期末大作业
期末大作业
实验主题
本次实验尝试构建一个基本的异性交友推荐系统,推荐系统会根据每个用户对其它用户的历史评分向该用户推荐更多的从未见过的异性。实验暂且视其它用户为物品,那么,推荐系统中的数据可以抽象为一个称为偏好的三元组(用户,物品,偏好值),即一个偏好包含一个用户ID、一个物品ID,还有一个表达用户对物品的偏爱程度的数值。偏好值(preference value)可任意设定,只需保证更大的值代表更强的正向偏好。
理论知识
推荐算法
基于用户的推荐
基于用户的推荐算法是建立在用户间有某种相似性的基础之上,为用户推荐与它相似的用户所喜好的物品,这些物品是用户从未接触过的。这种算法很直观,比如,两个男生喜欢的游戏大部分是相同的,那么除去这些相同游戏,向各自推荐不同的游戏,这样的游戏大概率也是对方喜欢的。
下面是一个为用户(记为u)进行推荐的过程:
for(用户u尚未表达偏好的)每个物品i
for(对i有偏好的)每个其他用户v
计算u和v之间的相似度s
按权重为s将v对i的偏好并入平均值
return值最高的物品(按加权平均排序)
外层循环把每个已知的、用户未对其表达过偏好的物品作为候选的推荐项。内层循环逐个计算该用户和对候选物品做过评价的其他用户的相似程度。最终,将相似程度作为加权因子,计算出目标用户对该物品偏好值的预测。与目标用户越相似,他的偏好值所占权重越大。
但是,实际应用中,不可能检查每个物品。我们通常会先计算出一个最相似用户的邻域, 然后仅考虑领域内用户评价过的物品。那么,算法便优化成:
for每个其他用户w
计算用户u和用户w的相似度s
按相似度排序后,将位置靠前的用户作为邻域n
for(n中用户有偏好,而用户u无偏好的)每个物品i
for(n中用户对i有偏好的)每个其他用户v
计算用户u和用户v的相似度s
按权重s将v对i的偏好并入平均值
可见,该算法的主要思想是首先确定相似的用户,再考虑这些最相似用户对什么物品感兴趣。
用户邻域
1、固定大小的邻域
通过确定最相似用户的数量来定义用户的邻域。
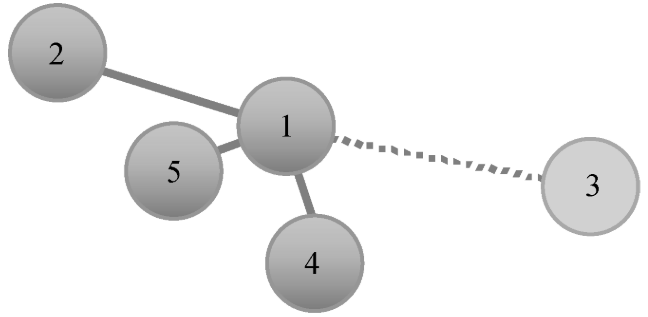
距离表示相似度: 越远则越不相似。用户1的邻域由3个最相似的用户组成:5、4和2
2、基于阈值的邻域
确定一个相似度阈值,并选择所有相似度超过这个阈值的用户。
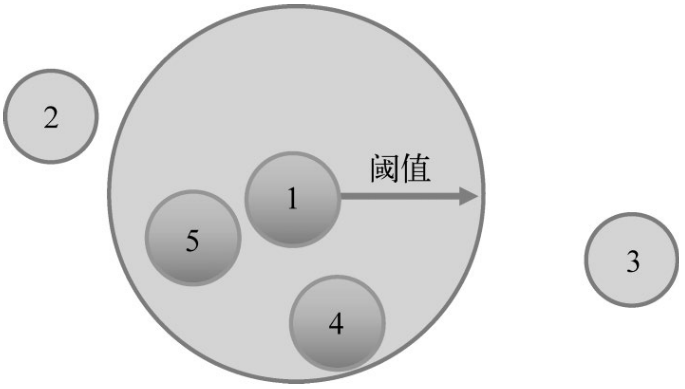
相似性度量
如果对用户之间的相似性缺乏可靠并有效的定义,这类推荐方法是没有意义的。因此,需要找到科学的度量相似性的方法。
1、皮尔逊相关系数
皮尔逊相关系数是一个介于 -1 和 1 之间的数,它度量两个一一对应的数列之间的线性相关程度。皮尔逊相关系数是两个序列协方差与二者标准差乘积的比值。 协方差计算的是两个序列变化趋势一致的绝对量,除以方差则是为了对这一变化进行归一化。
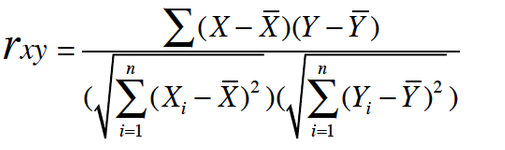
存在的问题
- 没有考虑两个用户同时给出偏好值的物品数目
- 如果两个用户的交集仅包含一个物品,则无法计算相关性(分母为0,NaN)
- 只要任何一个序列中出现偏好值相同的情况,则无法计算相关性(分母为0,NaN)
2、欧氏距离
将用户视为多维空间中的点(维数等于总的物品数,偏好值是坐标)计算两个用户点之间的欧氏距离d,取1/(1+d)为相似度。
3、余弦相似性
将用户视为多维空间中的点(维数等于总的物品数,偏好值是坐标)假设有两条从原点出发,分别到这两个点的射线。计算两条射线之间的夹角的余弦值,越接近1,用户越相似。
3、谷本系数
不管一个用户对一个物品的偏好值是高还是低,只关心用户是否表达过偏好。由两个用户共同表达过偏好的物品数目除以至少一个用户表达过偏好的物品数 目而得。
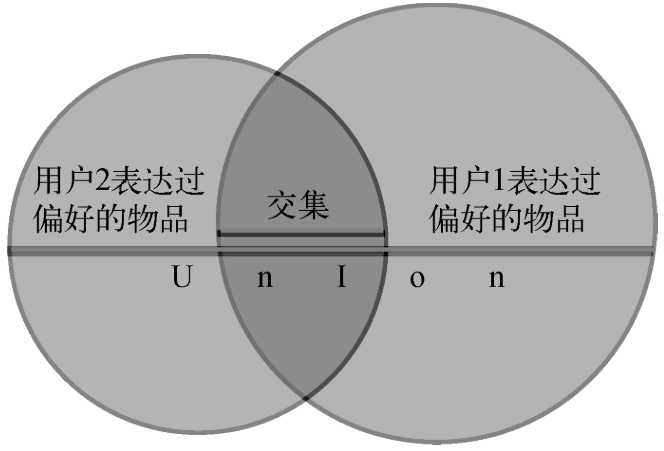
如图,谷本系数 = 交集中的物品数 / 并集中的物品数。当两个用户的偏好集合完全重合时,结果为1.0。当他们没有任何共同点时,结果为0.0。结果永远不会为负。
基于物品的推荐
基于物品的推荐是以物品(而不是用户)之间的相似度为基础的。
算法:
for(用户u尚未表达偏好的)每个物品i
for(用户u表达偏好的)每个物品j
计算i和j之间的相似度s
按权重为s将u对j的偏好并入平均值
return 值最高的物品(按加权平均排序)
基于线性插值物品的推荐
通过用户已评估过的物品的加权平均来估计偏好值,但权重不再是相似度,而是用一些线性代数技术计算出的所有物品对之间的最优权重集合。
基于聚类的推荐
将所有用户划分到不同簇,它将物品推荐给相似用户簇,而不是具体用户,这样,推荐的物品就会被尽可能多的用户接受。但是,聚类会花费很长的时间。
评估一个推荐系统
推荐系统需要能够准确预测用户所有喜好和行为,并且喜好把物品进行排序。一个推荐系统的准确性是很重要的,但是如何评估一个推荐系统是否足够准确呢?
一种评估推荐系统准确性的方法是评估其估计偏好值与实际偏好值的差异程度。实验打造的推荐系统试图给出用户对某些或其他所有物品的估计评分实际上是数值型数据,因此可以使用平均差值与均方根来度量差异程度。
注:平均差值与均方根的计算说明
| 物品1 | 物品2 | 物品3 | |
|---|---|---|---|
| 真实值 | 3.0 | 5.0 | 4.0 |
| 估计值 | 3.5 | 2.0 | 5.0 |
| 差值 | 0.5 | 3.0 | 1.0 |
平均差值 =(0.5+3.0+1.0)/ 3 = 1.5 均方根 = \(\sqrt{(0.5^2+3.0^2+1.0^2)/3}\) = 1.8484
推荐系统实践
分析样本数据
数据来自Líbímseti,该网站的用户可以对其他用户的档案进行评分,分值从1到10不等。分值为1代表不喜欢,分值为10代表喜欢。这个数据集由Vaclav Petricek进行了预处理:剔除了生成评分个数不到20个的用户。而且,其中排除了几乎对每个档案都给出相同分值的用户。
该数据集有17 359 346份评分,包含用户对物品的明确评分,这里的物品为其他人的用户档案。这意味着建立在该数据上的推荐系统是将人推荐给人。在数据中存在135 359个独立用户,总共评价了168 791个独立的用户档案,因为用户和物品的个数大致相同,基于用户和基于物品的推荐都不会明显更优。
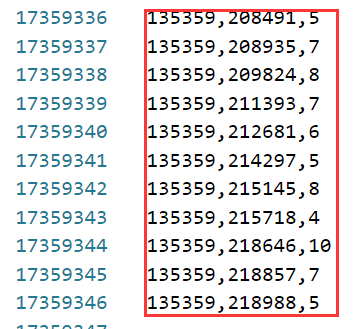
其中,第一列是用户ID,第二列是档案ID,第三列是评分。此外,还有一个文件标识每个用户的性别。
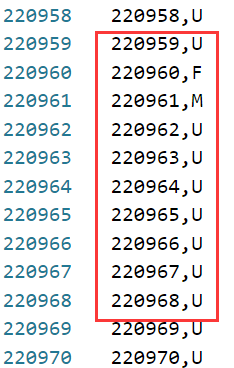
可见,第一列为用户ID,第二列为用户性别。其中,F(Female)表示性别女,M(Male)表示性别男,U(Unknown)表示性别未知。既然用户拥有了性别属性,那么,如果不考虑性别属性只根据评分进行推荐,结果肯定差强人意。因为当被推荐时,男性档案之间会比男性档案和女性档案之间表现得更像,反之亦然。如果某个用户的大多数或全部评分都面向男性档案,就有理由相信该用户对与男性档案约会的意愿远比女性档案更强。所以,性别属性可以作为优化推荐结果的一种参考途径,以使推荐系统变得更为准确。但是,暂时先不考虑性别属性,考查一下哪一种算法模型更适合该数据集。在该数据模型的基础上优化相似性度量机制,可以使推荐结果趋向最优。
实验准备从基于用户的推荐和基于物品的推荐两个推荐模型中挑选一个更优的算法模型进行后续实验。
基于用户的推荐
选择多种不同的相似性度量和邻域定义组合,以平均差值作为评估准则,对数据集进行测试。
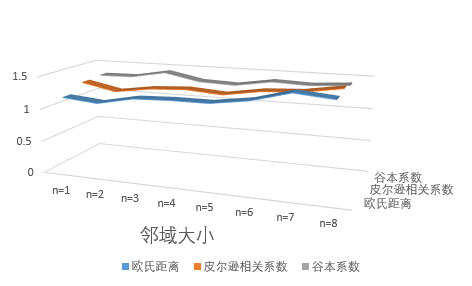
1、基于相似性度量和n最近邻评估的推荐程序,所得到的估计和实际偏好值之间的平均绝对差值:
| 相似性度量标准 | n=1 | n=2 | n=3 | n=4 | n=5 | n=6 | n=7 | n=8 |
|---|---|---|---|---|---|---|---|---|
| 欧氏距离 | 1.17 | 1.12 | 1.23 | 1.25 | 1.25 | 1.33 | 1.48 | 1.43 |
| 皮尔逊相关系数 | 1.30 | 1.19 | 1.27 | 1.30 | 1.26 | 1.35 | 1.38 | 1.47 |
| 谷本系数 | 1.32 | 1.33 | 1.43 | 1.32 | 1.30 | 1.39 | 1.37 | 1.41 |
2、基于相似性度量和阈值最近邻评估推荐程序,所得到的估计和实际偏好值之间的平均绝对差值:
| 相似性度量标准 | t=0.95 | t=0.9 | t=0.85 | t=0.8 | t=0.75 | t=0.7 |
|---|---|---|---|---|---|---|
| 欧氏距离 | 1.33 | 1.37 | 1.39 | 1.43 | 1.41 | 1.47 |
| 皮尔逊相关系数 | 1.47 | 1.4 | 1.42 | 1.4 | 1.38 | 1.37 |
| 谷本系数 | NaN | NaN | NaN | NaN | NaN | NaN |
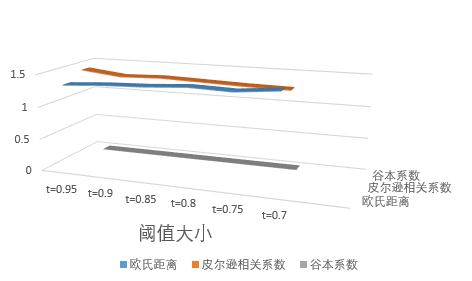
从结果可见,粗略的最佳方案为:
- 基于用户的推荐程序;
- 欧氏距离相似性度量;
- 两个最近邻的邻域。
评估程序源代码
public class UserBasedEvaluator {
public static void main(String[] args) throws IOException, TasteException {
DataModel dataModel = new FileDataModel(new File(DataSource.PREFSFILEPATH));
RandomUtils.useTestSeed();//生成可重复的结果
AverageAbsoluteDifferenceRecommenderEvaluator evaluator = new AverageAbsoluteDifferenceRecommenderEvaluator();
RecommenderBuilder builder = new RecommenderBuilder() {
public Recommender buildRecommender(DataModel dataModel) throws TasteException {
// 皮尔逊相关系数
// PearsonCorrelationSimilarity similarity1 = new PearsonCorrelationSimilarity(dataModel);
// 欧式距离
EuclideanDistanceSimilarity similarity1 = new EuclideanDistanceSimilarity(dataModel);
// 谷本系数
// TanimotoCoefficientSimilarity similarity1 = new TanimotoCoefficientSimilarity(dataModel);
// 使用缓存
CachingUserSimilarity similarity = new CachingUserSimilarity(similarity1, dataModel);
// 固定大小邻域
NearestNUserNeighborhood neighborhood1 = new NearestNUserNeighborhood(2, similarity, dataModel);
// 阈值领域
// ThresholdUserNeighborhood neighborhood1 = new ThresholdUserNeighborhood(0.95, similarity, dataModel);
CachingUserNeighborhood neighborhood = new CachingUserNeighborhood(neighborhood1, dataModel);
return new GenericUserBasedRecommender(dataModel, neighborhood, similarity);
}
};
// 使用 10%的数据作为评估测试数据集,其中95%的数据用于training,5%的数据用于testing
// double score = evaluator.evaluate(builder, null, dataModel, 0.95, 0.1);
Scanner scanner = new Scanner(System.in);
double para[] = new double[2];
int i = 1;
while (scanner.hasNext()) {
i = 1 - i;
para[i] = Double.parseDouble(scanner.next());
if (i == 1) {
// 使用para[0]的数据用于训练,1-para[0]的数据用于测试,para[1]表示使用的数据量
evaluator.evaluate(builder, null, dataModel, para[0], para[1]);
}
}
}
}
基于物品的推荐
直接每个相似性度量都尝试一遍,得到如下结果:
| 相似性度量标准 | 平均误差 |
|---|---|
| 欧氏距离 | 2.36 |
| 皮尔逊相关系数 | 2.32 |
| 谷本系数 | 2.40 |
平均误差,即估计值和实际值的平均差值,翻了大概两倍,具体值超过了2。可见,基于物品的推荐比基于用户的推荐效果来的差。
评估程序源代码
public class ItemBasedEvaluator {
public static void main(String[] args) throws IOException, TasteException {
DataModel dataModel = new FileDataModel(new File(".\\libimseti\\ratings.dat"));
RecommenderBuilder builder = new RecommenderBuilder() {
public Recommender buildRecommender(DataModel dataModel) throws TasteException {
// 皮尔逊相关系数
// PearsonCorrelationSimilarity similarity1 = new PearsonCorrelationSimilarity(dataModel);
// 欧式距离
EuclideanDistanceSimilarity similarity1 = new EuclideanDistanceSimilarity(dataModel);
// 谷本系数
// TanimotoCoefficientSimilarity similarity1 = new TanimotoCoefficientSimilarity(dataModel);
// 使用缓存
CachingItemSimilarity similarity = new CachingItemSimilarity(similarity1, dataModel);
return new GenericItemBasedRecommender(dataModel, similarity);
}
};
AverageAbsoluteDifferenceRecommenderEvaluator evaluator = new AverageAbsoluteDifferenceRecommenderEvaluator();
// double score = evaluator.evaluate(builder, null, dataModel, 0.95, 0.1);
Scanner scanner = new Scanner(System.in);
double para[] = new double[2];
int i = 1;
while (scanner.hasNext()) {
i = 1 - i;
para[i] = Double.parseDouble(scanner.next());
if (i == 1) {
// 使用para[0]的数据用于训练,1-para[0]的数据用于测试,para[1]表示使用的数据量
evaluator.evaluate(builder, null, dataModel, para[0], para[1]);
}
}
}
}
综上,后续实验将采用基于用户、采用欧氏距离相似性度量以及两个最近邻的推荐模型。
引入性别信息
性别过滤器
为了更好得形成推荐结果,需要结合性别信息对推荐结果进行筛选过滤。这里使用IDRescorer组件对用户档案进行过滤。
过滤器的主要思想:首先,通过检查用户已经评价过的档案的性别,来猜测该用户所偏好的性别。然后,就可以滤除与之性别相反的档案。
整体架构:
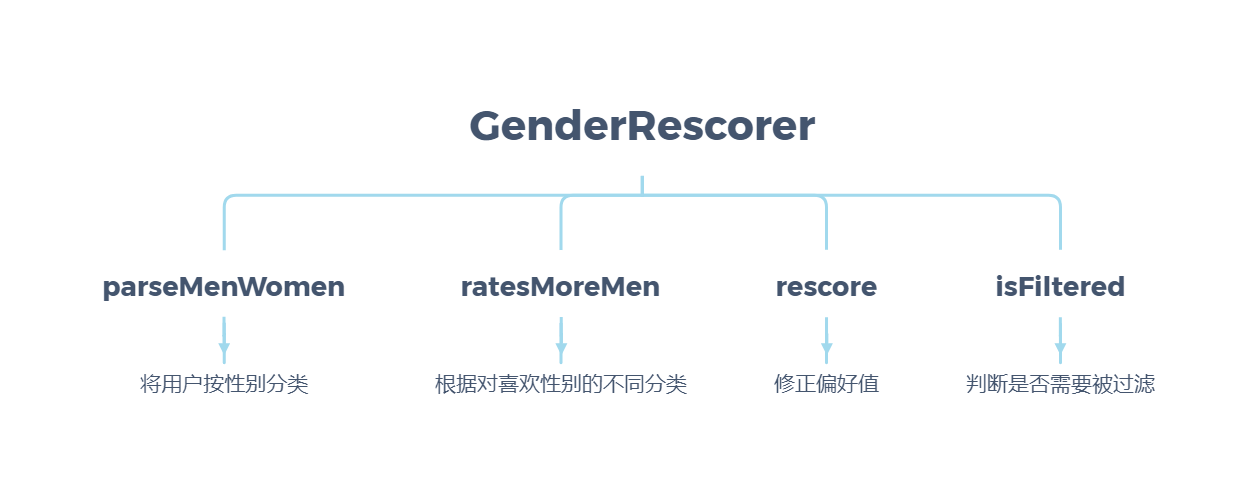
完整代码:
public class GenderRescorer implements IDRescorer {
private final FastIDSet men;// 性别为男的用户集合
private final FastIDSet women;//性别为女的用户集合
private final FastIDSet usersRateMoreMen;// 更偏向男性的用户集合
private final FastIDSet usersRateLessMen;// 更偏向女性的用户集合
private final boolean filterMen;
public GenderRescorer(FastIDSet men,
FastIDSet women,
FastIDSet usersRateMoreMen,
FastIDSet usersRateLessMen,
long userID, DataModel model)
throws TasteException {
this.men = men;
this.women = women;
this.usersRateMoreMen = usersRateMoreMen;
this.usersRateLessMen = usersRateLessMen;
this.filterMen = ratesMoreMen(userID, model);
}
public static FastIDSet[] parseMenWomen(File genderFile)
throws IOException {
FastIDSet men = new FastIDSet(50000);
FastIDSet women = new FastIDSet(50000);
for (String line : new FileLineIterable(genderFile)) {
int comma = line.indexOf(',');
char gender = line.charAt(comma + 1);
if (gender == 'U') {
continue;
}
long profileID = Long.parseLong(line.substring(0, comma));
if (gender == 'M') {
// 性别为男,加入男性集合
men.add(profileID);
} else {
// 性别为女,加入女性集合
women.add(profileID);
}
}
men.rehash();
women.rehash();
return new FastIDSet[]{men, women};
}
private boolean ratesMoreMen(long userID, DataModel model)
throws TasteException {
// 使用记忆化存储的方法减少重复计算
if (usersRateMoreMen.contains(userID)) {
return true;
}
if (usersRateLessMen.contains(userID)) {
return false;
}
PreferenceArray prefs = model.getPreferencesFromUser(userID);
int menCount = 0;
int womenCount = 0;
// 记录用户对不同性别的评分个数
for (int i = 0; i < prefs.length(); i++) {
long profileID = prefs.get(i).getItemID();
if (men.contains(profileID)) {
menCount++;
} else if (women.contains(profileID)) {
womenCount++;
}
}
boolean ratesMoreMen = menCount > womenCount;
if (ratesMoreMen) {
// 用户对男性的评价比对女性的评价多,故认为用户更喜欢男性
usersRateMoreMen.add(userID);
} else {
// 用户对女性的评价比对男性的评价多,故认为用户更喜欢女性
usersRateLessMen.add(userID);
}
return ratesMoreMen;
}
@Override
public double rescore(long profileID, double originalScore) {
// 修正偏好值,如果用户更喜欢男性,那么将修正推荐结果中的女性档案评分,反之亦然。
return isFiltered(profileID) ? Double.NaN : originalScore;
}
@Override
public boolean isFiltered(long profileID) {
// 重写过滤方法
return filterMen ? men.contains(profileID) : women.contains(profileID);
}
}
代码说明:
parseMenWomen()方法解析性别文件并创建男性用户ID集合和女性用户ID集合。
ratesMoreMen()方法用来计算用户的性别喜好并记忆化存储为两个集合,喜欢男性的集合和喜欢女性的集合。
重写rescore()方法和isFiltered()方法用于在适当的情况下排除掉男性或女性。
定制和封装推荐器
下面将现有的推荐引擎和IDRescorer过滤器封装在一个推荐器中,这样,就可以部署为一个完整的web推荐引擎。
整体架构:
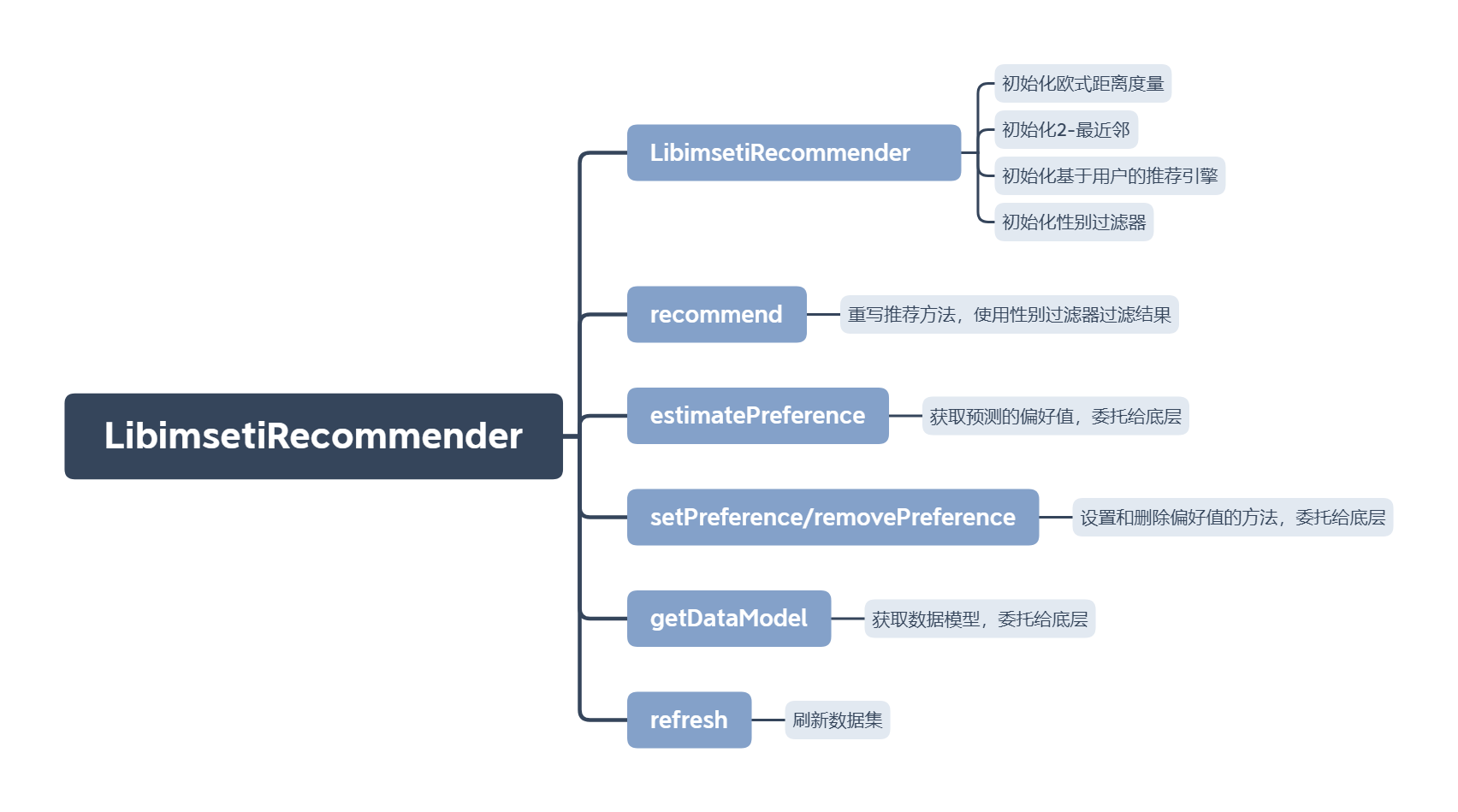
完整代码:
public class LibimsetiRecommender implements Recommender {
private final Recommender delegate;
private final DataModel model;
private final FastIDSet men;
private final FastIDSet women;
private final FastIDSet usersRateMoreMen;
private final FastIDSet usersRateLessMen;
public LibimsetiRecommender() throws TasteException, IOException {
this(new FileDataModel(readResourceToTempFile(DataSource.GENDERFILEPATH)));
}
public LibimsetiRecommender(DataModel model) throws TasteException, IOException {
// 构造函数,将推荐引擎初始化为基于用户、采用欧氏距离的2-最近邻推荐,并初始化性别过滤器。
UserSimilarity similarity = new EuclideanDistanceSimilarity(model);
CachingUserSimilarity cachingUserSimilarity = new CachingUserSimilarity(similarity, model);
UserNeighborhood neighborhood = new NearestNUserNeighborhood(2, similarity, model);
CachingUserNeighborhood cachingUserNeighborhood = new CachingUserNeighborhood(neighborhood, model);
// delegate = new GenericUserBasedRecommender(model, neighborhood, similarity);
delegate = new GenericUserBasedRecommender(model, cachingUserNeighborhood, cachingUserSimilarity);
this.model = model;
FastIDSet[] menWomen = GenderRescorer.parseMenWomen(readResourceToTempFile(DataSource.GENDERFILEPATH));
// FastIDSet[] menWomen = GenderRescorer.parseMenWomen(new File(DataSource.GENDERFILEPATH));
men = menWomen[0];
women = menWomen[1];
usersRateMoreMen = new FastIDSet(50000);
usersRateLessMen = new FastIDSet(50000);
}
@Override
public List<RecommendedItem> recommend(long userID, int howMany) throws TasteException {
// 重写推荐方法,并使用性别过滤器对推荐结果进行过滤
IDRescorer rescorer = new GenderRescorer(men, women, usersRateMoreMen, usersRateLessMen, userID, model);
return delegate.recommend(userID, howMany, rescorer);
}
@Override
public List<RecommendedItem> recommend(long userID,
int howMany,
IDRescorer rescorer) throws TasteException {
// 重写推荐方法,委托给底层推荐程序
return delegate.recommend(userID, howMany, rescorer);
}
@Override
public float estimatePreference(long userID, long itemID) throws TasteException {
// 重写获取偏好值(评分)的方法
IDRescorer rescorer = new GenderRescorer(
men, women, usersRateMoreMen, usersRateLessMen, userID, model);
return (float) rescorer.rescore(
itemID, delegate.estimatePreference(userID, itemID));
}
@Override
public void setPreference(long userID, long itemID, float value) throws TasteException {
// 重写设置偏好值的方法,委托给底层推荐程序
delegate.setPreference(userID, itemID, value);
}
@Override
public void removePreference(long userID, long itemID) throws TasteException {
// 重写移除偏好值的方法,委托给底层推荐程序
delegate.removePreference(userID, itemID);
}
@Override
public DataModel getDataModel() {
// 重写获取数据模型的方法
return delegate.getDataModel();
}
@Override
public void refresh(Collection<Refreshable> alreadyRefreshed) {
// 重写底层数据刷新的方法,当文件中的数据发生改变时,重新加载数据
delegate.refresh(alreadyRefreshed);
}
static File readResourceToTempFile(String resourceName) throws IOException {
// 读取数据到临时文件中
String absoluteResource = resourceName.startsWith("/") ? resourceName : '/' + resourceName;
InputSupplier<? extends InputStream> inSupplier;
try {
URL resourceURL = Resources.getResource(LibimsetiRecommender.class, absoluteResource);
inSupplier = Resources.newInputStreamSupplier(resourceURL);
} catch (IllegalArgumentException iae) {
File resourceFile = new File(resourceName);
inSupplier = Files.newInputStreamSupplier(resourceFile);
}
File tempFile = File.createTempFile("taste", null);
tempFile.deleteOnExit();
Files.copy(inSupplier, tempFile);
return tempFile;
}
}
冷启动问题
实验进行到目前为止,整个推荐系统看似小而完善,但还是存在一个比较严重的问题:如何对游客(没有对任何其它用户进行评价的用户)进行推荐呢?因为后台并没有游客的数据,无法进行个性化的推荐,这时就无数据可用,无历史可寻。
对于这个问题,我采用的解决方法是,生成一个临时用户,随机产生该临时用户对其它用户的评分。把为这个临时用户推荐看作是为游客推荐。我把该临时用户称为匿名用户。
带匿名用户的推荐器
该推荐器继承上一部分所示的定制的推荐器,将数据模型转为可存储匿名用户的数据模型,并重写了推荐方法,使得能够对匿名用户进行推荐,因为该用户在真实的数据模型中并不存在。
整体架构:
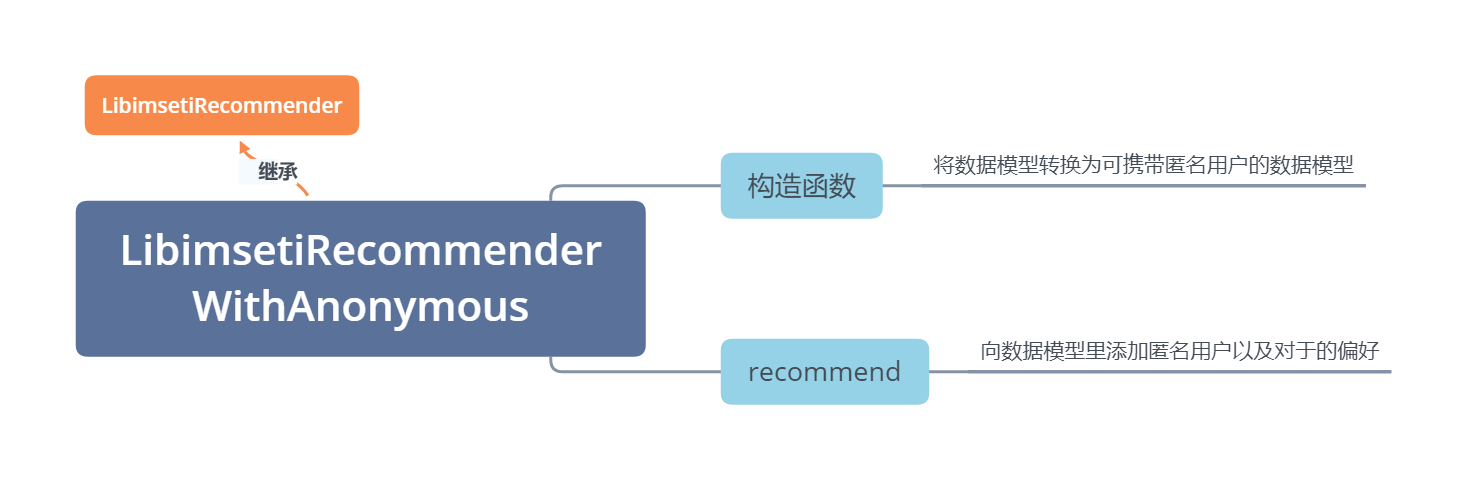
完整代码:
public class LibimsetiRecommenderWithAnonymous
extends LibimsetiRecommender {
private final PlusAnonymousUserDataModel plusAnonymousModel;
public LibimsetiRecommenderWithAnonymous() throws TasteException, IOException {
this(new FileDataModel(readResourceToTempFile(DataSource.PREFSFILEPATH)));
}
public LibimsetiRecommenderWithAnonymous(DataModel model) throws TasteException, IOException {
super(new PlusAnonymousUserDataModel(model));
// 将数据模型转换为可携带匿名用户的数据模型
plusAnonymousModel = (PlusAnonymousUserDataModel) getDataModel();
}
// 为匿名用户进行推荐
public synchronized List<RecommendedItem> recommend(PreferenceArray anonymousUserPrefs,
int howMany) throws TasteException {
// 向数据模型中添加匿名用户,并生成临时偏好值,用于为匿名用户推荐
plusAnonymousModel.setTempPrefs(anonymousUserPrefs);
List<RecommendedItem> recommendations =
recommend(PlusAnonymousUserDataModel.TEMP_USER_ID, howMany, null);
plusAnonymousModel.clearTempPrefs();
return recommendations;
}
}
WEB请求处理
处理过程:
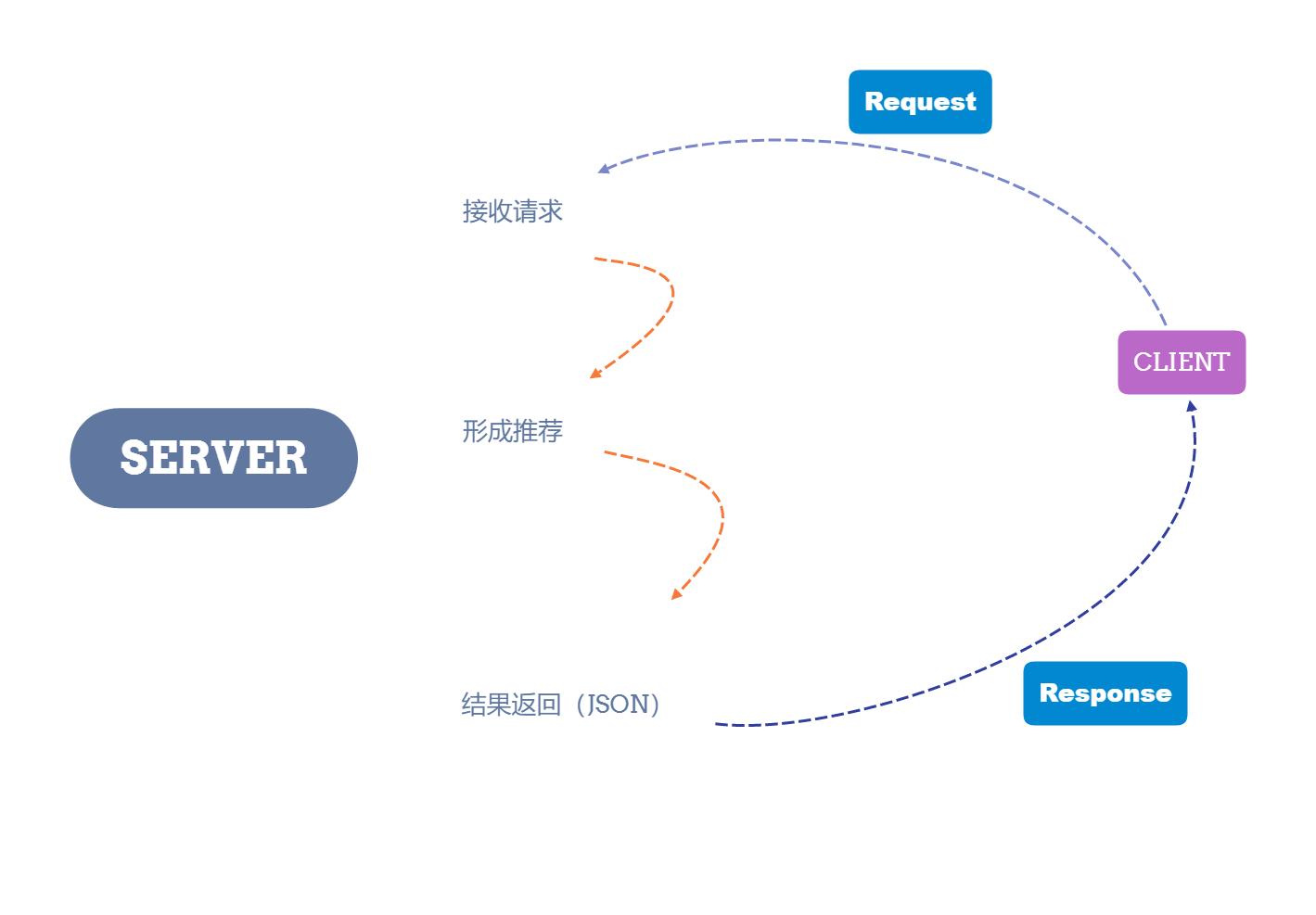
完整代码:
public class getResult extends HttpServlet {
protected static DataModel model;
protected static LibimsetiRecommenderWithAnonymous recommender;
protected static PreferenceArray anonymousPrefs;
static {
try {
model = new FileDataModel(new File(DataSource.PREFSFILEPATH));
recommender = new LibimsetiRecommenderWithAnonymous(model);
anonymousPrefs = new GenericUserPreferenceArray(3);
// 为匿名用户进行相关设置
anonymousPrefs.setUserID(0, PlusAnonymousUserDataModel.TEMP_USER_ID);
anonymousPrefs.setItemID(0, 123L);
anonymousPrefs.setValue(0, 1.0f);
anonymousPrefs.setItemID(1, 123L);
anonymousPrefs.setValue(1, 3.0f);
anonymousPrefs.setItemID(2, 123L);
anonymousPrefs.setValue(2, 2.0f);
} catch (TasteException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
doPost(req, resp);
}
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
String userIDString = req.getParameter("userID");
String howManyString = req.getParameter("howMany");
int howMany = howManyString == null ? 20 : Integer.parseInt(howManyString);
if (userIDString == null) {
// 将请求视为匿名用户
// throw new ServletException("userID was not specified");
try {
// 推荐结果
List<RecommendedItem> items = recommender.recommend(anonymousPrefs, howMany);
writeJSON(resp, items);
} catch (TasteException e) {
e.printStackTrace();
}
} else {
long userID = Long.parseLong(userIDString);
try {
// 推荐结果
List<RecommendedItem> items = recommender.recommend(userID, howMany);
writeJSON(resp, items);
} catch (TasteException e) {
e.printStackTrace();
}
}
resp.getWriter().write("\nSession ID:" + req.getRequestedSessionId() + "\n" +
"Server IP Address:" + Inet4Address.getLocalHost().getHostAddress() + "\n");
resp.getWriter().close();
}
//以JSON格式返回
private static void writeJSON(HttpServletResponse response, Iterable<RecommendedItem> items) throws IOException {
response.setContentType("application/json");
response.setCharacterEncoding("UTF-8");
response.setHeader("Cache-Control", "no-cache");
PrintWriter writer = response.getWriter();
writer.print("{\"recommendedItems\":{\"item\":[");
boolean first = true;
Iterator var4 = items.iterator();
while (var4.hasNext()) {
RecommendedItem recommendedItem = (RecommendedItem) var4.next();
if (first) {
first = false;
} else {
writer.print(',');
}
writer.print("{\"value\":\"");
writer.print(recommendedItem.getValue());
writer.print("\",\"id\":\"");
writer.print(recommendedItem.getItemID());
writer.print("\"}");
}
writer.println("]}}");
}
}
至此,只需要将该WEB项目打成war包,并进一步部署即可。
推荐系统部署
我们小组实验项目的本质是作为一个WEB服务,所使用的框架是nginx+tomcat+redis,并利用redis实现共享session和负载均衡的功能。负载均衡是为了能够应付短时高并发的的情况,而session是为了记录用户会话信息,因为目前网络中所使用的http是无状态协议,服务器是无法获知每一个请求是否是同一个用户,session正好解决这个问题。共享session是解决了在负载均衡的情况下,每次用户发送的请求会由不同的tomcat来处理而导致session重新创建的问题,想要每台tomcat都对同一个用户有唯一的session认证,那就需要共享session处理。
服务器配置部分由组员高鹏和钟博协作完成,高鹏负责按非微服务方式(传统方式)搭建服务器环境并记录成博客,而钟博负责将传统方式的搭建转为微服务方式并记录成博客。组长陈志明对钟博提供的配置文件做适当修改(文件volumes映射)后进行部署。
部署所使用到的文件如下所示:
最终使用的docker-compose.yml文件内容如下所示:
version: "3.8"
services:
nginx:
image: nginx
container_name: cngx
ports:
- 80:2420
volumes:
- ./nginx/default.conf:/etc/nginx/conf.d/default.conf # 挂载配置文件
depends_on:
- tomcat1
- tomcat2
- tomcat3
tomcat1:
image: tomcat:7.0
container_name: ctc1
volumes:
- ./tomcat/apps:/usr/local/tomcat/webapps
- ./data/:/usr/local/recommender/data/
- ./tomcat/context.xml:/usr/local/tomcat/conf/context.xml
- ./tomcat/lib/commons-pool2-2.2.jar:/usr/local/tomcat/lib/commons-pool2-2.2.jar
- ./tomcat/lib/jedis-2.5.2.jar:/usr/local/tomcat/lib/jedis-2.5.2.jar
- ./tomcat/lib/tomcat-redis-session-manager-master-2.0.0.jar:/usr/local/tomcat/lib/tomcat-redis-session-manager-master-2.0.0.jar
links:
- redis:redis
tomcat2:
image: tomcat:7.0
container_name: ctc2
volumes:
- ./tomcat/apps:/usr/local/tomcat/webapps
- ./data/:/usr/local/recommender/data/
- ./tomcat/context.xml:/usr/local/tomcat/conf/context.xml
- ./tomcat/lib/commons-pool2-2.2.jar:/usr/local/tomcat/lib/commons-pool2-2.2.jar
- ./tomcat/lib/jedis-2.5.2.jar:/usr/local/tomcat/lib/jedis-2.5.2.jar
- ./tomcat/lib/tomcat-redis-session-manager-master-2.0.0.jar:/usr/local/tomcat/lib/tomcat-redis-session-manager-master-2.0.0.jar
links:
- redis:redis
tomcat3:
image: tomcat:7.0
container_name: ctc3
volumes:
- ./tomcat/apps:/usr/local/tomcat/webapps
- ./data/:/usr/local/recommender/data/
- ./tomcat/context.xml:/usr/local/tomcat/conf/context.xml
- ./tomcat/lib/commons-pool2-2.2.jar:/usr/local/tomcat/lib/commons-pool2-2.2.jar
- ./tomcat/lib/jedis-2.5.2.jar:/usr/local/tomcat/lib/jedis-2.5.2.jar
- ./tomcat/lib/tomcat-redis-session-manager-master-2.0.0.jar:/usr/local/tomcat/lib/tomcat-redis-session-manager-master-2.0.0.jar
links:
- redis:redis
redis:
image: redis
container_name: redis
expose:
- "6379"
ports:
- "6379:6379"
restart: always
volumes:
- ./redis/redis.conf:/usr/local/etc/redis/redis.conf
command: redis-server /usr/local/etc/redis/redis.conf --appendonly yes
使用命令docker-compose up启动容器,并通过浏览器访问查看部署情况。
使用URL访问WEB服务,未指定userID参数,视为向匿名用户推荐:
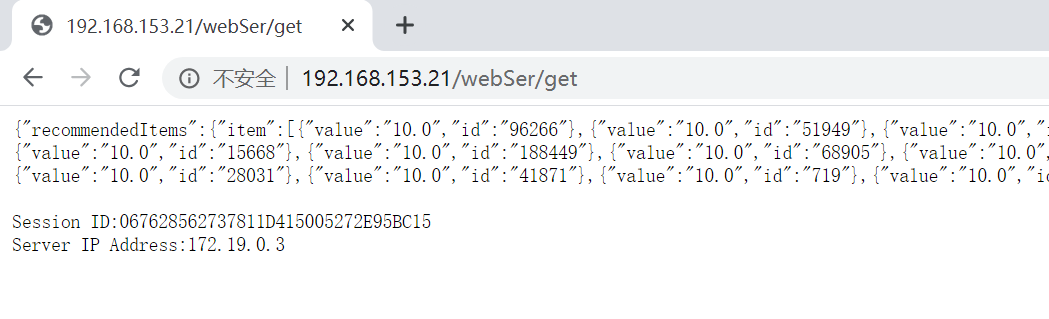
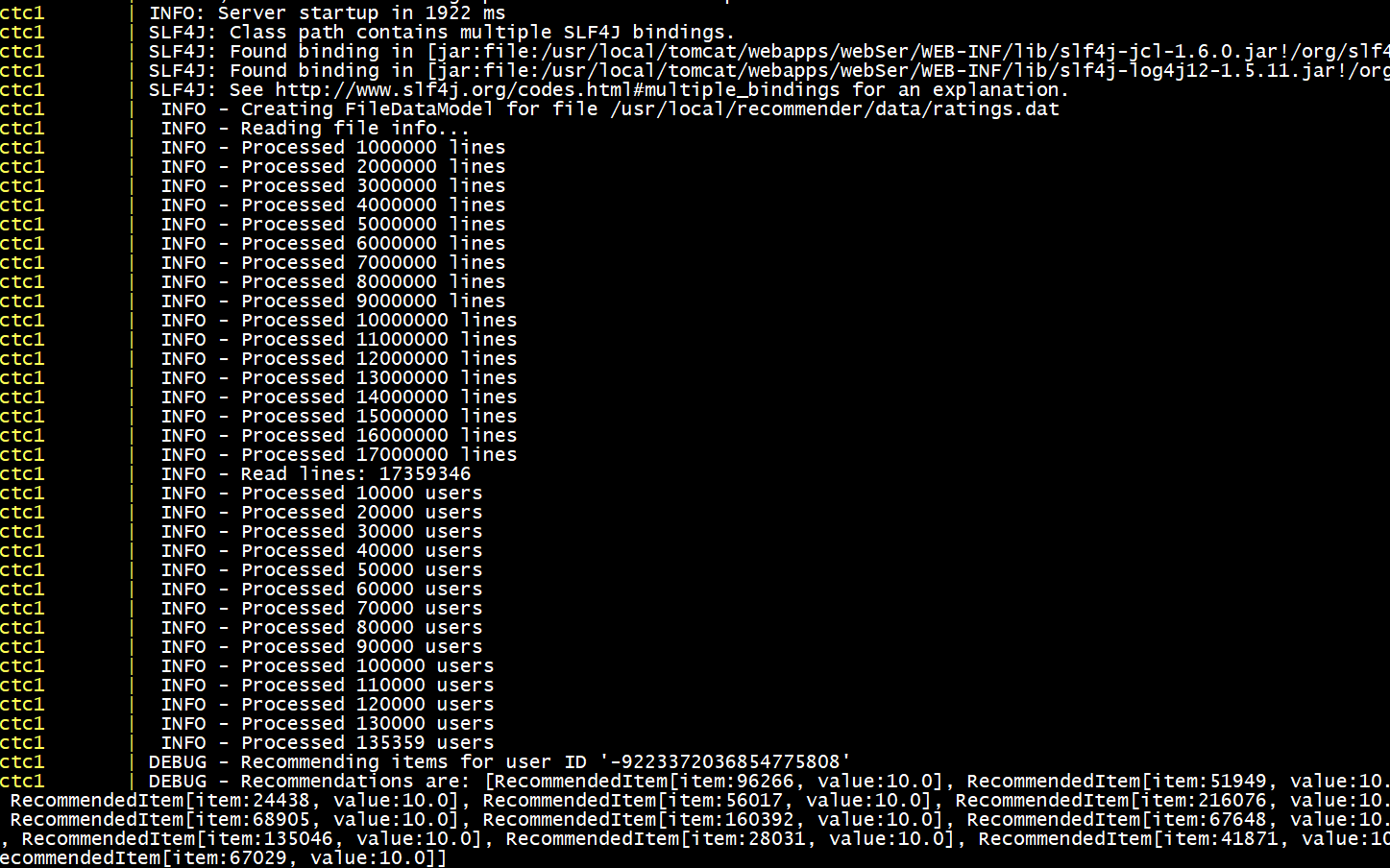
处理过程如图所示:
使用URL访问WEB服务,指定userID参数,视为为指定用户推荐:
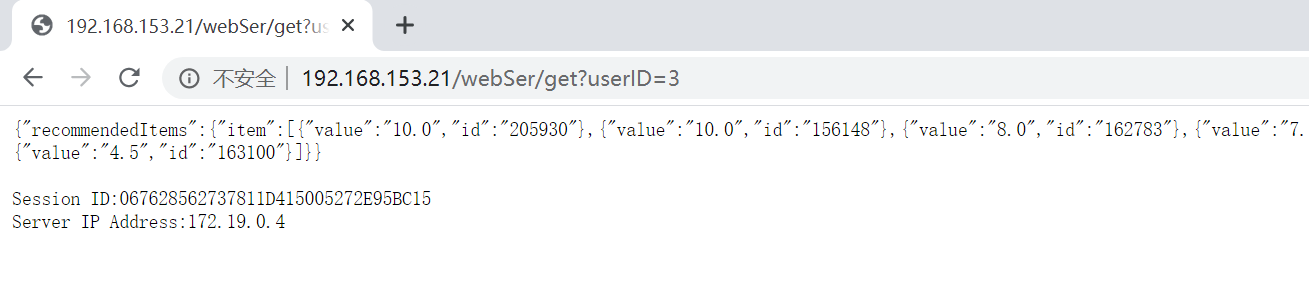
处理过程如图所示:

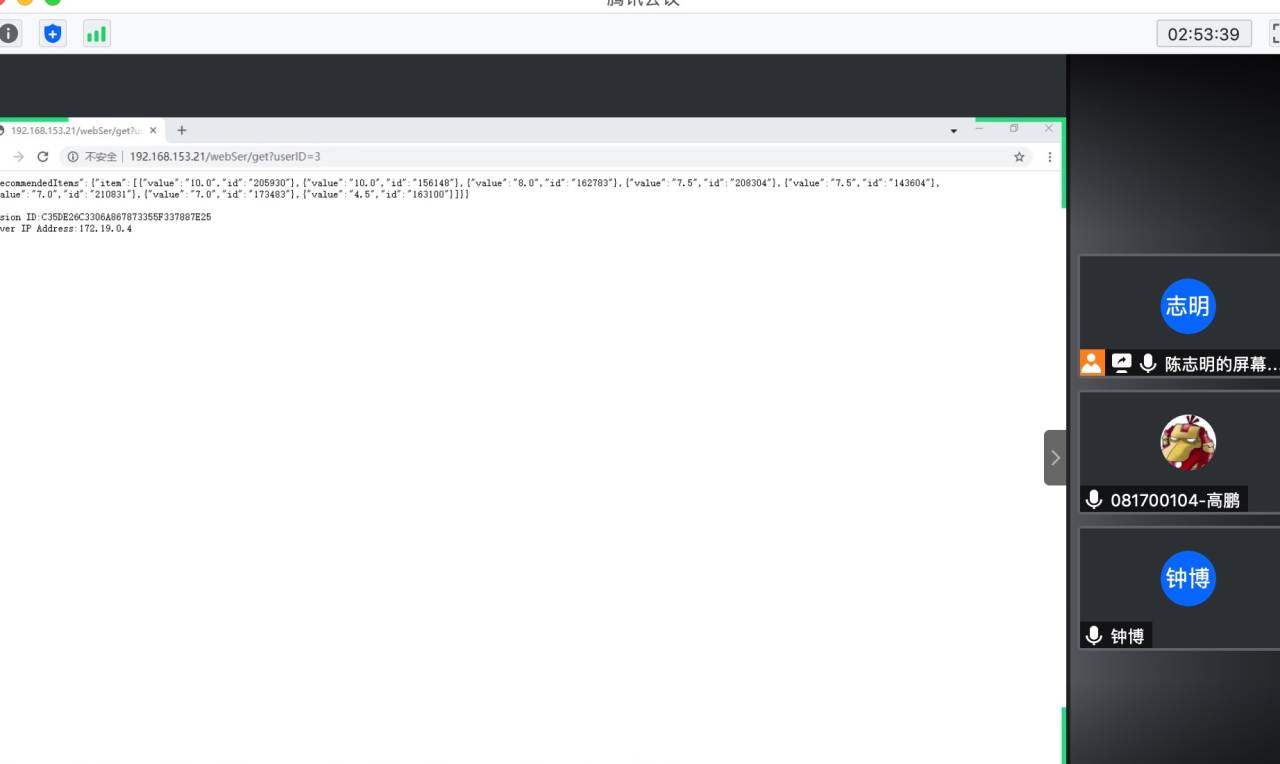
可见,只有第一次进行推荐时,需要对数据进行处理,并且能够保证了sessionID的不变,服务器实现了共享session的功能。
至此,实验已完成。
遇到的问题
1、冷启动问题,对游客推荐时无数据可用。(陈志明)
解决方案如上所述。
2、搭建传统式共享session服务器架构时出现缺失依赖导致nginx安装失败以及依赖难以下载等一系列问题。(高鹏)
具体解决方案请移步该组员博客文章。
3、搭建微服务式共享session服务器架构时教程少、jar包重编译、应用版本控制等一系列问题。(钟博)
具体解决方案请移步该组员博客文章。
组内协作
1、分工。
| 成员 | 分工 |
|---|---|
| 陈志明(40%) | 分析数据集、编写推荐程序、评估推荐模型(欧式距离相似性度量)、优化推荐结果、处理冷启动问题、项目测试、编写博客 |
| 高鹏(30%) | 收集数据集、评估推荐模型(谷本系数相似性度量)、搭建传统式共享session服务器架构、项目部署、编写博客 |
| 钟博(30%) | 收集数据集、评估推荐模型(皮尔逊相关系数)、搭建微服务式共享session服务器架构、项目部署、编写博客 |
2、组长向组员讲解如何使用评估推荐系统的程序。
3、组长向组员演示成功部署后的项目结果。
4、组内探讨问题的解决办法。

5、组内开麦进行交流。
组员总结
陈志明
在这次实验中,我作为组长负责选题、调动组员以及编程部分。这次是第一次做一个推荐系统,考虑问题并不能很完善,好在组员能够提出意见,使得整个实验做起来还是比较顺利的。首先,我组织了组员进行推荐系统相关的理论学习,并给组员安排了相关任务。在得到组员寻找的数据集后,便进行数据分析以及模型评估程序的编写。在完成评估程序后,我给每位组员分配了评估任务,我们三个人一起贡献算力,评估了在数据集上的模型表现。在得到以欧式距离度量相似性的基于用户2-最近邻模型较优的结果后,我的下一个目标就是优化推荐结果。我通过引入性别信息对推荐结果进行过滤,并引入匿名用户解决推荐系统的冷启动问题。等到队友完成了服务器的架构后,下一步便是推荐系统的部署与测试。在这一步骤我并没有遇到多少问题,因为服务器都是由队友架构的,我只需要将文件(war包)映射到容器即可。
通过这次实验,我们组了解到了开发一个推荐系统的基本流程,组员对微服务架构也更加的熟悉,体会到了微服务架构中的一次部署,到处运行的理念,就比如在这次实验中,组员架构了服务器,我只需要将项目部署一下,然后将依赖文件传给组员,就能够仅靠一句docker-compose up命令即可实现项目部署与运行。我对这次实验主题选择稍有进一步考虑:如今的互联网企业应用发展过程大都是从单体应用出发,经微服务架构到大数据阶段,然后才到人工智能阶段。我们组这次的实验正是从微服务架构到大数据阶段的一次小尝试,大数据阶段对于互联网企业来说,更多地是通过对用户行为进行分析以迎合用户的偏好,而我们组的推荐系统正是对这一目标的尝试,只是目前我们实验的数据尚可使用单机处理,当数据集更大的时候,就需要真正地使用大数据技术进行处理了。
最后,很感谢组员之间的互帮互助与相互配合,使得这次实验比较顺利的完成。
高鹏
这次系统综合实践大作业在选题上,组员之间找选题,一起评估一下,开始找题目限制在利用上一次作业基础上,所以思维一直停留在身份识别,监控预警这些方面再加些其他花哨的功能上。后来群里老师说选题不一定限得这么死,只要是用微服务的就行。然后组长提供的这个方案——异性交友推荐平台,大家商讨了一下,都感觉挺有搞头的,所以就定了这个题目。
这次大作业我做的工作主要是收集数据集,对推荐模型去评估以及用传统方式部署实现Nginx+Tomcat+Redis实现session共享的Web服务器。主要时间花费在推荐模型评估理论学习模型评估测试上、以及web服务器部署上。主要的困难在理论学习,代码的理解上,开始比较懵逼,通过组长提供资料,以及腾讯会议在在线讲解,结合组长给出代码注释,逐渐上手了。
在web服务器搭建上,搭建采用比较传统的方式部署了Nginx、Tomcat、Redis。相比之前使用微服务的经历能比较直观感受到采用微服务,用docker去部署时较传统方式相通的地方,以及不同和便利的方面。通过传统方式部署我能更直观地对一系列工具有了更深的了解,在使用微服务部署时相对而言,这方面收获可能就相对少了些。在使用传统方式部署,除了对不同工具了解,还要考虑各个工具版本之间适配,这一方面的权衡之前相对就考虑的少了些。但也通过对传统方式部署学习实践,更深的明白的通过微服务部署的好处,通过微服务部署,相对而言,降低很多的工作量,对docker-compose编写使用简化了传统方式很多步骤,降低在各种文件目录间cd来cd去的频率(这一方面感触颇深)。同时使用docker-compose也便利了项目测试与交接。通过这个大作业以及前面工作,深切体会到微服务的价值、便利性。
钟博
这次大作业我做的工作主要是收集数据集,对推荐模型去评估以及用docker实现共享session的微服务。总体来说,开始还算顺利,就是部署微服务方面花了比较长的时间,在推荐模型评估方面,一开始代码还有原理还有些模糊,上手不是特别顺利,经过组长代码的一些注释还有讲解最后也是成功上手测试了,再一个就是在部署微服务的时候出现了一个问题,我们小组也是各抒己见,没有组员的帮助,我可能还要卡在那个问题上很久。通过这次实践我对微服务的部署还有docker-compose的使用也是更加熟练了,不得不说,docker-compose还是很方便快捷的,不需要像其他方式需要手动配置一堆东西。这次实践也是第一次比较具体详细的去部署一个相对完整的项目,收获还是挺多的。
参考文章
如何理解皮尔逊相关系数(Pearson Correlation Coefficient)?

