一条SQL在内存结构与后台进程工作机制
oracle服务器由数据库以及实例组成,数据库由数据文件,控制文件等物理文件组成,实例是由内存结构+后台进程组成,实例又可以看做连接数据库的方式,在我看来就好比一家公司,实例就是一个决策的办公室,大大小小的决定都要从这个办公室解决。
实例分成内存结构以及后台进程部分。
内存结构主要可以分为:共享池(shared pool),数据库高速缓冲区(data buffer cache),重做日志缓冲区(Redo Log Buffer Cache)。
三大内存池:
共享池(shared pool):用来存放一些共享的资源,比如sql,pl/sql,数据字典一些信息,一条SQL的执行首先在shared pool中进行校验,解析,然后在执行。它主要由两个内存结构区域构成:Library cache和Data dictionary cache,共享池会对执行的sql进行校验,然后解析,最后执行,这里提到两个概念:
硬解析:没有被执行过的sql,会在shared pool中进行校验,然后解析,最后执行
1.查看语法是否错误
2.查看数据字典,检查SQL语句中涉及的对象和列是否存在
3.通过优化器创建一个最佳的执行计划
4.将该游标所产生的执行计划,SQL文本缓存到Library cache的hash中
软解析:将相同的sql存放在library cache中,减少硬解析一个或多个步骤,从而减少大量的资源使用。
所以写sql最好加上变量,减少硬解析,也就减少了IO的开销。
修改共享池的大小:ALTER SYSTEM SET SHARED_POOL_SIZE = 64M;
数据库高速缓冲区(data buffer cache):SGA的一部分,oracle利用buffer cache来管理data block数据块(8k),及用户使用过的数据,比如用户查询到磁盘上的数据就存储在这,修改数据时,同时保存数据库被修改前(前镜像)和修改后(后镜像),避免了对数据文件的直接操作,cache的最终目的还是减少磁盘的IO。一条SQL的执行,首先要将数据文件中的数据提到buffer cache中来修改,然后在buffer cache中修改完,再将这些脏数据写回数据文件中。
工作机制:假设查询到,或者更改的数据都已放在了buffer cache中,buffer cache的存量就那么大,怎么保证buffer cache不断更新呢?cache利用链表来实现数据块的快速定位,一个数据块8K大小,一次读取会有若干个数据块,缓冲区则是利用LRU(最近最少使用)算法来进行清除以前没用过的数据块,一次来释放内存。从而保证了一致性。
脏数据:一条更新sql,需要把数据文件的数据提到内存中来修改,但是还没有写回数据文件,这时在buffer cache中的这些已经更改过的不一致数据就叫做脏数据。
重做日志缓冲区(Redo Log Buffer Cache):记录一些ddl,dml操作的缓冲区,用来缓存对于数据块的所有修改。如果正在执行一条sql语句,在内存中已经修改完成,但是还没有将这些脏数据写进数据文件中,但是断电了,内存中的数据被释放掉了,这些东西就真的没了,但是有了log buffer,他会先记录,将这些操作记录下来,下次重新开机的时候,这些操作内存可以在log buffer中找到,重新执行一遍,相当于数据没有丢,还是保证了数据的一致性。
后台主要五大进程:
dbwn(写进程):顾名意义,oracle中有很多后台进程,写进程是很重要的,就是把脏数据写进磁盘的一个过程。
1.脏数据阈值达到25%时
2.扫描到整个buffer cache没有空闲时
3.ddl,dml操作时
4.表空间脱机
5.热备命令时
这些都会触发dbwn写进程
lgwr(log日志写进程):将log buffer缓冲区中记录的操作写入物理文件,日志文件中去,所以这个操作必须比较快速切频繁才能保证数据的一致性,同时也必须在dbwn操作之前触发lgwr,否则数据文件已经写进去了,日志文件还没有记录是不行的。
1.commit;
2.log buffer达到内存的三分之一时
3.dbwn写进脏数据之前
4.每隔3秒
ckpt(检查点进程):检查点的主要任务就是督促dbwn刷新脏块,也类似一个scn号,记录一个时间点的行为
1.调度数据写
2.会将自己完成的检查点写到数据文件头
3.把已经完成的检查点写进控制文件中
smon(系统进程):system monitior,系统监控,数据库的主进程,系统可以根据smon进程来判断oracle是否启动
1.系统监控管理,定期合并空闲,回收临时段
2.做实例的恢复,前滚,后滚,释放资源
pmon(监控进程):监控其他非核心进程,释放垃圾进程。如果你的进程卡死了,断掉了,pmon会帮你释放挂掉进程占得资源。
一条SQl的执行过程:
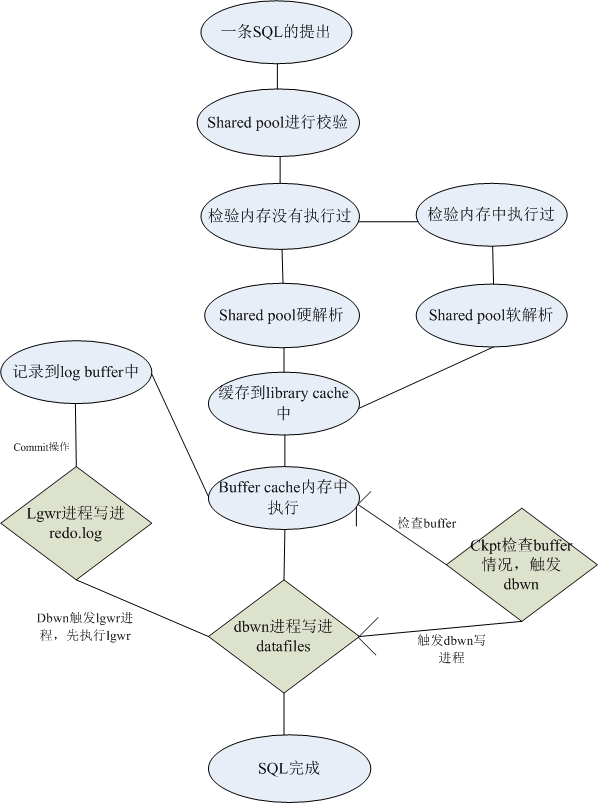

.jpg)

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· DeepSeek在M芯片Mac上本地化部署