第4次实践作业
使用Docker-compose实现Tomcat+Nginx负载均衡
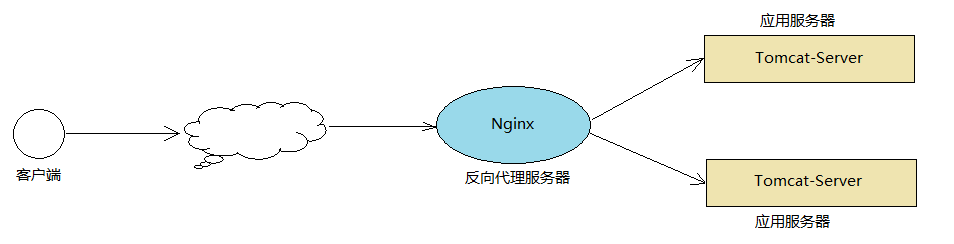
由于单台Tomcat的承载能力是有限的,当业务系统用户量比较大,请求压力比较大时,单台Tomcat是扛不住的,这个时候,就需要搭建Tomcat的集群,而目前比较流行的做法就是通过Nginx来实现Tomcat集群的负载均衡。
Nginx有热部署、高并发连接、低内存消耗、处理响应请求速度快和高可靠性的特点。下面直接来看怎么实现tomcat+nginx均衡负载吧。nginx内置了轮询、weight、ip_hash、least_conn等不同的负载均衡算法,实验着重了尝试轮询和weight。
首先,修改nginx.conf文件中的相关配置。
...
# 轮询
upstream tomcatpool{ # tomcat服务器池
server cat01:8080;
server cat02:8080;
server cat03:8080;
}
server {
listen 80;
server_name localhost;
#charset koi8-r;
#access_log logs/host.access.log main;
location / {
# root html;
# index index.html index.htm;
proxy_pass http://tomcatpool/;# 代理服务器重定向到tomcat服务器
}
...
然后,根据上图,进行运行环境搭建。使用的是docker-compose来实现。docker-compose.yml文件内容如下:
version: "3"
services:
proxy:
image: nginx
container_name: webproxy
ports:
- "80:80"
volumes:
- /usr/local/loadbalance/nginx.conf:/etc/nginx/nginx.conf
cat01:
image: tomcat:8.5.55-jdk8
container_name: cat01
volumes:
- /var/lib/tomcat/apps1:/usr/local/tomcat/webapps/ROOT
cat02:
image: tomcat:8.5.55-jdk8
container_name: cat02
volumes:
- /var/lib/tomcat/apps2:/usr/local/tomcat/webapps/ROOT
cat03:
image: tomcat:8.5.55-jdk8
container_name: cat03
volumes:
- /var/lib/tomcat/apps3:/usr/local/tomcat/webapps/ROOT
很清楚可以看到,有三台tomcat服务器,一台nginx代理服务器。其中tomcat服务器的web应用都持久化存储,在存储目录中,存放一个index.html文件,文件标识来自哪一个服务器的应答。通过nginx服务器的80端口,对tomcat服务器进行访问。
使用docker-compose up命令成功创建镜像并运行后,在命令行中使用curl localhost命令可以看到index.html网页返回的信息。
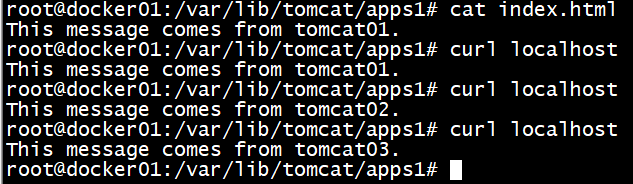
可见,目前方式为轮询方式,只curl了三次,也许会有巧合,那么写一个shell脚本执行多遍curl localhost并输出到logs文件看看吧。

可见,确实是nginx以轮询的方式进行均衡负载处理。下面看看weight方式的负载均衡吧。将nginx配置文件中的tomcat服务器池改为下述模样:
# 权重
upstream tomcatpool{
server cat01:8080 weight=3;
server cat02:8080 weight=2;
server cat03:8080 weight=1;
}
# weight参数用于指定轮询几率,weight的默认值为1;weight的数值与访问比率成正比
# 比如cat01服务器上的服务被访问的几率为cat03服务器的三倍
# 此策略比较适合服务器的硬件配置差别比较大的情况。
同样使用docker-compose up并使用shell脚本curl localhost,记录相关信息于logs文件中。查看logs文件可以看到如下内容:
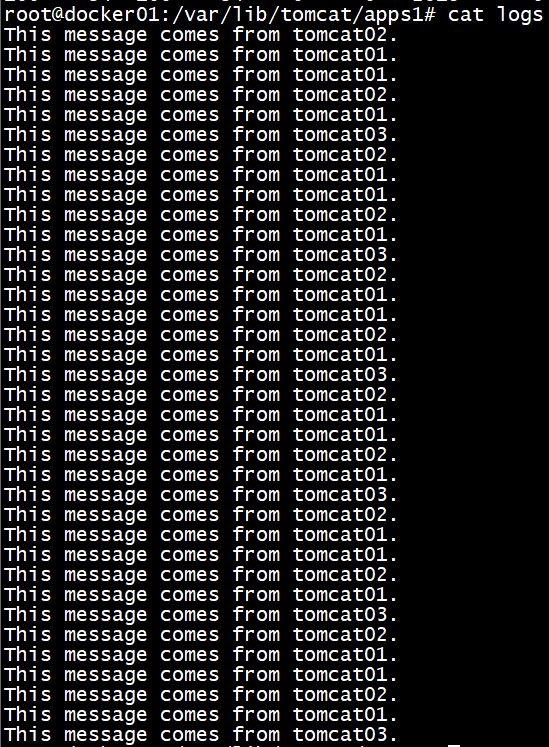
可以明显看到,来自tomcat服务器的响应数 tomcat01 > tomcat02 > tomcat03,也正是weight方式负载均衡的实现。
使用Docker-compose部署javaweb运行环境
javaweb运行环境基于第一个tomcat+nginx负载均衡实验,由于我的web应用需要用到 JDBC,所以在volumes中还额外的添加了 JDBC相关的JAR包的依赖。数据库使用的是MySQL,使用dockerfile对其镜像进行定制,主要是数据库用户、密码、数据库和基本表的初始化。Dockerfile文件内容如下:
FROM mysql
ENV MYSQL_ROOT_PASSWORD=123456 \
MYSQL_ALLOW_EMPTY_PASSWORD=no \
MYSQL_DATABASE=logintimes
COPY tableinit.sql /docker-entrypoint-initdb.d
执行的sql语句如下:
use logintimes;
create table times(
id int primary key,
times int not null
)DEFAULT CHARSET=latin1;
完整的docker-compose文件内容如下:
version: "3"
services:
proxy:
image: nginx
container_name: webproxy
ports:
- "80:80"
volumes:
- /usr/local/loadbalance/nginx.conf:/etc/nginx/nginx.conf
cat01:
image: tomcat:8.5.55-jdk8
container_name: cat01
volumes:
- /var/lib/tomcat/apps1:/usr/local/tomcat/webapps
- /var/lib/tomcat/lib/mysql-connector-java-8.0.20.jar:/usr/local/tomcat/lib/mysql-connector-java-8.0.20.jar
cat02:
image: tomcat:8.5.55-jdk8
container_name: cat02
volumes:
- /var/lib/tomcat/apps2:/usr/local/tomcat/webapps
- /var/lib/tomcat/lib/mysql-connector-java-8.0.20.jar:/usr/local/tomcat/lib/mysql-connector-java-8.0.20.jar
cat03:
image: tomcat:8.5.55-jdk8
container_name: cat03
volumes:
- /var/lib/tomcat/apps3:/usr/local/tomcat/webapps
- /var/lib/tomcat/lib/mysql-connector-java-8.0.20.jar:/usr/local/tomcat/lib/mysql-connector-java-8.0.20.jar
database:
container_name: mydb
build: ./mysql
ports:
- "3306:3306"
volumes:
- /var/lib/javaweb/mysql:/var/lib/mysql
我写的java web应用只是简单的记录网站被访问次数并显示给用户,主要操作是从数据库中读取已被访问的次数,然后对次数加1再写入数据库,所以涉及的数据库操作为查询与更新。数据库使用的是MySQL8,与MySQL5有些差异。由于功能简单,在一个函数里就能够实现:
// databaseRelated.class
static final String JDBC_DRIVER = "com.mysql.cj.jdbc.Driver";// 与MySQL5有差异
static final String DB_URL = "jdbc:mysql://mydb:3306/logintimes?useSSL=true&serverTimezone=GMT";// 与MySQL5有差异
static final String USER = "root";
static final String PASSWD = "123456";
public static synchronized int updateTimes() {
Connection connection = null;
Statement statement = null;
int times = 0;
try {
Class.forName(JDBC_DRIVER);
System.out.println("Database Connecting...");
connection = DriverManager.getConnection(DB_URL, USER, PASSWD);
statement = connection.createStatement();
String sqlCommand;
sqlCommand = "select times from times where id = 1";
System.out.println(sqlCommand);
ResultSet resultSet = statement.executeQuery(sqlCommand);
if (resultSet.next())
times = resultSet.getInt("times") + 1;
sqlCommand = "update times set times = " + times + " where id = 1";
System.out.println(sqlCommand);
statement.executeUpdate(sqlCommand);
statement.close();
connection.close();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
return times;
}
处理get与post请求的函数也极其简单:
// updateTimes.class
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
int times = databaseRelated.updateTimes();
resp.getWriter().write("This website has been visited " + times + " times,this message comes from tomcat x.");// x取决于tomcat服务器,如x=1对应于tomcat01.
}
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
doGet(req, resp);
}
将该web应用的servlet映射设置成如下形式:
...
<servlet>
<servlet-name>counter</servlet-name>
<servlet-class>updateTimes</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>counter</servlet-name>
<url-pattern></url-pattern>
</servlet-mapping>
...
将整个web应用打成war包后,放入到tomcat服务器的持久化存储目录中。然后使用docker-compose up命令生成镜像并启动。使用浏览器通过url访问该web应用,可以看到如下内容:

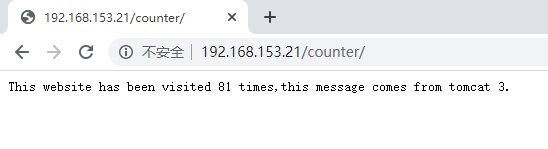
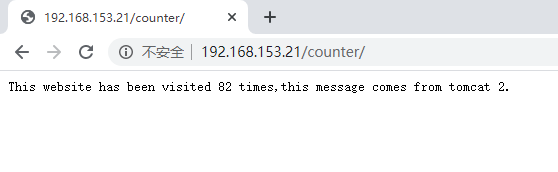
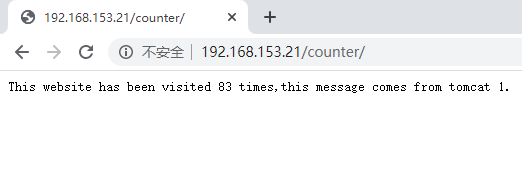
负载均衡使用的是weight方式,从返回的信息可以看到网站被访问的次数。
使用Docker搭建大数据集群环境
Hadoop集群的搭建教程在网上一搜即得,但是大多教程都需要进入容器中对容器进行相关环境(Java,Hadoop)搭建。由于学习了dockerfile,所以本次实验能用dockerfile完成的,尽量都用dockerfile完成,因为进入容器后再使用docker commit来创建镜像会保存大量的无关文件,而docker镜像是分层存储的,多次的commit会使的容器的体积剧增。
本次Hadoop的docker搭建使用一个namenode和两个datanode,所需要的文件如下图所示:
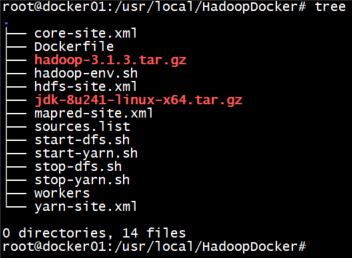
接下来将以ubuntu:18.04为基础镜像,逐步搭建大数据集群环境。
首先准备jdk-8u241-linux-x64.tar.gz和hadoop-3.1.3.tar.gz,两者分别是Java和Hadoop的应用程序安装包。因为接下来需要用到apt-get进行安装相关应用,所以先换源。
FROM ubuntu:18.04
COPY sources.list /etc/apt
RUN mkdir -p /usr/local/java/ && mkdir -p /usr/local/hadoop/
COPY jdk-8u241-linux-x64.tar.gz /usr/local/java/
COPY hadoop-3.1.3.tar.gz /usr/local/hadoop/
RUN tar -zxf /usr/local/java/jdk-8u241-linux-x64.tar.gz -C /usr/local/java \
&& tar -zxf /usr/local/hadoop/hadoop-3.1.3.tar.gz -C /usr/local/hadoop \
&& rm -f /usr/local/java/jdk-8u241-linux-x64.tar.gz /usr/local/hadoop/hadoop-3.1.3.tar.gz
ENV JAVA_HOME /usr/local/java/jdk1.8.0_241
ENV HADOOP_HOME /usr/local/hadoop/hadoop-3.1.3
ENV PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
上述的dockerfile内容是将ubuntu:18.04作为基础镜像,更换镜像源、创建Java与Hadoop目录、解压Java JDK与Hadoop安装包、删除已用的安装包并设置环境变量。
接着替换原Hadoop中etc/hadoop的workers、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml、hadoop-env.sh以及sbin中的start-dfs.sh、start-yarn.sh、stop-dfs.sh、stop-yarn.sh。其中,workers文件中指明的是datanode的主机名hostname:
workers指定datanode所在的主机名hostname,可以根据实际情况进行添加:
node02
node03
core-site.xml中设置的是HDFS(Hadoop Distributed File System)主端口以及Hadoop运行过程中产生的数据文件,更多的配置选项可以在Configuration - core-default.xml中查看。
<configuration>
<property>
<!-- hdfs://host:port -->
<name>fs.defaultFS</name>
<value>hdfs://node01:9000</value>
</property>
<property>
<!-- Hadoop运行过程产生数据的存放位置 -->
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/hadoop-3.1.3/tmp</value>
<description>A base for other temporary directories.</description>
</property>
</configuration>
hdfs-site.xml中设置的是HDFS的数据冗余量、namenode持久存储名字空间及事务日志的本地文件系统路径和DataNode存放块数据的本地文件系统路径,更多的配置选项可以在Configuration - hdfs-default.xml中查看。
<configuration>
<property>
<!-- 数据冗余量 -->
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<!--namenode持久存储名字空间及事务日志的本地文件系统路径-->
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hadoop-3.1.3/tmp/dfs/name</value>
</property>
<property>
<!--DataNode存放块数据的本地文件系统路径-->
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/hadoop-3.1.3/tmp/dfs/data</value>
</property>
</configuration>
mapred-site.xml中设置的是MapReduce分布式计算框架的相关组件,如运行主体、jobhistory、以及MR类路径,更多的配置选项可以在Configuration - mapred-default.xml中查看。
<configuration>
<property>
<!-- 使用yarn运行MapReduce程序 -->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<!-- jobhistory地址host:port -->
<name>mapreduce.jobhistory.address</name>
<value>node01:10020</value>
</property>
<property>
<!-- jobhistory的web地址host:port -->
<name>mapreduce.jobhistory.webapps.address</name>
<value>node01:19888</value>
</property>
<property>
<!-- 指定MR应用程序的类路径 -->
<name>mapreduce.application.classpath</name>
<value>/usr/local/hadoop/hadoop-3.1.3/share/hadoop/mapreduce/*,/usr/local/hadoop/hadoop-3.1.3/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
yarn-site.xml中设置的是yarn组件相关配置,yarn是Hadoop生态圈中的资源调度组件,涉及resourcemanager、shuffle、memory,更多的配置选项可以在Configuration - yarn-default.xml中查看。
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<!-- 虚拟内容和物理内存的比例 -->
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>3</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
hadoop-env.sh中主要添加一项Java的jdk环境:
...
export JAVA_HOME=/usr/local/java/jdk1.8.0_241
...
start-dfs.sh和stop-dfs.sh中主要指定HDFS USER:
HDFS_NAMENODE_USER=root
HDFS_DATANODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
start-yarn.sh和stop-yarn.sh中主要指定YARN USER:
YARN_RESOURCEMANAGER_USER=root
YARN_NODEMANAGER_USER=root
在Dockerfile中使用COPY命令将上述文件复制到相关目录,注意.sh后缀的文件是可执行文件,需要赋予777权限:
COPY workers /usr/local/hadoop/hadoop-3.1.3/etc/hadoop
COPY core-site.xml /usr/local/hadoop/hadoop-3.1.3/etc/hadoop
COPY hdfs-site.xml /usr/local/hadoop/hadoop-3.1.3/etc/hadoop
COPY mapred-site.xml /usr/local/hadoop/hadoop-3.1.3/etc/hadoop
COPY yarn-site.xml /usr/local/hadoop/hadoop-3.1.3/etc/hadoop
COPY hadoop-env.sh /usr/local/hadoop/hadoop-3.1.3/etc/hadoop
COPY start-dfs.sh /usr/local/hadoop/hadoop-3.1.3/sbin
COPY start-yarn.sh /usr/local/hadoop/hadoop-3.1.3/sbin
COPY stop-dfs.sh /usr/local/hadoop/hadoop-3.1.3/sbin
COPY stop-yarn.sh /usr/local/hadoop/hadoop-3.1.3/sbin
WORKDIR /usr/local/hadoop/hadoop-3.1.3/sbin
RUN chmod 777 /usr/local/hadoop/hadoop-3.1.3/etc/hadoop/hadoop-env.sh \
start-dfs.sh start-yarn.sh stop-dfs.sh stop-yarn.sh
到此,Java与Hadoop环境配置完成,接下来配置的是SSH免密登录。
回想正常的配置流程:
$ ssh-keygen -t rsa # 一直按回车即可
$ cd /root/.ssh/
$ cat id_rsa.pub >> authorized_keys
我将上述流程转为Dockerfile命令的方式:
RUN ssh-keygen -t rsa -f /root/.ssh/id_rsa && cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
最后,使用脚本进行ssh的服务自启动:
RUN mkdir -p /run/sshd && touch /root/run.sh \
&& echo "#!/bin/bash" >> /root/run.sh \
&& echo "/usr/sbin/sshd" >> /root/run.sh \
&& echo "/bin/bash" >> /root/run.sh \
&& chmod 777 /root/run.sh
ENTRYPOINT ["/root/run.sh"]
使用docker build -t命令创建镜像后运行是否直接就能使用Hadoop集群了呢?其实并不然,因为还需要设置集群中的主机名与IP,由于集群较小,为了方便这里采用手动方式进行设置。
首先创建三个容器,分别作为Hadoop集群中的master和slave:
$ docker run -it --rm -h node01 --name master myhadoop:v1 bash
$ docker run -it --rm -h node02 --name slave1 myhadoop:v1 bash
$ docker run -it --rm -h node03 --name slave2 myhadoop:v1 bash
再使用docker inspect --format='{{.NetworkSettings.IPAddress}}' [NAME]/[CONTAINER ID]命令查看容器IP:

在master上对/etc/hosts进行设置:
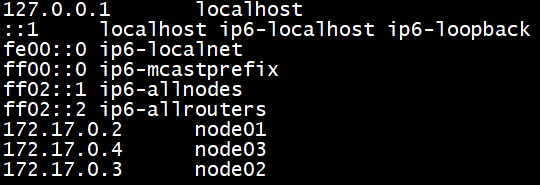
再使用scp命令将/etc/hosts文件传送到其它salve节点:

到此,Hadoop集群准备就绪,接下来是HDFS的初始化。
使用hdfs namenode -format对HDFS集群进行初始化,然后使用start-all.sh命令启动Hadoop集群:

为了验证集群是否启动成功,可以使用MapReduce自带的样例程序进行测试。MapReduce样例程序在Hadoop目录下的share/hadoop/mapreduce中。使用hadoop jar hadoop-mapreduce-examples-3.1.3.jar pi 20 50命令,可以启动Hadoop集群进行求pi运算,核心算法是Monte Carlo求Pi算法,最后可以求得pi=3.14800:
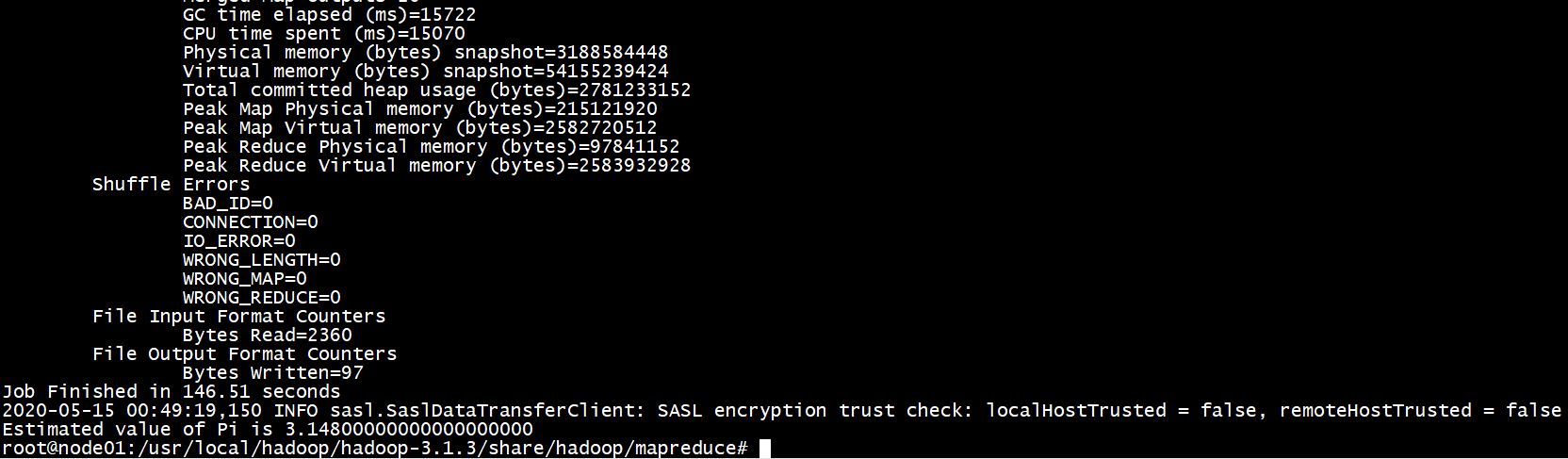
到此,大数据集群环境成功搭建,所需的完整Dockerfile如下:
FROM ubuntu:18.04
COPY sources.list /etc/apt
RUN mkdir -p /usr/local/java/ && mkdir -p /usr/local/hadoop/
COPY jdk-8u241-linux-x64.tar.gz /usr/local/java/
COPY hadoop-3.1.3.tar.gz /usr/local/hadoop/
RUN tar -zxf /usr/local/java/jdk-8u241-linux-x64.tar.gz -C /usr/local/java \
&& tar -zxf /usr/local/hadoop/hadoop-3.1.3.tar.gz -C /usr/local/hadoop \
&& rm -f /usr/local/java/jdk-8u241-linux-x64.tar.gz /usr/local/hadoop/hadoop-3.1.3.tar.gz
ENV JAVA_HOME /usr/local/java/jdk1.8.0_241
ENV HADOOP_HOME /usr/local/hadoop/hadoop-3.1.3
ENV PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
COPY workers /usr/local/hadoop/hadoop-3.1.3/etc/hadoop
COPY core-site.xml /usr/local/hadoop/hadoop-3.1.3/etc/hadoop
COPY hdfs-site.xml /usr/local/hadoop/hadoop-3.1.3/etc/hadoop
COPY mapred-site.xml /usr/local/hadoop/hadoop-3.1.3/etc/hadoop
COPY yarn-site.xml /usr/local/hadoop/hadoop-3.1.3/etc/hadoop
COPY hadoop-env.sh /usr/local/hadoop/hadoop-3.1.3/etc/hadoop
COPY start-dfs.sh /usr/local/hadoop/hadoop-3.1.3/sbin
COPY start-yarn.sh /usr/local/hadoop/hadoop-3.1.3/sbin
COPY stop-dfs.sh /usr/local/hadoop/hadoop-3.1.3/sbin
COPY stop-yarn.sh /usr/local/hadoop/hadoop-3.1.3/sbin
WORKDIR /usr/local/hadoop/hadoop-3.1.3/sbin
RUN chmod 777 /usr/local/hadoop/hadoop-3.1.3/etc/hadoop/hadoop-env.sh \
start-dfs.sh start-yarn.sh stop-dfs.sh stop-yarn.sh
RUN apt-get update && apt-get install -y vim openssh-server && ssh-keygen -t rsa -f /root/.ssh/id_rsa && cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
WORKDIR /
RUN mkdir -p /run/sshd && touch /root/run.sh \
&& echo "#!/bin/bash" >> /root/run.sh \
&& echo "/usr/sbin/sshd" >> /root/run.sh \
&& echo "/bin/bash" >> /root/run.sh \
&& chmod 777 /root/run.sh
EXPOSE 22
ENTRYPOINT ["/root/run.sh"]
问题与解决办法
问题:在docker build时,执行apt-get install出现了没有安全证书的情况:

方法:既然时apt-get命令执行出错,很自然的想到了是安装源的问题。根据计算机网络的知识,https是需要安全证书访问的,所以将https全部换成http后,顺利执行。
问题:在使用ENTRYPOINT ["/root/run.sh"]之后,出现使用docker run命令启动容器后马上退出容器的情况。
方法:根据文章《docker 容器启动后立马退出的解决方法》的解决方案,问题顺利解决。问题的来源是容器同时只能管理一个进程,如果这个进程结束了容器就退出了,但是不表示容器只能运行一个进程(其他进程可在后台运行),但是要使容器不退出必须要有一个进程在前台执行。
问题:执行MapReduce样例程序时,出现虚拟内存不足的情况
方法:在yarn-site.xml文件中修改虚拟内存倍率参数,虚拟内存 = 虚拟机物理内存 * 倍率,只要虚拟内存大于错误提示所需的内存即可。
时间开销
实践共15小时,博客共3小时,总共18小时。
参考资料
[3]docker-tomcat-nginx 反向代理和负载均衡

