第一次个人编程作业
- 首先是github链接:点击进入我的github
- 或者左上角的🐱
1. 计算模块接口的设计与实现过程
流程图:

实现过程:
百度、csdn和github
大体思路为,读入源文本与比对文本,利用jieba进行分词,提取其中出现次数前k的词,作为关键词,分别计算Jaccard系数。
核心算法是Jaccard(杰卡德)相似性系数的计算
Jaccard相似系数
Jaccard相似系数(Jaccard similarity coefficient)用于比较有限样本集之间的相似性与差异性。Jaccard系数值越大,样本相似度越高。Jaccard系数主要的应用的场景有:过滤相似度很高的新闻,或者网页去重,考试防作弊系统,论文查重系统(最近几天疯狂百度,看到和查重有关的算法就两眼放光)
给定两个集合A,B,Jaccard 系数定义为A与B交集的大小与A与B并集的大小的比值,公式如下:
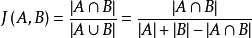
例如计算集合X与Y的Jaccard相似系数:
如集合A={a,b,c,d};B={b,c,d,e};
那么他们的Jaccard(X,Y)=3/5 = 0.6;
网上能找到非常多的样例,就不过多解释了
用到的python库:
jieba分词
sys读取命令行参数
提取关键词:
k1 = int(len(cut1)/5)
k2 = int(len(cut2)/5)
keywords1 = jieba.analyse.extract_tags(",".join(cut1), topK=k1, withWeight=False)#按出现次数前k个取出关键词
keywords2 = jieba.analyse.extract_tags(",".join(cut2), topK=k2, withWeight=False)
这里用到了jieba.analyse。
jieba.analyse.extract_tags()提取关键字的原理是使用TF-IDF算法
用余弦相似度计算也会用到这个算法

Jaccard系数计算模块:
def jaccrad(essay_source, essay_target): # essay_source为源文本,essay_target为待比较文本
essay_source = stopword(essay_source)
essay_target = stopword(essay_target)
cut1 = [i for i in jieba.cut(essay_source, cut_all=True) if i != ''] # 用Jieba默认精准模式分词
cut2 = [i for i in jieba.cut(essay_target, cut_all=True) if i != '']
k1 = int(len(cut1)/5)
k2 = int(len(cut2)/5)
# 按出现次数前k个取出关键词
keywords1 = jieba.analyse.extract_tags(",".join(cut1), topK=k1, withWeight=False)
keywords2 = jieba.analyse.extract_tags(",".join(cut2), topK=k2, withWeight=False)
temp = 0
for i in keywords2:
if i in keywords1:
temp += 1
# 并集
jaccard_union = len(keywords1) + len(keywords2) - temp
# 交集
jaccard_index = float(temp/jaccard_union)
# 返回杰卡德系数
return jaccard_index
2.计算模块接口部分的性能改进
这部分使用了profile工具(当然是从大佬们那里模仿的):
测试给出的所有数据耗费时间



分词就占了近一半
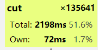
我真的太菜了,对优化什么的根本就完全就无从下手,先在DDL前交了,有时间再想想看
只增加了去标点。
3.计算模块部分单元测试展示
测试结果:

使用的是群里提供的测试样例,增加了相同文本和空文本
测试代码:
import calculate
import unittest
import jieba
import logging
import os
import sys
os.chdir(sys.path[0])
class MyTest(unittest.TestCase):
def setUp(self) -> None:
jieba.setLogLevel(logging.INFO)
def tearDown(self) -> None:
print("end!")
def test_add(self):
with open("sim_0.8/orig.txt", "r", encoding='UTF-8') as fp:
source = fp.read()
with open("sim_0.8/orig_0.8_add.txt", "r", encoding='UTF-8') as fp:
target = fp.read()
sim = round(calculate.jaccrad(source, target), 2)
print("测试样本:orig_0.8_add.txt ,相似度为: ","%.2f" %sim)
def test_del(self):
with open("sim_0.8/orig.txt", "r", encoding='UTF-8') as fp:
source = fp.read()
with open("sim_0.8/orig_0.8_del.txt", "r", encoding='UTF-8') as fp:
target = fp.read()
sim = round(calculate.jaccrad(source, target), 2)
print("测试样本:orig_0.8_del.txt ,相似度为: ","%.2f" %sim)
def test_dis_1(self):
with open("sim_0.8/orig.txt", "r", encoding='UTF-8') as fp:
source = fp.read()
with open("sim_0.8/orig_0.8_dis_1.txt", "r", encoding='UTF-8') as fp:
target = fp.read()
sim = round(calculate.jaccrad(source, target), 2)
print("测试样本:orig_0.8_dis_1.txt ,相似度为: ","%.2f" %sim)
def test_dis_3(self):
with open("sim_0.8/orig.txt", "r", encoding='UTF-8') as fp:
source = fp.read()
with open("sim_0.8/orig_0.8_dis_3.txt", "r", encoding='UTF-8') as fp:
target = fp.read()
sim = round(calculate.jaccrad(source, target), 2)
print("测试样本:orig_0.8_dis_3.txt ,相似度为: ","%.2f" %sim)
def test_dis_7(self):
with open("sim_0.8/orig.txt", "r", encoding='UTF-8') as fp:
source = fp.read()
with open("sim_0.8/orig_0.8_dis_7.txt", "r", encoding='UTF-8') as fp:
target = fp.read()
sim = round(calculate.jaccrad(source, target), 2)
print("测试样本:orig_0.8_dis_7.txt ,相似度为: ","%.2f" %sim)
def test_dis_10(self):
with open("sim_0.8/orig.txt", "r", encoding='UTF-8') as fp:
source = fp.read()
with open("sim_0.8/orig_0.8_dis_10.txt", "r", encoding='UTF-8') as fp:
target = fp.read()
sim = round(calculate.jaccrad(source, target), 2)
print("测试样本:orig_0.8_dis_10.txt ,相似度为: ","%.2f" %sim)
def test_dis_15(self):
with open("sim_0.8/orig.txt", "r", encoding='UTF-8') as fp:
source = fp.read()
with open("sim_0.8/orig_0.8_dis_15.txt", "r", encoding='UTF-8') as fp:
target = fp.read()
sim = round(calculate.jaccrad(source, target), 2)
print("测试样本:orig_0.8_dis_15.txt ,相似度为: ","%.2f" %sim)
def test_mix(self):
with open("sim_0.8/orig.txt", "r", encoding='UTF-8') as fp:
source = fp.read()
with open("sim_0.8/orig_0.8_mix.txt", "r", encoding='UTF-8') as fp:
target = fp.read()
sim = round(calculate.jaccrad(source, target), 2)
print("测试样本:orig_0.8_mix.txt ,相似度为: ","%.2f" %sim)
def test_rep(self):
with open("sim_0.8/orig.txt", "r", encoding='UTF-8') as fp:
source = fp.read()
with open("sim_0.8/orig_0.8_rep.txt", "r", encoding='UTF-8') as fp:
target = fp.read()
sim = round(calculate.jaccrad(source, target), 2)
print("测试样本:orig_0.8_rep.txt ,相似度为: ","%.2f" %sim)
def testmy1(self):
with open("sim_0.8/orig.txt", "r", encoding='UTF-8') as fp:
source = fp.read()
with open("mytest_1.txt", "r", encoding='UTF-8') as fp:
target = fp.read()
sim = round(calculate.jaccrad(source, target), 2)
print("测试样本:mytest_1.txt ,相似度为: ","%.2f" %sim)
def testmy2(self):
with open("sim_0.8/orig.txt", "r", encoding='UTF-8') as fp:
source = fp.read()
with open("mytest_2.txt", "r", encoding='UTF-8') as fp:
target = fp.read()
sim = round(calculate.jaccrad(source, target), 2)
print("测试样本:mytest_2.txt ,相似度为: ","%.2f" %sim)
if __name__ == '__main__':
unittest.main()
if __name__ == '__main__':
unittest.main()
代码覆盖率:


4.计算模块部分异常处理说明
异常处理也是使用的python自带的
try/except语句
考虑到文件不存在的情况:

try:
# 从命令行读入文件
with open(sys.argv[1], "r", encoding='UTF-8') as fp:
source = fp.read()
with open(sys.argv[2], "r", encoding='UTF-8') as fp:
target = fp.read()
sim = round(jaccrad(source, target), 2)
except Exception as err:
#异常情况输出-1
sim = -1
print(err)
# 计算相似度并保留两位小数
try:
with open(sys.argv[3], "w+", encoding='UTF-8') as fp:
fp.write(str(sim))
# 写入输出文本
except Exception as err:
print(err)
5.PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
| ---- | ---- | ---- | ---- | ---- | ---- |
| Planning | 计划 | 100 | 120 |
| Estimate | 估计这个任务需要多少时间 | 40 | 40 |
| Development | 开发 | 420 | 480 |
| Analysis | 需求分析 (包括学习新技术) | 480 | 840 |
| Design Spec | 生成设计文档 | 40 | 60 |
| Design Review | 设计复审 | 20 | 20 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 20 |
| Design | 具体设计 | 60 | 60 |
| Coding | 具体编码 | 300 | 180 |
| Code Review | 代码复审 | 30 | 30 |
| Test | 测试(自我测试,修改代码,提交修改) | 200 | 60 |
| Reporting | 报告 | 60 | 60 |
| Test Repor | 测试报告 | 30 | 30 |
| Size Measurement | 计算工作量 | 15 | 25 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 60 | 45 |
| | 合计 | 1885 | 2070 |
6.总结
我和其他说什么看到题目觉得懵逼的然后做的非常nb的大佬不一样,看到题目我根本没意识到题目的难度,越做越怀疑人生。
我花了很多时间,主要是学习各种工具的使用,github,性能分析工具等等,虽然很多搞了半天都只会了一点。。。再就是python,上次看书还是在疫情之前(整个疫情期间我居然还没学完python,反正当初懒癌发作,现在就是非常后悔),于是又花了不少时间把python大致看了一遍。反正写的过程中各种报错,还有环境出问题之类的,光是完成就有些吃力了,优化只能先放放了。
但是python真的好好用!希望自己能尽快花时间好好学一遍吧。会的东西实在太少了,加油吧。
