
并发通信、生产者消费者模型
多进程之间通信的限制
看一个例子:
import multiprocessing as mp data=666 def func(): global data data=222 p=mp.Process(target=func) p.start() p.join() print(data) >>>666
可以看到,声明为global的data也没有发生变化,输出结果仍然是666,这正是多进程之间通信的限制,各个进程之间是相互独立的,互不干扰的内存空间。因此如果想要空想数据就必须开辟一段共享的内存空间。就要用到Manger对象。

Manger对象
我们常用的Manger对象空间有list(),dict(),Queue()三种,下面举一个List()的简单例子。
from multiprocessing import Process,Manager mgr=Manager() #创建服务器进程并返回通信的管理器 list_proxy=mgr.list() #通过管理器在列表中开辟空间,并返回一个代理 print(list_proxy) def func(list_ex): list_ex.append('a')
#把代理传给子进程子进程就可以通过代理来访问共享的内存空间了。 p=Process(target=func,args=(list_proxy,)) p.start() p.join() print(list_proxy) >>>[] ['a']
线程间的共享与同步锁
进程间如果不通过Manger对象是无法进行内存共享的,那么对于线程呢?对于Python来讲每一次只能执行一个线程,由于GIL锁的存在。我们来看例子。
import threading data=666 def func(): global data data=222 t=threading.Thread(target=func) t.start() t.join() print(data) >>>222
我们看到结果输出了222,也就是说全局对象更改了data的值,由此可见线程之间的内存是共享的。正是因为共享的便会出现资源竞争的问题,我们来看例子:
import threading data=0 n=10000000 #这个n必须足够大才能看出效果 def add(n): global data for i in range(n): data+=1 def sub(n): global data for i in range(n): data-=1 a=threading.Thread(target=add,args=(n,)) s=threading.Thread(target=sub,args=(n,)) a.start() s.start() a.join() s.join() print(data) >>>-1561473
可以看到本来应该为0的值,在基数足够大的时候就出现了问题,这就是由于线程之间的内存共享导致的,所以为了解决这一个问题就出现了同步锁的概念,说白了就是加上锁,然后控制资源的访问权限这样就会避免资源竞争的出现。看代码。
import threading lock=threading.Lock() #生成一把锁 data=0 n=10000000 def add(n): global data for i in range(n): lock.acquire() data+=1 lock.release() def sub(n): global data for i in range(n): lock.acquire() data-=1 lock.release() a=threading.Thread(target=add,args=(n,)) s=threading.Thread(target=sub,args=(n,)) a.start() s.start() a.join() s.join() print(data) >>>0
这样通过锁来访问就正确的得出结果了,但是要记住一点加锁之后要记得释放,或者通过with语法这样会自动帮你释放。
with lock:
data-=1
线程与进程安全的队列
队列是一种常用的数据结构,原则是先进先出(FIFO)。
线程安全的队列
主要方法包括:
- 入队:put(item)
- 出队:get()
- 测试空:empty() #近似
- 测试满:full() #近似
- 队列长度:qsize() #近似
- 任务结束:task_done()
- 等待完成:join()
进程安全队列
进程的队列要用到之前提到的Manger对象,mgr.Queue()
主要方法包括:
- 入队:put(item)
- 出队:get()
- 测试空:empty() #近似
- 测试满:full() #近似
- 队列长度:qsize() #近似
例子我们放到下面的生产者消费者模型中讲解。
生产者消费者模型
何所谓生产者消费者模型?
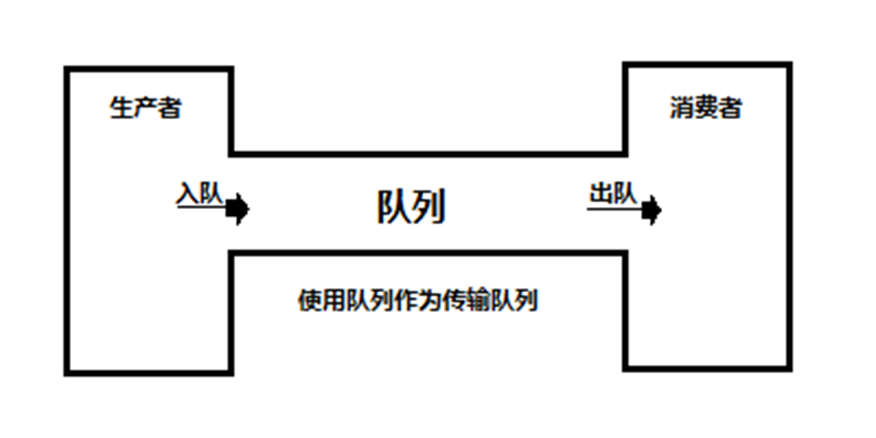
就是说我们把进程之间的通信分开考虑,生产者只要往队列里面丢东西,消费者只要从队列里取东西,而二者不用考虑对方。
多线程实现
#生产者消费者模型 import queue import threading import random import time class Producer(threading.Thread): def __init__(self, queue): super().__init__() self.queue = queue def run(self): while True: #生成了一个数据 data = random.randint(0, 99) self.queue.put(data) #把数据丢进队列中 print('生产者: 生产了:', data) time.sleep(1) class Concumer(threading.Thread): def __init__(self, queue): super().__init__() self.queue = queue def run(self): while True: item = self.queue.get() #从队列中拿一个数据 print('消费者: 从队列中拿到:', item) q = queue.Queue(5) #创建一个队列 producer = Producer(q) #创建一个生产者 concumer = Concumer(q) #创建一个消费者 producer.start() concumer.start() >>>生产者: 生产了: 46 消费者: 从队列中拿到: 46 生产者: 生产了: 9 消费者: 从队列中拿到: 9 生产者: 生产了: 39 消费者: 从队列中拿到: 39 生产者: 生产了: 89 消费者: 从队列中拿到: 89
多进程实现
import multiprocessing import random import time class Producer(multiprocessing.Process): def __init__(self,queue): super().__init__() self.queue=queue def run(self): while True: data=random.randint(0,100) self.queue.put(data) print("生产者生产了数据{}".format(data)) time.sleep(1) class Consumer(multiprocessing.Process): def __init__(self,queue): super().__init__() self.queue=queue def run(self): while True: item=self.queue.get() print("消费者消费{}".format(item)) if __name__ == '__main__': manger = multiprocessing.Manager() queue_m = manger.Queue() producer=Producer(queue_m) consumer=Consumer(queue_m) producer.start() consumer.start() producer.join() consumer.join() >>>生产者生产了数据20 消费者消费20 生产者生产了数据62 消费者消费62 生产者生产了数据26 消费者消费26 生产者生产了数据36 消费者消费36 生产者生产了数据56 消费者消费56

 浙公网安备 33010602011771号
浙公网安备 33010602011771号