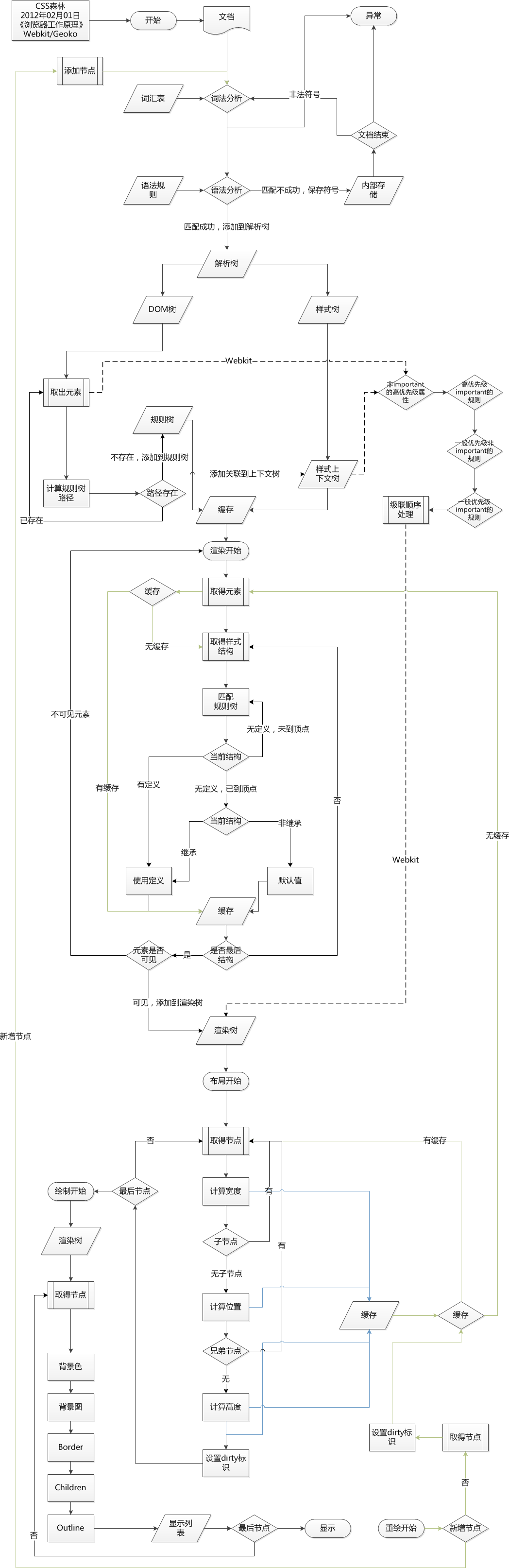
渲染机制
废话少说,先来看个图:
从上面这个图中,我们可以看到那么几个事:
1)浏览器会解析三个东西:
一个是HTML/SVG/XHTML,事实上,Webkit有三个C++的类对应这三类文档。解析这三种文件会产生一个DOM Tree。
CSS,解析CSS会产生CSS规则树。
Javascript,脚本,主要是通过DOM API和CSSOM API来操作DOM Tree和CSS Rule Tree.
2)解析完成后,浏览器引擎会通过DOM Tree 和 CSS Rule Tree 来构造 Rendering Tree。注意:
Rendering Tree 渲染树并不等同于DOM树,因为一些像Header或display:none的东西就没必要放在渲染树中了。
CSS 的 Rule Tree主要是为了完成匹配并把CSS Rule附加上Rendering Tree上的每个Element。也就是DOM结点。也就是所谓的Frame。
然后,计算每个Frame(也就是每个Element)的位置,这又叫layout和reflow过程。
3)最后通过调用操作系统Native GUI的API绘制。
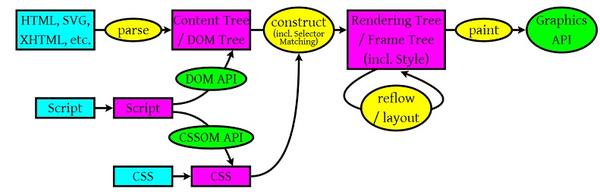
DOM解析
HTML的DOM Tree解析如下:
<html>
<html>
<head>
<title>Web page parsing</title>
</head>
<body>
<div>
<h1>Web page parsing</h1>
<p>This is an example Web page.</p>
</div>
</body>
</html>
上面这段HTML会解析成这样:
 下面是另一个有SVG标签的情况。
下面是另一个有SVG标签的情况。
CSS解析
CSS的解析大概是下面这个样子(下面主要说的是Gecko也就是Firefox的玩法),假设我们有下面的HTML文档:
<doc>
<title>A few quotes</title>
<para>
Franklin said that <quote>"A penny saved is a penny earned."</quote>
</para>
<para>
FDR said <quote>"We have nothing to fear but <span>fear itself.</span>"</quote>
</para>
</doc>
于是DOM Tree是这个样子:

然后我们的CSS文档是这样的:
/* rule 1 */ doc { display: block; text-indent: 1em; }
/* rule 2 */ title { display: block; font-size: 3em; }
/* rule 3 */ para { display: block; }
/* rule 4 */ [class="emph"] { font-style: italic; }
于是我们的CSS Rule Tree会是这个样子:
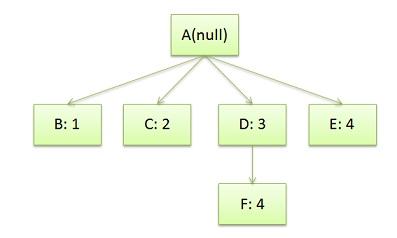
注 意,图中的第4条规则出现了两次,一次是独立的,一次是在规则3的子结点。所以,我们可以知道,建立CSS Rule Tree是需要比照着DOM Tree来的。CSS匹配DOM Tree主要是从右到左解析CSS的Selector,好多人以为这个事会比较快,其实并不一定。关键还看我们的CSS的Selector怎么写了。
注意:CSS匹配HTML元素是一个相当复杂和有性能问题的事情。所以,你就会在N多地方看到很多人都告诉你,DOM树要小,CSS尽量用id和class,千万不要过渡层叠下去,……
通过这两个树,我们可以得到一个叫Style Context Tree,也就是下面这样(把CSS Rule结点Attach到DOM Tree上):
 所
以,Firefox基本上来说是通过CSS 解析 生成 CSS Rule Tree,然后,通过比对DOM生成Style Context
Tree,然后Firefox通过把Style Context Tree和其Render Tree(Frame
Tree)关联上,就完成了。注意:Render
Tree会把一些不可见的结点去除掉。而Firefox中所谓的Frame就是一个DOM结点,不要被其名字所迷惑了。
所
以,Firefox基本上来说是通过CSS 解析 生成 CSS Rule Tree,然后,通过比对DOM生成Style Context
Tree,然后Firefox通过把Style Context Tree和其Render Tree(Frame
Tree)关联上,就完成了。注意:Render
Tree会把一些不可见的结点去除掉。而Firefox中所谓的Frame就是一个DOM结点,不要被其名字所迷惑了。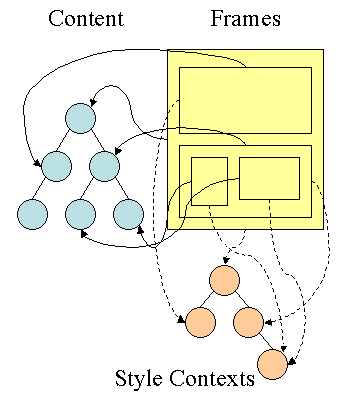
注:Webkit不像Firefox要用两个树来干这个,Webkit也有Style对象,它直接把这个Style对象存在了相应的DOM结点上了。
渲染
渲染的流程基本上如下(黄色的四个步骤):
计算CSS样式
构建Render Tree
Layout – 定位坐标和大小,是否换行,各种position, overflow, z-index属性 ……
正式开画

CSS森林(CSS Forest): 浏览器工作原理浅析