Operating Systems 3 Easy Pieces 阅读笔记:Chapter 36 I/O设备
Chapter 36 I/O设备
第三部分是持久化Persistence。
在介绍持久化之前,先了解输入输出设备input/output (I/O) device,以及操作系统如何和这些输入输出设备被打交道。
核心问题:IO设备是如何集成进系统的?他们通用的特性有哪些?如何使对它的操作变得高效?
1 系统架构 System Architecture
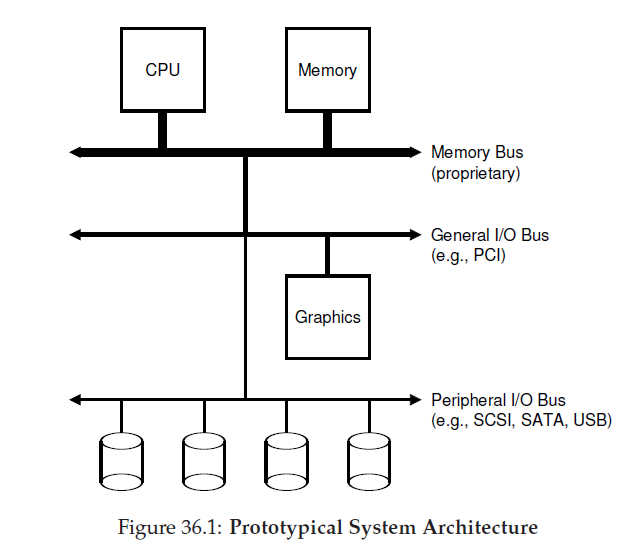
一个典型的系统架构如上图所示。CPU和主存通过Memory Bus直接连接;
一些高性能设备如显卡,通过General I/O BUS (比如PCI)进行连接。
接下来是外围总线(peripheral bus),连接低速设备(SCSI, SATA, or USB)
2 一个标准的设备(A Canonical Device)
一个标准设备由两部分组成:
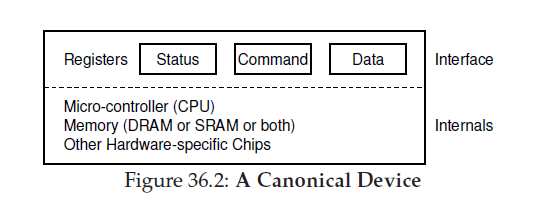
1. 向外面系统暴露的“硬件接口”(interface),来让操作系统进行操作和控制
2 .内部结构,具体实现暴露接口的功能,以及内部运行。简单的设备可以再一个小芯片上硬编码完成功能,复杂的设备自身会有一个CPU,一个小内存,还有一些专用芯片(device-specific chip)来完成上述工作。像RAID的控制器还会有上千行代码的固件(Firmware->software within a hardware device)。
3. 一个标准协议 (The Canonical Protocol)
再上述化简的设备中,包含了一个设备需要的最基础的三个寄存器:
- Status寄存器,表示当前设备的状态
- Data寄存器,用于传data给设备,或者从设备中取出data
- Command寄存器,用于告诉设备去执行具体的任务
那么一个简单的协议如下所示:

上述协议四步走,
1. 轮询设备的状态是否为BUSY;
2. 拷贝数据到DATA寄存器
3. 通知设备处理
4. 轮询设备状态(看看是不是完成了,或者出现了错误)
When the main CPU is involved with the data movement (as in this example protocol),
we refer to it as programmed I/O (PIO).
PIO: CPU亲自参与数据从内存到设备的拷贝工作,如第二步。
上述方法的好处在于简单并且能健壮工作。
但是,上述方法并不便捷而且低效:轮询会消费大量的CPU时,阻止CPU去处理别的进程的任务。
4. 通过中断来降低CPU的浪费(Lowering CPU Overhead With Interrupts)
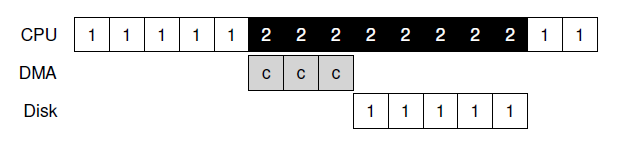
通过中断和上下文切换,可以做到多进程任务的重叠执行:

上图表示Disk在写1的时候,CPU切出去执行2,Disk在Finish之后会出发终端让CPU回来执行1.
但是,进行上下文的切换本身也是有成本的。
如果设备本身足够快,切换上下文的成本是得不偿失的。POLLING轮询是更好的选项。
如果设备的速度是未知的,可以采用混合(hybrid)的策略:先轮询一会,如果设备还是没有完成任务,就进入中断。
在网络应用的考虑中,也不建议使用中断。大量的包同时连接主机,如果使用中断,可能会导致livelock:切出了太多太多执行体,导致系统除了context switch啥也干不了。(* 所以handle 一个 request 就开一个线程(即使线程本身没有开销)也是不合理的,可以使用M:N线程来获得对执行本身的control和多路复用之间的平衡 *)。
还有一种基于中断的优化是聚合(coalescing)。在这种情况下,每次设备想发起中断时先等待一段时间,看看会不会有其他requests也要完成了,如果有就打包成一个中断发送给系统。当然等待时间本来就会带来延迟,因此这种方法也需要工程上的权衡。
5. 更进一步:用DMA来加速数据拷贝(More Efficient Data Movement With DMA)
在我们的标准设备中,还有一个值得注意的问题。就是PIO(Programmed I/O)传输大块大块的数据,CPU手把手把数据从内存往设备拷贝的时候,CPU的负担依旧时很重的,而且用在了一个这么简单的任务上,应该把这部分负担解决掉,PIO的时间用来处理别的进程。

那么如何降低PIO带来的浪费?
在设备Device和主存Main Memory之间引入DMA(Direct Memeory Access)Engine。
有DMA之后,操作系统就会告诉DMA数据在内存中的位置,长度,以及输送的目标,然后context switch去执行别的任务,知道数据拷贝完成,如下所示:
6. 与设备交互的方法(Methods Of Device Interaction)
1. explicit I/O instructions
IBM发明的,显式的命令,让OS来发送数据给某个具体设备的register,然后再进行上述的protocol。
在x86指令集上,就有in和out的指令来操作设备。比如向设备发送数据,执行体就要给两个参数,一个是目前保存了数据的寄存器,另一个是具体的port指向一个具体的设备。
这样的命令往往是高权限的,会带来一些安全问题。
2. memory-mapped I/O
把硬件的寄存器映射到内存地址中,这样就能像访存写存一样操作设备。
To access a particular register, the OS issues a load (to read) or store (to write) the address; the hardware then routes the load/store to the device instead of main memory.
7. 接入OS:设备驱动 (Fitting Into The OS:The Device Driver)
越通用越好:As Gerneral As Possible
一个文件系统,应该能在SCSI, IDE, USB的设备上都能使用
进行抽象↓↓↓

底层的软件了解设备工作的细节,并向上层提供接口,又名设备驱动Device Driver。
一个上层的文件系统(以及Applications)每次就发起块级的写入读取请求,然后被分流到具体的设备驱动进行。
这种做法也有坏处:SCSI设备具有丰富的错误码,但是ATA和IDE的error handling非常简单,所以上层的软件只能收到的是EIO(Generic IO Error)。
设备驱动占了一个操作系统内核代码的70%。
然后设备驱动往往不是最专业的内核编程者写的,sloppy, 更多BUG,导致内核crashes。
8. 简单案例: IDE Disk Driver
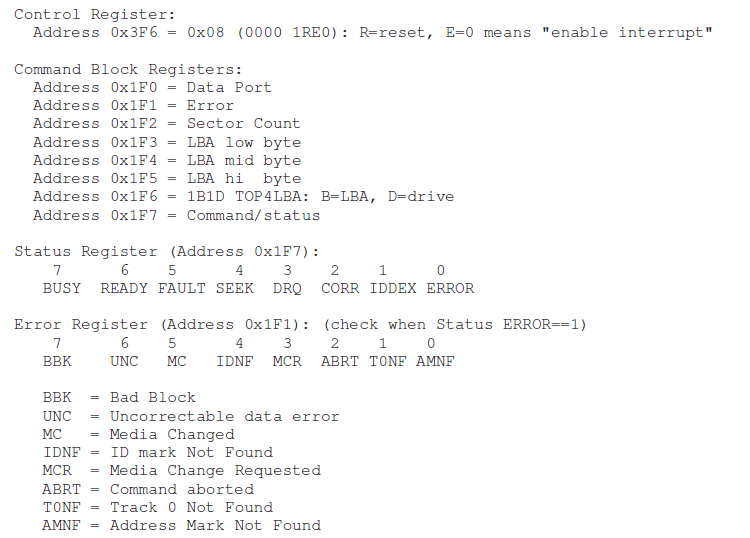
一个IDE具有四种寄存器:
- control
- command block
- status
- error
这四种寄存器通过访问具体的("I/O Address")比如0x3F6来读写,读写采用in和out命令。
它的基本执行流程如下:

XV6系统将上述流程Protocol实现为四个函数:
1. 等待设备

2. ide_rw
当有别的读写请求pending时,入队一个读/写请求
当没有,就通过ide_start_request直接写入磁盘

3. ide_start_request

4. ide_intr() 当一个中断发生时执行。它从device中读取数据,写到需要这个数据的process中,并lanuch下一个ide_start_request()。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号