
原文 :https://blog.csdn.net/milton2017/article/details/54406482/
python 把几个DataFrame合并成一个DataFrame——merge,append,join,conca
pandas provides various facilities for easily combining together
Series, DataFrame, and Panel objects with various kinds of set logic for
the indexes and relational algebra functionality in the case of join /
merge-type operations.
1、merge
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=('_x', '_y'), copy=True, indicator=False)
left︰ 对象
right︰ 另一个对象
on︰ 要加入的列 (名称)。必须在左、 右综合对象中找到。如果不能通过 left_index 和 right_index 是假,将推断 DataFrames 中的列的交叉点为连接键
left_on︰ 从左边的综合使用作为键列。可以是列名或数组的长度等于长度综合
right_on︰ 从正确的综合,以用作键列。可以是列名或数组的长度等于长度综合
left_index︰ 如果为 True,则使用索引 (行标签) 从左综合作为其联接键。在与多重 (层次) 的综合,级别数必须匹配联接键从右综合的数目
right_index︰ 相同用法作为正确综合 left_index
how︰ 之一 '左','右','外在'、 '内部'。默认为内部。每个方法的更详细说明请参阅︰
sort︰ 综合通过联接键按字典顺序对结果进行排序。默认值为 True,设置为 False将提高性能极大地在许多情况下
suffixes︰ 字符串后缀并不适用于重叠列的元组。默认值为 ('_x','_y')。
copy︰ 即使重新索引是不必要总是从传递的综合对象,复制的数据 (默认值True)。在许多情况下不能避免,但可能会提高性能 / 内存使用情况。可以避免复制上述案件有些病理但尽管如此提供此选项。
indicator︰ 将列添加到输出综合呼吁 _merge 与信息源的每一行。_merge 是绝对类型,并对观测其合并键只出现在 '左' 的综合,观测其合并键只会出现在 '正确' 的综合,和两个如果观察合并关键发现在两个 right_only left_only 的值。
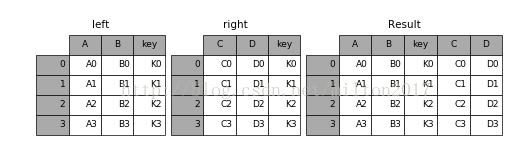
1.result = pd.merge(left, right, on='key')
2.result = pd.merge(left, right,on=['key1', 'key2'])
3.result = pd.merge(left, right, how='left', on=['key1', 'key2'])
4.result = pd.merge(left, right, how='right', on=['key1', 'key2'])
5.result = pd.merge(left, right, how='outer', on=['key1', 'key2'])
2、append
1.result = df1.append(df2)

2.result = df1.append(df4)
3.result = df1.append([df2, df3])
4.result = df1.append(df4, ignore_index=True)
4、join
left.join(right, on=key_or_keys)
pd.merge(left, right, left_on=key_or_keys, right_index=True,
how='left', sort=False)
1.result = left.join(right, on='key')

2.result = left.join(right, on=['key1', 'key2'])
3.result = left.join(right, on=['key1', 'key2'], how='inner')
4、concat
pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False,
copy=True)
objs︰ 一个序列或系列、 综合或面板对象的映射。如果字典中传递,将作为键参数,使用排序的键,除非它传递,在这种情况下的值将会选择 (见下文)。任何没有任何反对将默默地被丢弃,除非他们都没有在这种情况下将引发 ValueError。
axis: {0,1,...},默认值为 0。要连接沿轴。
join: {'内部'、 '外'},默认 '外'。如何处理其他 axis(es) 上的索引。联盟内、 外的交叉口。
ignore_index︰ 布尔值、 默认 False。如果为 True,则不要串联轴上使用的索引值。由此产生的轴将标记 0,...,n-1。这是有用的如果你串联串联轴没有有意义的索引信息的对象。请注意在联接中仍然受到尊重的其他轴上的索引值。
join_axes︰ 索引对象的列表。具体的指标,用于其他 n-1 轴而不是执行内部/外部设置逻辑。
keys︰ 序列,默认为无。构建分层索引使用通过的键作为最外面的级别。如果多个级别获得通过,应包含元组。
levels︰ 列表的序列,默认为无。具体水平 (唯一值) 用于构建多重。否则,他们将推断钥匙。
names︰ 列表中,默认为无。由此产生的分层索引中的级的名称。
verify_integrity︰ 布尔值、 默认 False。检查是否新的串联的轴包含重复项。这可以是相对于实际数据串联非常昂贵。
副本︰ 布尔值、 默认 True。如果为 False,请不要,不必要地复制数据。
1.frames = [df1, df2, df3]
2.result = pd.concat(frames)

3.result = pd.concat(frames, keys=['x', 'y', 'z'])
4.result.ix['y']
A B C D
4 A4 B4 C4 D4
5 A5 B5 C5 D5
6 A6 B6 C6 D6
7 A7 B7 C7 D7
5.result = pd.concat([df1, df4], axis=1)
6.result = pd.concat([df1, df4], axis=1, join='inner')
7.result = pd.concat([df1, df4], axis=1, join_axes=[df1.index])
8.result = pd.concat([df1, df4], ignore_index=True)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号