Hive函数
一、Hive函数
1.1.函数分类
Hive的函数分为两大类:内置函数、用户定义函数UDF
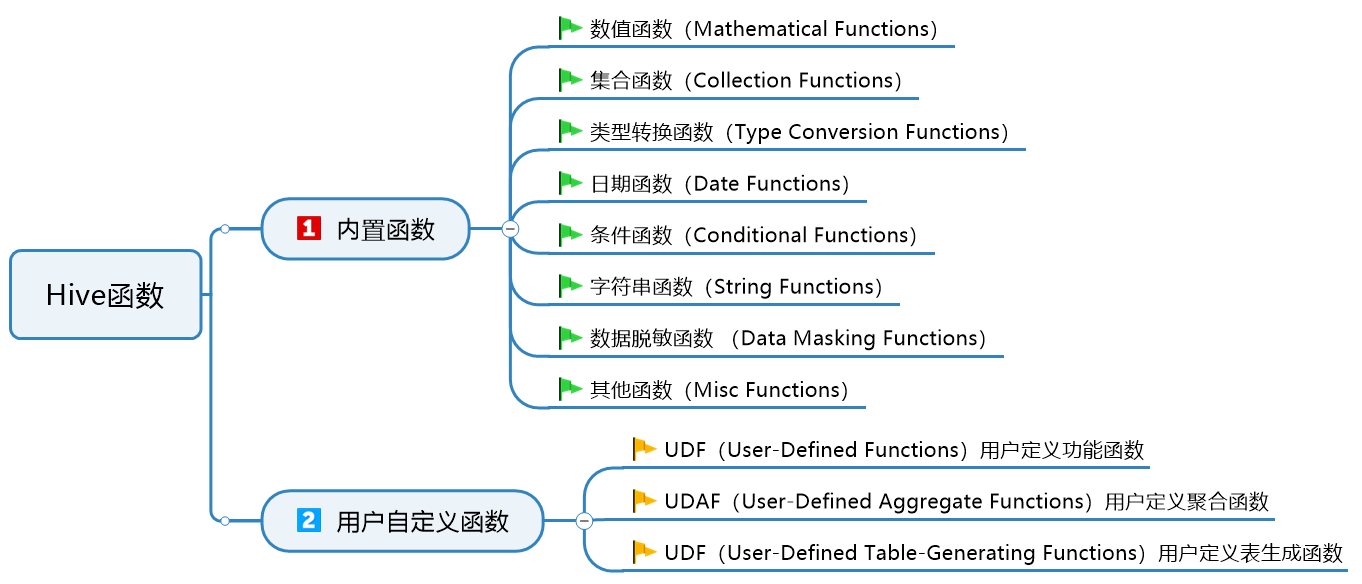
Hive 的函数共计有上百种,下面会挑选一些常用的进行讲解。
详细的函数使用可以参阅官方文档 (https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF#LanguageManualUDF-MathematicalFunctions)
1.2.查看函数列表
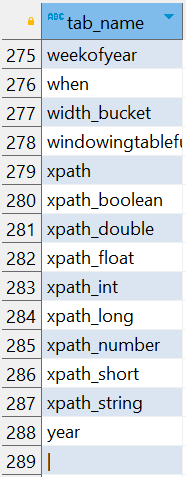
⑴.Hive有很多内置函数,通过 show functions 查看当下可用的所有函数:
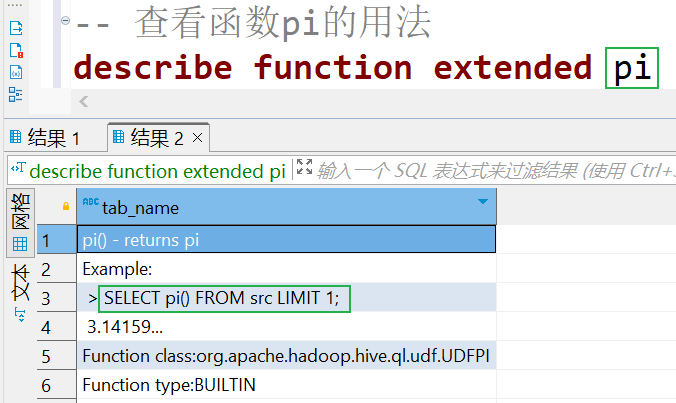
⑵.通过 describe function extended funcname 来查看函数的使用方式
二、内置函数
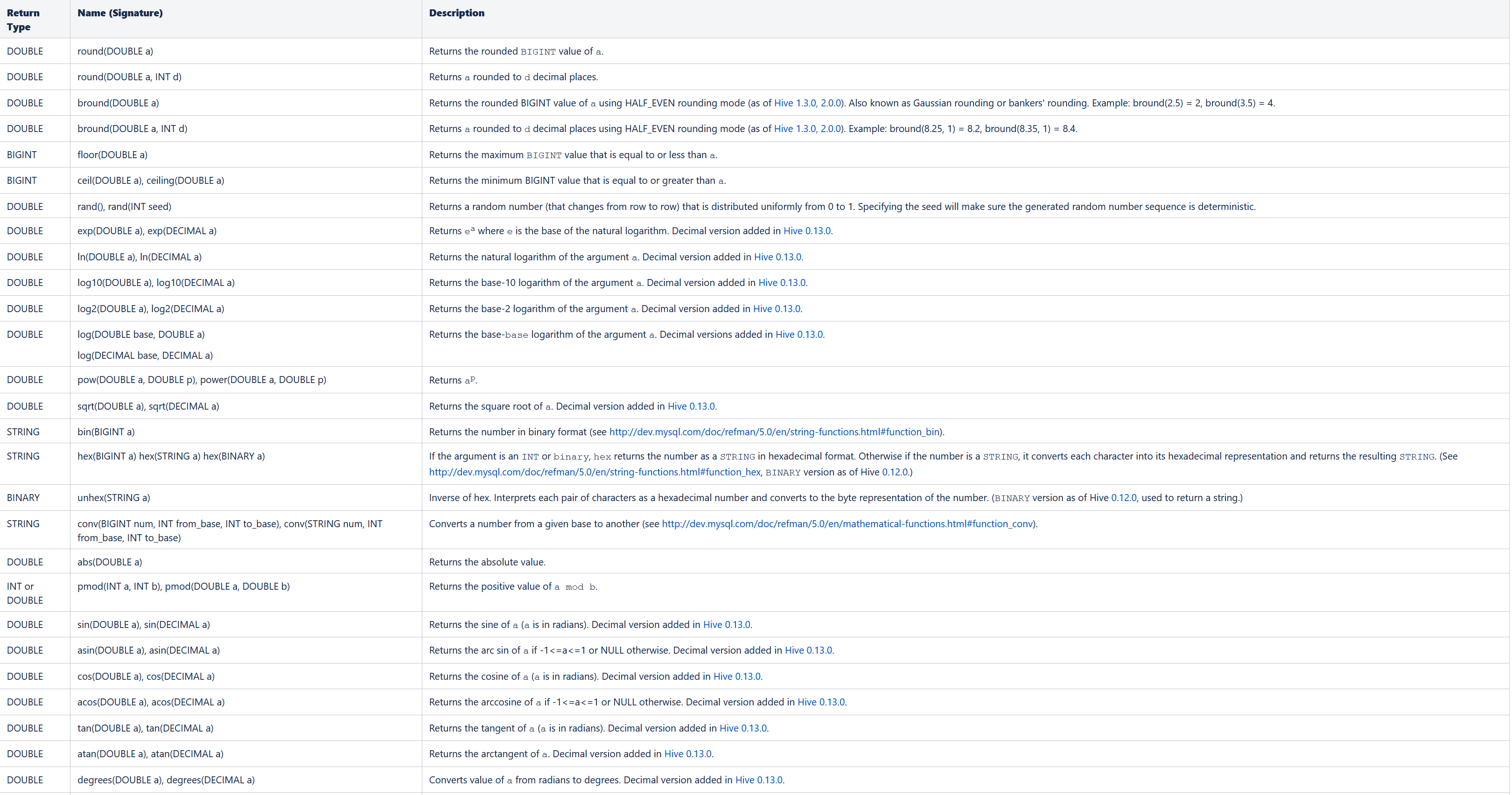
2.1.数值函数(Mathematical Functions)
----Mathematical Functions 数学函数 ------------- -- 取整函数 : round 返回 double 类型的整数值部分 (遵循四舍五入) select round(3.1415926); -- 指定精度取整函数 : round(double a, int d) 返回指定精度 d 的 double 类型 select round(3.1415926,4); -- 取随机数函数 : rand 每次执行都不一样 返回一个 0 到 1 范围内的随机数 select rand(); -- 指定种子取随机数函数 : rand(int seed) 得到一个稳定的随机数序列 select rand(3); -- 求数字的绝对值 select abs(-3); -- 得到 pi 值(小数点后 15 位精度) select pi();
2.2.集合函数(Collection Functions)
Hive 支持以下内置集合函数:
|
Return Type |
Name(Signature) |
Description |
|
int |
size(Map<K.V>) |
返回 map 类型的元素个数 |
|
int |
size(Array<T>) |
返回 array 类型的元素个数 |
|
array<K> |
map_keys(Map<K.V>) |
返回 map 内的全部 key (得到的是 array ) |
|
array<V> |
map_values(Map<K.V>) |
返回 map 内的全部 value (得到的是 array ) |
|
boolean |
array_contains(Array<T>, value) |
如果 array 包含指定 value ,返回 True |
|
array<t> |
sort_array(Array<T>) |
根据数组元素的自然顺序按升序对输入数组进行 |
案例:
-- 返回 map 类型的元素个数 SELECT name,size(members) FROM myhive.test_map; -- 返回 array 类型的元素个数 SELECT name,size(work_locations) FROM myhive.test_array; -- 返回 map 内的全部 key (得到的是 array ) SELECT name,map_keys(members) FROM myhive.test_map; -- 返回 map 内的全部 value (得到的是 array ) SELECT name,map_values(members) FROM myhive.test_map; -- 如果 array 包含指定 value ,返回 True SELECT * FROM myhive.test_array WHERE ARRAY_CONTAINS(work_locations,'beijing') ; -- 根据数组元素的自然顺序按升序对输入数组进行排序并返回它 SELECT name,sort_array(work_locations) FROM myhive.test_array;
2.3.类型转换函数(Type Conversion Functions)
Hive 支持以下类型转换函数:
| Return Type | Name(Signature) | Description |
|
binary |
binary(string|binary) |
将给定字符串转换为二进制 |
|
Expected "=" to follow "type" |
cast(expr as <type>) |
将表达式 expr 的结果转换为给定 |
示例:
-- 将Hadoop转换为二进制 SELECT BINARY('hadoop') -- 指定类型转换,转换成bigint类型 SELECT CAST('1' as bigint)
2.4.日期函数(Date Functions)
The following built-in date functions are supported in Hive:
|
Return Type |
Name(Signature) |
Description |
|
pre 2.1.0: string 2.1.0 on: date |
to_date(string timestamp) |
|
|
int |
year(string date) |
返回日期或时间戳字符串的年份部分:year("1970-01-01 00:00:00") = 1970, year("1970-01-01") = 1970. |
|
int |
quarter(date/timestamp/string) | 返回 1 到 4 范围内的日期、时间戳或字符串的季度(从 Hive 1.3.0 开始)。示例:quarter('2015-04-08') = 2. |
|
int |
month(string date) |
返回日期或时间戳字符串的月份部分:month("1970-11-01 00:00:00") = 11, month("1970-11-01") = 11.。 |
|
int |
day(string date) dayofmonth(date) |
返回日期或时间戳字符串的天数:day("1970-11-01 00:00:00") = 1, day("1970-11-01") = 1. |
|
int |
hour(string date) |
返回时间戳的小时数: hour('2009-07-30 12:58:59') = 12, hour('12:58:59') = 12. |
|
int |
minute(string date) |
返回时间戳的分钟数。 |
|
int |
second(string date) |
返回时间戳的秒数。 |
|
int |
weekofyear(string date) |
返回时间戳字符串的周数: weekofyear("1970-11-01 00:00:00") = 44, weekofyear("1970-11-01") = 44. |
|
int |
datediff(string enddate, string startdate) |
返回从开始日期到结束日期的间隔天数: datediff('2009-03-01', '2009-02-27') = 2. |
|
pre 2.1.0: string 2.1.0 on: date |
date_add(date/timestamp/string startdate, tinyint/smallint/int days) |
日期相加: date_add('2008-12-31', 1) = '2009-01-01'. |
|
pre 2.1.0: string 2.1.0 on: date |
date_sub(date/timestamp/string startdate, tinyint/smallint/int days) |
日期相减: date_sub('2008-12-31', 1) = '2008-12-30'. |
| date | current_date |
|
| timestamp | current_timestamp |
返回当前时间戳。在同一个查询中对 current _time 戳的所有调用都返回相同的值。 |
示例:
-- 求年份 SELECT year("1970-01-01 00:00:00") -- 求季度 SELECT quarter('2015-04-08') -- 月份 SELECT month("1970-11-01 00:00:00") -- 天数 SELECT day("1970-11-01 00:00:00") -- 小时 SELECT hour("1970-11-01 12:34:52") -- 分钟数 SELECT minute("1970-11-01 12:34:52") -- 秒数 SELECT second("1970-11-01 12:34:52") -- 返回周数 SELECT weekofyear("1970-11-01 12:34:52") -- 两个时间的间隔天数 SELECT datediff('2009-03-01', '2009-02-27') -- 日期相加 SELECT date_add('2008-12-31', 1) -- 日期相减 SELECT date_sub('2008-12-31', 1) -- 查看当前日期 SELECT current_date() -- 返回当前日期的时间戳 SELECT current_timestamp() -- 时间戳转换日期 SELECT TO_DATE('2024-06-12 15:43:40.072')
2.5.条件函数(Conditional Functions)
Conditional Functions
| Return Type | Name(Signature) | Description |
|
T |
if(boolean testCondition, T valueTrue, T valueFalseOrNull) |
当 testCondition 为 true 时返回 valueTrue,否则返回 valueFalseOrNull。 |
| boolean | isnull( a ) | 如果 a 为 NULL,则返回 true,否则返回 false。 |
| boolean | isnotnull ( a ) | 如果 a 不为 NULL,则返回 true,否则返回 false。 |
| T | nvl(T value, T default_value) | 如果 value 为 null,则返回默认值,否则返回值(截至 HIve 0.11)。 |
|
T |
COALESCE(T v1, T v2, ...) |
返回第一个不是 NULL 的 v,如果所有 v 都为 NULL,则返回 NULL。 |
|
T |
CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] END |
当 a = b 时,返回 c;当 a = d 时,返回 e;else 返回 f。 |
|
T |
CASE WHEN a THEN b [WHEN c THEN d]* [ELSE e] END |
当 a = true 时,返回 b;当 c = true 时,返回 d;else 返回 e。 |
| T | nullif( a, b ) |
如果 a=b,则返回 NULL;否则返回 a(从 Hive 2.3.0 开始)。 简写:CASE WHEN a = b then NULL else a |
| void | assert_true(boolean condition) | 如果“condition”不为 true,则抛出异常,否则返回 null(从 Hive 0.8.0 开始)。例如,选择assert_true (2<1) |
示例:
-- 如果truename为NULL则显示'未知的名字',不为NULL显示原本的值 SELECT IF(truename is NULL,'未知的名字',truename) FROM myhive.users; -- isnull SELECT isnull(truename) FROM myhive.users; -- isnotnull SELECT isnotnull(truename) FROM myhive.users; -- nvl如果 value 为 null,则返回默认值,否则返回值(截至 HIve 0.11)。 SELECT nvl(truename,'未知名字') FROM myhive.users; -- 返回第一个truename不是 NULL 的 则返回truename,如果所有truename,brithday都为 NULL,则返回 NULL。 SELECT COALESCE(truename,brithday) FROM myhive.users; -- 当 a = b 时,返回 c;当 a = d 时,返回 e;else 返回 f。 SELECT username, case username when '萧呀轩' then '知名女星' when '周杰轮' then '著名歌手' when '王力鸿' then '曾为未娃哈哈代言' when '张学油' then '型男' else '不知道了!!!' end FROM myhive.users; -- 当 a = true 时,返回 b;当 c = true 时,返回 d;else 返回 e。 SELECT truename, case when truename is null then '未知的姓名' else '明星' end FROM myhive.users; -- 如果 a=b,则返回 NULL;否则返回 a(从 Hive 2.3.0 开始)。 SELECT truename,nullif(truename, '王力鸿') FROM myhive.users; -- 如果“condition”不为 true,则抛出异常,否则返回 null(从 Hive 0.8.0 开始)。例如,选择assert_true (2<1) SELECT assert_true(2>4)
2.6.字符串函数(String Functions)
The following built-in String functions are supported in Hive:
|
Return Type |
Name(Signature) |
Description |
|
string |
concat(string|binary A, string|binary B...) |
字符串拼接. 案例 concat('foo', 'bar') 返回 'foobar'. |
|
string |
concat_ws(string SEP, string A, string B...) |
和 concat() 一样,但是可以自己通过SEP定义字符串之间的分隔符 |
|
int |
length(string A) |
返回字符串的长度 |
|
string |
lower(string A) |
全部转小写, 案例 lower('fOoBaR') 返回 'foobar'. |
| string | upper(string A) | 全部转大写,案例 upper('fOoBaR') 返回 'FOOBAR'. |
|
string |
trim(string A) |
返回从 A 的两端删除空格后产生的字符串, trim(' foobar ') 返回 'foobar' |
|
array |
split(string str, string pat) |
根据pat分隔字符串,pat是正则表达式 |
示例:
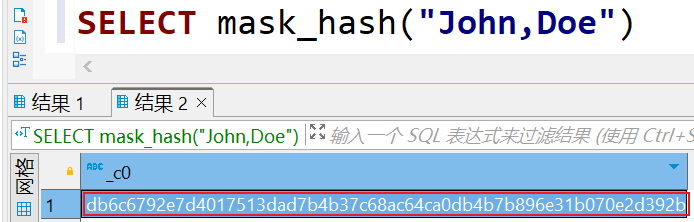
-- 字符串拼接. 案例 concat('foo', 'bar') 返回 'foobar'. SELECT concat('foo', 'bar') -- 和 concat() 一样,但是可以自己通过SEP定义字符串之间的分隔符 SELECT concat_ws('*','foo', 'bar') -- 返回字符串的长度 SELECT LENGTH('foobar') -- 全部转小写, 案例 lower('fOoBaR') 返回 'foobar'. SELECT lower('fOoBaR') -- 全部转大写,案例 upper('fOoBaR') 返回 'FOOBAR'. SELECT upper('fOoBaR') -- 返回从 A 的两端删除空格后产生的字符串, trim(' foobar ') 返回 'foobar' SELECT trim(' foo bar ') -- 根据pat分隔字符串,pat是正则表达式 -- 其中name字段的值为"John,Doe",我们可以使用split函数将name字段按逗号进行拆分,并返回一个数组: SELECT split("John,Doe",',')
2.7.数据脱敏函数 (Data Masking Functions)
Hive 支持以下内置数据脱敏功能:
|
Return Type |
Name(Signature) |
Description |
| string | mask_hash(string|char|varchar str) | 对字符串进行 hash 加密(结果是16进制字符串),非字符串加密会得到 NULL |
示例:
2.8.其他函数(Misc Functions)
| Return Type | Name(Signature) | Description |
| int | hash(a1[, a2...])) | 返回参数的 hash 数字 |
| string | current_user() | 返回当前登录用户 |
| string | current_database() | 返回当前选择的数据库 |
| string | version() | 返回当前 hive 版本 |
| string | md5(string/binary) | 返回给定参数的 md5 值 |
示例:
-- 返回参数的 hash 数字 SELECT hash('a1','a2','a3'); -- 返回当前登录用户 SELECT current_user(); -- 返回当前选择的数据库 SELECT current_database(); -- 返回当前 Hive 版本 SELECT version(); -- 返回给定参数的 md5 值 SELECT md5('your_string_or_binary_here')
三、窗口函数概述
在Hive中,窗口函数(Window Functions)是一种强大的功能,可以在查询结果中进行分组、排序和聚合操作,同时保留原始数据的完整性。窗口函数可以在查询结果中创建窗口(window),并在窗口内对数据进行计算和分析。
over窗口函数说明:
function(arg) over (partition by {partition columns} order by {order columns} desc/asc)
说明:
- partition columns:当前行中根据指定的列对partition columns列相同值归到一个分区中;
- order columns:在相同值的partition columns列分区中,按照order columns列值进行排序,可以指定升序或是降序,默认是升序
- function(arg):对应的窗口数据计算函数
3.1.窗口序列函数
准备数据
-- 创建表 CREATE TABLE tmp_cube ( user_id INT, province STRING, part STRING ) row format delimited fields terminated by '\t' -- 插入数据 INSERT INTO tmp_cube VALUES (137, '云南省', '01'), (139, '云南省', '01'), (138, '云南省', '02'), (136, '云南省', '02'), (135, '云南省', '03'), (140, '云南省', '03'), (133, '北京', '01'), (132, '北京', '02'), (134, '北京', '03'), (124, '广东省', '01'), (127, '广东省', '01'), (151, '广东省', '02'), (123, '广东省', '02'), (225, '广东省', '03'), (126, '广东省', '03'); SELECT * FROM tmp_cube
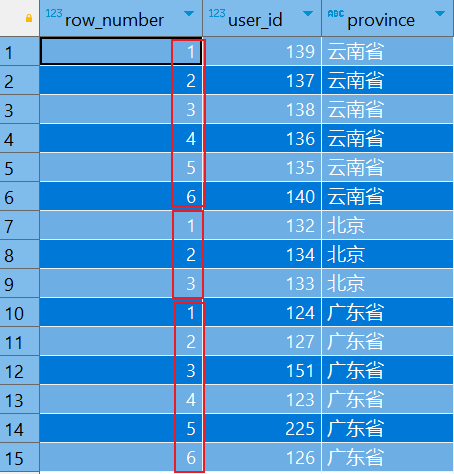
⑴.row_number
在窗口内会对所有数值,输出不同的序号,序号唯一且连续,如:1、2、3、4、5。
row_number() OVER (PARTITION BY COL1 ORDER BY COL2)
表示根据COL1分组,在分组内部根据 COL2排序,而此函数计算的值就表示每组内部排序后的顺序编号(组内连续的唯一的)。
-- 根据省份分组查询,并给分组添加序号 SELECT ROW_NUMBER() OVER (PARTITION BY province) AS row_number, user_id, province FROM tmp_cube
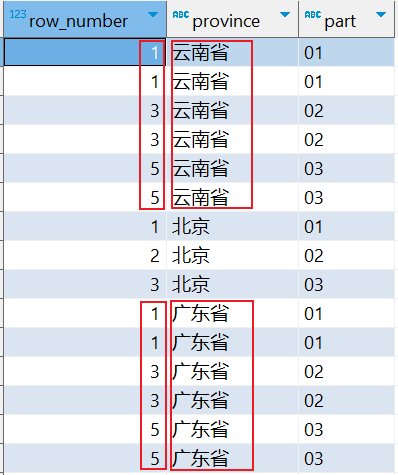
RANK()会对相同数值,输出相同的序号,而且下一个序号间断,如:1、1、3、3、5。
-- 根据省份分组查询,然后根据部门ID升序排序 SELECT RANK() OVER (PARTITION BY province ORDER BY part) AS row_number, province, part FROM tmp_cube
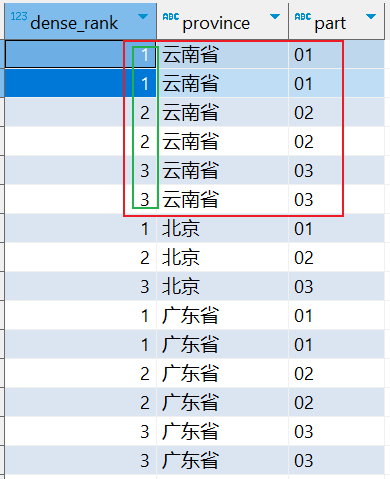
⑵.dense_rank
会对相同数值,输出相同的序号,但下一个序号不间断,如:1、1、2、2、3。
-- 根据省份分组查询,然后根据部门ID升序排序(会对相同数值,输出相同的序号,但下一个序号不间断,如:1、1、2、2、3。) SELECT dense_rank() OVER (PARTITION BY province order by part) AS dense_rank, province, part FROM tmp_cube
3.2.窗口边界
控制窗口范围,必须配合over窗口的order by排序,参数解释:n行数
unbounded 不限行数(修饰preceding和following) preceding 在前N行 following 在后N行 current row 当前行
举例说明 :
-- 窗口中整个的范围(over 窗口函数默认是整个窗口范围) rows between unbounded preceding and unbounded following -- 从 前无限行 到 当前行 rows between unbounded preceding and current row -- 从 当前行的前2行 到 当前行 rows between 2 preceding and current row -- 从 当前行 到 当前行后2行 rows between current row and 2 following -- 当前行 到 后不限行
rows between current row and unbounded following
根据tmp_cube表的数据,展示如何在Hive中编写查询来控制窗口范围,并配合over窗口的order by排序。以下是具体的案例示例:
⑴.从前无限行到当前行的范围内计算每个省份用户的累计数量:
SELECT user_id, province, COUNT(user_id) OVER (PARTITION BY province ORDER BY user_id ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cumulative_count FROM tmp_cube;
这个查询中,对于每个省份,窗口范围从前无限行到当前行,意味着对于每个用户,计算的累计数量包括该用户之前的所有行,即从最开始到当前行的所有行。
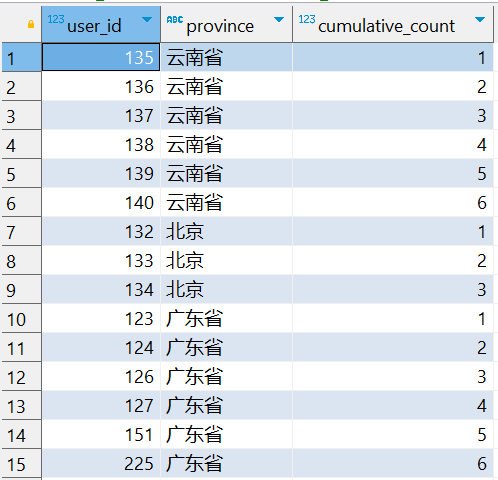
现在按照查询的窗口定义来计算 cumulative_count:
-
对于云南省 (
province = '云南省'):user_id135: 累积数量为 1,因为它是云南省的第一个用户。user_id136: 累积数量为 2,因为前两个用户是 135 和 136。user_id137: 累积数量为 3,因为前三个用户是 135、136 和 137。user_id138: 累积数量为 4,因为前四个用户是 135、136、137 和 138。- 以此类推,直到最后一个用户
user_id140。
-
对于北京 (
province = '北京') 和广东省 (province = '广东省'),也将按照相同的逻辑计算累积数量。
因此,每个省份中的 cumulative_count 列显示的是从该省份的第一个用户到当前用户的累积数量。
⑵.从当前行的前2行到当前行的范围内计算每个省份用户的累计数量:
SELECT user_id, province, COUNT(user_id) OVER (PARTITION BY province ORDER BY user_id ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) AS cumulative_count FROM tmp_cube;
在这个查询中,对于每个省份,窗口范围从当前行的前2行到当前行,意味着对于每个用户,计算的累计数量包括当前行以及前两行的数据。
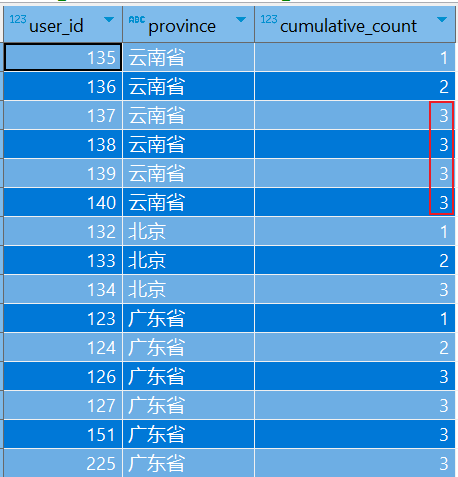
对于窗口函数 COUNT(user_id) OVER (PARTITION BY province ORDER BY user_id ROWS BETWEEN 2 PRECEDING AND CURRENT ROW),理解窗口范围的计算确实很重要。让我们再次仔细分析一下这个例子,特别是对于云南省中的用户 user_id 135 到 138 的累积计数:
- user_id = 135: 这是云南省的第一个用户,因此累积数量为 1。
- user_id = 136: 这是云南省的第二个用户,因此累积数量为 2。
- user_id = 137: 这是云南省的第三个用户,因此累积数量为 3。
- user_id = 138: 这是云南省的第四个用户。根据
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW,窗口范围应该包括当前行的前两行,即从user_id136 到user_id138。在这个范围内,有三个用户 (user_id136、137、138),因此累积数量应该是 3,而不是 4。
所以,对于 user_id 138,累积数量确实是3而不是4。这是因为窗口函数 COUNT 在窗口范围内简单地计数,而不是累积增加。每一行的结果都是基于当前行以及定义的窗口范围内的数据,不会像传统的累积求和函数一样逐步增加。
⑶.从当前行到当前行后2行的范围内计算每个省份用户的累计数量:
SELECT user_id, province, COUNT(user_id) OVER (PARTITION BY province ORDER BY user_id ROWS BETWEEN CURRENT ROW AND 2 FOLLOWING) AS cumulative_count FROM tmp_cube;
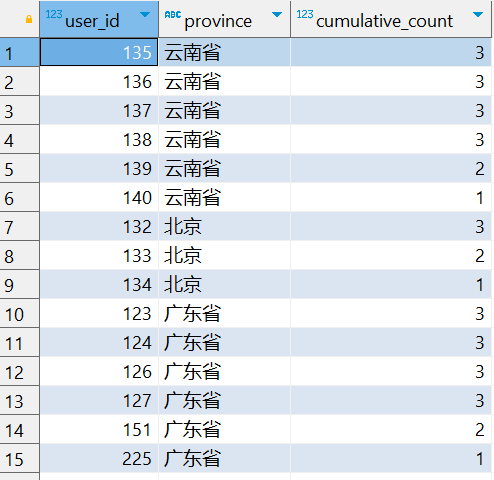
现在按照查询的窗口定义来计算 cumulative_count:
-
对于云南省 (
province = '云南省'):user_id135: 窗口范围为 135、136、137,因此累积数量为 3。user_id136: 窗口范围为 136、137、138,因此累积数量为 3。user_id137: 窗口范围为 137、138、139,因此累积数量为 3。user_id138: 窗口范围为 138、139、140,因此累积数量为 3。user_id139: 窗口范围为 139、140,因为后面只有两行数据,所以累积数量为 2。user_id140: 窗口范围为 140,因为后面只有一行数据,所以累积数量为 1。
-
对于北京 (
province = '北京') 和广东省 (province = '广东省'),也将按照相同的逻辑计算累积数量。
因此,每个省份中的 cumulative_count 列显示的是从当前行开始到当前行后两行的 user_id 的数量。
3.3.滑动窗口
⑴.lag 获取上一行数据
使用 LAG 函数获取前一行的数据:
SELECT user_id, province, part, LAG(user_id) OVER (ORDER BY user_id) AS prev_user_id, LAG(province) OVER (ORDER BY user_id) AS prev_province, LAG(part) OVER (ORDER BY user_id) AS prev_part FROM tmp_cube;
这个查询将会输出:
prev_user_id: 前一行的user_id。prev_province: 前一行的province。prev_part: 前一行的part。

⑵.lead 获取下一行数据
使用 LEAD 函数获取下一行的数据:
SELECT user_id, province, part, LEAD(user_id) OVER (ORDER BY user_id) AS next_user_id, LEAD(province) OVER (ORDER BY user_id) AS next_province, LEAD(part) OVER (ORDER BY user_id) AS nextnext_part FROM tmp_cube;
这个查询将会输出:
next_user_id: 后一行的user_id。next_province: 后一行的province。next_part: 后一行的part。
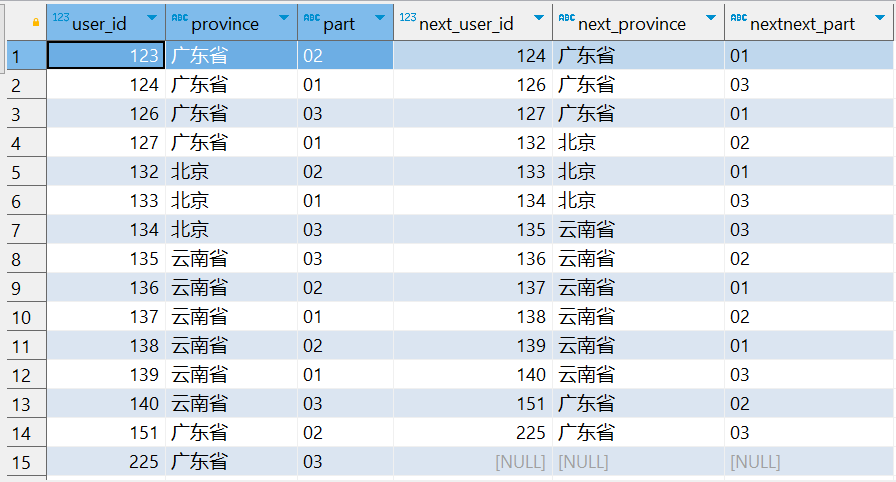
3.4.窗口专用计算函数
准备数据
CREATE TABLE user_total ( user_id INT, user_date STRING, user_amount FLOAT ) row format delimited fields terminated by '\t' INSERT INTO user_total VALUES (195, '202206', 20060.0), (195, '202207', 23028.0), (195, '202208', 20150.0), (195, '202209', 20170.0), (195, '202210', 20284.0), (195, '202211', 20150.0), (195, '202212', 20944.0), (195, '202301', NULL), (400, '202206', 0.0), (400, '202207', 20384.0), (400, '202208', 20150.0), (400, '202209', 0.0), (400, '202210', 20150.0), (400, '202211', 0.0), (400, '202212', 0.0), (400, '202301', NULL), (405, '202206', 0.0), (405, '202207', 38852.0), (405, '202208', 0.0), (405, '202209', 13650.0), (405, '202210', 25916.0), (405, '202211', 0.0), (405, '202212', 0.0); SELECT * FROM user_total;
⑴.sum累加函数
语法:
sum(num) over(partition by user_id,yyyy order by yyyymm asc )
实现效果:按照年月统计截至到当前行的sum(num)值:
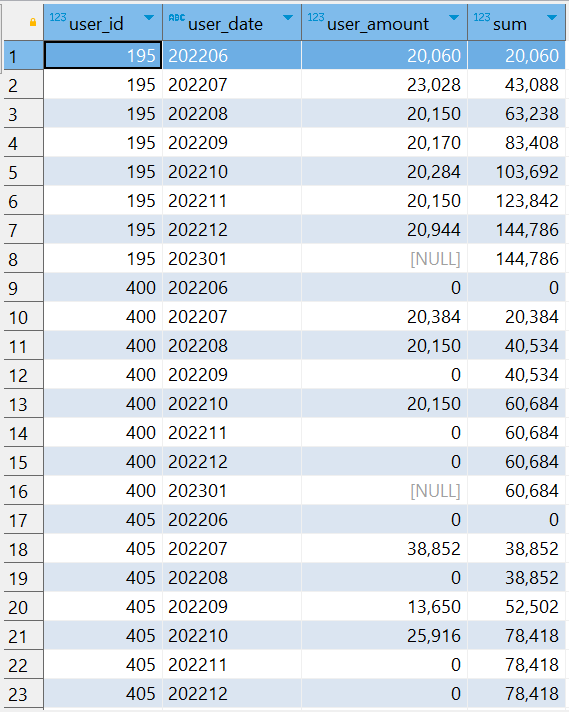
SELECT user_id, user_date, user_amount, SUM(user_amount) over (PARTITION BY user_id ORDER BY user_date) AS SUM FROM user_total
查询结果将会返回 user_id、user_date、user_amount 和 SUM 列,其中 SUM 列显示了每个用户在每个日期的累计金额。每行数据都显示了该用户截止到当前日期的总金额累计。
⑵.max最大值
语法:
min(expr) OVER([partition_by_clause] order_by_clause [window_clause]);
求每个用户的月收入金额中的最大值
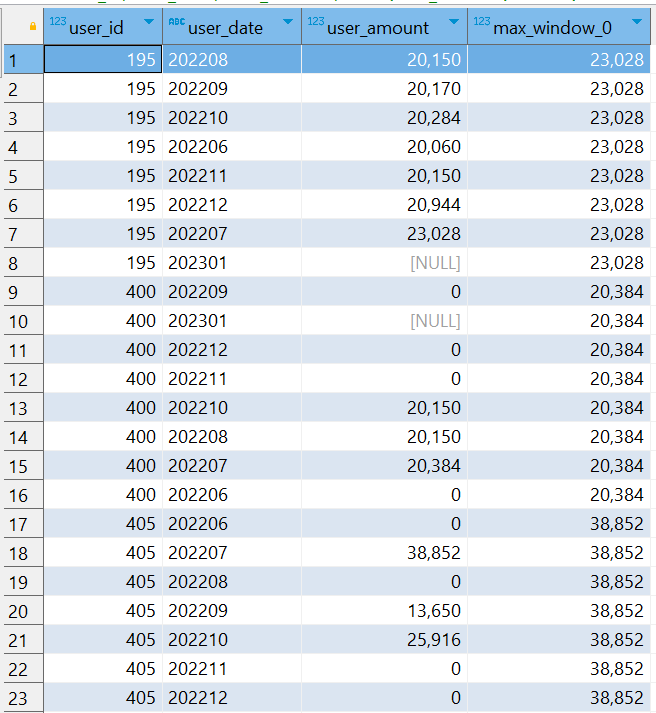
SELECT user_id, user_date, user_amount, MAX(user_amount) OVER (PARTITION BY user_id) FROM user_total
查询结果将会返回 user_id、user_date、user_amount 和 max_amount 列。max_amount 列显示了每个用户的所有金额中的最大值,而该值在每行中都是相同的,因为窗口函数应用于整个分区 (PARTITION BY user_id)。
⑶.min最小值
语法:
min(expr) OVER([partition_by_clause] order_by_clause [window_clause]);
求每个用户的月收入金额中的最小值
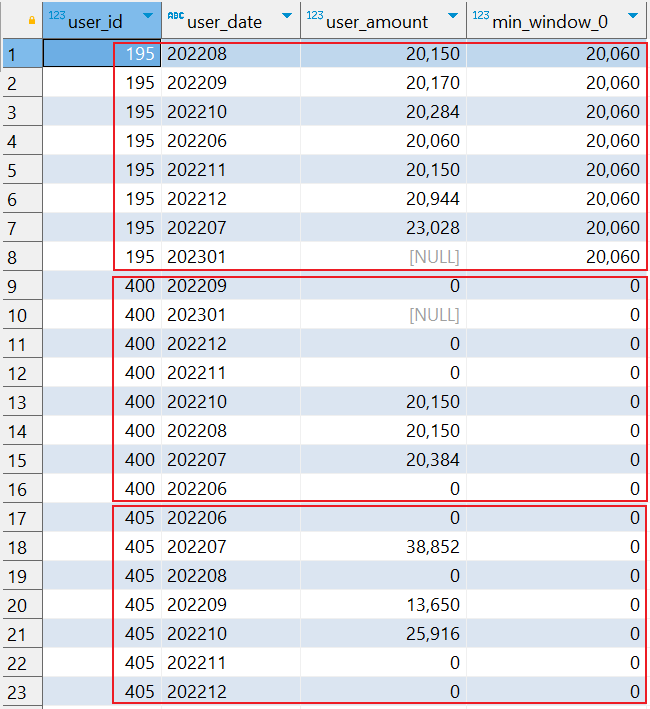
SELECT user_id, user_date, user_amount, MIN(user_amount) OVER (PARTITION BY user_id) FROM user_total
询结果将会返回 user_id、user_date、user_amount 和 max_amount 列。max_amount 列显示了每个用户的所有金额中的最小值,而该值在每行中都是相同的,因为窗口函数应用于整个分区 (PARTITION BY user_id)。
⑷.avg平均值
语法
avg(expr) OVER([partition_by_clause] order_by_clause [window_clause]);
求每个用户的月收入金额中的平均值
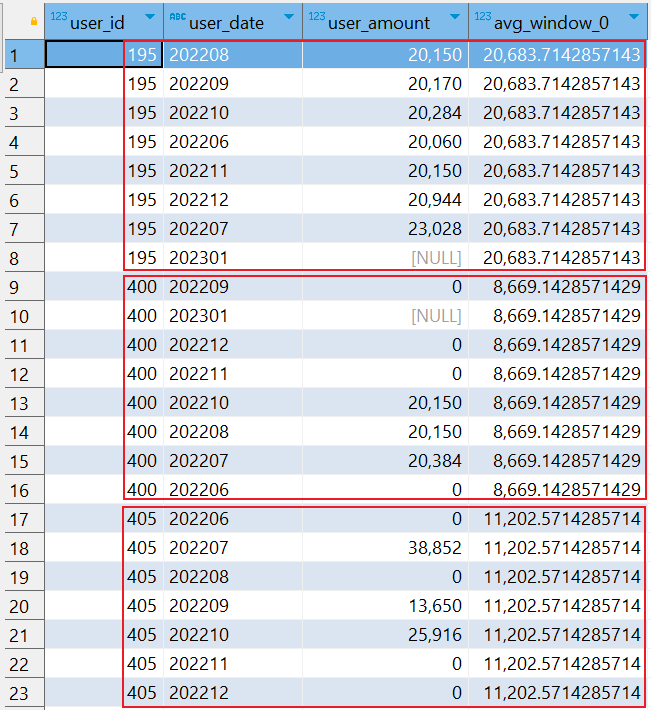
SELECT user_id, user_date, user_amount, AVG(user_amount) OVER (PARTITION BY user_id) FROM user_total
询结果将会返回 user_id、user_date、user_amount 和 max_amount 列。max_amount 列显示了每个用户的所有的平均薪资,而该值在每行中都是相同的,因为窗口函数应用于整个分区 (PARTITION BY user_id)。
⑸.count累计次数
语法:
COUNT(user_amount): 这是一个聚合函数,某行(expr)不为NULL的行数。
count(expr) OVER([partition_by_clause] order_by_clause [window_clause]);
统计每个用户月薪资不为NULL的次数
SELECT user_id, user_date, user_amount, COUNT(user_amount) OVER (PARTITION BY user_id) FROM user_total
结果说明:计算每个用户 (user_id) 的记录数,即该用户的 user_amount 不为NULL的行数。
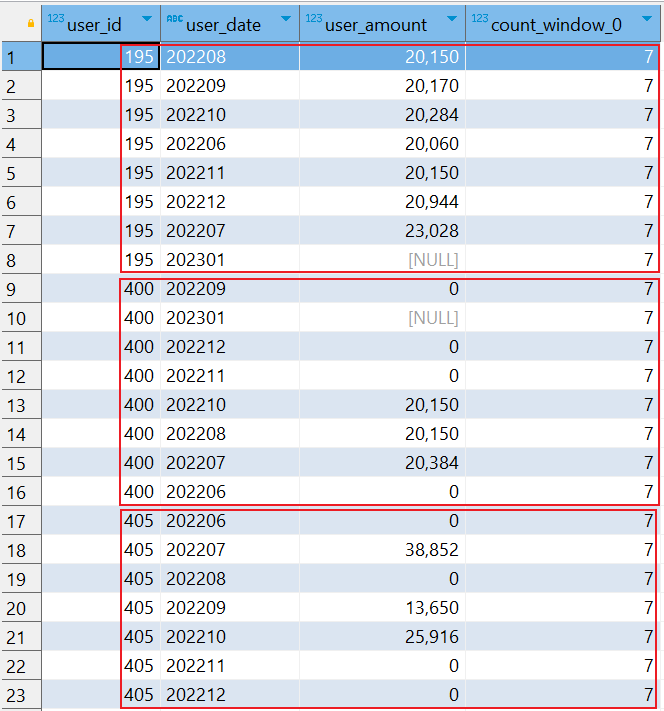
⑹.first_value首行值
语法:
first_value 函数用于返回在指定窗口内(partition)中,按照指定排序顺序(order by)的第一个值。
first_value(expr) OVER([partition_by_clause] order_by_clause [window_clause]);
示例
统计每个用户分组内按照日期排序的第一个日期。
SELECT user_id, user_date, user_amount, FIRST_value(user_date) OVER (PARTITION BY user_id ORDER BY user_date) FROM user_total
查询结果:
查询结果将会返回 user_id、user_date、user_amount 和 FIRST_VALUE(user_date) OVER (PARTITION BY user_id ORDER BY user_date) 列。在每行数据中,FIRST_VALUE(user_date) 列显示了每个用户分组内按照日期排序的第一个日期。
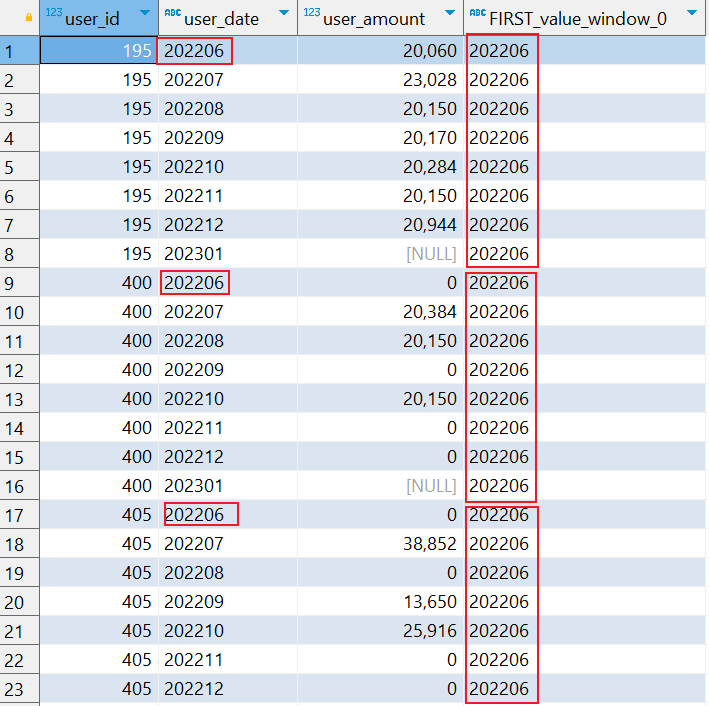
⑺.last_value末行值
在Hive中,last_value 函数用于返回在指定窗口内(partition)中,按照指定排序顺序(order by)的最后一个值。它是一种窗口函数(window function),用于在数据集的子集上执行计算和聚合操作。
语法
last_value(expression) OVER ( [PARTITION BY partition_expression] ORDER BY sort_expression [ASC|DESC] ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING )
说明:
expression: 要计算最后一个值的表达式或字段。PARTITION BY partition_expression: 可选部分,根据指定的列对数据进行分区,以便在每个分区内执行计算。如果不指定,则将整个结果集作为一个分区。ORDER BY sort_expression [ASC|DESC]: 指定排序表达式及排序顺序,确定如何在每个分区内对数据进行排序。ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING: 定义窗口的边界,确保计算考虑从每个分区的第一行到最后一行的所有行。
案例:
SELECT user_id, user_date, user_amount, LAST_VALUE(user_date) OVER (PARTITION BY user_id ORDER BY user_date) FROM user_total
默认情况下,窗口函数可能只计算当前行到窗口的结束部分,并且不会自动考虑整个分区。这就可能导致你看到的 LAST_VALUE 实际上只是到当前行为止的最后一个值,而不是整个分区的最后一个值。

为了解决这个问题,我们需要明确地指定窗口的范围,使其包括从当前行到分区的最后一行。我们可以使用 ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING 来定义窗口范围。
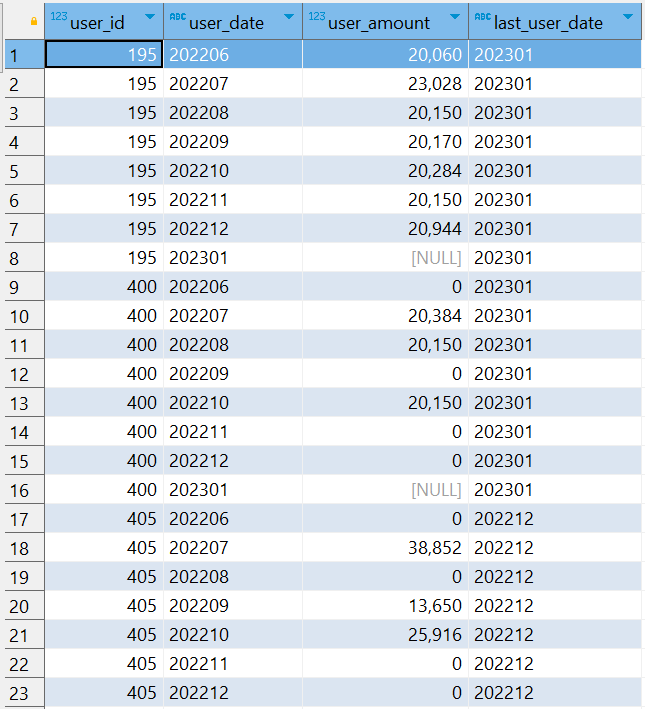
SELECT user_id, user_date, user_amount, last_value(user_date) OVER ( PARTITION BY user_id ORDER BY user_date ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING ) AS last_user_date FROM user_total
解释说明:
- PARTITION BY: 根据
user_id进行分区,即每个不同的user_id组内进行计算。 - ORDER BY: 按照
user_date的顺序进行排序。 - ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING:
UNBOUNDED PRECEDING: 从窗口的开头(分区的第一行)。UNBOUNDED FOLLOWING: 到窗口的结尾(分区的最后一行)。
这样定义窗口范围,确保 LAST_VALUE 函数考虑整个分区内的数据,从而返回每个分区中最后一行的值。
预期结果:
修正后的 SQL 查询应该返回每个 user_id 分区内,按照 user_date 排序的最后一个 user_date,并在每行中显示这个值。以下是预期的结果:
⑻.cume_dist分布统计
准备数据
CREATE TABLE sales_data ( sales_id INT, employee_id INT, sales_amount DOUBLE, sales_date STRING ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'; INSERT INTO sales_data VALUES (1, 101, 500.0, '2023-01-01'), (2, 102, 300.0, '2023-01-02'), (3, 103, 700.0, '2023-01-03'), (4, 101, 600.0, '2023-01-04'), (5, 102, 400.0, '2023-01-05'), (6, 103, 800.0, '2023-01-06'), (7, 101, 700.0, '2023-01-07'), (8, 102, 500.0, '2023-01-08'), (9, 103, 900.0, '2023-01-09');
CUME_DIST 函数是一个窗口函数,用于计算分区中指定排序的累积分布比例。它返回一个值,该值表示当前行及其之前的所有行在分区中的比例。
含义和作用
- CUME_DIST 计算的是相对于当前行及其之前的所有行的累积分布百分比。
- 它的值范围是从
> 0到<= 1。 - 在每个分区内,
CUME_DIST会按照指定的排序顺序计算当前行之前(包括当前行)有多少行,然后除以分区总行数。
计算公式
- 如果按升序排列,则统计:小于等于当前值的行数/总行数(number of rows ≤ current row)/(total number ofrows)。
- 如果是降序排列,则统计:大于等于当前值的行数/总行数
示例:
统计每个员工按照 销售金额排序的累积分布比例(升序)
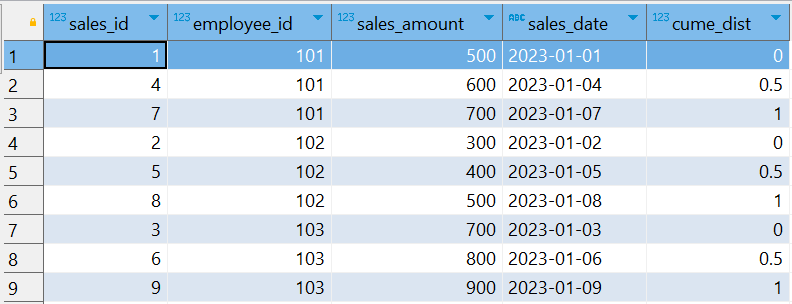
SELECT sales_id, employee_id, sales_amount, sales_date, CUME_DIST() OVER (PARTITION BY employee_id ORDER BY sales_amount) AS cume_dist FROM sales_data;
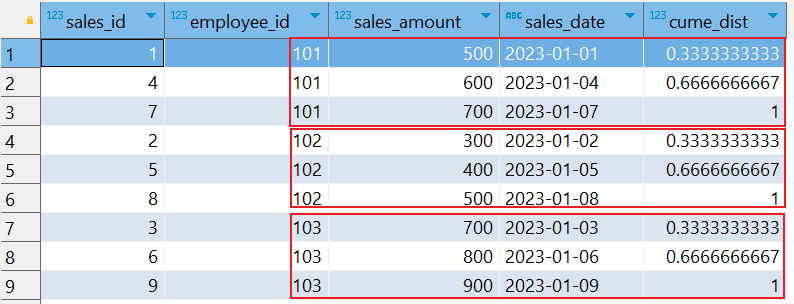
解释结果
-
对于
employee_id = 101:sales_id = 1的累积分布比例是0.3333,因为它是第一个值,之前有 1 个值,占总行数的1/3。sales_id = 4的累积分布比例是0.6667,因为它和之前的两个值,之前有 2 个值,占总行数的 2/3。sales_id = 7的累积分布比例是1.0,因为它是最后一个值,占总行数的3/3。
-
对于
employee_id = 102:sales_id = 2的累积分布比例是0.3333。sales_id = 5的累积分布比例是0.6667。sales_id = 8的累积分布比例是1.0。
-
对于
employee_id = 103:sales_id = 3的累积分布比例是0.3333。sales_id = 6的累积分布比例是0.6667。sales_id = 9的累积分布比例是1.0。
通过 CUME_DIST 函数,我们可以清楚地看到每个销售额在其分区中的累积分布比例,从而帮助我们了解销售额的分布情况。
⑼.percent_rank 秩分析函数
PERCENT_RANK 函数是一个窗口函数,用于计算当前行在其分区内的百分比排名。它返回一个值,表示当前行在排序后结果集中所处的位置的百分比排名。
作用和含义
-
PERCENT_RANK 计算的是当前行在其分区内按照指定排序的百分比排名。
-
它的值范围是从
0.0到1.0。 -
如果分区内只有一行,它的
PERCENT_RANK值为0.0。 -
如果分区内有多行,
PERCENT_RANK的计算公式为:<span class="katex-error" title="ParseError: KaTeX parse error: Expected 'EOF', got '_' at position 14: \text{PERCENT_̲RANK} = \frac{\…">\text{PERCENT_RANK} = \frac{\text{rank of the row} - 1}{\text{total number of rows in the partition} - 1}
其中,
rank of the row是当前行在分区内按照指定排序的排名。
案例
使用 PERCENT_RANK 计算每个 employee_id 分区内的百分比排名
SELECT sales_id, employee_id, sales_amount, sales_date, PERCENT_RANK() OVER (PARTITION BY employee_id ORDER BY sales_amount ) AS cume_dist FROM sales_data;
PERCENT_RANK() OVER (PARTITION BY employee_id ORDER BY sales_amount): 计算每个 employee_id 分区内,按照 sales_amount 排序的百分比排名。
解释结果
-
对于
employee_id = 101:sales_id = 1的PERCENT_RANK值为0.0,因为它是最小值。sales_id = 4的PERCENT_RANK值为0.5,因为它在排好序的employee_id = 101的数据中正好在中间位置。sales_id = 7的PERCENT_RANK值为1.0,因为它是最大值。
-
对于
employee_id = 102和employee_id = 103同理。
通过 PERCENT_RANK 函数,我们可以很直观地了解每个员工在销售额中的排名情况,即使在每个分区内的行数不同,也可以得到相对位置的百分比排名信息。
⑽.nitle数据切片函数
NTILE 函数是用于将有序数据集按照指定数量的桶(bucket)或分组进行分割,并为每个行分配一个桶号(bucket number)。它通常用于分析中,将数据集均匀地分割成指定数量的部分,以便进行进一步的分析或比较。
含义和作用
- NTILE(n) 将数据集分割成
n个桶(或分组),并为每行分配一个桶号,从1到n。 - 如果总行数不能被
n整除,前面的桶将比后面的桶包含更多的行。 NTILE可以帮助我们根据数据分布将数据划分成多个大致相等的部分,以进行统计分析或其他处理。
计算公式
对于每一行,NTILE 的计算公式是:
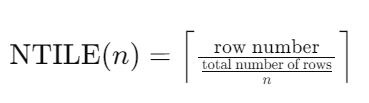
其中,row number 是当前行的行号,total number of rows 是分区内的总行数,n 是指定的桶数。
案例:
使用 NTILE 函数将 sales_amount 按照 3 个桶进行分组:
SELECT sales_id, employee_id, sales_amount, sales_date, NTILE(3) OVER (ORDER BY sales_amount) AS bucket_number FROM sales_data;
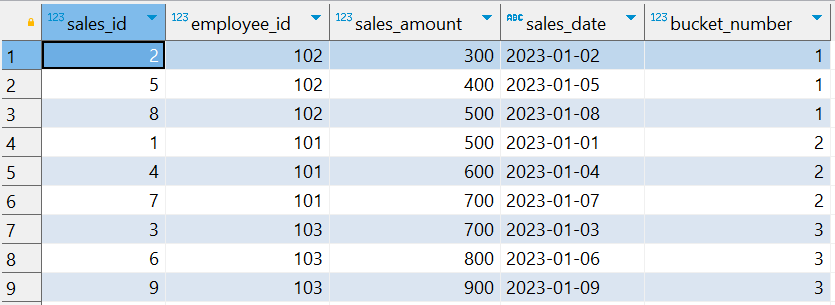
解释结果
NTILE(3)将sales_amount按照升序排序后分成了3个桶。- 桶号
1包含了最小的三个销售额。 - 桶号
2包含了接下来三个销售额。 - 桶号
3包含了最大的三个销售额。
通过 NTILE 函数,我们可以将数据集按照指定数量的桶进行分割,以便进行分组统计或者其他分析需求。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号