Numpy模块详解
一、NumPy是什么?有什么作用?
NumPy 是一个功能强大的 Python 库,主要用于对多维数组执行计算。 NumPy 这个词来源于两个单词-- Numerical 和 Python 。 NumPy 提供了大量的库函数和操作,可以帮助程序员轻松地进行数值计算。在数据分析和机器学习领域被广泛使用。它有以下几个特点:
- numpy内置了并行运算功能,当系统有多个核心时,做某种计算时,numpy会自动做并行计算。
- Numpy底层使用C语言编写,内部解除了GIL(全局解释器锁),其对数组的操作速度不受Python解释器的限制,效率远高于纯Python代码。
- 有一个强大的N维数组对象Array(一种类似于列表的东西)。
- 实用的线性代数、傅里叶变换和随机数生成函数。
NumPy中文文档: https://www.numpy.org.cn/user/ ,安装如下:
pip install numpy
Numpy 中的数组的使用跟 Python 中的列表非常类似。他们之间的区别如下:
- 一个列表中可以存储多种数据类型。比如 a = [1,‘sss’] 是允许的,而数组只能存储同种数据类型。
- 数组可以是多维的,当多维数组中所有的数据都是数值类型的时候,相当于线性代数中的矩阵,是可以进行相互间的运算的。
二、数组的创建
Numpy 经常和数组打交道,因此首先第一步是要学会创建数组。在 Numpy 中的数组的数据类型叫做 ndarray 。数组中的数据类型都是一致的,要么都是整形,要么都是浮点类型,要么都是字符串类型,不能同时出现多种数据类型。
2.1. 列表生成
import numpy as np a1 = np.array([1, 2, 3, 4]) print(a1) #[1 2 3 4] print(type(a1)) # <class 'numpy.ndarray'> print(a1[3]) # 4
2.2.使用 np.arange 生成
np.arange 的用法类似于 Python 中的 range :
# 生成数组,从2-21之间取值,间隔2取一个值 a2 = np.arange(2, 21, 2) print(a2)
2.3. np.random.random来创建一个N行N列的数组
其中里面的值是0-1之间的随机数
# 生成2行3列的随机数的数组 a3 = np.random.random((2,3)) ''' [[0.15360416 0.19531969 0.65597595] [0.72591998 0.62490847 0.09755287]] ''' print(a3)
2.4.np.random.randint来创建一个N行N列的数组
其中值的范围可以通过前面2个参数来指定
# 创建随机整数数组, 1到10之间获取数字,生成3个数组,每个里面4个数字 random_int_array = np.random.randint(1, 10, (3, 4)) print(random_int_array) ''' [[7 3 9 5] [5 9 8 2] [3 9 7 7]] '''
2.5.使用函数生成特殊的数组
- zeros
# 生成一个所有元素都是0的 3行4列的数组 array_zeros = np.zeros((3, 4)) print(array_zeros) ''' [[0. 0. 0. 0.] [0. 0. 0. 0.] [0. 0. 0. 0.]] '''
- ones
# 生成一个所有元素都是1的 3行5列的数组 array_ones = np.ones((3, 5)) ''' [[1. 1. 1. 1. 1.] [1. 1. 1. 1. 1.] [1. 1. 1. 1. 1.]] '''
- full
# 生成一个所有元素都是9的 2行3列的数组 array_full = np.full((2,3),9) print(array_full)
- eye
# 生成一个在斜方形上元素为1,其他元素都为0的4x4的矩阵 array_eye = np.eye(4) ''' [[1. 0. 0. 0.] [0. 1. 0. 0.] [0. 0. 1. 0.] [0. 0. 0. 1.]] '''
三、Numpy数组和Python列表性能对比
测试一下Numpy数组和Python列表性能,比如我们想要对一个Numpy数组和Python列表中的每个数进行求平方
import numpy as np import time # Python列表 t1 = time.time() nums = [] for i in range(1000000): nums.append(i**2) t2 = time.time() # 统计时间 print(t2-t1) # 0.11628222465515137 # numpy数组 t3 = time.time() b = np.arange(1000000)**2 t4 = time.time() print(t4-t3) # 0.011335372924804688
四、数组数据类型dtype
因为数组中只能存储同一种数据类型,因此可以通过 dtype 获取数组中的元素的数据类型。numpy 支持的数据类型比 Python 内置的类型要多很多,基本上可以和 C 语言的数据类型对应上,其中部分类型对应为 Python 内置的类型。下表列举了常用 NumPy 基本类型。
| 名称 | 描述 |
|---|---|
| bool_ | 布尔型数据类型(True 或者 False) |
| int_ | 默认的整数类型(类似于 C 语言中的 long,int32 或 int64) |
| intc | 与 C 的 int 类型一样,一般是 int32 或 int 64 |
| intp | 用于索引的整数类型(类似于 C 的 ssize_t,一般情况下仍然是 int32 或 int64) |
| int8 | 字节(-128 to 127) |
| int16 | 整数(-32768 to 32767) |
| int32 | 整数(-2147483648 to 2147483647) |
| int64 | 整数(-9223372036854775808 to 9223372036854775807) |
| uint8 | 无符号整数(0 to 255) |
| uint16 | 无符号整数(0 to 65535) |
| uint32 | 无符号整数(0 to 4294967295) |
| uint64 | 无符号整数(0 to 18446744073709551615) |
| float_ | float64 类型的简写 |
| float16 | 半精度浮点数,包括:1 个符号位,5 个指数位,10 个尾数位 |
| float32 | 单精度浮点数,包括:1 个符号位,8 个指数位,23 个尾数位 |
| float64 | 双精度浮点数,包括:1 个符号位,11 个指数位,52 个尾数位 |
| complex_ | complex128 类型的简写,即 128 位复数 |
| complex64 | 复数,表示双 32 位浮点数(实数部分和虚数部分) |
| complex128 | 复数,表示双 64 位浮点数(实数部分和虚数部分) |
numpy 的数值类型实际上是 dtype 对象的实例,并对应唯一的字符,包括 np.bool_,np.int32,np.float32,等等。
我们可以看到, Numpy 中关于数值的类型比 Python 内置的多得多,那为什么Numpy的数组中有这么多的数据类型呢?因为Numpy本身是基于C语言编写的,C语言中本身就是有很多数据类型,所以直接引用过来了。
Numpy为了考虑到处理海量数据的性能,针对不同的数据给不同的数据类型,来节省内存空间,所以有不同的数据类型。这是 Numpy 为了能高效处理处理海量数据而设计的。举个例子,比如现在想要存储上百亿的数字,并且这些数字都不超过254(一个字节内),我们就可以将 dtype 设置为 int8 ,这样就比默认使用 int64 更能节省内存空间了。类型相关的操作如下:
⑴.默认的数据类型:
import numpy as np a1 = np.array([1, 2, 3]) print(a1.dtype) #int32
注意:
- 如果是windows系统,默认是int32
- 如果是mac或者linux系统,则根据系统来
⑵.指定 dtype
import numpy as np a1 = np.array([1, 2, 3], dtype=np.int64) print(a1.dtype) # int64
⑶.修改 dtype
要在NumPy中修改数组的数据类型(dtype),可使用astype()方法。这个方法会返回一个新的数组,其中的元素类型被转换为指定的数据类型。下面是一个示例:
import numpy as np a1 = np.array([1, 2, 3]) print(a1.dtype) #window系统下默认是int32 # 以下修改dtype a2 = a1.astype(np.int64) # astype不会修改数组本身,而是会将修改后的结果返回 print(a2.dtype) # int64
五、多维数组的常用属性
5.1.ndarray.size
获取数组中总的元素的个数。如下有个二维数组:
import numpy as np a1 = np.array([[1, 2, 3], [4, 5, 6]]) print(a1.size) #因为总共有6个元素,输出值为6
5.2.ndarray.ndim
获取数组是几维数组。比如:
import numpy as np a1 = np.array([1, 2, 3]) print(a1.ndim) #维度为1 a2 = np.array([[1, 2, 3], [4, 5, 6]]) print(a2.ndim) #维度为2 a3 = np.array([[[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]]]) print(a3.ndim) #维度为3
5.3.ndarray.shape
ndarray.shape属性用于获取数组的形状信息,例如,对于一个二维数组,shape属性将是一个包含两个元素的元组,分别表示数组的行数和列数。比如以下代码:
import numpy as np a1 = np.array([1, 2, 3]) print(a1.shape) # 输出(3,),指的是一维数组,有三个数据 a2 = np.array([[4, 5, 6], [7, 8, 9]]) print(a2.shape) # 输出(2, 3),指的是二维数字,2行3列 a3 = np.array([[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]]) print(a3.shape) # 输出(2, 2, 3),指的是三维数组,共有2个元素,每个元素2列3行、 a4 = np.array([[1, 2, 3], [4, 5]]) print(a4.shape) # 会报错setting an array element with a sequence. The requested array has an inhomogeneous shape after 1 dimensions. The detected shape was (2,) + inhomogeneous part.
5.4.ndarray.reshape
ndarray.reshape() 是 NumPy 中用于改变数组维度的函数。它的作用是将数组重新调整为指定的维度数,而不改变其数据的内容。具体来说,它可以用于将数组变成一个新的形状,或者修改现有数组的维度。
在使用 reshape() 函数时,需要注意以下几点:
⑴.新形状的指定:通过向 reshape() 函数传递一个元组作为参数,元组中的每个元素表示数组在相应维度上的大小。
import numpy as np a1 = np.array([1, 2, 3, 4, 5, 6]) print(a1) reshaped_arr = a1.reshape((2, 3)) # 将一维数组变为2*3的二维数组 print(reshaped_arr)
输出
[1 2 3 4 5 6] [[1 2 3] [4 5 6]]
这里,原始的一维数组 a1被重新调整为一个 2 行 3 列的二维数组 reshaped_arr
⑵.总元素数量一致:在调整形状时,reshape() 函数要求新形状的总元素数量必须与原始数组的总元素数量一致。否则会抛出 ValueError 异常。
import numpy as np arr = np.array([1, 2, 3, 4, 5, 6]) try: reshaped_arr = arr.reshape((2, 4)) except ValueError as e: print(e)
输出:
cannot reshape array of size 6 into shape (2,4)
原因是尝试将包含 6 个元素的一维数组重新调整为一个包含 8 个元素的二维数组,这是不允许的。
⑶.特殊形状指定:可以使用 -1 作为一个特殊的参数值,表示由 NumPy 自动推断该维度的大小。这在需要根据另一些维度的大小来推断某一维度大小时非常有用。
import numpy as np arr = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]) reshaped_arr = arr.reshape((2, -1)) # NumPy会自动推断第二个维度的大小 print(reshaped_arr)
输出
[[ 1 2 3 4 5]
[ 6 7 8 9 10]]
这里,reshape((2, -1)) 将原始数组调整为 2 行,并且在第二个维度上自动计算出 5 列。
注意, reshape 并不会修改原来数组本身,而是会将修改后的结果返回。如果想要直接修改数组本身,那么可以使用 resize 来替代 reshape 。
5.5. ndarray.itemsize
ndarray.itemsize表示数组中每个元素占的大小,单位是字节。比如以下代码:
⑴.获取每个元素的字节大小:
import numpy as np a1 = np.array([1, 2, 3, 4, 5, 6], dtype=np.int16) # 使用 int16 数据类型 item_size = a1.itemsize print("Each element occupies {} bytes".format(item_size))
输出:
Each element occupies 2 bytes
这里,a1.itemsize 返回的是数组 arr 中每个元素的字节大小,因为我们指定了 dtype=np.int16,所以每个整数元素占据 2 个字节。
⑵.应用于多维数组:
arr = np.array([[1, 2, 3], [4, 5, 6]], dtype=np.float32) # 使用 float32 数据类型 item_size = arr.itemsize print("Each element occupies {} bytes".format(item_size))
输出:
Each element occupies 4 bytes
这里,arr.itemsize 返回的是数组 arr 中每个元素的字节大小,因为我们指定了 dtype=np.float32,所以每个浮点数元素占据 4 个字节。
注意事项
itemsize属性对于确定数组中元素在内存中的存储方式和大小非常有用。在处理大数据时,了解每个元素的大小可以帮助有效地管理内存和优化计算性能。- 默认情况下,NumPy 数组的
itemsize取决于数组的数据类型 (dtype)。不同的数据类型会占用不同数量的字节,例如np.int16占据 2 字节,np.float32占据 4 字节,np.float64则占据 8 字节,以此类推。
5.6.总结
前面的函数总结:
- 数组一般达到3维就已经很复杂了,不太方便计算了,所以我们一般都会把3维以上的数组转换成2维数组来计算。
- 通过ndarray.ndim可以看到数组的维度。
- 通过ndarray.shape可以看到数组的形状(几行几列),shape是一个元组,里面有几个元素代表是几维数组。
- 通过ndarray.reshape可以修改数组的形状。条件只有一个,就是修改后的形状的元素个数必须和原来的个数一致。比如原来是(2,6),那么修改完成后可以变成(3,4),但是不能变成(1,4)。reshape不会修改原来数组的形状,他只会将修改后的结果返回。
- 通过ndarray.size可以看到数组总共有多少个元素。
- 通过ndarray.itemsize可以看到数组中每个元素所占内存的大小,单位是字节。(1个字节=8位)。
六、数组索引和切片
6.1.一维数组的索引和切片
import numpy as np # [0 1 2 3 4 5 6 7 8 9] a1 = np.arange(10) # 进行索引操作 print(a1[4]) # 4 # 使用负数索引 print(a1[-1]) # 9 # 进行截取操作 print(a1[4:6]) # [4 5] # 使用步长 print(a1[::2]) # [0 2 4 6 8] # 使用步长结合截取 print(a1[5:9:2]) # [5 7]
6.2.多维数组的索引和切片
多维数组的索引和切片也是通过中括号来索引和切片,在中括号中,使用逗号进行分割,逗号前面的是行,逗号后面的是列,如果多维数组中只有一个值,那么这个值就是行。
import numpy as np arr = np.random.randint(0, 10, size=(4, 6)) print(arr) print("***************取的第一行数据*************") print(arr[0]) print("***************取的第二行到第三行数据*************") print(arr[1:3]) print("***************获取不连续的几行的数据*************") # arr[[0, 2, 3]] 使用了列表 [0, 2, 3] 作为索引,这意味着它选择了 arr 的第 0、2 和 3 行。 print(arr[[0, 2, 3]]) """ arr[[1, 3], [2, 4]]拼接规则说明: [1, 3] 是行索引。 [2, 4] 是列索引。 花式索引,取得是(1,3)第1行3列,(2,4)2行4列,注意行和列的索引都是从0开始 """ print("**************花式索引*************") print(arr[[1, 3], [2, 4]]) print("**********************************") # 取1-2行,4-5列 print(arr[1:3, 4:6])
数组索引总结:
- 如果数组是一维的,那么索引和切片就是跟python的列表是一样的。
- 如果是多维的(这里以二维为例),那么在中括号中,给两个值,两个值是通过逗号分隔的,逗号前面的是行,逗号后面的是列。如果中括号中只有一个值,那么就是代表的是行。
- 如果是多维数组(这里以二维为例),那么行的部分和列的部分,都是遵循一维数组的方式,可以使用整形,切片,还可以使用中括号的形式,来代表不连续的。比如a[[1,2],[3,4]],那么返回的就是(1,3),(2,4)的两个值。
6.3.布尔索引
布尔运算也是矢量的,比如以下代码
import numpy as np # 创建数组,24个数据,4行6列 a1 = np.arange(0, 24).reshape((4, 6)) print(a1) # 会返回一个新的数组,这个数组中的值全部都是bool类型 print(a1 > 10)
输入如下:
[[ 0 1 2 3 4 5] [ 6 7 8 9 10 11] [12 13 14 15 16 17] [18 19 20 21 22 23]] [[False False False False False False] [False False False False False True] [ True True True True True True] [ True True True True True True]]
上面看上去没有什么用,假如现在要实现一个需求,要将 a1 数组中所有小于10的数据全部都提取出来。那么可以使用以下方式实现:
import numpy as np # 创建数组,24个数据,4行6列 a1 = np.arange(0, 24).reshape((4, 6)) print(a1) # 求小于10的元素, a2 = a1 < 10 print(a2) # 这样就会在a1中把a2中为True的元素对应的位置的值提取出来 print(a1[a2])
其中布尔运算可以有 != 、 == 、 > 、 < 、 >= 、 <= 以及 &(与) 和 |(或) 。示例代码如下:
import numpy as np # 创建数组,24个数据,4行6列 a1 = np.arange(0, 24).reshape((4, 6)) # 获取数组a1中小于5,或者大于10的元素 a2 = a1[(a1 < 5)|(a1 > 10)] # 获取的值[ 0 1 2 3 4 11 12 13 14 15 16 17 18 19 20 21 22 23] print(a2)
6.4.值的替换
利用索引,也可以做一些值的替换。把满足条件的位置的值替换成其他的值。比如以下代码:
import numpy as np # 创建数组,24个数据,4行6列 a1 = np.arange(0, 24).reshape((4, 6)) # 将第三行的所有值都替换成 12 a1[3] = 12 print(a1)
也可以使用条件索引来实现:
import numpy as np # 创建数组,24个数据,4行6列 a1 = np.arange(0, 24).reshape((4, 6)) # 将小于5的所有值全部都替换成0 a1[a1 < 5] = 0 print(a1)
也可以使用函数来实现:
import numpy as np # 创建数组,24个数据,4行6列 a1 = np.arange(0, 24).reshape((4, 6)) # 把a1中所有小于10的数全部变成1,其余的变成0 a2 = np.where(a1 < 10, 1, 0) print(a2) """ [[1 1 1 1 1 1] [1 1 1 1 0 0] [0 0 0 0 0 0] [0 0 0 0 0 0]] """
6.5.练习
⑴.将 np.arange(10) 数组中的奇数全部都替换成 -1 。
import numpy as np # 创建数组,24个数据,4行6列 a1 = np.arange(10) # 将 np.arange(10) 数组中的奇数全部都替换成 -1 。 a1[a1 % 2 != 0] = -1 # [ 0 -1 2 -1 4 -1 6 -1 8 -1] print(a1)
⑵.有一个 4 行 4 列的数组(比如: np.random.randint(0,10,size=(4,4)) ),请将其中对角线的数取出来形成一个一维数组。提示(使用 np.eye )。
import numpy as np # 生成一个 4x4 的二维数组,数组中的元素是 0 到 9 的随机整数。 a1 = np.random.randint(0, 10, size=(4, 4)) print(a1) # 创建一个 4x4 的单位矩阵(对角线为 True,其他为 False),数据类型为布尔型。这个单位矩阵在布尔索引中用于选择 a1 的对角线元素。 eye = np.eye(4, dtype=bool) # 使用布尔索引从 a1 中提取对角线位置的元素(即单位矩阵中为 True 的位置)。这一步将生成一个包含 a1 对角线元素的一维数组 a2。 a2 = a1[eye] print(a2)
注意:使用 dtype=bool,使用布尔类型创建单位矩阵时,矩阵中的元素为 True 和 False,可以直接用于布尔索引。这样在进行布尔索引操作时会更简洁和直接。
⑶.有一个 4 行 4 列的数组,请取出其中 (0,0),(1,2),(3,2) 的点。
import numpy as np # 生成一个 4x4 的二维数组,数组中的元素是 0 到 9 的随机整数。 a1 = np.random.randint(0, 10, size=(4, 4)) print(a1) # 多维数组取出其中 (0,0),(1,2),(3,2) 的点 a2 = a1[[0, 1, 3], [0, 2, 2]] print(a2)
⑷.有一个 4 行 4 列的数组,请取出其中 2-3 行(包括第3行)的所有数据。
import numpy as np # 生成一个 4x4 的二维数组,数组中的元素是 0 到 9 的随机整数。 a1 = np.random.randint(0, 10, size=(4, 4)) print(a1) # 有一个 4 行 4 列的数组,请取出其中 2-3 行(包括第3行)的所有数据。 a2 = a1[2:4] print(a2) # 或者下面的方式均可 a3 = a1[[2, 3]] print(a3)
⑸.有一个 8 行 9 列的数组,请将其中1-5行(包含第5行)的第8列大于3的数全部都取出来。
import numpy as np # 生成一个 8x9 的二维数组,数组中的元素是 0 到 9 的随机整数。 a1 = np.random.randint(0, 10, size=(8, 9)) print(a1) #从 a1 中选择第 1 行到第 65 行(不包括第 6 行),第 8 列的元素,并将其存储在 nums 变量中。这一步形成了一个一维数组,包含了 a1 中特定列的部分元素。 nums = a1[1:6, 8] print(nums) # 创建一个布尔索引 idx,它用于标记 nums 中大于 3 的元素位置。这一步骤利用布尔条件生成一个布尔数组,其中 True 表示对应位置的元素满足条件(大于 3),而 False 表示不满足条件。 idx = nums > 3 print(idx) # 使用布尔索引 idx 来提取 nums 中满足条件(即 True 值所在位置)的元素,存储在 filtered_nums 变量中。这一步得到了满足条件的元素子集。 filtered_nums = nums[idx] print(filtered_nums)
七、数组操作
7.1.数组与数的计算
7.1.1.数组的计算
在 Python 列表中,想要对列表中所有的元素都加一个数,要么采用 map 函数,要么循环整个列表进行操作。但是 NumPy 中的数组可以直接在数组上进行操作。示例代码如下:
import numpy as np # 创建数组 3*4的小数 arr = np.random.random((3, 4)) print(arr) # 如果想要在数组上所有元素都乘以10,那么可以通过一下方式实现 new_arr = arr*10 print(new_arr) # 也可以使用round让所有的元素只保留2位小数 round_arr = new_arr.round(2) print(round_arr)
注意:以上例子是相乘,其实相加、相减、相除也都是类似的。
7.1.2.数组中的元素进行四舍五入
np.around() 是 NumPy 库中的一个函数,用于对数组中的元素进行四舍五入操作。其主要作用是将数组中的每个元素按照指定的精度进行四舍五入。这个函数可以处理标量(单个数值)或数组(多维数组),并返回与输入相同形状的数组,但元素的值经过了四舍五入处理。
np.around() 函数的基本语法如下:
np.around(a, decimals=0)
参数说明:
a:需要进行四舍五入的输入数据,可以是标量或数组。decimals:指定小数点后的位数,默认为 0,表示四舍五入到最接近的整数。可以是负数,这种情况下会对整数部分进行四舍五入。
示例:
import numpy as np # 四舍五入到最近的整数 array1 = np.array([1.23, 2.5, 3.67]) rounded1 = np.around(array1) print(rounded1) # 输出:[1. 2. 4.] # 四舍五入到小数点后一位 array2 = np.array([1.234, 2.567, 3.678]) rounded2 = np.around(array2, decimals=1) print(rounded2) # 输出: [1.2 2.6 3.7] # 四舍五入到小数点后两位 array3 = np.array([1.2345, 2.5678, 3.6789]) rounded3 = np.around(array3, decimals=2) print(rounded3) # 输出: [1.23 2.57 3.68] # 四舍五入到十位 array4 = np.array([15, 25, 35]) rounded4 = np.around(array4, decimals=-1) print(rounded4) # 输出: [20. 20. 40.]
7.2.数组与数组的计算
7.2.1.结构相同的数组之间的运算
import numpy as np # 定义两个数组 arr1 = np.arange(0, 24).reshape((4, 6)) arr2 = np.random.randint(1, 10, size=(4, 6)) print(arr1) print(arr2) # 相减/相除/相乘都是可以的 arr3 = arr1 + arr2 print(arr3)
输出如下:
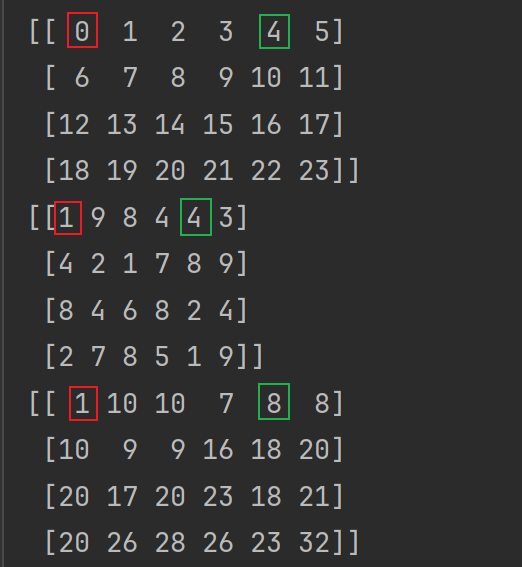
7.2.2.与行数相同并且只有1列的数组之间的运算
import numpy as np arr1 = np.random.randint(10, 20, size=(3, 8)) # 3行8列 arr2 = np.random.randint(1, 10, size=(3, 1)) # 3行1列 print(arr1) print(arr2) # 行数相同,且arr2只有一列,能互相运算 arr3 = arr1 - arr2 print(arr3)
输出如下:
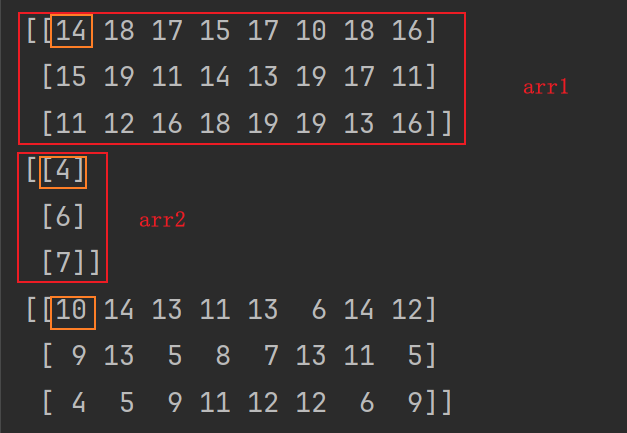
7.2.3.与列数相同并且只有1行的数组之间的运算
import numpy as np arr1 = np.random.randint(10, 20, size=(3, 8)) # 3行8列 arr2 = np.random.randint(1, 10, size=(1, 8)) # 1行8列 print(arr1) print(arr2) # 行数相同,且arr2只有一列,能互相运算 arr3 = arr1 - arr2 print(arr3)
输出如下:
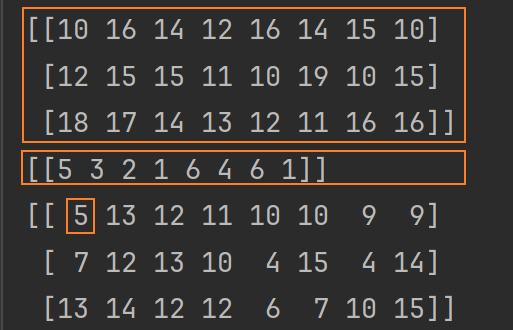
7.3. 数组广播机制
7.3.1.广播机制
NumPy 的广播机制是指在进行算术运算时,不同形状的数组之间可以自动地进行形状调整,使得它们能够兼容地进行运算。这种机制可以极大地简化代码,同时提高计算效率。广播机制允许 NumPy 在两个形状不一致的数组上执行逐元素操作,而无需显式地复制数据。
广播机制的基本规则:
-
维度对齐:
- 如果两个数组的维度数不同,则通过在较小数组的前面添加大小为 1 的维度来对齐它们。例如,一个形状为
(5,)的数组可以视为(1, 5)。
- 如果两个数组的维度数不同,则通过在较小数组的前面添加大小为 1 的维度来对齐它们。例如,一个形状为
-
形状匹配:
- 在对齐后的形状中,检查每个维度:
- 如果两个数组在某个维度的长度相同,或者其中一个数组在该维度的长度为 1,则认为它们在该维度上是兼容的。
- 如果两个数组在某个维度的长度不同且都不为 1,则不能广播,会引发错误。
- 在对齐后的形状中,检查每个维度:
-
扩展数组:
- 广播机制将较小数组沿着长度为 1 的维度扩展,以匹配较大数组的形状。
7.3.2.具体示例说明
示例 1: 可广播的数组
形状为 (3, 1) 的数组与形状为 (1, 4) 的数组相加
import numpy as np a = np.array([[1], [2], [3]]) # 形状 (3, 1) b = np.array([10, 20, 30, 40]) # 形状 (1, 4) # 广播机制使得 a 和 b 的形状变为 (3, 4) # a 被广播为 [[1, 1, 1, 1], # [2, 2, 2, 2], # [3, 3, 3, 3]] # b 被广播为 [[10, 20, 30, 40], # [10, 20, 30, 40], # [10, 20, 30, 40]] result = a + b print(result) # 输出: # [[11 21 31 41] # [12 22 32 42] # [13 23 33 43]]
广播过程的详细解释:
⑴.原始形状:
- a 的形状是 (3, 1)
- b 的形状是 (1, 4)
⑵.维度对齐:
- a 和 b 都有两个维度,已经对齐,不需要额外添加维度。
⑶.形状匹配:
- a 在第一个维度的长度是 3,b 在第一个维度的长度是 1,它们是兼容的。
- a 在第二个维度的长度是 1,b 在第二个维度的长度是 4,它们是兼容的。
⑷.扩展数组:
- a 被扩展为 [[1, 1, 1, 1], [2, 2, 2, 2], [3, 3, 3, 3]]
- b 被扩展为 [[10, 20, 30, 40], [10, 20, 30, 40], [10, 20, 30, 40]]
扩展后,a 和 b 都变为形状 (3, 4),可以进行元素级加法操作。
示例 2: 标量和数组相加
import numpy as np c = np.array([1, 2, 3]) # 形状 (3,) d = 10 # 标量被视为形状 () # 标量被广播位 [10, 10, 10] result = c + d print(result) # 输出:[11 12 13]
示例 3: 不可广播的数组
形状不兼容的数组,是无法广播的
import numpy as np arr4 = np.array([[1, 2], [3, 4]]) # 形状 2行2列 arr5 = np.array([1, 2, 3]) # 形状 (3,) print(arr4) print(arr5) # operands could not be broadcast together with shapes (2,2) (3,) result = arr4 + arr5 print(result)
不可广播的原因:
⑴.原始形状:
- arr4 的形状是 (2, 2)
- arr5 的形状是 (3,)
⑵.维度对齐:
- arr5 的形状可以视为 (1, 3)。
⑶.形状匹配:
- arr4 在第一个维度的长度是 2,arr5 在第一个维度的长度是 1,它们是兼容的。
- arr4 在第二个维度的长度是 2,arr5 在第二个维度的长度是 3,它们不兼容。
由于第二个维度的长度不同且都不为 1,无法广播。
示例4:高维数组之间的广播
[:, np.newaxis] 用于将一维数组 arr2 转换为二维数组,以便与 arr1 进行广播操作。
import numpy as np arr1 = np.ones((3, 3)) # 形状 3行3列,元素均为1 arr2 = np.array([1, 2, 3]) # 形状 (3,) print(arr1) print(arr2) # 在第二个轴上添加一个新的维度 result = arr1 * arr2[:, np.newaxis] print(result) # 输出: # [[1. 1. 1.] # [2. 2. 2.] # [3. 3. 3.]]
输出值为:

7.4.数组形状的操作
7.4.1. reshape和resize方法
两个方法都是用来修改数组形状的,但是有一些不同。
reshape 是将数组转换成指定的形状,然后返回转换后的结果,对于原数组的形状是不会发生改变的。调用方式:
import numpy as np arr1 = np.random.randint(0, 10, size=(3, 4)) print(arr1) """ 输出: [[0 0 9 3] [0 5 4 4] [3 0 2 0]] """ # 将修改后的结果返回,不会影响原数组本身 arr2 = arr1.reshape((2, 6)) print(arr2) """ 输出: [[0 0 9 3 0 5] [4 4 3 0 2 0]] """
resize 是将数组转换成指定的形状,会直接修改数组本身。并不会返回任何值。调用方式:
import numpy as np arr1 = np.random.randint(0, 10, size=(3, 4)) print(arr1) """ 输出: [[2 3 3 9] [6 4 5 3] [9 4 3 1]] """ # 将修改后的结果返回,不会影响原数组本身 arr1.resize((2, 6)) print(arr1) """ 输出: [[2 3 3 9 6 4] [5 3 9 4 3 1]] """
7.4.2.flatten和ravel方法
两个方法都是将多维数组转换为一维数组,但是有以下不同:
- flatten 是将数组转换为一维数组后,然后将这个拷贝返回回去,所以后续对这个返回值进行修改不会影响之前的数组。
- ravel 是将数组转换为一维数组后,将这个视图(可以理解为引用)返回回去,所以后续对这个返回值进行修改会影响之前的数组。
比如以下代码:
import numpy as np # 创建一个二维数组 arr = np.array([[1, 2, 3], [4, 5, 6]]) print("原始数组:", arr) # 使用 flatten 方法,将数组转换为一维数组 flattened = arr.flatten() print("Flattened array:", flattened) # 使用 ravel 方法,将数组转换为一维数组 raveled = arr.ravel() print("Raveled array:", raveled) # 修改 flattened 数组 flattened[0] = 100 print("原始数组:", arr) print("Flattened array:", flattened) # 修改 raveled 数组 raveled[1] = 200 # 对这个raveled返回值进行修改会影响之前的数组 print("原始数组:", arr) # 返回[[1 200 3] [4 5 6]] print("Raveled array:", raveled)
7.5.数组(矩阵)转置和轴对换
7.5.1.矩阵转换
numpy 中的数组其实就是线性代数中的矩阵。矩阵是可以进行转置的。为什么要进行矩阵转置呢?有时候在做一些计算的时候需要用到。比如做矩阵的内积的时候,就必须将矩阵进行转置后再乘以之前的矩阵。ndarray 有一个 T 属性,可以返回这个数组的转置的结果。示例代码如下:
import numpy as np arr1 = np.arange(0, 24).reshape((4, 6)) print(arr1) print("****************ndarray 有一个 T 属性,可以返回这个数组的转置的结果****************") arr2 = arr1.T print(arr2) """ 输出结果: [[ 0 1 2 3 4 5] [ 6 7 8 9 10 11] [12 13 14 15 16 17] [18 19 20 21 22 23]] ****************ndarray 有一个 T 属性,可以返回这个数组的转置的结果**************** [[ 0 6 12 18] [ 1 7 13 19] [ 2 8 14 20] [ 3 9 15 21] [ 4 10 16 22] [ 5 11 17 23]] """
另外还有一个方法叫做 transpose ,这个方法返回的是一个View,也即修改返回值,会影响到原来数组。示例代码如下:
import numpy as np arr1 = np.arange(0, 24).reshape((4, 6)) print(arr1) print("****************ndarray 有一个 T 属性,可以返回这个数组的转置的结果****************") arr2 = arr1.T print(arr2) print("****************transpose修改返回值,会影响到原来数组****************") arr3 = arr1.transpose() # 效果同a1.T print(arr3) """ 输出结果: [[ 0 1 2 3 4 5] [ 6 7 8 9 10 11] [12 13 14 15 16 17] [18 19 20 21 22 23]] ****************ndarray 有一个 T 属性,可以返回这个数组的转置的结果**************** [[ 0 6 12 18] [ 1 7 13 19] [ 2 8 14 20] [ 3 9 15 21] [ 4 10 16 22] [ 5 11 17 23]] ****************transpose修改返回值,会影响到原来数组**************** [[ 0 6 12 18] [ 1 7 13 19] [ 2 8 14 20] [ 3 9 15 21] [ 4 10 16 22] [ 5 11 17 23]] """
7.5.2.矩阵
NumPy 中包含了一个矩阵库 numpy.matlib,该模块中的函数返回的是一个矩阵,而不是 ndarray 对象。矩阵是一个由行(row)列(column)元素排列成的矩形阵列。numpy.matlib.identity() 函数返回给定大小的单位矩阵(同np.eye())。单位矩阵是个方阵,从左上角到右下角的对角线(称为主对角线)上的元素均为 1,除此以外全都为 0。
矩阵相乘:
numpy.dot(a, b, out=None)
参数:
- a : ndarray 数组
- b : ndarray 数组

第一个矩阵第一行的数字(2和1),各自乘以第二个矩阵第一列对应位置的数字(1和1),然后将乘积相加( 2 x 1 + 1 x 1),得到结果矩阵左上角的那个值3。也就是说,结果矩阵第m行与第n列交叉位置的那个值,等于第一个矩阵第m行与第二个矩阵第n列,对应位置的每个值的乘积之和。
# 结果矩阵第m行与第n列交叉位置的那个值,根据m在第一个矩阵取行,根据n在第二个矩阵取列,然后对应位置的每个值的乘积相加。 3=(2*1+1*1) m=1 n=1 4=(2*2+1*0) m=1 n=2 7=(4*1+3*1) m=2 n=1 8=(4*2+3*0) m=2 n=2
用代码实现就比较简单了:
import numpy as np arr1 = np.array([[2,1],[4,3]]) print(arr1) arr2 = np.array([[1,2],[1,0]]) print(arr2) print("*************矩阵的内积**************") result = np.dot(arr1,arr2) print(result) """ 输出结果: [[2 1] [4 3]] [[1 2] [1 0]] *************矩阵的内积************** [[3 4] [7 8]] """
7.6.不同数组的组合
如果有多个数组想要组合在一起,也可以通过其中的一些函数来实现。
7.6.1.vstack
vstack :将数组按垂直方向进行叠加。数组的列数必须相同才能叠加。示例代码如下:
import numpy as np arr1 = np.random.randint(0, 10, size=(3, 5)) print(arr1) arr2 = np.random.randint(0, 10, size=(1, 5)) print(arr2) print("*************将数组按垂直方向进行叠加**************") result = np.vstack([arr1, arr2]) print(result) """ 输出结果: [[9 1 2 6 8] [6 9 1 4 1] [2 7 1 6 7]] [[5 0 5 3 2]] *************将数组按垂直方向进行叠加************** [[9 1 2 6 8] [6 9 1 4 1] [2 7 1 6 7] [5 0 5 3 2]] """
7.6.2.hstack
hstack :将数组按水平方向进行叠加。数组的行必须相同才能叠加。示例代码如下:
import numpy as np arr1 = np.random.randint(0, 10, size=(3, 2)) print(arr1) arr2 = np.random.randint(0, 10, size=(3, 1)) print(arr2) print("*************将数组按水平方向进行叠加**************") result = np.hstack([arr1, arr2]) print(result) """ 输出结果: [[8 1] [4 7] [5 8]] [[9] [6] [8]] *************将数组按水平方向进行叠加************** [[8 1 9] [4 7 6] [5 8 8]] """
7.6.3.concatenate
语法:
concatenate([],axis)
说明:将两个数组进行叠加,但是具体是按水平方向还是按垂直方向。则要看 axis 的参数,如果 axis=0 ,那么代表的是往垂直方向(行)叠加,如果 axis=1 ,那么代表的是往水平方向(列)上叠加,如果 axis=None ,那么会将两个数组组合成一个一维数组。需要注意的是,如果往水平方向上叠加,那么行必须相同,如果是往垂直方向叠加,那么列必须相同。示例代码如下:
import numpy as np arr1 = np.array([[1, 2], [3, 4]]) print(arr1) arr2 = np.array([[5, 6]]) print(arr2) print("*************将数组按垂直方向进行叠加**************") result1 = np.concatenate((arr1, arr2), axis=0) print(result1) print("*************将数组按水平方向进行叠加**************") """ 这里需要将 arr2 转置为 arr2.T,因为 arr2 的形状为 (1, 2),而转置后的形状为 (2, 1),这样可以匹配 arr1 (2,2)的行数 如果不进行转置,直接执行 np.concatenate((arr1, arr2), axis=1) 会导致维度不匹配的错误(如果往水平方向上叠加,那么行必须相同),因为形状 (2, 2) 和 (1, 2) 沿 axis=1 拼接时行数不一致。 """ result2 = np.concatenate((arr1, arr2.T), axis=1) # arr2.T 即arr2的转置 print(result2) print("*************将两个数组组合成一个一维数组**************") result3 = np.concatenate((arr1, arr2), axis=None) print(result3) """ 输出结果: [[1 2] [3 4]] [[5 6]] *************将数组按垂直方向进行叠加************** [[1 2] [3 4] [5 6]] *************将数组按水平方向进行叠加************** [[1 2 5] [3 4 6]] *************将两个数组组合成一个一维数组************** [1 2 3 4 5 6] """
7.7.数组的切割
通过 hsplit 和 vsplit 以及 array_split 可以将一个数组进行切割。
7.7.1.hsplit
hsplit :按照水平方向进行切割。用于指定分割成几列,可以使用数字来代表分成几部分,也可以使用数组来代表分割的地方。示例代码如下:
import numpy as np arr1 = np.arange(16).reshape(4,4) print(arr1) print("*************将arr1分割成2部分**************") arr2 = np.hsplit(arr1,2) print(arr2) print("*************下标为1的地方切一刀,下标为2的地方切一刀,分成三部分**************") arr3 = np.hsplit(arr1,[1, 2]) print(arr3) """ 输出结果: [[ 0 1 2 3] [ 4 5 6 7] [ 8 9 10 11] [12 13 14 15]] *************将arr1分割成2部分************** [array([[ 0, 1], [ 4, 5], [ 8, 9], [12, 13]]), array([[ 2, 3], [ 6, 7], [10, 11], [14, 15]])] *************下标为1的地方切一刀,下标为2的地方切一刀,分成三部分************** [array([[ 0], [ 4], [ 8], [12]]), array([[ 1], [ 5], [ 9], [13]]), array([[ 2, 3], [ 6, 7], [10, 11], [14, 15]])] """
7.7.2.vsplit
vsplit :按照垂直方向进行切割。用于指定分割成几行,可以使用数字来代表分成几部分,也可以使用数组来代表分割的地方。示例代码如下:
import numpy as np arr1 = np.arange(16).reshape(4,4) print(arr1) print("*************将arr1按照行总共分成2个数组**************") arr2 = np.vsplit(arr1,2) print(arr2) print("*************按照行进行划分,在下标为1的地方和下标为2的地方分割,[1,2] 和 (1,2)结果一样**************") arr3 = np.vsplit(arr1,[1, 2]) print(arr3) """ 输出结果: [[ 0 1 2 3] [ 4 5 6 7] [ 8 9 10 11] [12 13 14 15]] *************将arr1按照行总共分成2个数组************** [array([[0, 1, 2, 3], [4, 5, 6, 7]]), array([[ 8, 9, 10, 11], [12, 13, 14, 15]])] *************按照行进行划分,在下标为1的地方和下标为2的地方分割,[1,2] 和 (1,2)结果一样************** [array([[0, 1, 2, 3]]), array([[4, 5, 6, 7]]), array([[ 8, 9, 10, 11], [12, 13, 14, 15]])] """
7.7.3.split/array_split
split/array_split(array,indicate_or_seciont,axis) :用于指定切割方式,在切割的时候需要指定是按照行还是按照列, axis=1 代表按照列, axis=0 代表按照行。示例代码如下:
import numpy as np arr1 = np.arange(16).reshape(4, 4) print(arr1) print("*************按照垂直方向切割成2部分**************") arr2 = np.array_split(arr1, 2, axis=0) print(arr2) print("*************按照水平方向切割成2部分**************") arr3 = np.array_split(arr1, 2, axis=1) print(arr3) """ 输出结果: [[ 0 1 2 3] [ 4 5 6 7] [ 8 9 10 11] [12 13 14 15]] *************按照垂直方向切割成2部分************** [array([[0, 1, 2, 3], [4, 5, 6, 7]]), array([[ 8, 9, 10, 11], [12, 13, 14, 15]])] *************按照水平方向切割成2部分************** [array([[ 0, 1], [ 4, 5], [ 8, 9], [12, 13]]), array([[ 2, 3], [ 6, 7], [10, 11], [14, 15]])] """
7.8.常用的统计函数
numpy.amin()和numpy.amax():用于计算数组中的元素沿指定轴的最小、最大值numpy.ptp():计算数组中元素最大值与最小值的差(最大值 - 最小值)numpy.median():用于计算数组 a 中元素的中位数(中值)- 标准差
std():标准差是一组数据平均值分散程度的一种度量。公式:
std = sqrt(mean((x - x.mean())**2))
说明:如果数组是 [1,2,3,4],则其平均值为 2.5。 因此,差的平方是[2.25,0.25,0.25,2.25],并且其平均值的平方根除以 4,即 sqrt(5/4) ,结果为 1.118033988749895。
# 1.计算平均值 (1+2+3+4)/ 4=2.5 # 2.计算每个元素与平均值的差并平方(其中减去的2.5指的是平均值): 2.25 =(1-2.5)**2 0.25 =(2-2.5)**2 0.25 =(3-2.5)**2 2.25 =(4-2.5)**2 # 3.计算方差: (2.25+0.25+0.25+2.25)/ 4 = 1.25 # 4.计算标准差(方差的平方根) 1.25平方根约等于1.118
- 方差
var():统计中的方差(样本方差)是每个样本值与全体样本值的平均数之差的平方值的平均数,即mean((x - x.mean())** 2)。换句话说,标准差是方差的平方根。
# 1.计算平均值 (1+2+3+4)/ 4=2.5 # 2.计算每个元素与平均值的差并平方(其中减去的2.5指的是平均值): 2.25 =(1-2.5)**2 0.25 =(2-2.5)**2 0.25 =(3-2.5)**2 2.25 =(4-2.5)**2 # 3.计算方差: (2.25+0.25+0.25+2.25)/ 4 = 1.25
示例:
import numpy as np arr1 = np.array([1, 2, 3, 4]) print(arr1) print(arr1.ptp()) # (最大值 - 最小值) = (4 - 1) = 3 print(arr1.mean()) # 计算数组 a 中元素的中位数(中值)2.5 print(arr1.std()) # 标准差 1.118033988749895 print(arr1.var()) # 方差 1.25
八、numpy数组的深浅拷贝
在操作数组的时候,它们的数据有时候拷贝进一个新的数组,有时候又不是,这经常使初学者感到困惑。在数组操作中分成三种拷贝:
- 不拷贝:直接赋值,那么栈区没有拷贝,只是用同一个栈区定义了不同的名称。
- 浅拷贝:只拷贝栈区,栈区指定的堆区并没有拷贝。
- 深拷贝:栈区和堆区都拷贝了。
8.1.不拷贝
如果只是简单的赋值,那么不会进行拷贝。示例代码如下:
import numpy as np arr1 = np.array([1, 2, 3, 4]) # 这种情况不会进行拷贝 arr2 = arr1 # 返回True,说明b和a是相同的 print(arr2 is arr1)
8.2.View或者浅拷贝
有些情况,会进行变量的拷贝,所指向的内存空间都是一样的,那么这种情况叫做浅拷贝,或者叫做 View(视图) 。比如以下代码:
import numpy as np arr1 = np.array([1, 2, 3, 4]) arr2 = arr1.view() # 返回False,说明arr1和arr2是两个不同的变量 print(arr2 is arr1) # 修改值 arr2[0] = 100 # 打印100,说明对arr2的修改,会影响arr1上面的值,说明他们指向的内存空间还是一样的,这种叫做浅拷贝,或者说是view print(arr1[0])
8.3.深拷贝
将之前数据完完整整的拷贝一份放到另外一块内存空间中,这样就是两个完全不同的值了。示例代码如下:
import numpy as np arr1 = np.array([1, 2, 3, 4]) arr2 = arr1.copy() # 返回False,说明arr1和arr2是两个不同的变量 print(arr2 is arr1) # 修改值 arr2[0] = 100 # 打印1,说明arr2和arr1指向的内存空间完全不同了。 print(arr1[0])
之前用到的ravel 返回的就是View(浅拷贝),而 flatten 返回的就是深拷贝。
注意:这里和python list中的区别是copy直接是深拷贝,两者互不影响
九、文件操作
如果想专门的操作CSV文件,python内置的有一个模块叫做csv,不需要安装,这里不作过多介绍。接下来我们主要讲numpy操作文件。
9.1.文件保存
有时候我们有了一个数组,需要保存到文件中,那么可以使用 np.savetxt 来实现。相关的函数描述如下:
numpy.savetxt(fname, X, fmt='%.18e', delimiter=' ', newline='\n', header='', footer='', comments='# ', encoding=None)
参数说明
fname: 文件名或文件对象。可以是字符串或文件对象。如果是字符串,表示要保存到的文件名。X: 需要保存的数组。fmt: 可选。格式字符串,指定数组中每个元素的格式。默认为'%.18e',表示科学计数法。fmt 参数还可以使用其他格式选项:- %f:浮点数(默认保留六位小数)
- %.2f:浮点数(保留两位小数)
- %e:科学计数法表示的浮点数
- %s:字符串
- %d:保留成整数类型,以十进制整数形式保存到文件
delimiter: 可选。分隔符字符串,用于分隔数组中的元素。默认为空格' '。newline: 可选。定义行结束符,默认为换行符\n。header: 可选。字符串,将被写入到文件的开头。footer: 可选。字符串,将被写入到文件的末尾。comments: 可选。字符串,将被添加到header和footer的开头。默认是#。encoding: 可选。文件的编码方式,默认为None,表示使用系统默认编码。
⑴.基本使用:
import numpy as np # 创建一个二维数组 arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) # 将数组保存到文本文件中 np.savetxt('array.txt', arr)
生成文件如下:

⑵.使用自定义分隔符和格式:
import numpy as np # 创建一个二维数组 arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) # 将数组保存到文本文件中,使用逗号作为分隔符,保留2位小数 np.savetxt('array.txt', arr, delimiter=',', fmt="%.2f")
生成文件如下:
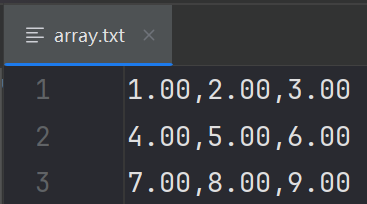
⑶.添加头部和尾部:
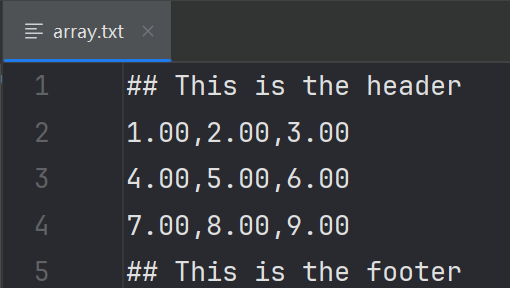
import numpy as np # 创建一个二维数组 arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) # 将数组保存到文本文件中,添加头部和尾部 np.savetxt('array.txt', arr, delimiter=',', fmt="%.2f", header='This is the header', footer='This is the footer', comments='## ')
生成文件如下:
9.2.读取文件
有时候我们的数据是需要从文件中读取出来的,那么可以使用 np.loadtxt 来实现。相关的函数描述如下:
numpy.loadtxt(fname, dtype=<class 'float'>, comments='#', delimiter=None, converters=None, skiprows=0, usecols=None, unpack=False, ndmin=0, encoding='bytes', max_rows=None, like=None)
参数说明
fname: 文件名或文件对象。可以是字符串、文件对象或生成器。dtype: 可选。要加载的数据类型。默认是float。comments: 可选。用于标识注释的字符串,默认为#。所有从该字符串开始的行都将被忽略。delimiter: 可选。用于分隔列的字符串。默认是空格。converters: 可选。字典,用于将列转换为特定数据类型的函数。键是列索引,值是转换函数。skiprows: 可选。跳过文件开头的行数。usecols: 可选。要读取的列索引。可以是整数或整数序列。unpack: 可选。如果为True,则返回解包后的列数据。ndmin: 可选。指定返回数组的最小维度。encoding: 可选。指定文件的编码类型。默认为bytes。max_rows: 可选。要读取的最大行数。like: 可选。通过传递数组的类,可以生成类似的数组对象。
⑴.基本使用:
import numpy as np # 创建并保存一个数组到文本文件 arr = np.array([[1.1, 2.2, 3.3], [4.4, 5.5, 6.6], [7.7, 8.8, 9.9]]) np.savetxt('array.txt', arr) # 从文本文件加载数据 load_arr = np.loadtxt('array.txt') print(load_arr) """ 输入: [[1.1 2.2 3.3] [4.4 5.5 6.6] [7.7 8.8 9.9]] """
⑵.使用自定义分隔符:
import numpy as np # 创建并保存一个数组到csv文件 arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) np.savetxt('array.csv', arr, delimiter=',') # 从csv文件加载数据 load_arr = np.loadtxt('array.csv', delimiter=',') print(load_arr) """ 输入: [[1. 2. 3.] [4. 5. 6.] [7. 8. 9.]] """
⑶,指定数据类型和跳过行数:
本地有一个students.csv文件,格式是这样的。需要我们读取文件 内容,但是不要加载文件的第一行表头信息
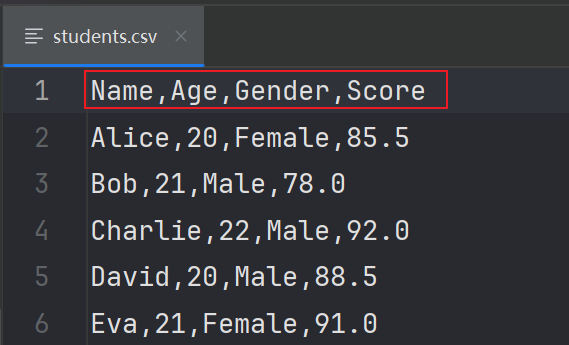
代码如下:
import numpy as np # 创建学生信息列表 students = [ ["Name", "Age", "Gender", "Score"], ["Alice", 20, "Female", 85.5], ["Bob", 21, "Male", 78.0], ["Charlie", 22, "Male", 92.0], ["David", 20, "Male", 88.5], ["Eva", 21, "Female", 91.0] ] # 将学生信息列表转换为numpy数组 students_array = np.array(students) # 保存到csv文件 np.savetxt('students.csv', students_array, delimiter=',', fmt='%s') # 获取文件内容,跳过第一行 loaded_students = np.loadtxt('students.csv', delimiter=',', dtype=str, skiprows=1) print(loaded_students) """ 输入: [['Alice' '20' 'Female' '85.5'] ['Bob' '21' 'Male' '78.0'] ['Charlie' '22' 'Male' '92.0'] ['David' '20' 'Male' '88.5'] ['Eva' '21' 'Female' '91.0']] """
⑷.读取特定列:
import numpy as np # 从文本文件加载数组,只读取第一列和第三列 loaded_students = np.loadtxt('students.csv', delimiter=',', dtype=str, usecols=(0, 2)) print(loaded_students) """ 输入: [['Name' 'Gender'] ['Alice' 'Female'] ['Bob' 'Male'] ['Charlie' 'Male'] ['David' 'Male'] ['Eva' 'Female']] """
⑸.解包列数据:
import numpy as np # 从csv文件加载数组,并解包列数据(unpack=True) name, age, gender, score = np.loadtxt('students.csv', delimiter=',', dtype=str, unpack=True) print("Column 1:", name) print("Column 2:", age) print("Column 3:", gender) print("Column 3:", score) """ 输入: Column 1: ['Name' 'Alice' 'Bob' 'Charlie' 'David' 'Eva'] Column 2: ['Age' '20' '21' '22' '20' '21'] Column 3: ['Gender' 'Female' 'Male' 'Male' 'Male' 'Female'] Column 3: ['Score' '85.5' '78.0' '92.0' '88.5' '91.0'] """
9.3. numpy独有的存储解决方案
numpy 中还有一种独有的存储解决方案。文件名是以 .npy 或者 npz 结尾的。以下是存储和加载的函数。
- 存储: np.save(fname,array) 或 np.savez(fname,array) 。其中,前者函数的扩展名是 .npy ,后者的扩展名是 .npz ,后者是经过压缩的。
- 加载: np.load(fname) 。
9.3.1.使用 .npy 文件存储和加载单个数组
- 存储单个数组
import numpy as np # 创建一个数组 arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) # 将数组保存到 .npy 文件 np.save("array.npy", arr)
- 加载单个数组
import numpy as np # # 从 .npy 文件加载数组 loaded_arr = np.load("array.npy") print(loaded_arr) """ 输入: [[1 2 3] [4 5 6] [7 8 9]] """
9.3.2.使用 .npz 文件存储和加载多个数组
- 存储多个数组
import numpy as np # 创建多个数组 arr1 = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) arr2 = np.array([10, 20, 30]) arr3 = np.array([[1.1, 2.2], [3.3, 4.4]]) # 将多个数组保存到 .npz 文件 np.savez("arrays.npz", arr1=arr1, arr2=arr2, arr3=arr3)
- 加载多个数组
import numpy as np # 从 .npz 文件加载多个数组 loaded_data = np.load("arrays.npz") # 提取打印输出每个数组 loaded_arr1 = loaded_data['array1'] loaded_arr2 = loaded_data['array2'] loaded_arr3 = loaded_data['array3'] print("Array 1:", loaded_arr1) print("Array 2:", loaded_arr2) print("Array 3:", loaded_arr3) """ 输入: Array 1: [[1 2 3] [4 5 6] [7 8 9]] Array 2: [10 20 30] Array 3: [[1.1 2.2] [3.3 4.4]] """
总结
.npy文件 用于存储单个数组,存储和读取速度快,文件体积较小。.npz文件 是一个压缩文件,可以存储多个数组,适用于需要保存和加载多个数组的情况。
这些方法使得处理大规模数据时更加高效和便捷,特别是在科学计算和数据分析领域。
十、数组实操
问题1:数组a = np.random.rand(3,2,3)能和b = np.random.rand(3,2,2)进行运算吗?能和c = np.random.rand(3,1,1)进行运算吗?请说明结果的原因
⑴.a 和 b 不能直接进行运算,这里的 a 和 b 分别是形状为 (3, 2, 3) 和 (3, 2, 2) 的三维数组。
- a 的形状是 (3, 2, 3),即第一个维度为 3,第二个维度为 2,第三个维度为 3。
- b 的形状是 (3, 2, 2),即第一个维度为 3,第二个维度为 2,第三个维度为 2。
在 NumPy 的广播机制中,两个数组在每个维度的对应轴上要么具有相同的形状,要么其中一个数组在该维度上的长度为 1,才能进行运算。
- a 和 b 的最后两个维度分别是 (2, 3) 和 (2, 2),它们在这两个维度上的形状并不匹配,因此不能直接进行逐元素的加法、减法等运算。
因此,a 和 b 不能直接进行运算,因为它们不满足广播的机制要求。
⑵.数组 a 和 c可以进行运算,这里的 a 是形状为 (3, 2, 3) 的数组,而 c 是形状为 (3, 1, 1) 的数组。
- a 的形状是 (3, 2, 3),即第一个维度为 3,第二个维度为 2,第三个维度为 3。
- c 的形状是 (3, 1, 1),即第一个维度为 3,第二个维度为 1,第三个维度为 1。
在这种情况下:
- c 的形状是 (3, 1, 1),可以通过广播规则扩展为 (3, 2, 3),即复制其第二和第三个维度,使得与 a 的形状相匹配。
- 扩展后,c 变成了一个形状为 (3, 2, 3) 的数组,与 a 的形状相同,因此它们可以进行逐元素的加法、减法等运算。
因此,a 和 c 可以进行运算,因为它们满足广播机制的要求。
问题2:想要将数组a = np.arange(15).reshape(3,5)和b=np.arange(100,124).reshape(6,4)叠加在一起,其中a在b的上面,并且在b的第1列后面(下标从0开始)新增一列,用0来填充。
import numpy as np # 1.创建数组 a = np.arange(15).reshape(3, 5) """ a输出: [[ 0 1 2 3 4] [ 5 6 7 8 9] [10 11 12 13 14]] """ b = np.arange(100, 124).reshape(6, 4) """ b输出: [[100 101 102 103] [104 105 106 107] [108 109 110 111] [112 113 114 115] [116 117 118 119] [120 121 122 123]] """ # 2. 因为b只有4列,无法直接和a堆叠,且题目要求在第1列后面添加一列,所以先将b数组在下标为1的地方切割,然后添加完0数组后再进行拼接 b_split_arr = np.hsplit(b, [2]) print(b_split_arr) """ [array([[100, 101], [104, 105], [108, 109], [112, 113], [116, 117], [120, 121]]), array([[102, 103], [106, 107], [110, 111], [114, 115], [118, 119], [122, 123]])] """ # 3.创建一个班全0的6行1列数组 zero_arr = np.zeros((6, 1)) # 4.将b的前半部分、0、b的后半部分组合在一起形成一个新的数组 c = np.hstack([b_split_arr[0], zero_arr, b_split_arr[1]]) # 5.将a和c新生成的数组进行堆叠(将数组按垂直方向进行叠加) result = np.vstack([a, c]) print(result) """ [[ 0. 1. 2. 3. 4.] [ 5. 6. 7. 8. 9.] [ 10. 11. 12. 13. 14.] [100. 101. 0. 102. 103.] [104. 105. 0. 106. 107.] [108. 109. 0. 110. 111.] [112. 113. 0. 114. 115.] [116. 117. 0. 118. 119.] [120. 121. 0. 122. 123.]] """
问题3:将数组a = np.random.rand(4,5)扁平化成一维数组,可以使用flatten和ravel,对两者的返回值进行操作,哪个会影响到数组a?对会影响到a数组的那个函数,请说明原因。
ravel会影响原来的数组。原因是因为ravel返回的是一个浅拷贝(视图),虽然在栈中的内存不一样,但是指向的堆区的内存地址还是一样,所以操作其返回值,会影响到原来堆区的值。但是flatten返回的却是一个深拷贝,也即栈区和堆区都进行了拷贝,所以操作其返回值,不会影响到原来堆区的值。
十一、NAN和INF值处理
11.1.NAN和INF
NAN和INF意思:
- NAN:Not A number,不是一个数字的意思,是属于浮点类型的,所以想要进行数据操作的时候需要注意他的类型。
- INF: Infinity,代表的是无穷大的意思,也是属于浮点类型。 np.inf 表示正无穷大, -np.inf 表示负无穷大,一般在出现除数为0的时候为无穷大。比如 2/0 。
NAN一些特点:
- NAN和NAN不相等。比如 np.NAN != np.NAN 这个条件是成立的。
- NAN和任何值做运算,结果都是NAN。
11.2.缺失值处理
有些时候,特别是从文件中读取数据的时候,经常会出现一些缺失值。缺失值的出现会影响数据的处理。因此我们在做数据分析之前,先要对缺失值进行一些处理。处理的方式有多种,需要根据实际情况来做。一般有两种处理方式:
- 一种是删除缺失值
- 另外一种就是用其他值进行替代。
⑴.删除缺失值
有时候,我们想要将数组中的 NAN 删掉,那么我们可以换一种思路,就是只提取不为 NAN 的值。示例代码如下:
- 删除所有的NAN值
import numpy as np # 1. 删除所有NAN的值,因为删除了值后数组将不知道该怎么变化,所以会被变成一维数组 # 生成一个形状为 (3, 5) 的随机整数数组,并将其转换为 float32 类型。 data = np.random.randint(0, 10, size=(3, 5)).astype(np.float32) print(data) """ [[7. 8. 4. 2. 1.] [6. 1. 9. 2. 4.] [0. 4. 0. 9. 9.]] """ # 将数组 data 中第一行第二列的元素设为 NAN(Not a Number),这里的 np.nan 是 NumPy 提供的表示非数字的特殊值。 data[0, 1] = np.nan print(data) """ [[ 7. nan 4. 2. 1.] [ 6. 1. 9. 2. 4.] [ 0. 4. 0. 9. 9.]] """ """ 此时的data会没有nan,并且变成一维数组 使用掩码 ~np.isnan(data) 过滤掉数组 data 中的 NAN 值。np.isnan(data) 返回一个布尔数组,其中元素为 True 表示对应位置是 NAN。~ 是取反操作符,
所以 ~np.isnan(data) 的意思是将 NAN 的位置取反,即得到一个掩码数组,其中元素为 True 表示对应位置不是 NAN。这个掩码数组用于索引原始数组 data,从而得到不包含 NAN 值的一维数组。 """ data = data[~np.isnan(data)] print(data) """ [7. 4. 2. 1. 6. 1. 9. 2. 4. 0. 4. 0. 9. 9.] """
- 删除NAN所在的行
import numpy as np # 2. 删除NAN所在的行 # 生成一个形状为 (3, 5) 的随机整数数组,并将其转换为 float32 类型。这里的 np.random.randint(0, 10, size=(3, 5)) 生成一个范围在 0 到 9 之间的整数随机数组成的数组,astype(np.float32) 将整数数组转换为 float32 类型。 data = np.random.randint(0, 10, size=(3, 5)).astype(np.float32) print(data) """ [[6. 7. 1. 0. 3.] [7. 2. 4. 4. 6.] [5. 0. 9. 3. 0.]] """ # 使用花式索引将数组 data 中第 0 行第 0 列和第 1 行第 2 列的元素设为 NAN(Not a Number),这里的 np.nan 是 NumPy 提供的表示非数字的特殊值。 data[[0, 1],[0, 2]] = np.nan print(data) """ [[nan 7. 1. 0. 3.] [ 7. 2. nan 4. 6.] [ 5. 0. 9. 3. 0.]] """ # 使用 np.isnan(data) 找出数组 data 中所有 NAN 元素所在的位置,np.where() 返回一个元组,第一个元素是包含 NAN 元素的行索引数组,第二个元素是包含 NAN 元素的列索引数组。通过 [0] 取出行索引数组。 lines = np.where(np.isnan(data))[0] print(lines) """ [0 1] """ # 使用delete方法删除指定的行,axis=0表示删除行,lines表示删除的行号 result = np.delete(data, lines, axis=0) print(result) """ [[5. 0. 9. 3. 0.]] """
⑵.用其他值进行替代
有些时候我们不想直接删掉,比如有一个成绩表,分别是数学和英语,但是因为某个人在某个科目上没有成绩,那么此时就会出现NAN的情况,这时候就不能直接删掉了,就可以使用某些值进行替代。假如有以下表格:

处理代码如下:
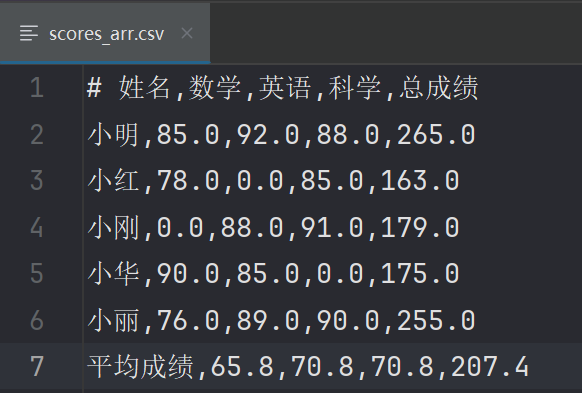
import numpy as np # 加载数据 scores = np.loadtxt("scores.csv", delimiter=",", skiprows=1, encoding="utf-8", dtype=np.str_) print(scores) # 找到所有的 'NAN' 并替换为 'nan' scores[scores == "NAN"] = np.nan print(scores) # 将姓名和成绩进行分割 scores_split = np.hsplit(scores, [1]) print(scores_split) # 将成绩部分进行转换 scores_float = scores_split[1].astype(np.float32) print(scores_float) """ [[85. 92. 88.] [78. nan 85.] [nan 88. 91.] [90. 85. nan] [76. 89. 90.]] """ # 将成绩为nan的转换为0 scores_float[np.isnan(scores_float)] = 0 print(scores_float) # 1.求出学生成绩的总分 # 除了delete用axis=0表示行以外,其他的大部分函数都是axis=1来表示行。 sum_score = scores_float.sum(axis=1).reshape(-1, 1) # 使用 reshape 方法将一维数组修改为多行一列 print(sum_score) # 将数组按水平方向进行叠加。数组的行必须相同才能叠加 arr_result = np.hstack([scores_float, sum_score]) print(arr_result) # 2.求出每门成绩的平均分 """ 也可以这样写: # scores_float.shape[1] 是用于获取 NumPy 数组 scores_float 的第二个维度的大小,也就是列出3 # for x in range(scores_float.shape[1]): # col = scores_float[:, x] # 通过遍历 scores_float 数组的每一列,: 表示选择该维度的所有元素。x 是列索引,col 是当前列的数组。 # non_nan_col = col[~np.isnan(col)] # 使用布尔索引 ~np.isnan(col) 获取当前列中非 NAN 的元素(也就是数字),生成一个新的数组 non_nan_col,其中只包含非 NAN 的值。 # mean = non_nan_col.mean() # 成绩的平均值,并将其存储在 mean 变量中。 """ # 求每门成绩的平均值 avg_score = arr_result.mean(axis=0) print(avg_score) # 平均值(将数组按垂直方向进行叠加。数组的列数必须相同才能叠加) result2 = np.vstack([arr_result, avg_score]) """ [[ 85. 92. 88. 265. ] [ 78. 0. 85. 163. ] [ 0. 88. 91. 179. ] [ 90. 85. 0. 175. ] [ 76. 89. 90. 255. ] [ 65.8 70.8 70.8 207.4]] """ # 在姓名列添加一个元素, # 1.要添加的新元素 new_name = np.array([['平均成绩']]) # 2.使用 vstack 方法垂直堆叠数组 names = np.vstack([scores_split[0], new_name]) """ [['小明'] ['小红'] ['小刚'] ['小华'] ['小丽'] ['平均成绩']] """ # 组合拼接 new_arr = np.hstack([names, result2]) print(new_arr) # 保存结果到csv文件 np.savetxt('scores_arr.csv', new_arr, delimiter=',', fmt='%s', encoding="utf-8", header='姓名,数学,英语,科学,总成绩')
生成文件如下:
11.3.NAN和INF总结
- NAN:Not A Number的简写,不是一个数字,但是他是属于浮点类型。
- INF:无穷大,在除数为0的情况下会出现INF。
- NAN和所有的值进行计算结果都是等于NAN
- NAN != NAN
- 可以通过np.isnan来判断某个值是不是NAN。
- 处理值的时候,可以通过删除NAN的形式进行处理,也可以通过值的替换进行处理。
- np.delete比较特殊,通过axis=0来代表行,而其他大部分函数是通过axis=1来代表行

 浙公网安备 33010602011771号
浙公网安备 33010602011771号