

python基础(十二):正则、re模块、贪婪和非贪婪
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。
元字符:在正则表达式中被赋予特殊意义的符号。
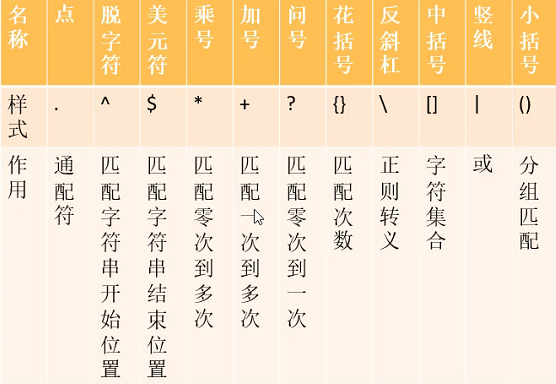
. 通配符
匹配除了\n外所有的字符。
import re str1='asdbcnv' str2=re.findall('.',str1) print(str2) >>>['a', 's', 'd', 'b', 'c', 'n', 'v']
^匹配字符串开始位置
搜索位置定在字符串开始位置
import re str1='asdbcnv' str2=re.findall('^a',str1) print(str2) >>>['a']
$匹配字符串结束位置
$要写在正则匹配的最后面
import re str1='asdbcnv' str2=re.findall('v$',str1) print(str2) >>>['v']
*匹配前面的正则0到无穷次
当匹配单个字符的时候,会因为匹配0次而出现空字符。
import re str1='iii amiiii ssdii i ' str2=re.findall('i*',str1) print(str2) >>>['iii', '', '', '', 'iiii', '', '', '', '', 'ii', '', 'i', '', '']
匹配多次的情况
import re str1='iii amiiii ssdii i ' str2=re.findall('ii*',str1) print(str2) >>>['iii', 'iiii', 'ii', 'i']
+匹配前面的正则1到无穷次
匹配单个字符
import re str1='iii amiiii ssdii i ' str2=re.findall('i+',str1) print(str2) >>>['iii', 'iiii', 'ii', 'i']
匹配多个字符
import re str1='iii amiiii ssdii i ' str2=re.findall('ii+',str1) print(str2) >>>['iii', 'iiii', 'ii']
?匹配前面正则0到1次
单个字符
import re str1='iii amiiii ssdii i ' str2=re.findall('i?',str1) print(str2) >>>['i', 'i', 'i', '', '', '', 'i', 'i', 'i', 'i', '', '', '', '', 'i', 'i', '', 'i', '', '']
多个字符
import re str1='iii amiiii ssdii i ' str2=re.findall('ii?',str1) print(str2) >>>['ii', 'i', 'ii', 'ii', 'ii', 'i']
{}匹配次数
匹配的次数N和M必须为正整数
{N,}匹配前面正则N到无穷次
import re str1='iii amiiii ssdii iihjf iiifgfdgi ' str2=re.findall('ii{2,}',str1) print(str2) >>>['iii', 'iiii', 'iii']
{,M}匹配前面的正则0到M次
import re str1='iii amiiii ssdii iihjf iiifgfdgi ' str2=re.findall('ii{,2}',str1) print(str2) >>>['iii', 'iii', 'i', 'ii', 'ii', 'iii', 'i']
{N,M}匹配前面的正则N到M次
import re str1='iii amiiii ssdii iihjf iiifgfdgi ' str2=re.findall('ii{1,2}',str1) print(str2) >>>['iii', 'iii', 'ii', 'ii', 'iii']
\正则转义符
在使用时需在字符串外加上 r 来取消转义
\d 数字
import re str1='iii amiiii 123er45vg44 ' str2=re.findall(r'\d',str1) print(str2) >>>['1', '2', '3', '4', '5', '4', '4']
\w 字母、数字、汉字和下划线
import re str1='iii am_你好iiii 123er45vg44 ' str2=re.findall(r'\w',str1) print(str2) >>>['i', 'i', 'i', 'a', 'm', '_', '你', '好', 'i', 'i', 'i', 'i', '1', '2', '3', 'e', 'r', '4', '5', 'v', 'g', '4', '4']
\s 匹配空白符号(\n,\t和空格)
import re str1='iii am_你好iiii 123\ner\t45vg44 ' str2=re.findall(r'\s',str1) print(str2) >>>[' ', ' ', '\n', '\t', ' ']
\b 单词边界
字符的位置是非常重要的。如果它位于要匹配的字符串的开始,它在单词的开始处查找匹配项。如果它位于字符串的结尾,它在单词的结尾处查找匹配项。
import re str1='i love python ' str2=re.findall(r'\bon',str1) str3=re.findall(r'on\b',str1) print(str2) print(str3) >>>[] ['on']
\D 匹配数字以外的字符
import re str1='i love python12456' str2=re.findall(r'\D',str1) print(str2) >>>['i', ' ', 'l', 'o', 'v', 'e', ' ', 'p', 'y', 't', 'h', 'o', 'n']
\S 匹配除了空白字符之外的
import re str1='i love python12456\n\t' str2=re.findall(r'\S',str1) print(str2) >>>['i', 'l', 'o', 'v', 'e', 'p', 'y', 't', 'h', 'o', 'n', '1', '2', '4', '5', '6']
\W 非\w匹配的字符
import re str1='i love ¥%*python12456\n\t' str2=re.findall(r'\W',str1) print(str2) >>>[' ', ' ', '¥', '%', '*', '\n', '\t']
\B 匹配非单词边界
对于 \B 非字边界运算符,位置并不重要,因为匹配不关心究竟是单词的开头还是结尾。
import re str1='i love python12456' str2=re.findall(r'ov\B',str1) print(str2) >>>['ov']
[]字符集,匹配中括号中间的所有字符
. % * + ? () {} 出现在中括号中仅表示字符本身。^字符在中括号中表示取反。
import re str1='i love python12456' str2=re.findall(r'[a-z]',str1) print(str2) >>>['i', 'l', 'o', 'v', 'e', 'p', 'y', 't', 'h', 'o', 'n']
import re str1='i love python12456' str2=re.findall(r'[^\d]',str1) print(str2) >>>['i', ' ', 'l', 'o', 'v', 'e', ' ', 'p', 'y', 't', 'h', 'o', 'n']
| 或
指明两项之间的一个选择。要匹配 |,请使用 \|。
import re str1='i love python12456\n\n' str2=re.findall(r'[\d|\s]',str1) print(str2) >>>[' ', ' ', '1', '2', '4', '5', '6', '\n', '\n']
()分组匹配
标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。只会匹配括号中的内容。
import re str1='i love python12456\n\n' str2=re.findall(r'n(\d)',str1) print(str2) >>>['1']
贪婪和非贪婪
正则表达式通常用于在文本中查找匹配的字符串。Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;非贪婪则相反,总是尝试匹配尽可能少的字符。在"*","?","+","{m,n}"后面加上?,使贪婪变成非贪婪。
贪婪模式下字符串查找会直接走到字符串结尾去匹配,如果不相等就向前寻找,这一过程称为回溯。

import re str1='<table><td><th>贪婪</th><th>贪婪</th><th>贪婪</th></td></table>贪婪' str2=re.findall(r'<.*>',str1) print(str2) >>>['<table><td><th>贪婪</th><th>贪婪</th><th>贪婪</th></td></table>']
非贪婪模式下会自左向右查找,一个一个匹配不会出现回溯的情况。

import re str1='<table><td><th>贪婪</th><th>贪婪</th><th>贪婪</th></td></table>贪婪' str2=re.findall(r'<.*?>',str1) print(str2) >>>['<table>', '<td>', '<th>', '</th>', '<th>', '</th>', '<th>', '</th>', '</td>', '</table>']
re模块
1、compile()
编译正则表达式模式,返回一个对象的模式。(可以把那些常用的正则表达式编译成正则表达式对象,这样可以提高一点效率。)
格式:
re.compile(pattern,flags=0)
pattern: 编译时用的表达式字符串。
flags 编译标志位,用于修改正则表达式的匹配方式,如:是否区分大小写,多行匹配等。常用的flags有:
| 标志 |
含义
|
|
re.S(DOTALL)
|
使.匹配包括换行在内的所有字符 |
|
re.I(IGNORECASE)
|
使匹配对大小写不敏感
|
|
re.L(LOCALE)
|
做本地化识别(locale-aware)匹配,法语等
|
|
re.M(MULTILINE)
|
多行匹配,影响^和$
|
|
re.X(VERBOSE)
|
该标志通过给予更灵活的格式以便将正则表达式写得更易于理解
|
|
re.U
|
根据Unicode字符集解析字符,这个标志影响\w,\W,\b,\B
|
import re
tt = "Tina is a good girl, she is cool, clever, and so on..."
rr = re.compile(r'\w*oo\w*')
print(rr.findall(tt)) #查找所有包含'oo'的单词
执行结果如下:
['good', 'cool']
2、match()
决定RE是否在字符串刚开始的位置匹配。//注:这个方法并不是完全匹配。当pattern结束时若string还有剩余字符,仍然视为成功。想要完全匹配,可以在表达式末尾加上边界匹配符'$'
格式:
re.match(pattern, string, flags=0)
print(re.match('com','comwww.runcomoob').group())
print(re.match('com','Comwww.runcomoob',re.I).group())
执行结果如下:
com
com
3、search()
格式:
re.search(pattern, string, flags=0)
re.search函数会在字符串内查找模式匹配,只要找到第一个匹配然后返回,如果字符串没有匹配,则返回None。
print(re.search('\dcom','www.4comrunoob.5com').group())
执行结果如下:
4com
*注:match和search一旦匹配成功,就是一个match object对象,而match object对象有以下方法:
- group() 返回被 RE 匹配的字符串
- start() 返回匹配开始的位置
- end() 返回匹配结束的位置
- span() 返回一个元组包含匹配 (开始,结束) 的位置
- group() 返回re整体匹配的字符串,可以一次输入多个组号,对应组号匹配的字符串。
a. group()返回re整体匹配的字符串,
b. group (n,m) 返回组号为n,m所匹配的字符串,如果组号不存在,则返回indexError异常
c.groups()groups() 方法返回一个包含正则表达式中所有小组字符串的元组,从 1 到所含的小组号,通常groups()不需要参数,返回一个元组,元组中的元就是正则表达式中定义的组。
import re
a = "123abc456"
print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(0)) #123abc456,返回整体
print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(1)) #123
print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(2)) #abc
print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(3)) #456
###group(1) 列出第一个括号匹配部分,group(2) 列出第二个括号匹配部分,group(3) 列出第三个括号匹配部分。###
4、findall()
re.findall遍历匹配,可以获取字符串中所有匹配的字符串,返回一个列表。
格式:
re.findall(pattern, string, flags=0)
p = re.compile(r'\d+')
print(p.findall('o1n2m3k4'))
执行结果如下:
['1', '2', '3', '4']
import re
tt = "Tina is a good girl, she is cool, clever, and so on..."
rr = re.compile(r'\w*oo\w*')
print(rr.findall(tt))
print(re.findall(r'(\w)*oo(\w)',tt))#()表示子表达式
执行结果如下:
['good', 'cool']
[('g', 'd'), ('c', 'l')]
5、finditer()
搜索string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器。找到 RE 匹配的所有子串,并把它们作为一个迭代器返回。
格式:
re.finditer(pattern, string, flags=0)
iter = re.finditer(r'\d+','12 drumm44ers drumming, 11 ... 10 ...')
for i in iter:
print(i)
print(i.group())
print(i.span())
执行结果如下:
<_sre.SRE_Match object; span=(0, 2), match='12'>
12
(0, 2)
<_sre.SRE_Match object; span=(8, 10), match='44'>
44
(8, 10)
<_sre.SRE_Match object; span=(24, 26), match='11'>
11
(24, 26)
<_sre.SRE_Match object; span=(31, 33), match='10'>
10
(31, 33)
6、split()
按照能够匹配的子串将string分割后返回列表。
可以使用re.split来分割字符串,如:re.split(r'\s+', text);将字符串按空格分割成一个单词列表。
格式:
re.split(pattern, string[, maxsplit])
maxsplit用于指定最大分割次数,不指定将全部分割。
print(re.split('\d+','one1two2three3four4five5'))
执行结果如下:
['one', 'two', 'three', 'four', 'five', '']
7、sub()
使用re替换string中每一个匹配的子串后返回替换后的字符串。
格式:
re.sub(pattern, repl, string, count)
import re
text = "JGood is a handsome boy, he is cool, clever, and so on..."
print(re.sub(r'\s+', '-', text))
执行结果如下:
JGood-is-a-handsome-boy,-he-is-cool,-clever,-and-so-on...
其中第二个函数是替换后的字符串;本例中为'-'
第四个参数指替换个数。默认为0,表示每个匹配项都替换。
re.sub还允许使用函数对匹配项的替换进行复杂的处理。
如:re.sub(r'\s', lambda m: '[' + m.group(0) + ']', text, 0);将字符串中的空格' '替换为'[ ]'。
import re
text = "JGood is a handsome boy, he is cool, clever, and so on..."
print(re.sub(r'\s+', lambda m:'['+m.group(0)+']', text,0))
执行结果如下:
JGood[ ]is[ ]a[ ]handsome[ ]boy,[ ]he[ ]is[ ]cool,[ ]clever,[ ]and[ ]so[ ]on...
8、subn()
返回替换次数
格式:
subn(pattern, repl, string, count=0, flags=0)
print(re.subn('[1-2]','A','123456abcdef'))
print(re.sub("g.t","have",'I get A, I got B ,I gut C'))
print(re.subn("g.t","have",'I get A, I got B ,I gut C'))
执行结果如下:
('AA3456abcdef', 2)
I have A, I have B ,I have C
('I have A, I have B ,I have C', 3)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号