
[优化] 数据库优化基础
一、主题
大数据下,如何优化数据库才能使系统的性能有较好的提升。
改善数据库的结构有两种:
一种是采用存储过程代替普通的SQL语句或者优化低效率的SQL语句
另外一种就是使用数据库系统中增强索引和规划分区表进行优化
二、阅读结构
|-数据库优化 |-数据库分库分表 |-垂直切分 |-水平切分 |-数据库分区 |-垂直分区 |-水平分区 |-读写分离 |-主主 |-主从
三、数据库分库分表
1、什么是分库分表?
把原本存储于一个库的数据分块存储到多个库上
把原本存储于一个表的数据分块存储到多个表上
2、为什么要分库分表?
性能瓶颈+存储瓶颈
一方面,数据库中的数据量不一定是可控的,在未进行分库分表的情况下,随着时间和业务的发展,库中的表会越来越多,表中的数据量也会越来越大。 相应地,数据操作,增删改查的开销也会越来越大;
另一方面,由于无法进行分布式式部署,而一台服务器的资源(CPU、磁盘、内存、IO等)是有限的,最终数据库所能承载的数据量、数据处理能力都将遭遇瓶颈。
3、如何实现分库分表?
(1)垂直切分 将表按照业务逻辑、功能模块、关系密切程度划分出来,部署到不同的库上。 例如: 一个C2C系统可以划分为 系统定义数据库SystemDB 商品数据库GoodsDB 用户数据库UserDB 日志数据库LogDB 分别用于存储项目数据定义表、商品定义表、用户数据表、日志数据表等
(2)水平切分 当一个表中的数据量过大时,我们可以按照某种规则,比如散列userid,将表的数据划分到不同的数据库,但不同数据库中的表的结构一样。 例如: 数据表的数据根据userid的奇偶来确定数据的划分。 把id为奇数的放到A库的表user,为偶数的放B库表user。 这样通过userId就可以知道用户的博客的数据在哪个数据库。 还可以可以根据userId%10来处理。或者根据著名的HASH算法来处理。
(3)如何抉择?
应该使用哪一种方式来实施数据库分库分表,这要看数据库中数据量的瓶颈所在,并综合项目的业务类型进行考虑。
如果数据库是因为表太多而造成海量数据,并且项目的各项业务逻辑划分清晰、低耦合,那么规则简单明了、容易实施的垂直切分必是首选。
而如果数据库中的表并不多,但单表的数据量很大、或数据热度很高,这种情况之下就应该选择水平切分,水平切分比垂直切分要复杂一些,它将原本逻辑上属于一体的数据进行了物理分割,除了在分割时要对分割的粒度做好评估,考虑数据平均和负载平均,后期也将对项目人员及应用程序产生额外的数据管理负担。
在现实项目中,往往是这两种情况兼而有之,这就需要做出权衡,甚至既需要垂直切分,又需要水平切分。首先按业务逻辑对数据库进行垂直切分,然后,再针对一部分表,通常是用户数据表,进行水平切分。
4、分库分表存在的问题
1)事务问题 在执行分库分表之后,由于数据存储到了不同的库上,数据库事务管理出现了困难。 如果依赖数据库本身的分布式事务管理功能去执行事务,将付出高昂的性能代价; 如果由应用程序去协助控制,形成程序逻辑上的事务,又会造成编程方面的负担。 2)跨库跨表的join问题 在执行了分库分表之后,难以避免会将原本逻辑关联性很强的数据划分到不同的表、不同的库上。 这时,表的关联操作将受到限制,我们无法join位于不同分库的表,也无法join分表粒度不同的表。
结果原本一次查询能够完成的业务,可能需要多次查询才能完成。 3)额外的数据管理负担和数据运算压力 额外的数据管理负担,最显而易见的就是数据的定位问题和数据的增删改查的重复执行问题,这些都可以通过应用程序解决,但必然引起额外的逻辑运算。 例如,对于一个记录用户成绩的用户数据表userTable,业务要求查出成绩最好的100位。 在进行分表之前,只需一个order by语句就可以搞定。 但是在进行分表之后,将需要n个order by语句,分别查出每一个分表的前100名用户数据,然后再对这些数据进行合并计算,才能得出结果。
四、数据库分区
请务必把数据库分区和分表两个概念区分开来!
分表是把一张表分成N多个小表,可能分散在不同的数据库上。当一张表分成很多表后,每一个小表都是完正的一张表,都对应三个文件,一个.MYD数据文件,.MYI索引文件,.frm表结构文件。
分区是把一张表的数据分成N多个区块,这些区块可以在同一个磁盘上,也可以在不同的磁盘上。一张大表进行分区后,他还是一张表,不会变成二张表,但是他存放数据的区块变多了。
1、什么是分区?
分区基于数据表。是表中的某一段。 当表中的数据量不断增大,查询数据的速度就会变慢,应用程序的性能就会下降,这时就应该考虑对表进行分区。 表进行分区后,逻辑上表仍然是一张完整的表,只是将表中的数据在物理上存放到多个表空间(物理文件上),这样查询数据时,不至于每次都扫描整张表。 如:login_record表现在有一千万条数据,按照每个分区一百万的标准,需要划分10个分区。 0000001-1000000(第1个分区:一百万条数据) 1000000-2000000(第2个分区:一百万条数据) ... 9000000-10000000(第10个分区:一百万条数据) 当检索到 2001110 这条数据的时候,就可以定位到第三个分区进行检索。
2、为什么需要分区?
提高检索效率。
将表、索引或索引组织表进一步细分为段(分区),这些段既可进行集体管理,也可单独管理。
从应用程序的角度来看,分区后的表与非分区表完全相同,使用 SQL DML 命令访问分区后的表时,无需任何修改。
但是却可以提高数据库的读写性能和读写效率
一方面分区把一大块数据分成了n小块,这样查询的时候很快定位到某一小块上,在小块中寻址要快很多;
另一方面CPU比磁盘IO快很多倍,而硬件上又有多个磁盘,或者是RAID(廉价磁盘冗余阵列),可以让数据库驱动CPU同时去读写不同的磁盘,这样才有可能可以提高效率。
3、如何分区?用什么字段做分区?
主要分为水平分区和垂直分区。
如何分区和涉及的业务有关系,要看业务上最经常的写入和读取操作是什么,然后再考虑分区的策略。 1)垂直分区(按列分区) 将原始表分成多个只包含较少列的表。 2)水平分区(按行分区) 将表分为多个表。每个表包含的列数相同,但是行更少。 例如:可以将一个包含十亿行的表水平分区成12个表,每个小表表示特定年份内一个月或几个月的数据。任何需要特定月份数据的查询只需引用相应月份的表。 水平分区策略如下: A 范围分区 范围分区将数据基于范围映射到每一个分区,这个范围是你在创建分区时指定的分区键决定的。这种分区方式是最为常用的,并且分区键经常采用日期。举个例子:你可能会将销售数据按照月份进行分区。 B 列表分区 该分区的特点是某列的值只有几个,基于这样的特点我们可以采用列表分区。 C 散列分区 这类分区是在列值上使用散列算法,以确定将行放入哪个分区中。当列的值没有合适的条件时,建议使用散列分区。 散列分区为通过指定分区编号来均匀分布数据的一种分区类型,因为通过在I/O设备上进行散列分区,使得这些分区大小一致。 hash分区最主要的机制是根据hash算法来计算具体某条纪录应该插入到哪个分区中,hash算法中最重要的是hash函数,Oracle中如果你要使用hash分区,只需指定分区的数量即可。建议分区的数量采用2的n次方,这样可以使得各个分区间数据分布更加均匀。 D 组合范围散列分区 这种分区是基于范围分区和列表分区,表首先按某列进行范围分区,然后再按某列进行列表分区,分区之中的分区被称为子分区。 E 复合范围散列分区 这种分区是基于范围分区和散列分区,表首先按某列进行范围分区,然后再按某列进行散列分区。
4、多大的数据量才需要分区?
表的大小超过2GB
表中包含历史数据,新的数据被增加到新的分区中
5、优缺点
优点: 1、改善查询性能:对分区对象的查询可以仅搜索自己关心的分区,提高检索速度。 2、增强可用性:如果表的某个分区出现故障,表在其他分区的数据仍然可用; 3、维护方便:如果表的某个分区出现故障,需要修复数据,只修复该分区即可; 4、均衡I/O:可以把不同的分区映射到磁盘以平衡I/O,改善整个系统性能。 缺点: 分区表相关:已经存在的表没有方法可以直接转化为分区表。 不过 Oracle 提供了在线重定义表的功能。
6、mysql如何分区?oracle如何分区?sql server 如何分区?用什么字段做分区?
sqlserver:http://blog.csdn.net/lgb934/article/details/8662956 oracle:http://blog.csdn.net/kadwf123/article/details/7950025 mysql:http://www.2cto.com/database/201503/380096.html
下面利用mysql分区例子来说明mysql如何执行分区操作
(1)查看数据库是否支持分区
对于mysql来讲,现阶段支持分区操作的版本有5.1和5.5 SHOW VARIABLES LIKE '%partition%'; 显示为YES则表明该数据库支持分区操作。
(2)创建四种类型的分区
RANGE分区:范围分区
- 根据表的字段的值,依据给定某段连续的区间来分区。 #创建teacher表,并在创建teacher表同时根据birthdate字段将表划分为p1、p2、p3三个分区。 create table teacher( id varchar(20) not null , name varchar(20), age varchar(20), birthdate date not null, salary int ) partition by range(year(birthdate))( partition p1 values less than (1970), partition p2 values less than (1990), partition p3 values less than maxvalue ); #创建表后分区 ALTER TABLE teacher partition by range(year(birthdate))( partition p1 values less than (1970), partition p2 values less than (1990), partition p3 values less than maxvalue );
LIST分区:列表分区
- 其实list分区和range分区应该说都是一样的,不同的是range分区在分区是的依据是一段连续的区间;而list分区针对的分区依据是一组分布的散列值。需要注意的是一般情况下,针对表的分区字段为int等数值类型。 create table student( id varchar(20) not null , studentno int(20) not null, name varchar(20), age varchar(20) ) partition by list(studentno)( partition p1 values in (1,2,3,4), partition p2 values in (5,6,7,8), partition p3 values in (9,10,11) );
HASH分区:哈希分区 - 依据表的某个字段以及指定分区的数量。 比较有限制的就是需要知道表的数据有多少才能更好平均分配分区。 #创建user表,并将user表平均分为十个分区。 create table user ( id int(20) not null, role varchar(20) not null, description varchar(50) ) partition by hash(id) partitions 10;
KEY分区 - 类似于按HASH分区,区别在于KEY分区只支持计算一列或多列,且MySQL服务器提供其自身的哈希函数。 必须有一列或多列包含整数值。 create table role( id int(20) not null,name varchar(20) not null) partition by linear key(id) partitions 10;
(3)管理分区表
#对指定表添加分区 alter table user add partition(partition p4 values less than MAXVALUE); #删除指定表指定分区 alter table student drop partition p1; #创建子分区 create table role_subp(id int(20) not null,name int(20) not null) partition by list(id) subpartition by hash(name) subpartitions 3 ( partition p1 values in(10), partition p2 values in(20) ) #合并分区 alter table user reorganize partition p1,p3 into (partition p1 values less than (1000));
注意:数据多并不是创建分区表的惟一条件,哪怕你有一千万条记录,但是这一千万条记录都是常用的记录,那么最好也不要使用分区表,说不定会得不偿失。只有你的数据是分段的数据,那么才要考虑到是否需要使用分区表。比如数据是按时间段进行查询的(常见于报表统计),可以考虑分区。
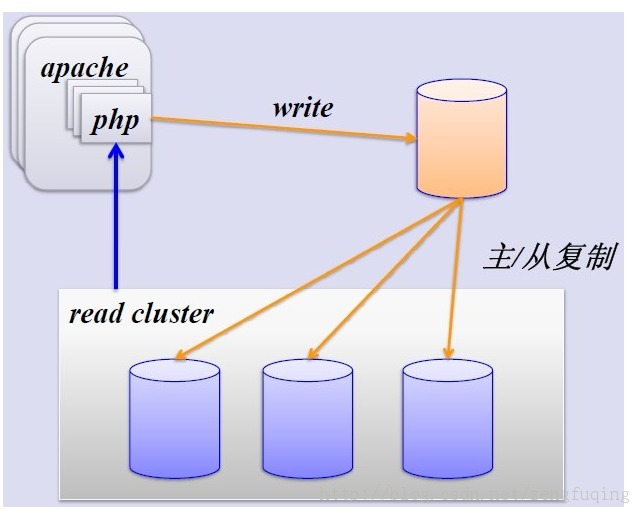
五、数据库集群与主主、主从分离
1、集群
在多台机器上安装数据库,然后安装些代理。
这些数据库之间没有主从的区别,都是平等的节点。
2、主主分离和主从分离
一个数据库可以做主数据库,可以做从数据库,也可以同时担当主数据库和从数据库两个角色。
下面通过一些例子来说明。
(1)主主模式:本身是自己的master ,又是彼此的slave。
#第一台主服务器 - 10.0.106.1 #注意看--master首先是做为master启动,并且同时还有第二个身份就是10.0.106.2的slave mkdir -p /usr/mongodb/data/ #放数据文件的目录 mkdir -p /usr/mongodb/log/ #放日志文件的目录 mongod --dbpath=/usr/mongodb/data/ --logpath=/usr/mongodb/log/mongodb.log --master --slave --source 10.0.106.2:27017 #第二台主服务器 - 10.0.106.2 #注意看--master首先是做为master启动,并且同时还有第二个身份就是10.0.106.1的slave mkdir -p /usr/mongodb/data/ #放数据文件的目录 mkdir -p /usr/mongodb/log/ #放日志文件的目录 mongod --dbpath=/usr/mongodb/data/ --logpath=/usr/mongodb/log/mongodb.log --master --slave --source 10.0.106.1:27017
(2)主从模式
master:10.0.106.31
slave:10.0.106.131
【第一步:配置主服务器 - 10.0.106.31】 #创建主服务器 #--master是表示做为主启动 mkdir -p /usr/mongodb/data/ #放数据文件的目录 mkdir -p /usr/mongodb/log/ #放日志文件的目录 mongod --dbpath=/usr/mongodb/data/ --logpath=/usr/mongodb/log/mongodb.log --master #查看日志 tail -f /usr/mongodb/log/mongodb.log #进入mongo命令行模式 查看主从复制状态 默认连接到了test库,想指定库就use 库名; #是否是master > rs.isMaster() { "ismaster" : true, #是 "maxBsonObjectSize" : 16777216, "maxMessageSizeBytes" : 48000000, "localTime" : ISODate("2013-10-18T03:09:22.863Z"), "ok" : 1 } #查看replica信息 下面看slave时,就知道区别了 > db.printReplicationInfo(); configured oplog size: 1435.5470703125002MB log length start to end: 716secs (0.2hrs) oplog first event time: Fri Oct 18 2013 11:03:20 GMT+0800 (CST) oplog last event time: Fri Oct 18 2013 11:15:16 GMT+0800 (CST) now: Fri Oct 18 2013 11:15:24 GMT+0800 (CST)
【第二步:配置从服务器 - 10.0.106.131】 #创建从服务器 #注意:--slave --source 10.0.106.31:27017 指定了类型是slave并指定了主的ip:port mkdir -p /usr/mongodb/data/ mkdir -p /usr/mongodb/log/ mongod --dbpath=/usr/mongodb/data/ --logpath=/usr/mongodb/log/mongodb.log --slave --source 10.0.106.31:27017 #查看日志 tail -f /usr/mongodb/log/mongodb.log #查看主从复制状态 > rs.isMaster() { "ismaster" : false, "maxBsonObjectSize" : 16777216, "maxMessageSizeBytes" : 48000000, "localTime" : ISODate("2013-10-18T03:16:27.310Z"), "ok" : 1 } > db.printReplicationInfo();db.printReplicationInfo(); this is a slave, printing slave replication info. source: 10.0.106.31:27017 syncedTo: Fri Oct 18 2013 11:16:06 GMT+0800 (CST) = 41 secs ago (0.01hrs)
【最后,主从模式建立完成,测试】 在10.0.106.31(主)建立张一表 > db.wocao.insert({'name':'tompig'}); db.wocao.insert({'name':'tompig'}); > show collections; system.indexes wocao 去10.0.106.131(从)看一下是否也有,如果有则成功,没有则说明我们的主从设置得不成功。 > show collections; system.indexes wocao #过来了 > db.printReplicationInfo(); this is a slave, printing slave replication info. source: 10.0.106.31:27017 syncedTo: Fri Oct 18 2013 11:51:10 GMT+0800 (CST) #通过这我们可以看到同步的信息
参考文档
分库分表:http://my.oschina.net/ydsakyclguozi/blog/199498
分区:http://www.iteye.com/problems/67953
主从分离:
图1垂直分库分表
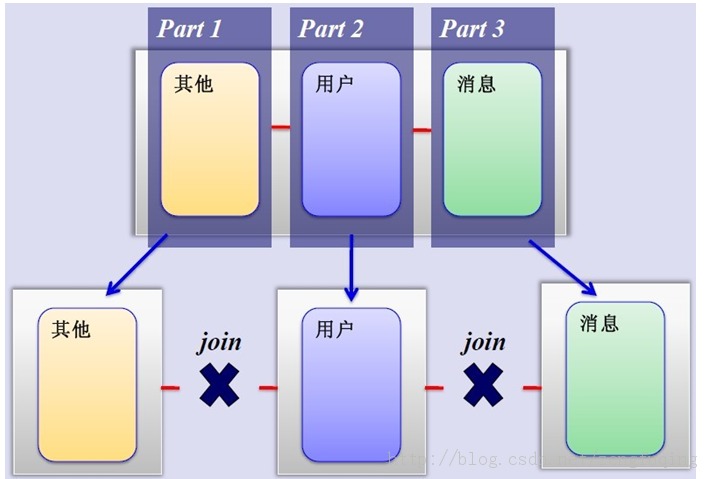
图2 水平分库分表
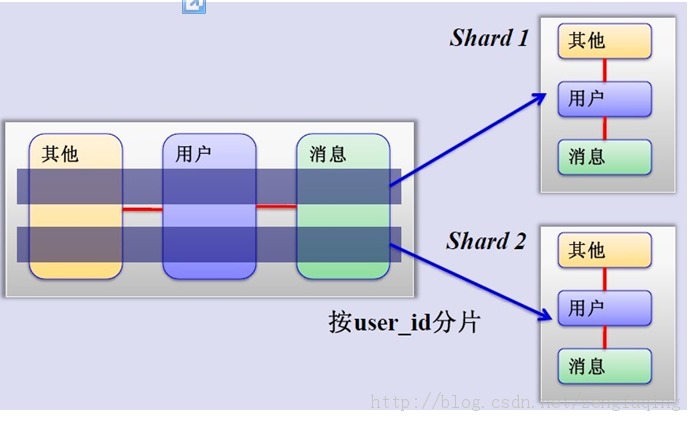
图3 水平分库分表后的数据查找
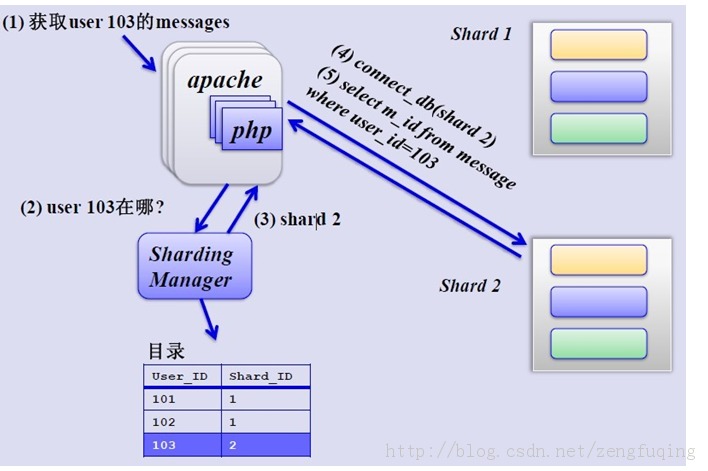
图4 读写分离-主从模式

 浙公网安备 33010602011771号
浙公网安备 33010602011771号