Hive架构设计和Hive Driver执行流程
一、Hive架构设计
1.1.Hive架构设计
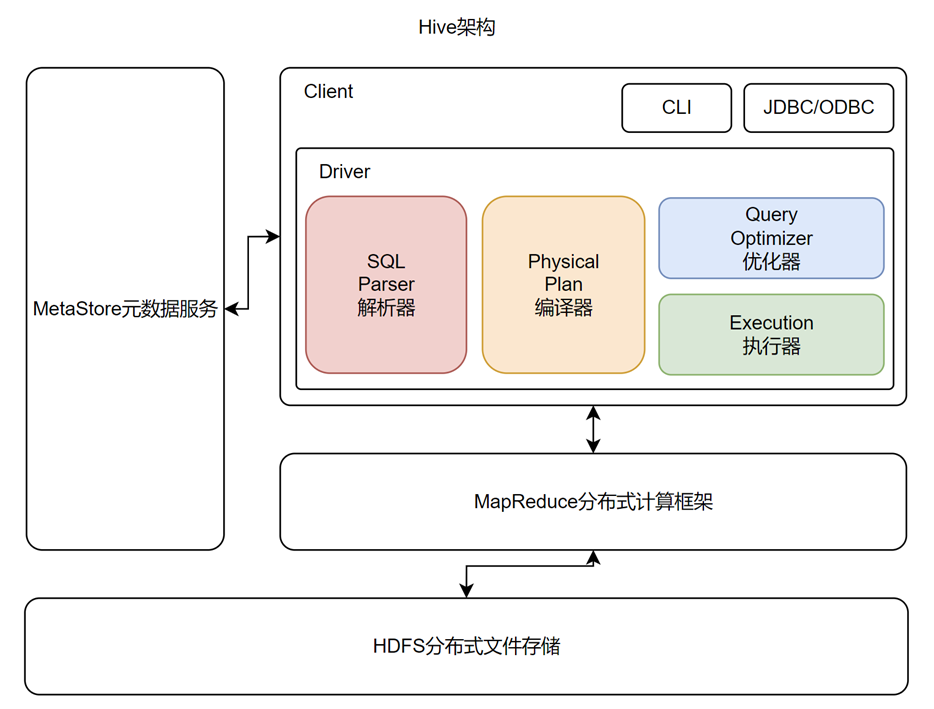
由上图可知,Hive全局架构图中可以看到Hive架构包括如下组件:CLI(command line interface)、JDBC/ODBC、MetaStore和Driver(Compiler、Optimizer)。
CLI:command line interface,命令行接口
MetaStore组件:元数据服务组件,这个组件用于存储Hive的元数据,包括表名、表所属的数据库、表的拥有者、列/分区字段、表的类型、表的数据所在目录等内容。Hive的元数据存储在关系数据库里,支持Derby、MySQL两种关系型数据库。元数据对于Hive十分重要,因此Hive支持把MetaStore服务独立出来,安装到远程的服务器集群里,从而解耦Hive服务和MetaStore服务,保证Hive运行的健壮性。
Driver组件:该组件包括Parser、Compiler、Optimizer和Executor,它的作用是将我们写的HiveSQL(类SQL)语句进行解析、编译、优化,生成执行计划,然后调用底层的MapReduce计算框架。
- 解析器(Parser):将SQL字符串转化为抽象语法树AST;
- 编译器(Compiler):将AST编译成逻辑执行计划;
- 优化器(Optimizer):对逻辑执行计划进行优化;
- 执行器(Executor):将逻辑执行计划转成可执行的物理计划,如MR/Spark
1.2.Hive表设计原理
1.Hive查询基本原理
Hive的设计思想是通过元数据解析描述将HDFS上的文件映射成表;
基本的查询原理是当用户通过HQL语句对Hive中的表进行复杂数据处理和计算时,默认将其转换为分布式计算MapReduce程序对HDFS中的数据进行读取处理的过程。
2.创建数据库、数据表
在Hive中创建数据库、数据库下再创建一张表tb_login并加载数据到表中
--创建数据库 create database tb_part; --创建表 create table tb_login( userid string, logindate string) row format delimited fields terminated by '\t'; -- 加载数据 load data local inpath '/tmp/login.log' into table tb_login;
3.查看对应存储路径
HDFS中自动在Hive数据仓库的目录下和对应的数据库目录下,创建表的目录
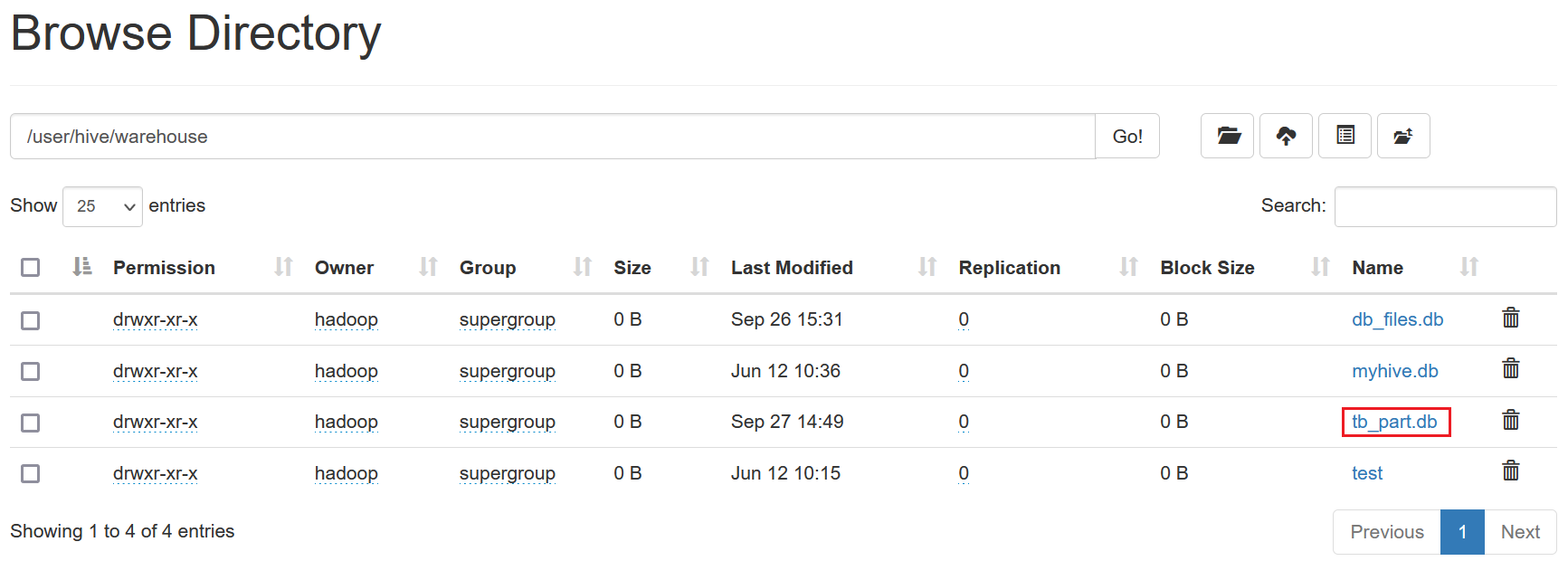
HDFS中自动在Hive数据仓库的目录下和对应的数据库目录下,创建表的目录
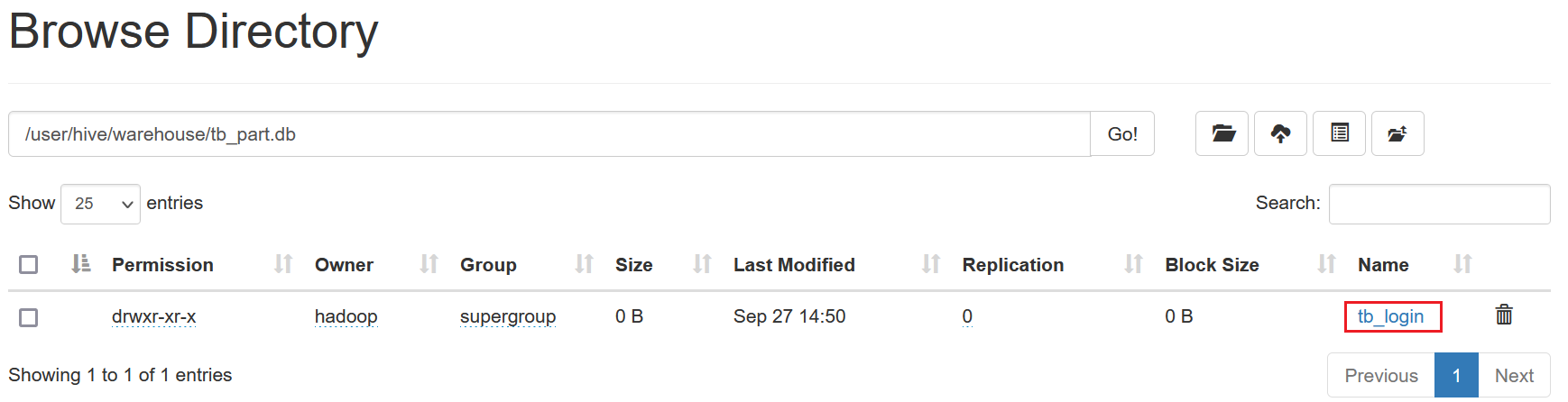
加载数据后,数据会自动被关联到表对应的HDFS的目录中
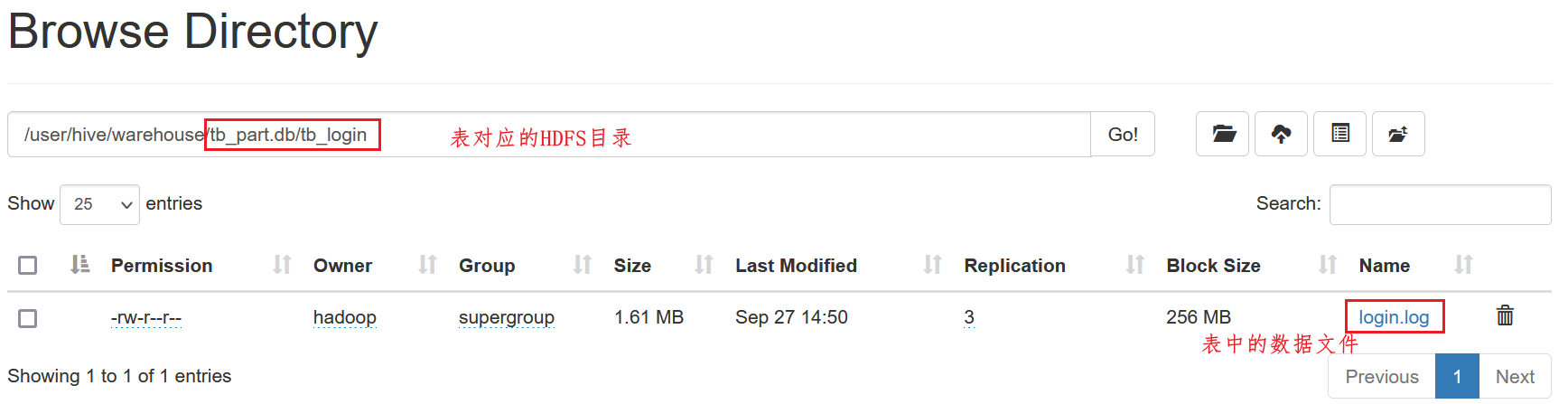
4.数据可以正常被查询
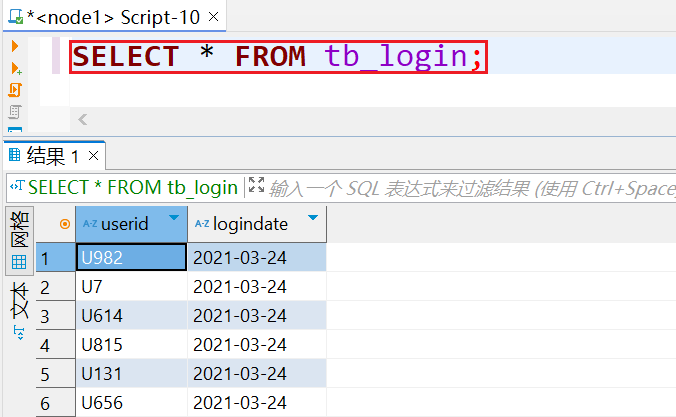
当执行查询计划时,Hive会使用表的最后一级目录作为底层处理数据的输入
-- 统计3月24号的登录人数 select logindate,count(*) as cnt from tb_login where logindate = '2021-03-24' group by logindate;
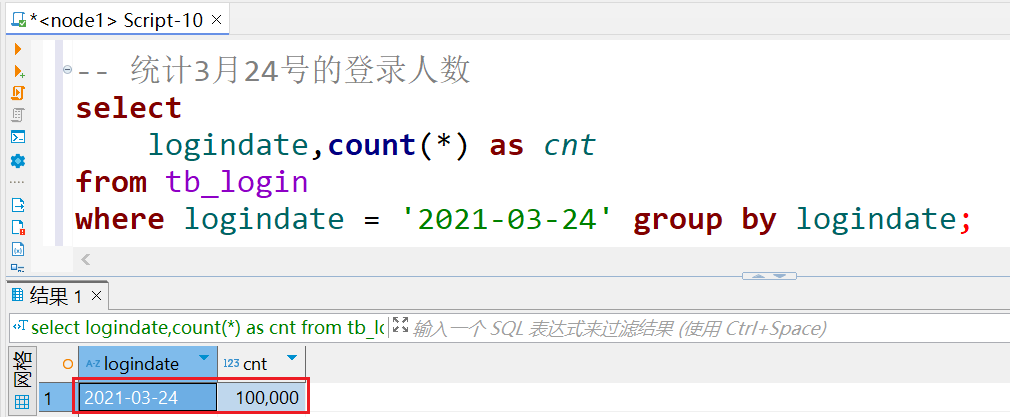
5.当执行查询计划时,Hive会使用表的最后一级目录作为底层处理数据的输入
- Step1:先根据表名在元数据中进行查询表对应的HDFS目录(元数据中显示:该表对应的SD_ID为42)
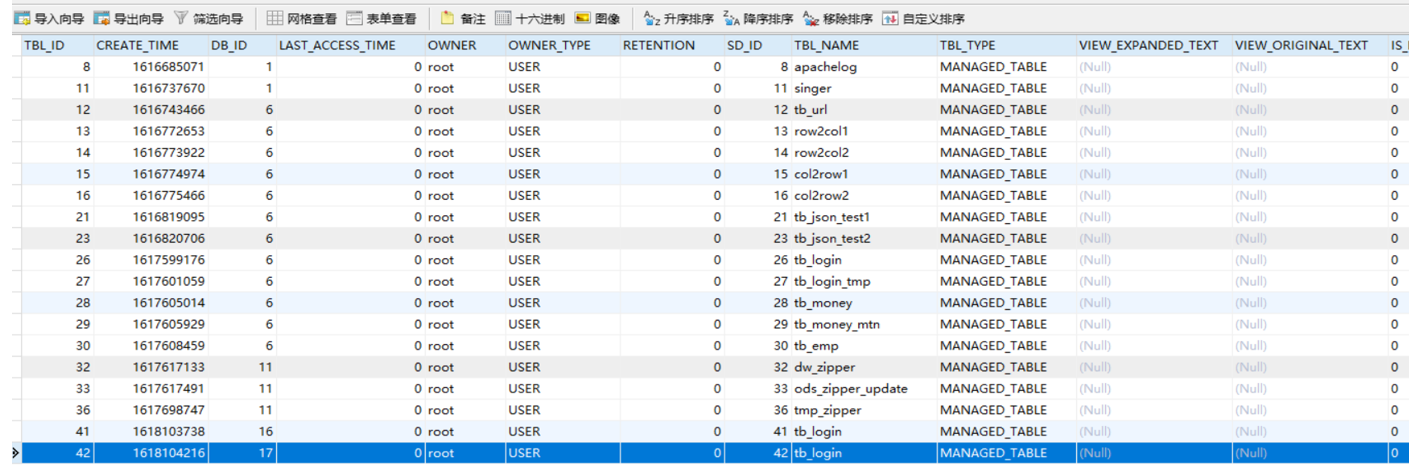
- Step2:然后将整个HDFS中表的目录作为底层查询的输入,可以通过explain命令查看执行计划依赖的数据(SDS元数据表中记录每个SD_ID对应的HDFS的目录位置)
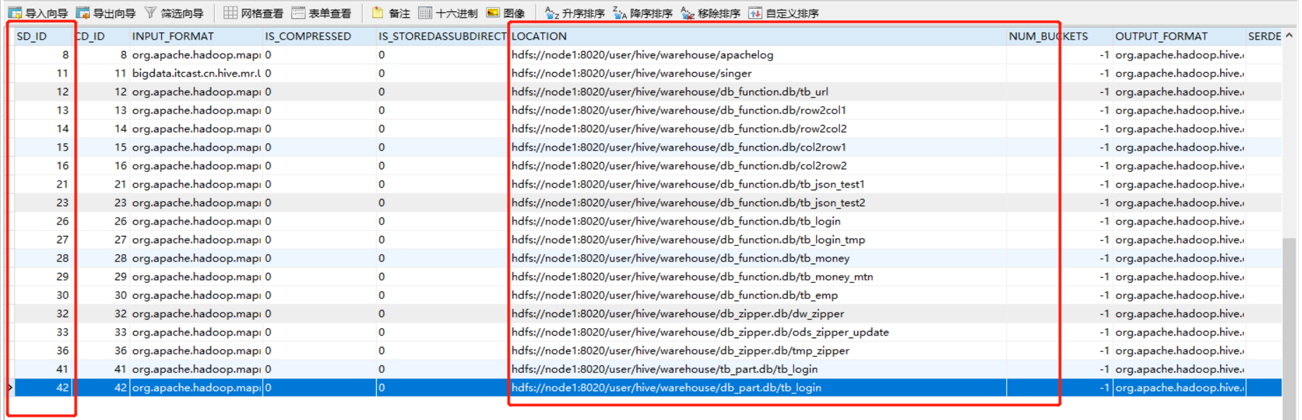
- Step2:然后将整个HDFS中表的目录作为底层查询的输入,可以通过explain命令查看执行计划依赖的数据
explain extended select logindate,count(*) as cnt from tb_login where logindate = '2021-03-24' group by logindate;

二、Hive Driver执行流程
2.1.Hive解析器
Hive语法解析器是Hive的第一步,它负责将用户输入的查询语句转化为抽象语法树(AST)。AST是一种树状结构,用于表示查询语句的语法结构。Hive使用ANTLR(Another Tool for Language Recognition)工具生成语法解析器,ANTLR是一个流行的语法解析器生成器,它基于LL(*)算法。
下面是一个示例的Hive查询语句:
SELECT name, age FROM students WHERE age > 18;
语法解析器将此查询语句解析器为如下的抽象语法树:
外部工具推荐: https://astexplorer.net/
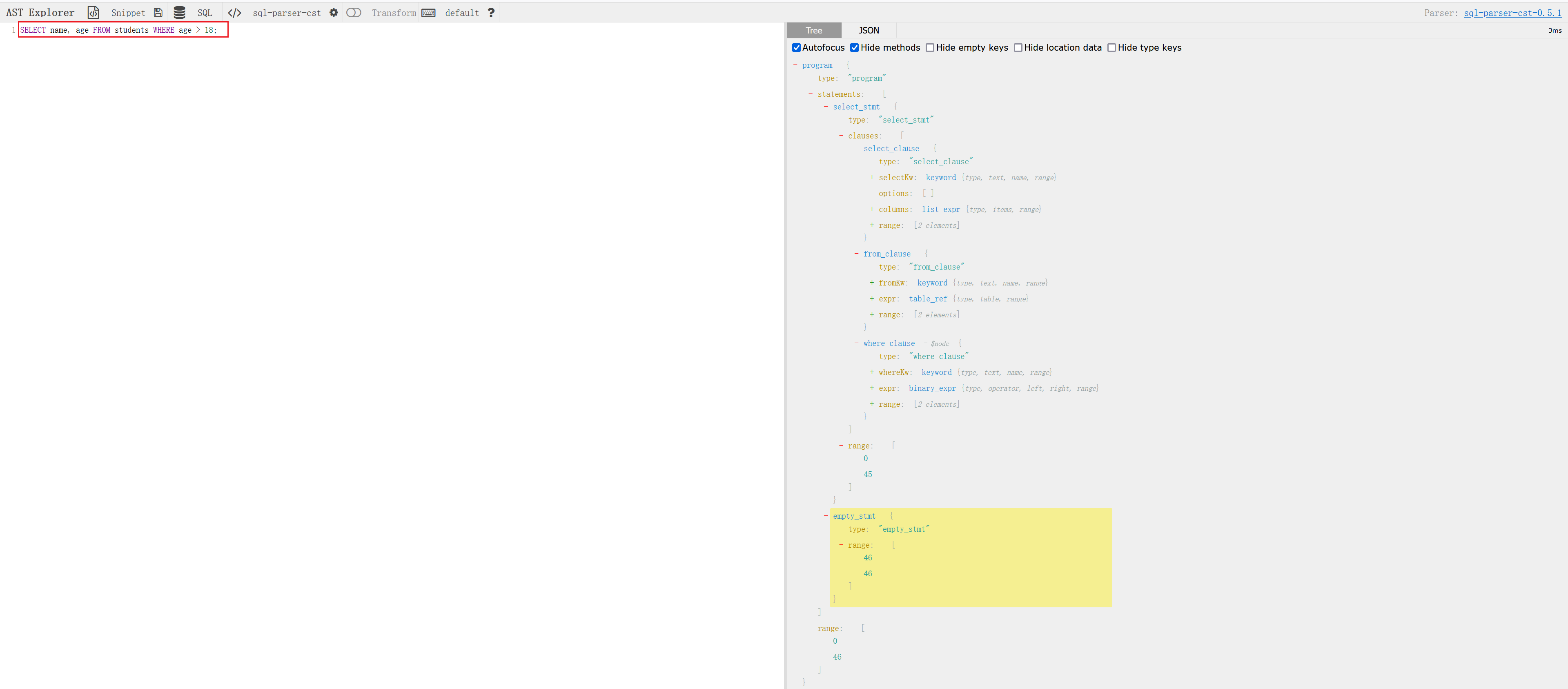
上图中,根节点是一个“program”,表示整个程序。它包含一个“statements”节点,表示程序中的语句。这个“statements”节点下有一个“select_stmt”节点,表示一个SQL的SELECT语句。“select_stmt”节点下有几个子节点:
- from_clause:表示FROM子句,包含表名或数据源。
- where_clause:表示WHERE子句,包含查询条件。
- empty_stmt:表示一个空语句。
2.2. Hive编译器
Hive编译器的主要工作包括语法检查、语义分析。首先,编译器会进行语法检查,确保查询语句符合Hive的语法规则。然后,编译器会进行语义分析,检查表和列是否存在,以及查询语句是否合法。
以下是一个示例的Hive查询语句的编译过程:
SELECT name, age FROM students WHERE age > 18;
编译器将AST转化为以下的查询执行计划:
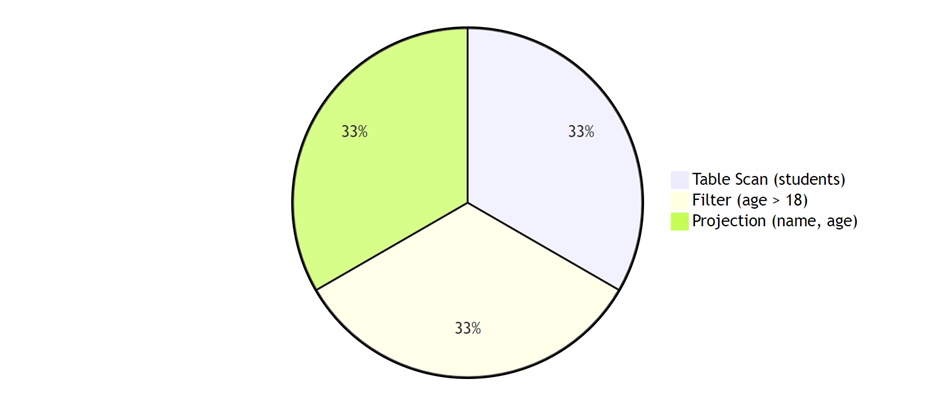
查询执行计划表示查询的执行顺序和方式。在上述示例中,首先进行表扫描(Table Scan),然后使用过滤器(Filter)筛选出年龄大于18的记录,最后进行投影(Projection),只返回name和age两列。
2.3.Hive优化器
Hive优化器会根据执行计划进行优化,它会尝试重新组织查询以提高性能。优化器可以执行诸如重排序操作、选择最佳连接方法以及应用常见的查询优化技术(如谓词下推、表达式求值等)。
谓词下推(Predicate Pushdown):
- 优化器会尝试将过滤条件“age > 18”下推到数据源,即在读取数据时应用过滤条件。这样可以减少传输到执行器的数据量,提高性能。
列剪裁(Column Pruning):
- 由于查询中只需要返回“name”和“age”列,优化器可能会对数据源执行列剪裁操作,只选择这两列,而不是读取整个表的所有列。这样可以减少内存和网络传输开销。
使用索引(Index Usage):
- 如果表“students”上存在适当的索引,优化器可能会选择使用索引来加速查询。例如,如果存在“age”字段的索引,优化器可以使用该索引来快速定位年龄大于18的记录。
统计信息使用(Statistics Usage):
- 优化器可能会使用表“students”的统计信息来估计数据分布和大小,以帮助决定执行计划。例如,它可以使用统计信息来确定过滤条件“age > 18”会过滤掉多少行,从而选择最佳的执行计划。
重新连接顺序(Reordering Joins):
- 虽然这个查询只涉及单个表,但是如果存在多个表的连接操作,优化器可能会重新排列连接的顺序,以选择最优的连接顺序。
2.4.Hive执行器
Hive执行器根据经过优化的执行计划执行查询,并将结果返回给用户。执行器首先根据查询执行计划生成一系列的MapReduce任务,然后将这些任务提交给Hadoop集群进行执行。执行过程中,执行器会监控任务的状态,并在任务完成后将结果返回给用户。
下面是一个示例的Hive查询执行过程:
SELECT name, age FROM students WHERE age > 18;
- 执行器根据查询执行计划生成以下的MapReduce任务:
- Map任务:对students表进行扫描,并将满足条件的记录发送给Reduce任务。
- Reduce任务:进行投影操作,只输出name和age两列。
- 执行器将以上的任务提交给Hadoop集群执行,并在任务完成后将查询结果返回给用户。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号