Hive表数据优化
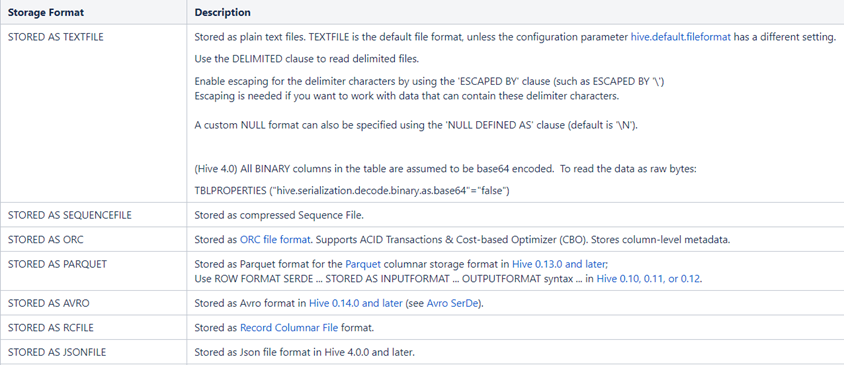
一、Hive文件格式
Hive数据存储的本质还是HDFS,所有的数据读写都基于HDFS的文件来实现,为了提高对HDFS文件读写的性能,Hive中提供了多种文件存储格式:TextFile、SequenceFile、RCFile、ORC、Parquet等。不同的文件存储格式具有不同的存储特点,有的可以降低存储空间,有的可以提高查询性能等,可以用来实现不同场景下的数据存储,以提高对于数据文件的读写效率。
1.1.行存储和列存储
下面为大家介绍常用的几种文件格式以及各自使用的场景。
行式存储:TextFile、SequenceFile(小数据)
列式存储:RCFile、ORC、Parquet(中大型数据)

行存储和列存储是两种不同的数据存储方式,它们在数据排列和访问方式上存在显著差异。
⑴.行存储
行存储(Row-Based Storage)是一种按行组织数据的存储方式。在行存储中,整行数据被作为基本单元存储在磁盘或内存中。这种方式类似于传统的关系数据库中的存储方式,每一行表示一条记录,包含了该记录的所有字段或属性。
优点:
- 写入效率高:行存储的写入是一次性完成的,相对于列存储在写入过程中需要多次写入,行存储占有较大的优势。
- 数据完整性:行存储能够保证写入过程的成功或失败,因为写入是一次性完成的。这确保了数据的完整性。
缺点:
- 读取冗余数据:在读取过程中,通常将整行数据完全读出,可能会产生冗余数据,特别是在只需要部分数据的情况下。
- 解析复杂:行存储中包含多种类型的数据,数据解析需要在不同数据类型之间频繁转换,消耗CPU,增加解析时间。
⑵.列存储
列存储(Column-Based Storage)是一种按列组织数据的存储方式。数据以列为单位存储在磁盘上,每一列包含相同类型的数据。相比于行存储,列存储更注重将同一属性的数据集中在一起,以提高读取效率和压缩比。
优点:
- 读取效率高:列存储在大数据应用中批量访问列数据时表现出色,读取速度比行存储方式要快50到100倍。
- 高压缩比:列存储有利于提高数据的压缩比,因为同类数据存储在一起有助于提高数据之间的相关性。
缺点:
- 写入效率低:列存储在写入过程中需要将一行记录拆分成多列保存,写入次数明显比行存储多,导致写入效率较低。
- 数据修改复杂:数据修改涉及到删除标记和多次写入,相较于行存储,列存储在这方面较为繁琐。
⑶.选择存储方案
在选择大数据存储方案时,需要根据实际业务需求和数据特点进行综合考虑。例如,如果大数据应用中主要涉及批量访问列数据,列存储可能更为适合;而对于频繁的写入操作,行存储可能更具优势。
1.2.TextFile格式
TextFile是Hive中默认的文件格式,存储形式为按行存储。工作中最常见的数据文件格式就是TextFile文件,几乎所有的原始数据生成都是TextFile格式,所以Hive设计时考虑到为了避免各种编码及数据错乱的问题,选用了TextFile作为默认的格式。建表时不指定存储格式即为textfile,导入数据时把数据文件拷贝至HDFS不进行处理。
⑴.TextFile的优点:
- 最简单的数据格式,不需要经过处理,可以直接cat查看
- 可以使用任意的分隔符进行分割
- 便于和其他工具(Pig, grep, sed, awk)共享数据
- 可以搭配Gzip、Bzip2、Snappy等压缩一起使用
⑵.TextFile的缺点:
- 耗费存储空间,I/O性能较低
- 结合压缩时Hive不进行数据切分合并,不能进行并行操作,查询效率低
- 按行存储,读取列的性能差
⑶.TextFile的应用场景:
- 适合于小量数据的存储查询
- 一般用于做第一层数据加载和测试使用
⑷.创建TextFile数据表
SQL如下:
-- 创建数据库 create database if not exists db_datatype; -- 指定数据库 use db_datatype; -- 创建表类型:textfile create table log_text ( track_time string, url string, session_id string, referer string, ip string, end_user_id string, city_id string ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE ; -- 加载数据 load data local inpath '/tmp/hivedata/log.data' into table log_text;
上传的数据log.data是18.1MB

上传后发现文件大小并没有变化

1.3.SequenceFile格式
SequenceFile是Hadoop里用来存储序列化的键值对即二进制的一种文件格式。SequenceFile文件也可以作为MapReduce作业的输入和输出,hive也支持这种格式。
⑴.SequenceFile存储原理
SequenceFile 是 Hadoop 生态系统中的一种基于行存储的文件格式,专门用于存储键值对。SequenceFile 的存储结构包括以下部分:
文件头(File Header):
- 包含文件的元数据,包括版本号、键/值的类名、压缩类型等信息。
- 目的是确保 SequenceFile 文件在读取时能够正确解析,并定位到相应的键/值。
记录(Records):
- 每条记录由键和值组成,并存储在文件中。根据具体配置,数据可以不压缩或压缩存储。
- SequenceFile 的记录是按行存储的,即每条记录按顺序写入文件,因此读取时也可以顺序读取。
同步标记(Sync Marker):
- 为了增加容错能力,文件中插入了同步标记,类似于检查点。如果文件中有部分数据损坏,SequenceFile 读取器能够跳过这些损坏部分,继续读取。
详细说明:
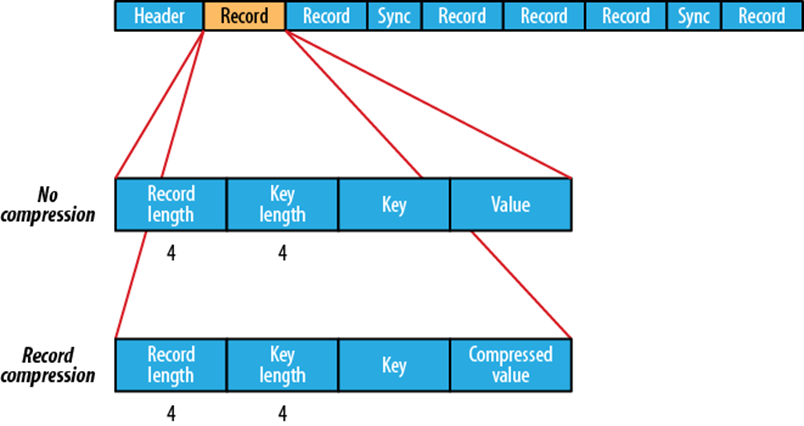
- Sequence FIle,每条数据记录都是以
Key、Value键值对进行序列化存储(二进制格式) 序列化文件与文本文件相比更加紧凑,且支持record、block块级压缩。压缩的同时支持文件切分- 通常把Sequence File
作为中间数据存储格式,例如:将大量小文件合并放入到Sequence File文件中。
record
- record 就是一个kv键值对,其中数据保存在value中,可以选择是否针对value进行压缩
- Value部分不压缩key;
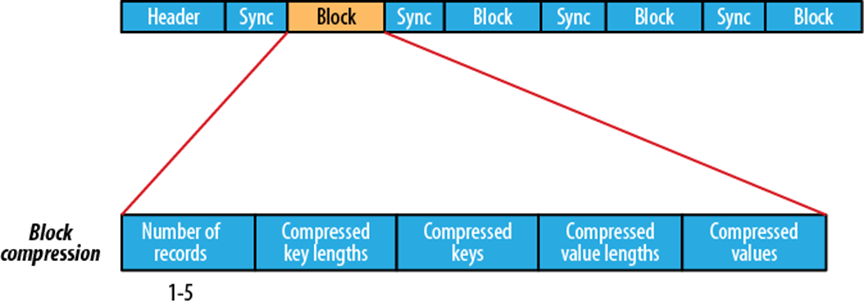
block
- block就是多个record的集合,block级别的压缩性能更好
- Block对Key和Value都压缩。
⑵.SequenceFile的优点:
- 以二进制的KV形式存储数据,与底层交互更加友好,性能更快
- 可压缩、可分割,优化磁盘利用率和I/O
- 可并行操作数据,查询效率高
- SequenceFile也可以用于存储多个小文件
⑶.SequenceFile的缺点:
- 存储空间消耗最大
- 与非Hadoop生态系统之外的工具不兼容
- 构建SequenceFile需要通过TextFile文件转化加载。
⑷.SequenceFile的应用:
- 适合于小量数据,但是查询列比较多的场景
⑸.SequenceFile的使用
创建表,导入数据
-- 创建表类型:sequencefile create table log_sequencefile ( track_time string, url string, session_id string, referer string, ip string, end_user_id string, city_id string ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS sequencefile ; -- 导入数据 insert into table log_sequencefile select * from log_text; -- 查询数据 SELECT * from log_sequencefile;
SequenceFile 默认不会进行压缩。它支持三种压缩方式,但默认情况下是不压缩(NONE)。如果你需要压缩数据,需要显式指定压缩模式。以下是三种压缩模式:
- 不压缩(NONE):这是默认模式,数据不会被压缩,键值对原样存储。
- 记录压缩(RECORD):每条记录单独压缩。
- 块压缩(BLOCK):将多个记录聚集成一个块进行压缩,通常效率较高,适合处理大量小记录。
你可以在代码中通过配置来选择压缩方式。
查看数据大小如下,发现并没有压缩

1.4.Parquet
Parquet是一种支持嵌套结构的列式存储文件格式,最早是由Twitter和Cloudera合作开发,2015年5月从Apache孵化器里毕业成为Apache顶级项目。是一种支持嵌套数据模型对的列式存储系统,作为大数据系统中OLAP查询的优化方案,它已经被多种查询引擎原生支持,并且部分高性能引擎将其作为默认的文件存储格式。通过数据编码和压缩,以及映射下推和谓词下推功能,Parquet的性能也较之其它文件格式有所提升。
Parquet 是与语言无关的,而且不与任何一种数据处理框架绑定在一起,适配多种语言和组件,能够与 Parquet 适配的查询引擎包括 Hive, Impala, Pig, Presto, Drill, Tajo, HAWQ, IBM Big SQL等,计算框架包括 MapReduce, Spark, Cascading, Crunch, Scalding, Kite 等
Parquet是Hadoop生态圈中主流的列式存储格式,并且行业内流行这样一句话流传:如果说HDFS是大数据时代文件系统的事实标准,Parquet 就是大数据时代存储格式的事实标准。Hive中也同样支持使用Parquet格式来实现数据的存储,并且是工作中主要使用的存储格式之一。
⑴.存储原理
Parquet文件是以二进制方式存储的,所以是不可以直接读取的,文件中包括该文件的数据和元数据,因此Parquet格式文件是自解析的。通常情况下,在存储Parquet数据的时候会按照Block大小设置行组的大小,由于一般情况下每一个Mapper任务处理数据的最小单位是一个Block,这样可以把每一个行组由一个Mapper任务处理,增大任务执行并行度。
通常情况下,在存储Parquet数据的时候会按照Block大小设置行组的大小,由于一般情况下每一个Mapper任务处理数据的最小单位是一个Block,这样可以把每一个行组由一个Mapper任务处理,增大任务执行并行度。
- 行组(Row Group):每一个行组包含一定的行数,在一个HDFS文件中至少存储一个行组,类似于orc的stripe的概念。
- 列块(Column Chunk):在一个行组中每一列保存在一个列块中,行组中的所有列连续的存储在这个行组文件中。一个列块中的值都是相同类型的,不同的列块可能使用不同的算法进行压缩。
⑵.Parquet的优点
- 更高效的压缩和编码
- 可用于多种数据处理框架
⑶.Parquet的缺点:
- 不支持update, insert, delete, ACID
⑷.Parquet的应用:
- 适用于字段数非常多,无更新,只取部分列的查询。
⑸.Parquet的使用
创建表,导入数据
-- 创建表,存储数据格式为parquet create table log_parquet( track_time string, url string, session_id string, referer string, ip string, end_user_id string, city_id string ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS PARQUET; -- 导入数据 insert into table log_parquet select * from log_text ;
查看发现数据从18.1MB压缩到了13.09 MB

1.6.ORC
ORC(OptimizedRC File)文件格式也是一种Hadoop生态圈中的列式存储格式,源自于RC(RecordColumnar File),它的产生早在2013年初,最初产生自Apache Hive,用于降低Hadoop数据存储空间和加速Hive查询速度。它并不是一个单纯的列式存储格式,仍然是首先根据行组分割整个表,在每一个行组内进行按列存储。ORC文件是自描述的,它的元数据使用Protocol Buffers序列化,并且文件中的数据尽可能的压缩以降低存储空间的消耗,目前也被Hive、Spark SQL、Presto等查询引擎支持。2015年ORC项目被Apache项目基金会提升为Apache顶级项目。
ORC文件也是以二进制方式存储的,所以是不可以直接读取,ORC文件也是自解析的,它包含许多的元数据,这些元数据都是同构ProtoBuffer进行序列化的。其中涉及到如下的概念:
- ORC文件:保存在文件系统上的普通二进制文件,一个ORC文件中可以包含多个stripe,每一个stripe包含多条记录,这些记录按照列进行独立存储,对应到Parquet中的row group的概念。
- 文件级元数据:包括文件的描述信息PostScript、文件meta信息(包括整个文件的统计信息)、所有stripe的信息和文件schema信息。
- stripe:一组行形成一个stripe,每次读取文件是以行组为单位的,一般为HDFS的块大小,保存了每一列的索引和数据。
- stripe元数据:保存stripe的位置、每一个列的在该stripe的统计信息以及所有的stream类型和位置。
- row group:索引的最小单位,一个stripe中包含多个row group,默认为10000个值组成。
- stream:一个stream表示文件中一段有效的数据,包括索引和数据两类。索引stream保存每一个
- row group的位置和统计信息,数据stream包括多种类型的数据,具体需要哪几种是由该列类型和编码方式决定。
ORC文件中保存了三个层级的统计信息,分别为文件级别、stripe级别和row group级别的,他们都可以用来根据Search ARGuments(谓词下推条件)判断是否可以跳过某些数据,在统计信息中都包含成员数和是否有null值,并且对于不同类型的数据设置一些特定的统计信息。
⑴.ORC文件存储原理
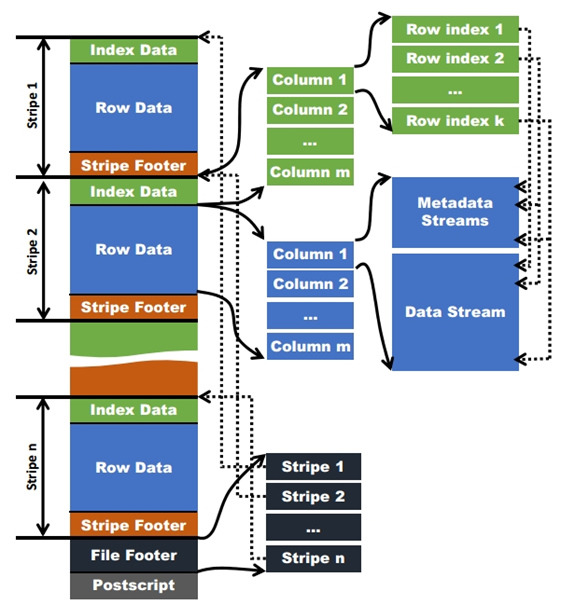
Orc的存储文件方式如上图所示,存储文件最初默认大小是256M,一个文件在逻辑结果上被分为多个Stripe,新版本的Orc写入数据时,默认每个Stripe数据大小为64M(Hive0.1版本默认值是256M),每一个stripe包含多条记录,这些记录按照列进行独立存储。每个Stripe又分为Index Data(索引数据)、Row Data(行数据)和Stripe Footer(尾数据)三部分。
- 索引数据(Index Data):为每个数据块创建索引,用于快速定位数据,提高查询速度。
- 行数据(Row Data):里面存储的是具体的数据,包括metadata stream和data stream;metadata stream用于描述每个行组的元数据信息,为了进一步的避免读入不必要的数据,在逻辑上将一个column的index以一个给定的值(默认为10000,可由参数配置)分割为多个index组。以10000条记录为一个group,对数据进行统计。Hive查询引擎会将where条件中的约束传递给ORC reader,这些reader根据组级别的统计信息,过滤掉不必要的数据。如果该值设置的太小,就会保存更多的统计信息,用户需要根据自己数据的特点权衡一个合理的值。数据是以Stream的形式保存了数据的具体信息。
- 尾数据(Stripe Footer):里面存储的是数据所在的文件目录,包含了该Stripe的统计结果,包括Max、Min以及Count等信息。
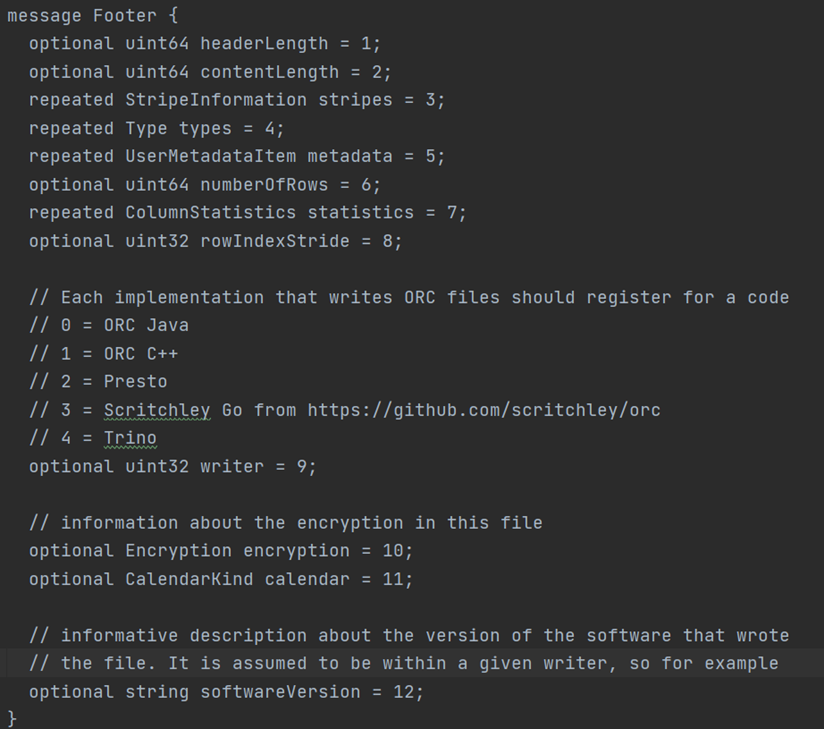
- 文件的末尾File Footer里面包含了ORC文件中Stripe的列表、每个Stripe的行数,以及每个列的数据类型。它还包含了该表每个列的最小值、最大值等信息。因此,如果查询一个列的最大、最小值,可以从这里直接读取。FileFooter记录信息截图如下:
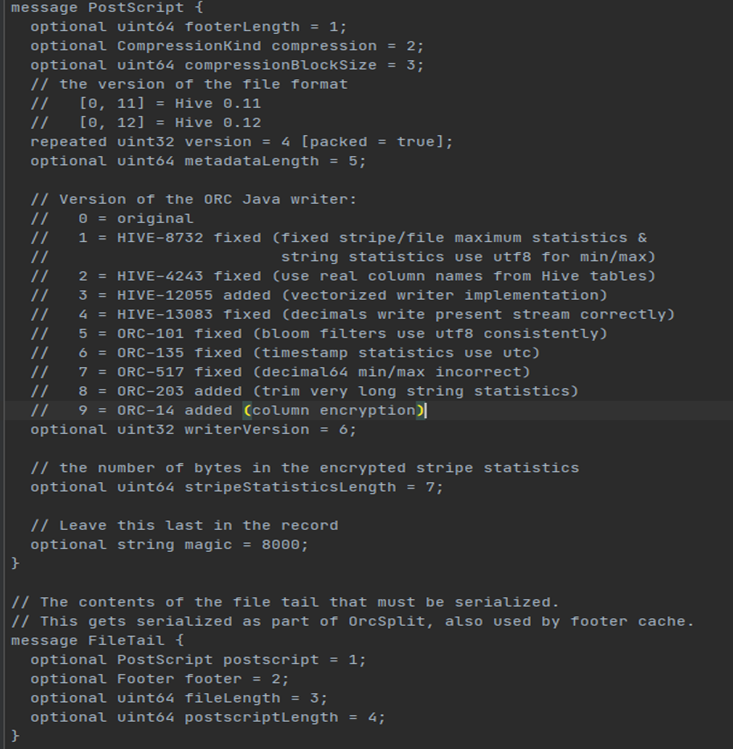
- PostScript中保存着整个文件的元数据信息,它包括文件的压缩格式、文件内部每一个压缩块的最大长度(每次分配内存的大小)、Footer长度,以及一些版本信息。Postscript记录信息截图如下:
⑵.ORC的优点
- 列式存储,存储效率非常高
- 可压缩,高效的列存取
- 查询效率较高,支持索引
- 支持矢量化查询
⑶.ORC的缺点
- 加载时性能消耗较大
- 需要通过text文件转化生成
- 读取全量数据时性能较差
⑷.ORC的应用
- 适用于Hive中大型的存储、查询
⑸.ORC的使用
创建数据表,执行存储数据格式为loc,SQL如下:
-- 创建表,存储数据格式为loc。 create table log_orc( track_time string, url string, session_id string, referer string, ip string, end_user_id string, city_id string ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS orc; -- 导入数据 insert into table log_orc select * from log_text ;
发现数据从18.1MB压缩到了2.78 MB

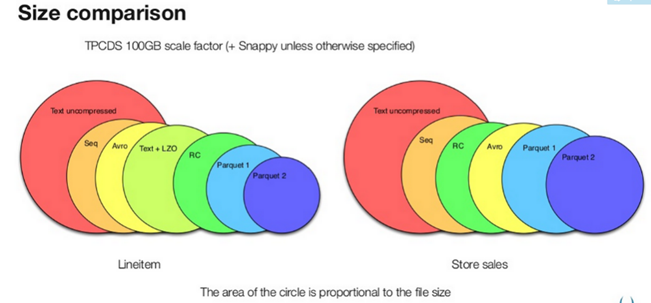
1.7.小结
存储文件的压缩比总结:ORC > Parquet > TextFile
SequenceFile不压缩,所以就没有比较
1.8.存储文件查询速度对比
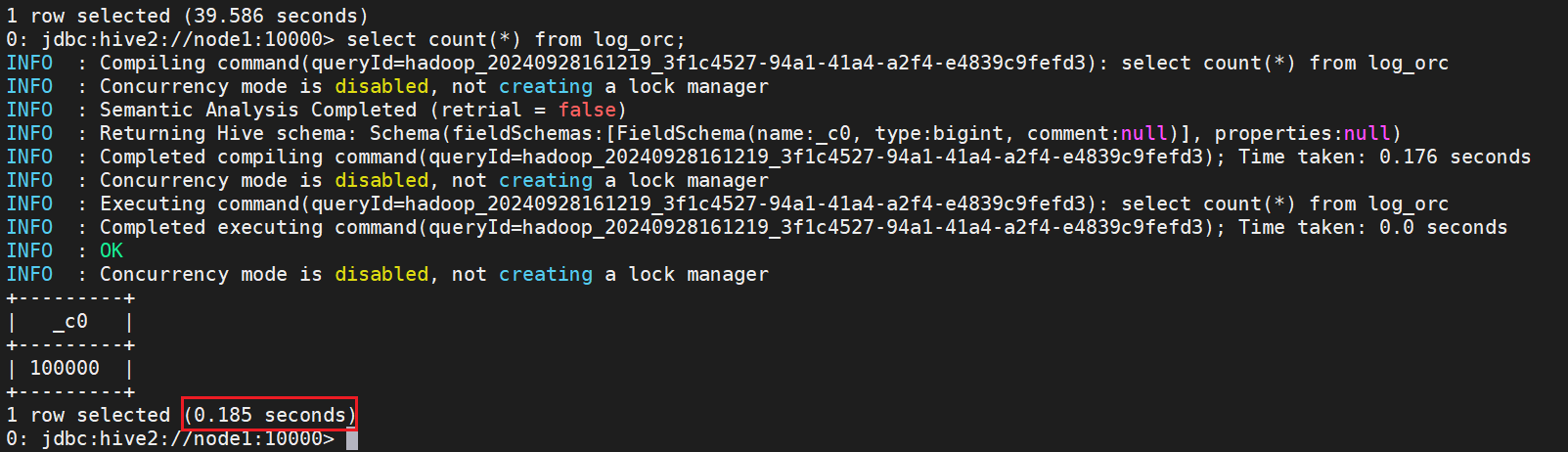
⑴.ORC存储格式
select count(*) from log_orc;
ORC存储格式,相同的表结构和数据,只需要0.185s
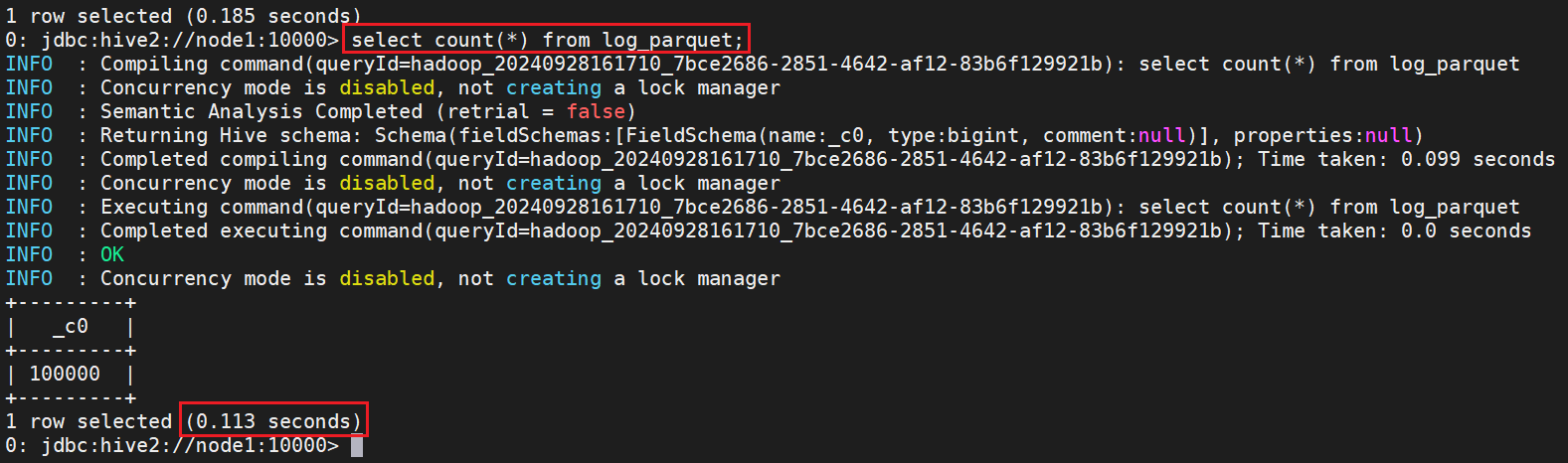
⑵.Parquet存储格式
select count(*) from log_parquet;
Parquet存储格式,相同的表结构和数据,只需要0.113s
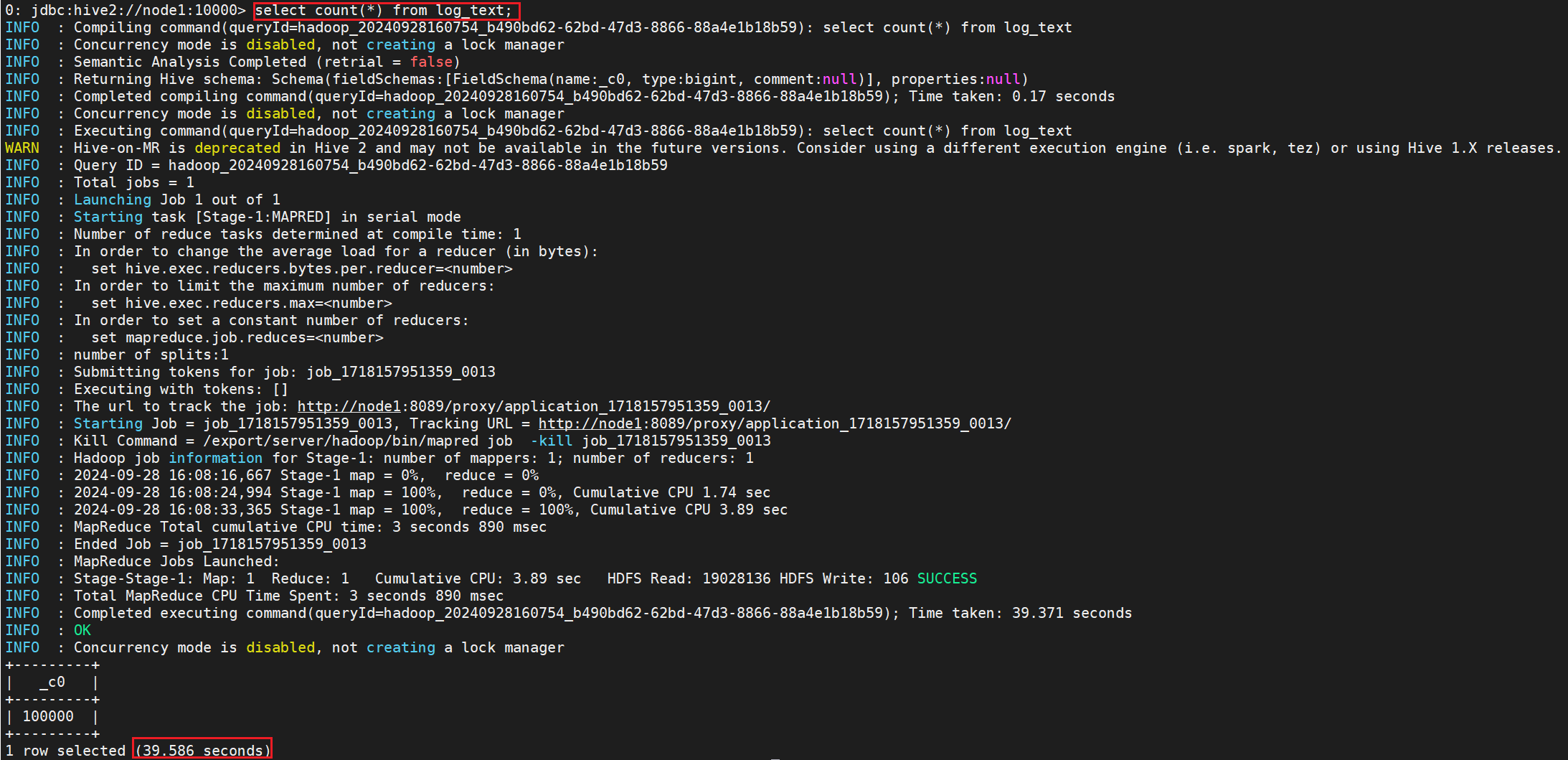
⑶.TextFile存储格式
执行SQL
select count(*) from log_text;
查看需要发现需要39.586s
二、Hive数据压缩
2.1.数据压缩概述
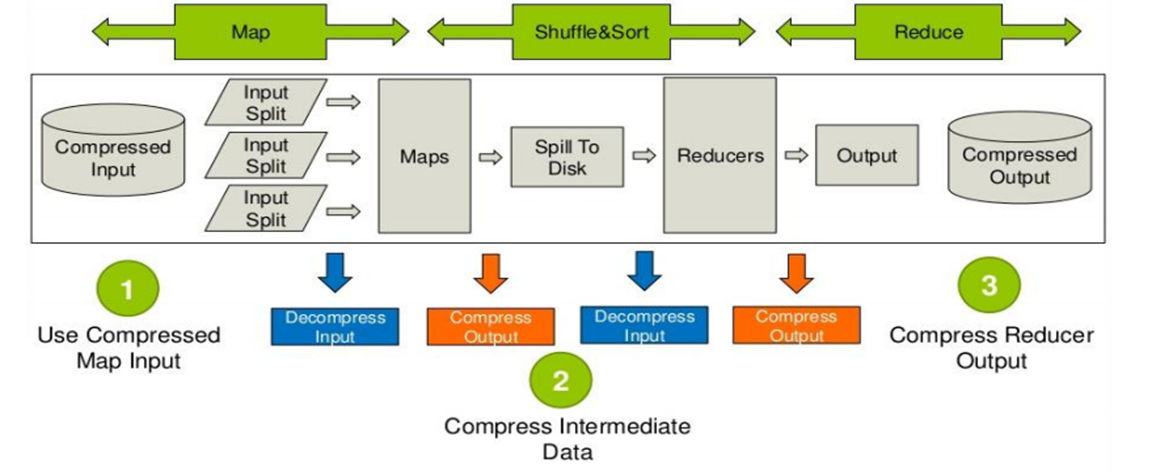
Hive底层运行MapReduce程序时,磁盘I/O操作、网络数据传输、shuffle和merge要花大量的时间,尤其是数据规模很大和工作负载密集的情况下。
鉴于磁盘I/O和网络带宽是Hadoop的宝贵资源,数据压缩对于节省资源、最小化磁盘I/O和网络传输非常有帮助。
Hive压缩实际上说的就是MapReduce的压缩。
2.2.数据压缩优缺点
优点:
- 减少存储磁盘空间,降低单节点的磁盘IO。
- 由于压缩后的数据占用的带宽更少,因此可以加快数据在Hadoop集群流动的速度,减少网络传输带宽。
缺点:
- 需要花费额外的时间/CPU做压缩和解压缩计算。
2.3.压缩分析
问题:Hive底层是MapReduce,MapReduce到底哪些阶段可以进行压缩操作呢?
首先说明mapreduce哪些过程可以设置压缩:需要分析处理的数据在进入map前可以压缩,然后解压处理,map处理完成后的输出可以压缩,这样可以减少网络I/O(reduce通常和map不在同一节点上),reduce拷贝压缩的数据后进行解压,处理完成后可以压缩存储
在hdfs上,以减少磁盘占用量。
2.4.Hive压缩算法
Hive中的压缩就是使用了Hadoop中的压缩实现的,所以Hadoop中支持的压缩在Hive中都可以直接使用。
Hadoop中支持的压缩算法:
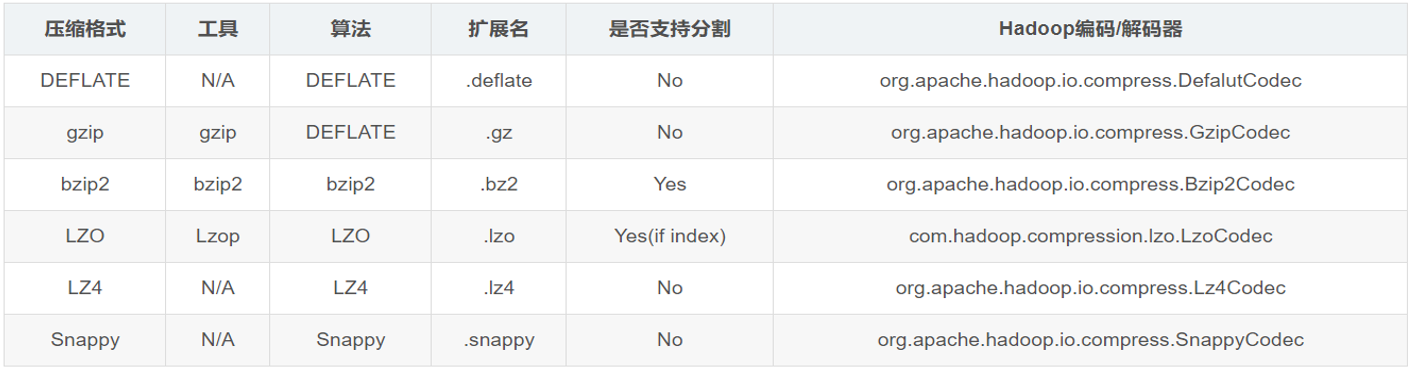
要想在Hive中使用压缩,需要对MapReduce和Hive进行相应的配置
性能对比表
| 算法 | 压缩率 | 压缩速度 | 解压速度 | 优势 | 适用场景 |
|---|---|---|---|---|---|
| Snappy | 低 | 非常快 | 非常快 | 速度快,适合实时计算 | 实时数据处理、HBase、Kafka |
| LZ4 | 低 | 非常快 | 非常快 | 超快的解压速度 | 实时计算、需要快速随机读取的场景 |
| LZO | 中等 | 快 | 非常快 | 平衡压缩率与速度,支持分片压缩 | Hadoop HDFS、分布式数据处理 |
| Bzip2 | 非常高 | 非常慢 | 慢 | 最大压缩率,用于存储优化 | 数据归档、长期存储 |
| Deflate | 中高 | 中等 | 中等 | 适度的压缩率与速度平衡 | 存储优化、gzip 文件、日志压缩 |
总结与建议
- 实时数据处理:Snappy 和 LZ4 是最好的选择,具有极快的压缩和解压速度,适用于高频数据处理和实时应用。
- 分布式大数据处理:LZO 在压缩率和速度之间取得了良好平衡,特别是其分片压缩功能使其在分布式系统(如 HDFS)中非常适用。
- 高压缩率需求:Bzip2 压缩率最高,适合归档或不频繁访问的数据存储,但由于压缩和解压速度较慢,不适合实时应用。
- 常规压缩:Deflate(如 gzip)在压缩率和解压速度上较为均衡,适合需要一定压缩率但不追求极致性能的场景。
2.5.Hive中压缩配置
开启hive中间传输数据压缩功能
--1)开启hive中间传输数据压缩功能 set hive.exec.compress.intermediate=true; --2)开启mapreduce中map输出压缩功能 set mapreduce.map.output.compress=true; --3)设置mapreduce中map输出数据的压缩方式 set mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
开启Reduce输出阶段压缩
--1)开启hive最终输出数据压缩功能 set hive.exec.compress.output=true; --2)开启mapreduce最终输出数据压缩 set mapreduce.output.fileoutputformat.compress=true; --3)设置mapreduce最终数据输出压缩方式 set mapreduce.output.fileoutputformat.compress.codec = org.apache.hadoop.io.compress.SnappyCodec; --4)设置mapreduce最终数据输出压缩为块压缩 set mapreduce.output.fileoutputformat.compress.type=BLOCK;
2.6.数据压缩-Hive中压缩测试
开启开启hive中间传输数据压缩功能和Reduce输出阶段压缩,然后创建表,指定为textfile格式,并使用snappy压缩
create table tb_snappy stored as textfile as select * from log_text;
上面从log_text表中加载数据到新创建的表tb_snappy中,会发现log_text表中数据是18.13MB

数据加载完成后,查看新创建的tb_snappy表,由于采用了snappy压缩,所以文件压缩成了8.41 MB

⑴.非压缩ORC文件
之前创建过表log_orc,采用了ORC存储方式,orc存储文件默认采用ZLIB压缩。所以文件是2.78MB

还是创建相同结构的表,存储格式依然是ORC,但是不进行压缩
-- 创建表格式:ORC,不进行压缩 create table log_orc_none( track_time string, url string, session_id string, referer string, ip string, end_user_id string, city_id string ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS orc tblproperties ("orc.compress"="NONE"); -- 导入数据 insert into table log_orc_none select * from log_text ;
文件是7.69MB

⑵.Snappy压缩ORC文件
创建表log_orc_snappy,采用ORC格式存储,压缩方式设置为SNAPPY
create table log_orc_snappy( track_time string, url string, session_id string, referer string, ip string, end_user_id string, city_id string ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS orc tblproperties ("orc.compress"="SNAPPY"); -- 导入数据 insert into table log_orc_snappy select * from log_text ;
文件是3.75MB

⑶.小结说明
之前默认创建的ORC存储方式,导入数据后的大小为2.78 MB比Snappy压缩的3.75 MB还小。原因是orc存储文件默认采用ZLIB压缩。比snappy压缩的小。在实际的项目开发当中:
- hive表的数据存储格式一般选择:orc或parquet。
- 压缩方式一般选择snappy。
存在问题:有小伙伴可能会问,为什么ORC存储在刚才的实验中,只有2.78MB。但是ORC + Snappy经过实验竟然占用3.75MB空间大小,为什么压缩以后反而更大了?
答:因为底层压缩算法不同,如果直接以ORC方式存储,其底层采用Zlib压缩算法,其压缩率比Snappy更高,但是其压缩和解压缩速度相对于Snappy而言,要慢很多。
三、存储优化
3.1.存储优化-避免小文件生成
Hive的存储本质还是HDFS,HDFS是不利于小文件存储的,因为每个小文件会产生一条元数据信息,并且不利用MapReduce的处理,MapReduce中每个小文件会启动一个MapTask计算处理,导致资源的浪费,所以在使用Hive进行处理分析时,要尽量避免小文件的生成。
那么在使用Hive时,如何能避免小文件的生成呢?当我们使用多个Reduce进行聚合计算时,我们并不清楚每个Reduce最终会生成的结果的数据大小,无法控制用几个Reduce来处理。Hive中为我们提供了一个特殊的机制,可以自动的判断是否是小文件,如果是小文件可以自动将小文件进行合并。
配置:
-- 如果hive的程序,只有maptask,将MapTask产生的所有小文件进行合并 set hive.merge.mapfiles=true; -- 如果hive的程序,有Map和ReduceTask,将ReduceTask产生的所有小文件进行合并 set hive.merge.mapredfiles=true; -- 每一个合并的文件的大小 set hive.merge.size.per.task=256000000; -- 平均每个文件的大小,如果小于这个值就会进行合并 set hive.merge.smallfiles.avgsize=16000000;
3.2.存储优化-合并小文件
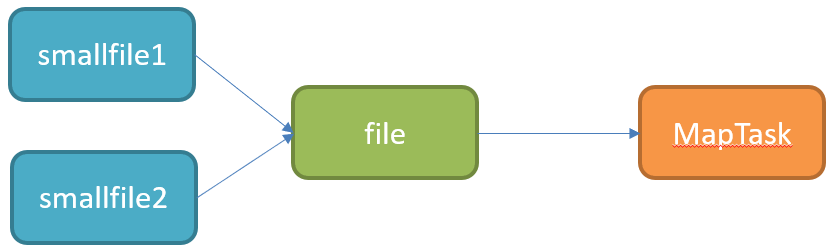
尽管我们通过配置避免了多个小文件的同时产生,但是我们总会遇到数据处理的中间结果是小文件的情况,例如每个小时的分区数据中,大多数小时的数据都比较多,但是个别几个小时,如凌晨的2点~6点等等,数据量比较小,下一步进行处理时就必须对多个小文件进行处理,那么这种场景下怎么解决呢?
类似于MapReduce中的解决方案,Hive中也提供一种输入类CombineHiveInputFormat,用于将小文件合并以后,再进行处理。
Hive中提供一种输入类CombineHiveInputFormat,用于将小文件合并以后,再进行处理。配置:
-- 设置Hive中底层MapReduce读取数据的输入类:将所有文件合并为一个大文件作为输入 set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
3.3.存储优化-ORC文件索引
在使用ORC文件时,为了加快读取ORC文件中的数据内容,ORC提供了两种索引机制:Row Group Index 和 Bloom Filter Index可以帮助提高查询ORC文件的性能,当用户写入数据时,可以指定构建索引,当用户查询数据时,可以根据索引提前对数据进行过滤,避免不必要的数据扫描。
⑴.Row Group Index

一个ORC文件包含一个或多个stripes(groups of row data),每个stripe中包含了每个column的min/max值的索引数据,当查询中有<,>,=的操作时,会根据min/max值,跳过扫描不包含的stripes。而其中为每个stripe建立的包含min/max值的索引,就称为Row Group Index行组索引,也叫min-max Index大小对比索引,或者Storage Index。
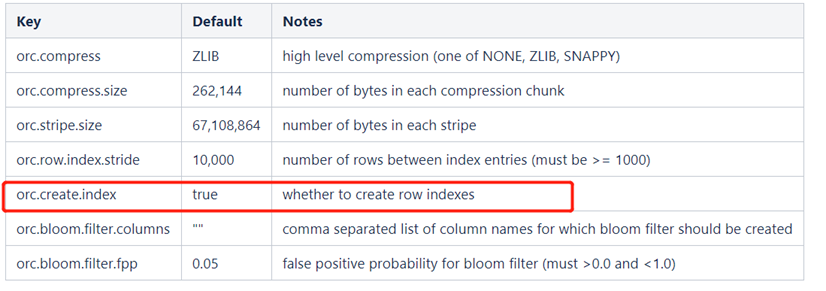
在建立ORC格式表时,指定表参数’orc.create.index’=’true’之后,便会建立Row Group Index,需要注意的是,为了使Row Group Index有效利用,向表中加载数据时,必须对需要使用索引的字段进行排序,否则,min/max会失去意义。另外,这种索引主要用于数值型字段的范围查询过滤优化上
- Row Group Index(行组索引)存储原理
Row Group Index 是通过对行组(row group)的统计信息(如最小值、最大值等)来优化查询的。每个 ORC 文件被分成多个 Stripe,每个 Stripe 进一步分为多个 Row Group。对于每个列的 Row Group,ORC 会记录该列的 min/max 值、数据长度、行数等。每个 Stripe 的组成:
- Header:Stripe 的元数据信息
- Index Data:Row Group 索引数据(包括每列的最小值、最大值等统计信息)
- Row Data:实际的列数据
- Footer:元数据,包括列的类型和编码信息
在查询时,Hive 使用这些统计信息来判断某个行组是否可能包含匹配的数据。例如,如果查询 WHERE price > 100,则 Hive 可以跳过那些 price 列的最大值小于 100 的行组,从而减少不必要的扫描。
图示:Row Group Index 存储结构
+---------------------------+ | ORC File | +---------------------------+ | Stripe 1 | | +-----------------------+ | | | Row Group 1 | | | | min(price)=50, max=100 | | | +-----------------------+ | | | Row Group 2 | | | | min(price)=101, max=150| | | +-----------------------+ | | Stripe 2 | +---------------------------+
在查询 WHERE price > 100 时,Hive 会直接跳过 Stripe 1 的 Row Group 1,因为 price 列的最大值是 100,显然不会满足条件。
- 开启索引配置
set hive.optimize.index.filter=true;
永久生效,请配置在hive-site.xml中
- 创建表,并指定构建索引
CREATE TABLE tb_orc_index stored as orc tblproperties ("orc.create.index"="true") as select * from log_text distribute by track_time sort by track_time;
当进行范围或者等值查询(<,>,=)时就可以基于构建的索引进行查询
SELECT COUNT(*) FROM tb_orc_index
WHERE track_time > "2017-08-10 13:00:01" AND track_time > "2017-08-10 13:00:07"

⑵.Bloom Filter Index
建表时候,通过表参数”orc.bloom.filter.columns”=”columnName……”来指定为哪些字段建立BloomFilter索引,这样在生成数据的时候,会在每个stripe中,为该字段建立BloomFilter的数据结构,当查询条件中包含对该字段的=号过滤时候,先从BloomFilter中获取以下是否包含该值,如果不包含,则跳过该stripe。

- Bloom Filter Index 存储原理
Bloom Filter Index 是一种用于加速精确匹配查询的数据结构。布隆过滤器是一种基于哈希函数的概率性结构,用于判断某个元素是否可能在集合中存在。每个 ORC 文件可以为指定的列创建布隆过滤器索引。它会为每个行组构建布隆过滤器,并根据输入的值生成多个哈希,存储在位数组中。
- 布隆过滤器的位数组大小是固定的,且使用多个哈希函数来决定哪些位会被设置为 1。当查询精确值时,Hive 可以通过布隆过滤器来快速判断某值是否可能在某个行组中出现。
图示:Bloom Filter Index 存储结构
+---------------------------+ | ORC File | +---------------------------+ | Stripe 1 | | +-----------------------+ | | | Row Group 1 | | | | Bloom Filter: | | | | Hash('abc123') -> set | | | +-----------------------+ | | | Row Group 2 | | | | Bloom Filter: | | | | Hash('xyz456') -> set | | | +-----------------------+ | | Stripe 2 | +---------------------------+
当查询 WHERE session_id = 'abc123' 时,Hive 使用布隆过滤器判断 'abc123' 是否可能在每个行组中存在,快速排除不包含此值的行组,减少扫描的数据量
- 创建表,并指定构建索引
CREATE TABLE tb_orc_bloom STORED AS ORC TBLPROPERTIES ( "orc.create.index"="true", "orc.bloom.filter.columns"="track_time,session_id" ) AS SELECT * FROM log_text DISTRIBUTE BY track_time SORT BY track_time;
- track_time的范围过滤可以走row group index,ip的过滤可以走bloom filter index
select count(*) from tb_orc_bloom where track_time > '2017-08-10 13:00:01' and track_time < '2017-08-10 13:00:06' and ip = '10.4.6.47' ;

⑶.存储与性能的对比
| 特性 | Row Group Index | Bloom Filter Index |
|---|---|---|
| 存储类型 | 统计信息(min/max) | 位数组,使用哈希函数 |
| 适用查询类型 | 范围查询,如 <, >, BETWEEN |
精确匹配查询,如 =, IN |
| 存储开销 | 较小,存储最小值、最大值等统计信息 | 较大,存储 Bloom Filter 数据 |
| 性能优化 | 跳过不相关的行组,减少扫描 | 快速排除不包含匹配值的行组,减少扫描 |
| 误判可能性 | 无 | 有一定假阳性几率,但概率很低 |
3.4.ORC矢量化查询
Hive的默认查询执行引擎一次处理一行,而矢量化查询执行是一种Hive针对ORC文件操作的特性,目的是按照每批1024行读取数据,并且一次性对整个记录整合(而不是对单条记录)应用操作,提升了像过滤, 联合, 聚合等等操作的性能。
注意:要使用矢量化查询执行,就必须以ORC格式存储数据。
set hive.vectorized.execution.enabled = true; set hive.vectorized.execution.reduce.enabled = true;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号