import requests
from bs4 import BeautifulSoup
from pygtrans import Translate
def multi_requests(url, headers=None, verify=False, proxies=None, timeout=120):
res = None
for _ in range(5):
try:
res = requests.get(url, headers=headers, verify=verify, proxies=proxies, timeout=timeout)
if res.status_code == 200:
break
except Exception as err:
time.sleep(5)
return res
def md5_hash(content):
md5 = hashlib.md5()
if isinstance(content, str):
content = content.encode('utf-8')
md5.update(content)
return md5.hexdigest()
def new_request(url: list):
(MD_url, IVD_url, IVD2_url) = (i for i in url)
bytes_datas = get_bytesdata((MD_url, IVD_url, IVD2_url))
df_list = parse_excel_bytes_data(bytes_datas)
for df in df_list:
df.columns = df.columns.str.replace('_', ' ')
df_all = pd.concat(df_list, axis=0, ignore_index=True).dropna(axis=1, how='all').fillna('')
df_all['create_date'] = '2023-03-02'
group = [
'EXPEDIENTE',
'PRODUCTO',
'REGISTRO SANITARIO',
'ESTADO REGISTRO',
'FECHA EXPEDICION',
'FECHA VENCIMIENTO',
'MODALIDAD',
'GRUPO',
'NIVEL RIESGO',
'USOS',
'VIDA UTIL',
'TITULAR',
'PAIS TITULAR',
'DEPARTAMENTO TITULAR',
'CIUDAD TITULAR',
'ivd md type',
'create_date'
]
# 多行转多列
df_all.drop_duplicates(group + ['ROL'], inplace=True)
reset_df = df_all.pivot(index=group, columns=['ROL'], values=['NOMBRE ROL', 'PAIS ROL'])
df_reset = reset_df.reset_index().fillna('')
# 翻译国家名
df_reset.columns = [''.join(col) for col in df_reset.columns.values]
# country_column = [column for column in self.df_reset.columns if 'PAIS' in column]
need_tran = ['PAIS TITULAR', 'PAIS ROLACONDICIONADOR', 'PAIS ROLALMACENADOR', 'PAIS ROLAPODERADO',
'PAIS ROLEMPACADOR', 'PAIS ROLENTIDAD RESPONSABLE SISMED', 'PAIS ROLENVASADOR',
'PAIS ROLEXPORTADOR', 'PAIS ROLFABRICANTE', 'PAIS ROLIMPORTADOR', 'PAIS ROLMAQUILADOR',
'PAIS ROLREPRESENTANTE LEGAL', 'PAIS ROLRESPONSABLE']
for col in need_tran:
df_reset[f'{col}_t'] = country_translate(df_reset[col])
date_column = ['FECHA EXPEDICION', 'FECHA VENCIMIENTO']
for column in date_column:
df_reset[column] = parser_date(df_reset[column])
df_reset['ID'] = df_reset.apply(lambda x: md5_hash((x['PRODUCTO'] + x['TITULAR']).encode()),
axis=1)
return df_reset
def parser_date(data: pd.Series):
dict_ = {}
for date_value in data.unique():
try:
dict_.update({date_value: pd.to_datetime(date_value, infer_datetime_format=True, format=None,
errors='coerce').strftime("%Y-%m-%d")})
except:
pass
return data.apply(lambda x: dict_.get(x, ''))
def parse_excel_bytes_data(bytes_data):
"""
bytes_data : 二进制文件们
"""
df_excel = [pd.read_excel(io.BytesIO(bytes), engine='openpyxl') for bytes in bytes_data]
df_excel[0]['ivd_md_type'] = 'MD'
df_excel[1]['ivd_md_type'] = 'IVD'
df_excel[2]['ivd_md_type'] = 'IVD'
return df_excel
def get_bytesdata(urls):
"""
urls : excel的url们
"""
bytes_data = tuple(multi_requests(url, verify=False).content for url in urls)
return bytes_data
def country_translate(data: pd.Series):
"""
获取国家翻译映射字典
column:需要翻译的column列表
"""
client = Translate()
dict_ = {}
for i in data.unique():
try:
text = client.translate(i, target='en').translatedText.strip()
dict_.update({i: text})
except:
continue
return data.apply(lambda x: dict_.get(x, ''))
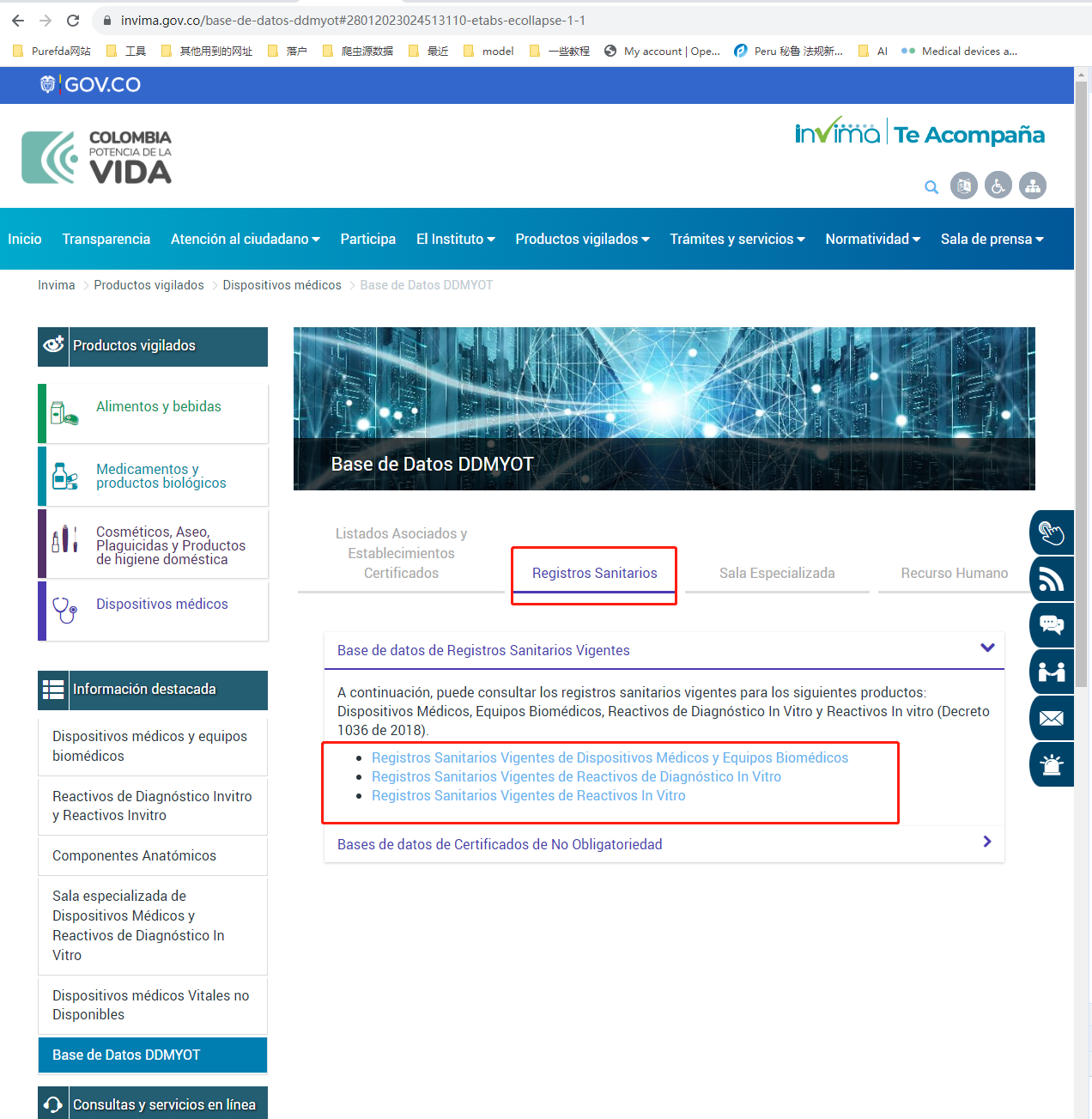
frist_res = multi_requests(url="https://www.invima.gov.co/base-de-datos-ddmyot")
soup = BeautifulSoup(frist_res.content, 'html.parser')
url_list = [a['href'] for a in soup.find('div', id=re.compile('\d?-etabs-ecollapse-2-1')).find_all(['a'])]
url_list[0] = "https://drive.google.com/uc?export=download&id=" + re.findall(r"/d/(.*?)/edit", url_list[0])[0]
content = new_request(url_list)