GeoPandas地图可视化
一、基础绘图
1.1.绘图接口说明
GeoPandas基于matplotlib库封装高级接口用于制作地图,GeoSeries或GeoDataFrame对象都提供了plot函数以进行对象可视化。与GeoSeries对象相比,GeoDataFrame对象提供的plot函数在参数上更为复杂,也更为常用。GeoDataFrame对象提供的plot函数的常用输入参数如下:
def GeoDataFrame.plot( column: str, np.array, pd.Series (default None), # 用于绘图的列名或数据列 kind: str, # 绘图类型 cmap: str, # matplotlib的颜色图Colormaps color: str, np.array, pd.Series (default None), # 指定所有绘图对象的统一颜色 ax: matplotlib.pyplot.Artist (default None), # 指定matplotlib的绘图轴 cax: matplotlib.pyplot Artist (default None), # 设置图例的坐标轴 categorical: bool (default False), # 是否按照类别设置对象颜色 legend: bool (default False), # 是否显示图例,如果column或color参数未赋值,则此参数无效 scheme: str (default None), # 用于控制分层设色 k:int (default 5), # scheme的层次数 vmin:None or float (default None), # 图例cmap的最小值 vmax:None or float (default None), # 图例cmap的最大值 markersize:str or float or sequence (default None), # 绘图点的大小 figsize: tuple of integers (default None), # 用于控制matplotlib.figure.Figure legend_kwds: dict (default None), # matplotlib图例参数 missing_kw: dsdict (default None), # 缺失值区域绘制参数 aspect:‘auto’, ‘equal’, None or float (default ‘auto’), # 设置绘图比例 **style_kwds: dict, # 其他参数,如对象边界色edgecolor, 对象填充色facecolor, 边界宽linewidth,透明度alpha )->ax: matplotlib axes instance
GeoSeries对象提供的plot函数的常用输入参数如下:
def GeoSeries.plot( s: Series, # GeoSeries对象 cmap: str (default None), color: str, np.array, pd.Series, List (default None), ax: matplotlib.pyplot.Artist (default None), figsize: pair of floats (default None), aspect: ‘auto’, ‘equal’, None or float (default ‘auto’), **style_kwds: dict )->ax: matplotlib axes instance
1.1.1.读取数据集
Shapefile 是一种用于存储地理数据的矢量数据格式,通常由多个文件组成,其中最主要的三个文件是 .shp、.shx 和 .dbf。以下是对这三个文件的详细说明:
- .shp 文件存储几何形状数据,
- .shx 文件存储几何索引,
- .dbf 文件存储属性数据。
1. ne_110m_admin_0_countries.shp
文件类型: Shapefile 文件
作用和含义:.shp 文件存储几何形状数据。它包含地理要素的几何形状(例如点、线、多边形)的基本信息。这些几何形状定义了地图上的地理特征,例如国家的边界、河流的路径或城市的位置。
这个文件是 Shapefile 的核心文件,没有它就无法表示地理数据的几何部分。
2. ne_110m_admin_0_countries.shx
文件类型: 索引文件
作用和含义:.shx 文件是一个几何索引文件,用于快速访问 .shp 文件中的几何形状数据。它包含每个几何形状的记录的索引,使得在读取或处理特定几何形状时更加高效。没有 .shx 文件,读取 .shp 文件会变得很慢,因为每次需要找到特定几何形状时都需要扫描整个文件。
3.ne_110m_admin_0_countries.dbf
文件类型: 属性表文件
作用和含义:
- .dbf 文件是一个属性表文件,使用 dBASE 格式存储。它包含与几何形状关联的属性数据。例如,对于国家边界的 Shapefile,属性数据可能包括国家名称、人口、GDP 等信息。
- .dbf 文件是一个表格形式的文件,其中每一行对应于一个几何形状,每一列对应于一个属性字段。
没有 .dbf 文件,几何形状的数据将没有任何属性信息,仅有几何形状本身。Shapefile 除了 .shp、.shx 和 .dbf 之外,Shapefile 还可能包含其他辅助文件,如:
- .prj:投影文件,存储地图投影和坐标系统信息。
- .cpg:编码文件,存储属性表 .dbf 文件的字符编码信息。
- .sbn 和 .sbx:空间索引文件,进一步加快空间查询的速度。
下载 https://www.naturalearthdata.com/downloads/110m-cultural-vectors/ 需要文件
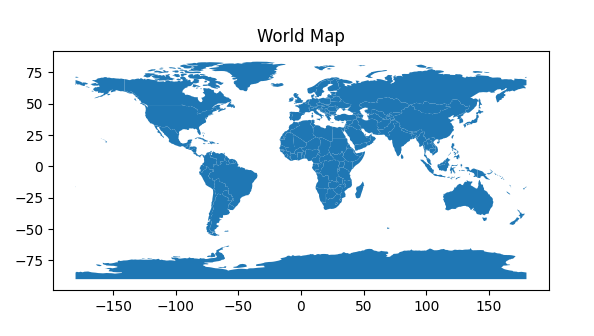
import geopandas as gpd import matplotlib.pyplot as plt # 指定 Shapefile 文件的路径 # 这里指定的是 Shapefile 文件的路径,该路径需要替换为实际存放 .shp 文件的路径。 shapefile_path = './ne_110m_admin_0_countries/ne_110m_admin_0_countries.shp' # 替换为实际路径 # 读取 Shapefile 文件 # 使用 GeoPandas 中的 read_file 函数读取指定路径的 Shapefile 文件。 # 该函数会将 Shapefile 文件加载为 GeoDataFrame,方便后续进行地理数据处理和分析。 world = gpd.read_file(shapefile_path) # 打印前几行数据 # 使用 head() 函数查看 GeoDataFrame 的前几行数据。 # 这有助于了解数据的结构和字段名称,确保文件正确读取。 print(world.head()) # 绘制世界地图 # 使用 plot() 函数绘制 GeoDataFrame 的几何数据。 # 这将显示一个包含所有国家边界的简单世界地图。 world.plot() # 设置图表标题 # 使用 plt.title() 函数设置图表的标题。 # 这里将图表标题设置为“世界地图”。 plt.title('World Map') # 显示图表 # 使用 plt.show() 函数显示绘制的地图。 # 这一步将打开一个窗口展示绘制的地图图像。 plt.show()
执行后绘制的时间地图如下:
输出如下:
featurecla ... geometry 0 Admin-0 country ... MULTIPOLYGON (((180 -16.06713, 180 -16.55522, ... 1 Admin-0 country ... POLYGON ((33.90371 -0.95, 34.07262 -1.05982, 3... 2 Admin-0 country ... POLYGON ((-8.66559 27.65643, -8.66512 27.58948... 3 Admin-0 country ... MULTIPOLYGON (((-122.84 49, -122.97421 49.0025... 4 Admin-0 country ... MULTIPOLYGON (((-122.84 49, -120 49, -117.0312...
列的解释
⑴.featurecla
- 含义:表示地理要素的分类。在这个数据集中,所有的值都是 Admin-0 country,即国家级的行政区划。
- 示例值:Admin-0 country
⑵.geometry
含义:表示地理要素的几何形状。几何形状可以是多边形 (POLYGON) 或多多边形 (MULTIPOLYGON)。
示例值:
- MULTIPOLYGON (((180 -16.06713, 180 -16.55522, ...:这是一个多多边形,表示由多个多边形组成的地理要素(例如,一个由多个岛屿组成的国家)。
- POLYGON ((33.90371 -0.95, 34.07262 -1.05982, ...:这是一个单一的多边形,表示一个单独的地理要素(例如,一个大陆上的国家)。
1.1.2.分区统计图
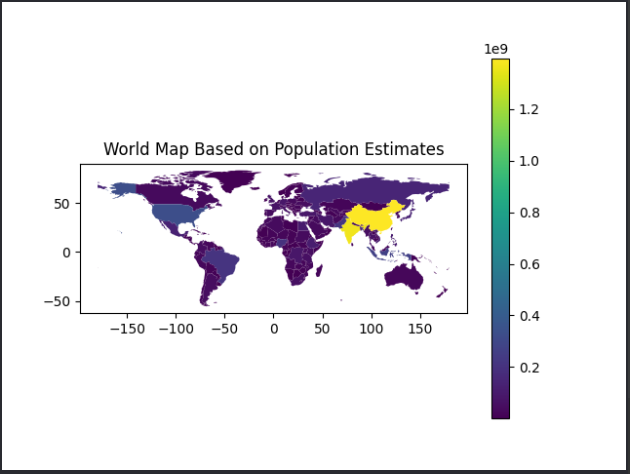
GeoPandas可以轻松创建分区统计图(每个形状的颜色基于关联变量值的地图)。只需在plot函数中将参数column设置为要用于指定颜色的列。使用人口估计值(POP_EST)绘制分区统计图的示例代码:
import geopandas as gpd import matplotlib.pyplot as plt # 指定 Shapefile 文件的路径 shapefile_path = './ne_110m_admin_0_countries/ne_110m_admin_0_countries.shp' # 替换为实际路径 # 读取 Shapefile 文件 world = gpd.read_file(shapefile_path) # 获取有哪些字段 # print(world.columns) # 打印前几行数据 # print(world.head()) # 去除南极地区 """ 从world数据集中删除名称为"Antarctica"的行。具体来说: world是一个GeoDataFrame,它包含了各个国家或地区的地理数据。 world['NAME']是world数据集中的一列,表示国家或地区的名称。 world['NAME'] != "Antarctica"创建一个布尔索引(布尔Series),其每个元素对应world数据集的每一行。如果该行的NAME列等于"Antarctica",则该元素为False;否则,该元素为True。 world[world['NAME'] != "Antarctica"]使用布尔索引过滤world数据集,只保留NAME列不等于"Antarctica"的行。 """ world = world[world['NAME'] != "Antarctica"] # 检查是否存在 'POP_EST' 列 if 'POP_EST' in world.columns: # 绘制基于人口估计值的分区统计图 world.plot(column='POP_EST', legend=True, cmap='viridis') else: print("The 'POP_EST' column does not exist in the dataset.") # 设置图表标题 plt.title('World Map Based on Population Estimates') # 显示图表 plt.show()
1.1.3.图例设置
在GeoPandas中,设置legend=True参数在绘制地图时会显示图例,图例通常用来说明地图中各个颜色区域对应的数据范围或含义。例如,在使用plot()函数时,可以像这样设置参数:
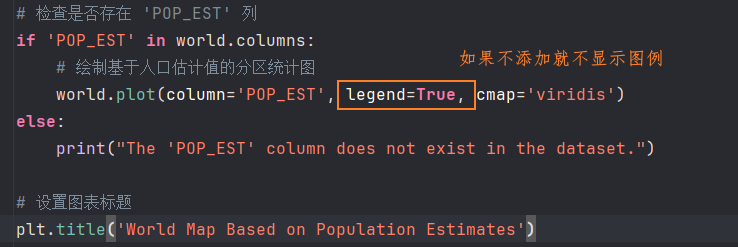
- 删除掉legend=True,就不会显示图例了
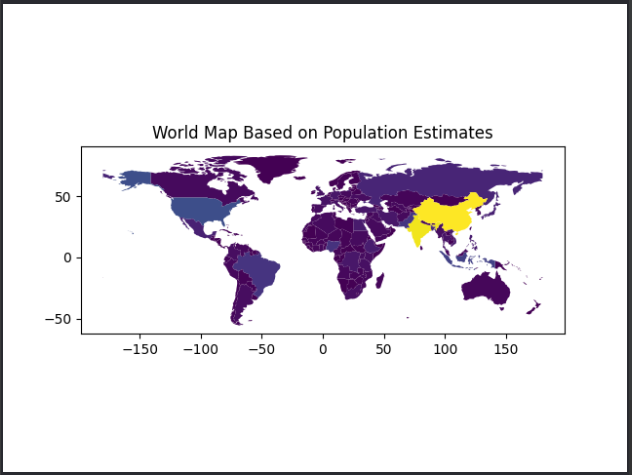
- 如果发现绘图区域和图例区域不对齐,我们通过mpl_toolkits设置图例轴,并通过cax参数直接控制plot函数的图例绘制。
# 从 mpl_toolkits.axes_grid1 导入 make_axes_locatable 函数,用于创建可以包含多个轴的容器 from mpl_toolkits.axes_grid1 import make_axes_locatable # 创建一个包含一个子图的图形对象 (fig) 和轴对象 (ax) # 这里的 1, 1 表示图形对象中只有一个子图 fig, ax = plt.subplots(1, 1) # 使用 make_axes_locatable 函数创建一个可以包含多个轴的容器 (divider) # 该容器与现有的轴对象 (ax) 相关联 divider = make_axes_locatable(ax) # 在主轴 (ax) 的右侧添加一个新的轴 (cax),用于放置颜色条或图例 # "right" 表示新轴的位置在主轴的右边 # size="5%" 表示新轴的宽度为主轴宽度的 5% # pad=0.2 表示新轴与主轴之间的间距为 0.2 个轴的宽度单位 cax = divider.append_axes("right", size="5%", pad=0.2) # 绘制世界地图,按人口估计值进行着色,并在地图右侧添加一个颜色条或图例 # column='pop_est' 指定用于着色的列,这里是 'pop_est'(人口估计值) # ax=ax 指定绘图的轴对象为 ax # legend=True 启用图例 # cax=cax 指定图例放置的轴对象为 cax world.plot(column='pop_est', ax=ax, legend=True, cax=cax)
完整的代码:
import geopandas as gpd import matplotlib.pyplot as plt # 这个函数用于创建一个可以包含多个轴(axes)的容器,使得能够在主轴旁边放置颜色条或图例。 from mpl_toolkits.axes_grid1 import make_axes_locatable # 指定 Shapefile 文件的路径 shapefile_path = './ne_110m_admin_0_countries/ne_110m_admin_0_countries.shp' # 替换为实际路径 # 读取 Shapefile 文件 world = gpd.read_file(shapefile_path) # 获取有哪些字段 # print(world.columns) # 打印前几行数据 # print(world.head()) # 去除南极地区 """ 从world数据集中删除名称为"Antarctica"的行。具体来说: world是一个GeoDataFrame,它包含了各个国家或地区的地理数据。 world['NAME']是world数据集中的一列,表示国家或地区的名称。 world['NAME'] != "Antarctica"创建一个布尔索引(布尔Series),其每个元素对应world数据集的每一行。如果该行的NAME列等于"Antarctica",则该元素为False;否则,该元素为True。 world[world['NAME'] != "Antarctica"]使用布尔索引过滤world数据集,只保留NAME列不等于"Antarctica"的行。 """ world = world[world['NAME'] != "Antarctica"] # 检查是否存在 'POP_EST' 列 if 'POP_EST' in world.columns: # 创建一个包含一个轴的图形对象和轴对象:fig 是图形对象,ax 是轴对象。这行代码创建了一个包含一个子图的图形对象。 fig, ax = plt.subplots(1, 1) # 创建了一个新的容器(divider),这个容器能够在指定的轴(这里是 ax)旁边放置其他轴。 divider = make_axes_locatable(ax) # 设置图例,right表示位置,size=5%表示图例宽度,pad表示图例离图片间距 cax = divider.append_axes("right", size="5%", pad=0.2) # 绘制基于人口估计值的分区统计图 world.plot(column='POP_EST', legend=True, cmap='viridis',cax=cax,ax=ax) else: print("The 'POP_EST' column does not exist in the dataset.") # 设置图表标题 plt.title('World Map Based on Population Estimates') # 显示图表 plt.show()
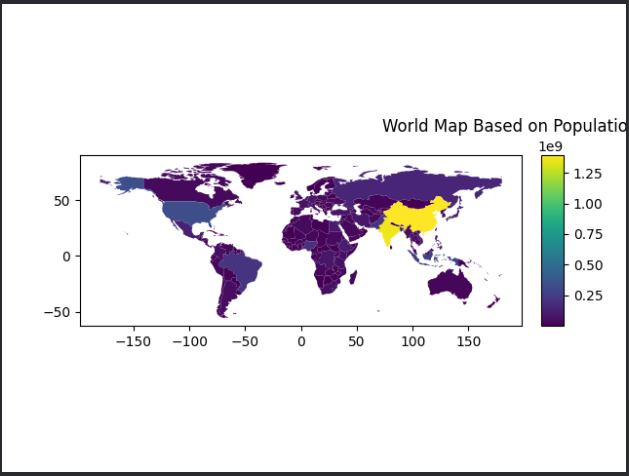
- 此外我们可以通过legend_kwds设置图例信息和方向,就像matplotlib那样。语法:
import matplotlib.pyplot as plt # 创建一个包含一个子图的图形对象 (fig) 和轴对象 (ax) fig, ax = plt.subplots(1, 1) # 绘制世界地图,按人口估计值进行着色,并在地图下方添加一个水平的图例 world.plot(column='pop_est', # 指定用于着色的列,这里是 'pop_est'(人口估计值) ax=ax, # 指定绘图的轴对象为 ax legend=True, # 启用图例 legend_kwds={ # 设置图例的关键字参数 'label': "Population by Country and Area", # 图例标签 'orientation': "horizontal" # 图例的方向,设置为水平 })
完整代理如下:
import geopandas as gpd import matplotlib.pyplot as plt # 这个函数用于创建一个可以包含多个轴(axes)的容器,使得能够在主轴旁边放置颜色条或图例。 from mpl_toolkits.axes_grid1 import make_axes_locatable # 指定 Shapefile 文件的路径 shapefile_path = './ne_110m_admin_0_countries/ne_110m_admin_0_countries.shp' # 替换为实际路径 # 读取 Shapefile 文件 world = gpd.read_file(shapefile_path) # 获取有哪些字段 # print(world.columns) # 打印前几行数据 # print(world.head()) # 去除南极地区 """ 从world数据集中删除名称为"Antarctica"的行。具体来说: world是一个GeoDataFrame,它包含了各个国家或地区的地理数据。 world['NAME']是world数据集中的一列,表示国家或地区的名称。 world['NAME'] != "Antarctica"创建一个布尔索引(布尔Series),其每个元素对应world数据集的每一行。如果该行的NAME列等于"Antarctica",则该元素为False;否则,该元素为True。 world[world['NAME'] != "Antarctica"]使用布尔索引过滤world数据集,只保留NAME列不等于"Antarctica"的行。 """ world = world[world['NAME'] != "Antarctica"] # 检查是否存在 'POP_EST' 列 if 'POP_EST' in world.columns: # 创建一个包含一个轴的图形对象和轴对象:fig 是图形对象,ax 是轴对象。这行代码创建了一个包含一个子图的图形对象。 fig, ax = plt.subplots(1, 1) # 绘制基于人口估计值的分区统计图 world.plot(column='POP_EST', legend=True, cmap='viridis', ax=ax, legend_kwds={ # 设置图例的关键字参数 'label': "Population by Country and Area", # 图例标签 'orientation': "horizontal" # 图例的方向,设置为水平 }) else: print("The 'POP_EST' column does not exist in the dataset.") # 设置图表标题 plt.title('World Map Based on Population Estimates') # 显示图表 plt.show()
1.1.4.颜色设置
GeoPandas的绘图函数中通过cmap参数设置颜色图,具体cmap参数的设置可以见matplotlib颜色图选择教程。
# 设置颜色图为tab20 # 绘制基于人口估计值的分区统计图 world.plot(column='POP_EST', legend=True, cmap='tab20', ax=ax, legend_kwds={ # 设置图例的关键字参数 'label': "Population by Country and Area", # 图例标签 'orientation': "horizontal" # 图例的方向,设置为水平 })
如果只想绘制边界,可以调用boundary属性进行绘制。
world.boundary.plot()
1.1.5.缺失数据绘制
当绘制项某些地图的数据缺失时,GeoPandas会自动放弃这些区域数据的绘制通过missing_kwds设置。如下所示,人为设置一些国家的 'POP_EST' 列为缺失值以演示效果。
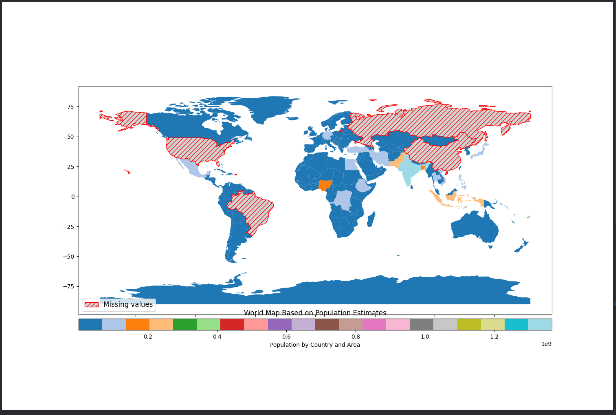
import geopandas as gpd # 导入 GeoPandas 库,用于处理地理数据 import matplotlib.pyplot as plt # 导入 Matplotlib 库,用于绘制图形 from mpl_toolkits.axes_grid1 import make_axes_locatable # 用于创建可以容纳多个轴的容器 from matplotlib.patches import Patch # 导入 Patch 类,用于创建自定义图例条目 # 指定 Shapefile 文件的路径 shapefile_path = './ne_110m_admin_0_countries/ne_110m_admin_0_countries.shp' # 请替换为实际路径 # 读取 Shapefile 文件 world = gpd.read_file(shapefile_path) # 人为设置一些国家的 'POP_EST' 列为缺失值以演示效果 """ 这两句代码的作用是将特定国家(美国、巴西、中国、俄罗斯)的 POP_EST 列值设置为缺失值,以模拟数据缺失的情况,便于在绘图时演示如何处理和显示这些缺失数据。 missing_countries = ['United States of America', 'Brazil', 'China', 'Russia']: 这行代码创建了一个包含一些国家名称的列表。 列表中的国家是:美国(United States of America)、巴西(Brazil)、中国(China)、俄罗斯(Russia)。 world.loc[world['SOVEREIGNT'].isin(missing_countries), 'POP_EST'] = None: """ missing_countries = ['United States of America', 'Brazil', 'China', 'Russia'] """ world['SOVEREIGNT']:访问 world 数据集中的 SOVEREIGNT 列,该列包含国家的主权名称。 .isin(missing_countries):检查 SOVEREIGNT 列中的每个值是否在 missing_countries 列表中。如果是,则返回 True,否则返回 False。 world.loc[...]:使用布尔索引定位 SOVEREIGNT 列值在 missing_countries(缺失数据国家) 列表中的行。 world.loc[world['SOVEREIGNT'].isin(missing_countries), 'POP_EST'] = None:将这些行的 POP_EST 列值设置为 None(即缺失值)。 """ world.loc[world['SOVEREIGNT'].isin(missing_countries), 'POP_EST'] = None # 检查是否存在 'POP_EST' 列 if 'POP_EST' in world.columns: # 创建一个包含一个轴的图形对象和轴对象 fig, ax = plt.subplots(1, 1, figsize=(15, 10)) # figsize 设置图形大小 # 创建一个可以包含多个轴的容器 divider = make_axes_locatable(ax) # 在底部添加一个轴用于图例,size 和 pad 控制其大小和间距 cax = divider.append_axes("bottom", size="5%", pad=0.1) # 绘制基于人口估计值的分区统计图 world.plot(column='POP_EST', cmap='tab20', legend=True, # 使用 'tab20' 颜色图绘制 'POP_EST' 列 legend_kwds={'label': "Population by Country and Area", # 设置图例标签 'orientation': "horizontal", # 将图例方向设置为水平 'cax': cax}, # 将图例绘制在指定的轴上 missing_kwds={"color": "lightgrey", "edgecolor": "red", "hatch": "///", "label": "Missing values"}, # 设置缺失值的颜色、边框颜色、阴影和标签 ax=ax) # 指定要绘制的轴 # 创建代理用于图例 proxy = [Patch(facecolor='lightgrey', edgecolor='red', hatch='///', label='Missing values')] # 自定义图例条目表示缺失值 # 获取当前的图例 legend = ax.get_legend() if legend: # 如果已经存在图例,则检查图例条目,移除原有的缺失值条目,并添加自定义条目 # legend.legendHandles这是一个列表,包含了图例中的所有句柄(handles)。句柄是图例中每个条目的图形表示,比如线条、矩形、圆圈等。作用:通过操作这个列表,你可以添加、移除或修改图例中的图形条目。每个句柄对应一个图形元素(如颜色块、线条等),用于在图例中展示。 # legend.get_texts():返回一个包含所有图例文本对象的列表。每个文本对象对应图例中的一个标签(label)。作用:通过操作这个列表,你可以获取、修改或移除图例中的文本标签。每个文本对象包含了图例条目的描述性文字。 for handle, text in zip(legend.legendHandles, legend.get_texts()): # 遍历图例条目,查找标记为 'Missing values' 的条目 if text.get_text() == 'Missing values': legend.legendHandles.remove(handle) # 移除图例句柄 legend.get_texts().remove(text) # 移除图例文本 # 添加自定义图例条目,用于表示缺失值 legend.legendHandles.extend(proxy) # 添加自定义图例句柄 legend.get_texts().append(plt.Text(0, 0, 'Missing values')) # 添加自定义图例文本 else: # 如果没有现有图例,则创建一个新的图例 ax.legend(handles=proxy, loc='lower left', fontsize='large') # handles=proxy: 设置图例句柄为自定义的缺失值条目 # loc='lower left': 将图例放置在左下角 # fontsize='large': 设置图例字体大小为大号 else: print("The 'POP_EST' column does not exist in the dataset.") # 如果 'POP_EST' 列不存在,打印提示信息 # 设置图表标题 plt.title('World Map Based on Population Estimates') # 显示图表 plt.show()
1.1.6.图层设置
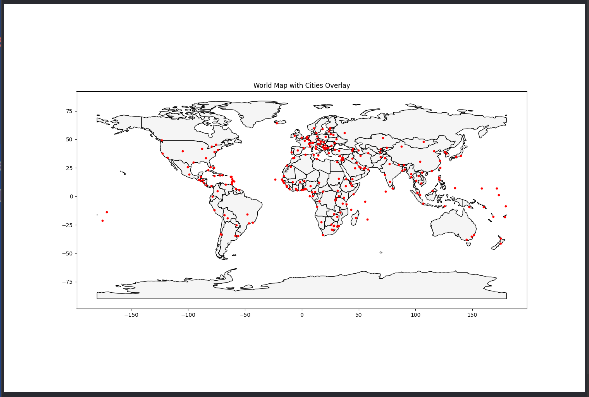
当我们需要叠加多张地图或多个数据的结果,则需要用到地图的图层。GeoPandas提供了两种方式进行图层设置,但是要注意的是在合并地图之前,始终确保它们共享一个共同的坐标参考系crs。如将world地图和cities地图合并绘制。
import geopandas as gpd # 导入 GeoPandas 库,用于处理地理数据 import matplotlib.pyplot as plt # 导入 Matplotlib 库,用于绘制图形 # 指定 Shapefile 文件的路径 shapefile_path = './ne_110m_admin_0_countries/ne_110m_admin_0_countries.shp' # 世界地图的 Shapefile 文件路径,请替换为实际路径 cities_path = './ne_110m_populated_places/ne_110m_populated_places.shp' # 城市数据的 Shapefile 文件路径,请替换为实际路径 # 读取 Shapefile 文件 world = gpd.read_file(shapefile_path) # 读取世界地图 Shapefile 文件,创建 GeoDataFrame cities = gpd.read_file(cities_path) # 读取城市数据 Shapefile 文件,创建 GeoDataFrame # 确保两个 GeoDataFrames 共享相同的坐标参考系 if world.crs != cities.crs: # 如果两个 GeoDataFrames 的 CRS 不同 cities = cities.to_crs(world.crs) # 将 cities 数据转换为与 world 数据相同的 CRS # 设置绘图 fig, ax = plt.subplots(1, 1, figsize=(15, 10)) # 创建一个包含一个轴的图形对象和轴对象 # 1, 1 表示创建一个 1 行 1 列的子图,figsize 指定图形的大小(宽 15 英寸,高 10 英寸) # 绘制世界地图(作为底层) world.plot(ax=ax, color='whitesmoke', edgecolor='black') # 使用 GeoDataFrame 的 plot 方法绘制世界地图 # ax=ax:指定绘图的轴对象 # color='whitesmoke':设置多边形的填充颜色为浅灰色 # edgecolor='black':设置多边形的边框颜色为黑色 # 绘制城市数据(作为上层) cities.plot(ax=ax, color='red', markersize=10) # 使用 GeoDataFrame 的 plot 方法绘制城市数据 # ax=ax:指定绘图的轴对象 # color='red':设置标记颜色为红色 # markersize=10:设置标记大小为 10 # 设置图表标题 plt.title('World Map with Cities Overlay') # 设置图表的标题为 "World Map with Cities Overlay" # 显示图表 plt.show() # 显示绘制的图表
1.1.7.图层顺序控制
如果我们需要控制地图图层的展示顺序,即哪张图片显示在前。一种办法是通过绘图顺序设置,后绘制的数据的图层顺序越靠上。一种是通过zorder参数设置图层顺序,zorder值越大,表示图层顺序越靠上。如下所示:
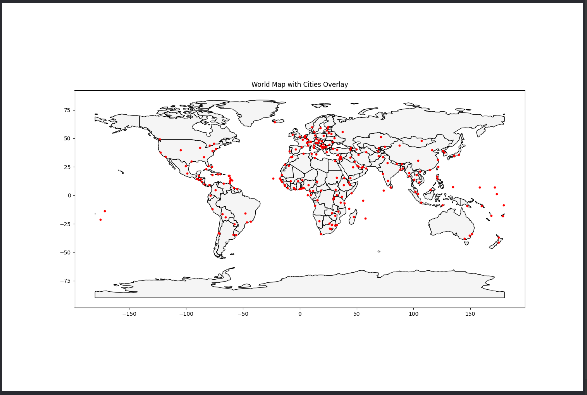
1.通过绘图顺序来控制图层顺序是最简单的一种方式。我们可以先绘制世界地图,然后再绘制城市数据,以确保城市数据位于世界地图的上层。
import geopandas as gpd # 导入 GeoPandas 库,用于处理地理数据 import matplotlib.pyplot as plt # 导入 Matplotlib 库,用于绘制图形 # 指定 Shapefile 文件的路径 shapefile_path = './ne_110m_admin_0_countries/ne_110m_admin_0_countries.shp' # 世界地图的 Shapefile 文件路径,请替换为实际路径 cities_path = './ne_110m_populated_places/ne_110m_populated_places.shp' # 城市数据的 Shapefile 文件路径,请替换为实际路径 # 读取 Shapefile 文件 world = gpd.read_file(shapefile_path) # 读取世界地图 Shapefile 文件,创建 GeoDataFrame cities = gpd.read_file(cities_path) # 读取城市数据 Shapefile 文件,创建 GeoDataFrame # 确保两个 GeoDataFrames 共享相同的坐标参考系 if world.crs != cities.crs: # 如果两个 GeoDataFrames 的 CRS 不同 cities = cities.to_crs(world.crs) # 将 cities 数据转换为与 world 数据相同的 CRS # 设置绘图 fig, ax = plt.subplots(1, 1, figsize=(15, 10)) # 创建一个包含一个轴的图形对象和轴对象 # 1, 1 表示创建一个 1 行 1 列的子图,figsize 指定图形的大小(宽 15 英寸,高 10 英寸) # 绘制世界地图(作为底层) world.plot(ax=ax, color='whitesmoke', edgecolor='black') # 使用 GeoDataFrame 的 plot 方法绘制世界地图 # ax=ax:指定绘图的轴对象 # color='whitesmoke':设置多边形的填充颜色为浅灰色 # edgecolor='black':设置多边形的边框颜色为黑色 # 绘制城市数据(作为上层) cities.plot(ax=ax, color='red', markersize=10) # 使用 GeoDataFrame 的 plot 方法绘制城市数据 # ax=ax:指定绘图的轴对象 # color='red':设置标记颜色为红色 # markersize=10:设置标记大小为 10 # 设置图表标题 plt.title('World Map with Cities Overlay') # 设置图表的标题为 "World Map with Cities Overlay" # 显示图表 plt.show() # 显示绘制的图表
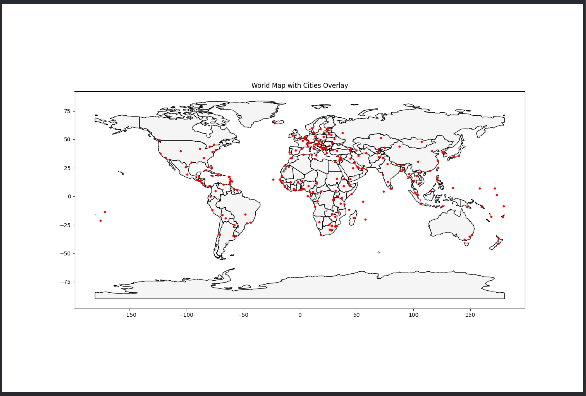
2.一种是通过zorder参数设置图层顺序,zorder值越大,表示图层顺序越靠上
import geopandas as gpd # 导入 GeoPandas 库,用于处理地理数据 import matplotlib.pyplot as plt # 导入 Matplotlib 库,用于绘制图形 # 指定 Shapefile 文件的路径 shapefile_path = './ne_110m_admin_0_countries/ne_110m_admin_0_countries.shp' # 世界地图的 Shapefile 文件路径,请替换为实际路径 cities_path = './ne_110m_populated_places/ne_110m_populated_places.shp' # 城市数据的 Shapefile 文件路径,请替换为实际路径 # 读取 Shapefile 文件 world = gpd.read_file(shapefile_path) # 读取世界地图 Shapefile 文件,创建 GeoDataFrame cities = gpd.read_file(cities_path) # 读取城市数据 Shapefile 文件,创建 GeoDataFrame # 确保两个 GeoDataFrames 共享相同的坐标参考系 if world.crs != cities.crs: # 如果两个 GeoDataFrames 的 CRS 不同 cities = cities.to_crs(world.crs) # 将 cities 数据转换为与 world 数据相同的 CRS # 设置绘图 fig, ax = plt.subplots(1, 1, figsize=(15, 10)) # 创建一个包含一个轴的图形对象和轴对象 # 1, 1 表示创建一个 1 行 1 列的子图,figsize 指定图形的大小(宽 15 英寸,高 10 英寸) # 绘制世界地图(作为底层) world.plot(ax=ax, color='whitesmoke', edgecolor='black', zorder=1) # 使用 GeoDataFrame 的 plot 方法绘制世界地图 # ax=ax:指定绘图的轴对象 # color='whitesmoke':设置多边形的填充颜色为浅灰色 # edgecolor='black':设置多边形的边框颜色为黑色 # zorder=1:设置图层顺序,zorder 值越小,图层越靠下 # 绘制城市数据(作为上层) cities.plot(ax=ax, color='red', markersize=10, zorder=2) # 使用 GeoDataFrame 的 plot 方法绘制城市数据 # ax=ax:指定绘图的轴对象 # color='red':设置标记颜色为红色 # markersize=10:设置标记大小为 10 # zorder=2:设置图层顺序,zorder 值越大,图层越靠上 # 设置图表标题 plt.title('World Map with Cities Overlay') # 设置图表的标题为 "World Map with Cities Overlay" # 显示图表 plt.show() # 显示绘制的图表
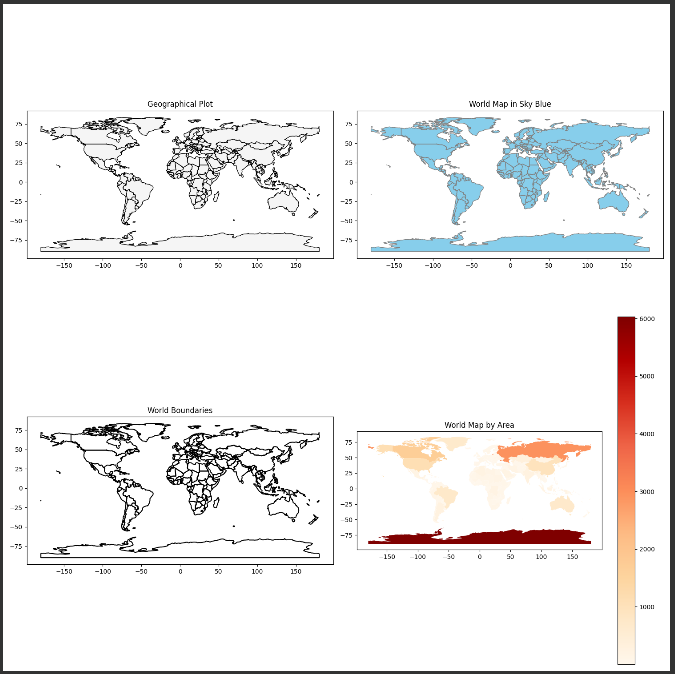
1.1.8.Pandas Plots
GeoPandas 的 plot 函数与 Pandas 的 plot 函数类似,允许通过 kind 参数来指定绘图类型。默认情况下,GeoPandas 使用 kind='geo' 来绘制地理图形。然而,你也可以使用其他类型的图形,例如线图、柱状图、散点图等,这些类型与 Pandas 的绘图函数兼容。pandas默认提供的绘图函数见:Chart visualization。
下面是一个使用 GeoPandas 和 Pandas 的示例,展示如何使用不同的 kind 参数来绘制各种类型的图形。
import geopandas as gpd # 导入 GeoPandas 库,用于处理地理数据 import matplotlib.pyplot as plt # 导入 Matplotlib 库,用于绘制图形 # 指定 Shapefile 文件的路径 shapefile_path = './ne_110m_admin_0_countries/ne_110m_admin_0_countries.shp' # 请替换为实际路径 # 读取 Shapefile 文件 world = gpd.read_file(shapefile_path) # 读取世界地图 Shapefile 文件,创建 GeoDataFrame # 设置绘图区域和大小 fig, axs = plt.subplots(2, 2, figsize=(15, 15)) # 创建一个包含2x2网格子图的图形对象和轴对象 # 2, 2 表示创建2行2列的子图网格 # figsize=(15, 15) 表示图形的大小为15x15英寸 # 绘制地理图形(默认) world.plot(ax=axs[0, 0], color='whitesmoke', edgecolor='black') # 使用 GeoPandas 的 plot 方法绘制地理图形 # ax=axs[0, 0] 指定绘图的子图轴 # color='whitesmoke' 设置地图颜色为浅灰色 # edgecolor='black' 设置地图边界颜色为黑色 axs[0, 0].set_title('Geographical Plot') # 设置子图标题 # 世界地图(重新绘制) world.plot(ax=axs[0, 1], color='skyblue', edgecolor='grey') # 使用不同颜色绘制世界地图 # ax=axs[0, 1] 指定绘图的子图轴 # color='skyblue' 设置地图颜色为天蓝色 # edgecolor='grey' 设置地图边界颜色为灰色 axs[0, 1].set_title('World Map in Sky Blue') # 设置子图标题 # 简单地理图形 world.boundary.plot(ax=axs[1, 0], color='black') # 仅绘制世界地图边界 # ax=axs[1, 0] 指定绘图的子图轴 # color='black' 设置边界颜色为黑色 axs[1, 0].set_title('World Boundaries') # 设置子图标题 # 面积图(假设有需要的数据) world['area'] = world.area # 添加面积列作为示例 world.plot(column='area', ax=axs[1, 1], legend=True, cmap='OrRd') # 使用面积绘制颜色渐变图 # column='area' 指定用于着色的列 # ax=axs[1, 1] 指定绘图的子图轴 # legend=True 启用图例 # cmap='OrRd' 使用橙红色颜色映射 axs[1, 1].set_title('World Map by Area') # 设置子图标题 # 调整布局并显示图形 plt.tight_layout() # 自动调整子图布局,使其不重叠 plt.show() # 显示图形
1.2.绘图实例之中国地图绘制
1.2.1.读取地图数据
import geopandas as gpd # 导入 GeoPandas 库,用于处理地理数据 import matplotlib.pyplot as plt # 导入 Matplotlib 库,用于绘制图形 # 读取中国地图数据,数据来自 DataV.GeoAtlas,将其投影到 EPSG:4573 data = gpd.read_file('https://geo.datav.aliyun.com/areas_v3/bound/100000_full.json').to_crs('EPSG:4573') # gpd.read_file() 从指定 URL 读取 GeoJSON 数据并创建 GeoDataFrame # 'https://geo.datav.aliyun.com/areas_v3/bound/100000_full.json' 是中国地图数据的 URL # to_crs('EPSG:4573') 将数据投影转换为 EPSG:4573 坐标参考系统 # 打印 GeoDataFrame 的形状(行数和列数),用于检查数据是否正确读取 print(data.shape) # 打印 GeoDataFrame 的最后五行,用于检查数据内容 print(data.tail()) # # 保存各个省级行政区的面积,单位万平方公里 data['area'] = data.area / 1e6 / 1e4 # data.area 计算每个省级行政区的面积,默认单位为平方米 # / 1e6 将面积从平方米转换为平方公里 # / 1e4 将面积从平方公里转换为万平方公里 # 将计算结果存储在新的 'area' 列中 # 计算并打印所有省级行政区的总面积,单位为万平方公里 print(data['area'].sum())
输出结果如下:
C:\Users\Augus\Envs\flask3env\Scripts\python.exe D:\code\flaskProject5\test9.py Skipping field center: unsupported OGR type: 3 Skipping field centroid: unsupported OGR type: 3 Skipping field acroutes: unsupported OGR type: 1 (35, 8) adcode ... geometry 30 650000 ... MULTIPOLYGON (((17794320.693 4768675.631, 1779... 31 710000 ... MULTIPOLYGON (((20103629.026 2566628.808, 2011... 32 810000 ... MULTIPOLYGON (((19432072.34 2517924.724, 19428... 33 820000 ... MULTIPOLYGON (((19385068.278 2470740.132, 1939... 34 100000_JD ... MULTIPOLYGON (((20309263.208 2708129.155, 2032... [5 rows x 8 columns] 989.1500769770856
data.tail()输出参数如:
解释 adcode: 这是表示每个省级行政区的代码。其中: 650000 是新疆维吾尔自治区的代码。 710000 是台湾省的代码。 810000 是香港特别行政区的代码。 820000 是澳门特别行政区的代码。 100000_JD 表示南海九段线的代码。 geometry: 这一列包含每个省级行政区的几何形状数据,通常是多边形或多边形集(MULTIPOLYGON),定义了这些区域的边界。 这些几何数据使用坐标点表示。例如,MULTIPOLYGON (((17794320.693 4768675.631, ...))) 表示一个多边形,其中每个坐标点表示地图上的一个点
拆分数据语法:
# 拆分数据 nine_dotted_line = data.iloc[-1] data = data[:-1] nine_dotted_line
使用GeoPandas来拆分和处理地理数据。这段代码的目的是将南海九段线从数据集中拆分出来,并保留其独立数据。以下是一个完整的案例,并包含注释解释每一步的作用和含义:
import geopandas as gpd # 读取中国地图数据,并将其投影到 EPSG:4573 坐标参考系统 data = gpd.read_file('https://geo.datav.aliyun.com/areas_v3/bound/100000_full.json').to_crs('EPSG:4573') # 输出数据的形状,包含34个省级行政区和1个南海九段线,共35条数据 print(data.shape) # 输出:(35, x),x表示列数 # 输出数据集的最后五条数据,查看数据的基本结构和内容 print(data.tail()) # 拆分数据,将南海九段线单独保存 nine_dotted_line = data.iloc[-1] # 提取数据集的最后一条数据,即南海九段线 data = data[:-1] # 去除数据集的最后一条数据,只保留34个省级行政区 # 打印南海九段线的数据,验证拆分结果 print(nine_dotted_line)
说明结果如下:
C:\Users\Augus\Envs\flask3env\Scripts\python.exe D:\code\flaskProject5\test10.py Skipping field center: unsupported OGR type: 3 Skipping field centroid: unsupported OGR type: 3 Skipping field acroutes: unsupported OGR type: 1 adcode 100000_JD name adchar JD childrenNum NaN level None parent None subFeatureIndex NaN geometry MULTIPOLYGON (((20309263.208229765 2708129.154... Name: 34, dtype: object
这段输出是南海九段线的数据,以下是每个字段的说明:
adcode:100000_JD,这是南海九段线的行政代码。name: 为空,这里没有提供南海九段线的名称。adchar:JD,这可能是南海九段线的简称或代号。childrenNum:NaN,没有子级区域数据。level:None,没有提供行政级别。parent:None,没有提供上级区域。subFeatureIndex:NaN,没有子特征索引。geometry:MULTIPOLYGON (((20309263.208229765 2708129.154...,这是南海九段线的几
1.2.2.地图绘制
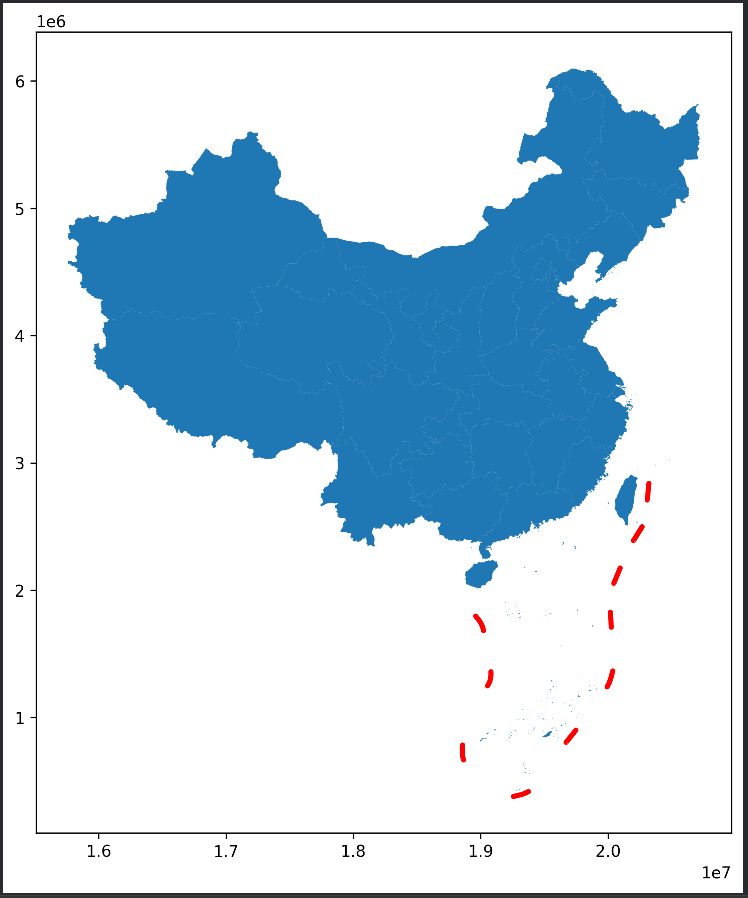
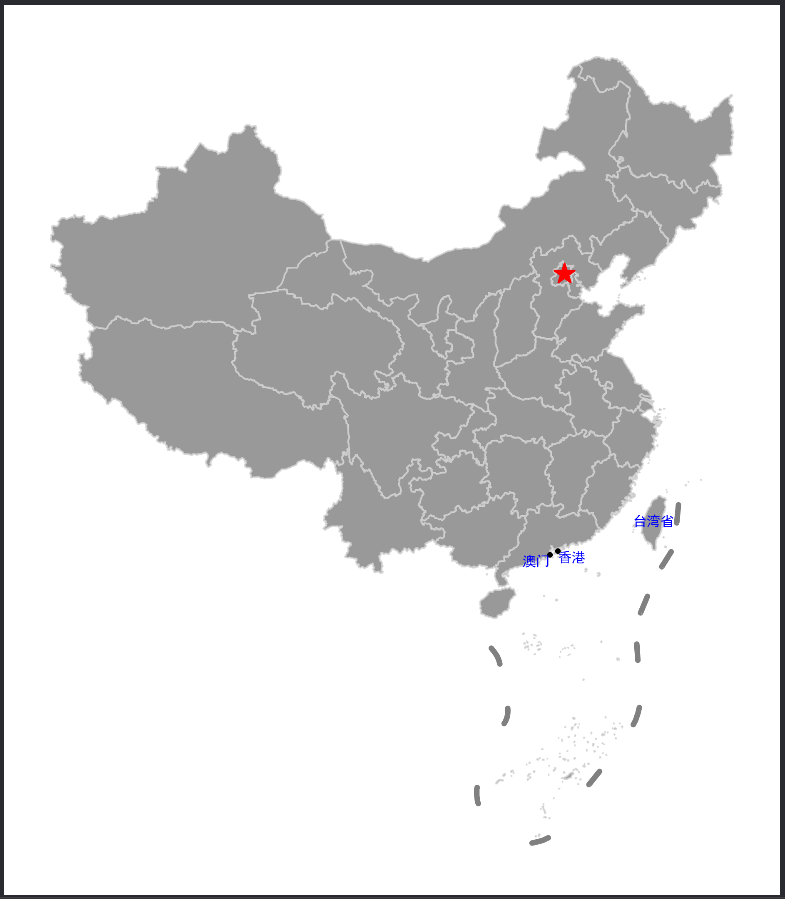
import geopandas as gpd # 导入 GeoPandas 库,用于处理地理数据 import matplotlib.pyplot as plt # 导入 Matplotlib 库,用于绘制图形 # 读取中国地图数据,数据来自 DataV.GeoAtlas,将其投影到 EPSG:4573 # read_file:从指定的URL读取地理数据文件 # to_crs:将读取的数据投影到 EPSG:4573 坐标参考系统 data = gpd.read_file('https://geo.datav.aliyun.com/areas_v3/bound/100000_full.json').to_crs('EPSG:4573') print(data.shape) # 打印数据的形状,查看数据的行数和列数,以确保数据正确加载 # 查看最后五条数据 print(data.tail()) # 打印数据的最后五行,包含南海九段线数据,以检查数据内容 # 拆分数据 # iloc[-1]:获取数据的最后一行,即南海九段线数据 nine_dotted_line = data.iloc[-1] # 取出南海九段线的数据 # data[:-1]:保留数据的前面所有行,去除最后一行 data = data[:-1] # 去除最后一条南海九段线的数据,保留其他数据 print(nine_dotted_line) # 打印南海九段线的数据,确保正确提取 # 创建画布 # subplots:创建一个包含一个轴的图形对象和轴对象 # figsize:设置图形的大小为 12 x 9 英寸 fig, ax = plt.subplots(figsize=(12, 9)) # 创建一个包含一个轴的图形对象和轴对象,设置图形大小为 12 x 9 英寸 # 绘制主要区域 # plot:在轴上绘制主要区域(中国各省级行政区),使用默认颜色和边框颜色 ax = data.plot(ax=ax) # 在轴上绘制主要区域(中国各省级行政区),默认颜色和边框颜色 # 绘制九段线 # GeoSeries:将南海九段线的数据转换为 GeoSeries 对象 # plot:在轴上绘制南海九段线,设置边框颜色为红色,线宽为 3 ax = gpd.GeoSeries(nine_dotted_line.geometry).plot(ax=ax, edgecolor='red', linewidth=3) # 在轴上绘制南海九段线,设置边框颜色为红色,线宽为 3 # 保存结果 # savefig:将绘制结果保存为文件 # dpi:设置图像分辨率为 300 DPI # bbox_inches='tight':设置紧密布局,去除多余的空白边距 fig.savefig('res.png', dpi=300, bbox_inches='tight') # 将绘制结果保存为名为 'res.png' 的文件,分辨率为 300 DPI,紧密布局
生成图片如下:
1.2.3.自定义绘图
import geopandas as gpd # 导入 GeoPandas 库,用于处理地理数据 import matplotlib.pyplot as plt # 导入 Matplotlib 库,用于绘制图形 # 读取中国地图数据,数据来自 DataV.GeoAtlas,将其投影到 EPSG:4573 data = gpd.read_file('https://geo.datav.aliyun.com/areas_v3/bound/100000_full.json').to_crs('EPSG:4573') print(data.shape) # 打印数据的形状,查看数据行数和列数 # 查看最后五条数据 print(data.tail()) # 打印数据的最后五行,包含南海九段线数据 # 拆分数据 nine_dotted_line = data.iloc[-1] # 取出南海九段线的数据 data = data[:-1] # 去除最后一条南海九段线的数据,保留其他数据 print(nine_dotted_line) # 打印南海九段线的数据 # 创建画布 fig, ax = plt.subplots(figsize=(12, 9)) # 创建一个包含一个轴的图形对象和轴对象,设置图形大小为 12 x 9 英寸 # 绘制主要区域 # plot:在轴上绘制主要区域(中国各省级行政区) # facecolor:设置区域填充颜色为灰色 # edgecolor:设置边框颜色为浅灰色 # alpha:设置透明度为 0.8 # linewidth:设置边框线宽为 1 ax = data.plot(ax=ax, facecolor='grey', edgecolor='lightgrey', alpha=0.8, linewidth=1) # 绘制九段线 # GeoSeries:将南海九段线的数据转换为 GeoSeries 对象 # plot:在轴上绘制南海九段线 # edgecolor:设置边框颜色为灰色 # linewidth:设置线宽为 3 ax = gpd.GeoSeries(nine_dotted_line.geometry).plot(ax=ax, edgecolor='grey', linewidth=3) # 强调首都 # 选择北京市的数据并绘制代表点 # representative_point:获取北京市的代表点(通常为几何中心) # plot:在轴上绘制代表点 # facecolor:设置点的颜色为红色 # marker:设置点的形状为星形('*') # markersize:设置点的大小为 150 ax = data[data.name == "北京市"].representative_point().plot(ax=ax, facecolor='red', marker='*', markersize=150) # 强调港澳台 # 设置字体 fontdict = {'family': 'SimHei', 'size': 8, 'color': "blue", 'weight': 'bold'} # 字体属性,包括字体家族、大小、颜色和加粗 # 遍历港澳台的数据,绘制标签和中心点 for index in data[data.adcode.isin(['710000', '810000', '820000'])].index: if data.iloc[index]['name'] == "台湾省": x = data.iloc[index].geometry.centroid.x # 获取台湾省的几何中心的 x 坐标 y = data.iloc[index].geometry.centroid.y # 获取台湾省的几何中心的 y 坐标 name = "台湾省" # 设置标签名称 ax.text(x, y, name, ha="center", va="center", fontdict=fontdict) # 在地图上绘制标签,设置水平和垂直对齐方式为中心 elif data.iloc[index]['name'] == "香港特别行政区": x = data.iloc[index].geometry.centroid.x # 获取香港特别行政区的几何中心的 x 坐标 y = data.iloc[index].geometry.centroid.y # 获取香港特别行政区的几何中心的 y 坐标 name = "香港" # 设置标签名称 ax.text(x, y, name, ha="left", va="top", fontdict=fontdict) # 在地图上绘制标签,设置水平对齐方式为左,垂直对齐方式为顶部 gpd.GeoSeries(data.iloc[index].geometry.centroid).plot(ax=ax, facecolor='black', markersize=5) # 绘制几何中心点,设置颜色为黑色,大小为 5 elif data.iloc[index]['name'] == "澳门特别行政区": x = data.iloc[index].geometry.centroid.x # 获取澳门特别行政区的几何中心的 x 坐标 y = data.iloc[index].geometry.centroid.y # 获取澳门特别行政区的几何中心的 y 坐标 name = "澳门" # 设置标签名称 ax.text(x, y, name, ha="right", va="top", fontdict=fontdict) # 在地图上绘制标签,设置水平对齐方式为右,垂直对齐方式为顶部 gpd.GeoSeries(data.iloc[index].geometry.centroid).plot(ax=ax, facecolor='black', markersize=5) # 绘制几何中心点,设置颜色为黑色,大小为 5 # 移除坐标轴 ax.axis('off') # 移除图形的坐标轴 # 保存结果 fig.savefig('res.png', dpi=300, bbox_inches='tight') # 将绘制结果保存为名为 'res.png' 的文件,分辨率为 300 DPI,紧密布局
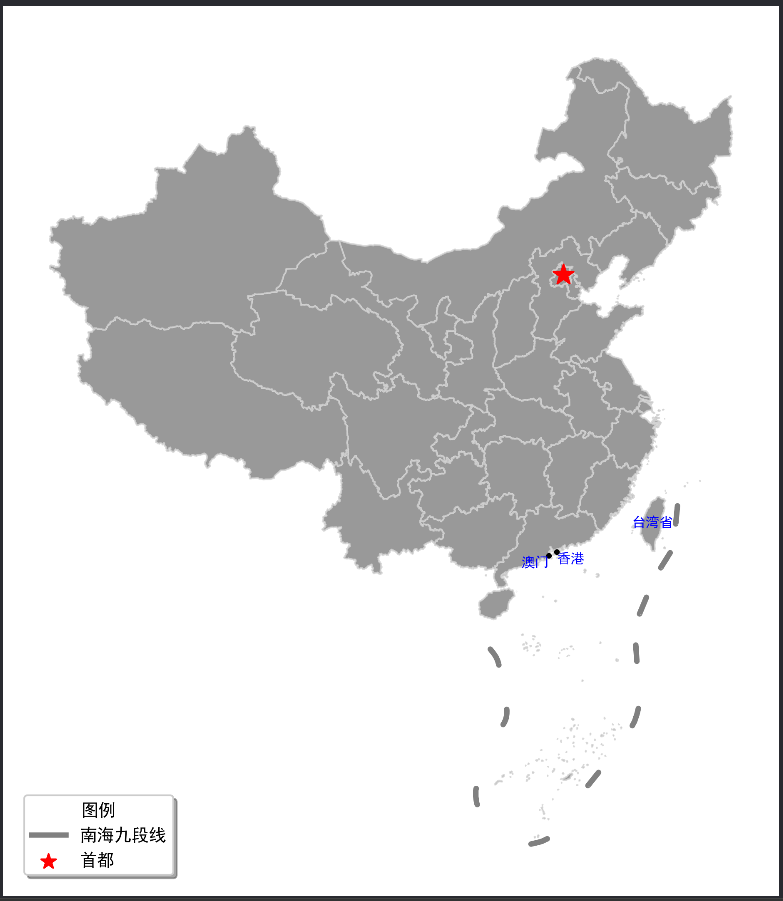
1.2.4.图例设置
这里采用单独绘制图例的方式来创建图例,需要对matplotlib使用有一定的了解。
import geopandas as gpd # 导入 GeoPandas 库,用于处理地理数据 import matplotlib.pyplot as plt # 导入 Matplotlib 库,用于绘制图形 # 读取中国地图数据,数据来自 DataV.GeoAtlas,将其投影到 EPSG:4573 data = gpd.read_file('https://geo.datav.aliyun.com/areas_v3/bound/100000_full.json').to_crs('EPSG:4573') print(data.shape) # 打印数据的形状,查看数据行数和列数 # 查看最后五条数据 print(data.tail()) # 打印数据的最后五行,包含南海九段线数据 # 拆分数据 nine_dotted_line = data.iloc[-1] # 取出南海九段线的数据 data = data[:-1] # 去除最后一条南海九段线的数据,保留其他数据 print(nine_dotted_line) # 打印南海九段线的数据 # 创建画布 fig, ax = plt.subplots(figsize=(12, 9)) # 创建一个包含一个轴的图形对象和轴对象,设置图形大小为 12 x 9 英寸 # 绘制主要区域 # plot:在轴上绘制主要区域(中国各省级行政区) # facecolor:设置区域填充颜色为灰色 # edgecolor:设置边框颜色为浅灰色 # alpha:设置透明度为 0.8 # linewidth:设置边框线宽为 1 ax = data.plot(ax=ax, facecolor='grey', edgecolor='lightgrey', alpha=0.8, linewidth=1) # 绘制九段线 # GeoSeries:将南海九段线的数据转换为 GeoSeries 对象 # plot:在轴上绘制南海九段线 # edgecolor:设置边框颜色为灰色 # linewidth:设置线宽为 3 ax = gpd.GeoSeries(nine_dotted_line.geometry).plot(ax=ax, edgecolor='grey', linewidth=3) # 强调首都 # 选择北京市的数据并绘制代表点 # representative_point:获取北京市的代表点(通常为几何中心) # plot:在轴上绘制代表点 # facecolor:设置点的颜色为红色 # marker:设置点的形状为星形('*') # markersize:设置点的大小为 150 ax = data[data.name == "北京市"].representative_point().plot(ax=ax, facecolor='red', marker='*', markersize=150) # 强调港澳台 # 设置字体 fontdict = {'family': 'SimHei', 'size': 8, 'color': "blue", 'weight': 'bold'} # 字体属性,包括字体家族、大小、颜色和加粗 # 遍历港澳台的数据,绘制标签和中心点 for index in data[data.adcode.isin(['710000', '810000', '820000'])].index: if data.iloc[index]['name'] == "台湾省": x = data.iloc[index].geometry.centroid.x # 获取台湾省的几何中心的 x 坐标 y = data.iloc[index].geometry.centroid.y # 获取台湾省的几何中心的 y 坐标 name = "台湾省" # 设置标签名称 ax.text(x, y, name, ha="center", va="center", fontdict=fontdict) # 在地图上绘制标签,设置水平和垂直对齐方式为中心 elif data.iloc[index]['name'] == "香港特别行政区": x = data.iloc[index].geometry.centroid.x # 获取香港特别行政区的几何中心的 x 坐标 y = data.iloc[index].geometry.centroid.y # 获取香港特别行政区的几何中心的 y 坐标 name = "香港" # 设置标签名称 ax.text(x, y, name, ha="left", va="top", fontdict=fontdict) # 在地图上绘制标签,设置水平对齐方式为左,垂直对齐方式为顶部 gpd.GeoSeries(data.iloc[index].geometry.centroid).plot(ax=ax, facecolor='black', markersize=5) # 绘制几何中心点,设置颜色为黑色,大小为 5 elif data.iloc[index]['name'] == "澳门特别行政区": x = data.iloc[index].geometry.centroid.x # 获取澳门特别行政区的几何中心的 x 坐标 y = data.iloc[index].geometry.centroid.y # 获取澳门特别行政区的几何中心的 y 坐标 name = "澳门" # 设置标签名称 ax.text(x, y, name, ha="right", va="top", fontdict=fontdict) # 在地图上绘制标签,设置水平对齐方式为右,垂直对齐方式为顶部 gpd.GeoSeries(data.iloc[index].geometry.centroid).plot(ax=ax, facecolor='black', markersize=5) # 绘制几何中心点,设置颜色为黑色,大小为 5 # 移除坐标轴 ax.axis('off') # 移除图形的坐标轴 # 单独绘制图例 plt.rcParams["font.family"] = 'SimHei' # 设置全局字体家族为 'SimHei'(黑体) # 绘制图例标识 ax.scatter([], [], c='red', s=80, marker='*', label='首都') # 绘制首都的图例标识,红色星形,大小为 80 ax.plot([], [], c='grey', linewidth=3, label='南海九段线') # 绘制南海九段线的图例标识,灰色线,线宽为 3 # 设置图例顺序 handles, labels = ax.get_legend_handles_labels() # 获取当前图例的句柄和标签 ax.legend(handles[::-1], labels[::-1], title="图例", frameon=True, shadow=True, loc="lower left", fontsize=10) # 绘制图例,设置图例标题为 "图例",带边框和阴影,位置在左下角,字体大小为 10 # 保存结果 fig.savefig('res.png', dpi=300, bbox_inches='tight') # 将绘制结果保存为名为 'res.png' 的文件,分辨率为 300 DPI,紧密布局
说明
ax.scatter 用于绘制散点图,即一组离散的点。它常用于表示二维数据点,尤其是当你希望对每个点进行个性化设置时,如颜色、大小和形状等。常见参数:
x, y:点的横坐标和纵坐标。c:点的颜色。s:点的大小。marker:点的形状。label:图例标签。
示例用法:这行代码将绘制三颗红色星形的点,大小为 80。
ax.scatter(x=[1, 2, 3], y=[4, 5, 6], c='red', s=80, marker='*', label='Example Points')
ax.plot 用于绘制线图,但它也可以用于绘制单个数据点。一般用于连接一系列点形成的线条或绘制单个点。常见参数:
x, y:点的横坐标和纵坐标。color(或c):线条或点的颜色。linewidth(或lw):线条的宽度。label:图例标签。marker:点的形状(用于绘制单个点时)。
示例用法:这行代码将绘制一条灰色的线,宽度为 3,连接点 (1,4)、(2,5) 和 (3,6)。
ax.plot([1, 2, 3], [4, 5, 6], color='grey', linewidth=3, label='Example Line')
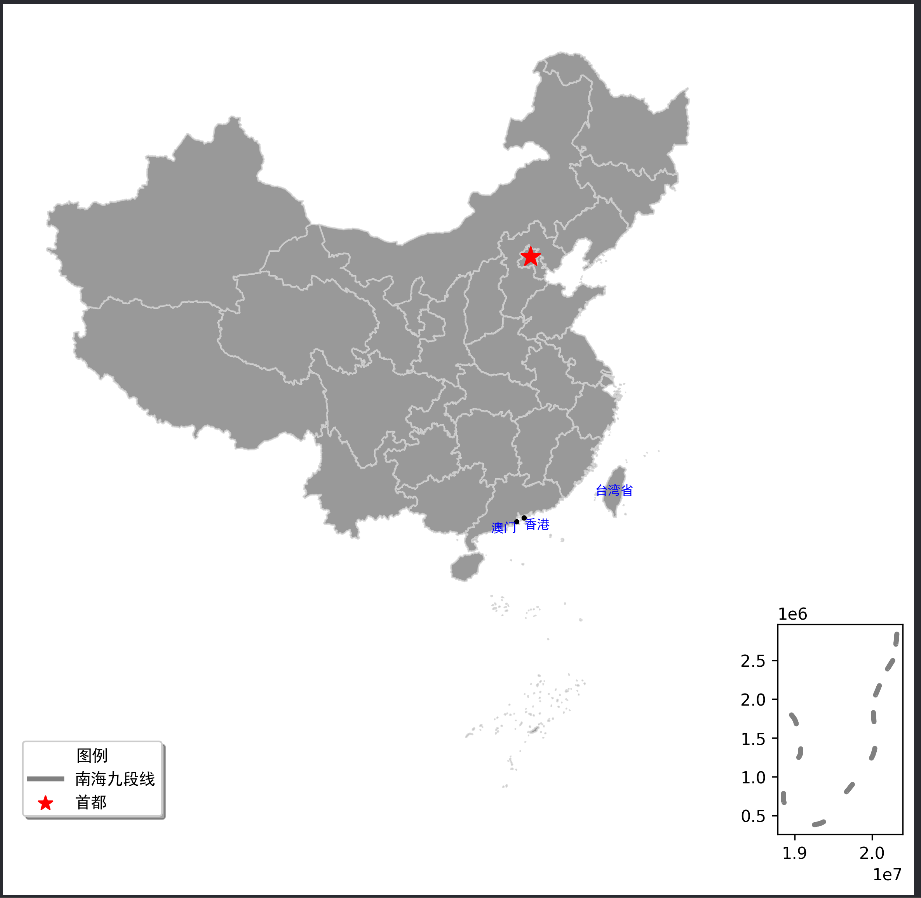
1.2.5.小地图绘制
在很多中国地图中,南海诸岛区域都是在右下角的小地图单独绘制。在GeoPandas中想要实现这一功能,可以通过matplotlib的add_axes函数实现。add_axes主要功能为为新增绘图子区域,该区域可以位于画布中任意区域,且可设置任意大小。add_axes输入参数为(left, bottom, width, height),left, bottom表示相对画布的比例坐标,width和height表示相对画布的比例长宽。
在中国地图的右下角添加一个南海诸岛的小地图,可以使用 matplotlib 的 add_axes 函数。在这个小地图中,单独绘制南海诸岛,并将其放置在主地图的右下角。以下是一个详细的示例,展示如何实现这一功能:
import geopandas as gpd import matplotlib.pyplot as plt # 读取中国地图数据,数据来自 DataV.GeoAtlas,将其投影到 EPSG:4573 data = gpd.read_file('https://geo.datav.aliyun.com/areas_v3/bound/100000_full.json').to_crs('EPSG:4573') # 拆分数据,将九段线单独提取出来 nine_dotted_line = data.iloc[-1] # 最后一行是南海九段线 data = data[:-1] # 除去最后一行,其余的是省级行政区 # 创建画布,设置尺寸为12x9英寸 fig, ax = plt.subplots(figsize=(12, 9)) # 绘制主要区域 data.plot(ax=ax, facecolor='grey', edgecolor='lightgrey', alpha=0.8, linewidth=1) # 强调首都北京市 data[data.name == "北京市"].representative_point().plot(ax=ax, facecolor='red', marker='*', markersize=150) # 强调港澳台,设置字体样式 fontdict = {'family': 'SimHei', 'size': 8, 'color': "blue", 'weight': 'bold'} for index in data[data.adcode.isin(['710000', '810000', '820000'])].index: # 标注台湾省 if data.iloc[index]['name'] == "台湾省": x = data.iloc[index].geometry.centroid.x y = data.iloc[index].geometry.centroid.y name = "台湾省" ax.text(x, y, name, ha="center", va="center", fontdict=fontdict) # 标注香港特别行政区 elif data.iloc[index]['name'] == "香港特别行政区": x = data.iloc[index].geometry.centroid.x y = data.iloc[index].geometry.centroid.y name = "香港" ax.text(x, y, name, ha="left", va="top", fontdict=fontdict) gpd.GeoSeries(data.iloc[index].geometry.centroid).plot(ax=ax, facecolor='black', markersize=5) # 标注澳门特别行政区 elif data.iloc[index]['name'] == "澳门特别行政区": x = data.iloc[index].geometry.centroid.x y = data.iloc[index].geometry.centroid.y name = "澳门" ax.text(x, y, name, ha="right", va="top", fontdict=fontdict) gpd.GeoSeries(data.iloc[index].geometry.centroid).plot(ax=ax, facecolor='black', markersize=5) # 移除坐标轴 ax.axis('off') # 添加南海诸岛子图区域 ax_inset = fig.add_axes([0.75, 0.1, 0.2, 0.2]) # 参数为(left, bottom, width, height),相对画布的比例坐标 gpd.GeoSeries(nine_dotted_line.geometry).plot(ax=ax_inset, edgecolor='grey', linewidth=3) # 单独绘制图例 plt.rcParams["font.family"] = 'SimHei' # 全局设置字体为SimHei(黑体) ax.scatter([], [], c='red', s=80, marker='*', label='首都') # 图例标识,红色星形,大小为80 ax.plot([], [], c='grey', linewidth=3, label='南海九段线') # 图例标识,灰色线,线宽为3 handles, labels = ax.get_legend_handles_labels() # 获取图例句柄和标签 ax.legend(handles[::-1], labels[::-1], title="图例", frameon=True, shadow=True, loc="lower left", fontsize=10) # 保存结果到文件,dpi=300表示高分辨率,bbox_inches='tight'表示紧凑的边界框 fig.savefig('res.png', dpi=300, bbox_inches='tight')
二、分层设色
2.1.分层设色基本介绍
准备csv数据如下:
排行,地级市,2022年GDP(亿元)
1,苏州市,23958.3
2,南京市,16907.9
3,无锡市,14850.8
4,南通市,11379.6
5,常州市,9550.1
6,徐州市,8457.8
7,盐城市,7079.8
8,扬州市,6696.4
9,泰州市,6401.8
10,镇江市,5017.0
11,淮安市,4742.4
12,宿迁市,4112.0
13,连云港市,4005.0
如下代码所示,绘制江苏省地级市GDP地图。
import geopandas as gpd import matplotlib.pyplot as plt import pandas as pd # 设置全局字体为SimHei(黑体) plt.rcParams["font.family"] = 'SimHei' # 读取GDP数据,数据来自互联网 gdp = pd.read_csv("2022江苏省各市GDP.csv") # 读取江苏地图数据,数据来自DataV.GeoAtlas,将其投影到EPSG:4573 data = gpd.read_file('https://geo.datav.aliyun.com/areas_v3/bound/320000_full.json').to_crs('EPSG:4573') # 合并地图数据和GDP数据 data = data.join(gdp.set_index('地级市')["2022年GDP(亿元)"], on='name') # 修改列名,将'2022年GDP(亿元)'改为'GDP' data.rename(columns={'2022年GDP(亿元)': 'GDP'}, inplace=True) # 创建画布,设置尺寸为9x9英寸 fig, ax = plt.subplots(figsize=(9, 9)) # 绘制地图,根据'GDP'列着色,使用coolwarm颜色映射,显示图例 # legend_kwds设置matplotlib的legend参数,如标签和缩放比例 data.plot(ax=ax, column='GDP', cmap='coolwarm', legend=True, legend_kwds={'label': "GDP(亿元)", 'shrink': 0.5}) # 移除坐标轴 ax.axis('off') # 设置字体样式 fontdict = {'family': 'SimHei', 'size': 8, 'color': "black", 'weight': 'bold'} # 设置标题 ax.set_title('江苏省地级市2022年GDP数据可视化', fontsize=24) # 为每个地级市添加名称标签 for index in data.index: x = data.iloc[index].geometry.centroid.x y = data.iloc[index].geometry.centroid.y name = data.iloc[index]["name"] # 调整苏州市和无锡市的标签位置 if name in ["苏州市", "无锡市"]: x = x * 1.001 ax.text(x, y, name, ha="center", va="center", fontdict=fontdict) # 保存图片,dpi=300表示高分辨率,bbox_inches='tight'表示紧凑的边界框 fig.savefig('res.png', dpi=300, bbox_inches='tight')
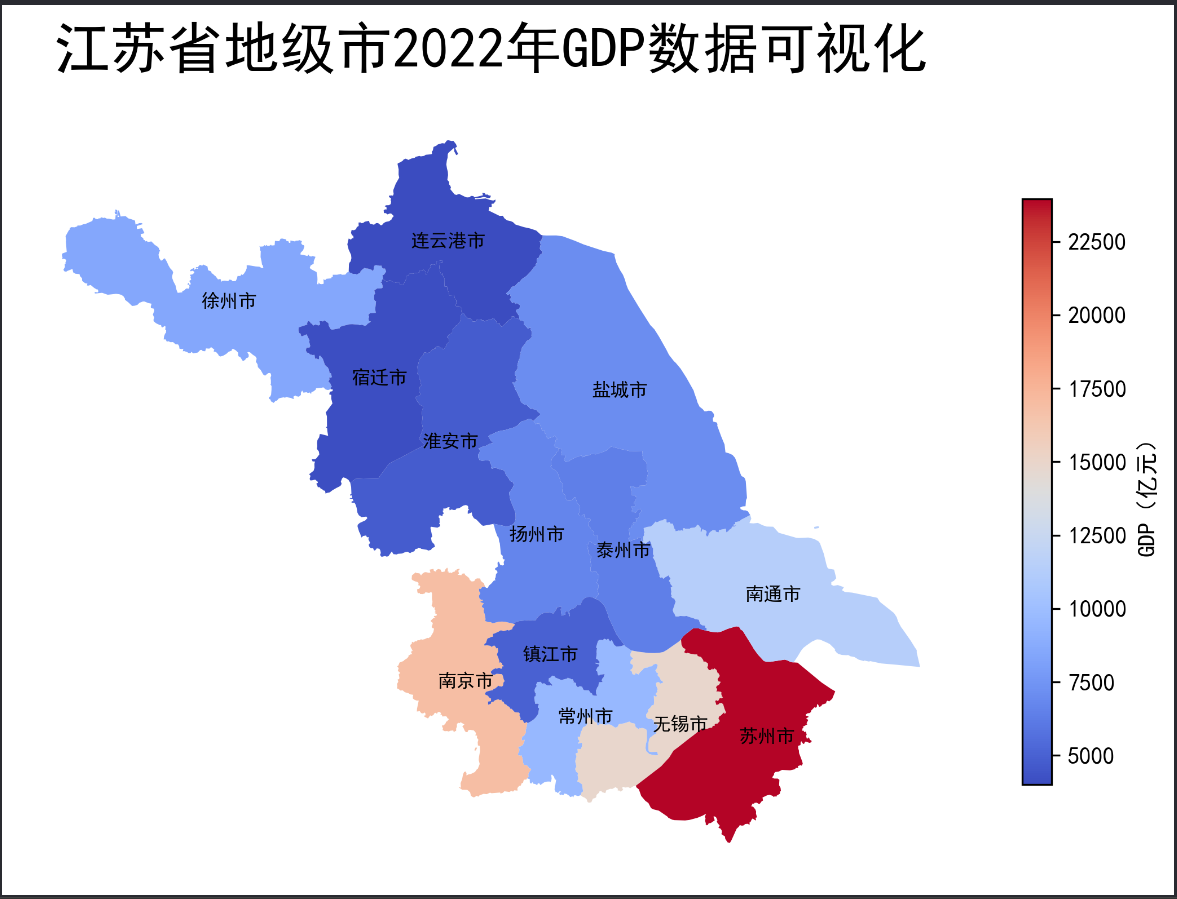
可以看到在上述地图中,由于苏州市的数值太大,其他数据被压缩到浅色区域,无法有效展示数据分布。需要使用地图分层设色来更好地展示数据。地图分层设色是一种常见的地图可视化方式,它可以将地图上的数据按照不同的分类进行分层,并对每一层数据进行不同的颜色设定,以便更加直观地展现地理空间数据的分布情况和特征。在本文通过Python模块mapclassify用于分层设色和数据可视化。使用mapclassify之前需要输入以下命令安装相关模块:
pip install mapclassify
mapclassify官方仓库见:mapclassify。mapclassify提供了多种分组方法,可以帮助我们更好地理解数据的分布情况,mapclassify提供的方法包括:
BoxPlot: 基于箱线图的分类方法。这种分类方法适用于数据分布比较规律的情况。EqualInterval: 等距离分类方法。这种分类方法将数据划分为等距离的若干区间。适用于数据分布比较均匀的情况。FisherJenks: 基于Fisher-Jenks算法的分类方法。这种分类方法将数据划分为若干区间,使得每个区间内部的差异最小,不同区间之间的差异最大。适用于数据分布比较不规律的情况。HeadTailBreaks: 基于Head-Tail算法的分类方法。这种分类方法将给定的数据集分为两部分:头部和尾部。头部通常包含出现频率最高的值,而尾部包含出现频率较低的值。适用于识别数据集中的异常值和离群值。JenksCaspall: 基于Jenks-Caspall算法的分类方法。这种分类方法根据数据中发现的自然分组将数据集划分为类。适用于需要将数据分类为几个具有明显含义的区间的情况。JenksCaspallForced: 强制基于Jenks-Caspall算法的分类方法。与JenksCaspall算法类似,但是它对区间的数量和大小有更强的控制力。适用于需要精确控制区间数量和大小的情况。JenksCaspallSampled: 采样基于Jenks-Caspall算法的分类方法。该方法对数据进行采样,然后使用Jenks-Caspall算法对采样后的数据进行分类,适用于数据量比较大的情况。MaxP: 基于最大界限的分类方法。这种分类方法将数据划分为几个区间,使得不同区间之间的差异最大。适用于需要将数据分类为几个具有明显差异的区间的情况。MaximumBreaks: 基于最大间隔的分类方法。这种分类方法与MaxP算法类似,但是它更加注重区间的可理解性。适用于需要将数据分类为几个具有明显含义的区间的情况。NaturalBreaks: 基于自然间隔的分类方法。这种分类方法将数据划分为几个区间,使得每个区间内部的差异最小,不同区间之间的差异最大。适用于数据分布比较不规律的情况Quantiles: 基于分位数的分类方法。Percentiles: 基于百分位数的分类方法。StdMean: 基于标准差分组的分类方法。UserDefined: 基于自定义分组的分类方法。
2.2.绘图实例之用于地图的分层设色
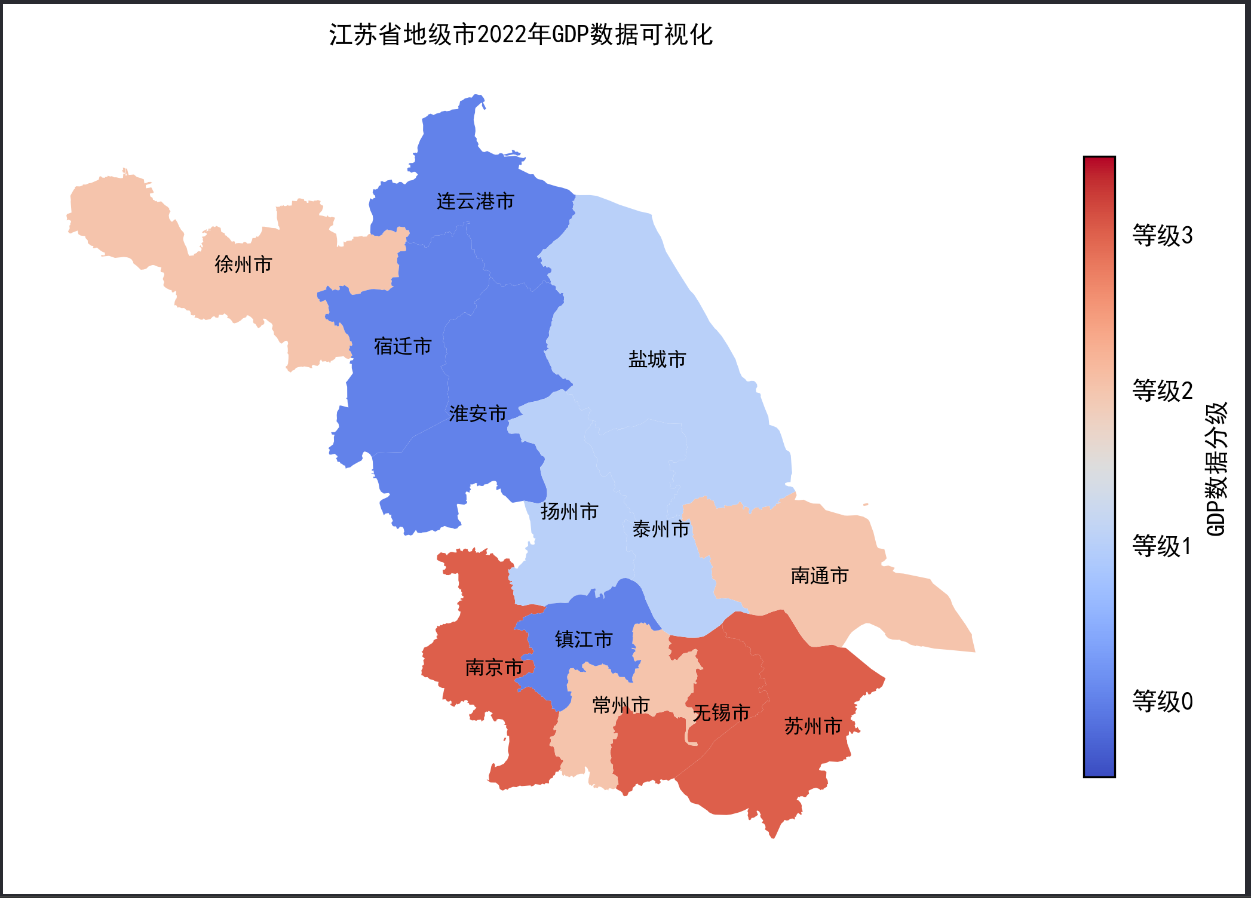
方法1:GeoPandas中分层设色可以通过plot函数中的scheme参数和k参数设置数据分层方式和分层类别数。如下所示,通过JenksCaspall将GDP数据分为4级,可以直观看到GDP数据在第一梯队的城市有哪些。
import geopandas as gpd # 导入geopandas库,用于地理空间数据处理 import matplotlib.pyplot as plt # 导入matplotlib.pyplot库,用于绘图 import pandas as pd # 导入pandas库,用于数据处理 plt.rcParams["font.family"] = 'SimHei' # 设置matplotlib全局字体为SimHei(黑体) # 从互联网读取2022年江苏省各市GDP数据 gdp = pd.read_csv("2022江苏省各市GDP.csv") # 读取江苏地图数据,并将其投影到EPSG:4573坐标系 data = gpd.read_file('https://geo.datav.aliyun.com/areas_v3/bound/320000_full.json').to_crs('EPSG:4573') # 将GDP数据与地图数据按地级市名称合并 data = data.join(gdp.set_index('地级市')["2022年GDP(亿元)"], on='name') # 修改列名为简单的'GDP' data.rename(columns={'2022年GDP(亿元)': 'GDP'}, inplace=True) # 创建一个9x9英寸大小的画布 fig, ax = plt.subplots(figsize=(9, 9)) # 使用Jenks-Caspall方法对GDP数据进行分层设色,并显示图例 data.plot(ax=ax, # 指定绘图的Axes对象为ax column='GDP', # 使用'GDP'列的数据进行分层设色 cmap='coolwarm', # 设置颜色映射为'coolwarm' legend=True, # 显示图例 scheme='JenksCaspall', # 使用Jenks-Caspall方法进行分层 k=4, # 将数据分为4个级别 legend_kwds={'loc': 'lower left', 'title': 'GDP数据分级(亿元)'} # 设置图例的位置和标题 ) # 移除坐标轴 ax.axis('off') # 设置字体样式 fontdict = {'family': 'SimHei', 'size': 8, 'color': "black", 'weight': 'bold'} # 设置标题 ax.set_title('江苏省地级市2022年GDP数据可视化', fontsize=24) # 在地图上的每个地级市中心点添加名称标签 for index in data.index: x = data.iloc[index].geometry.centroid.x # 获取地级市的几何中心点的x坐标 y = data.iloc[index].geometry.centroid.y # 获取地级市的几何中心点的y坐标 name = data.iloc[index]["name"] # 获取地级市的名称 if name in ["苏州市", "无锡市"]: # 对苏州市和无锡市进行位置微调,避免标签重叠 x = x * 1.001 ax.text(x, y, name, ha="center", va="center", fontdict=fontdict) # 在指定位置添加地级市名称标签 # 保存图像 fig.savefig('res.png', dpi=300, bbox_inches='tight')

方法2:在GeoPandas中也可以通过mapclassify直接处理数据,生成新的数据列进行展示。通过该种方式可以看到,苏州和南京的GDP领先于其他地级市。
import geopandas as gpd # 导入geopandas库,用于地理空间数据处理 import matplotlib.pyplot as plt # 导入matplotlib.pyplot库,用于绘图 import pandas as pd # 导入pandas库,用于数据处理 import mapclassify # 导入mapclassify库,用于分级 from matplotlib.font_manager import FontProperties # 从matplotlib.font_manager导入FontProperties,用于字体管理 # 从本地CSV文件读取2022年江苏省各市GDP数据 gdp = pd.read_csv("2022江苏省各市GDP.csv") # 从DataV.GeoAtlas获取江苏省地图数据,并将其投影到EPSG:4573坐标系 data = gpd.read_file('https://geo.datav.aliyun.com/areas_v3/bound/320000_full.json').to_crs('EPSG:4573') # 将GDP数据与地图数据按地级市名称合并 data = data.join(gdp.set_index('地级市')["2022年GDP(亿元)"], on='name') # 修改列名为简单的'GDP' data.rename(columns={'2022年GDP(亿元)': 'GDP'}, inplace=True) # 使用mapclassify对GDP数据进行分级,分为4级 data['GDP_class'] = mapclassify.JenksCaspall(data['GDP'], k=4).yb # 设置字体属性 font_path = 'C:/Windows/Fonts/simhei.ttf' # 指定字体路径为SimHei黑体字体 font_prop = FontProperties(fname=font_path) # 创建字体属性对象 # 全局设置字体 plt.rcParams['font.sans-serif'] = ['SimHei'] # 用于正常显示中文标签 plt.rcParams['axes.unicode_minus'] = False # 用于正常显示负号 # 创建一个9x9英寸大小的画布和轴对象 fig, ax = plt.subplots(figsize=(9, 9)) # 设置分层颜色条,使用coolwarm颜色映射 cmap = plt.colormaps.get_cmap('coolwarm') # vmax和vmin设置是为了让等级值居中 data.plot(ax=ax, column='GDP_class', cmap=cmap, legend=False, vmin=-0.5, vmax=3.5) ax.axis('off') # 关闭坐标轴 # 设置Colorbar的刻度 cbar = ax.get_figure().colorbar(ax.collections[0], shrink=0.5) # 添加颜色条,设置颜色条缩小比例 cbar.set_ticks([0, 1, 2, 3]) # 设置颜色条的刻度 cbar.set_label('GDP数据分级', fontproperties=font_prop) # 设置颜色条的标签 cbar.set_ticklabels(['等级0', '等级1', '等级2', '等级3']) # 设置颜色条的刻度标签 # 隐藏颜色条的刻度线 ticks = cbar.ax.get_yaxis().get_major_ticks() for tick in ticks: tick.tick1line.set_visible(False) tick.tick2line.set_visible(False) # 设置字体样式 fontdict = {'family': 'SimHei', 'size': 8, 'color': "black", 'weight': 'bold'} # 设置标题 ax.set_title('江苏省地级市2022年GDP数据可视化', fontsize=24, fontproperties=font_prop) # 在地图上的每个地级市中心点添加名称标签 for index in data.index: x = data.iloc[index].geometry.centroid.x # 获取地级市几何中心点的x坐标 y = data.iloc[index].geometry.centroid.y # 获取地级市几何中心点的y坐标 name = data.iloc[index]["name"] # 获取地级市的名称 if name in ["苏州市", "无锡市"]: x = x * 1.001 # 对苏州市和无锡市进行位置微调,避免标签重叠 ax.text(x, y, name, ha="center", va="center", fontdict=fontdict, fontproperties=font_prop) # 在指定位置添加地级市名称标签 # 保存图像,dpi设置为300以保证图像质量,bbox_inches='tight'去除多余空白 fig.savefig('res.png', dpi=300, bbox_inches='tight')
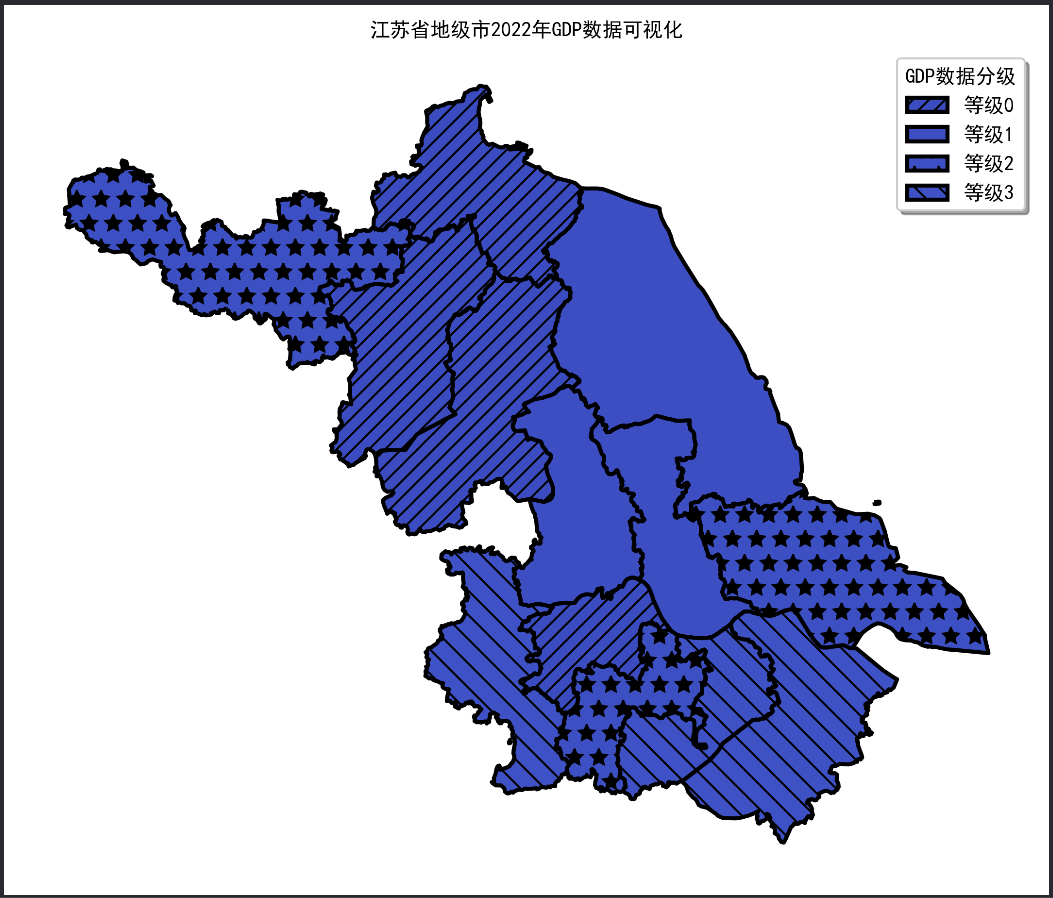
方法3:分层设色不仅可以设置各区域的颜色,也可以设置各区域的填充图案
# 创建分类器 classifier = mapclassify.MaximumBreaks(data['GDP'], k=3) classifier
完整案例:
import geopandas as gpd # 导入geopandas库,用于地理空间数据处理 import matplotlib.pyplot as plt # 导入matplotlib.pyplot库,用于绘图 import pandas as pd # 导入pandas库,用于数据处理 import mapclassify # 导入mapclassify库,用于数据分级 from matplotlib.font_manager import FontProperties # 从matplotlib.font_manager导入FontProperties,用于字体管理 import matplotlib.patches as mpatches # 导入matplotlib.patches库,用于创建自定义图示 # 从本地CSV文件读取2022年江苏省各市GDP数据 gdp = pd.read_csv("2022江苏省各市GDP.csv") # 读取CSV文件中的数据,并存储到gdp变量中 # 从DataV.GeoAtlas获取江苏省地图数据,并将其投影到EPSG:4573坐标系 data = gpd.read_file('https://geo.datav.aliyun.com/areas_v3/bound/320000_full.json').to_crs('EPSG:4573') # 从指定URL读取GeoJSON文件,获取江苏省地图数据,并转换其坐标系为EPSG:4573 # 将GDP数据与地图数据按地级市名称合并 data = data.join(gdp.set_index('地级市')["2022年GDP(亿元)"], on='name') # 将GDP数据与地图数据按地级市名称(name列)进行合并,结果存储在data变量中 # 修改列名为简单的'GDP' data.rename(columns={'2022年GDP(亿元)': 'GDP'}, inplace=True) # 重命名列名为'GDP',以便于后续处理,inplace=True表示在原数据上进行修改 # 使用mapclassify对GDP数据进行分级,分为4级 data['GDP_class'] = mapclassify.JenksCaspall(data['GDP'], k=4).yb # 使用自然断点法对GDP数据进行分级,分为4级,结果存储在新列'GDP_class'中 # 设置字体属性 font_path = 'C:/Windows/Fonts/simhei.ttf' # 指定字体路径为SimHei黑体字体 font_prop = FontProperties(fname=font_path) # 创建字体属性对象,指定字体文件路径 # 全局设置字体 plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置全局字体为SimHei,以便正常显示中文标签 plt.rcParams['axes.unicode_minus'] = False # 设置全局参数,用于正常显示负号 # 创建一个9x9英寸大小的画布和轴对象 fig, ax = plt.subplots(figsize=(9, 9)) # 创建一个9x9英寸的画布(Figure)和轴对象(Axes) # 设置图案列表,每个图案对应一个不同的GDP分级 patterns = ["///", "", "*", "\\\\", ".", "o", "O", ] # 定义填充图案列表,每个图案对应不同的GDP分级 # 使用新的获取colormap方法,并根据不同的GDP分级数量设置颜色 cmap = plt.colormaps['coolwarm'] # 获取颜色映射表'coolwarm' color_list = cmap(range(len(set(data['GDP_class'])))) # 根据不同的GDP分级数量设置颜色列表 # 自定义图示 legend_list = [] # 创建一个空列表,用于存储自定义图示 # 按层次设置legend for i in set(data['GDP_class']): # 遍历所有的GDP分级 tmp = data[data['GDP_class'] == i] # 筛选出当前分级的所有数据 # 绘制每个分级的图形,设置填充图案、边框颜色、填充颜色、线型和线宽 tmp.plot(ax=ax, legend=False, hatch=patterns[i], edgecolor='black', facecolor=color_list[i], linestyle='-', linewidth=2) # 创建自定义图示,添加到legend_list legend_list.append( mpatches.Patch(facecolor=color_list[i], edgecolor='black', linestyle='-', linewidth=2, hatch=patterns[i], label='等级{}'.format(i)) ) # 创建一个补丁对象(Patch),用于自定义图示,并添加到legend_list中 ax.axis('off') # 关闭坐标轴显示 # 设置标题 ax.set_title('江苏省地级市2022年GDP数据可视化', fontsize=24, fontproperties=font_prop) # 设置图表标题,并指定字体属性和字体大小 # 自定义图示 ax.legend(handles=legend_list, loc='best', fontsize=12, title='GDP数据分级', shadow=True, prop=font_prop) # 添加自定义图示,设置位置、字体大小、标题和阴影效果 # 保存图片,dpi设置为300以保证图像质量,bbox_inches='tight'去除多余空白 fig.savefig('res.png', dpi=300, bbox_inches='tight') # 保存生成的图像,指定分辨率为300 dpi,去除多余的边距

 浙公网安备 33010602011771号
浙公网安备 33010602011771号