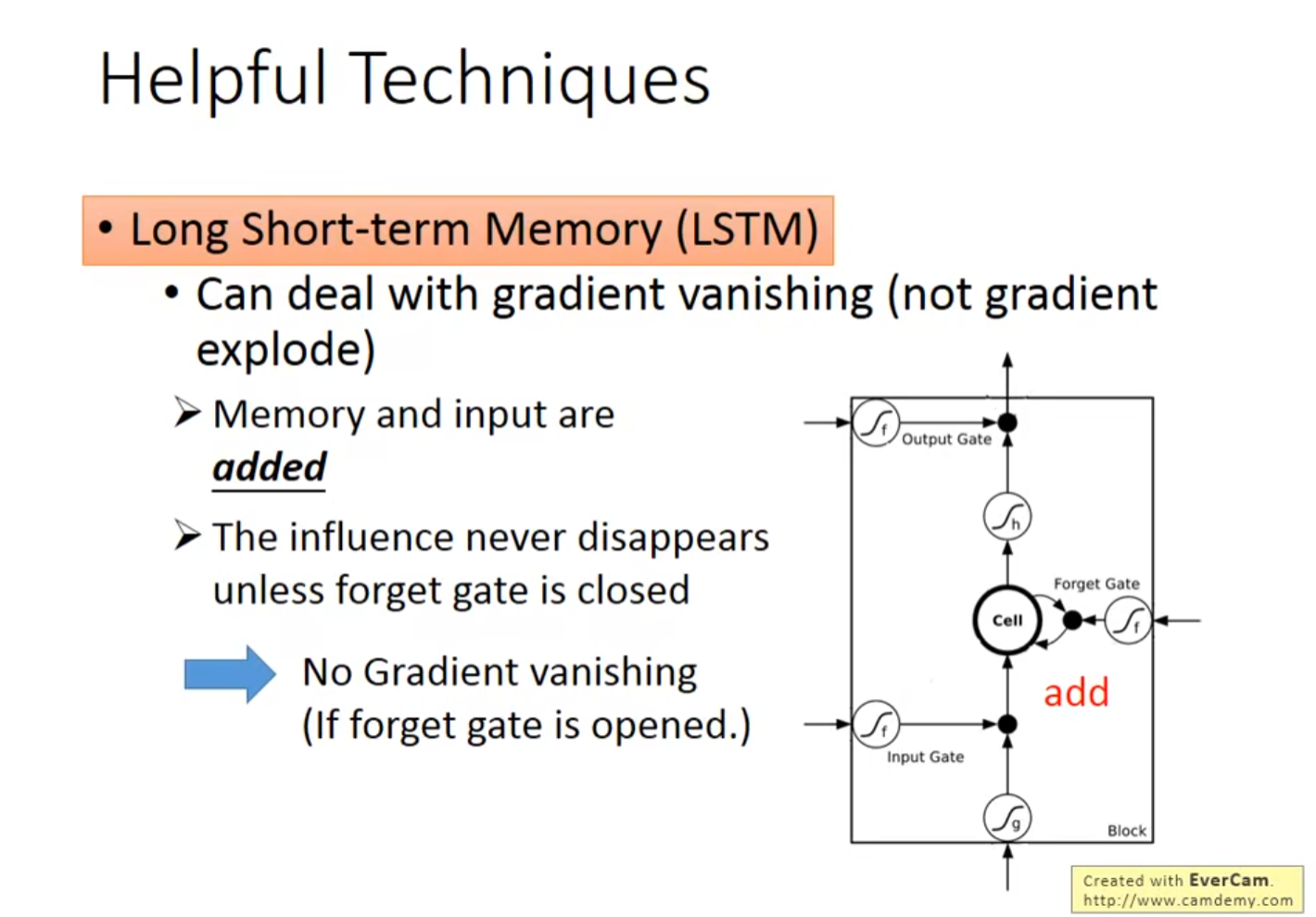
7.1.4.2 GRU(Gated Recurrent Unit)
- GRU 和LSTM一样,也可以解决该问题

8. Many To One
-
之前讲的 Slot Filling 的例子是 Many To Many 的,即输入是向量序列,输出也是向量序列且长度和输入相同
-
Many To One 指的就是 输入是向量序列,但是输出仅仅只是一个向量的问题,下面会讲 Many To One 的实际应用
8.1 Sentiment Analysis 情绪分析
- 使用RNN进行情绪分析,输出判断

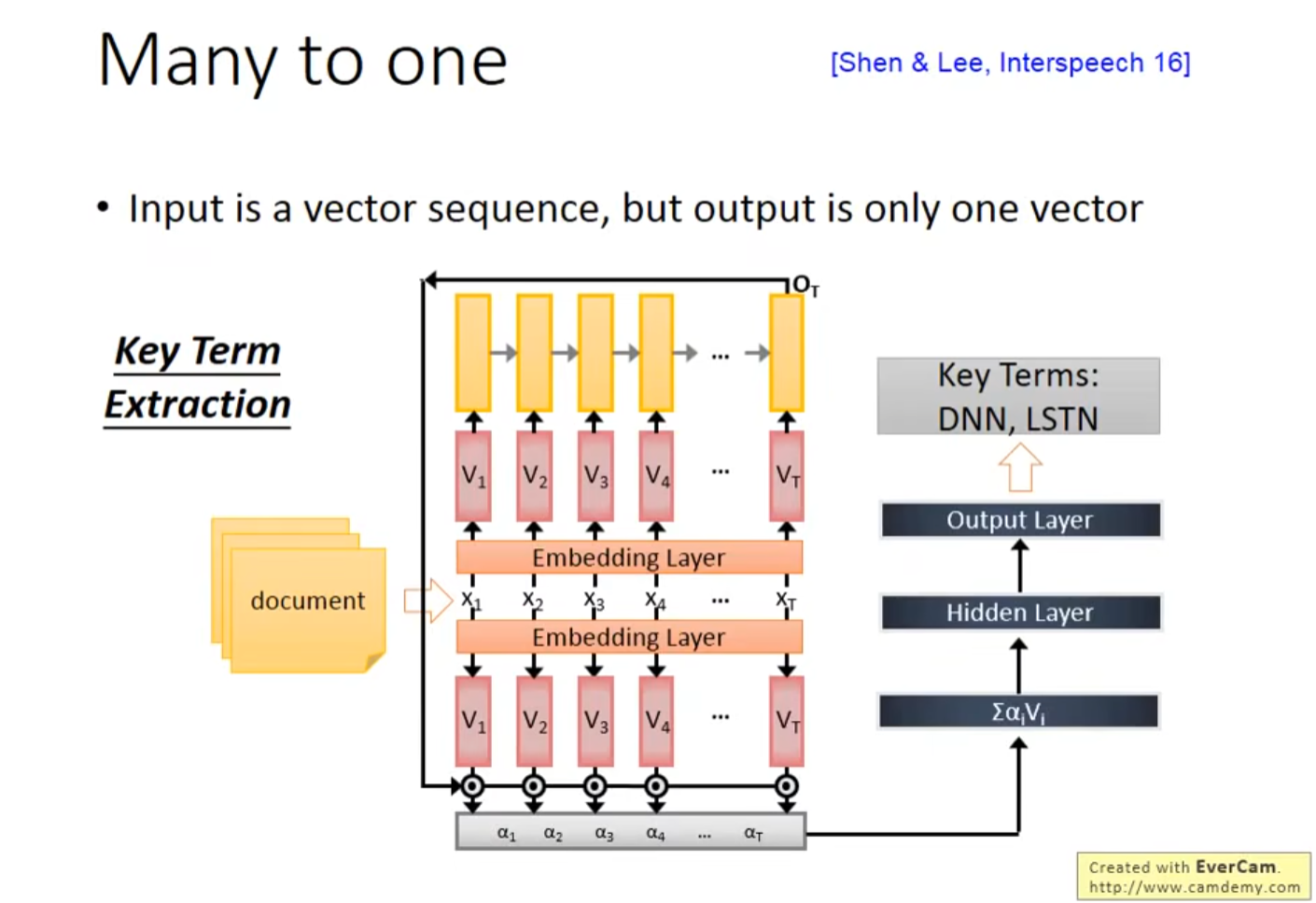
8.2 Key Term Extraction 关键词提取
- 使用RNN进行关键词提取
9 Many To Many(Output is shorter)
- 这种结构又叫Encoder-Decoder模型,也可以称之为Seq2Seq模型
- Encoder-Decoder结构不限制输入和输出的序列长度,因此应用的范围非常广泛
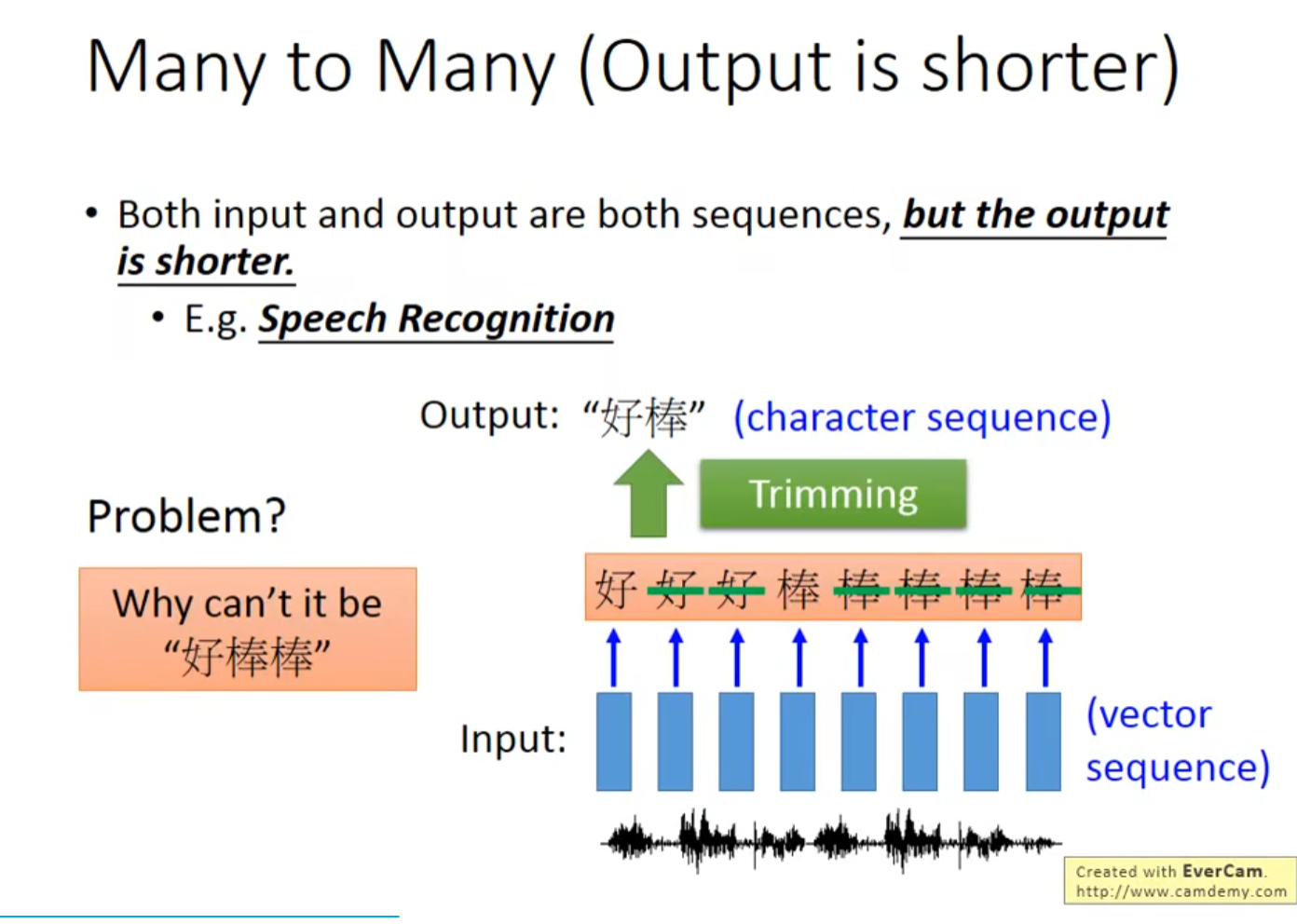
9.1 Speech Recognition 语音辨识
-
由于所取时间间隔短,可能会出现重复,所以简单而言,我们去掉重复即可,但是像下面而言,单纯去掉重复得到好棒,但为什么不可以是好棒棒呢?
-
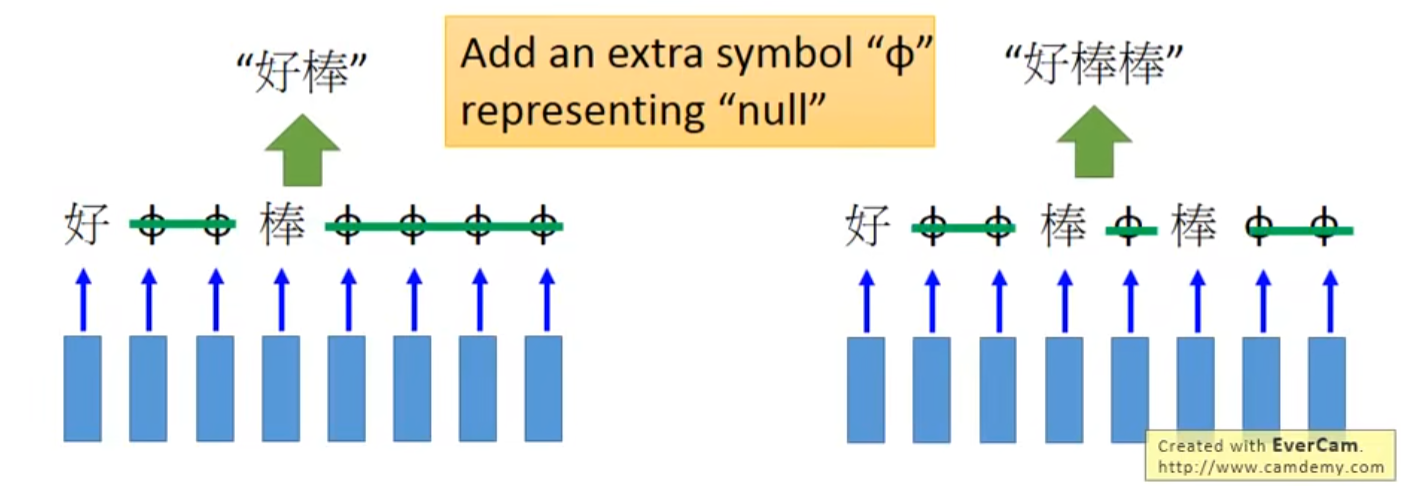
常用的方法叫CTC,即定义一个代表空的符号,然后在得到Output的时候,讲空符号去掉,剩下的就是真正的Output
10. 循环神经网络训练
10.1 RNN 激活函数
- RNN常用的激活函数是tanh和sigmoid
10.2 RNN 训练算法BPTT
- 如果将RNNs进行网络展开,那么参数W、U、V是共享的,并且在使用梯度下降算法中,每一步的输出不仅依赖当前步的网络,还依赖前面若干步网络的状态。该学习算法称为Backpropagation Through Time (BPTT)

10.2.1 BPTT三步骤
- BPTT算法是针对循环层的训练算法,它的基本原理和BP算法是一样的,也包含
同样的三个步骤:
- 前向计算每个神经元的输出值;
- 反向计算每个神经元的误差项值;
- 计算每个权重的梯度,用随机梯度下降算法更新权重
10.2.2 BPTT前向计算

10.2.3 BPTT反向传播

10.2.4 梯度消失和梯度爆炸



 浙公网安备 33010602011771号
浙公网安备 33010602011771号