

hashmap 1.8原理解析
https://blog.csdn.net/zjxxyz123/article/details/81111627
JDK 8 以前 HashMap 的实现是 数组+链表 很难达到元素百分百均匀分布。
1.8 中引入了红黑树(查找时间复杂度为 O(logn))数组+链表+红黑树
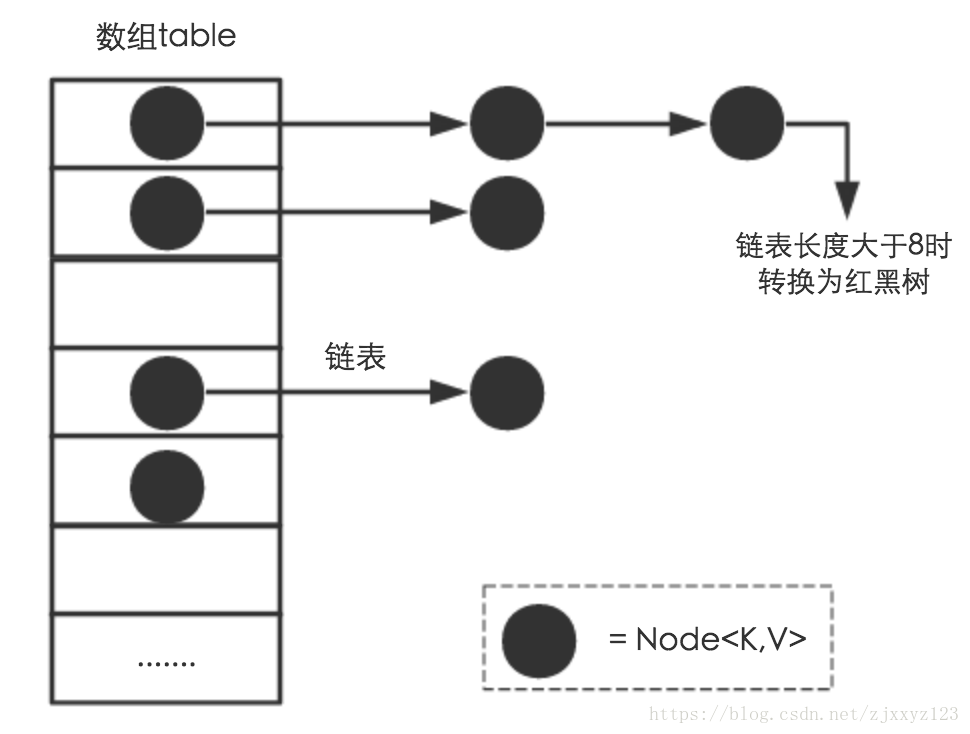
链表节点 Node ,红黑树节点 TreeNode
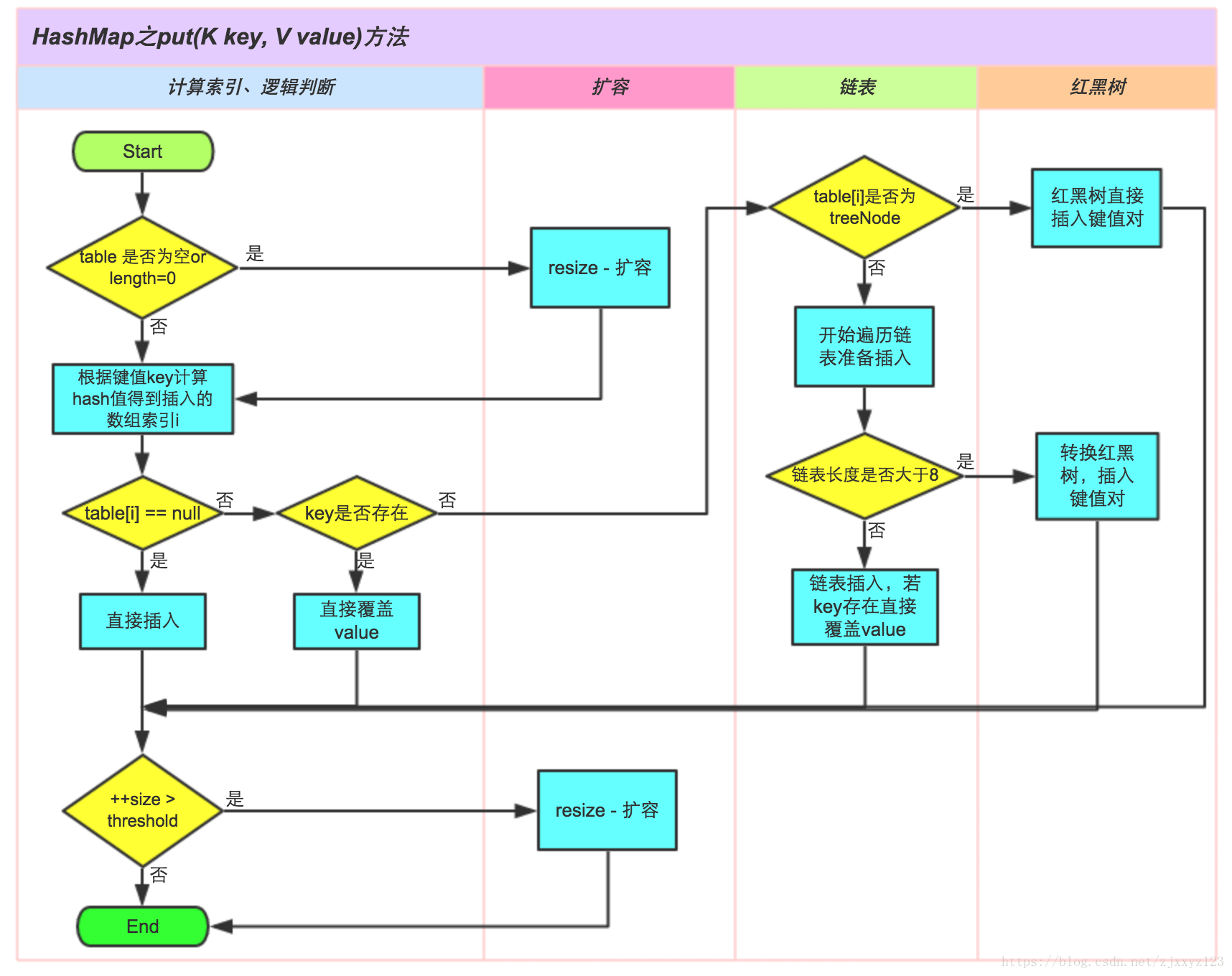
capacity向上取2的n次方,好处可以使用按位与替代取模来提升hash的效率 -> 保证n-1低位全1
装载因子用来衡量HashMap满的程度 size/capacity,而不是占用桶的数量去除以capacity
TREEIFY_THRESHOLD: 树化阈值 8
UNTREEIFY_THRESHOLD :链表化阈值 6
MIN_TREEIFY_CAPACITY :最小树化容量 64
hash
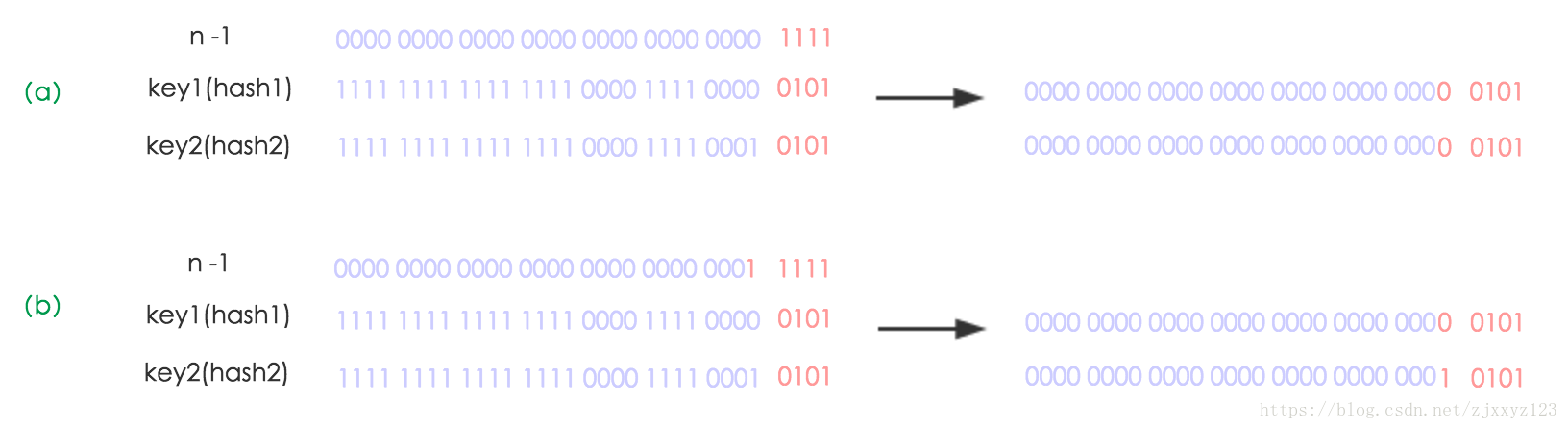
其hash值是key的hashcode与其hashcode右移16位的异或结果 --->由于最终获取下表是对二进制数组最后几位的与操作。所以直接取hash值会丢失高位的数据,从而增大冲突引起的可能. 将高位的16位于低位的16位进行异或操作,即可将高位的信息存储到低位。因此该函数也叫做扰乱函数。 直接使用key的hash算法与扰乱函数的hash算法冲突概率相差10%左右
在put方法中,将取出的hash值与当前的hashmap容量-1进行与运算。得到的就是位桶的下标。
put流程
resize流程
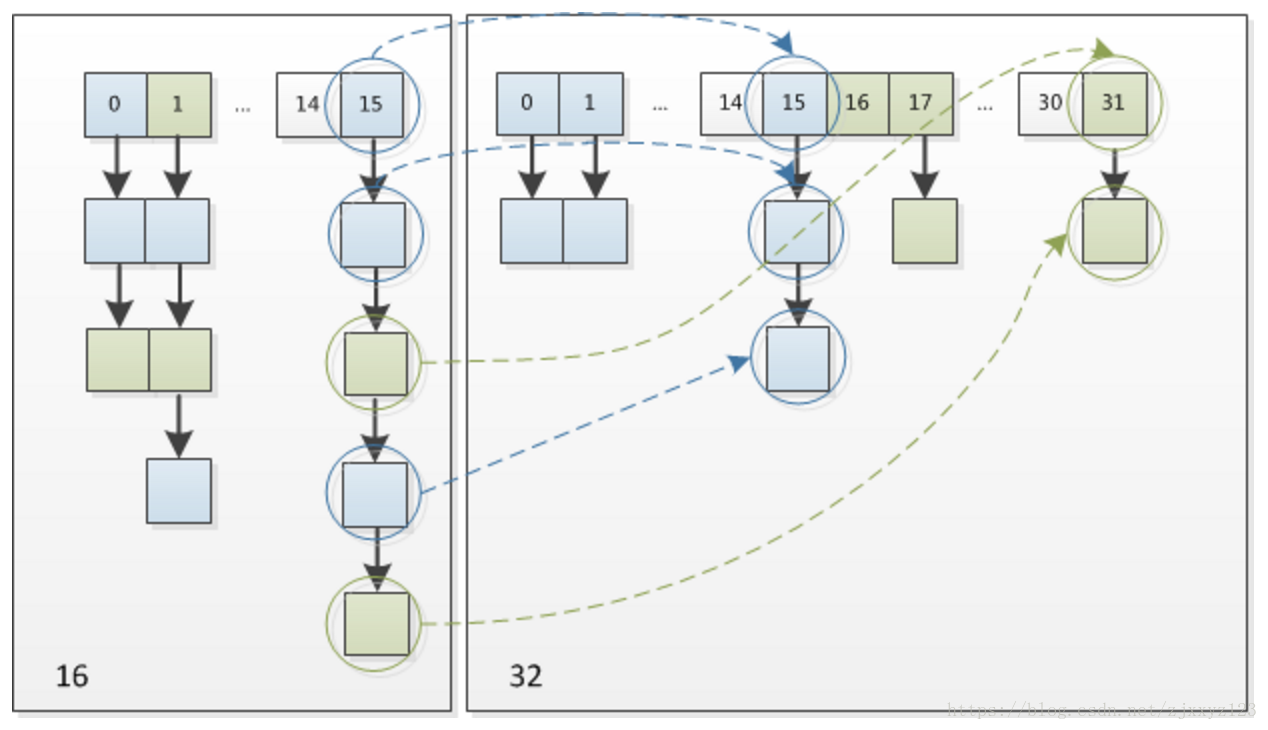
在扩充HashMap的时候,不需要像JDK1.7的实现那样重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变(因为任何数与0与都依旧是0),是1的话index变成“原索引+oldCap”。
32位扩容到64位 其中key1位置不变 key2移到+n的位置上
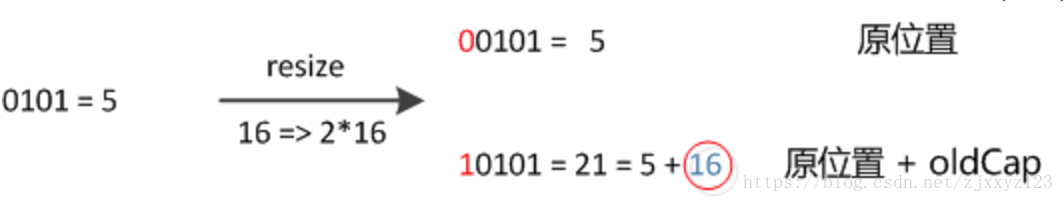
jdk 7 与 jdk 8 中关于HashMap的对比
8时红黑树+链表+数组的形式,当桶内元素大于8时,便会树化
hash值的计算方式不同
1.7 table在创建hashmap时分配空间,而1.8在put的时候分配,如果table为空,则为table分配空间。
在发生冲突,插入链中时,7是头插法,8是尾插法。
在resize操作中,7需要重新进行index的计算,而8不需要,通过判断相应的位是0还是1,要么依旧是原index,要么是oldCap + 原index

