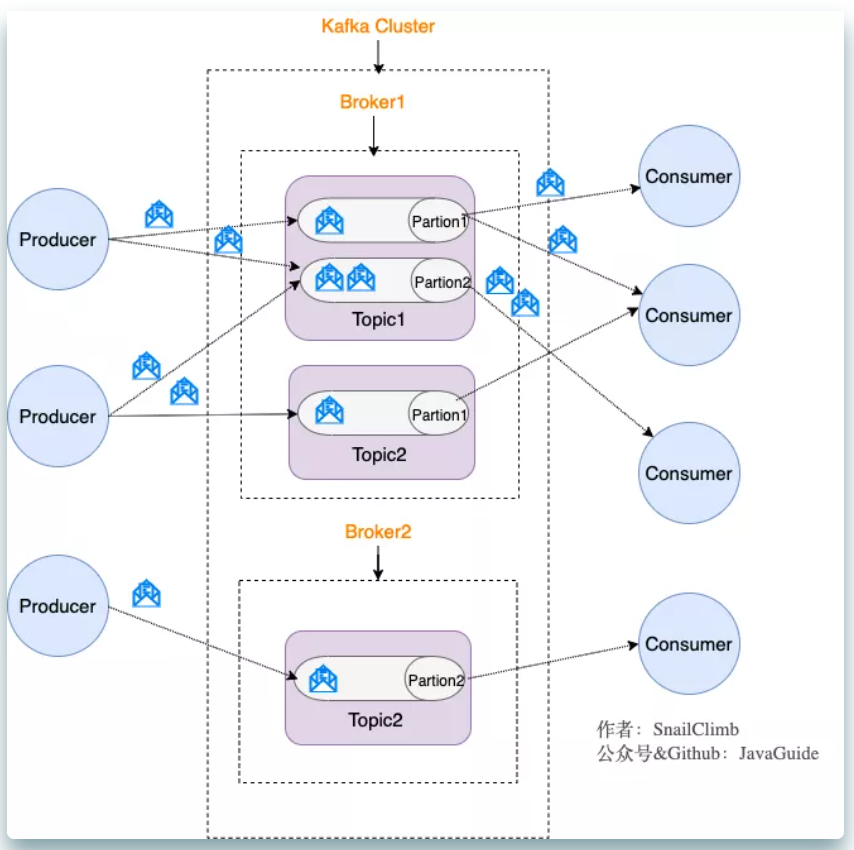
kafka的结构如下:
一、生产者
1、生产者(Producer)使用send方法 发送消息是异步的,所以可以通过get方法或回调函数拿到调用的结果。如果失败了,可以重试。
重试次数可以稍微大些,比如5次。间隔可以稍微长些。
二、消费者:
基础概念:当消息被追加到分区(partition)时,会为其分配一个偏移量(offset)。这个偏移量可以记录consumer消费到这个patition的哪个位置。
所以:kafka是通过偏移量(offset)来保证消息在某个分区的顺序的。
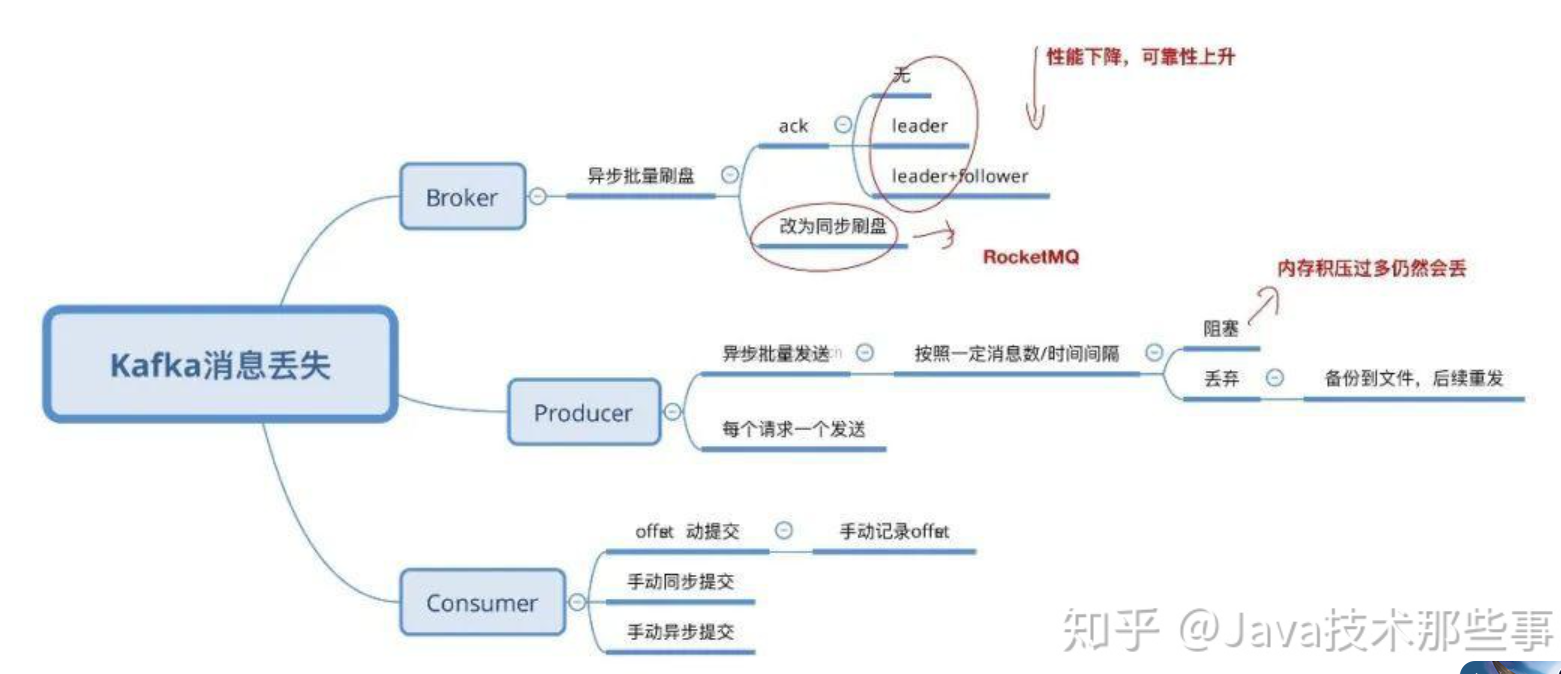
1、解决消费端丢失数据:关闭自动提交offset,等消费者处理完成后再手动提交offset。
2、kafka的partition有多副本机制,其中一个为leader,别的称之为follower。消息到了之后先存在leader,follower副本再去leader拉取同步,这样生产者和消费者都只和leader交互,follower副本是leader副本的备份,保证数据存储的安全性。
除此之外如果leader所在的broker挂了,那么会在follower之间选一个leader。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号