
如何理解词向量、Transformer模型以及三个权重矩阵
词向量与transformer
生成词向量的过程和训练Transformer的过程是两个不同的过程,但它们都是自然语言处理中的重要组成部分。
# 词向量的生成
词向量(如Word2Vec、GloVe、FastText等)通常是通过预训练的词嵌入模型得到的。这些模型在大规模文本数据上训练,捕捉词与词之间的语义关系,并将每个词表示为一个固定维度的向量。这些词向量可以在许多自然语言处理任务中作为预处理的输入特征。
# Transformer的训练
在Transformer模型的训练过程中,词向量用作输入,但这只是整个模型的一部分。Transformer还包括许多其他组件,如注意力机制和前馈神经网络。
1. 初始化词向量:在训练Transformer时,词向量可能会被初始化为预训练词嵌入(如BERT或GPT等),也可能从头开始学习。
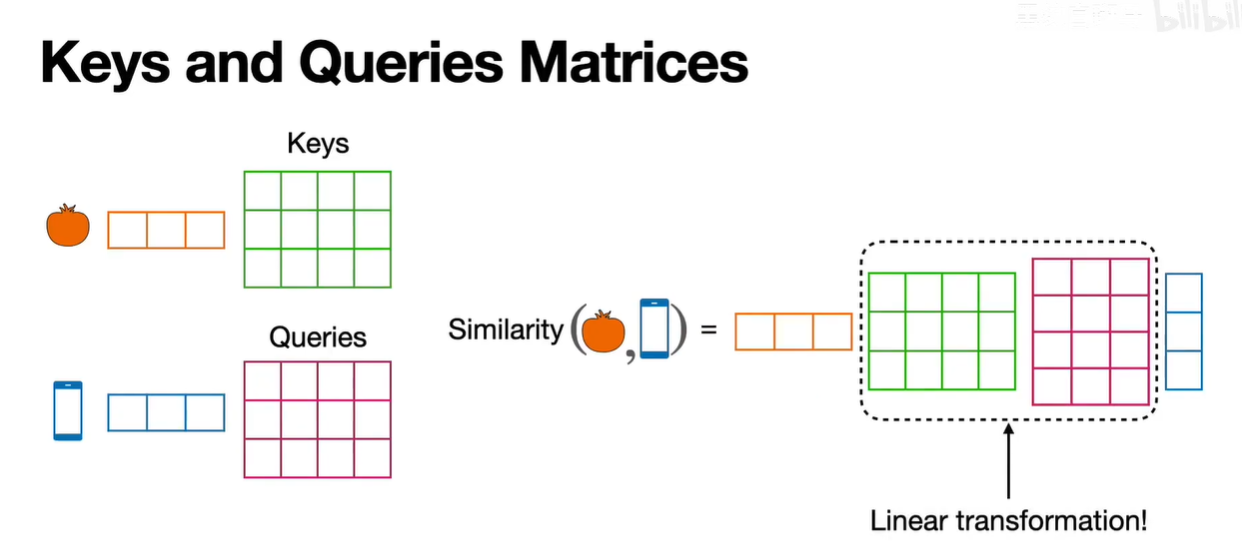
2. 训练过程:Transformer模型会在大量的训练数据上进行训练。在这个过程中,包括查询(Query)、键(Key)和值(Value)在内的所有权重矩阵都会被调整和学习。模型通过前向传播和反向传播的过程,逐渐优化这些参数,使其能够更好地理解和生成文本。
3. 最终模型:训练结束后,我们得到的是一个完整的Transformer模型,包括所有的参数和权重矩阵。这些权重矩阵捕捉了模型对数据的理解,包括如何在注意力机制中使用查询、键和值。
# 使用阶段
在分析具体文本时,我们使用已经训练好的Transformer模型。此时,模型利用它学到的权重矩阵和其他参数处理新的输入数据。例如,在自然语言理解任务中,模型可以将输入句子分解成查询、键和值向量,然后使用注意力机制来理解句子的语义并生成输出。
# 总结
因此,词向量的生成和Transformer的训练是两个不同的过程。词向量通常作为输入特征,而Transformer模型在训练过程中学习到的权重矩阵则用于在推理时处理和分析具体的文本数据。
使用还是训练?
当我们使用GPT(Generative Pre-trained Transformer)模型时,我们实际上是在利用已经训练好的Transformer模型,而不是在训练新的模型。
# 已训练好的Transformer模型
GPT模型,如GPT-3或GPT-4,是在大规模文本数据集上预先训练好的。这些模型在训练过程中学习了大量的语言特征、语法、语义关系以及世界知识。这包括通过大量的数据进行前向传播和反向传播来优化模型的参数,如查询(Query)、键(Key)和值(Value)向量的权重矩阵。

# 使用阶段
在使用阶段,当用户输入文本时,GPT模型会利用它在训练过程中学习到的参数来生成响应。这些响应是基于输入的内容和模型内存储的知识生成的。用户与GPT的交互不涉及模型的再训练;相反,用户输入的文本通过模型的编码器和解码器部分,经过复杂的计算和生成过程,最终得到输出。
# 总结
使用GPT模型时,您实际上是在使用已经训练和优化好的Transformer架构。这个过程不包括模型的再训练,而是直接利用预训练模型来处理和生成语言内容。这使得GPT模型能够迅速、有效地为各种输入生成高质量的文本响应。
是的,一般编程人员在Python中导入Transformer模块后输入一段文本,并基于该文本提出问题,实际上是在使用已经训练好的Transformer模型,而不是在训练该模型。
Python中导入Transformer的实质
# 使用预训练模型
Transformer模型,如GPT、BERT等,通常已经在大规模数据集上经过预训练,学习了语言的特征和知识。开发人员在使用这些模型时,会通过导入相关的库或模块,如`transformers`库(Hugging Face的Transformers库),并使用其中的预训练模型来进行推理或生成任务。
例如,使用Hugging Face的Transformers库,开发人员可以这样做:
from transformers import AutoTokenizer, AutoModelForQuestionAnswering
import torch
# 加载预训练的模型和分词器
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
model = AutoModelForQuestionAnswering.from_pretrained("bert-base-uncased")
# 输入文本
context = "The Eiffel Tower is located in Paris."
question = "Where is the Eiffel Tower located?"
# 编码输入
inputs = tokenizer.encode_plus(question, context, return_tensors="pt")
# 进行推理
outputs = model(inputs)
start_scores = outputs.start_logits
end_scores = outputs.end_logits
# 获取答案
all_tokens = tokenizer.convert_ids_to_tokens(inputs["input_ids"].numpy()[0])
answer = ' '.join(all_tokens[torch.argmax(start_scores): torch.argmax(end_scores)+1])
print(answer)
在这个例子中,`AutoTokenizer`和`AutoModelForQuestionAnswering`分别用于加载预训练的分词器和问答模型。输入的文本和问题被编码为模型可以理解的格式,然后通过模型生成输出。这些输出用于确定答案在文本中的位置。
# 总结
因此,当开发人员在Python中使用Transformer模型时,他们是在利用已经预训练好的模型进行推理或生成任务,而不是重新训练模型。这使得他们能够迅速应用先进的自然语言处理技术,而无需耗费大量资源和时间来训练模型。
训练Transformer模型得到了哪些权重?
训练Transformer模型的主要目的确实包括学习查询(Query)、键(Key)、和值(Value)的权重矩阵,但不仅限于此。Transformer模型还包括其他重要的参数和组件,这些在训练过程中同样需要学习和优化。
主要参数和组件
查询(Query)、键(Key)、值(Value)权重矩阵:
这些权重矩阵用于生成对应的查询、键和值向量,进而计算注意力得分。每个注意力头都会有自己的一组权重矩阵,这些权重矩阵在模型的自注意力层中起到关键作用。
位置编码(Positional Encoding):
由于Transformer模型不使用循环或卷积,因此没有自然的顺序信息。位置编码用于在输入数据中注入位置信息,帮助模型理解序列的顺序。这些编码参数在训练过程中是固定的,不会更新。
前馈神经网络(Feed-Forward Networks):
每个自注意力层后面都有一个前馈神经网络。这些网络由权重矩阵和偏置项组成,是训练过程中需要学习的参数。
层归一化(Layer Normalization):
用于稳定训练过程,每个层归一化操作也包含一些可训练的参数。
输出层的权重矩阵:
在解码器的最后一层,通常会有一个全连接层,其权重矩阵用于将解码器的输出映射到词汇表的概率分布。这些权重矩阵也是需要学习的参数。
多头注意力机制中的其他参数:
多头注意力机制包括多个注意力头,每个头有自己的权重矩阵。这些头允许模型关注输入的不同部分,从而捕捉更复杂的模式和关系。
训练的目标
训练Transformer模型的整体目标是优化所有这些参数,使得模型能够在给定的输入上生成准确和流畅的输出。这些参数的优化通常通过最小化损失函数(如交叉熵损失)来实现。模型的训练是一个复杂的过程,需要大量的计算资源和数据。
总的来说,训练Transformer模型不仅仅是为了得到查询、键和值的权重矩阵,还包括优化多个其他关键参数,以确保模型在各种自然语言处理任务中表现良好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号