MySQL和SqlAlchemy配置指北
近期做了一个项目+库存的管理应用,开发时偷懒用的SQLite,上线后再调整时有时候要直接进数据库改数据,开始想念navicat的好处,动了上MySQL的念头,折腾一番后把一些安装要点写在这里。
安装
安装最新版本的MySQL在Ubuntu上是十分容易的。只要执行
$ sudo apt-get install mysql-server mysql-client
安装过程中会要求设置用户的root密码。
其中, mysql-server相当于mysql数据库的核心系统,mysql-client则提供交互管理的组件,比如`mysql`命令进入的命令行管理程序,就是mysql-client提供的。
配置
值得一提的是我安装好的mysql版本(5.7.20),在/etc/mysql/my.cnf文件的内容为:
!includedir /etc/mysql/conf.d/ !includedir /etc/mysql/mysql.conf.d/
也就是说,按这个版本的实践,最好去这两个目录里修改对应的配置文件。
为了能够远程直接访问数据库,需要更改数据库的bind-address。
本版本中,是前往` /etc/mysql/mysql.conf.d/`目录,修改mysqld.cnf文件,如下:
[mysqld] # log文件配置 bind-address = 0.0.0.0
重启数据库的方式:
$ sudo /etc/init.d/mysql restart
账户和权限
安装完的Mysql提供了一个只能从本地访问的root账户。通过root账户登录数据库,可以查看`mysql database`中的数据。查看mysql中用户列表的方法:
mysql > use mysql; # 进入mysql数据库 mysql > select host, user from mysql.user; # 查看用户列表
直接能远程登录root账户显然是不安全的,目前我采用的办法是用root账户创建项目的数据库和开发数据库,然后创建使用账户,授权给这个账户对于这两个数据库的所有权限。
命令如下:
mysql> create database project_name; mysql> create database project_name_dev; mysql> create user ‘username’@’%’ identified by ‘password’; mysql> grant all on project_name.* to ‘username’@’%’; mysql> grant all on project_name_dev.* to ‘username’@’%’;
文字编码问题
在实际使用MySQL时,我遇到第一个头痛的问题是存入的中文变成了乱码,或者报错。
首先是乱码问题,默认安装完的MySQL(我的版本是5.7.20)采用的是latin1的数据库字符集,如果要更改以后创建的数据库的字符集可以去/etc目录修改配置文件。
MySQL的字符集和校对规则有4个级别的默认设置:服务器级、数据库级、表级和字段级。
服务器字符集和校对规则可以在MySQL服务启动的时候确定。
服务器级的默认字符集和校对规则可以通过my.cnf中设置:
[mysqld] character-set-server = utf8mb4
collation_server = utf8mb4_unicode_ci
连接字符集和校对规则
在配置文件/etc/mysql/conf.d/mysql.cnf修改默认编码:
[mysql] default-character-set = utf8mb4 [client] default-character-set = utf8mb4 [mysqld] # init_connect: A string to be executed by the server for each client that connects. The string consists of one or more SQL statements, separated by semicolon characters. init_connect = 'SET NAMES utf8mb4'
关于这个utf8mb4多出来的mb4,mb4就是most bytes 4的意思。MySQL在5.5.3之后增加了这个utf8mb4的编码,专门用来兼容四字节的unicode。好在utf8mb4是utf8的超集,除了将编码改为utf8mb4外不需要做其他转换。我一开始采用utf8编码时,导入数据就会遇到“超过3个字节”的错误,采用utf8mb4能解决这个问题。有人说utf8mb4的会占用更多内存是不对的,因为utf-8本来就是变长编码,是mysql一开始对utf-8的支持就不正确,所有字符都需要四个bytes来存储就是UTF-32了。
所有涉及的配置变量的官方文档见链接。按本文设置完在mysql命令行中结果如下所示:
$ mysql> show variables like '%char%'; +--------------------------+----------------------------+ | Variable_name | Value | +--------------------------+----------------------------+ | character_set_client | utf8mb4 | | character_set_connection | utf8mb4 | | character_set_database | utf8mb4 | | character_set_filesystem | binary | | character_set_results | utf8mb4 | | character_set_server | utf8mb4 | | character_set_system | utf8 | | character_sets_dir | /usr/share/mysql/charsets/ | +--------------------------+----------------------------+ 8 rows in set (0.00 sec)
如何在SqlAlchemy中指定显式表的引擎和字符集
class User(Base):
__table_args__ = {
'mysql_engine': 'InnoDB',
'mysql_charset': 'utf8mb4'
}
也可以在基类上直接修改:
class Base (Base):
__abstract__ = True
__table_args__ = { # 可以省掉子类的 __table_args__ 了
'mysql_engine': 'InnoDB',
'mysql_charset': 'utf8mb4'
}
使用基类来创建所有表都需要的字段的方法:
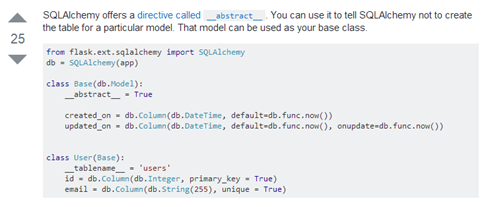
链接:
https://stackoverflow.com/questions/22976445/how-do-i-declare-a-base-model-class-in-flask-sqlalchemy
ORM中计数器的”atomic increment”
在这篇Django博主介绍自己如何给网站做uv和pv统计的博文中,提到了可能存在的计数器竞争的问题。https://www.the5fire.com/pv-statistics-in-django-blog.html
具体而言,假设我们有个`post`表,对应有一个叫Post的class:
class Post:
__tablename__ = ‘post’
id = db.Column(db.Integer, primary_key=True)
content = db.Column(db.Text)
uv = db.Column(db.Integer)
pv = db.Column(db.Integer)
然后我们在视图函数中每次访问执行以下语句是会有问题的:
# 错误示范1 p.uv = p.uv + 1 # 错误示范2 p.uv += 1
我们暂时不考虑缓存设施,先让视图函数直接访问操作数据库。
假设一篇id为2的文章在下午3点的uv是5。然后恰好有两个人在3点00分01秒同时点击这篇文章,可能就会出现竞争问题。线程一接待了客户1,从数据库读到了uv = 5。然后线程被调度挂起了,线程2开始接待客户2,再次从数据库中读到了uv = 5。然后两个线程在python运行环境中计算出5 + 1 => 6,先后执行SQL语句
UPDATE `post` SET `pv` = 6 WHERE `id` = 2
语句被执行了两遍,uv没有被加到7,GG。
正确的做法应该是视图函数要去传入SQL语句
UPDATE `post` SET (`pv` = `pv` + 1) WHERE `id` = 2
那么SqlAlchemy中如何做呢?很简单:
p.uv = Post.uv + 1
如此自然,SqlAlchemy棒棒的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号