MyBatis环境搭建初次使用
一、创建maven项目导入相关依赖
1.从maven学习之后使用框架都是分三步走
- 使用maven导入依赖
- 处理相关配置文件
- 开发项目业务代码
2.先创建一个空项目,用于存放后面Mybatis相关项目模块,并且创建一个meven模块
3.给创建的项目设置自己安装的maven
4.检查项目模块目录结构是否有缺失
5.在pom.xml中导入MyBatis相关依赖jar文件
下面引入的依赖从https://mvnrepository.com/网站获取即可
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.mybatis01</groupId> <artifactId>mybatis01</artifactId> <version>1.0-SNAPSHOT</version> <dependencies> <!-- MySQL连接 --> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>8.0.28</version> </dependency> <!--mybatis--> <dependency> <groupId>org.mybatis</groupId> <artifactId>mybatis</artifactId> <version>3.5.9</version> </dependency> <!--Junit5相关测试--> <!--JUnit Jupiter测试引擎的实现,仅仅在运行时需要。--> <dependency> <groupId>org.junit.jupiter</groupId> <artifactId>junit-jupiter-engine</artifactId> <version>5.7.0</version> <scope>test</scope> </dependency> <!--JUnit Vintage测试引擎实现,允许在新的JUnit Platform上运行低版本的JUnit测试,即那些以JUnit 3或JUnit 4风格编写的测试。 非必须 --> <dependency> <groupId>org.junit.vintage</groupId> <artifactId>junit-vintage-engine</artifactId> <version>5.7.0</version> <scope>test</scope> </dependency> <!--编写测试 和 扩展 的JUnit Jupiter API。--> <dependency> <groupId>org.junit.jupiter</groupId> <artifactId>junit-jupiter-api</artifactId> <version>5.7.0</version> </dependency> </dependencies> </project>
注意:在idea新版本中引入之后需要点击右上角的Load meaven changes 或者使用快捷键Ctrl+shirt+O才会自动导入上述依赖
二、准备数据库,包结构和实体类
2.1.在MySQL数据库中新建数据库和表
创建数据mydb,在里面创建表dept:
DROP TABLE IF EXISTS `dept`; CREATE TABLE `dept` ( `deptno` int(11) NOT NULL, `dname` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL, `loc` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL, PRIMARY KEY (`deptno`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic; SET FOREIGN_KEY_CHECKS = 1;
2.2.给上述的表创建实体类
在Java目录下创建com.augus包,在下面创建dao子包,用于存放实体类,实体类对应的就是表,需要包含一下内容:
- 属性通过private修饰
- getter、setter方法
- toString方法
- 空参构造器、有参构造器
public class Dept implements Serializable { private Integer deptno; private String dname; private String loc; public Dept() { } public Dept(Integer deptno, String dname, String loc) { this.deptno = deptno; this.dname = dname; this.loc = loc; } public Integer getDeptno() { return deptno; } public void setDeptno(Integer deptno) { this.deptno = deptno; } public String getDname() { return dname; } public void setDname(String dname) { this.dname = dname; } public String getLoc() { return loc; } public void setLoc(String loc) { this.loc = loc; } @Override public String toString() { return "Dept{" + "deptno=" + deptno + ", dname='" + dname + '\'' + ", loc='" + loc + '\'' + '}'; } }
实体类需要实现 Serializable 序列化接口接口原因如下:
- 序列化:将对象状态信息转化成可以存储或传输的形式的过程(Java中就是将对象转化成字节序列byte[]的过程)
- 反序列化:从存储文件中恢复对象的过程(Java中就是通过字节序列转化成对象的过程)
- Java中对象都是存储在内存中,准确地说是JVM的堆或栈内存中,可以各个线程之间进行对象传输,但是无法在进程之间进行传输。另外如果需要在网络传输中传输对象也没有办法,同样内存中的对象也没有办法直接保存成文件。
- 所以需要对对象进行序列化,序列化对象之后一个个的Java对象就变成了字节序列,而字节序列是可以传输和存储的。而反序列化就可以通过序列化生产的字节序列再恢复成序列化之前的对象状态及信息。
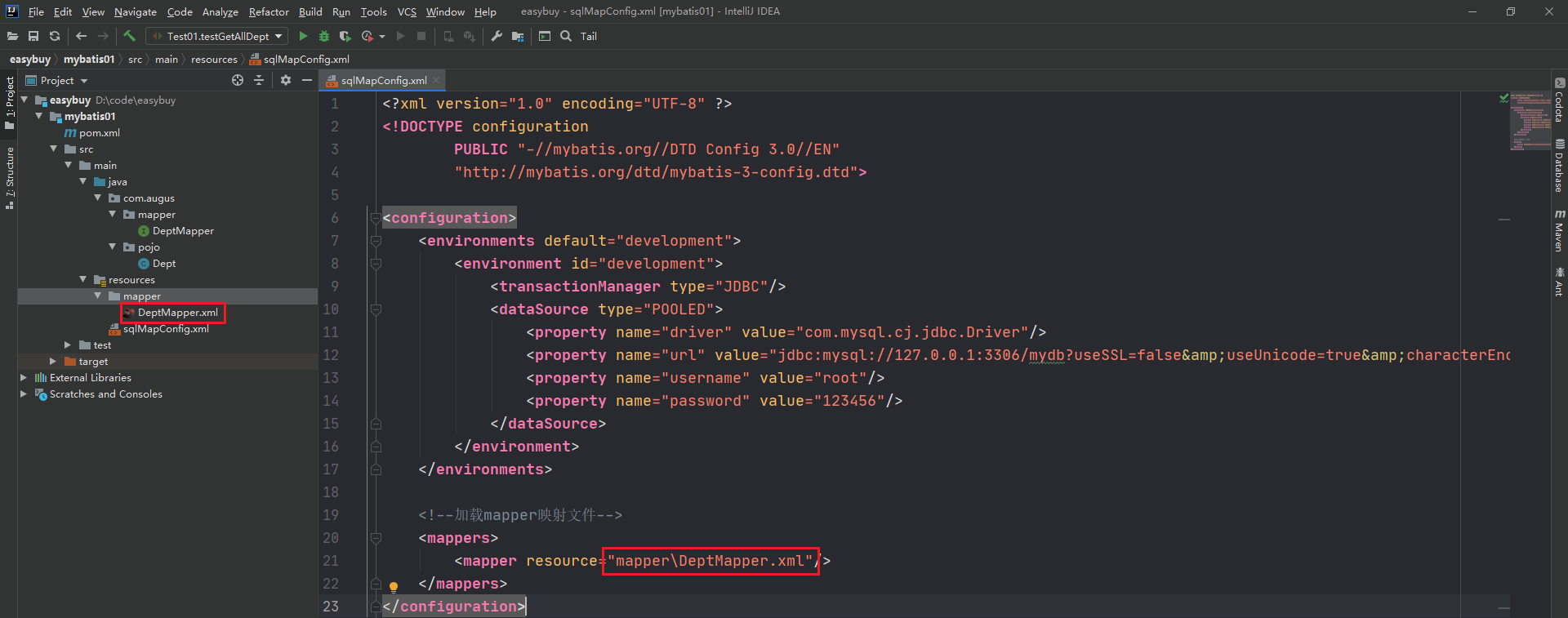
2.3.在resources目录下准备sqlMapConfig.xml 核心配置文件
这里说明了连接的数据库的信息如下:
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd"> <configuration> <environments default="development"> <environment id="development"> <transactionManager type="JDBC"/> <dataSource type="POOLED"> <property name="driver" value="com.mysql.cj.jdbc.Driver"/> <property name="url" value="jdbc:mysql://127.0.0.1:3306/mydb?useSSL=false&useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai"/> <property name="username" value="root"/> <property name="password" value="123456"/> </dataSource> </environment> </environments> <!--加载mapper映射文件--> <mappers> <mapper resource="mapper\DeptMapper.xml"/> </mappers> </configuration>
三、准备Mapper映射文件和核心配置文件
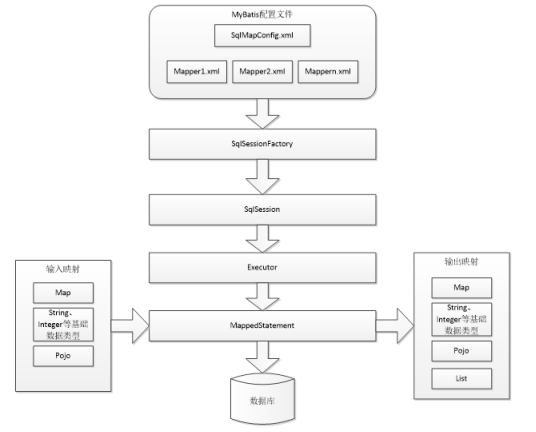
3.1.创建DeptMapper接口文件
在Java下的com.augus包下创建mapper包,创建接口文件DeptMapper,内容如下:
public interface DeptMapper { //查询所有的部门信息,返回的是多条数据,所以返回成一个dept的list集合 List<Dept> findAllDept(); }
3.2.创建DeptMapper.xml文件
在resources目录下创建文件夹mapper,里面存放mapper映射文件,在映射文件中编写SQL对应接口的功能,创建的DeptMapper.xml内容如下
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <!-- namespace这里需要对应接口的路径 可以理解成要实现的SQL定义在那个接口文件中 --> <mapper namespace="com.augus.mapper.DeptMapper"> <!--需要注意的是每一个配置文件只是mapper中的内容有区别--> <!-- 要实现查询出来所有的部门信息的接口 List<Dept> findAllDept(); select标签是查询,id属性的值必须和DeptMapper中定义的方法名 resultType="com.augus.pojo.Dept" 返回值类型这里指定是那个这pojo包下的Dept类 --> <select id="findAllDept" resultType="com.augus.pojo.Dept"> select * from dept </select> </mapper>
上述配置完成后,需要在pom.xml中添加如下内容,在编译的时候,java包下的.xml文件不会被编译,所以需在pom.xml中添加下面这个标签,指定需要编译xml文件
<build> <resources> <resource> <directory>src/main/java</directory> <includes> <include>**/*.xml</include> </includes> </resource> <resource> <directory>src/main/resources</directory> <includes> <include>**/*.xml</include> <include>**/*.properties</include> </includes> </resource> </resources> </build>
其次需要在sqlSession.xml文件中指定mapper映射文件
四、运行测试
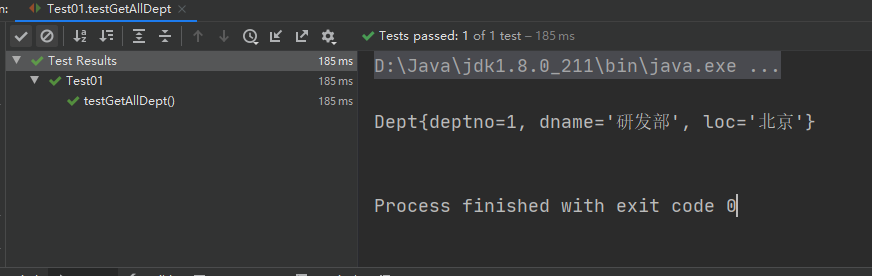
在test目录下创建测试代码并运行,测试代码内容如下
public class Test01 { private static SqlSession sqlSession; @BeforeAll static void init(){ //创建一个对象:参照了XML 文档或上面讨论过的更特定的 mybatis-config.xml 文件的 Reader 实例 SqlSessionFactoryBuilder factoryBuilder = new SqlSessionFactoryBuilder(); InputStream resourceAsStream; try { //Resources.getResourceAsStream对于简单的只读二进制或文本数据,加载为 Stream。 resourceAsStream = Resources.getResourceAsStream("sqlMapConfig.xml"); /* SqlSessionFactory SqlSessionFactory 有六个方法创建 SqlSession 实例。通常来说,当你选择这些方法时你需要考虑以下几点: 事务处理:需要在 session 使用事务或者使用自动提交功能(auto-commit)吗?(通常意味着很多数据库和/或 JDBC 驱动没有事务) 连接:需要依赖 MyBatis 获得来自数据源的配置吗?还是使用自己提供的配置? 执行语句:需要 MyBatis 复用预处理语句和/或批量更新语句(包括插入和删除)吗? */ SqlSessionFactory build = factoryBuilder.build(resourceAsStream); /* 默认的 openSession()方法没有参数,它会创建有如下特性的 SqlSession: 会开启一个事务(也就是不自动提交)。 将从由当前环境配置的 DataSource 实例中获取 Connection 对象。 事务隔离级别将会使用驱动或数据源的默认设置。 预处理语句不会被复用,也不会批量处理更新。 */ sqlSession = build.openSession(); } catch (IOException ioException) { ioException.printStackTrace(); } } @Test public void testGetAllDept(){ // 这里写需要执行的SQL,写的时候DeptMapper.xml中select标签id属性的值 List<Object> findAllDept = sqlSession.selectList("findAllDept"); for (Object o : findAllDept) { System.out.println(o); } } }
执行后结果输出如下:
五、lombok
Java 语言的排名一直名列前茅,但是有时候我们的代码与业务无关,并且过于冗长,并例如在实体类中,经常写很多
getter 或者 setter 方法。这时候我们使用 Lombok 来使用一些功能,使其代替我们把 Java 字节码自动编译到 class 文件中。5.1.安装lombok插件后,然后重启idea
Lombok项目是一个java库,它可以自动插入到编辑器和构建工具中,增强java的性能。不需要再写getter、setter或equals方法,只要有一个注解,你的类就有一个功能齐全的构建器、自动记录变量等等
5.2.导入lombok依赖后,单独设置启用注解处理
注意下面的启动注释处理,一定要勾选才可以

5.3.添加依赖
在pom.xml中添加lombok依赖如下:
<!--lombok--> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.18.24</version> <scope>provided</scope> </dependency>
5.4.实体类修改代码
下面介绍一下常用的几个注解:
- @Setter 注解在类或字段,注解在类时为所有字段生成setter方法,注解在字段上时只为该字段生成setter方法。
- @Getter 使用方法同上,区别在于生成的是getter方法。
- @ToString 注解在类,添加toString方法。
- @EqualsAndHashCode 注解在类,生成hashCode和equals方法。
- @NoArgsConstructor 注解在类,生成无参的构造方法。
- @RequiredArgsConstructor 注解在类,为类中需要特殊处理的字段生成构造方法,比如final和被@NonNull注解的字段。
- @AllArgsConstructor 注解在类,生成包含类中所有字段的构造方法。
- @Data 注解在类,生成setter/getter、equals、canEqual、hashCode、toString方法,如为final属性,则不会为该属性生成setter方法。
- @Slf4j 注解在类,生成log变量,严格意义来说是常量。private static final Logger log = LoggerFactory.getLogger(UserController.class);
package com.augus01.pojo; import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; import java.io.Serializable; @Data //@Data 注解的主要作用是提高代码的简洁,使用这个注解可以省去代码中大量的get()、 set()、 toString()等方法;但是需要先导入lombok @AllArgsConstructor //使用lombok后生成一个构造方法 @NoArgsConstructor //使用lombok后生成无参数的构造方法 //实体类需要实现Serializable接口 public class Dept implements Serializable { private Integer deptno; private String dname; private String loc; }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号