索引库和文档操作
一、索引库
索引库就相当于表,索引库里面有文档,相当于数据库里面的一行一行的数据,数据库先创建表才能添加数据,ES里面也一样,先有索引库,才能往里面添加文档。创建一个个索引库,就想建表一样,如果想创建一个索引库,需要指定mapping映射,mapping是对文档的约束
分词器分词是在:第一个给文档创建索引的时候,对文档个中的某个内容进行分词,给词条创建倒排索引,第二个是用户在搜索的时候进行分词,对用户输入的内容进行分词。
1.1.操作索引库-mapping属性
映射(Mapping)是定义文档及其包含的字段如何存储和索引的过程。 每个文档都是字段的集合,每个字段都有自己的数据类型。为数据创建一个映射定义,包含与文档相关的字段列表。
Mapping 类似于数据库中的表结构定义 schema,它有以下几个作用:
- 定义索引中的字段的名称
- 定义字段的数据类型,比如字符串、数字、布尔
- 字段,倒排索引的相关配置,比如设置某个字段为不被索引、记录 position 等
mapping是对索引库中文档的约束,常见的mapping属性包括:
- type:字段数据类型,常见的简单类型有:
- 字符串:text(可分词的文本)、keyword(精确值,例
- 数值:long、integer、short、byte、double、float、
- 布尔:boolean
- 日期:date
- 对象:object
- index:是否创建索引,默认为true
- analyzer:使用哪种分词器
- properties:该字段的子字段,用于定义索引中字段的属性的关键字。每个字段都可以具有不同的属性,例如数据类型、分词器、索引选项等
- store:指定是否将字段的原始值存储在索引中。如果设置为"true",则可以从索引中检索字段的原始值。
type:看一下这个字段需要不需要拆,需要拆的话用text,不需要拆的话用keyword
index:创建索引,默认是true 创建索引是字面意思,要不要创建倒排索引 ,然后就可以搜索了,没有倒排索引就没有办法搜索这个字段 在实际的开发过程中并不是所有的字段需要搜索,不需要搜索的字段,把这个值设置为false
在 ES 早期版本,一个索引下是可以有多个 Type 的,从 7.0 开始,一个索引只有一个 Type,也可以说一个 Type 有一个 Mapping 定义。
1.2.字段数据类型
ES 字段类型类似于 MySQL 中的字段类型,ES 字段类型主要有:核心类型、复杂类型、地理类型以及特殊类型,具体的数据类型如下图所示:
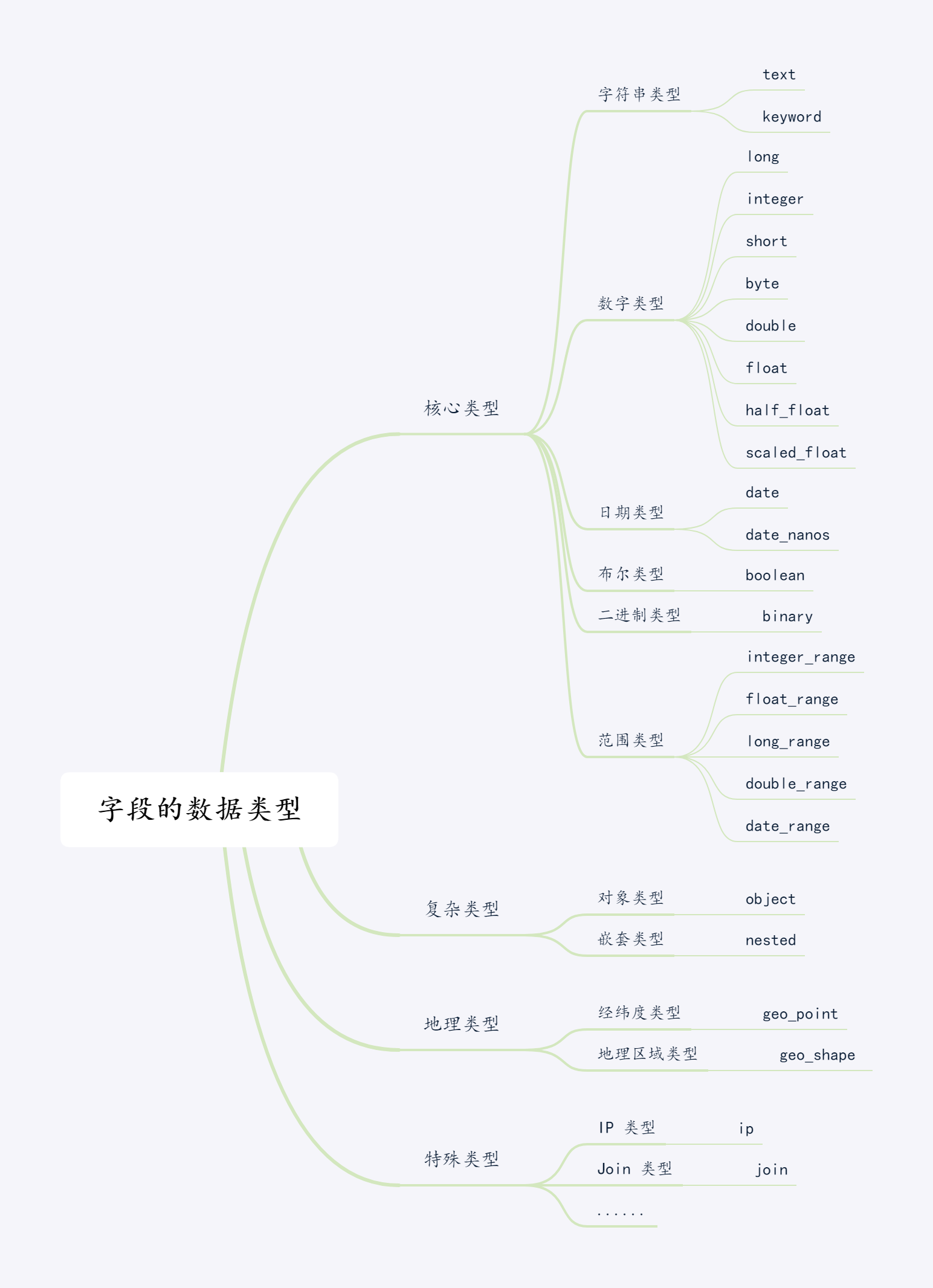
1.2.1.核心类型
从图中可以看出核心类型可以划分为字符串类型、数字类型、日期类型、布尔类型、基于 BASE64 的二进制类型、范围类型。
1.2.1.1.字符串类型
其中,在 ES 7.x 有两种字符串类型:text 和 keyword,在 ES 5.x 之后 string 类型已经不再支持了。
text 类型适用于需要被全文检索的字段,例如新闻正文、邮件内容等比较长的文字,text 类型会被 Lucene 分词器(Analyzer)处理为一个个词项,并使用 Lucene 倒排索引存储,text 字段不能被用于排序,如果需要使用该类型的字段只需要在定义映射时指定 JSON 中对应字段的 type 为 text。
keyword 适合简短、结构化字符串,例如主机名、姓名、商品名称等,可以用于过滤、排序、聚合检索,也可以用于精确查询。
1.2.1.2.数字类型
数字类型分为 long、integer、short、byte、double、float、half_float、scaled_float。
数字类型的字段在满足需求的前提下应当尽量选择范围较小的数据类型,字段长度越短,搜索效率越高,对于浮点数,可以优先考虑使用 scaled_float 类型,该类型可以通过缩放因子来精确浮点数,例如 12.34 可以转换为 1234 来存储。
1.2.1.3.日期类型
在 ES 中日期可以为以下形式:
- 格式化的日期字符串,例如 2020-03-17 00:00、2020/03/17
- 时间戳(和 1970-01-01 00:00:00 UTC 的差值),单位毫秒或者秒
即使是格式化的日期字符串,ES 底层依然采用的是时间戳的形式存储。
1.2.1.4.布尔类型
JSON 文档中同样存在布尔类型,不过 JSON 字符串类型也可以被 ES 转换为布尔类型存储,前提是字符串的取值为 true 或者 false,布尔类型常用于检索中的过滤条件。
1.2.1.5.二进制类型
二进制类型 binary 接受 BASE64 编码的字符串,默认 store 属性为 false,并且不可以被搜索。
1.2.1.6.范围类型
范围类型可以用来表达一个数据的区间,可以分为5种:integer_range、float_range、long_range、double_range 以及 date_range。
1.2.2.复杂类型
复合类型主要有对象类型(object)和嵌套类型(nested):
1.2.2.1.对象类型
JSON 字符串允许嵌套对象,一个文档可以嵌套多个、多层对象。可以通过对象类型来存储二级文档,不过由于 Lucene 并没有内部对象的概念,ES 会将原 JSON 文档扁平化,例如文档:
{ "name": { "first": "san", "last": "zhangsan" } }
实际上 ES 会将其转换为以下格式,并通过 Lucene 存储,即使 name 是 object 类型:
{ "name.first": "san", "name.last": "zhang" }
1.2.2.2嵌套类型
嵌套类型可以看成是一个特殊的对象类型,可以让对象数组独立检索,例如文档:
{ "group": "users", "username": [ { "first": "du", "last": "ax"}, { "first": "fu", "last": "by"}, { "first": "gu", "last": "cx"} ] }
username 字段是一个 JSON 数组,并且每个数组对象都是一个 JSON 对象。如果将 username 设置为对象类型,那么 ES 会将其转换为:
{ "group": "users", "username.first": ["du", "fu", "gu"], "username.last": ["ax", "by", "cx"] }
可以看出转换后的 JSON 文档中 first 和 last 的关联丢失了,如果尝试搜索 first 为 du,last 为 by 的文档,那么成功会检索出上述文档,但是 du 和 by 在原 JSON 文档中并不属于同一个 JSON 对象,应当是不匹配的,即检索不出任何结果。
嵌套类型就是为了解决这种问题的,嵌套类型将数组中的每个 JSON 对象作为独立的隐藏文档来存储,每个嵌套的对象都能够独立地被搜索,所以上述案例中虽然表面上只有 1 个文档,但实际上是存储了 4 个文档。
1.2.3.地理类型
地理类型字段分为两种:经纬度类型和地理区域类型:
1.2.3.1.经纬度类型
经纬度类型字段(geo_point)可以存储经纬度相关信息,通过地理类型的字段,可以用来实现诸如查找在指定地理区域内相关的文档、根据距离排序、根据地理位置修改评分规则等需求。
1.2.3.2.地理区域类型
经纬度类型可以表达一个点,而 geo_shape 类型可以表达一块地理区域,区域的形状可以是任意多边形,也可以是点、线、面、多点、多线、多面等几何类型。
1.2.4.特殊类型
特殊类型包括 IP 类型、过滤器类型、Join 类型、别名类型等,在这里简单介绍下 IP 类型和 Join 类型,其他特殊类型可以查看官方文档。
1.2.4.1.IP 类型
IP 类型的字段可以用来存储 IPv4 或者 IPv6 地址,如果需要存储 IP 类型的字段,需要手动定义映射:
{ "mappings": { "properties": { "my_ip": { "type": "ip" } } } }
1.2.4.2.Join类型
Join 类型是 ES 6.x 引入的类型,以取代淘汰的 _parent 元字段,用来实现文档的一对一、一对多的关系,主要用来做父子查询。Join 类型的 Mapping 如下:
PUT my_index { "mappings": { "properties": { "my_join_field": { "type": "join", "relations": { "question": "answer" } } } } }
其中,my_join_field 为 Join 类型字段的名称;relations 指定关系:question 是 answer 的父类。例如定义一个 ID 为 1 的父文档:
PUT my_join_index/1?refresh { "text": "This is a question", "my_join_field": "question" }
接下来定义一个子文档,该文档指定了父文档 ID 为 1:
PUT my_join_index/_doc/2?routing=1&refresh { "text": "This is an answer", "my_join_field": { "name": "answer", "parent": "1" } }
1.3.什么是 Dynamic Mapping?
Dynamic Mapping 机制使我们不需要手动定义 Mapping,ES 会自动根据文档信息来判断字段合适的类型,但是有时候也会推算的不对,比如地理位置信息有可能会判断为 Text,当类型如果设置不对时,会导致一些功能无法正常工作,比如 Range 查询。
1.3.1.类型自动识别
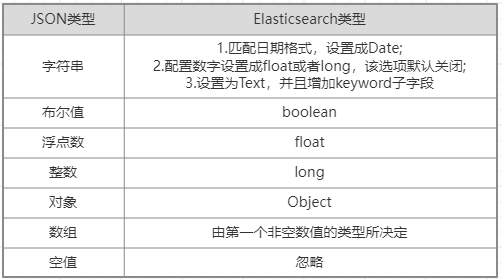
ES 类型的自动识别是基于 JSON 的格式,如果输入的是 JSON 是字符串且格式为日期格式,ES 会自动设置成 Date 类型;当输入的字符串是数字的时候,ES 默认会当成字符串来处理,可以通过设置来转换成合适的类型;如果输入的是 Text 字段的时候,ES 会自动增加 keyword 子字段,还有一些自动识别如下图所示:
下面我们通过一个例子是看看是怎么类型自动识别的(示例的HTTP请求,使用的是PUT方法。它的作用是将一个文档存储到名为"mapping_test"的索引中,文档的ID是"1"),输入如下请求,创建索引:
PUT /mapping_test/_doc/1 { "uid": "123", "username": "Augus", "birth": "2023-08-16", "married": false, "age": 18, "heigh": 180, "tags": [ "java", "boy" ], "money": 999.9 }
然后使用 GET /mapping_test/_mapping 查看,结果如下图所示
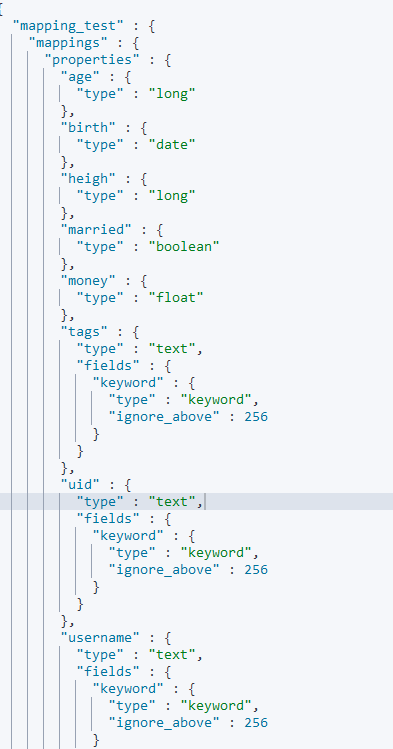
可以从结果中看出,ES 会根据文档信息自动推算出合适的类型。万一我想修改 Mapping 的字段类型,能否更改呢?让我们分以下两种情况来探究下:
1.4.修改 Mapping 字段类型?
如果是新增加的字段,根据 Dynamic 的设置分为以下三种状况:
- 当 Dynamic 设置为
true时,一旦有新增字段的文档写入,Mapping 也同时被更新。 - 当 Dynamic 设置为
false时,索引的 Mapping 是不会被更新的,新增字段的数据无法被索引,也就是无法被搜索,但是信息会出现在_source中。 - 当 Dynamic 设置为
strict时,文档写入会失败。
另外一种是字段已经存在,这种情况下,ES 是不允许修改字段的类型的,因为 ES 是根据 Lucene 实现的倒排索引,一旦生成后就不允许修改,如果希望改变字段类型,必须使用 Reindex API 重建索引。
不能修改的原因是如果修改了字段的数据类型,会导致已被索引的无法被搜索,但是如果是增加新的字段,就不会有这样的影响。
1.5.创建索引库
ES中通过Restful请求操作索引库、文档。请求内容用DSL语句来表示。创建索引库和mapping的DSL语法如下:

代码如下:
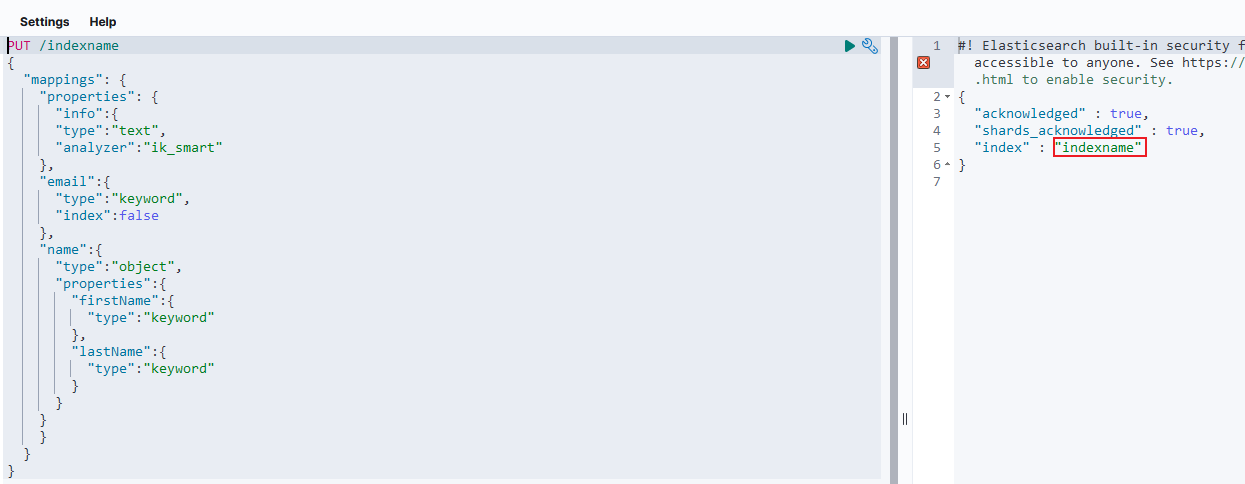
PUT /indexname { "mappings": { "properties": { "info":{ "type":"text", "analyzer":"ik_smart" }, "email":{ "type":"keyword", "index":false }, "name":{ "type":"object", "properties":{ "firstName":{ "type":"keyword" }, "lastName":{ "type":"keyword" } } } } } }
执行结果如下:
1.6.查询、删除和修改索引库
1.6.1.查看索引库
语法如下:
GET 索引库的名称
案例如下:
GET indexname
1.6.2.删除索引库
语法如下:
DELETE 索引库的名称
案例如下:
DELETE indexname
1.6.3.修改索引库
ES一般是不允许修改索引库的,如果你要去修改一个字段的话,就会导致我们原有的倒排索引失效,但是可以修改库添加新的字段。语法如下:
PUT /索引库的名称/_mapping { "properties":{ "新的字段名":{ "type":"integer" } } }
案例如下:
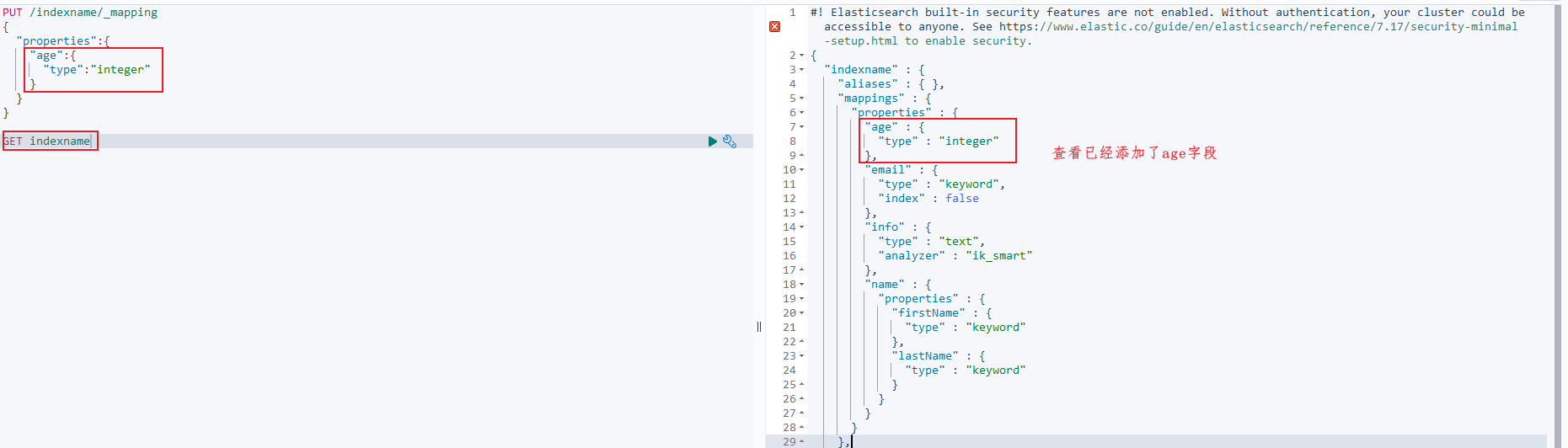
PUT /indexname/_mapping { "properties":{ "age":{ "type":"integer" } } }
执行添加新字典如下:

再次查看可以看到索引库中已经有了字段:
二、文档操作
2.1.添加文档
语法如下:
POST /索引库/_doc/文档id { "字段1":"值1", "字段2":"值2", "字段3":{ "子属性1":"值3", "子属性2":"值4" } }
案例语法如下:
POST /indexname/_doc/1 { "info":"我的zhangsan,擅长软件测试和java开发", "email":"Auguses@126.com", "name":{ "firstName":"三", "lastName":"张" } }
执行后如下:

2.2.查看文档
查看文档语法:
GET/索引库名/_doc/文档id
示例
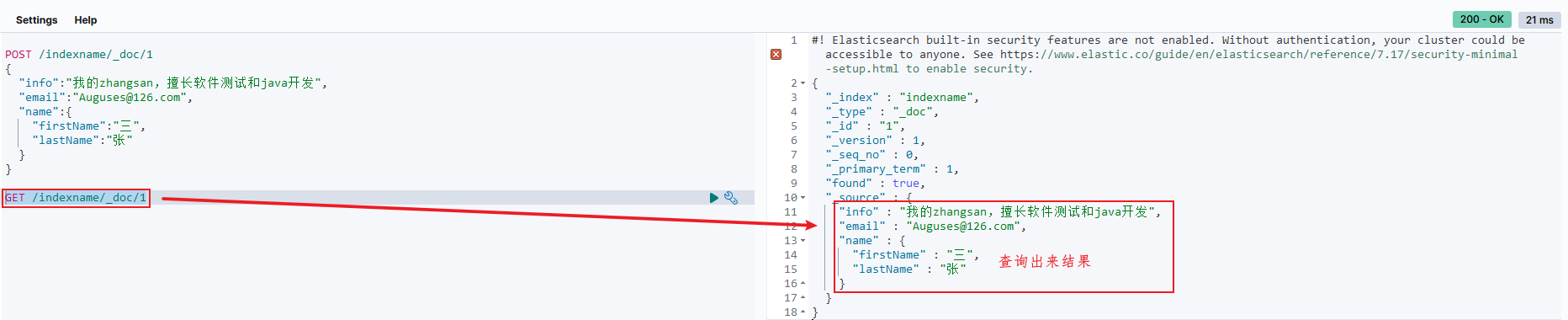
GET /indexname/_doc/1
执行后结果如下:
2.3.删除文档
删除文档库语法如下:
DELETE /索引库名称/_doc/文档id
案例:
DELETE /indexname/_doc/1
执行后如下:

再次查看,文档id为1的文档已经不存在了:

2.4.修改文档
方式一:全量修改 (所有字段全部修改)
跟新增文档的写法相似,只是更换了请求方式 为PUT,它会根据id查询查询出来删除旧数据,添加新数据,当id不存在时,就变成了新增数据,语法如下:
语法如下:
PUT /索引库/_doc/文档id
{
"字段1":"值1",
"字段2":"值2",
"字段3":{
"子属性1":"值3",
"子属性2":"值4"
}
}
案例语法如下:
PUT /indexname/_doc/1
{
"info":"我的ZS,擅长软件测试和java开发",
"email":"zs@126.com",
"name":{
"firstName":"三",
"lastName":"张"
}
}
执行后再次查看如下,发现数据已经修改了:

如果文档id不存在,则会创建

方式二:增量修改(可以修改部分字典)
增量修改,修改指定字段值,语法如下:
POST /索引库名称/_update/文档id { "doc": { "字段1":"新的值", "字段2":"新的值" } }
案例如下:
POST /indexname/_update/1 { "doc": { "info":"我是张三,是一名程序员", "email":"zhangsan@163.com" } }
执行后结果如下:

修改后查询结果,发现info和email字段的值已经被修改,如下图:

id如果不存在则直接报错


 浙公网安备 33010602011771号
浙公网安备 33010602011771号