pandas的基本使用
Pandas概述
pandas介绍
- 2008年WesMckinney开发出的库
- 专门用于数据挖掘的开源python库
- 以numpy为基础,接力Numpy模块在计算方面性能高的优势
- 基于matplotlib,能够简便的画图
- 独特数据结构
Pandas的作用
相比于Numpy在处理数据方面的优势,结合matplotlib展示数据,能够解决大多数问题;Pandas的优势在于一下几点:
- 增强图表的可读性
- 便捷的数据处理能力
- 读取文件更加方便
- 对Matplotlib、Numpy的画图和计算进行了封装,使他们更便于使用
Pandas数据结构
Pandas中一共有三种数据结构:一维数据结构Series,二维数据结构DataFrame,三维数据结构MultiIndex。
Series数据类型
Series由一组数据和与之相关的索引组成,类似于Python中的字典。
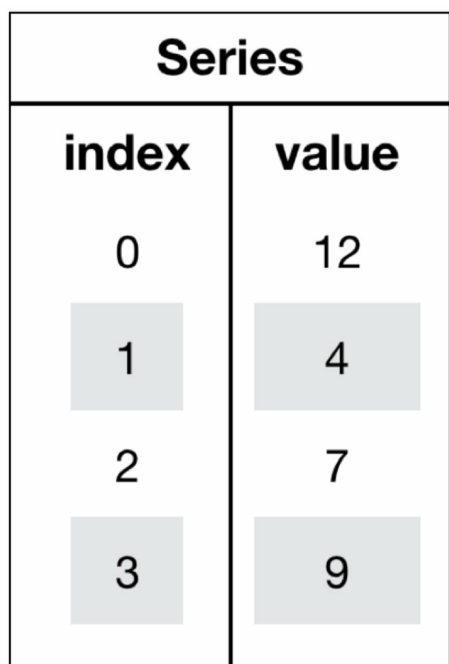
Series的创建
pd.Series(data=,index=,dtype=)
pd.Series(key1:value1, key2:value2, key3:value3,...)
Series的属性
series.index
series.value
DataFrame数据类型
DataFrame是一个类似于二维数组或表格的对象,既有行索引,又有列索引,根据这种存储数据的方式不难看出,DataFrame的操作将类似于关系型数据库。
DataFrame的创建
pd.DataFrame(data=,Index=,columns=)
pd.DataFrame(column1:series1, column2:series2, column3:series3)
DataFrame的属性
dataframe.shape
dataframe.index
dataframe.columns
dataframe.values 这是一张类似于二维结构的ndarray
dataframe.T
dataframe.head(5)
dataframe.tail(5)
DataFrame的索引
dataframe.index = index
dataframe.reset_index(drop = False)
dataframe.set_index(key2,drop=True)
MultiIndex数据类型
MultiIndex(多级索引/层次化索引)是三维的数据结构:
MultiIndex的属性
multindex.levels
multindex.names
MultiIndex的创建
array = [[1, 1, 2, 2], ['red', 'blue', 'red', 'blue']]
pd.MultiIndex.from_arrays(array, names=['num', 'color'])
Pandas基本数据操作
索引操作
Pandas的索引是先列后行的,data['open']['2018-08-08']
dataframe[:, :] 注意,切片的内容必须和索引一致,不存在下标索引。
data.loc[index, columns] 先行后列
data.iloc[num_index, num_columns]
赋值操作
data['close'] = 1
data.close = 10
排序
data.sort_values(by=['open', 'high'], ascending=True)
data.sort_index()
DataFrame运算
算术运算
data['open'].add(1)
data['open'].sub(1)
逻辑运算
data['open'] > 23
data[data['open'] > 23]
data[(data['open']>23)&(data['open']<24)]
data.query('oepn<24&open>23').head()
data['open'].isin([23,53,33,43])
统计运算
decribe
data.describe
统计函数
data.max()
data.var()
data.std()
dataframe.median()
dataframe.idmax()
dataframe.idmin()
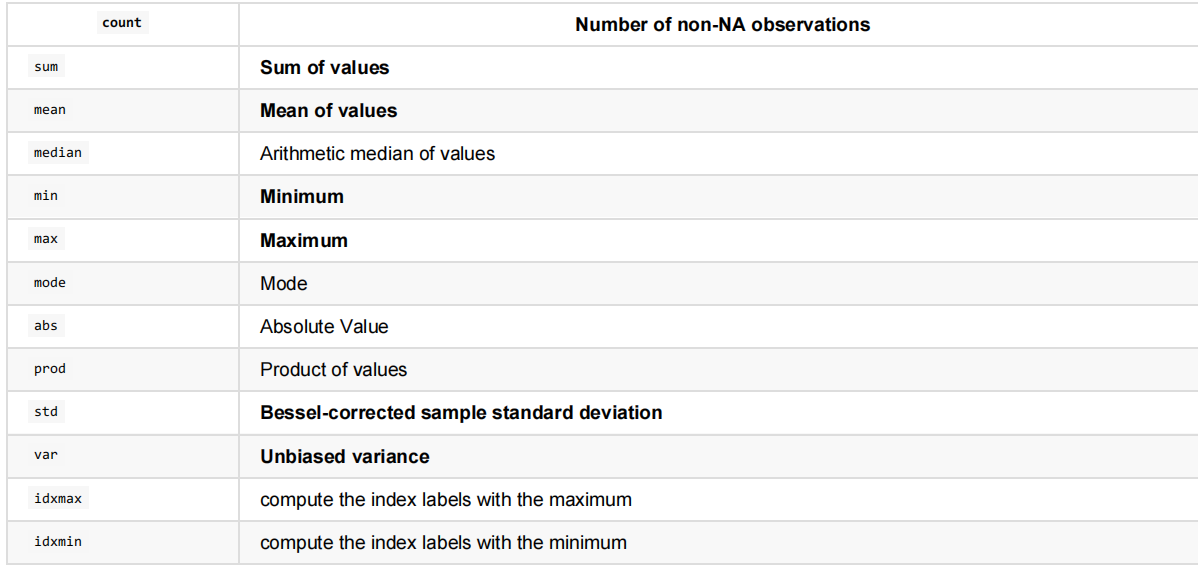
累计统计函数

自定义函数
data[['open', 'close']].apply(lambda x: x.max()- x.min(), axis=0)
Pandas画图
文件的读取与存储
CSV
# pandas.read_csv(filepath_or_buffer, sep=',',usecols)
# filepath_or_buffer:文件路径
# sep:分隔符,默认用“,”隔开
# usecols:指定读取的列名,列表形式
# DataFrame.to_csv(path_or_buf=None, sep=',', columns=None, header=True, index=True, mode='w', encoding=None)
# path_or_buf:文件路径
# sep:分隔符
# columns:选择需要的列索引
# header:boolean or list of string,default True,是否写入列索引值
# index:是否写进行索引
# mode:'w',重写模式;'a',追加模式。
HDF5
# pandas.read_hdf(path_or_buf, key=None, **kwargs)
# path_or_buffer:文件路径
# key:读取的键
# return:The selected object
# DataFrame.to_hdf(path_or_buf, key, **kwargs)
JSON
# JSON是我们常用的一种数据交换格式,前面在前后端的交互经常用到,也会在存储的时候选择这种格式。所以我们需要知道Pandas如何进行读取和存储JSON格式。
# pandas.read_json(path_or_buf=None, orient=None, typ='frame', lines=False)
# 将JSON格式置换成默认的Pandas DataFrame格式
# orient:string,Indication of expected JSON string format.
# orient : string,Indication of expected JSON string format.
# 'split' : dict like {index -> [index], columns -> [columns], data -> [values]}
split 将索引总结到索引,列名到列名,数据到数据。将三部分都分开了
#'records' : list like [{column -> value}, ... , {column -> value}]
records 以 columns:values 的形式输出
# 'index' : dict like {index -> {column -> value}}
index 以 index:{columns:values}... 的形式输出
# 'columns' : dict like {column -> {index -> value}},默认该格式
colums 以 columns:{index:values} 的形式输出
# 'values' : just the values array
values 直接输出值
# lines : boolean, default False
按照每行读取json对象
# typ : default ‘frame’, 指定转换成的对象类型series或者dataframe
-------------------------------------------------- 花有重开日,人无再少年... -----------------------------------------------------

 浙公网安备 33010602011771号
浙公网安备 33010602011771号