Hive项目实战
一、需求分析
1.1. 背景介绍
在线社交平台每天都会有大量的用户在线,会出现大量的聊天数据,通过对聊天数据的统计分析,可以更好的对用户构建精准的用户画像,为用户提供更好的服务以及实现高 ROI 的平台运营推广,给公司的发展决策提供精确的数据支撑。后续将基于一个社交平台 App 的用户数据,完成相关指标的统计分析并结合 BI 工具对指标进行可视化展现。
1.2.目标
基于 Hadoop 和 Hive 实现聊天数据统计分析,构建聊天数据分析报表
1.3.需求
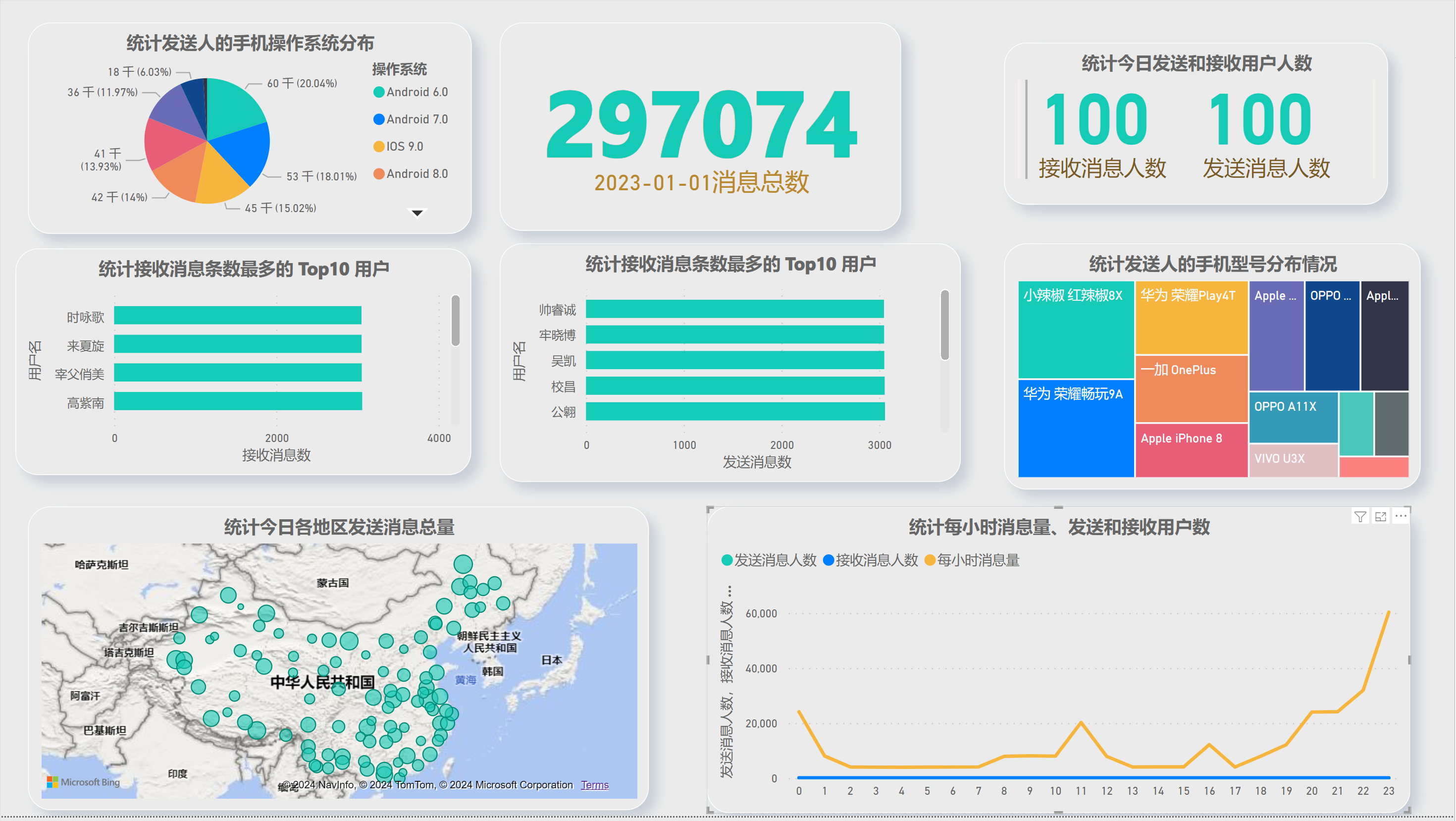
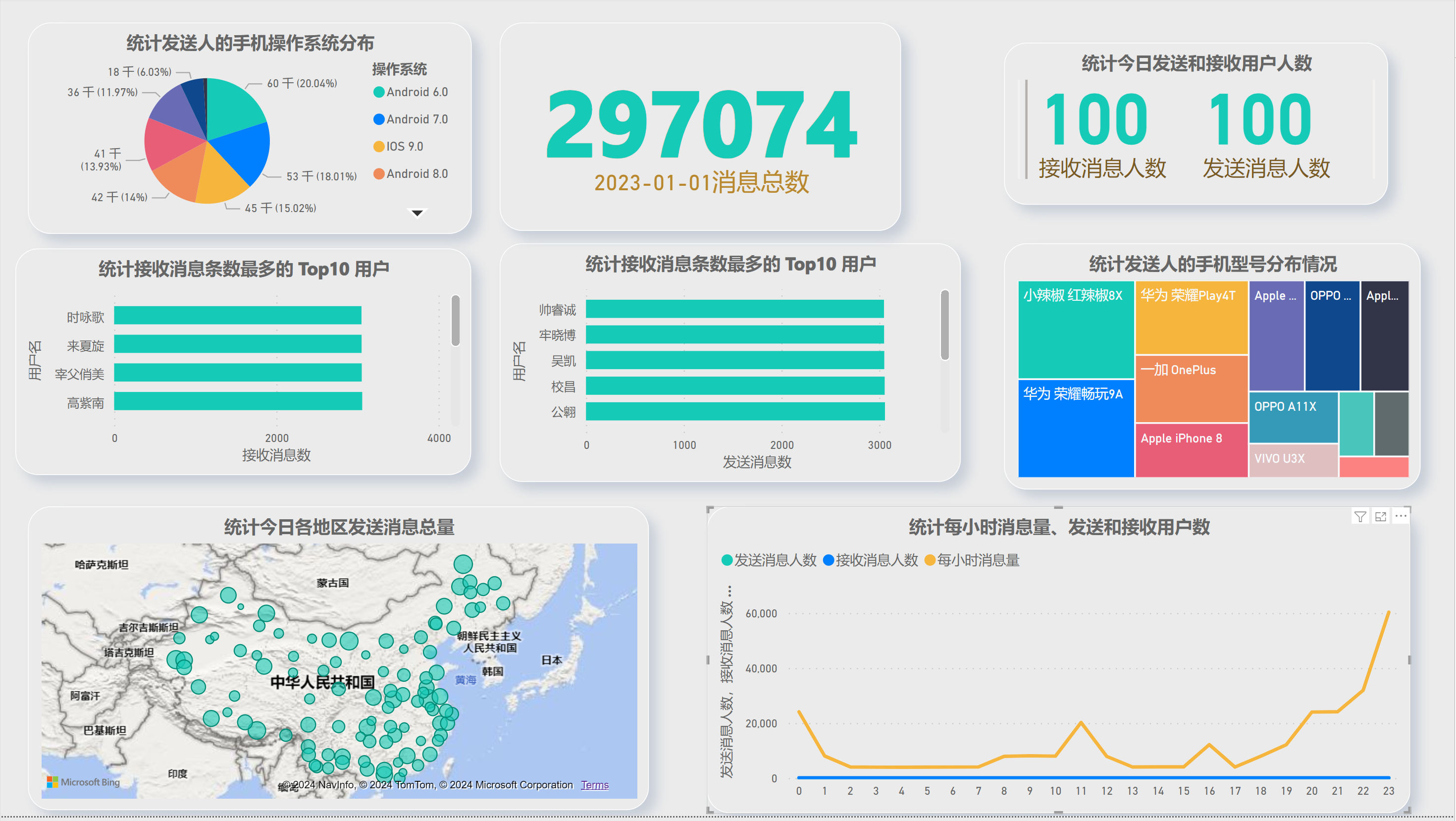
- 统计今日总消息量
- 统计今日每小时消息量、发送和接收用户数
- 统计今日各地区发送消息数据量
- 统计今日发送消息和接收消息的用户数
- 统计今日发送消息最多的 Top10 用户
- 统计今日接收消息最多的 Top10 用户
- 统计发送人的手机型号分布情况
- 统计发送人的设备操作系统分布情况
1.4.数据内容
- 数据大小: 30 万条数据
- 列分隔符: Hive 默认分隔符’ \001’
1.5.建库建表导入数据
- 创建数据库
-- 如果数据库已存在就删除 drop database if exists db_msg cascade ; -- 创建数据库 create database db_msg ; -- 切换数据库 use db_msg ; -- 列举数据库 show databases ;
- 创建数据表
-- 如果表已存在就删除 drop table if exists db_msg.tb_msg_source ; -- 建表 create table db_msg.tb_msg_source( msg_time string comment " 消息发送时间 ", sender_name string comment " 发送人昵称 ", sender_account string comment " 发送人账号 ", sender_sex string comment " 发送人性别 ", sender_ip string comment " 发送人 ip 地址 ", sender_os string comment " 发送人操作系统 ", sender_phonetype string comment " 发送人手机型号 ", sender_network string comment " 发送人网络类型 ", sender_gps string comment " 发送人的 GPS 定位 ", receiver_name string comment " 接收人昵称 ", receiver_ip string comment " 接收人 IP", receiver_account string comment " 接收人账号 ", receiver_os string comment " 接收人操作系统 ", receiver_phonetype string comment " 接收人手机型号 ", receiver_network string comment " 接收人网络类型 ", receiver_gps string comment " 接收人的 GPS 定位 ", receiver_sex string comment " 接收人性别 ", msg_type string comment " 消息类型 ", distance string comment " 双方距离 ", message string comment " 消息内容 " );
导入数据
load data local inpath '/home/hadoop/chat_data-30W.csv' overwrite into table tb_msg_source;
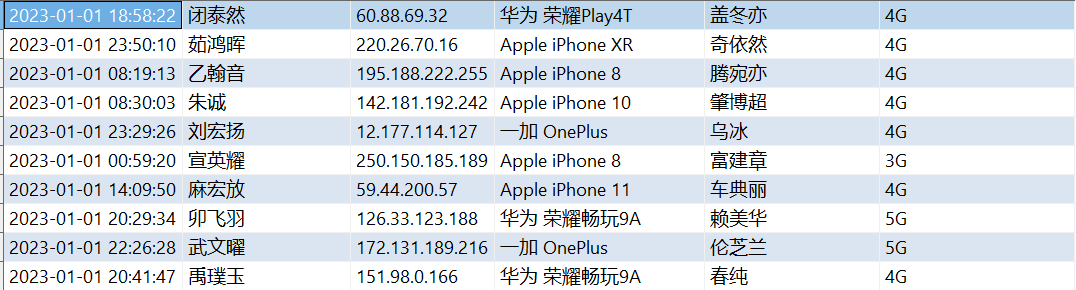
验证数据是否加载成功:
SELECT msg_time, sender_name, sender_ip, sender_phonetype, receiver_name, receiver_network FROM tb_msg_source limit 10;
如下:
列分隔符:Hive默认分隔符’\001’数据字典及样例数据
二、ETL 数据清洗
2.1.数据问题
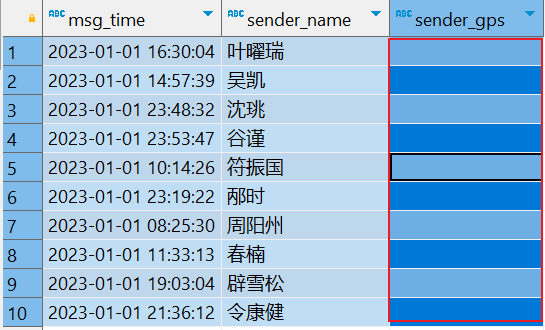
问题 1 :当前数据中,有一些数据的字段为空,不是合法数据
select msg_time,sender_name,sender_gps from db_msg.tb_msg_source where length(sender_gps) = 0 limit 10
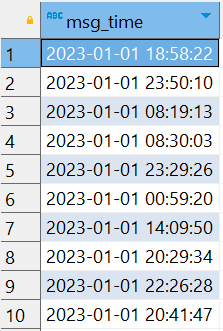
问题 2 :需求中,需要统计每天、每个小时的消息量,但是数据中没有天和小时字段,只有整体时间字段,不好处理
SELECT msg_time FROM tb_msg_source limit 10;
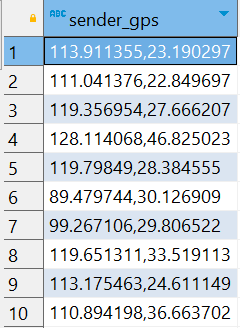
问题 3 :需求中,需要对经度和维度构建地区的可视化地图,但是数据中 GPS 经纬度为一个字段,不好处理
SELECT sender_gps FROM tb_msg_source limit 10;
2.2.需求分析
- 需求 1 :对字段为空的不合法数据进行过滤
- where 过滤
- 需求 2 :通过时间字段构建天和小时字段
- date hour 函数
- 需求 3 :从 GPS 的经纬度中提取经度和维度
- split 函数
- 需求 4 :将 ETL 以后的结果保存到一张新的 Hive 表中
创建一张新表,用于保存处理后的数据
create table db_msg.tb_msg_etl( msg_time string comment " 消息发送时间 ", sender_name string comment " 发送人昵称 ", sender_account string comment " 发送人账号 ", sender_sex string comment " 发送人性别 ", sender_ip string comment " 发送人 ip 地址 ", sender_os string comment " 发送人操作系统 ", sender_phonetype string comment " 发送人手机型号 ", sender_network string comment " 发送人网络类型 ", sender_gps string comment " 发送人的 GPS 定位 ", receiver_name string comment " 接收人昵称 ", receiver_ip string comment " 接收人 IP", receiver_account string comment " 接收人账号 ", receiver_os string comment " 接收人操作系统 ", receiver_phonetype string comment " 接收人手机型号 ", receiver_network string comment " 接收人网络类型 ", receiver_gps string comment " 接收人的 GPS 定位 ", receiver_sex string comment " 接收人性别 ", msg_type string comment " 消息类型 ", distance string comment " 双方距离 ", message string comment " 消息内容 ", msg_data string comment " 消息日 ", msg_hour string comment " 消息小时 ", sender_lng double comment " 经度 ", sender_lat double comment " 纬度 " );
2.3.实现数据清洗
数据清洗,导入到新创建的表中
INSERT OVERWRITE TABLE db_msg.tb_msg_etl SELECT *, to_date(msg_time) as msg_data, HOUR(msg_time) as msg_hour, split(sender_gps, ',')[0] AS sender_lng, split(sender_gps, ',')[1] AS sender_lat FROM db_msg.tb_msg_source WHERE LENGTH(sender_gps) > 0;
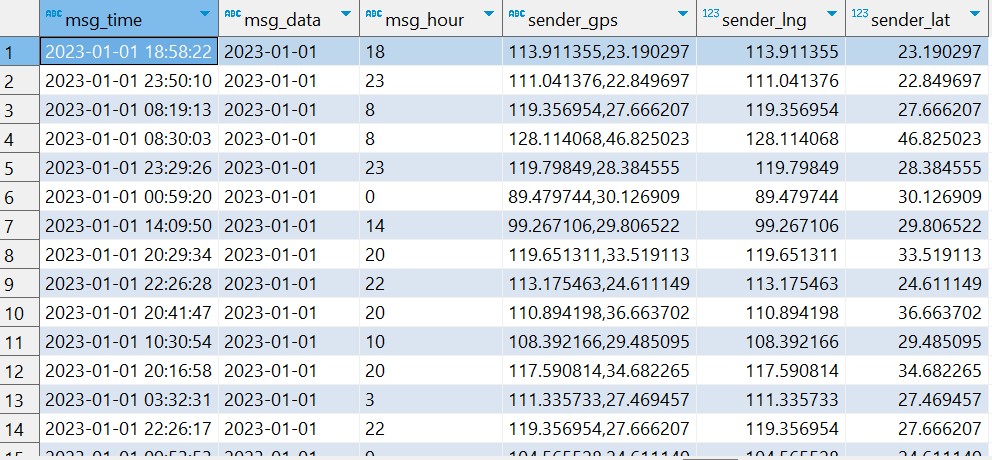
查看结果
SELECT msg_time,msg_data,msg_hour,sender_gps,sender_lng,sender_lat FROM db_msg.tb_msg_etl
2.4. ETL说明
上面完成了从表 tb_msg_source 查询数据进行数据过滤和转换,并将结果写入到: tb_msg_etl 表中的操作,这种操作本质上是一种简单的 ETL 行为。ETL :
- E : Extract ,抽取
- T :Transform ,转换
- L :Load ,加载
从 A 抽取数据 (E) ,进行数据转换过滤 (T) ,将结果加载到 B(L) ,就是 ETL ,ETL 在大数据系统数据清洗是非常常见的。
三、指标计算
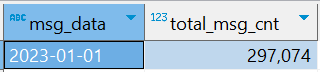
⑴.指标1 :统计今日消息总量
CREATE TABLE IF NOT EXISTS db_msg.tb_rs_total_msg_cnt COMMENT '每日消息总量' AS SELECT msg_data,COUNT(*) AS total_msg_cnt FROM db_msg.tb_msg_etl GROUP BY msg_data;
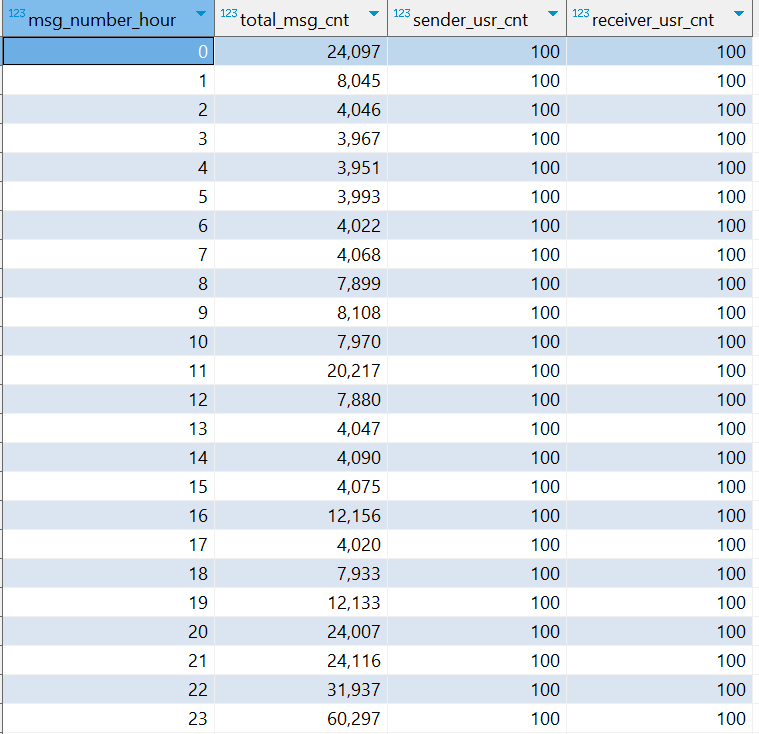
⑵.指标2 :统计每小时消息量、发送和接收用户数
-- CAST(msg_hour as int) AS msg_number_hour 将小时转换为数字,方便排序。排序则是为了后续可视化连续月份显示 CREATE TABLE IF NOT EXISTS db_msg.tb_rs_hour_msg_cnt COMMENT "每小时消息量趋势" AS SELECT CAST(msg_hour as int) AS msg_number_hour, COUNT(*) AS total_msg_cnt, COUNT(DISTINCT sender_account) AS sender_usr_cnt, COUNT(DISTINCT receiver_account) AS receiver_usr_cnt FROM db_msg.tb_msg_etl GROUP BY msg_hour ORDER BY msg_number_hour ASC;
⑶.指标3 :统计今日各地区发送消息总量
CREATE TABLE IF NOT EXISTS db_msg.tb_loc_cnt COMMENT '今日各地区发送消息总量' AS SELECT msg_data, sender_lng, sender_lat, COUNT(*) AS total_msg_cnt FROM db_msg.tb_msg_etl GROUP BY msg_data,sender_lng,sender_lat
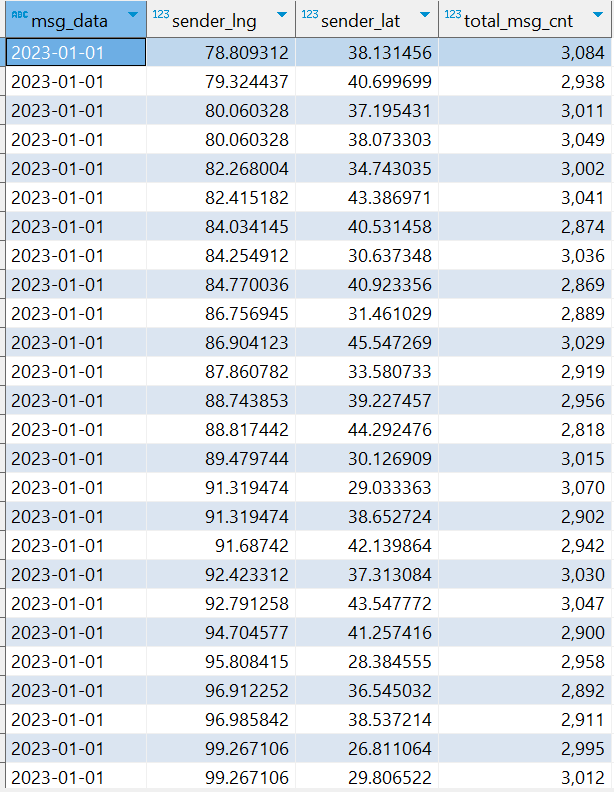
⑷.指标4 :统计今日发送和接收用户人数
CREATE TABLE IF NOT EXISTS db_msg.tb_rs_usr_cnt COMMENT '今日发送消息人数、接收消息人数' AS SELECT msg_data, COUNT(DISTINCT sender_account) AS sender_usr_cnt, COUNT(DISTINCT receiver_account) AS receiver_usr_cnt FROM db_msg.tb_msg_etl GROUP BY msg_data

⑸.指标 5 :统计发送消息条数最多的 Top10 用户
CREATE TABLE IF NOT EXISTS db_msg.tb_rs_s_user_top10 COMMENT '发送消息条数最多的Top10用户' AS SELECT sender_name AS username, COUNT(*) AS sender_msg_cnt FROM db_msg.tb_msg_etl GROUP BY sender_name ORDER BY sender_msg_cnt DESC LIMIT 10;
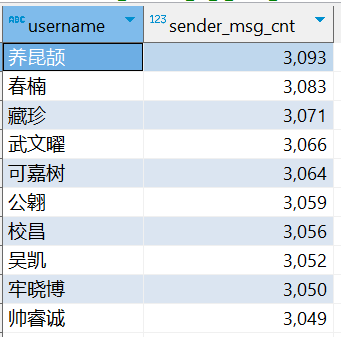
⑹.指标 6 :统计接收消息条数最多的 Top10 用户
CREATE TABLE IF NOT EXISTS db_msg.tb_rs_r_user_top10 COMMENT '接收消息条数最多的Top10 用户' AS SELECT receiver_name AS username, COUNT(*) AS receiver_msg_cnt FROM db_msg.tb_msg_etl GROUP BY receiver_name ORDER BY receiver_msg_cnt DESC LIMIT 10;

⑺.指标7 :统计发送人的手机型号分布情况
CREATE TABLE IF NOT EXISTS db_msg.tb_rs_sender_phone COMMENT '发送人的手机型号分布' AS SELECT sender_phonetype, COUNT(sender_account) AS cnt FROM db_msg.tb_msg_etl GROUP BY sender_phonetype
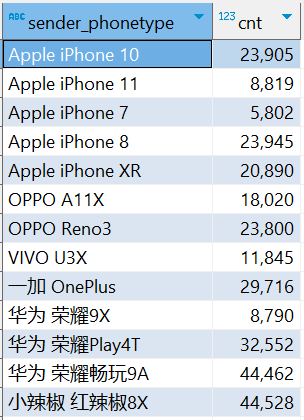
⑻.指标 8 :统计发送人的手机操作系统分布
CREATE TABLE IF NOT EXISTS db_msg.tb_rs_sender_os COMMENT '发送人的手机操作系统分布' AS SELECT sender_os, COUNT(sender_account) AS cnt FROM db_msg.tb_msg_etl GROUP BY sender_os
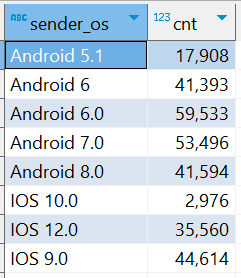
四、可视化展现
4.1.PowerBI连接Hive
⑴.由于目前PowerBI没有直接链接HIVE数据库的工具,在连接ClouderaHadoop大数据集群前,需要确保已经安装了最新的驱动程序。按照以下的步骤,安装对应的驱动程序,首先到Cloudera的官方网站下载对应的驱动,网站地址为:https://www.cloudera.com/downloads/connectors/hive/odbc/2-7-0.html,选择Hive的下载连接
⑵.双击运行下载的“ClouderaHiveODBC64.msi”安装程序,安装过程比较简单,默认设置即可
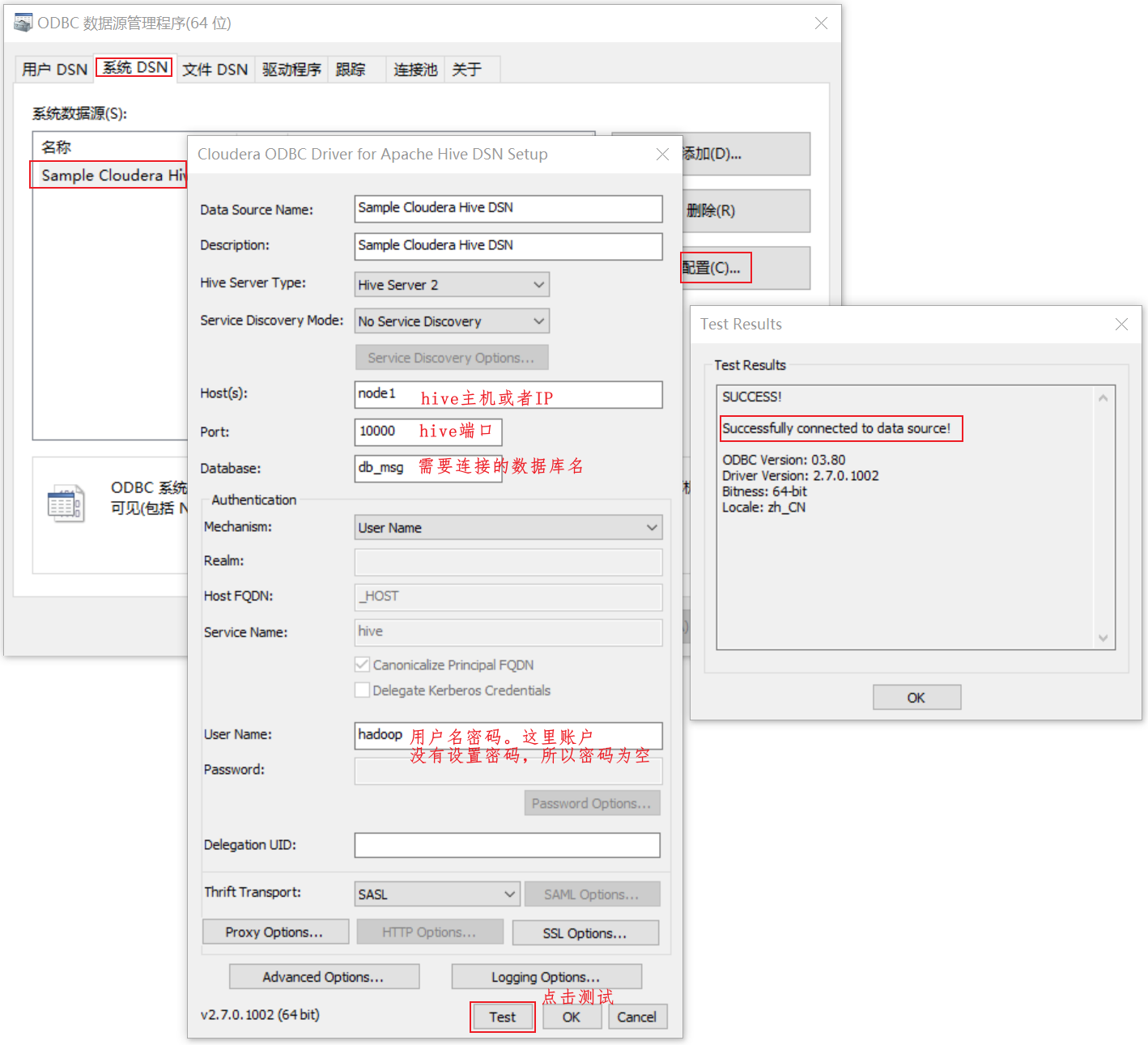
⑶.然后在电脑“ODBC数据源(64位)”中的“系统DSN”下,如果有“SampleClouderaHiveDSN”,说明安装过程没有问题。下面我们将检查一下,是否可以正常连接ClouderaHive集群,前提是连接前需要正常启动集群,如图所示,点击“Test”按钮,如果测试结果出现“SUCCESS!”,说明正常连接
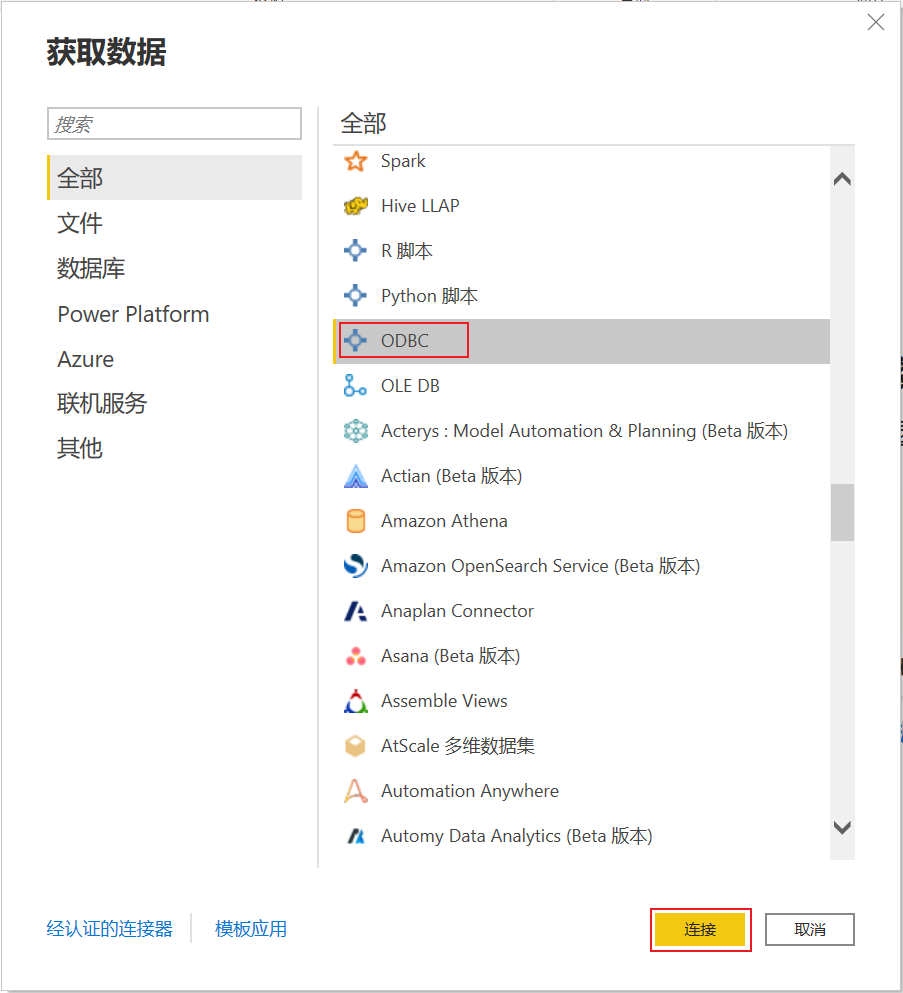
⑷.在power bi在获取数据中,点击更多。选择ODBC
⑸.数据源选择刚才配置好的hive数据库
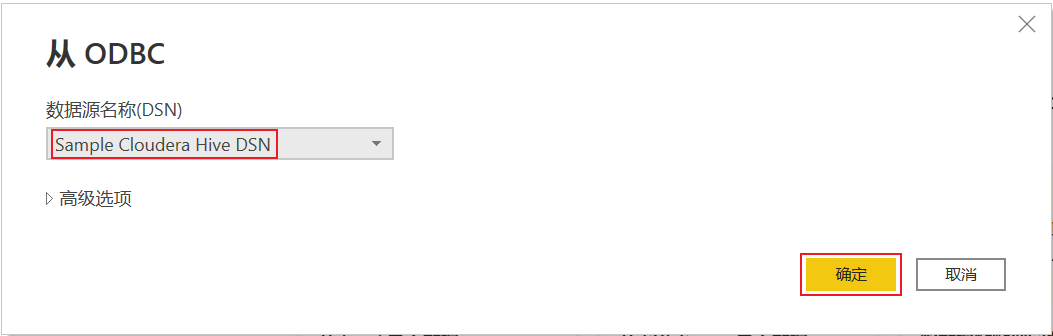
⑹.在弹出对话框中,数据库选项卡中输入用户名和密码(我的账户没有设置密码,密码为空即可),点击连接即可
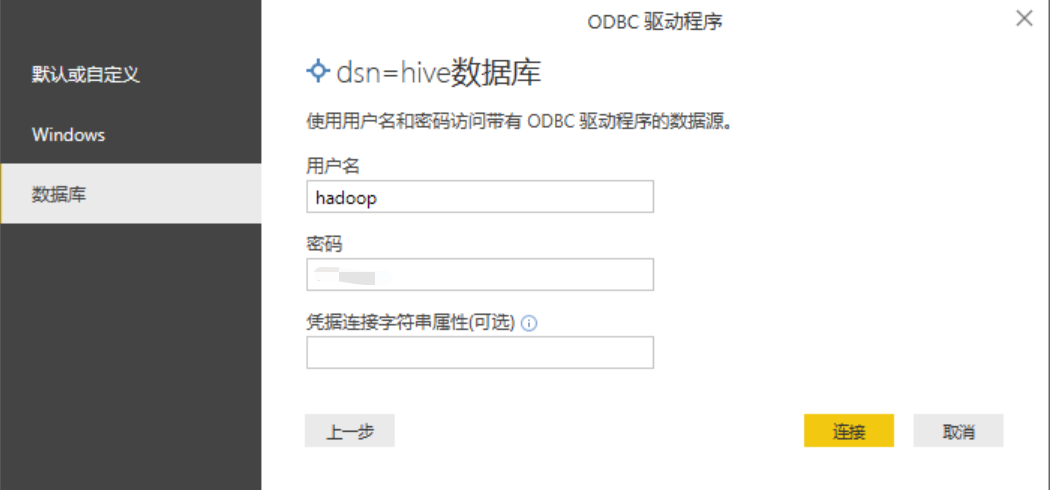
⑺.选择加载需要的表数据

4.2.PowerBI中

 浙公网安备 33010602011771号
浙公网安备 33010602011771号