


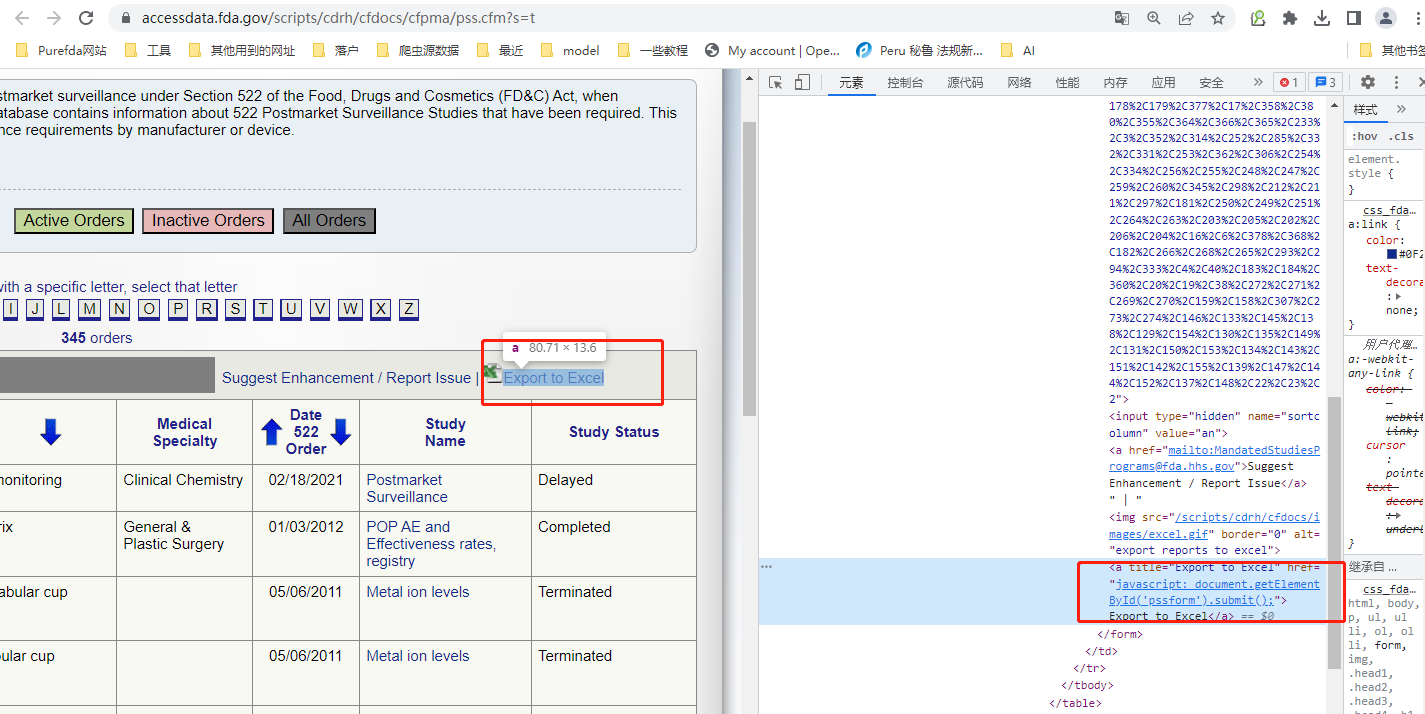

如上图,点击Export to Excel 就会下载一个Exce文件,但是当我们查看元素时,,并没有excel的url。查看网络的文档时,也没有excel的url
这是我们清空网络的页面,重新点击页面的Export to Excel 按钮,就会出现三个响应文件 ,并下载了一个excel文件。逐个分析,




如果我们不知道载荷第一个的长串怎么得到,可以复制,到主页面搜索。找到之后可以用xpath拿到。

最终代码如下
import requests from lxml import etree import pandas as pd request_url = 'https://www.accessdata.fda.gov/scripts/cdrh/cfdocs/cfpma/pss.cfm?s=t' data_url = 'https://www.accessdata.fda.gov/scripts/cdrh/cfdocs/cfpma/pss_Excel.cfm' headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Safari/537.36' } def get_cookies_id(): r = requests.get(request_url) selector = etree.HTML(r.text) id = selector.xpath('//*[@id="pssform"]/input[1]/@value')[0] return id data = { 'ID': '%s' % get_cookies_id(), 'sortcolumn': 'an' } r = requests.post(url=data_url, headers=headers, data=data) d = r.text.split('\r\n') list_data = [] for i in d: tmp_list = i.split(",") if tmp_list != ['']: list_data.append(tmp_list) dict_data = [] key_list = list_data[0] for i in range(len(list_data)): if i != 0: dict_data.append(dict(zip(key_list, list_data[i]))) content = pd.DataFrame(dict_data)

