
测试网站1:http://www.msxindl.com/tools/unicode16.asp
如 \ud83d\udc15 从Unicode还原 是一只🐕
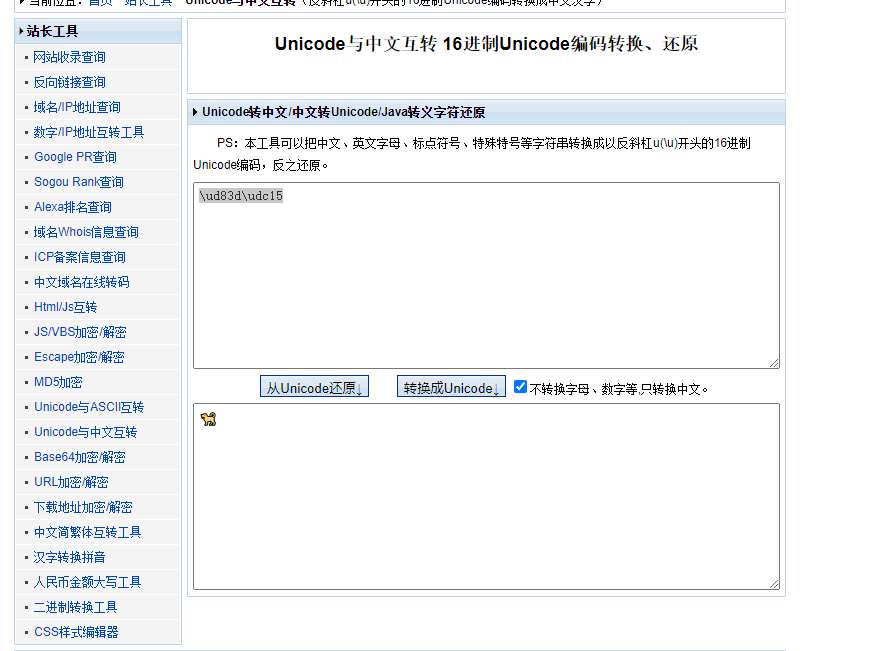
测试网站2:https://www.toolhelper.cn/EncodeDecode/EncodeDecode

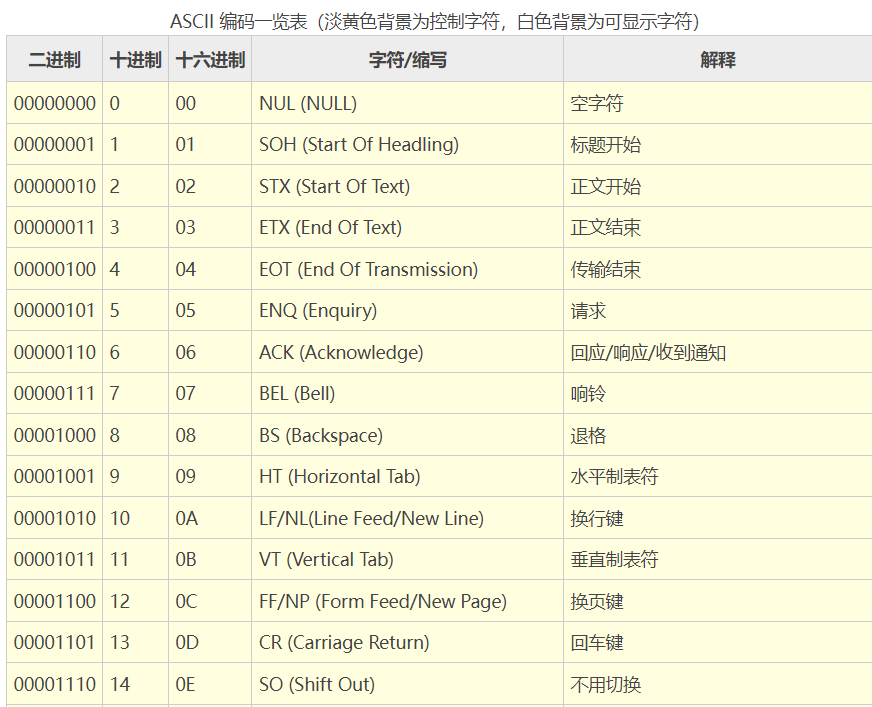
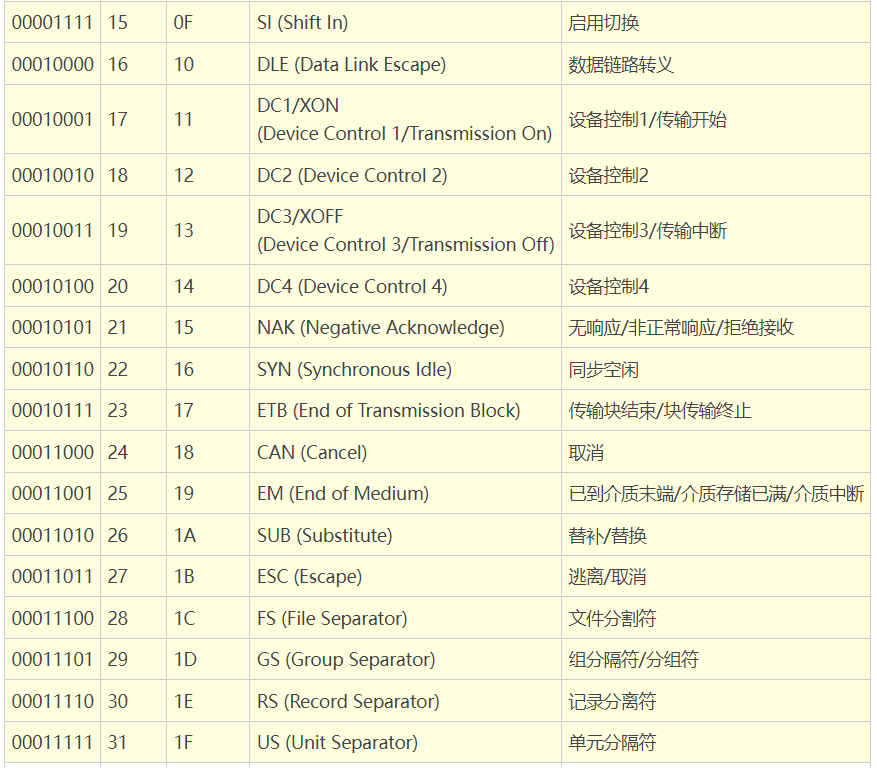
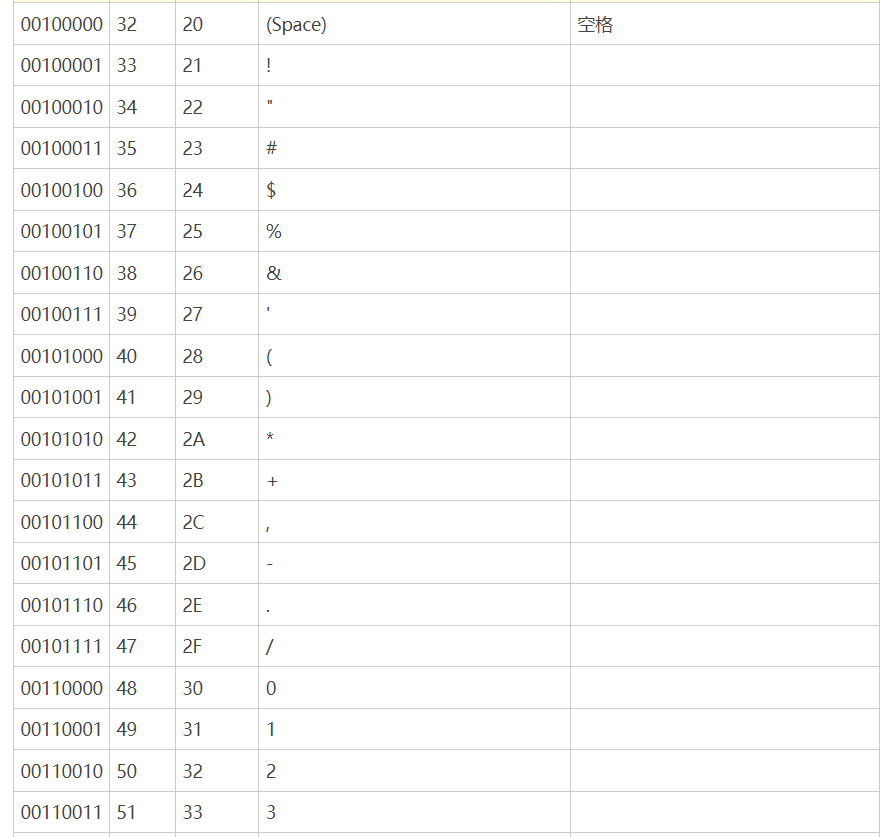
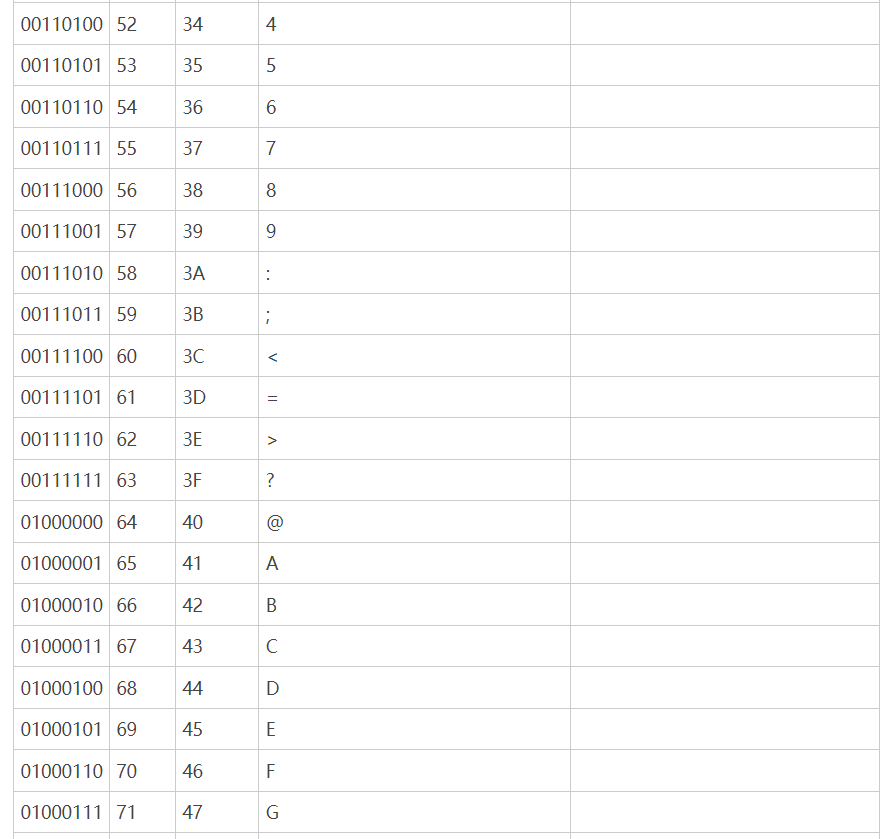
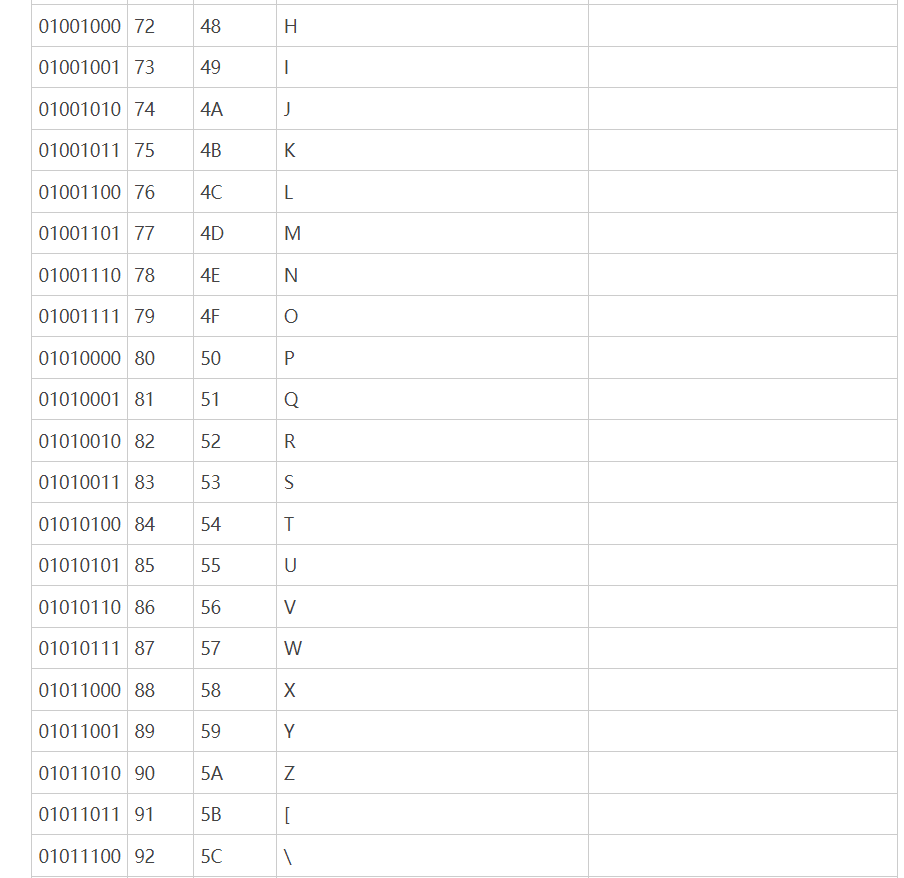
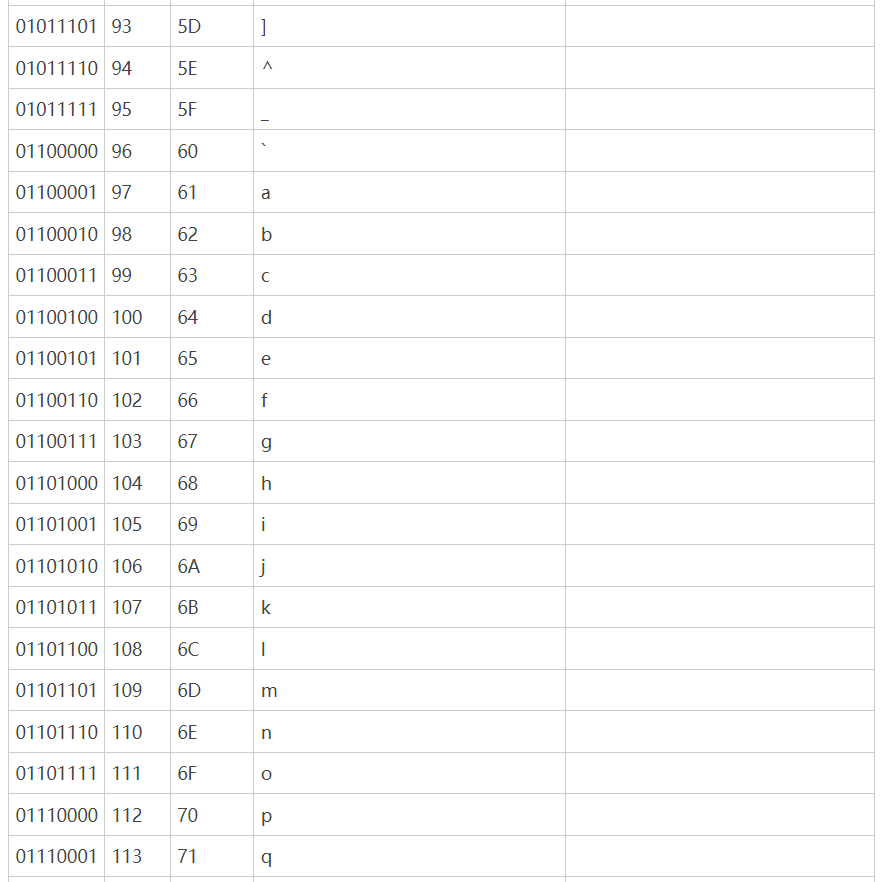
链接:http://c.biancheng.net/c/ascii/
2、
扩展的ASCII码
原本的ASCII码对于英文语言的国家是够用了,但是欧洲国家的一些语言会有拼音,这时7个字节就不够用了。因此一些欧洲国家就决定,利用字节中闲置的最高位编入新的符号。比如,法语中的é的编码为130(二进制10000010)。这样一来,这些欧洲国家使 用的编码体系,可以表示最多256个符号。但这时问题也出现了:不同的国家有不同的字母,因此,哪怕它们都使用256个符号的编码方式,代表的字母却不一样。比如,130在法语编码 中代表了é,在希伯来语编码中却代表了字母Gimel (ג),在俄语编码中又会代表另一个符号。但是不管怎样,所有这些编码方式中,0—127表示的符号是一样的,不一样的只是128—255的这一段。这个问题就直接促使了Unicode编码的产生。
3、
Unicode符号集
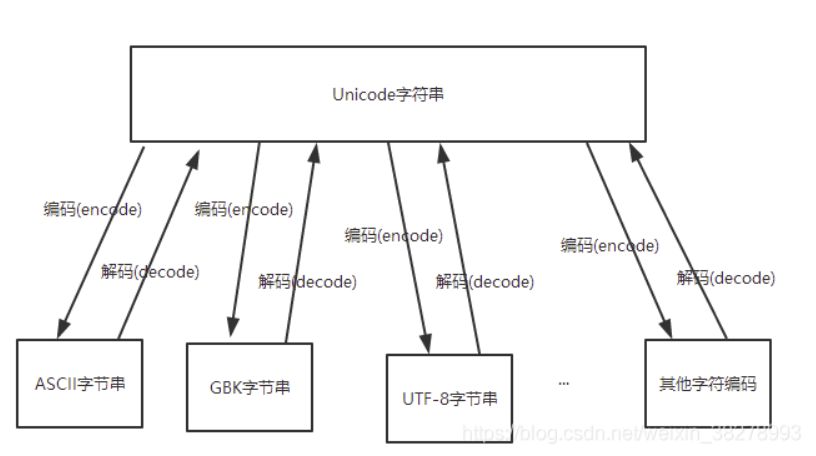
正如上一节所说,世界上存在着多种编码方式,同一个二进制数字可以被解释成不同的符号。因此,要想打开一个文本文件,就必须知道它的编码方式,否则用错误的编码方式解读,就会出现乱码。为什么电子邮件常常出现乱码?就是因为发信人和收信人使用的编码方式不一样。而Unicode就是这样一种编码:它包含了世界上所有的符号,并且每一个符号都是独一无二的。比如,U+0639表示阿拉伯字母Ain,U+0041表示英语的大写字母A,U+4E25表示汉字“严”。具体的符号对应表,可以查询unicode.org,或者专门的汉字对应表 。很多人都说Unicode编码,但其实Unicode是一个符号集(世界上所有符号的符号集),而不是一种新的编码方式。
但是正因为Unicode包含了所有的字符,而有些国家的字符用一个字节便可以表示,而有些国家的字符要用多个字节才能表示出来。即产生了两个问题:第一,如果有两个字节的数据,那计算机怎么知道这两个字节是表示一个汉字呢?还是表示两个英文字母呢?第二,因为不同字符需要的存储长度不一样,那么如果Unicode规定用2个字节存储字符,那么英文字符存储时前面1个字节都是0,这就大大浪费了存储空间。
上面两个问题造成的结果是:1)出现了unicode的多种存储方式,也就是说有许多种不同的二进制格式,可以用来表示unicode。2)unicode在很长一段时间内无法推广,直到互联网的出现。
Unicode码表及说明 :
https://blog.csdn.net/hherima/article/details/9045765
http://www.tamasoft.co.jp/en/general-info/unicode.html
随便找一个,前面加上/u

4、Utf-8
在所有字符集中,最知名的可能要数被称为ASCII的8位字符集了。它是美国标准信息交换代码(American Standard Code for Information Interchange)的缩写, 为美国英语通信所设计。它由128个字符组成,包括大小写字母、数字0-9、标点符号、非打印字符(换行符、制表符等4个)以及控制字符(退格、响铃等)组成。其中有一种通常被称为IBM字符集,它把值为128-255之间的字符用于画图和画线,以及一些特殊的欧洲字符。另一种8位字符集是ISO 8859-1Latin 1,也简称为ISOLatin-1。它把位于128-255之间的字符用于拉丁字母表中特殊语言字符的编码,也因此而得名。
5、

 浙公网安备 33010602011771号
浙公网安备 33010602011771号