需要登陆,请求数据 session
requests中的session模块思路:
# 1. 登录 --> 等到cookie#
2.带着cookie 请求到书架的url-->书架上的内容#
注意:
# 两个操作要连续起来操作
# 我们可以用session进行请求-->session可以连续进行对话,而且我们得到的cookie不会丢失
import requests #第一步:导入模块
#session : 对话
session = requests.session() #第二步:建立会话
data = { #第四步:从浏览器抓包工具中找到data(用户名密码)
"loginName": "juakn1350",
"password": "abc123456"
}
# 1.登录
url = "https://passport.17k.com/ck/user/login" #第三步:打开网页
session.post(url, data=data) #第五步:登录。session:这是我们建立会话的函数, post登录。
#登录成功后下面这两个操作,是没问题的
# print(requ.text) #查看session.po st(url, data=data)是否有响应
# print(requ.cookies) #查看cookie
# 2.拿书架上的数据
# 刚才的session有cookie,所以这次登录我们直接使用session。(不能直接用get登录,get是从新请求,没有cookie的数据,
# 我们需要在get前面加session函数: session.get)
requ = session.get("https://user.17k.com/ck/author/shelf?page=1&appKey=2406394919")
#第六步:在抓包工具中找到我们的包,然后把链接放到这个请求上来。
(这是对网页源代码没有的数据,二次请求的数据处理方式:如下图:)
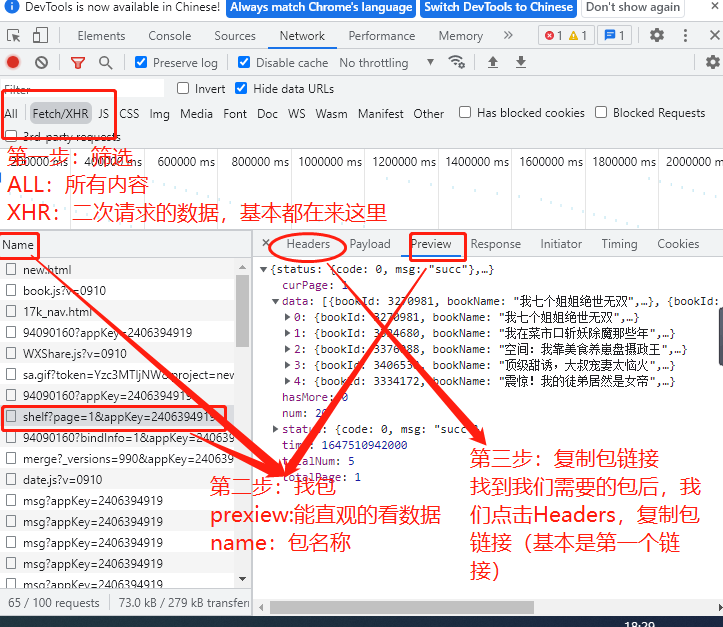
#第八步(可无):乱码解决方法
#content中间存的是字节码,而text中存的是Beautifulsoup根据猜测的编码方式将content内容编码成字符串。
#当我们编码是中文类型(GBK,GB2312等),有时我们直接用text进行解码有时会发生乱码,这是我们需要用字节码的解码函数content.decode('utf-8')
result = requ.content.decode('utf-8') #中文乱码,指定解码
#第七步:输出数据
print(result)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号