Python基础指北
编码
Python的世界中内存中统一使用Unicode,使用时转换为其他编码,比如网页/文档编辑器


Python3中字符串类型 str 使用Unicode编码,而I/O得到的是字节码 byte,使用内建函数可以相互转换

(python中encode后得到的bytes如果不能用ascii呈现,比如中文encode成bytes,就会显示'\x##')
为了在python中正确使用中文,应该在py文件中声明 # -*- coding: utf-8 -*-,同时在文本编辑器使用utf8进行编辑。
(如说你声称你讲中文,然后blabla讲了一堆韩语,对方的翻译器肯定是)(¥&!)(@*%S%……(@#%)
what's more:
python2中有两种字符串类型
str:字节流
unicode:code point
到了python3,我们使用的类型变成了
str:code point
bytes:字节流
在python2中,不同类型的字符串会隐式转换,在python3中,不会隐式转换。
what to do:
1.在python内部使用unicode,在IO时与bytes转换,对于input的数据decode之,对于要ouput的数据encode之。
2.了解IO得到的bytes数据具体是哪一种encoding方式,是utf8、GBK,还是其它什么。
3.你从第2条得到的信息可能是错的,所以记得测试一下。
list/tuple
list.append(something)
list.insert(position, something)
list.pop([position])
生成器
容器类的大小固定时,一个大的容器类会占据很多空间,尤其当我们只需访问部分内容时,多余的空间就被浪费了,我们可以使用生成器,在遍历的同时生成元素,这就是生成器完成的任务。
获得生成器的方法:
1.使用列表解析我们可以得到一个list,但是将[]换成()就可以得到一个generator,被称为generator expression。
2.yield会成为程序的断点,跳出这个函数,在重入的时候从上次yield断开的地方继续,调用一个包含yield的函数会得到generator,这样的一个函数也被称为generator function,一个__iter__可以是generator function。
生成器支持迭代器的方法,比如next(generator)可以运行至下一个yield,没有yield时调用next会throw StopException,使用for语句遍历将自动catch exception。使用for遍历生成器时会导致yield之后的return被忽略,如果需要这个返回值可以通过捕获异常得到。
def fib(max): n, a, b = 0, 0, 1 while n < max: yield b a, b = b, a + b n = n + 1 return 'done' >>> g = fib(6) >>> while True: ... try: ... x = next(g) ... print('g:', x) ... except StopIteration as e: ... print('Generator return value:', e.value) ... break ... g: 1 g: 1 g: 2 g: 3 g: 5 g: 8 Generator return value: done
for语句遍历一个迭代器的顺序是,调用iter获得迭代器,每次通过调用next直到catch stopException,由于生成器天然支持迭代器的next方法,而又不需要实现__next__,所以往往可以节省大量代码,这里是一个例子。
class Train(object): def __init__(self, cars): self.cars = cars def __len__(self): return self.cars def __iter__(self): return TrainIterator(self) #自身不作为迭代器,否则return self即可 class TrainIterator(object): def __init__(self, train): self.train = train self.current = 0 def __next__(self): if self.current < len(self.train): self.current += 1 return 'car #%s' %(self.current) else: raise StopIteration() next = __next__ #与python2兼容 class Train(object: def __init__(self, cars): self.cars = cars def __iter__(self): for i in range(self.cars): yield 'car #%s' % (i+1)
迭代器
可以用for遍历循环的对象称为Iterable,包括两类
1. list set tuple str dict等
2. generator
实现一个iterable的对象必须实现__iter__,__iter__返回一个迭代器,一个迭代器必须实现__next__。
因此,迭代器可以被next()调用,而调用iter()可以让Iterable变成Iterator。Iterable和Iterator是更高层的抽象,无法用type()判断,可以使用isinstance方法判断。
>>> from collections import Iterable
>>> isinstance(iter([]), Iterator) True >>> isinstance(iter('abc'), Iterator) True
当调用iter(x)时,如果x.__iter__存在,那么就会通过x.__iter__()来获得iterator。否则,python就会尝试通过下标自动访问x[0]、x[1]、x[2]...,因此,你可以通过__getitem__定制下标访问的结果。
sequence protocol :protocol是用于动态语言的interface的同义词,不同于interface的地方是protocol不强制要求实现,不做静态检查。包括__reverse__、__len__、__getitem__,等等,都是protocol。sequence protocol指的是__len__和__getitem__。
函数式编程
map/reduce,google使用的mapreduce算法就来自于函数式编程的这两个方法。
Python中map可以直接使用,reduce需要从functools引入。
map接受两个参数,一个接受一个参数的函数和一个Iterable对象,返回一个Iterator对象。

reduce接受两个参数,一个是接受两个参数的函数,另一个是一个Iterable对象,返回结果对象

很多问题可以通过map/reduce的组合解决,比如完成字符串转换成数字的功能
from functools import reduce def char2num(s): return {'0': 0, '1': 1, '2': 2, '3': 3, '4': 4, '5': 5, '6': 6, '7': 7, '8': 8, '9': 9}[s] def str2int(s): return reduce(lambda x, y: x * 10 + y, map(char2num, s))
filter
filter()接受两个参数,一个接受一个参数做布尔判断,另一个是Iterable对象,返回一个惰性对象(Iterator对象)。同时filter进行惰性计算,所以尝在在一个生成器中使用filter,只有代码运行到filter处才会执行filter。
filter可以来写筛选器,以实现素数生成功能为例:
因为素数无限,应该使用惰性对象来生成,这里使用generator
def _odd_iter(): n = 1 while True: n = n + 2 yield n
进行布尔判断的一个筛选函数
def _not_divisible(n): return lambda x: x % n > 0
结合序列生成器和筛选函数,写出一个素数生成器
def primes(): yield 2 it = _odd_iter() # 初始序列 while True: n = next(it) # 返回序列的第一个数 yield n it = filter(_not_divisible(n), it) # 构造新序列
调用素数生成器,并设定跳出条件
for n in primes(): if n < 1000: print(n) else: break
sorted
sorted也是高阶函数,可选参数key表示排序前对元素使用的修饰函数,reverse表示正序还是反序,默认是反序。
>>> sorted(['bob', 'about', 'Zoo', 'Credit'], key=str.lower, reverse=True)
返回函数
函数可以被返回,这样函数会包含相应的上下文环境。值得注意的是,一个函数被返回并不会被执行,而只是返回函数的地址,调用时才会执行函数的本体。
使用闭包时需要注意的是,不要轻易访问循环体内的变量,因为相应的上下文环境可能改变,所谓相应上下文环境,以例说明
def count(): def f(i): def g(): def h(): return i*i return h return g fs = [] for i in range(1, 4): fs.append(f(i)) return fs f1, f2, f3 = count() f1 = f1() print(f1())
当append(f1(i))时,红色部分的代码的上下文信息(如局部变量、参数的值)会被保存,所以可以通过多加一层闭包保存变量。否则,访问的是外部闭包的变量,这里也就是9,
fs中保存的三个f闭包都会指向同一个闭包--count()。count返回函数的列表,实际上count也是一个闭包。与之相关的作用域问题也被收录于Programing FAQ中,见为什么循环内lambda的返回值一样?

另一个容易产生意外数值的原因是python中return expression是惰性求值。

返回值是一个函数调用而不是结果,所以参数的绑定也会现在当前作用域寻找,再在父作用域寻找。
装饰器
装饰器依赖闭包实现,装饰器的记号是在def定义函数前使用@decorator,相当于func = decorator(func),之前说过闭包的作用就是持久化数据,保存上下文,由decorator(func)可知装饰器保存了func的上下文。由于定义时不知道func的接口设计,所以装饰器返回的内部函数也设计为接受任意参数。
def log(func): def wrapper(*args, **kw): print('call %s():' % func.__name__) return func(*args, **kw) return wrapper @log def now(): print('2015-3-25')
如果想要在使用装饰器时传入参数,无非是多加一层闭包
def log(text): def decorator(func): def wrapper(*args, **kw): print('%s %s():' % (text, func.__name__)) return func(*args, **kw) return wrapper return decorator @log('execute') def now(): print('2015-3-25')
装饰器保留了原本的接口,但是,一些与接口无关的参数如__name__,未调用时就已发生改变。访问now.__name__得到'wrapper',而且已经无法通过now().__name__得到'now',因为now()相当于func(),已经无法访问func.__name__,这部分信息也就丢失。
正确的方式如下,functools提供的wraps可以代劳将丢失的信息复制过来
import functools def log(func): @functools.wraps(func) def wrapper(*args, **kw): print('call %s():' % func.__name__) return func(*args, **kw) return wrapper
what's more:
python中的装饰器
偏函数
使用functools.partial可以固定参数,包括*args和*kwargs
比如 int2 = functools.partial(int, base=2)
模块
一个.py文件就是一个模块,可以预见模块之间会冲突,所以使用包来管理模块。所谓包,就是文件夹下至少包含__init__.py文件。
命名
__name__被保留使用
_name 被用作内部变量和函数
__name 用在类中,会被改写成 _type__name
name_ 用于解决和关键字命名冲突
for _ in range(n) 表明丢弃这个值,只是为了循环n次
OOP
python支持的OOP有限,包括之前通过命名限制数据访问,实际上不能真正做到数据屏蔽,只是作为一种规范要求人们遵守。
多态:子类可以重写父类的方法
开闭原则:对扩展开放,允许增加新的子类;对修改封闭,不需要更改父类的代码。
鸭子类型:甚至子类不继承的情况下,只需拥有同名方法,在仅仅调用这个方法的情况下一样可以被视作是一个子类。
对象信息
type可以返回对象的class信息,判断函数类型可以通过types包来判断
>>> import types >>> def fn(): ... pass ... >>> type(fn)==types.FunctionType True >>> type(abs)==types.BuiltinFunctionType True >>> type(lambda x: x)==types.LambdaType True >>> type((x for x in range(10)))==types.GeneratorType True
isinstance
isinstance方法可以判断一个对象是否是一个类及其子类的实例。
dir
dir()可以获得对象的所有属性和方法。
之前提到__name__用来保存特殊信息,实际上len()会调用对象的__len__方法,所以我们可以在类中实现__len__以支持len()。
getattr/setattr/hasattr
getattr(obj, attr_name, [default]),setattr与getattr类似,hasattr做布尔判断。在不知道对象信息的情况下可以通过这些方法获取和设置一个对象的属性。
More OOP
与静态类型的语言不同,python可以在运行时为对象添加属性和方法,甚至可以给类添加方法。
>>> class s(): ... def func(self): pass >>> def set_age(self, age): # 定义一个函数作为实例方法 ... self.age = age ... >>> from types import MethodType >>> s.set_age = MethodType(set_age, s) # 给实例绑定一个方法 >>> s.set_age(25) # 调用实例方法 >>> s.age # 测试结果 25
方法和函数(method & function)
方法和函数是不同的,通过类名访问其中def声明的对象,被视为访问了一个方法;通过实例访问其中def声明的对象,被视为访问了一个函数。
特别之处在于,通过types.MethodType,你可以为类创建一个方法,此时self实际上起的是cls的功能。在Python中,实际上不区分self和cls,只作为一种命名规范。当类内一个def定义的对象是function时,其第一个参数就被视为self,当定义的对象是method时,第一个参数就被视为cls。关于self和cls的说明见PEP8
__slots__
__slots__是类属性,可以通过元组设定这个类的实例的那些属性是read-only的,子类如果设置__slots__则会同时继承父类的__slots__,否则子类不继承父类的__slots__。
@property
我们使用set和get方法来控制属性访问,但是使用形式就是函数调用,python提供@property和@score.setter来将get和set方法变成属性来访问
class Student(object): @property def birth(self): return self._birth @birth.setter def birth(self, value): self._birth = value @property def age(self): return 2015 - self._birth
>>> s = Student()
>>> s.birth = 1999
>>> s.birth
199
这里birth方法封装了_birth属性的访问,@property使得birth可以作为一个可读属性访问;@score.setter使得birth可以作为一个属性赋值。
Mixin
Mixin的目的是通过多重继承减少继承的层次,比如
class Dog(Mammal, RunnableMixIn, CarnivorousMixIn): pass
通过多重继承让Dog类具有Runnable和Carnivorous的特点,为了表明Mixin的目的,那些为了添加特性而加入的父类命名为#####Mixin。
定制类
def __str__ 返回print输出的内容
def __repr__ 返回控制台输出的信息,一般和__str__一样
def __iter__ 返回一个迭代对象,迭代对象的时候使用自己的__next__ 遍历,当类本身是迭代对象的时候def __iter__(self) return self即可
class Fib(object): def __init__(self): self.a, self.b = 0, 1 # 初始化两个计数器a,b def __iter__(self): return self # 实例本身就是迭代对象,故返回自己 def __next__(self): self.a, self.b = self.b, self.a + self.b # 计算下一个值 if self.a > 100000: # 退出循环的条件 raise StopIteration() return self.a # 返回下一个值
def __getitem__ 支持下标访问和切片 a = obj[name], obj[i:j]
class Fib(object): def __getitem__(self, n): if isinstance(n, int): # n是索引 a, b = 1, 1 for x in range(n): a, b = b, a + b return a if isinstance(n, slice): # n是切片 start = n.start stop = n.stop if start is None: start = 0 a, b = 1, 1 L = [] for x in range(stop): if x >= start: L.append(a) a, b = b, a + b return L
def __setitem__ 用于支持下标赋值 obj[index] = something
def __delitem__ 用于支持列表元素删除 del obj[index]
def __getattr__(self,name) 改写访问a.name的结果,如果__getattr__返回一个函数,那么从使用上来看则是a.name(),如同调用了一个函数。
值得注意的是__setattr__总是会被调用,而__getattr__只有在a.name访问的属性不存在时才被调用,这可能导致名字屏蔽
class Fuck(dict): a = 2222 def __setattr__(self, key, value): self[key] = value def __getattr__(self, item): return self[item] fuck = Fuck() fuck.a = 1 #等价于fuck['a'] = 1 print(fuck.a) # 上得到2222
print(fuck['a']) # 得到1
def __call__ 使得实例可以被调用 obj()
枚举类
http://www.cnblogs.com/ucos/p/5896861.html
https://docs.python.org/3/library/enum.html#iteration
元类
type()可以判断一个对象的类型,可以用来创造一个类,只要传入参数(name,父类元组,方法字符串名和具体方法的字典)。
metaclass
定义一个类之后可以创建一个实例,在参数中定义metaclass=xxmetaclass之后可以创建一个类。用于创建类的类常常命名为XXmetaclass,返回值自然是type创建的新类。
# metaclass用来创建类,所以必须从`type`类型派生: class ListMetaclass(type): def __new__(cls, name, bases, attrs): attrs['add'] = lambda self, value: self.append(value) return type.__new__(cls, name, bases, attrs)
class MyList(list, metaclass=ListMetaclass):
pass
学习metaclass的用法必须了解__new__的用法

常见用法:见文档中的说明,__new__的常见的用法之一是调用父类的__new__方法,并且在返回之前进行需要进行的修饰。XXmetaclass类就相当于type和要创建的class之间的一层起到修饰作用的类,对于__new__方法而言,必要参数只有cls,cls指向XXmetaclass。在XXmetaclass通过metaclass传入时,__new__的其余可选参数被自动传入。
执行顺序:__new__在__init__之前被执行,如果__new__返回的type创建的实例不是cls指向的实例(比如给type传了错误的第一参数,而不是cls),那么__init__也不会被执行。
what's more:
python中的类
错误处理和调试
try except [finally]
try block内的语句出现错误时如果被except捕获,则跳转到except block,finally可选,而且如果存在总是会被执行。错误被except语句按执行顺序捕获,如果一个错误没有被except捕获,那么最终会被python解释器捕获,并且产生一个调用堆栈。
python内置的logging可以用在except block中,记录错误信息。
抛出错误
因为错误是class,捕获一个错误就是捕获到该class的一个实例。因此,错误并不是凭空产生的,而是有意创建并抛出的。Python的内置函数会抛出很多类型的错误,我们自己编写的函数也可以抛出错误。
如果要抛出错误,首先根据需要,可以定义一个错误的class,选择好继承关系,然后,用raise语句抛出一个错误的实例:
class FooError(ValueError): pass def foo(s): n = int(s) if n==0: raise FooError('invalid value: %s' % s) return 10 / n foo('0')
raise语句也可以用在except block中,甚至可以raise一个和捕获的异常不同的异常,raise抛出的异常会传送到上一层,比如调用当前函数的另一段函数,直到这个异常被处理。
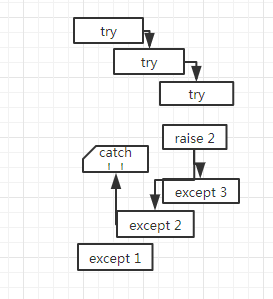
调试
使用assert调试,要禁止所有assert语句只需在启动时加上-O参数。
使用logging代替print语句调试
import logging logging.basicConfig(level=logging.INFO)
这就是logging的好处,它允许你指定记录信息的级别,有debug,info,warning,error等几个级别,当我们指定level=INFO时,logging.debug就不起作用了。同理,指定level=WARNING后,debug和info就不起作用了。这样一来,你可以放心地输出不同级别的信息,也不用删除,最后统一控制输出哪个级别的信息。
logging的另一个好处是通过简单的配置,一条语句可以同时输出到不同的地方,比如console和文件。
unitest
class Dict(dict): def __init__(self, **kwargs): super().__init__(**kwargs) def __getattr__(self, key): try: return self[key] except KeyError: raise AttributeError('dict object has not attribute.') def __setattr__(self, key, value): self[key] = value import unittest class TestDict(unittest.TestCase): def test_init(self): d = Dict(a=1, b='test') self.assertEqual(d.a, 1) self.assertEqual(d.b, 'test') self.assertTrue(isinstance(d, dict)) def test_key(self): d = Dict() d['key'] = 'value' self.assertEqual(d.key, 'value') def test_attr(self): d = Dict() d.key = 'value' self.assertTrue('key' in d) self.assertEqual(d['key'], 'value') def test_keyerror(self): d = Dict() with self.assertRaises(KeyError): value = d['empty'] def test_attrerror(self): d = Dict() with self.assertRaises(AttributeError): value = d.empty def setUp(self): pass def tearDown(self): pass if __name__ == '__main__': unittest.main() # python36 -m unittest test_driven
python自带的unitest可以完成自动测试的任务,通过继承实现一个类,类中名字以‘test’开头的方法会在测试时被执行,setUp和tearDown负责实现每个测试方法被执行前后处理的任务,比如每个测试都需要连接数据库时,可以通过setUp方法打开数据库,tearDown方法关闭数据库。
IO
基本方法open(file,[mode],[encoding],[errors]),read([size])返回所有或指定内容,readline()返回一行,readlines()返回所有内容并且保存为list,close()。
像open()函数返回的这种有个read()方法的对象,在Python中统称为file-like Object。除了file外,还可以是内存的字节流,网络流,自定义流等等。file-like Object不要求从特定类继承,只要写个read()方法就行。
StringIO就是在内存中创建的file-like Object,常用作临时缓冲,支持通用的IO方法和一个getvalue()。
>>> from io import StringIO >>> f = StringIO() >>> f.write('hello') 5 >>> f.write(' ') 1 >>> f.write('world!') 6 >>> print(f.getvalue()) hello world!
BytesIO相较于StringIO而言是用来处理bytes数据的
>>> from io import BytesIO >>> f = BytesIO() >>> f.write('中文'.encode('utf-8')) 6 >>> print(f.getvalue()) b'\xe4\xb8\xad\xe6\x96\x87'
操作文件和目录
>>> os.name 'nt' >>> os.environ environ({'ALLUSERSPROFILE': 'C:\\ProgramData', 'APPDATA': 'C:\\Users\\Liu_100\\AppData\\Roaming', 'CLASSPATH': 'C:\\Program Files\\Java\\jdk1.8.0_11\\lib\\tools.jar', 'CM2014DIR': 'C:\\Program Files (x86)\\Common Files\\Autodesk Shared\\Materials\\', 'COMMONPROGRAMFILES':'C:\\ProgramData\\Oracle\\Java\\javapath;C:\\Program Files (x86)\\NVIDIA Corporation\\PhysX\\Common;C:\\Program Files\\Broadcom\\Broadcom 802.11 Network Adapter\\Driver;C:\\Program Files (x86)\\Intel\\iCLS Client\\;C:\\Program Files\\Intel\\iCLS Client\\;C:\\WINDOWS\\system32;
>>> os.environ.get()
>>> os.path.abspath('.')
'C:\\Users\\Liu_100\\PycharmProjects\\Learning_Python'
>>> os.path.join('.')
'.'
>>> os.path.join('.','sf/sf')
'.\\sf/sf'
>>> os.mkdir()
>>> os.rmdir()
不必自己拼接地址字符串,通过os.path.join方法可以根据系统正确地得到组合字符串,split可以得到正确的文件名,splitext可以得到正确的后缀。
os模块带有rename和remove方法来控制文件,但是没有提供复制文件的方法,shutil模块是os模块的补充,提供了copyfile方法和其他方法。
实例
列出所有文件 >>> [x for x in os.listdir('.') if os.path.isdir(x)] ['.lein', '.local', '.m2', '.npm', '.ssh', '.Trash', '.vim', 'Applications', 'Desktop', ...] 列出所有.py文件 >>> [x for x in os.listdir('.') if os.path.isfile(x) and os.path.splitext(x)[1]=='.py'] ['apis.py', 'config.py', 'models.py', 'pymonitor.py', 'test_db.py', 'urls.py', 'wsgiapp.py']
序列化
我们把变量从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
Python提供了pickle模块来实现序列化。
>>> import pickle >>> d = dict(name='Bob', age=20, score=88) >>> pickle.dumps(d) b'\x80\x03}q\x00(X\x03\x00\x00\x00ageq\x01K\x14X\x05\x00\x00\x00scoreq\x02KXX\x04\x00\x00\x00nameq\x03X\x03\x00\x00\x00Bobq\x04u.'
pickle.dumps()方法把任意对象序列化成一个bytes,然后,就可以把这个bytes写入文件。或者用另一个方法pickle.dump()直接把对象序列化后写入一个file-like Object:
>>> f = open('dump.txt', 'wb') >>> pickle.dump(d, f) >>> f.close()
通过pickle.loads()可以使用反转序列
>>> f = open('dump.txt', 'rb') >>> d = pickle.load(f) >>> f.close() >>> d {'age': 20, 'score': 88, 'name': 'Bob'}
JSON
Python内置的json模块提供了非常完善的Python对象到JSON格式的转换。我们先看看如何把Python对象变成一个JSON:
>>> import json >>> d = dict(name='Bob', age=20, score=88) >>> json.dumps(d) '{"age": 20, "score": 88, "name": "Bob"}'
dumps()方法返回一个str,内容就是标准的JSON。类似的,dump()方法可以直接把JSON写入一个file-like Object。
要把JSON反序列化为Python对象,用loads()或者对应的load()方法,前者把JSON的字符串反序列化,后者从file-like Object中读取字符串并反序列化:
>>> json_str = '{"age": 20, "score": 88, "name": "Bob"}' >>> json.loads(json_str) {'age': 20, 'score': 88, 'name': 'Bob'}
由于JSON标准规定JSON编码是UTF-8,所以我们总是能正确地在Python的str与JSON的字符串之间转换。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号