Docker部署Elasticsearch
一、Elasticsearch安装说明
Elasticsearch是一个Java项目,从Elasticsearch7.0以上的版本已经内置jdk,不同的版本所需要的jdk版本是不同的(建议使用自己的Java版本,推荐Java长期版本),同时不同的系统版本所需要的ES版本也是不同的,
注意:ES自带openjdk,如果你的主机本身没有安装JDK,那么它会使用自带的JDK,如果安装了,那么会使用系统JDK。可是如果系统JDK版本小于ES需要的JDK版本,那么就会在启动时抛出不支持你的JDK的错误
参考官方网址:https://www.elastic.co/cn/support/matrix#matrix_os
下载地址:https://www.elastic.co/cn/downloads/elasticsearch,下载下来目录如下图:
| 目录名称 | 描述 |
| bin | 可执行脚本文件,包括启动elastic search服务、插件管理、函数命令等等 |
| config | 配置文件目录,如elasticsearch配置、角色配置、jvm配置等。 |
| jdk | 7.0以后才有,自带的Java环境 |
| lib | elasticsearch所依赖的Java库 |
| data | 默认的数据存放目录,包含节点、分片、索引、文档的所有数据,生产环境要求必须修改。 |
| logs | 默认的日志文件存储路径,生产环境务必修改。 |
| modules | 包含所有的Elasticsearch模块,如Cluster、Discovery、Indices等。 |
| plugins | 已经安装的插件的目录 |
二、部署单点es
2.1.创建网络
因为我们还需要部署kibana容器,因此需要让es和kibana容器互联。这里先创建一个网络:
docker network create es-net
2.2.拉取镜像
考虑到elasticsearch的兼容性,这里elasticsearch、kibana、IK分词器统一下载7.17.5版本,拉取镜像
docker pull elasticsearch:7.17.5 docker pull kibana:7.17.5
2.3.运行
运行docker命令,部署单点es,
docker run -d \ --name es \ -e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \ -e "discovery.type=single-node" \ -v es-data:/usr/share/elasticsearch/data \ -v es-plugins:/usr/share/elasticsearch/plugins \ --privileged \ --network es-net \ -p 9200:9200 \ -p 9300:9300 \ elasticsearch:7.17.5
下面是各个参数的含义解释和作用:
-
-d:以后台模式运行容器。 -
--name es:为容器指定一个名称为 "es"。 -
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m":设置 Elasticsearch 的 Java 虚拟机选项,指定初始堆大小为 512MB,最大堆大小也为 512MB。 -
-e "discovery.type=single-node":设置 Elasticsearch 的发现类型为单节点模式,这意味着它将以单节点模式启动,不会尝试与其他节点进行通信。 -
-v es-data:/usr/share/elasticsearch/data:将名为 “es-data” 的 Docker 卷挂载到容器内的/usr/share/elasticsearch/data目录,用于持久化 Elasticsearch 的数据。 -
-v es-plugins:/usr/share/elasticsearch/plugins:将名为 “es-plugins” 的 Docker 卷挂载到容器内的/usr/share/elasticsearch/plugins目录,用于安装 Elasticsearch 插件。 -
--privileged:以特权模式运行容器,这允许容器内的进程获得更高的权限。 -
--network es-net:将容器连接到名为 “es-net” 的网络,这样容器内的服务可以通过网络进行通信。 -
-p 9200:9200:将容器的 9200 端口映射到主机的 9200 端口,这样可以通过主机的 IP 地址和端口访问 Elasticsearch 的 HTTP API。 -
-p 9300:9300:将容器的 9300 端口映射到主机的 9300 端口,这样可以通过主机的 IP 地址和端口访问 Elasticsearch 的节点间通信。
总体而言,这个命令会创建一个名为 “es” 的 Elasticsearch 容器,配置了内存限制、数据和插件目录的挂载,以及网络和端口的映射,使得可以通过主机访问 Elasticsearch 服务
2.4.测试
在浏览器中输入:http://192.168.42.146:9200 即可看到elasticsearch的响应结果:
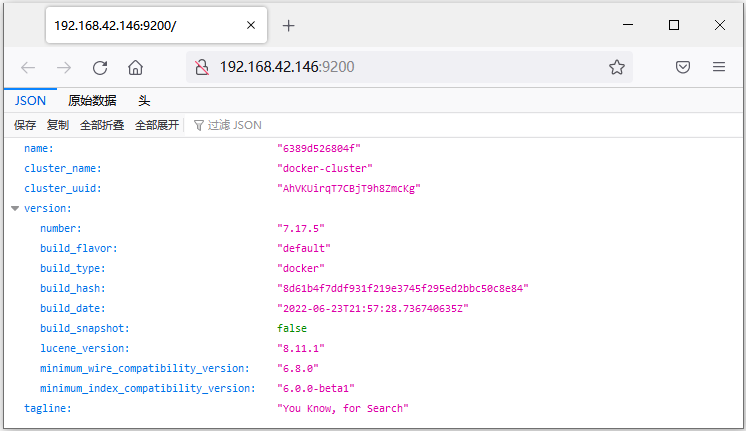
三、部署kibana
Kibana 是一款开源的数据分析和可视化平台,设计用于和 Elasticsearch 协作。可以使用 Kibana 对 Elasticsearch 索引中的数据进行搜索、查看、交互操作。kibana可以给我们提供一个elasticsearch的可视化界面,方便学习。
3.1.部署
创建kibana容器,如下:
docker run -d --name kibana -e ELASTICSEARCH_HOSTS=http://es:9200 --network=es-net -p 5601:5601 kibana:7.17.5
参数说明:
- –network es-net :加入一个名为es-net的网络中,与elasticsearch在同一个网络中
- -e ELASTICSEARCH_HOSTS=http://es:9200":设置elasticsearch的地址,因为kibana已经与elasticsearch在一个网络,因此可以用容器名直接访问elasticsearch
- -p 5601:5601:端口映射配置
kibana启动比较慢,需要多等待一会,可以通过命令查看启动情况:
docker logs -f kibana
查看运行日志,当查看到下面的日志,说明成功:

此时,在浏览器输入地址访问:http://192.168.42.146:5601,即可看到结果:
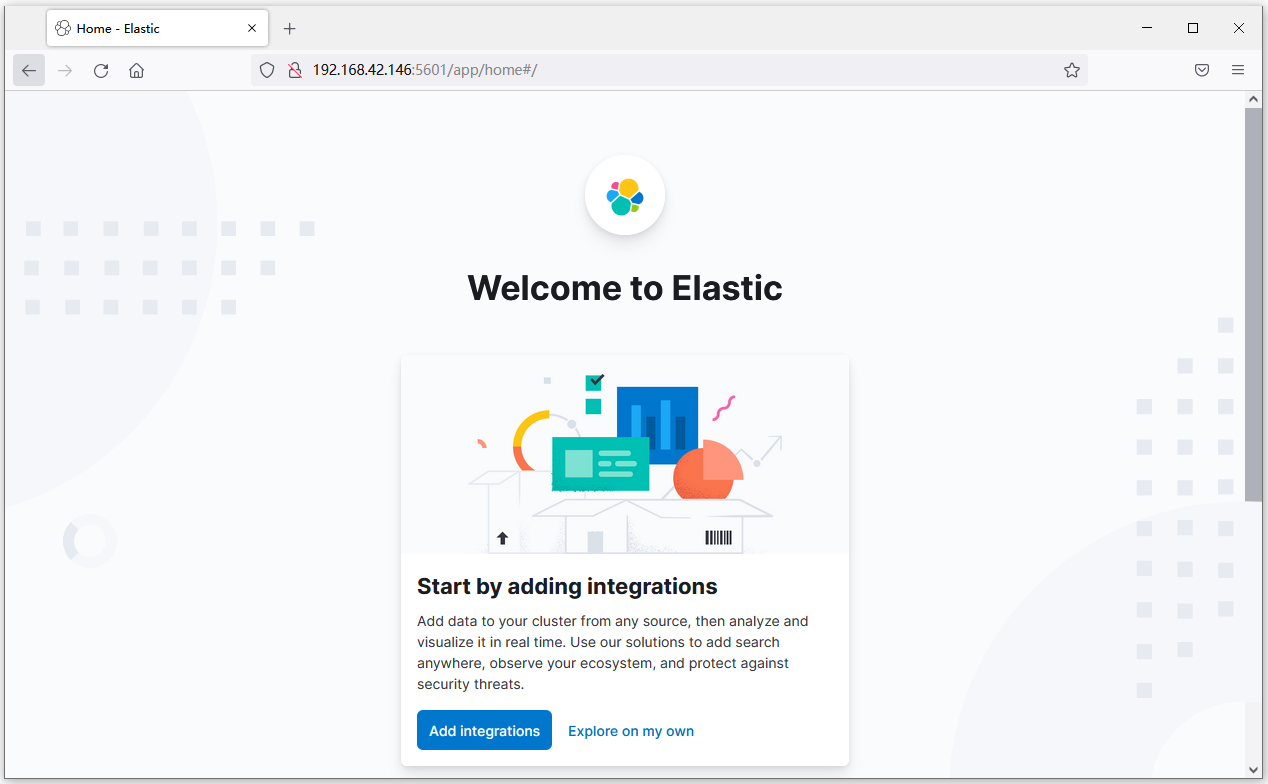
3.2.DevTools
kibana中提供了一个DevTools界面,地址:http://192.168.42.146:5601/app/dev_tools#/console,如下:
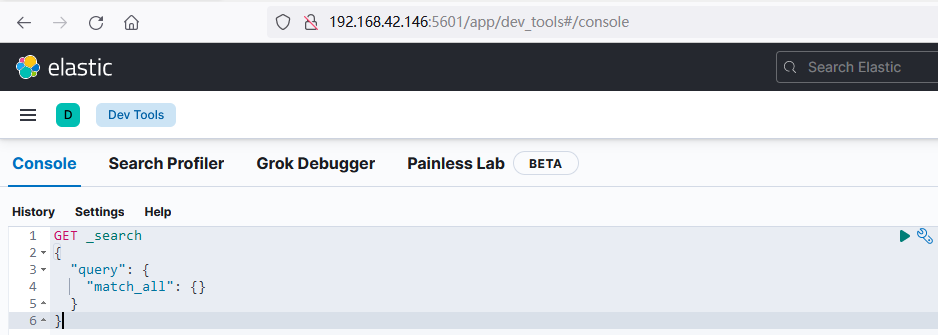
这个界面中可以编写DSL来操作elasticsearch。并且对DSL语句有自动补全功能。
四、安装IK分词器
4.1.在线安装ik插件(较慢)
不推荐下面方式
# 进入容器内部
docker exec -it elasticsearch /bin/bash
# 在线下载并安装
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.17.5/elasticsearch-analysis-ik-7.17.5.zip
#退出容器
exit
#重启容器
docker restart es
4.2.离线安装ik插件(推荐)
4.2.1.查看数据卷目录
安装插件需要知道elasticsearch的plugins目录位置,而我们用了数据卷挂载,因此需要查看elasticsearch的数据卷目录,通过下面命令查看:
docker volume inspect es-plugins
如下图:
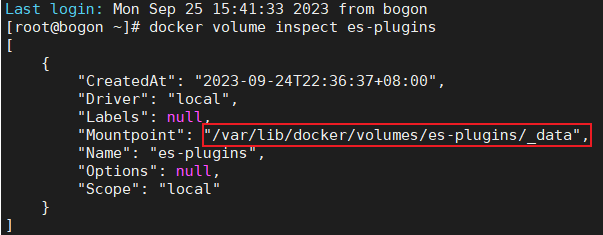
说明plugins目录被挂载到了:/var/lib/docker/volumes/es-plugins/_data这个目录中。
4.2.2.解压缩分词器安装包
去GitHub下载ik分词器,下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.17.5,

4.2.3.上传到es容器的插件数据卷中
在/var/lib/docker/volumes/es-plugins/_data,创建路径analysis-ik,路径即可,然后解压
# 创建路径
mkdir analysis-ik
将文件上传到创建的路径,然后解压

4.2.4.重启容器
# 4、重启容器 docker restart es # 查看es日志 docker logs -f es
4.2.5.测试:
IK分词器包含两种模式:
- ik_smart:最少切分
- ik_max_word:最细切分
4.3.扩展词词典
随着互联网的发展,“造词运动”也越发的频繁。出现了很多新的词语,在原有的词汇列表中并不存在。比如:“显眼包”,“蓝瘦香菇” 等。所以我们的词汇也需要不断的更新,IK分词器提供了扩展词汇的功能。
所谓扩展词:就是不想哪些词分开,让他们成为一个词,比如“蓝瘦香菇”
4.3.1.打开IK分词器config目录,在IKAnalyzer.cfg.xml配置文件内容添加
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典 *** 添加扩展词典--> <entry key="ext_dict">ext.dic</entry> </properties>
4.3.2.在config包下新建一个 ext.dic,可以参考config目录下复制一个配置文件进行修改
显眼包
蓝瘦香菇
4.3.3.重启elasticsearch
docker restart es
# 查看 日志
docker logs -f es
日志中已经成功加载ext.dic配置文件
4.3.4.测试效果:
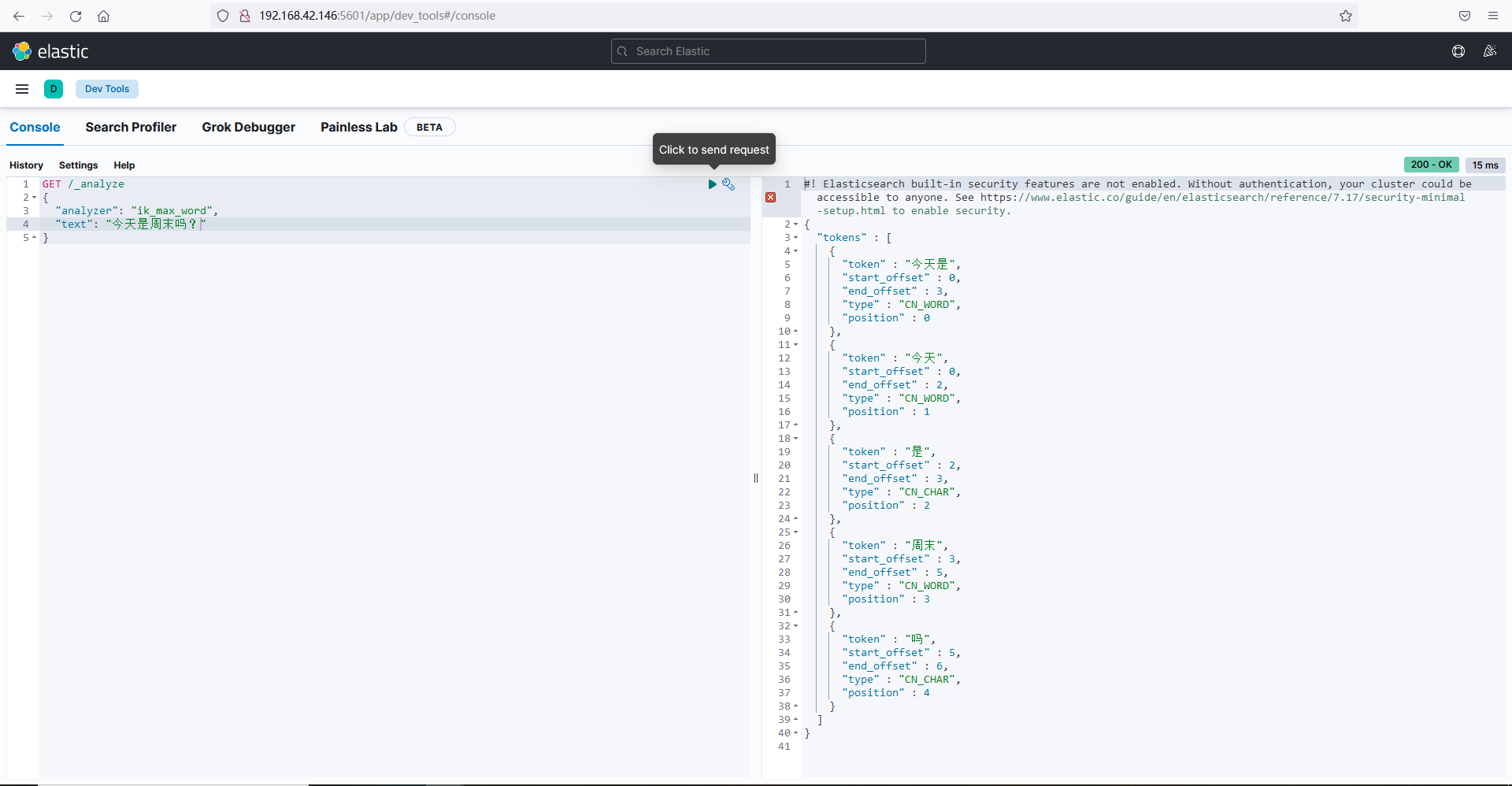
执行最细粒度的拆分,
- 在没有将“蓝瘦香菇”、“显眼包”放到扩展词典前,会拆分成单个汉字或者词语,
- 添加后将“蓝瘦香菇”和“显眼包”放到扩展词典,并重启elasticsearch服务之后,执行会“蓝瘦香菇”、“显眼包”显示成单词出现:
执行后如下:
GET /_analyze { "analyzer": "ik_max_word", "text": "蓝瘦香菇的作者真的是个显眼包,奥力给!" }
执行如下图:
4.4 停用词词典
在互联网项目中,在网络间传输的速度很快,所以很多语言是不允许在网络上传递的,如:关于宗教、政治等敏感词语,那么我们在搜索时也应该忽略当前词汇。IK分词器也提供了强大的停用词功能,让我们在索引时就直接忽略当前的停用词汇表中的内容。
停用词:有些词在文本中出现的频率非常高。但对本文的语义产生不了多大的影响。例如英文的a、 an、the、of等。或中文的”的、了、呢等”。这样的词称为停用词。停用词经常被过滤掉,不会被进行索引。在检索的过程中,如果用户的查询词中含有停用词,系统会自动过滤掉。停用词可以加快索引的速度,减少索引库文件的大小。
4.4.1.IKAnalyzer.cfg.xml配置文件内容添加:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典--> <entry key="ext_dict">ext.dic</entry> <!--用户可以在这里配置自己的扩展停止词字典 *** 添加停用词词典--> <entry key="ext_stopwords">stopword.dic</entry> </properties>
4.4.2.在 stopword.dic 添加停用词
嗯
的
了
嘤
4.4.3.重启elasticsearch
# 重启服务
docker restart es
# 查看 日志
docker logs -f es
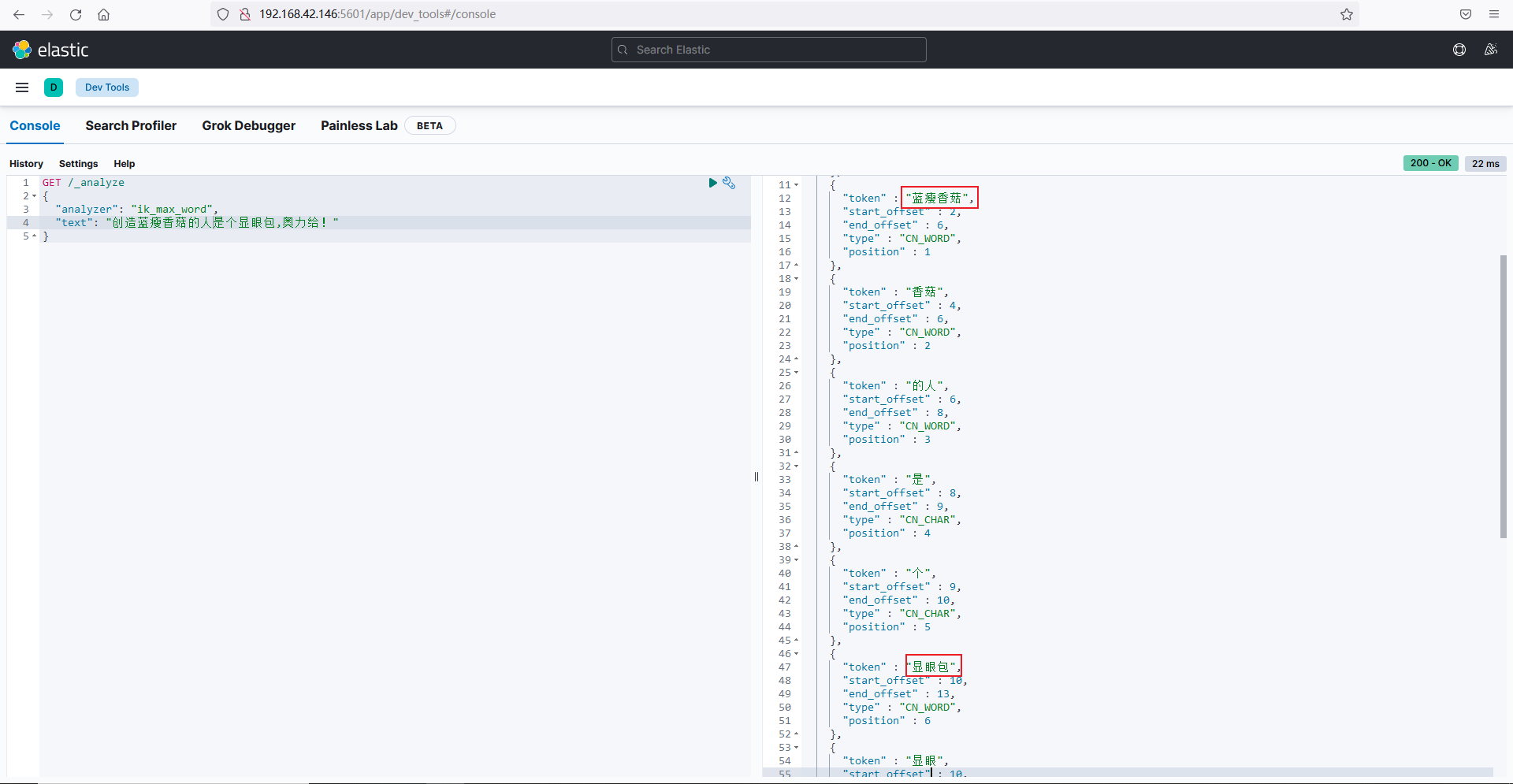
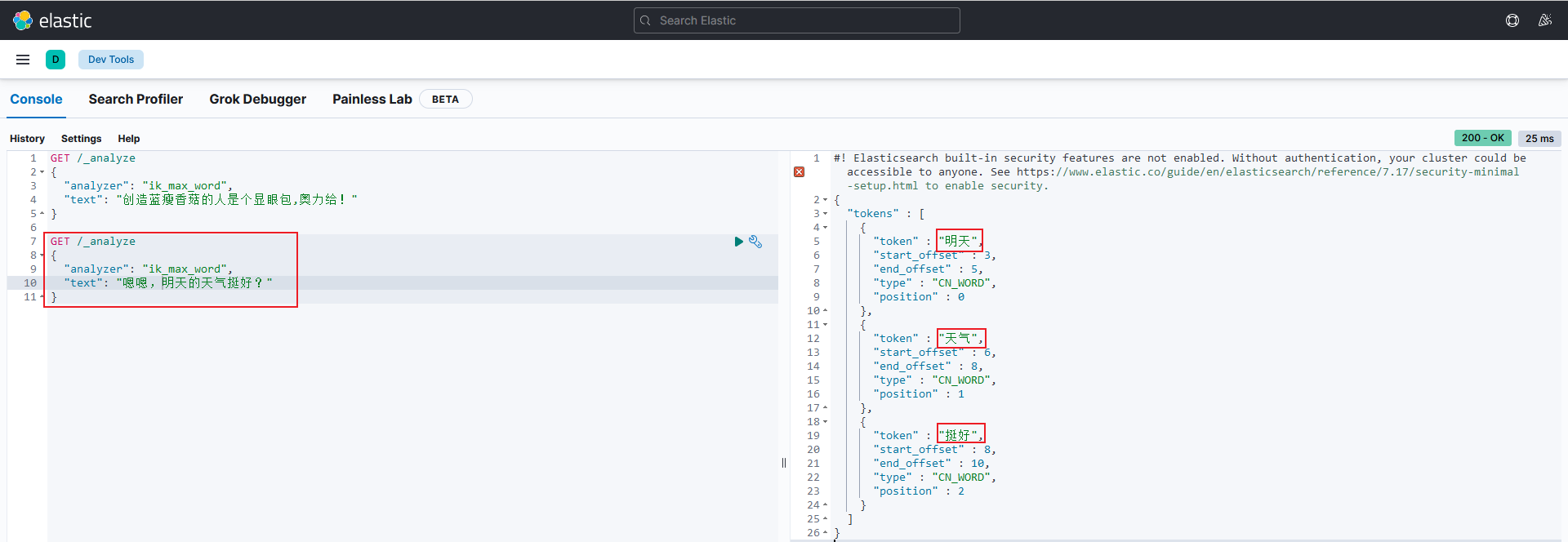
4.4.4.测试效果,
执行如下:
GET /_analyze { "analyzer": "ik_max_word", "text": "嗯嗯,明天的天气挺好?" }
之前的配置中停用了嗯、的等字,所以在检索的时候就不会再出现,如下图:
4.5.同义词典
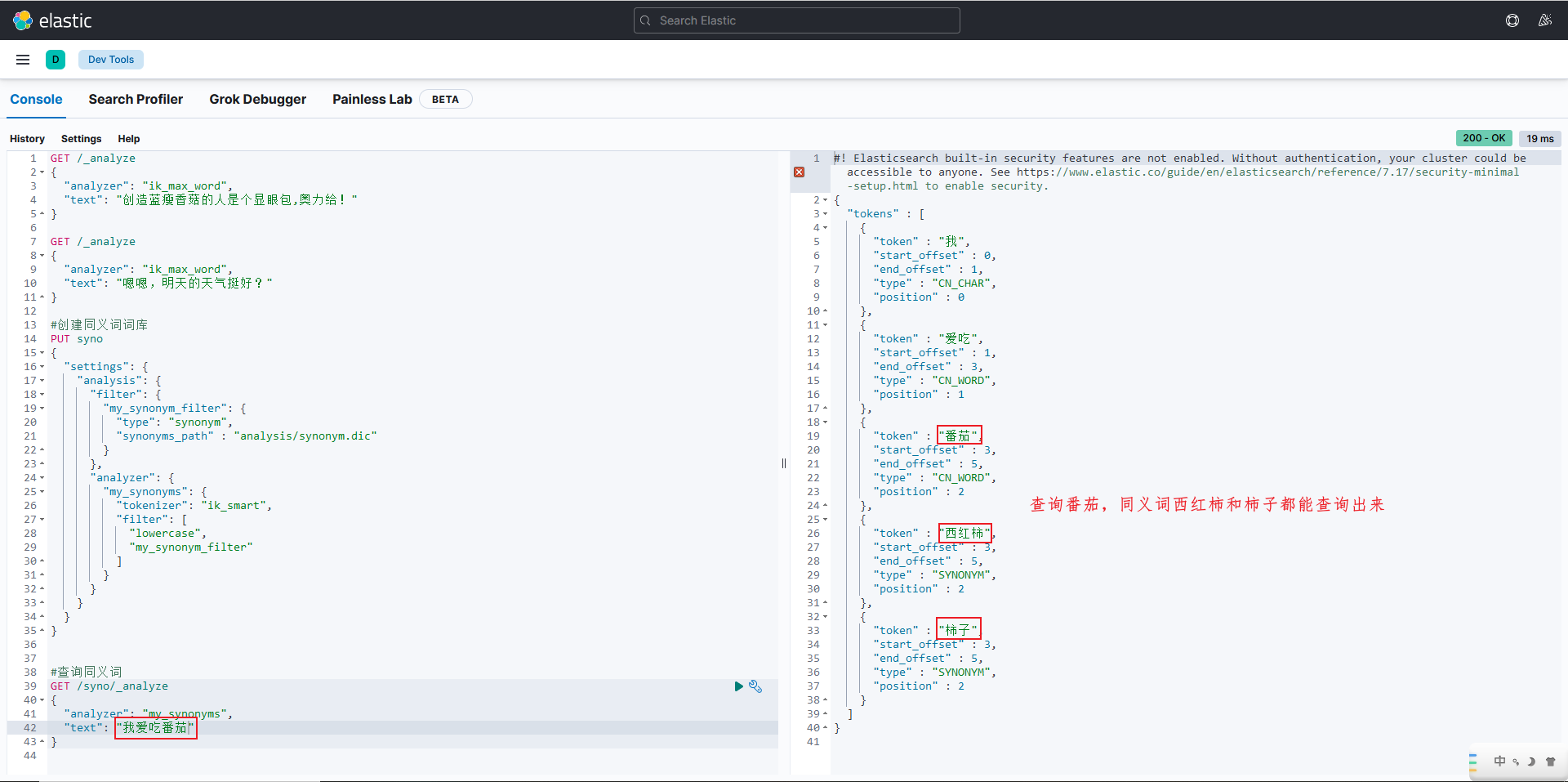
同义词:意思相同的,“番茄”和“西红柿”,查询“番茄”的时候,把带有“西红柿”的数据一起查出来,这种叫做同义词查询,
4.5.1.先进入到es容器,创建目录
# 进入到es的配置路径 cd /usr/share/elasticsearch/config/ # 创建路径,后续同义词词典保存在这里 mkdir analysis
4.5.2.在创建配置IK同义词(服务器中),创建名为synonym.dic的文件,输入下面同义词,并保存
番茄,西红柿,柿子
土豆,马铃薯
4.5.3.将同义词文件synonym.dic拷贝到容器
docker cp synonym.dic es:/usr/share/elasticsearch/config/analysis
4.5.4.重启容器
然后重启elasticsearch会自动加载相近词
docker restart db562acdab85 9d596d3672ab
4.5.5.打开kibana输入以下命令测试
注意先要创建同义词库,才可以查询同义词库
#创建同义词词库 PUT syno { "settings": { "analysis": { "filter": { "my_synonym_filter": { "type": "synonym", "synonyms_path" : "analysis/synonym.dic" } }, "analyzer": { "my_synonyms": { "tokenizer": "ik_smart", "filter": [ "lowercase", "my_synonym_filter" ] } } } } } #查询同义词 GET /syno/_analyze { "analyzer": "my_synonyms", "text": "我爱吃土豆" } #删除数据库 DELETE syno
创建词库后,执行查询同义词结果如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号