计算Job执行优化
一、Explain
1.1.功能
HiveQL是一种类SQL的语言,从编程语言规范来说是一种声明式语言,用户会根据查询需求提交声明式的HQL查询,而Hive会根据底层计算引擎将其转化成Mapreduce/Tez/Spark的 job。大多数情况下,用户不需要了解Hive内部是如何工作的,不过,当用户对于Hive具有越来越多的经验后,尤其是需要在做性能优化的场景下,就要学习下Hive背后的理论知识以及底层的一些实现细节,会让用户更加高效地使用Hive。explain命令就可以帮助用户了解一条HQL语句在底层的实现过程,explain会解析HQL语句,将整个HQL语句的实现步骤、依赖关系、实现过程都会进行解析返回,可以帮助更好的了解一条HQL语句在底层是如何实现数据的查询及处理的过程,这样可以辅助用户对Hive进行优化。
官网:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Explain
1.2.语法
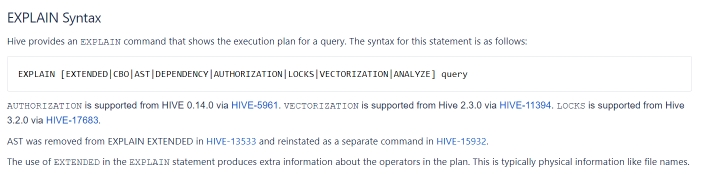
常用语法命令如下:
EXPLAIN [FORMATTED|EXTENDED|DEPENDENCY|AUTHORIZATION|] query
说明:
- FORMATTED:对执行计划进行格式化,返回JSON格式的执行计划
- EXTENDED:提供一些额外的信息,比如文件的路径信息
- DEPENDENCY:以JSON格式返回查询所依赖的表和分区的列表
- AUTHORIZATION:列出需要被授权的条目,包括输入与输出
1.3 组成
解析后的执行计划一般由三个部分构成,分别是:
- The Abstract Syntax Tree for the query
- 抽象语法树:Hive使用Antlr解析生成器,可以自动地将HQL生成为抽象语法树
- The dependencies between the different stages of the plan
- Stage依赖关系:会列出运行查询所有的依赖以及stage的数量
- The description of each of the stages
- Stage内容:包含了非常重要的信息,比如运行时的operator和sort orders等具体的信息
1.4.示例1:过滤
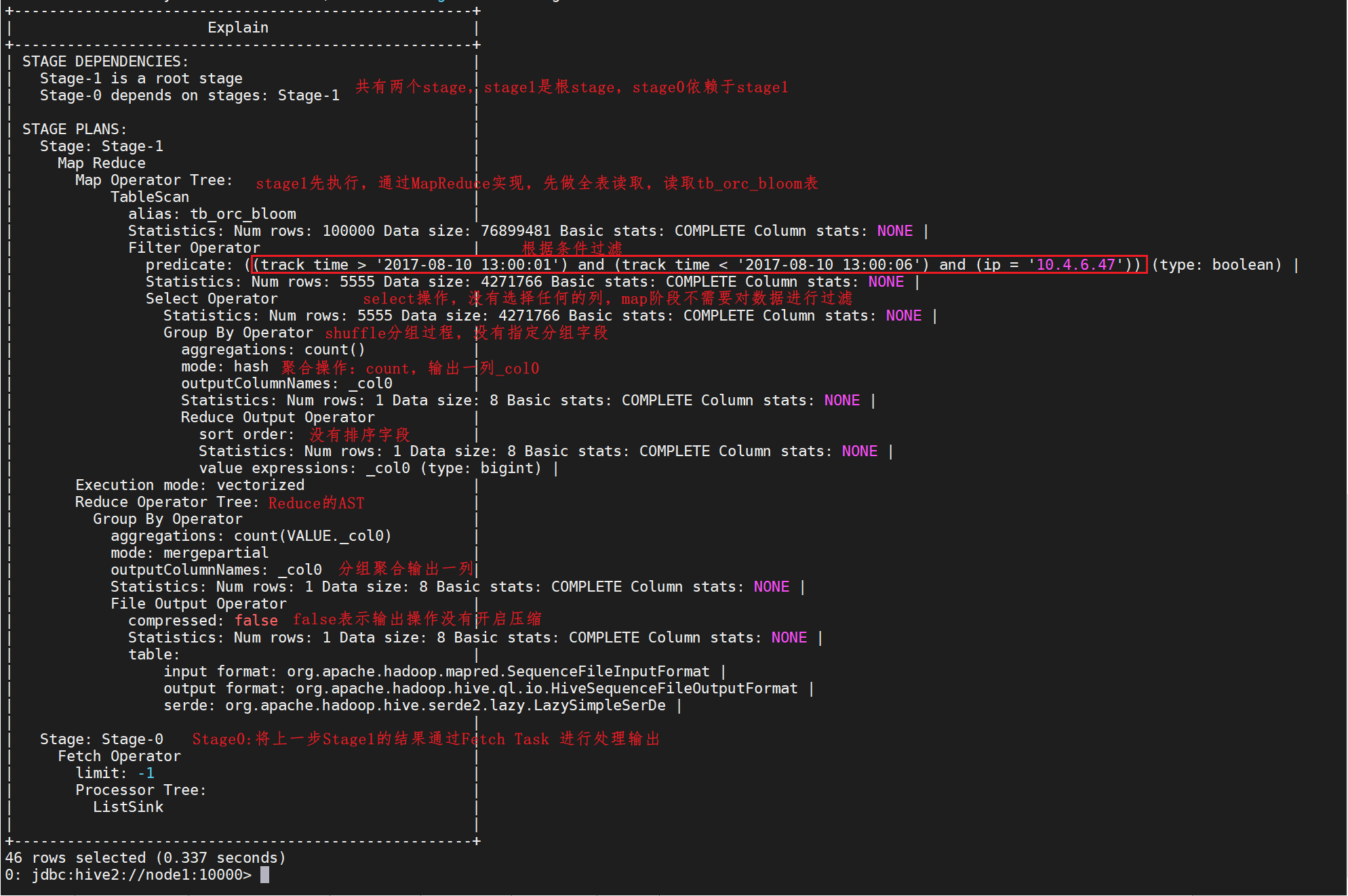
执行SQL:
explain select count(*) from tb_orc_bloom where track_time > '2017-08-10 13:00:01' and track_time < '2017-08-10 13:00:06' and ip = '10.4.6.47' ;
组成说明:
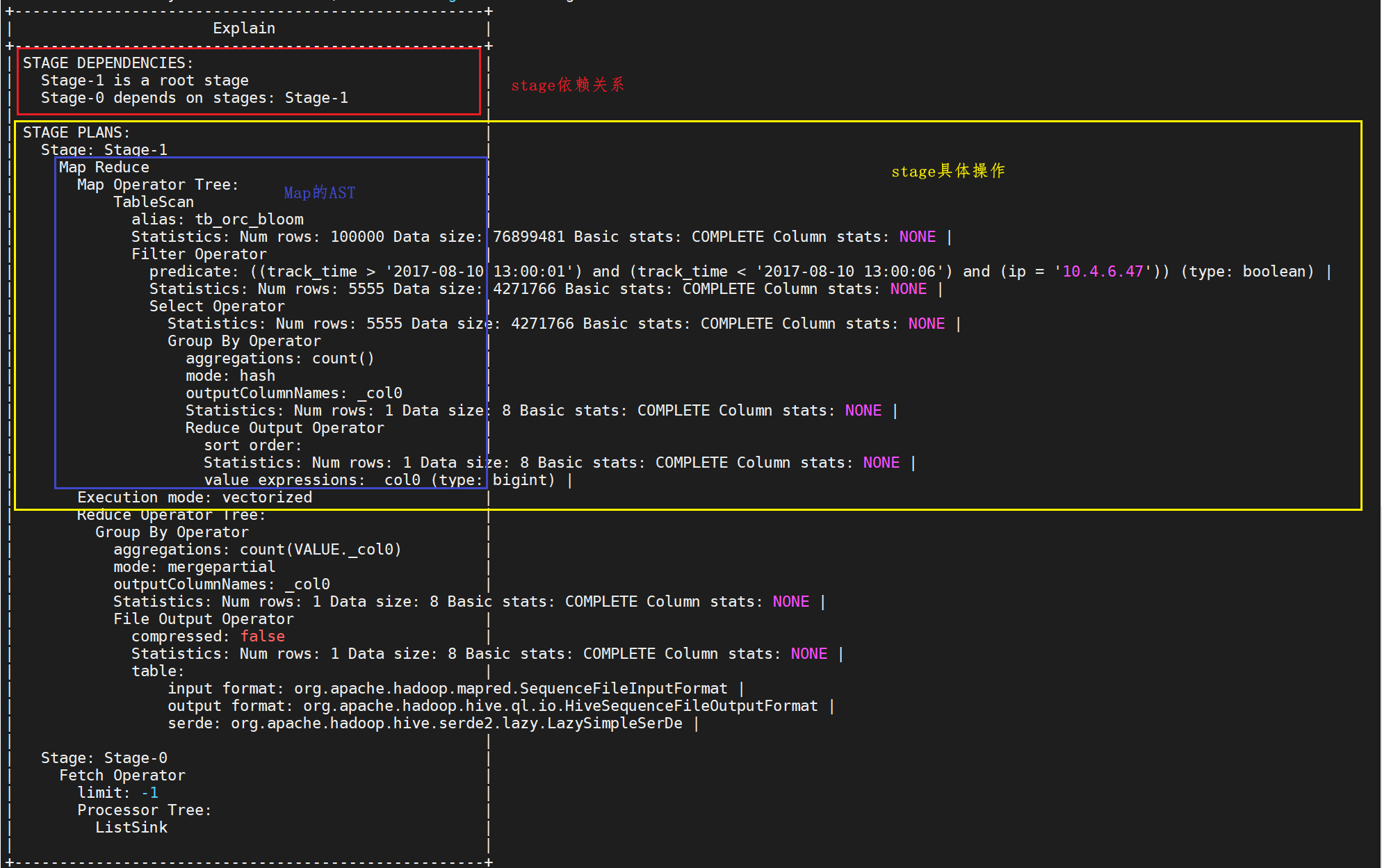
解释:
1.5.示例2:分组排序
准备表,然后加载数据:
-- 创建普通表,因为.txt文件格式保存的数据只能加载到普通表中 CREATE TABLE orders_text ( orderId bigint COMMENT ' 订单 id', orderNo string COMMENT ' 订单编号 ', shopId bigint COMMENT ' 门店 id', userId bigint COMMENT ' 用户 id', orderStatus tinyint COMMENT ' 订单状态 -3: 用户拒收 -2: 未付款的订单 -1 :用户取消 0: 待发货 1: 配送中 2: 用户确认收货 ', goodsMoney double COMMENT ' 商品金额 ', deliverMoney double COMMENT ' 运费 ', totalMoney double COMMENT ' 订单金额(包括运费) ', realTotalMoney double COMMENT ' 实际订单金额(折扣后金额) ', payType tinyint COMMENT ' 支付方式 ,0: 未知 ;1: 支付宝, 2 :微信 ;3 、现金; 4 、其他 ', isPay tinyint COMMENT ' 是否支付 0: 未支付 1: 已支付 ', userName string COMMENT ' 收件人姓名 ', userAddress string COMMENT ' 收件人地址 ', userPhone string COMMENT ' 收件人电话 ', createTime timestamp COMMENT ' 下单时间 ', payTime timestamp COMMENT ' 支付时间 ', totalPayFee int COMMENT ' 总支付金额 ' ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'; -- 导入数据 LOAD DATA LOCAL INPATH '/tmp/hivedata/hive_orders.txt' INTO TABLE orders_text; -- 创建订单表,采用orc存储格式,使用SNAPPY压缩方式 CREATE TABLE orders ( orderId bigint COMMENT ' 订单 id', orderNo string COMMENT ' 订单编号 ', shopId bigint COMMENT ' 门店 id', userId bigint COMMENT ' 用户 id', orderStatus tinyint COMMENT ' 订单状态 -3: 用户拒收 -2: 未付款的订单 -1 :用户取消 0: 待发货 1: 配送中 2: 用户确认收货 ', goodsMoney double COMMENT ' 商品金额 ', deliverMoney double COMMENT ' 运费 ', totalMoney double COMMENT ' 订单金额(包括运费) ', realTotalMoney double COMMENT ' 实际订单金额(折扣后金额) ', payType tinyint COMMENT ' 支付方式 ,0: 未知 ;1: 支付宝, 2 :微信 ;3 、现金; 4 、其他 ', isPay tinyint COMMENT ' 是否支付 0: 未支付 1: 已支付 ', userName string COMMENT ' 收件人姓名 ', userAddress string COMMENT ' 收件人地址 ', userPhone string COMMENT ' 收件人电话 ', createTime timestamp COMMENT ' 下单时间 ', payTime timestamp COMMENT ' 支付时间 ', totalPayFee int COMMENT ' 总支付金额 ' ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS orc tblproperties ("orc.compress"="SNAPPY"); -- 加载数据 INSERT INTO TABLE orders SELECT * FROM orders_text; -- 查看数据 SELECT * FROM orders;
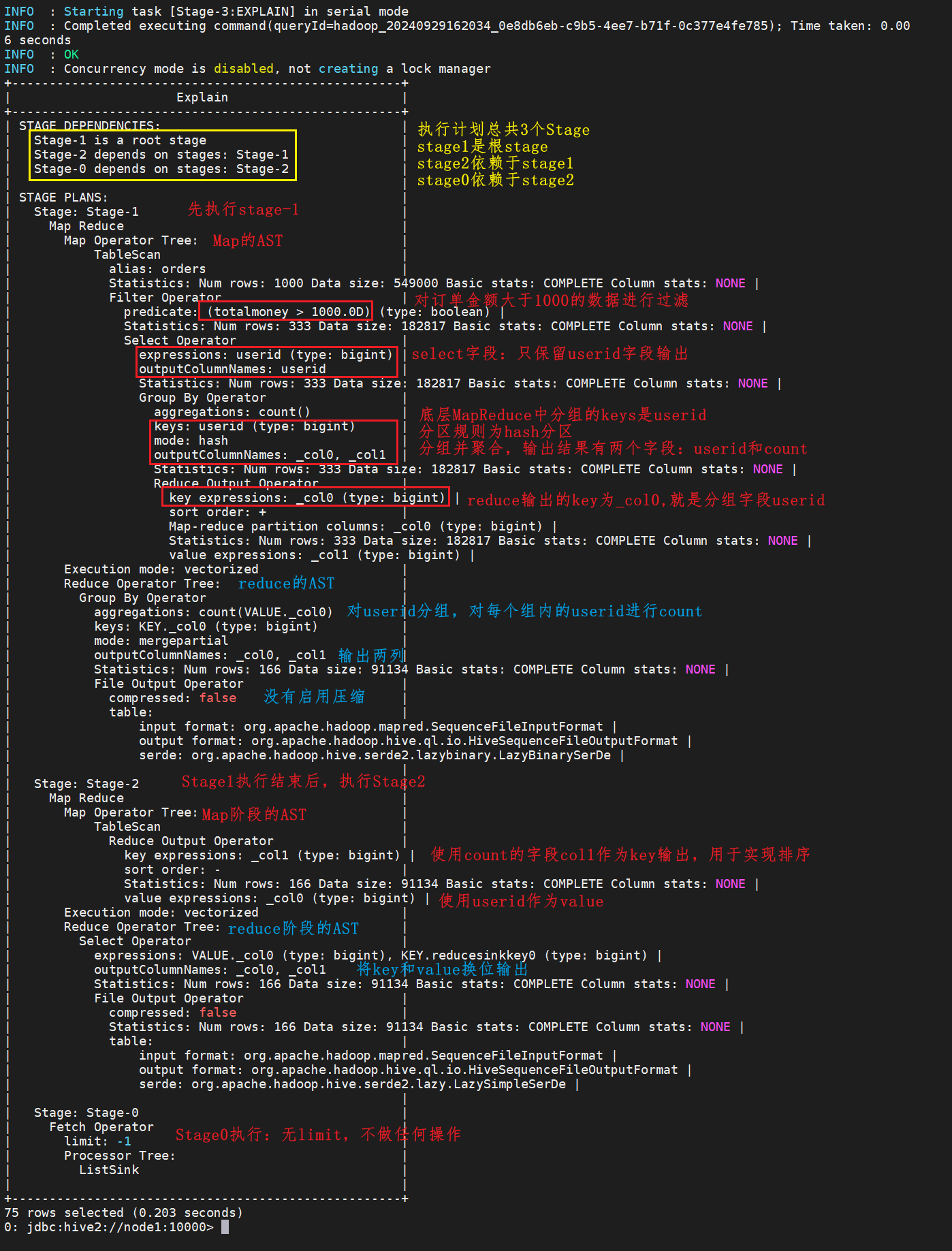
统计每个用户(userid)消费总金额超过 1000 的订单数量,并按订单数量降序排列。
explain SELECT userid,COUNT(*) num FROM orders WHERE totalMoney>1000 GROUP BY userid ORDER BY num DESC;
二、 MapReduce属性优化
2.1.本地模式
使用Hive的过程中,有一些数据量不大的表也会转换为MapReduce处理,提交到集群时,需要申请资源,等待资源分配,启动JVM进程,再运行Task,一系列的过程比较繁琐,本身数据量并不大,提交到YARN运行返回会导致性能较差的问题。
Hive为了解决这个问题,延用了MapReduce中的设计,提供本地计算模式,允许程序不提交给YARN,直接在本地运行,以便于提高小数据量程序的性能。
- 配置
-- 开启本地模式 set hive.exec.mode.local.auto = true;
限制条件
Hive为了避免大数据量的计算也使用本地模式导致性能差的问题,所以对本地模式做了以下限制,如果以下任意一个条件不满足,那么即使开启了本地模式,将依旧会提交给YARN集群运行。
- 处理的数据量不超过128M
- MapTask的个数不超过4个
- ReduceTask的个数不超过1个
2.2 JVM重用
JVM正常指代一个Java进程,Hadoop默认使用派生的JVM来执行map-reducer,如果一个MapReduce程序中有100个Map,10个Reduce,Hadoop默认会为每个Task启动一个JVM来运行,那么就会启动100个JVM来运行MapTask,在JVM启动时内存开销大,尤其是Job大数据量情况,如果单个Task数据量比较小,也会申请JVM资源,这就导致了资源紧张及浪费的情况。
为了解决上述问题,MapReduce中提供了JVM重用机制来解决,JVM重用可以使得JVM实例在同一个job中重新使用N次,当一个Task运行结束以后,JVM不会进行释放,而是继续供下一个Task运行,直到运行了N个Task以后,就会释放,N的值可以在Hadoop的mapred-site.xml文件中进行配置,通常在10-20之间。
配置
-- Hadoop3之前的配置,在mapred-site.xml中添加以下参数 -- Hadoop3中已不再支持该选项 mapreduce.job.jvm.numtasks=10
2.3.并行执行
Hive在实现HQL计算运行时,会解析为多个Stage,有时候Stage彼此之间有依赖关系,只能挨个执行,但是在一些别的场景下,很多的Stage之间是没有依赖关系的,例如Union语句,Join语句等等,这些Stage没有依赖关系,但是Hive依旧默认挨个执行每个Stage,这样会导致性能非常差,我们可以通过修改参数,开启并行执行,当多个Stage之间没有依赖关系时,允许多个Stage并行执行,提高性能。
配置:
-- 开启Stage并行化,默认为false SET hive.exec.parallel=true; -- 指定并行化线程数,默认为8 SET hive.exec.parallel.thread.number=16;
注意:线程数越多,程序运行速度越快,但同样更消耗CPU资源
三、Join优化
3.1.Hive中的Join方案
表的Join是数据分析处理过程中必不可少的操作,Hive同样支持Join的语法,Hive Join的底层还是通过MapReduce来实现的,Hive实现Join时,为了提高MapReduce的性能,提供了多种Join方案来实现,例如适合小表Join大表的Map Join,大表Join大表的Reduce Join,以及大表Join的优化方案Bucket Join等。
3.2 Map Join
⑴.应用场景:
- 适合于小表join大表或者小表Join小表
⑵.原理:
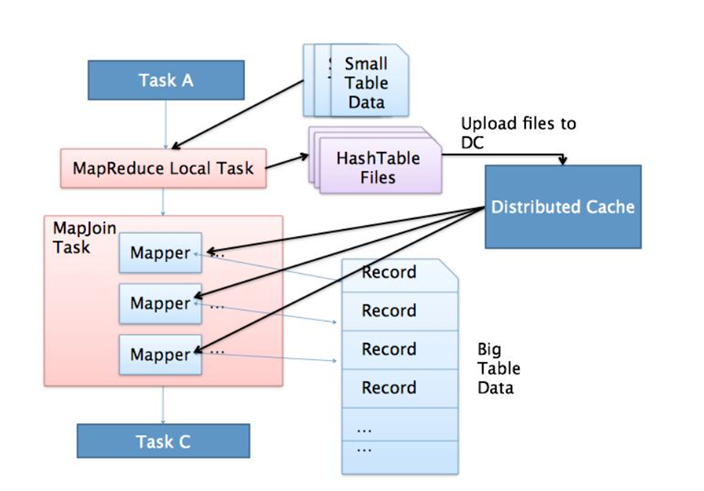
- 将小的那份数据给每个MapTask的内存都放一份完整的数据,大的数据每个部分都可以与小数据的完整数据进行join
- 底层不需要经过shuffle,需要占用内存空间存放小的数据文件
⑶.使用
- 尽量使用Map Join来实现Join过程
- Hive中默认自动开启了Map Join
-- 默认已经开启了Map Join hive.auto.convert.join=true
⑷.Hive中判断哪张表是小表及限制
- LEFT OUTER JOIN的左表必须是大表
- RIGHT OUTER JOIN的右表必须是大表
- INNER JOIN左表或右表均可以作为大表
- FULL OUTER JOIN不能使用MAPJOIN
- MAPJOIN支持小表为子查询
- 使用MAPJOIN时需要引用小表或是子查询时,需要引用别名
- 在MAPJOIN中,可以使用不等值连接或者使用OR连接多个条件
- 在MAPJOIN中最多支持指定6张小表,否则报语法错误
⑸.Hive中小表的大小限制
-- 2.0版本之前的控制属性 hive.mapjoin.smalltable.filesize=25M -- 2.0版本开始由以下参数控制 hive.auto.convert.join.noconditionaltask.size=512000000
3.3.Reduce Join
⑴.应用场景
- 适合于大表Join大表
⑵.原理
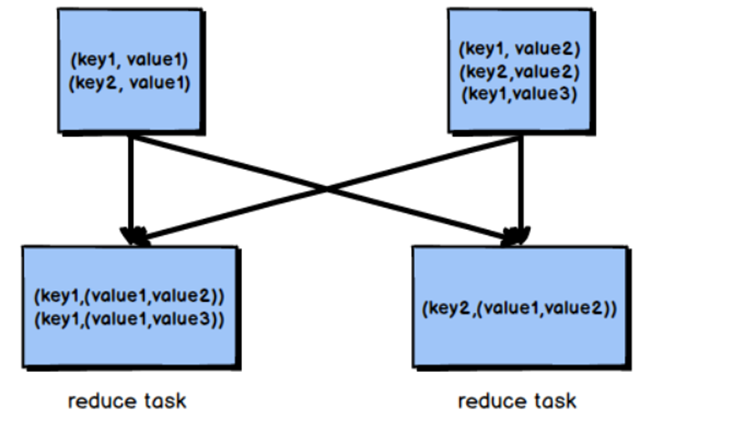
- 将两张表的数据在shuffle阶段利用shuffle的分组来将数据按照关联字段进行合并
- 必须经过shuffle,利用Shuffle过程中的分组来实现关联
⑶.使用
Hive会自动判断是否满足Map Join,如果不满足Map Join,则自动执行Reduce Join
3.4 Bucket Join
⑴.应用场景
适合于大表Join大表
⑵.原理
将两张表按照相同的规则将数据划分,根据对应的规则的数据进行join,减少了比较次数,提高了性能
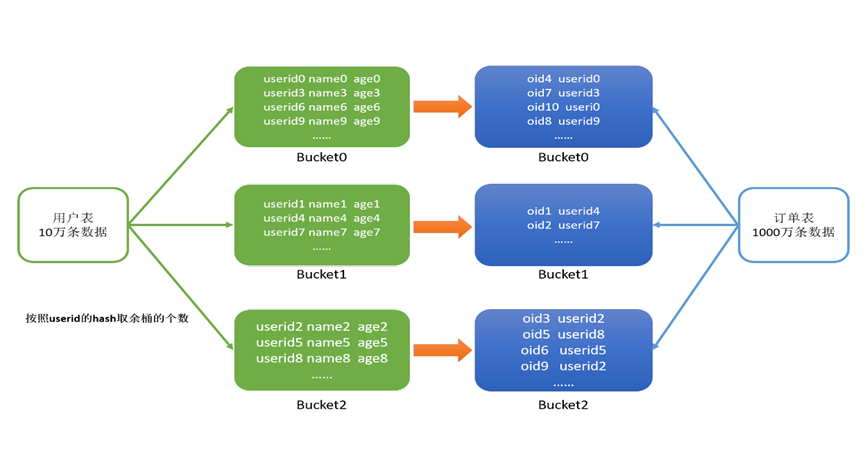
⑶.使用
Bucket Join
语法:clustered by colName
参数
-- 开启分桶join set hive.optimize.bucketmapjoin = true;
要求
- 分桶字段 = Join字段 ,桶的个数相等或者成倍数
Sort Merge Bucket Join(SMB):基于有序的数据Join
语法:clustered by colName sorted by (colName)
参数
-- 开启分桶SMB join set hive.optimize.bucketmapjoin = true; set hive.auto.convert.sortmerge.join=true; set hive.optimize.bucketmapjoin.sortedmerge = true; set hive.auto.convert.sortmerge.join.noconditionaltask=true;
要求
- 分桶字段 = Join字段 = 排序字段 ,桶的个数相等或者成倍数
四、优化器
4.1.关联优化
在使用Hive的过程中经常会遇到一些特殊的问题,例如当一个程序中如果有一些操作彼此之间有关联性,是可以放在一个MapReduce中实现的,但是Hive会不智能的选择,Hive会使用两个MapReduce来完成这两个操作。
例如:当我们执行以下SQL语句:
select …… from table group by id order by id desc;
该SQL语句转换为MapReduce时,我们可以有两种方案来实现:
方案一
- 第一个MapReduce做group by,经过shuffle阶段对id做分组
- 第二个MapReduce对第一个MapReduce的结果做order by,经过shuffle阶段对id进行排序
方案二
- 因为都是对id处理,可以使用一个MapReduce的shuffle既可以做分组也可以排序
在这种场景下,Hive会默认选择用第一种方案来实现,这样会导致性能相对较差,我们可以在Hive中开启关联优化,对有关联关系的操作进行解析时,可以尽量放在同一个MapReduce中实现。
配置
set hive.optimize.correlation=true;
4.2 CBO优化器引擎
在使用MySQL或者Hive等工具时,我们经常会遇到一个问题,默认的优化器在底层解析一些聚合统计类的处理的时候,底层解析的方案有时候不是最佳的方案。
例如:当前有一张表【共1000条数据】,id构建了索引,id =100值有900条,我们现在的需求是查询所有id = 100的数据,所以SQL语句为:select * from table where id = 100;
由于id这一列构建了索引,索引默认的优化器引擎RBO,会选择先从索引中查询id = 100的值所在的位置,再根据索引记录位置去读取对应的数据,但是这并不是最佳的执行方案。有id=100的值有900条,占了总数据的90%,这时候是没有必要检索索引以后再检索数据的,可以直接检索数据返回,这样的效率会更高,更节省资源,这种方式就是CBO优化器引擎会选择的方案。
使用Hive时,Hive中也支持RBO与CBO这两种引擎,默认使用的是RBO优化器引擎。
⑴.RBO
- rule basic optimise:基于规则的优化器
- 根据设定好的规则来对程序进行优化
⑵.CBO
- cost basic optimise:基于代价的优化器
- 根据不同场景所需要付出的代价来合适选择优化的方案
- 对数据的分布的信息【数值出现的次数,条数,分布】来综合判断用哪种处理的方案是最佳方案
很明显CBO引擎更加智能,所以在使用Hive时,我们可以配置底层的优化器引擎为CBO引擎。
配置
set hive.cbo.enable=true; set hive.compute.query.using.stats=true; set hive.stats.fetch.column.stats=true; set hive.stats.fetch.partition.stats=true;
要求
- 要想使用CBO引擎,必须构建数据的元数据【表行数、列的信息、分区的信息……】
- 提前获取这些信息,CBO才能基于代价选择合适的处理计划
- 所以CBO引擎一般搭配analyze分析优化器一起使用
五、谓词下推(PPD)
5.1.基本思想
谓词下推 Predicate Pushdown(PPD)的思想简单点说就是在不影响最终结果的情况下,尽量将过滤条件提前执行。谓词下推后,过滤条件在map端执行,减少了map端的输出,降低了数据在集群上传输的量,降低了Reduce端的数据负载,节约了集群的资源,
也提升了任务的性能。
5.2.基本规则
开启参数
-- 默认自动开启谓词下推 hive.optimize.ppd=true;
不同Join场景下的Where谓词下推测试
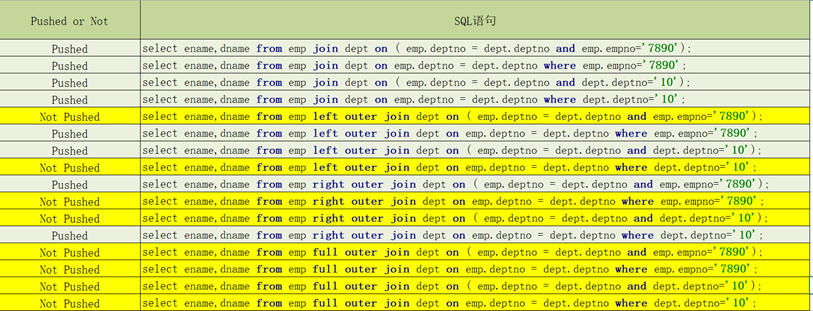
试验结论

说明
- Inner Join和Full outer Join,条件写在on后面,还是where后面,性能上面没有区别
- Left outer Join时 ,右侧的表写在on后面,左侧的表写在where后面,性能上有提高
- Right outer Join时,左侧的表写在on后面、右侧的表写在where后面,性能上有提高
- 如果SQL语句中出现不确定结果的函数,也无法实现下推
六、Hive其他优化
6.1.Fetch抓取机制
Hive中对某些情况的查询可以不必使用MapReduce计算。例如:SELECT * FROM employees; 在这种情况下,Hive可以简单地读取employee对应的存储目录下的文件,然后输出查询结果到控制台。
在hive-default.xml.template文件中 hive.fetch.task.conversion 默认是more,老版本hive默认是 minimal,该属性修改为more以后,在全局查找、字段查找、limit查找等都不走mapreduce。
- 把hive.fetch.task.conversion设置成none,然后执行查询语句,都会执行mapreduce程序。
set hive.fetch.task.conversion=none; select * from log_text; select ip from log_text; select ip from log_text limit 3;
- 把hive.fetch.task.conversion设置成more,然后执行查询语句,如下查询方式都不会执行mapreduce程序。
set hive.fetch.task.conversion=more; select * from log_text; select ip from log_text; select ip from log_text limit 3;
6.2.推测执行计划
在分布式集群环境下,因为程序Bug(包括Hadoop本身的bug),负载不均衡或者资源分布不均等原因,会造成同一个作业的多个任务之间运行速度不一致,有些任务的运行速度可能明显慢于其他任务(比如一个作业的某个任务进度只有50%,而其他所有任务已经运行完毕),则这些任务会拖慢作业的整体执行进度。为了避免这种情况发生,Hadoop采用了推测执行(Speculative Execution)机制,它根据一定的法则推测出“拖后腿”的任务,并为这样的任务启动一个备份任务,让该任务与原始任务同时处理同一份数据,并最终选用最先成功运行完成任务的计算结果作为最终结果。
执行一个MR任务的同时,又开启了一个相同的MR任务共同执行(底层),其会根据Map阶段的执行结果选择一个最优的,然后再根据Reduce阶段执行结果选择一个最优的。
- Reduce 3s
- Reduce 7s
hadoop中默认两个阶段都开启了推测执行机制。
hive本身也提供了配置项来控制reduce-side的推测执行:
<property> <name>hive.mapred.reduce.tasks.speculative.execution</name> <value>true</value> </property>
关于调优推测执行机制,还很难给一个具体的建议。如果用户对于运行时的偏差非常敏感的话,那么可以将这些功能关闭掉。如果用户因为输入数据量很大而需要执行长时间的map或者Reduce task的话,那么启动推测执行造成的浪费是非常巨大。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号