Flink介绍及阿里云flink使用
学习 Apache Flink 有几个重要的理由:
- 实时数据处理:Flink 是一个强大的流处理框架,能够处理大规模的数据流,适用于需要实时分析的应用场景。
- 高吞吐量与低延迟:Flink 能够提供高吞吐量的同时保持低延迟的数据处理能力,这使得它在处理实时数据时非常高效。
- 容错机制:Flink 提供了先进的容错机制,确保即使在节点故障的情况下也能保证数据处理的准确性和一致性。
- 批处理支持:除了流处理,Flink 还支持批处理作业,这意味着你可以用同一个框架同时处理流数据和批数据。
- 机器学习集成:Flink 支持机器学习算法的实现和部署,可以用于构建复杂的实时数据分析应用。
- 社区活跃:Flink 拥有一个活跃的开源社区,不断有新的特性和改进被添加进来,同时也提供了丰富的文档和支持资源。
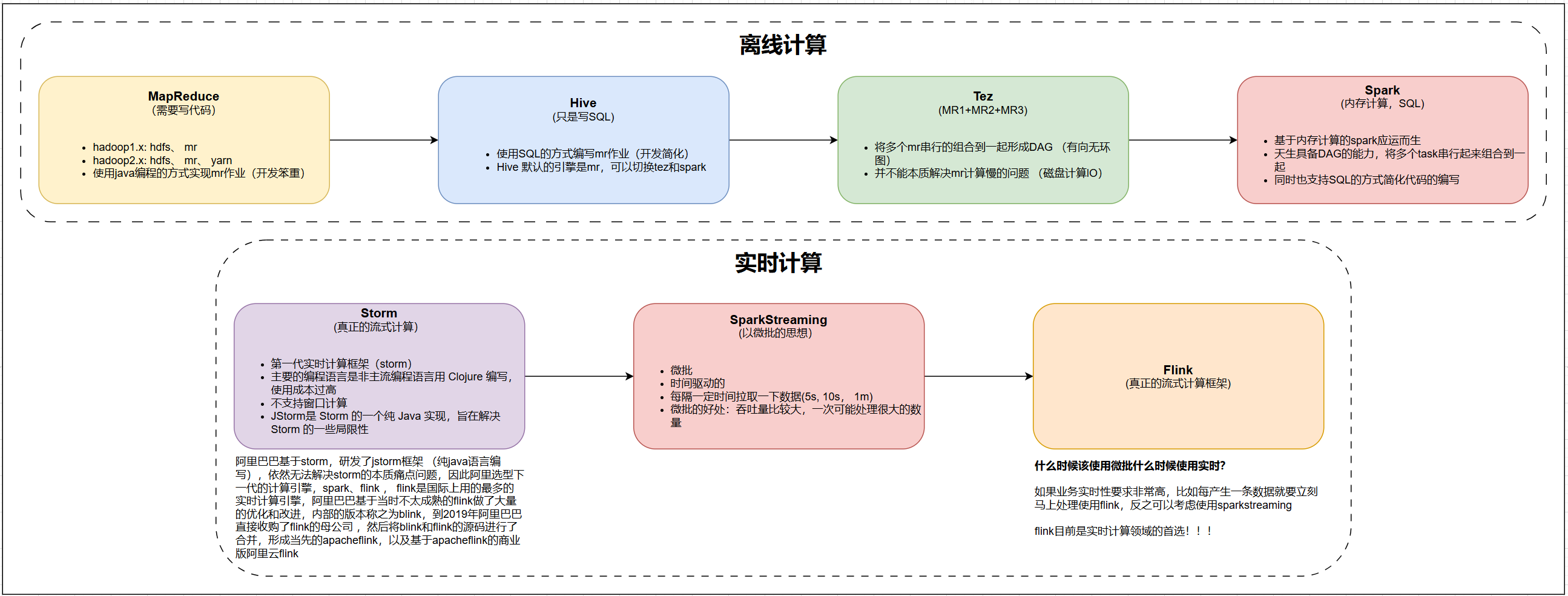
二、流式计算框架发展历史
- 离线(批量):MapReduce --> Hive --> Tez --> Spark
- 实时(流式):Storm --> StructuredStreaming --> Flink
三、流式计算
3.1.生活中的流式场景
流水或者水龙头、车流、行人、


3.2.程序中的流式场景
实时计算道路拥堵的情况
实时计算外卖配置位置信息
3.3.流式的特点
- 数据是有开始,但是没有结束,所以说数据是没有边界的;
- 数据是源源不断产生(到来);
- 数据到来的顺序不确定;
- 数据量可大可小;
- 数据是一条一条地计算,把这种计算称之为数据流的计算;
数据流:数据是流动的,流动的数据称之为数据流。数据是实时产生,实时到达,实时计算,实时出结果。
小结:
- 流式计算中,数据是流动的。先有计算逻辑,再有数据。
3.4.终极问题:流式计算和Flink有什么关系?
- Flink是流式计算思想的一种实现而已。
四、Flink简介
4.1.Apache Flink(开源免费)
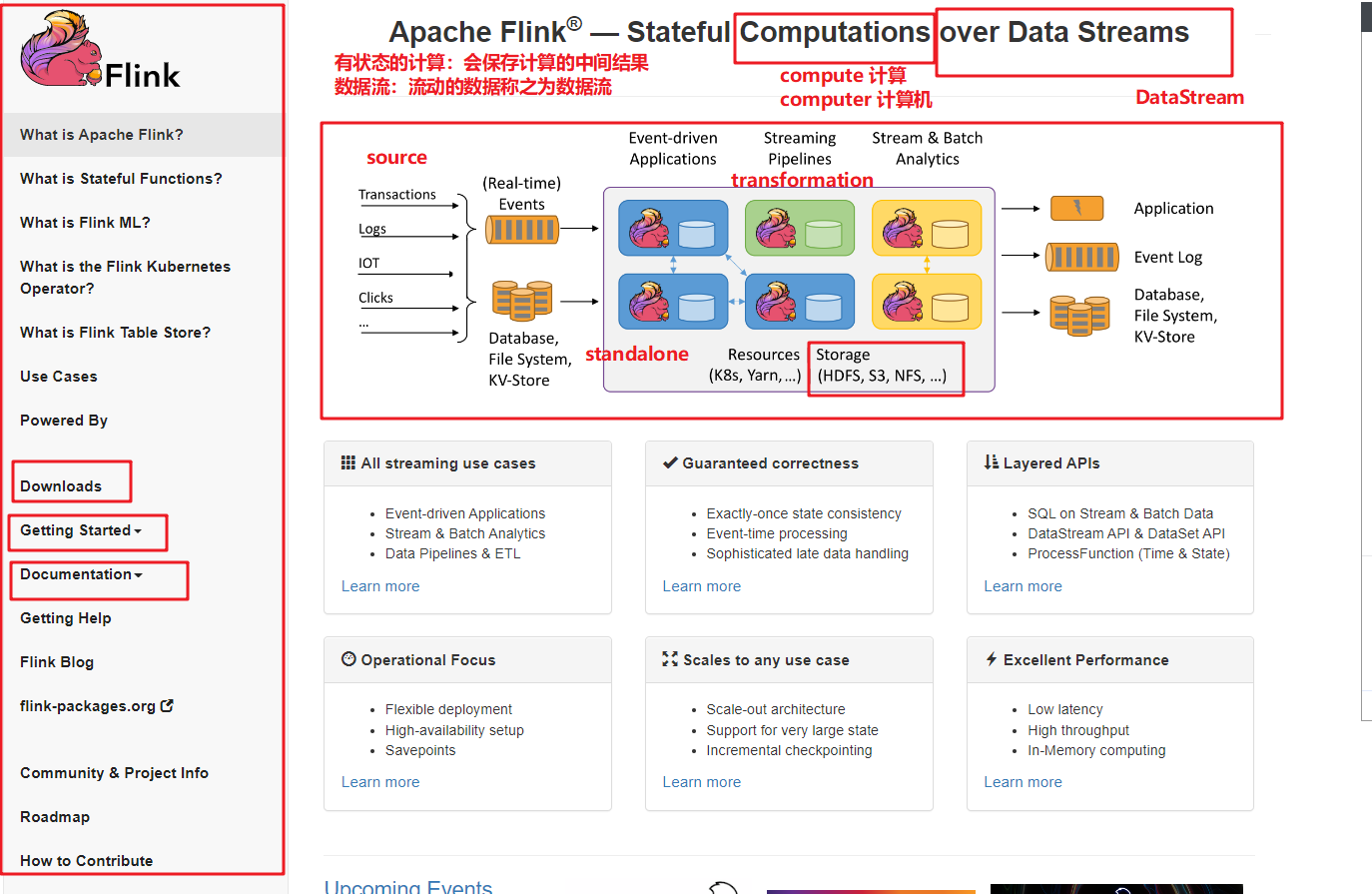
4.1.1.概述
- 数据流:流动的数据。
4.1.2.历史
起源
- 2009年:Flink 项目起源于 Stratosphere 项目,该项目由柏林工业大学、汉堡大学和慕尼黑工业大学的研究人员共同发起。
- 2014年:Stratosphere 项目正式更名为 Apache Flink,并于同年成为 Apache 孵化器项目。
发展历程
- 2014年:Flink 成为 Apache 孵化器项目,标志着其从学术研究项目向工业级大数据处理框架的转变。
- 2015年:Flink 正式毕业成为 Apache 顶级项目(Top-Level Project, TLP),表明其在社区和技术成熟度上得到了广泛认可。
- 2016年:Flink 1.0 版本发布,引入了流处理和批处理统一的 API,支持高吞吐量、低延迟的实时数据处理。
- 2017年:Flink 1.3 版本发布,增加了对 SQL 的支持,使得用户可以通过 SQL 查询来处理流数据。
- 2018年:Flink 1.5 版本发布,引入了 Table API 和 SQL 的统一,进一步简化了流处理和批处理的开发。
- 2019年:Flink 1.9 版本发布,增强了状态管理和容错机制,提高了系统的稳定性和可靠性。同年Flink的母公司被阿里巴巴收购,从此Flink就归于阿里了
- 2020年:Flink 1.11 版本发布,引入了动态表和时间窗口的增强功能,支持更复杂的流处理场景。
- 2021年:Flink 1.13 版本发布,进一步优化了性能和资源管理,增加了对 Kubernetes 的更好支持。
- 2022年:Flink 1.15 版本发布,引入了更多的优化和新特性,如动态资源分配和更好的状态管理。
- 2024年:Apache Flink 社区已于2024-10-23发布了 Flink 2.0版本,这是自 Flink 1.0 发布以来的首个重大更新。Flink 2.0 将引入多项激动人心的功能和改进,包括存算分离状态管理、物化表、批作业自适应执行等,同时也包含了一些不兼容的变更。目前提供的预览版旨在让用户提前尝试新功能并收集反馈。
4.1.3.特性
- 流处理和批处理统一:Flink 提供了一套统一的 API,可以同时处理流数据和批数据,简化了开发和维护。
- 高性能:Flink 支持高吞吐量、低延迟的实时数据处理,适用于大规模数据流的处理。
- 容错机制:Flink 提供了强大的容错机制,能够自动恢复失败的任务,保证数据的完整性和一致性。
- 状态管理:Flink 提供了丰富的状态管理功能,支持有状态的流处理,可以处理复杂的业务逻辑。
- SQL 支持:Flink 支持 SQL 查询,使得用户可以通过 SQL 来处理流数据,降低了学习和使用的门槛。
- 生态系统:Flink 拥有丰富的生态系统,包括 connectors、libraries 和 tools,支持多种数据源和存储系统。
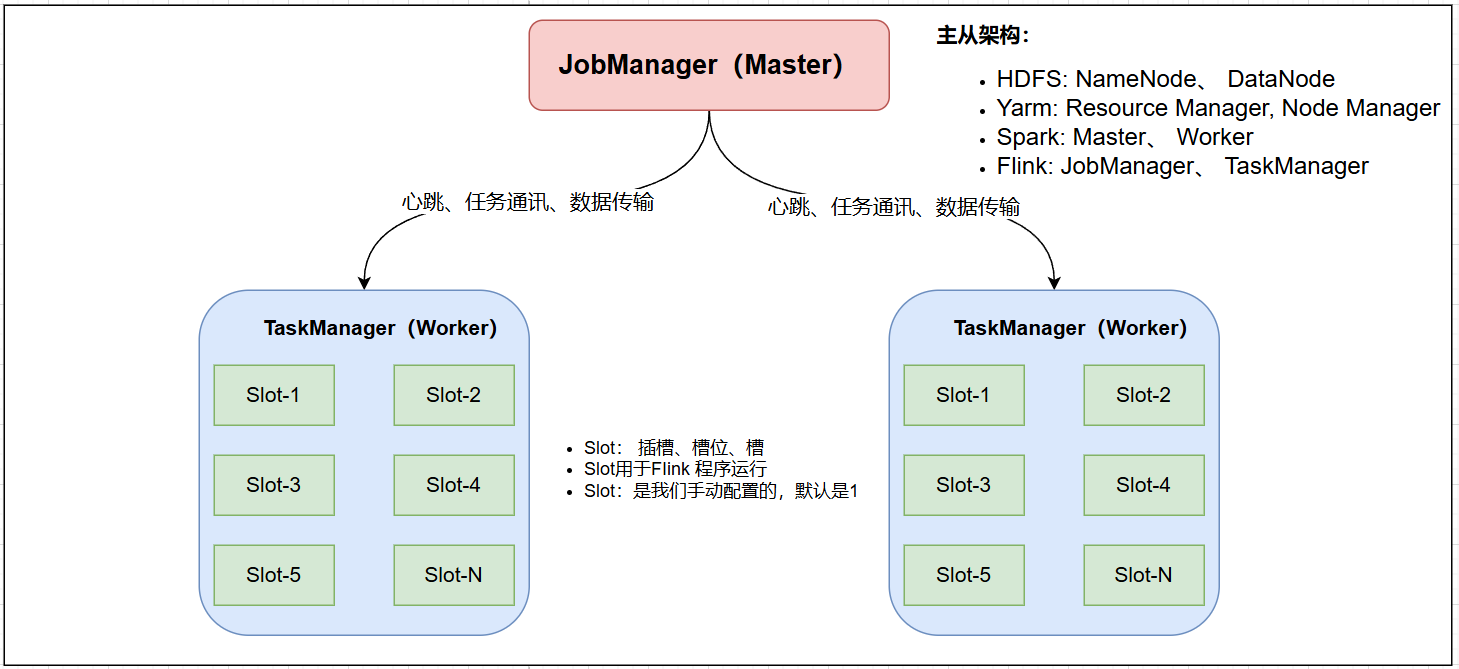
4.1.4.架构
- JobManager:集群的主节点,负责集群管理等
- TaskManager:集群的从节点,负责任务的执行
- Slot:槽,或者叫插槽,是从节点的资源单位,Flink任务必须在Slot里运行。Slot的数量是人为设置的,默认是1。一旦设置后,就无法更改。如果要更改,需要修改配置,然后重启集群。
详细说明:
- JobManager:相当于校区的办公室,管理所有的教室资源,是静态的概念,客户端将作业递交以后,需要根据具体的并行度和算子之间的依赖关系切割成一个个具体的任务,然后调度到具体的taskManager上去运行。
- TaskManage:相当于上课的教室,受办公室管理的,可以有一个或者多个TaskManager,也是静态的(相对,集群启动以后,TaskManager节点的数量是固定的,除非通过命令增加节点),会向主节点进行通信汇报心跳。
- Solt:是具体的任务运行的地方,类似于教室里面的工位,是物理的(平均分配cpu、网络带宽、内存等等资源),所以slot的数量决定了同一个时间可以运行的任务的最大数量
4.1.5.核心组件与功能概述
根据你的问题,以下是关于 Apache Flink 的核心组件及其主要功能的详细介绍:
1.DataStream API
- 简介:DataStream API 是 Flink 提供的低级流处理 API,适用于需要细粒度控制的应用场景。
- 特点:
- 事件驱动:处理单个事件或数据流。
- 状态管理:支持有状态的流处理,可以维护状态。
- 窗口操作:支持各种窗口操作,如滚动窗口、滑动窗口等。
- 容错机制:提供强大的容错机制,确保数据处理的可靠性。
- 编程语言:支持python、Java、Scala 编程语言。
2.FlinkSQL(流批一体 API,本次课程以SQL为主)
- 简介:Table API 和 SQL 是 Flink 提供的高级 API,支持流批一体处理。
- 特点:
- 统一接口:使用相同的 API 处理流数据和批数据,简化开发流程。
- SQL 支持:支持标准 SQL 查询,便于数据分析人员使用。
- 优化引擎:内置优化引擎,自动优化查询计划。
- 集成性:与 Flink 的其他组件(如 DataStream API)无缝集成。
- 编程语言:支持 Java、Scala 和 Python 编程语言。
3.图计算(Gelly)
- 简介:Gelly 是 Flink 提供的图计算库,用于处理大规模图数据。
- 特点:
- 图模型:支持多种图模型,如顶点、边、属性图等。
- 算法库:提供丰富的图算法库,如 PageRank、Connected Components 等。
- 分布式计算:利用 Flink 的分布式计算能力,高效处理大规模图数据。
- 灵活性:支持自定义图算法,满足特定需求。
- 编程语言:支持 Java 和 Scala 编程语言。
4.机器学习(FlinkML & Alink)
- 简介:FlinkML 是 Flink 的机器学习库,Alink 是阿里巴巴开源的机器学习平台,与 Flink 集成良好。
- 特点:
- 分布式训练:支持分布式机器学习算法,适合大规模数据集。
- 算法库:提供多种机器学习算法,如分类、回归、聚类等。
- 集成性:与 Flink 的流处理和批处理能力无缝集成。
- 易用性:提供简单的 API,方便开发者使用。
- 编程语言:支持 Java 和 Scala 编程语言。
5.复杂事件处理(FlinkCEP)
- 简介:FlinkCEP 是 Flink 提供的复杂事件处理库,用于检测事件流中的模式。
- 特点:
- 模式检测:支持复杂的事件模式检测,如序列、循环、条件等。
- 实时处理:能够在实时数据流中快速检测模式。
- 灵活性:支持自定义模式和处理逻辑。
- 集成性:与 Flink 的其他组件无缝集成。
- 编程语言:支持 Java 和 Scala 编程语言
4.2.阿里云Flink(商业版)
阿里云实时计算Flink版(Alibaba Cloud Realtime Compute for Apache Flink,Powered by Ververica)是阿里云基于Apache Flink构建的企业级、高性能实时大数据处理系统。
阿里云实时计算Flink版是一套基于Apache Flink构建的⼀站式实时大数据分析平台,提供端到端亚秒级实时数据分析能力,并通过标准SQL降低业务开发门槛,助力企业向实时化、智能化大数据计算升级转型。
阿里云实时计算Flink版是一种全托管Serverless的Flink云服务,开箱即用,计费灵活。具备一站式开发运维管理平台,支持作业开发、数据调试、运行与监控、自动调优、智能诊断等全生命周期能力。100%兼容Apache Flink,支持开源Flink平滑迁移上云,核心企业级增强Flink引擎较开源Flink有约两倍性能的提升。拥有Flink CDC、企业级复杂事件处理(CEP)等企业级增值功能,并内置丰富上下游连接器,助力企业构建高效、稳定和强大的实时数据应用。
4.2.2.产品优势
全托管Flink服务
- 开箱即用
- 开发运维全周期
丰富的企业级能力
- Flink CDC实时入湖入仓
性能强劲
100%兼容开源
- 100% 兼容Apache Flink
- 支持开源 Flink 平滑迁移上云
开放被集成能力强
业界认可

4.2.3.领取资源
①.输入搜索ECS,点击立即领取,
②.选择服务器版本为centos7,大区选择华北2,即可。
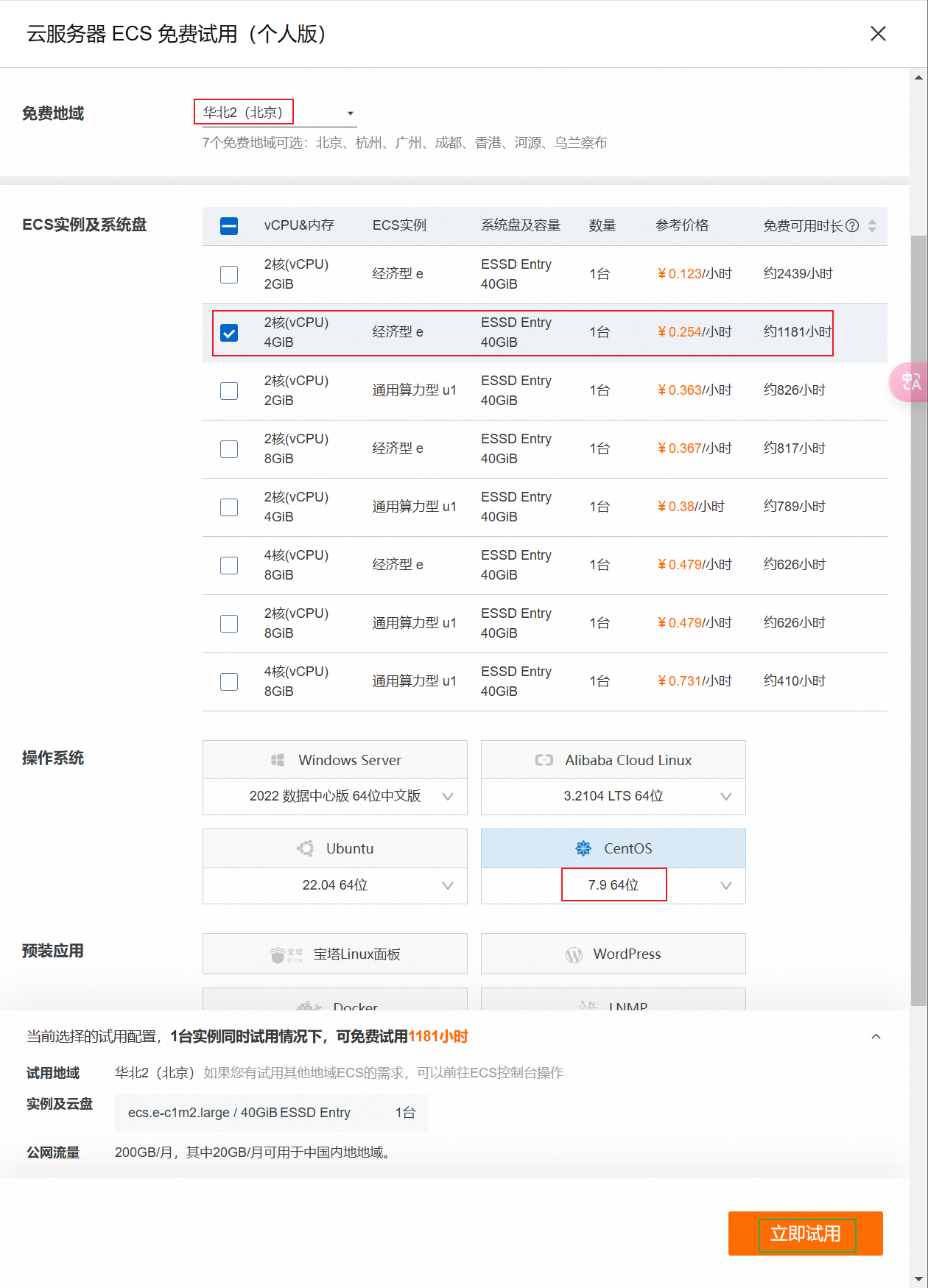
等待创建成功
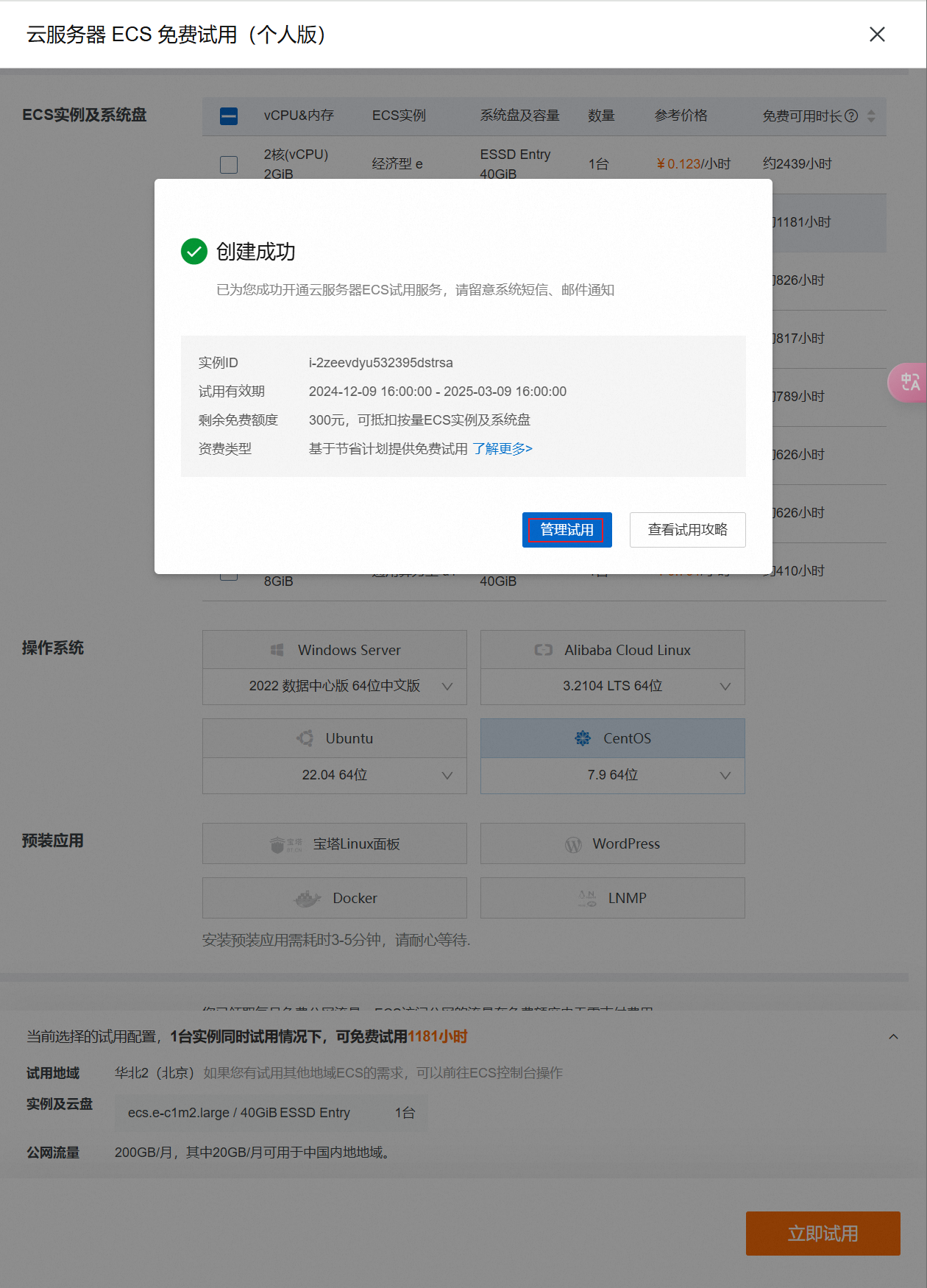
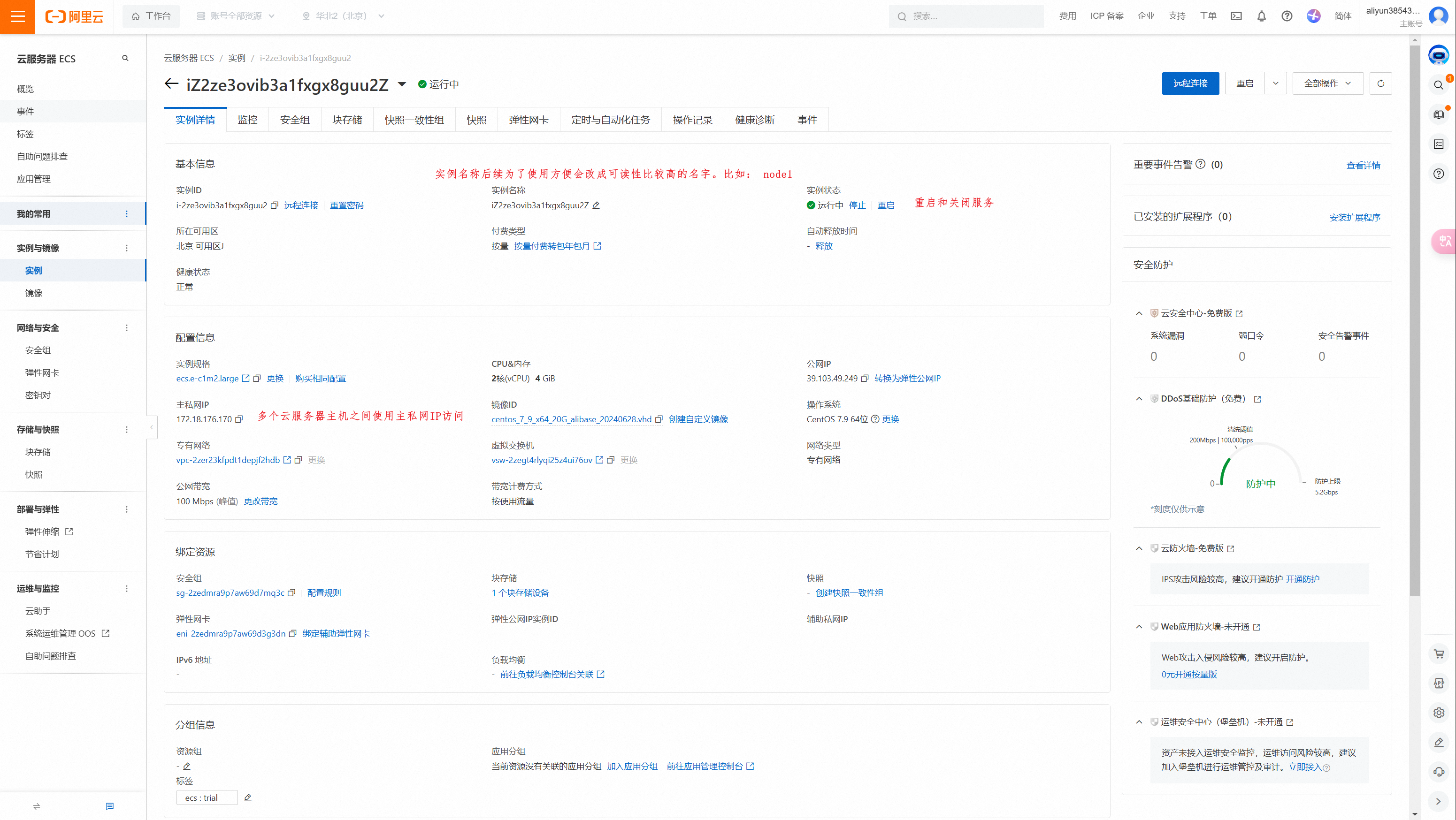
点击前往控制台,可以看到实例状态是待启动。等待几分钟,状态变成运行中。

点击实例名称,进入实例。可以看到实例详情,可以看到公网ip、私网ip等。
ECS已经成功领取。`点击跳过引导任务,查看我的资源`
查看领取的资源主机
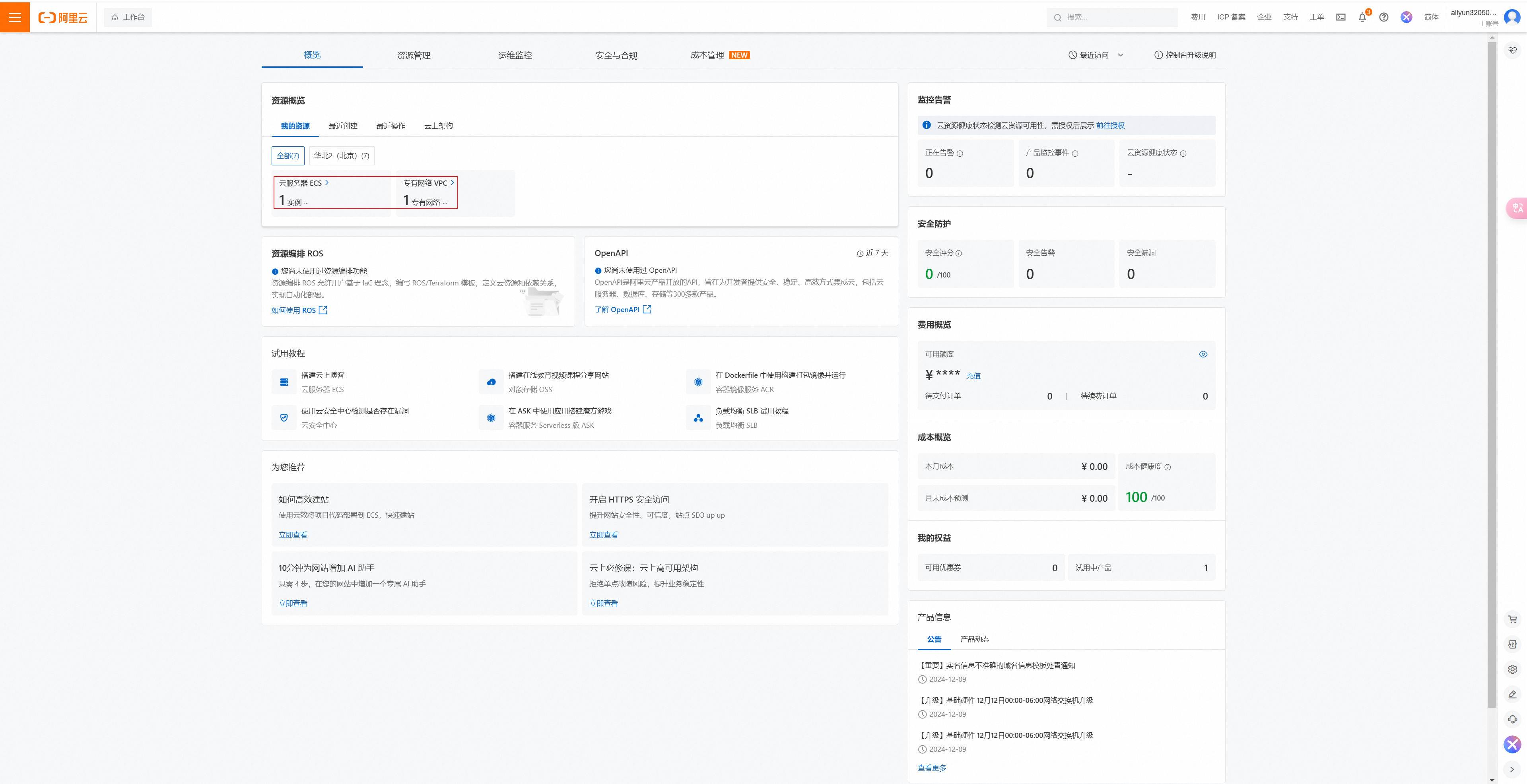
点击VPC。在专有网络和交换机中可以看到一个vpc实例和一个交换机实例。它们是领取ECS过程系统自动创建的。


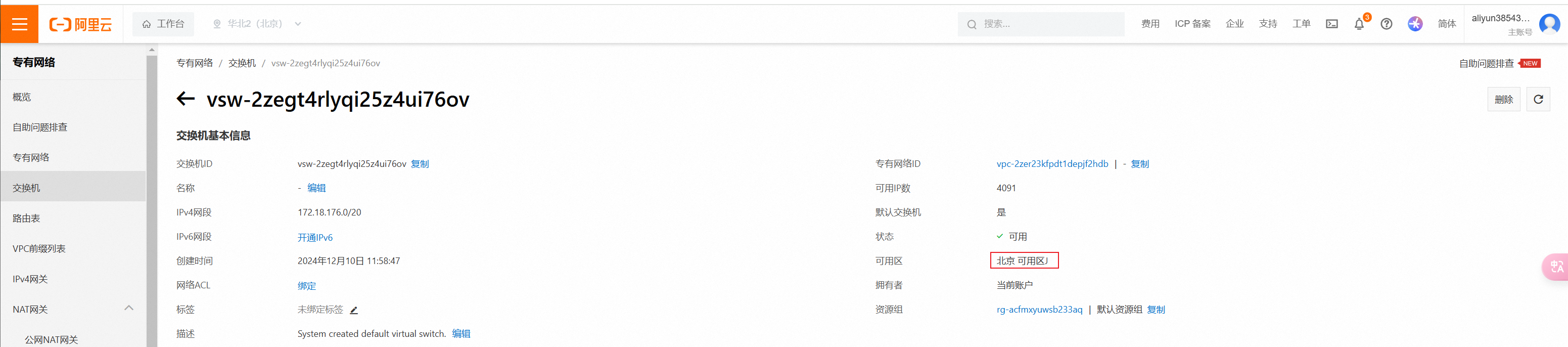
点击交换机实例名,进入详情。可以看到它是北京下的可用区J。之后领取产品时可用区尽量也选择H。所以需要创建对应的交换机。
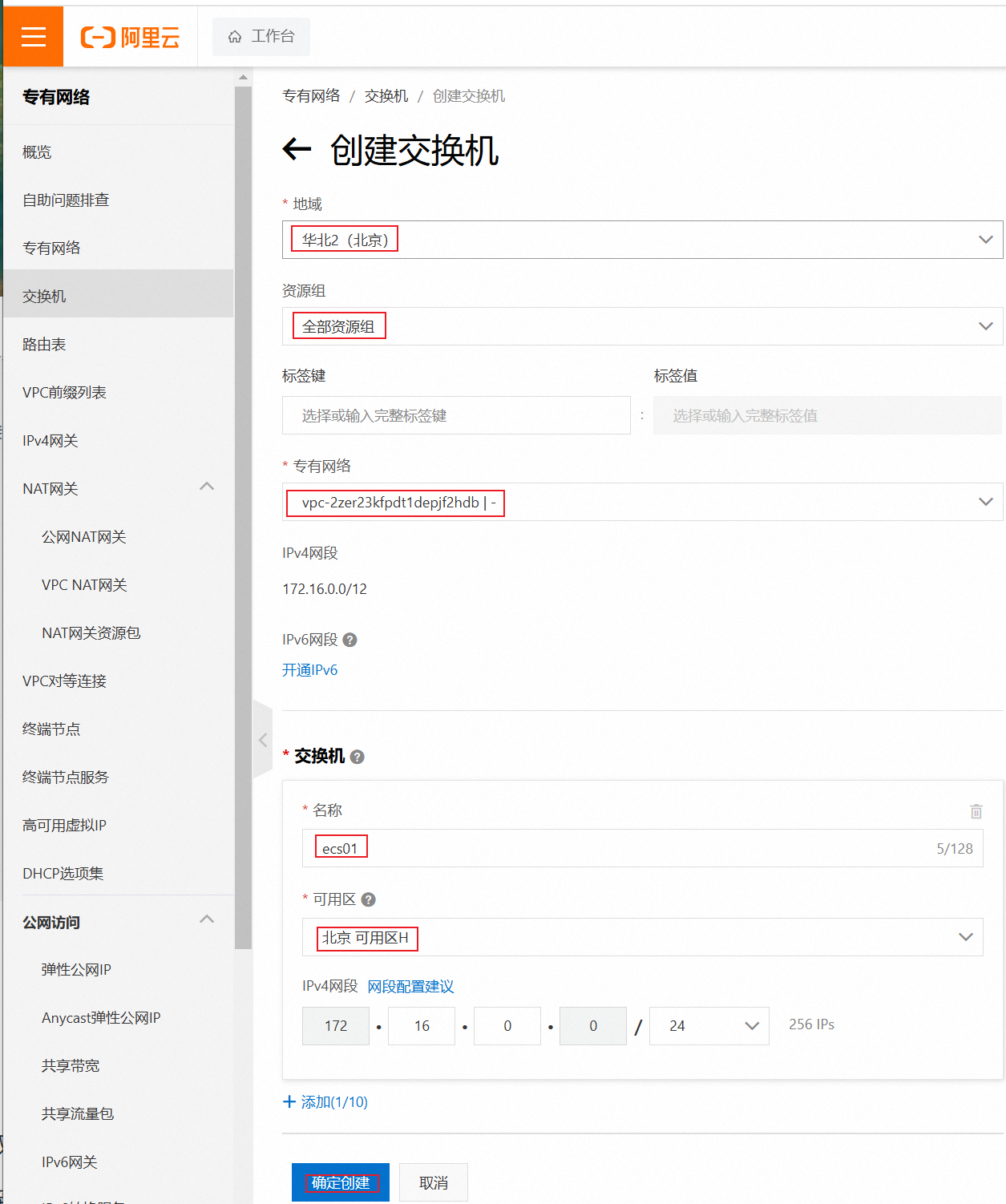
我这里发现是J区的,所以重新创建交换机,选择H区
⑵.Flink
搜索Flink,找到实时计算Flink版,点击立即试用,看到如下页面:
首先点击前往授权
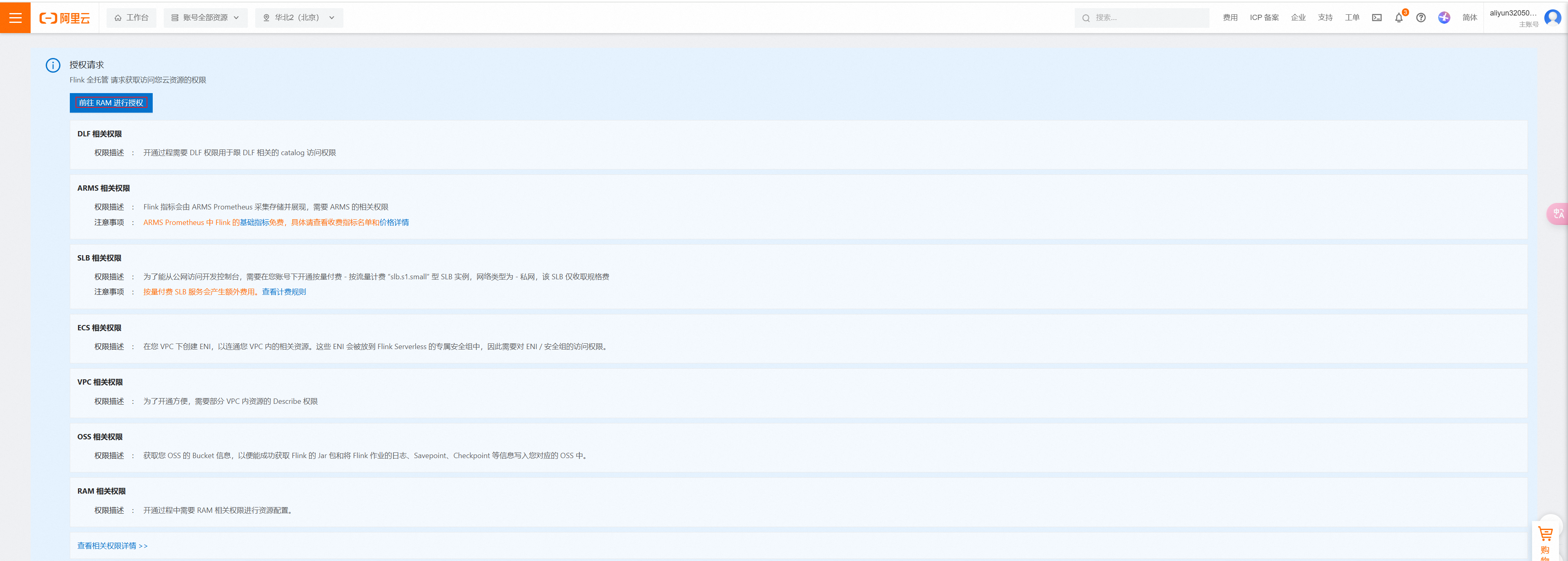
点击同意授权

授权完成后,注意一定要再次点击flink的立即试用(在搜索页面找到后)。进入配置页面,地域选择北京,可用区选择H
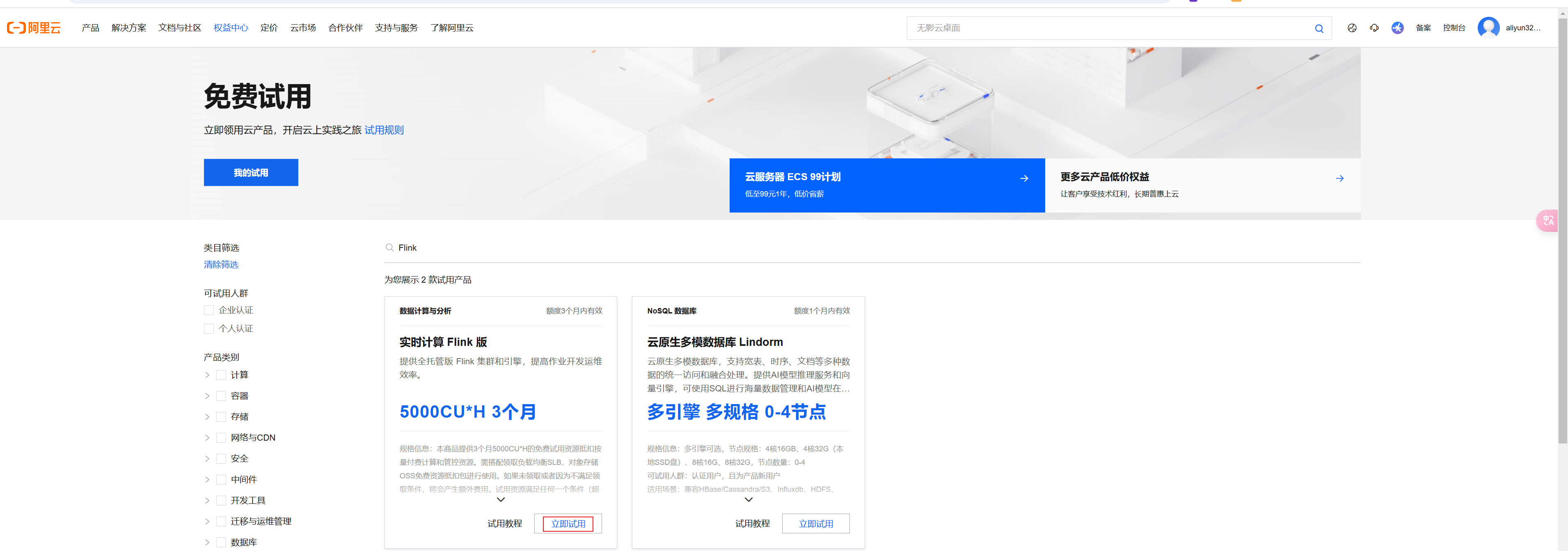
选择按量计费、可用区H、这里先领取资源抵扣包。不领取无法使用的资源抵扣包:
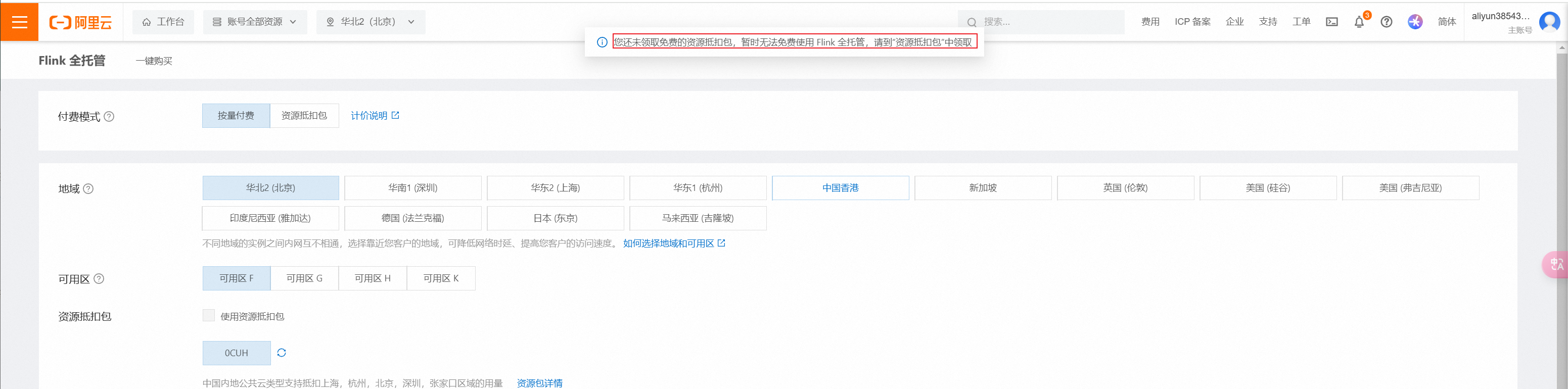
领取操作选择5000CUH,这里自己切换,看那个不收费可以免费领取就选择哪里:
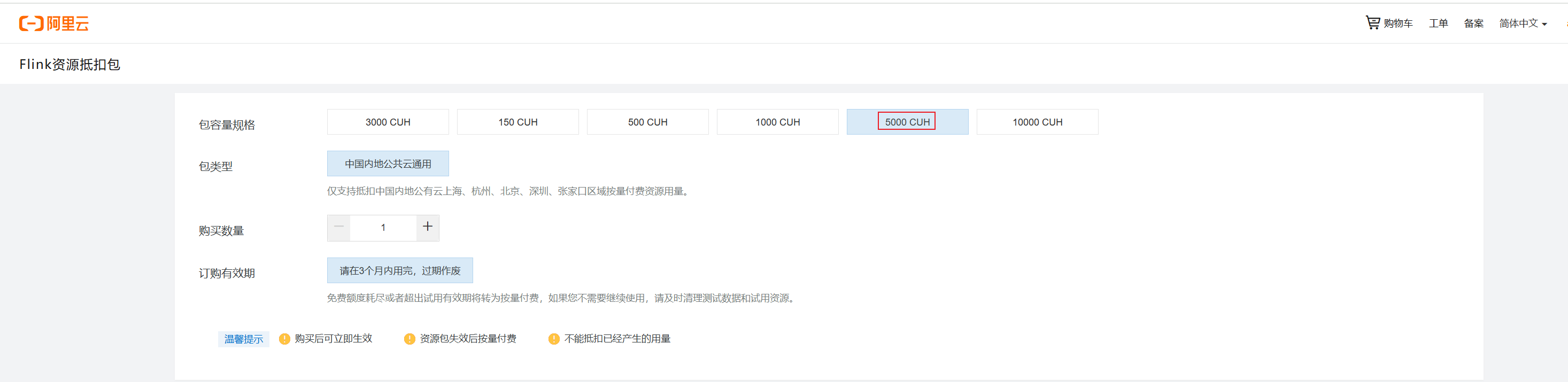
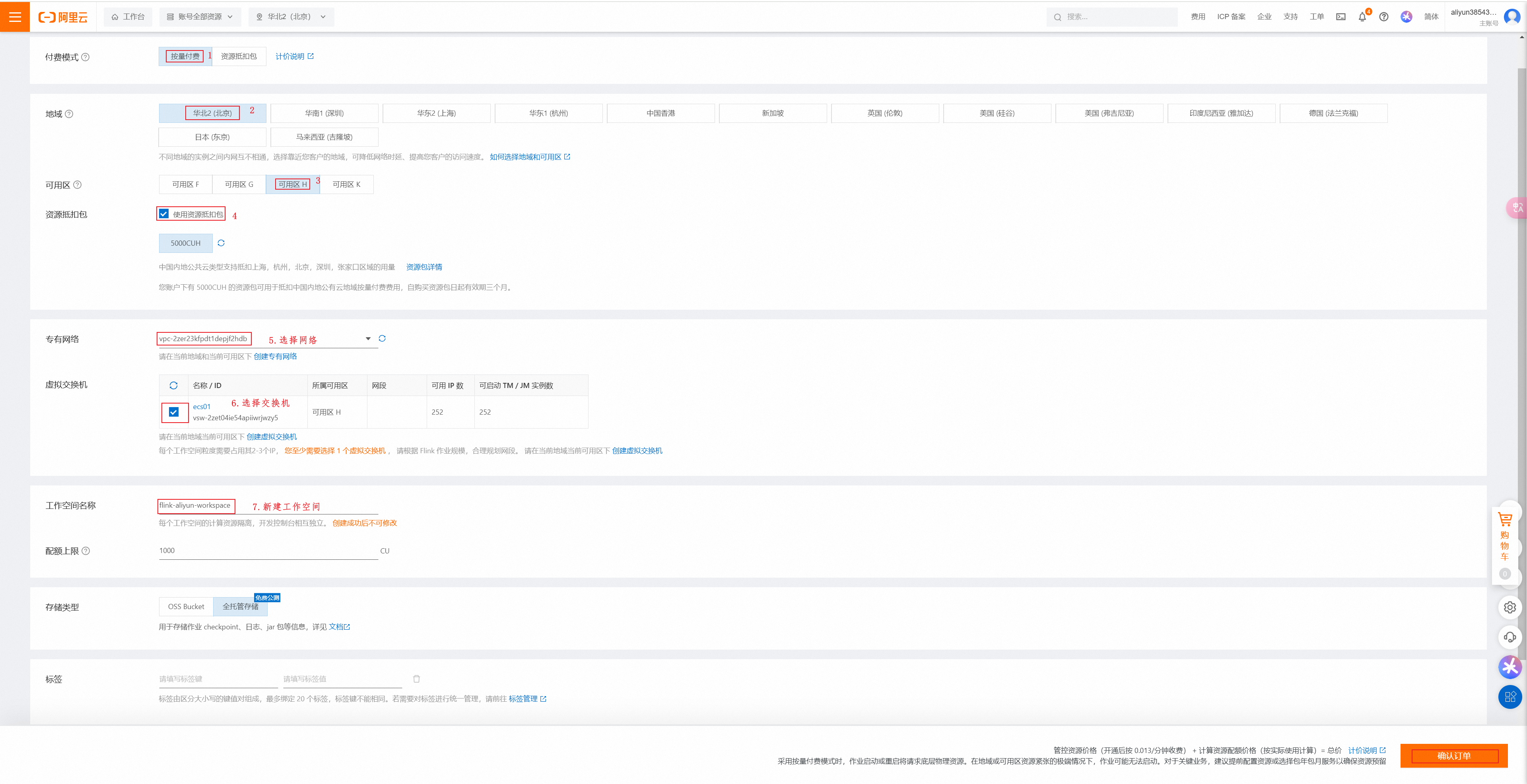
选择按量付费、华北2(北京)、可用区H、使用资源抵扣包、专用网络、虚拟交换机、设置空间名
③.MySQL
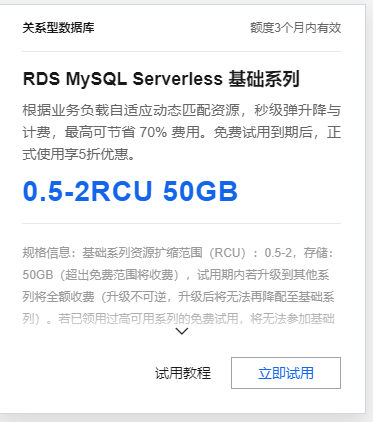
创建MySQL,选择H区,MySQL版本选择5.7
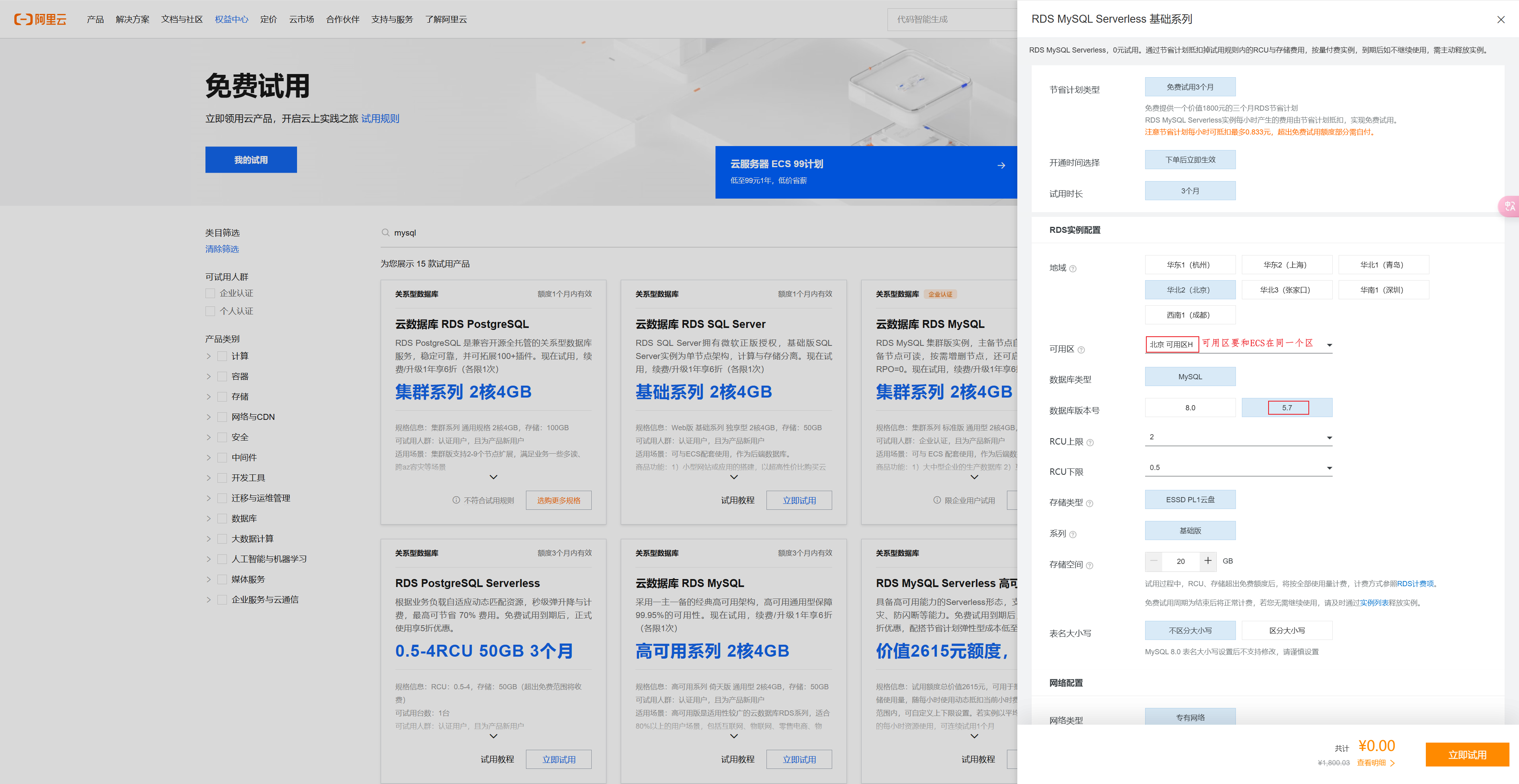
稍等一会儿,能看到服务已经有了:
从运行实例点击进入到设置内部

点击创建账号:
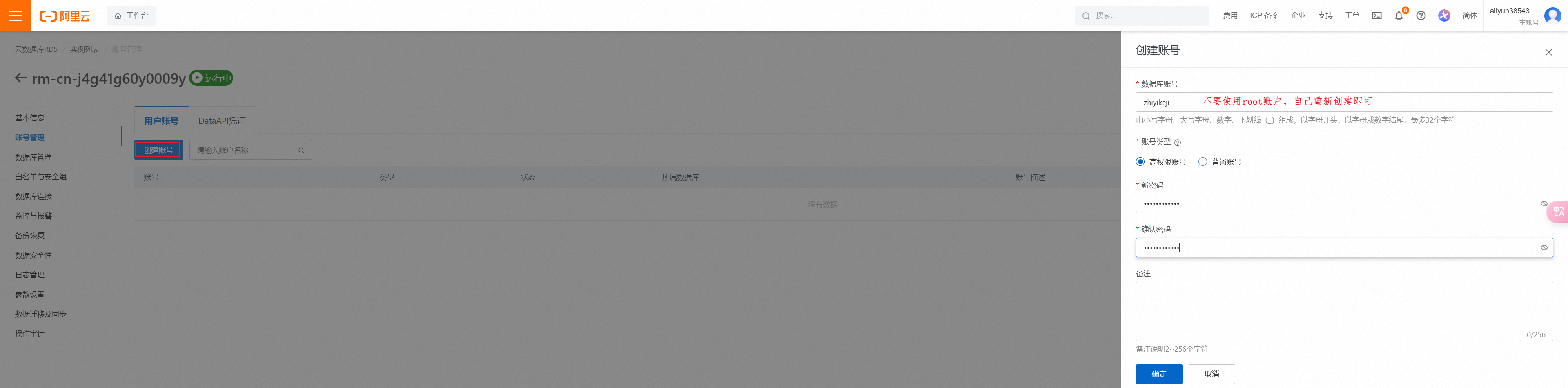
- 账号:zhiyikeji
④.Hologres
搜索Hologres,点击立即试用,先选择创建交换机(名字可以自己随意取,Hologres选择在I区,所以需要创建对应的交换机),
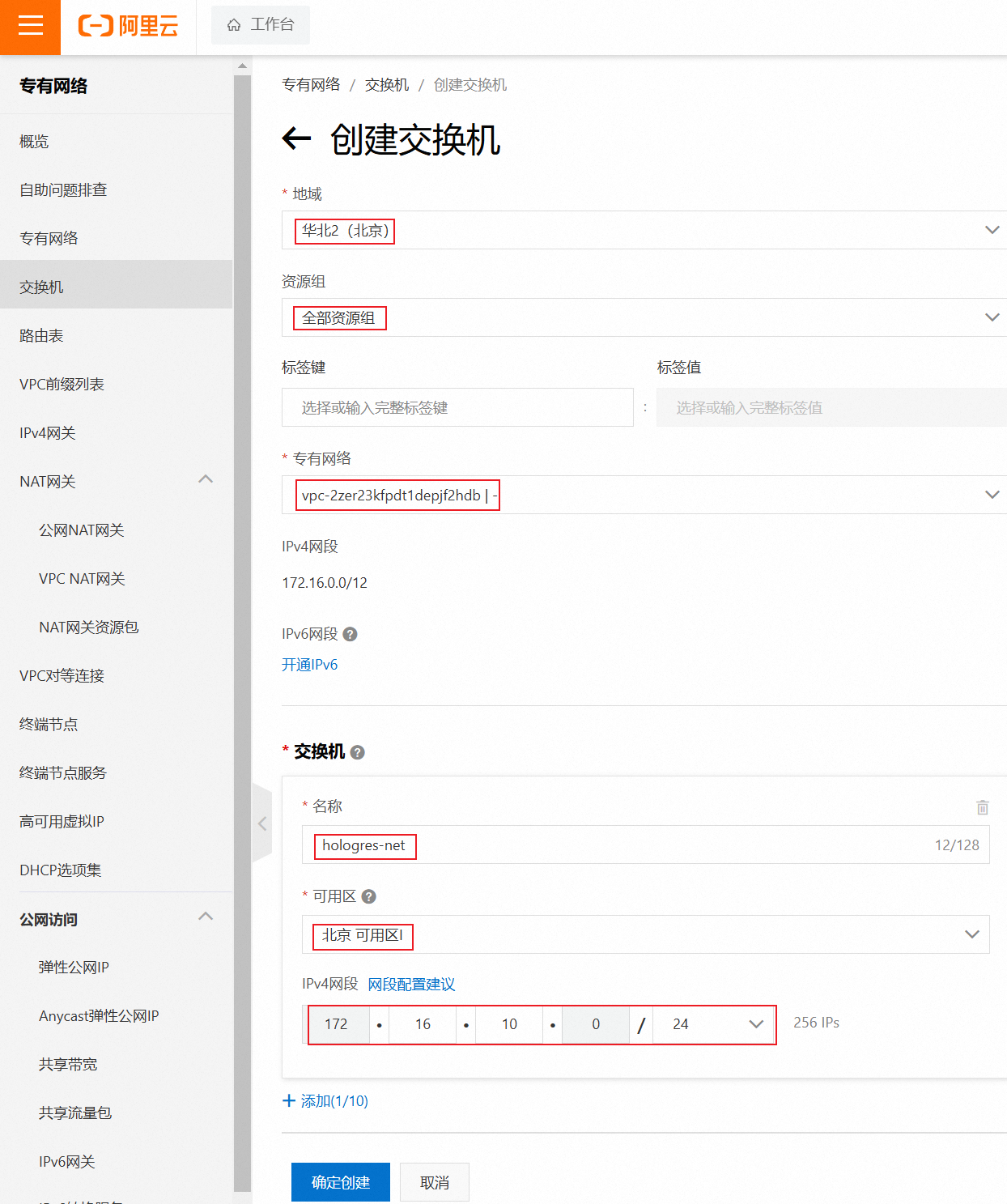
创建完后,选择创建好的交换机即可。
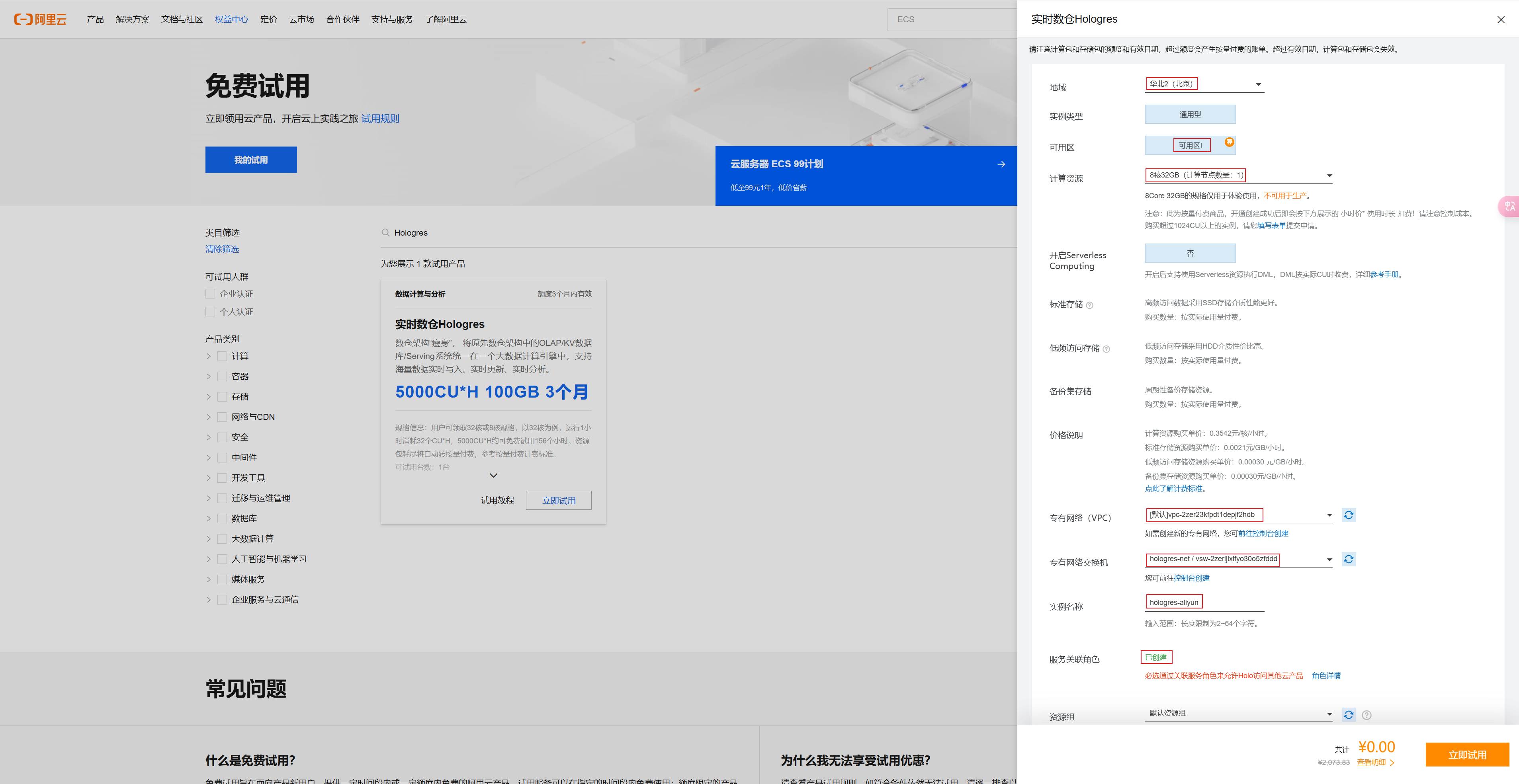
点击立即试用即可。
⑤.共享流量包
搜索”流量“,选择共享流量包,点击立即试用:
我这里没有搜索到流量包,所以买了一个流量包,
⑥.领取SLB(可以后续项目领取)
首先领取SLB,即CLB。如下:
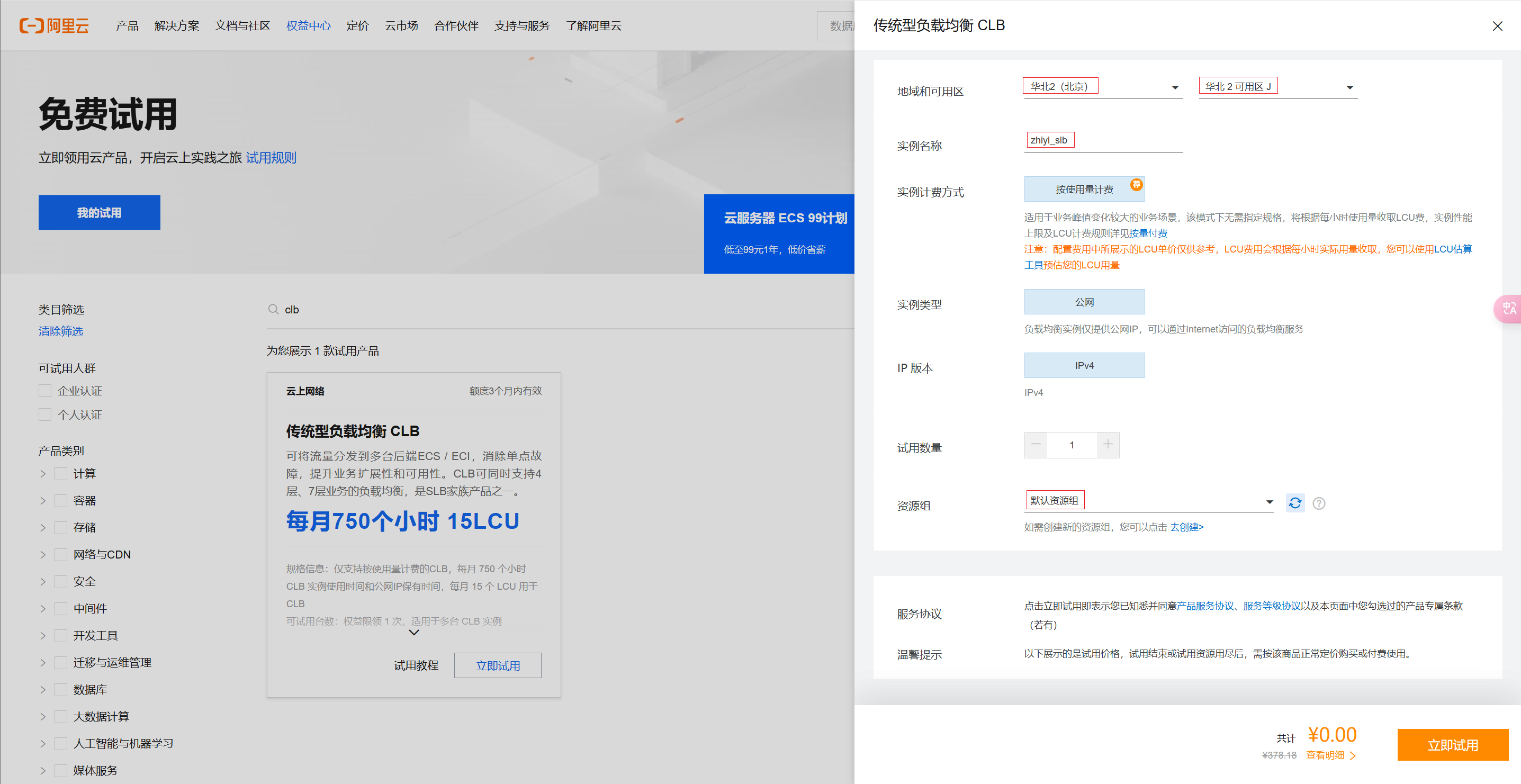
点击立即试用后,按照下图配置
领取完成后,继续领取OSS。
⑦.OSS资源包(可以后续项目领取)
领取完成后,继续领取OSS。
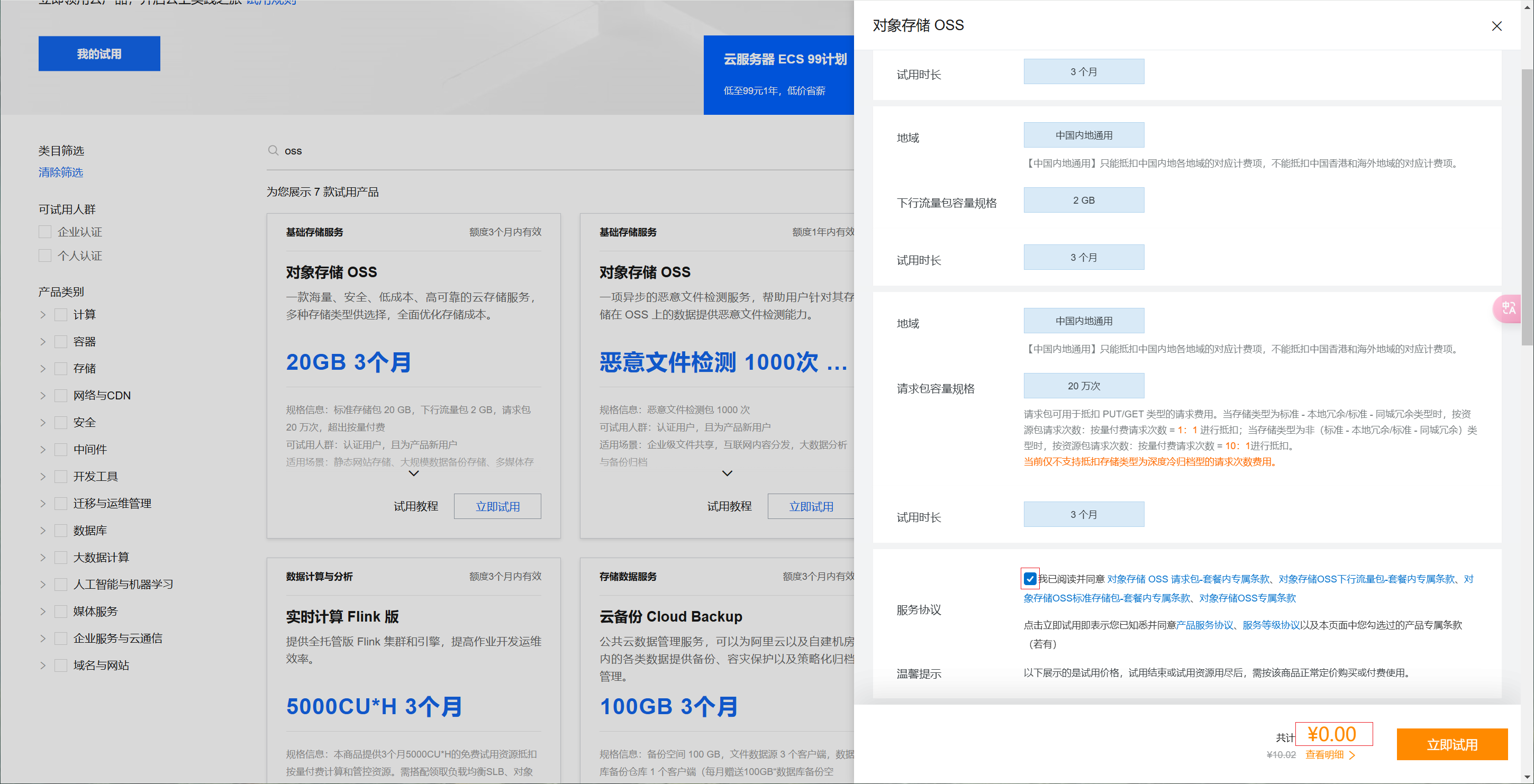
点击立即试用后,参数页面同意服务协议即可,点击立即试用。
点击创建bucket

自定义Bucket名称:如zhiyikeji-ossbucket。地域选择北京,资源组选择默认,其它配置默认即可。
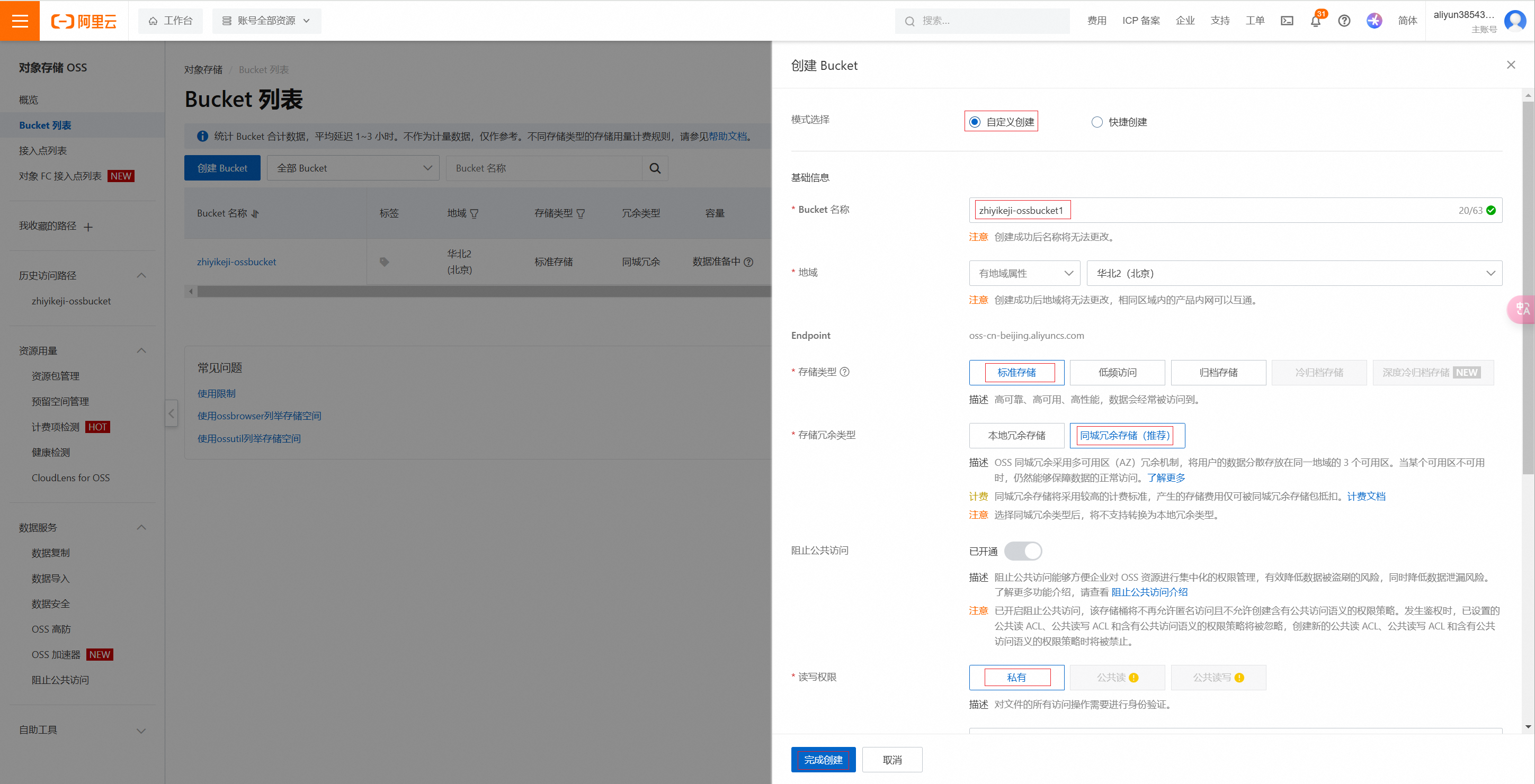
点击确定,即可创建成功。
4.2.4.
⑴.更改实例和主机名

点击实例->实例ID,点击主机名,修改名字即可。
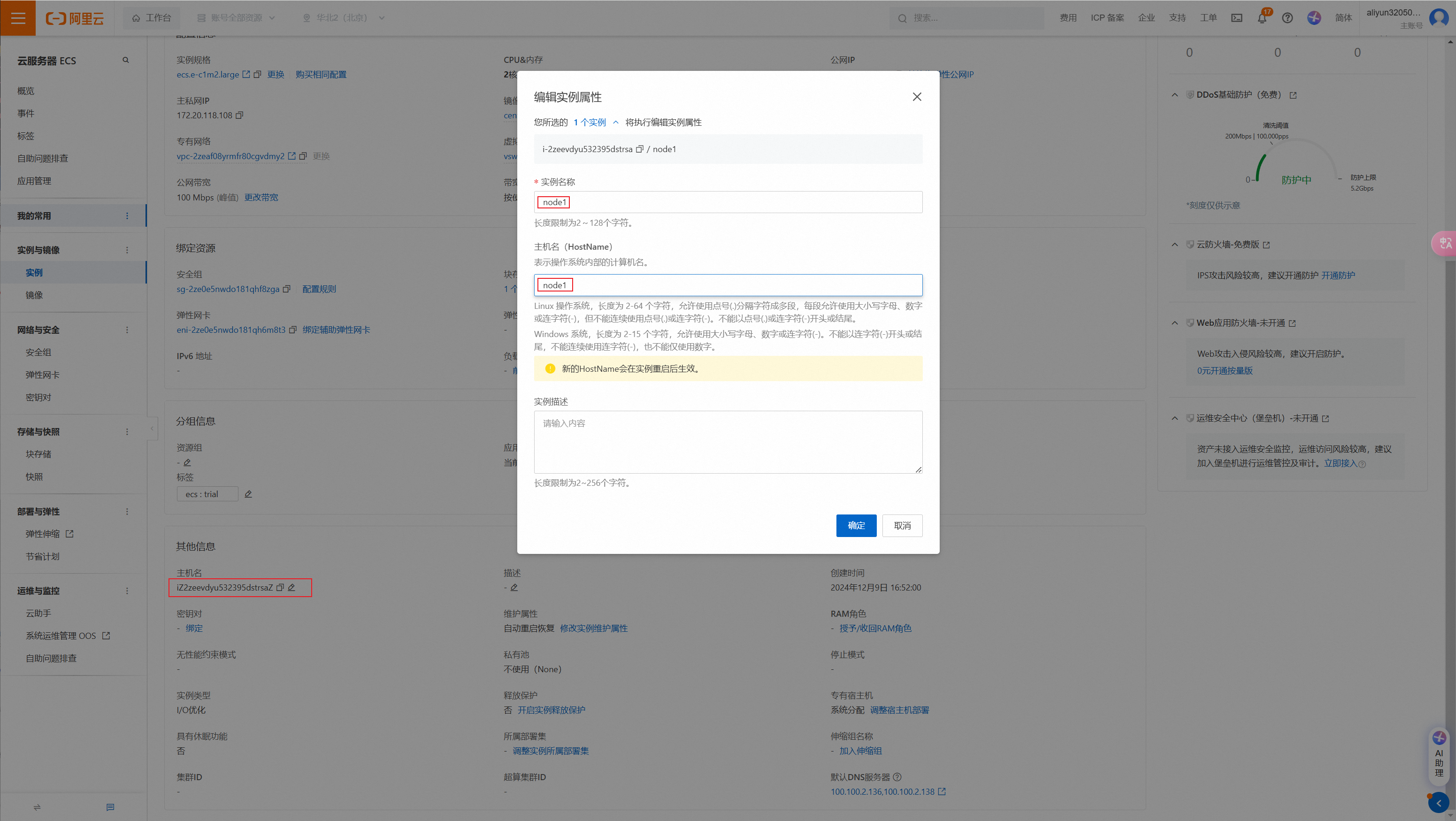
注意:修改完主机名和实例名以后需要重启ecs生效。
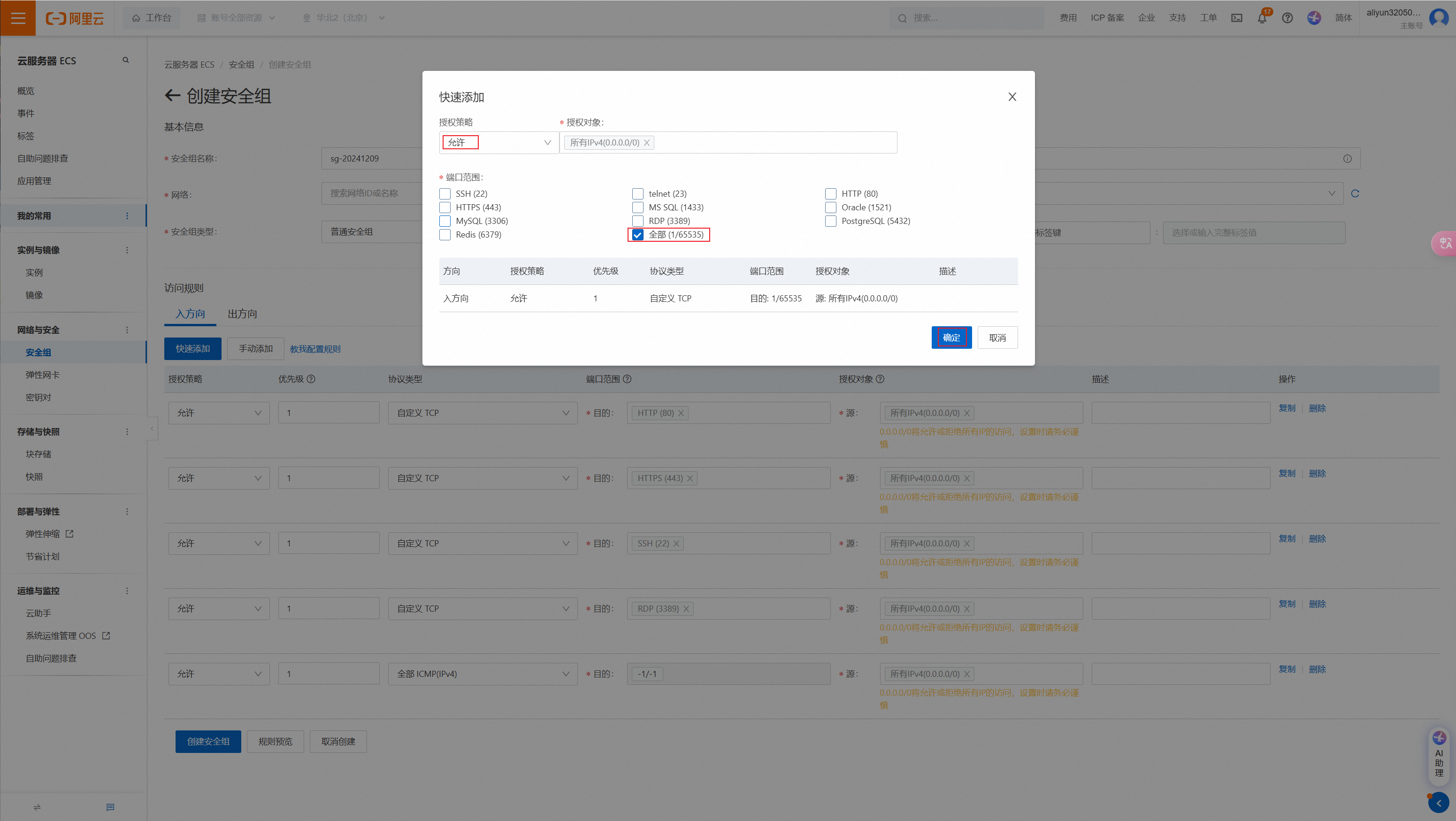
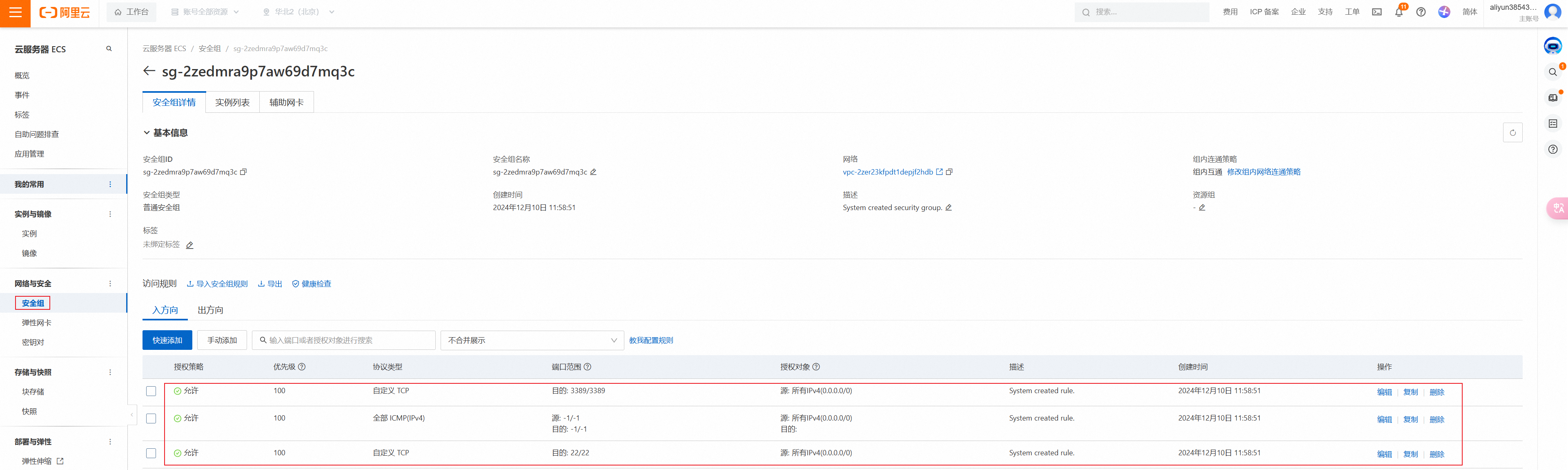
⑵.添加安全组
点击安全组->创建安全组,快速创建,把主机网络加进来。
⑶.重置实例密码
点击实例->实例ID,点击重置密码,输入新密码即可。
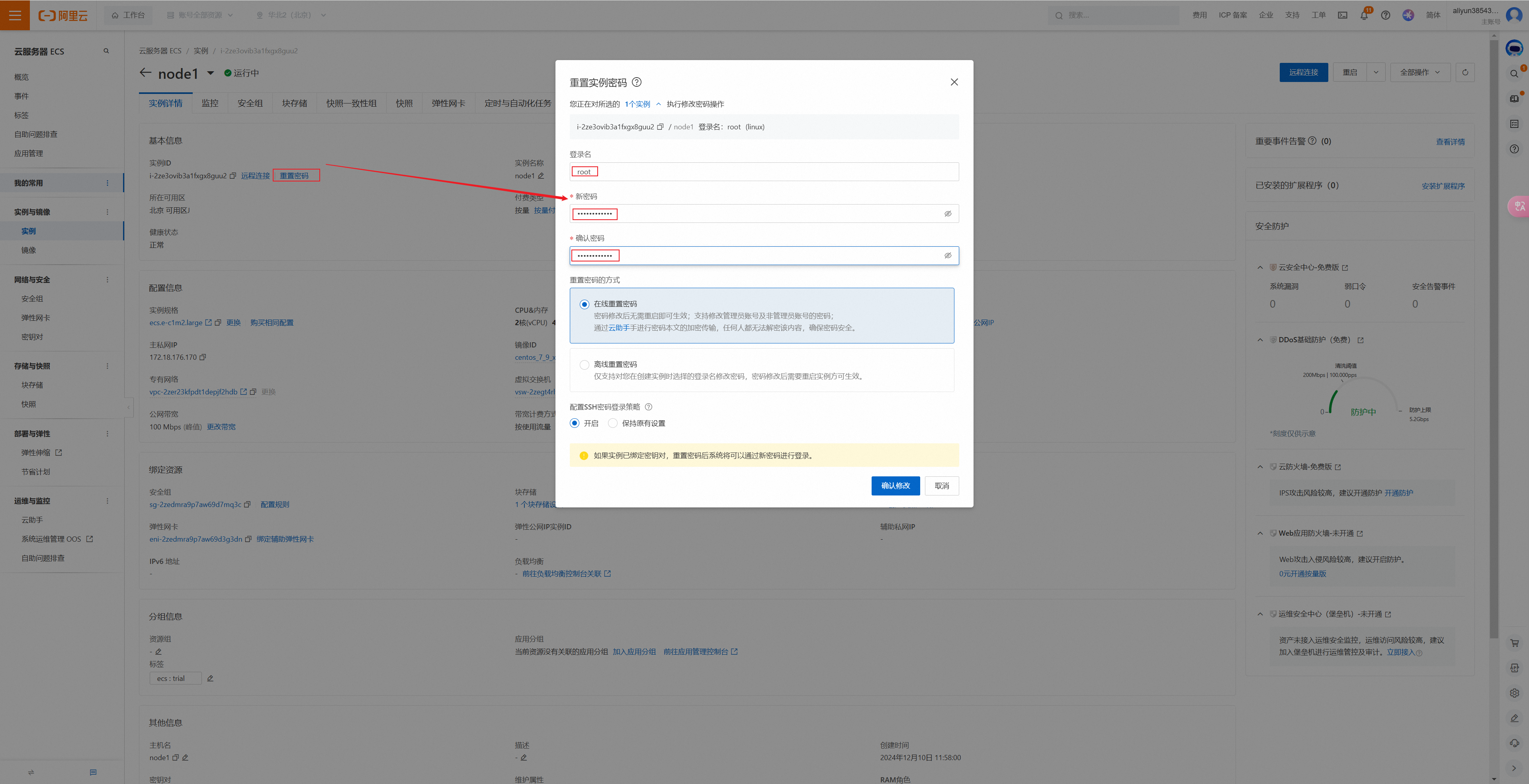
重置密码后,登录服务器,选择私网,输入密码:
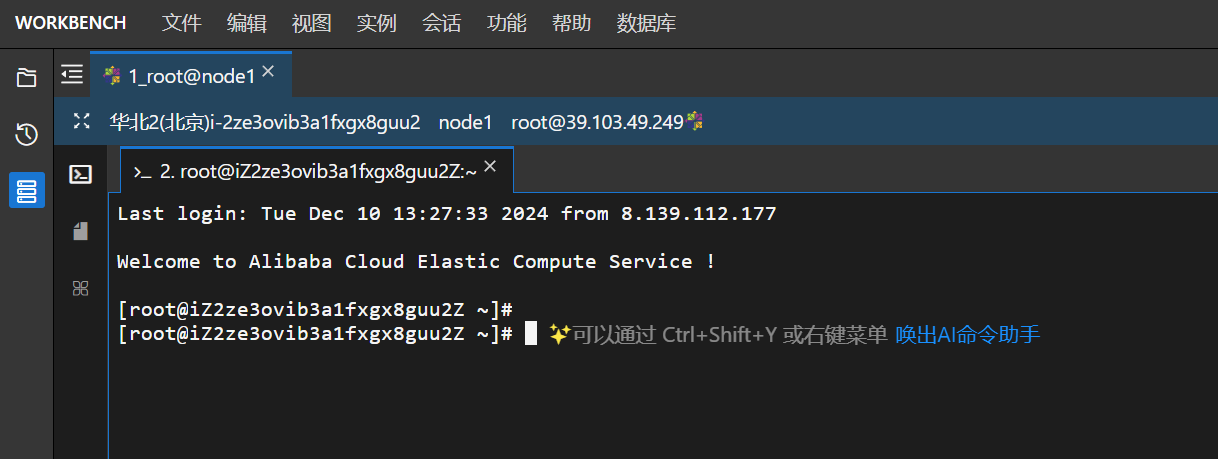
- 用户名:root
⑴.JDK
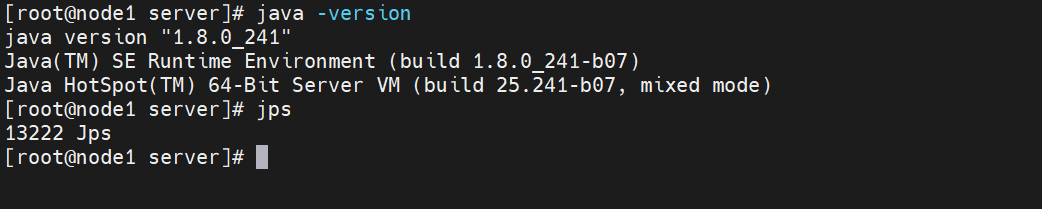
#1.创建目录,用于上传JDK mkdir -p /export/server mkdir -p /export/software #2.来到software目录下,上传JDK #3.解压JDK tar -xf jdk-8u241-linux-x64.tar.gz -C /export/server/ #4.配置环境变量 vi /etc/profile 在文件最后添加如下3行配置 #JAVA_HOME export JAVA_HOME=/export/server/jdk1.8.0_241 export PATH=$PATH:$JAVA_HOME/bin #5.重新加载profile文件 source /etc/profile #6.测试JDK是否安装成功 jps java -version
如下:
⑵.Zookeeper
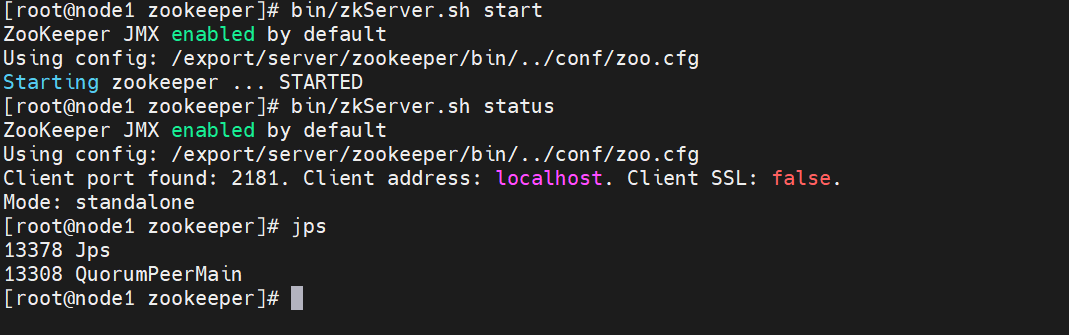
#1.来到software目录下,上传Zookeeper cd /export/software #2.解压Zookeeper tar -xf apache-zookeeper-3.5.10-bin.tar.gz -C /export/server/ #3.回到解压后的目录 cd /export/server #4.创建软连接 ln -s apache-zookeeper-3.5.10-bin/ zookeeper #5.进入Zookeeper安装目录 cd zookeeper #6.配置conf下的zoo.cfg文件 cp conf/zoo_sample.cfg conf/zoo.cfg #7.编辑zoo.cfg文件 vi conf/zoo.cfg文件,修改dataDir这一行,同时添加server.1这一行,保存退出 dataDir=/export/data/zkdata server.1=node1:2888:3888 #8.创建zk存储数据的目录 mkdir -p /export/data/zkdata #9.创建myid文件 echo 1 >/export/data/zkdata/myid #10.启动zookeeper,测试是否安装成功 bin/zkServer.sh start #11.校验是否安装成功 bin/zkServer.sh status
如下:
⑶.kafka
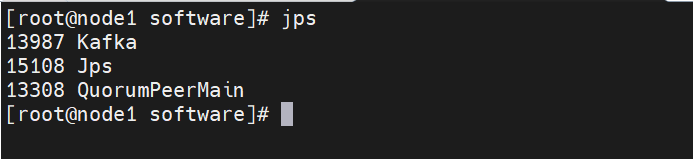
#1.来到software目录下,上传Zookeeper cd /export/software #2.解压kafka tar -xf kafka_2.12-3.5.0.tgz -C /export/server/ #3.回到解压后的目录 cd /export/server #4.创建软连接 ln -s kafka_2.12-3.5.0/ kafka #5.进入kafka安装目录 cd kafka #6.配置conf下的server.properties文件 vim config/server.properties文件,注意下IP地址要改成ECS的丝网IP 34行,放开注释:listeners=PLAINTEXT://172.25.71.118:9092 62行:log.dirs=/export/data/kafka-logs 125行:zookeeper.connect=172.25.71.118:2181 #7.配置环境变量 #ZK_HOME export ZOOKEEPER_HOME=/export/server/zookeeper export PATH=$PATH:$ZOOKEEPER_HOME/bin #KAFKA_HOME export KAFKA_HOME=/export/server/kafka export PATH=$PATH:$KAFKA_HOME/bin #8.尝试启动kafka bin/kafka-server-start.sh config/server.properties #9.正式启动 nohup bin/kafka-server-start.sh config/server.properties > /tmp/kafka.log &
如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号