MapReduce和YARN入门
一、分布式计算概述
1.1.什么是计算
计算是对数据进行处理,使用统计分析等手段得到需要的结果,大数据体系内的计算, 举例:
- 销售额统计、区域销售占比、季度销售占比
- 利润率走势、客单价走势、成本走势
- 品类分析、消费者分析、店铺分析
等等一系列,基于数据得出的结论。 这些就是我们所说的计算。
1.2.分布式计算?
分布式计算:多台服务器协同工作,共同完成一个计算任务
问题:大数据为什么一定要分布式计算,非分布式计算不行吗?
答案:数据太大,一台计算机无法独立处理,这时候就需要靠多台计算机共同协作来完成(本质还是以数量取胜)
1.3.分布式计算常见的两种工作模式
分布式计算的时候管理多台计算机有两种方式:
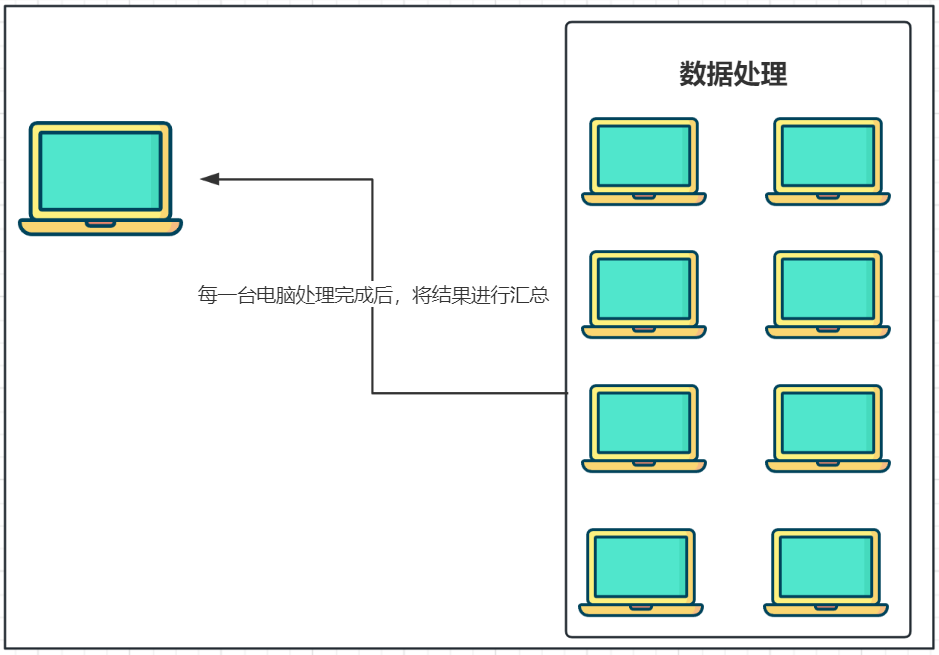
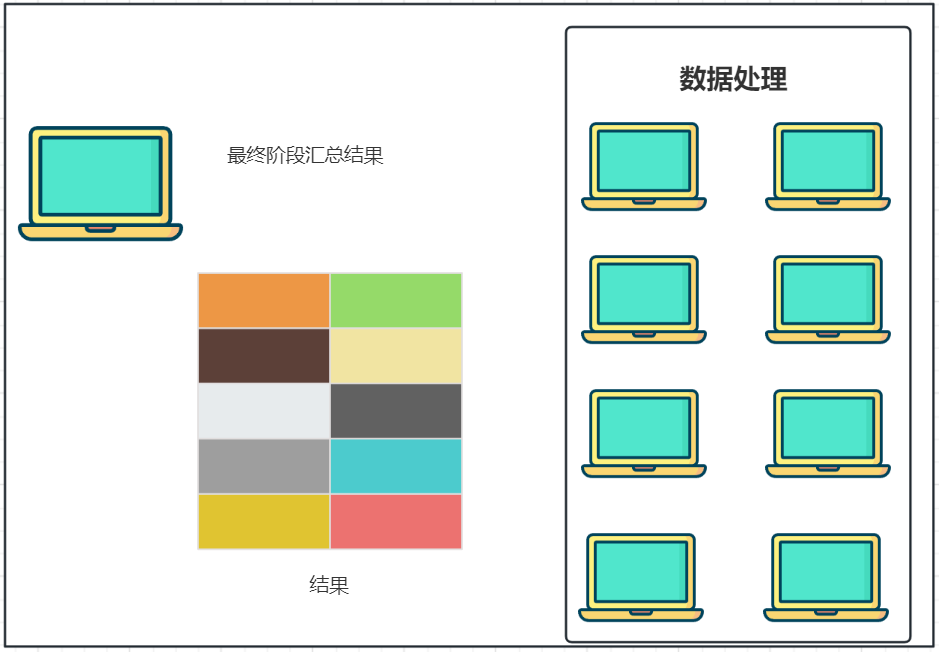
⑴.分散===>汇总模式:
将数据分片,多台服务器各自负责一部分数据处理,然后将各自的结果,进行汇总处理,最终得到想要的计算结果
⑵.中心调度===>步骤执行 (大数据体系的Spark、Flink等是这种模式)
由一个节点作为中心调度管理者,将任务划分为几个具体步骤,管理者安排每个机器执行任务,最终得到结果数据
二、MapReduce概述
2.1.分布式计算框架MapReduce
Hadoop三大组件说明:Hadoop HDFS、Hadoop MapReduce、Hadoop YARN
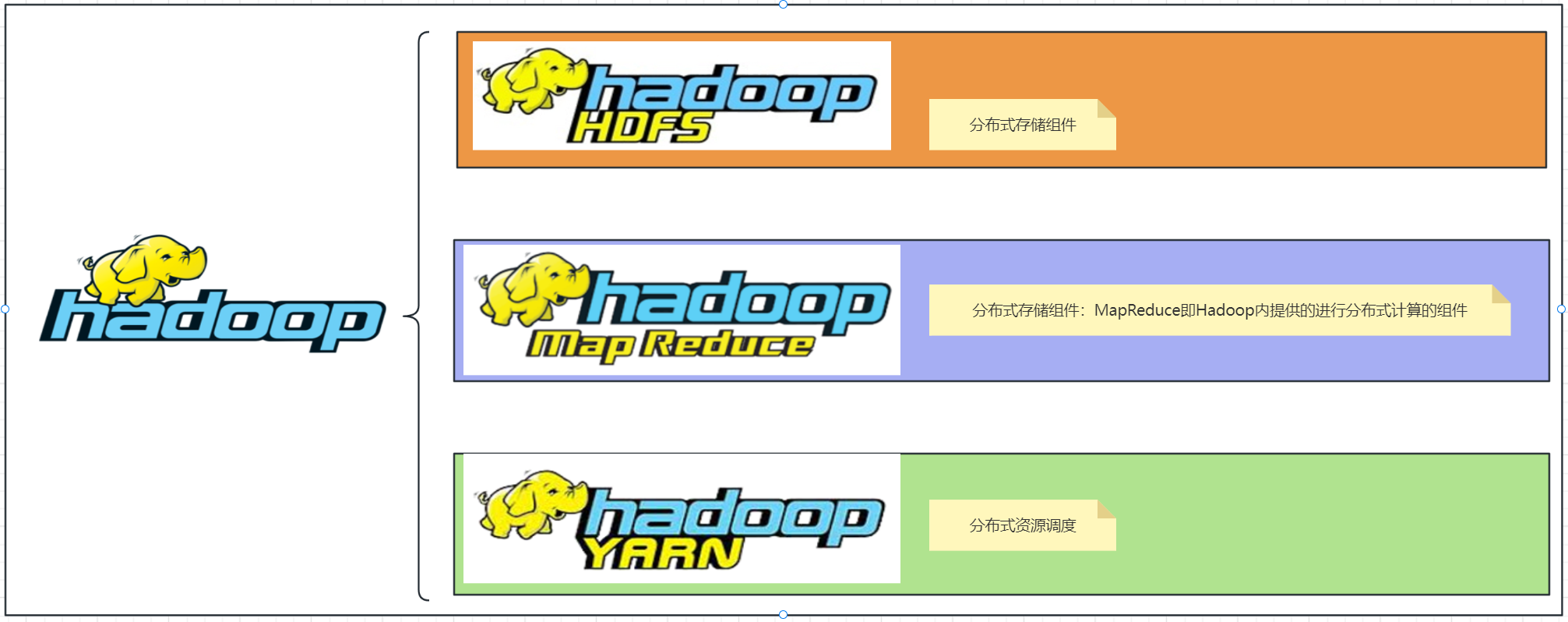
MapReduce是“分散===>汇总”模式的分布式计算框架,可供开发人员开发相关程序进行分布式数据计算。MapReduce提供了2个编程接口:
- Map:Map功能接口提供了“分散”的功能, 由服务器分布式对数据进行处理
- Reduce:Reduce功能接口提供了“汇总(聚合)”的功能,将分布式的处理结果汇总统计
用户如需使用MapReduce框架完成自定义需求的程序开发,只需要使用Java、Python等编程语言,实现MapReduce功能接口即可。
2.2.MapReduce执行原理
简单分析一下,MapReduce是如何完成分布式计算的。假设有如下文件,内部记录了许多的单词。且已经开发好了一个MapReduce程序,功能是统计每个单词出现的次数。
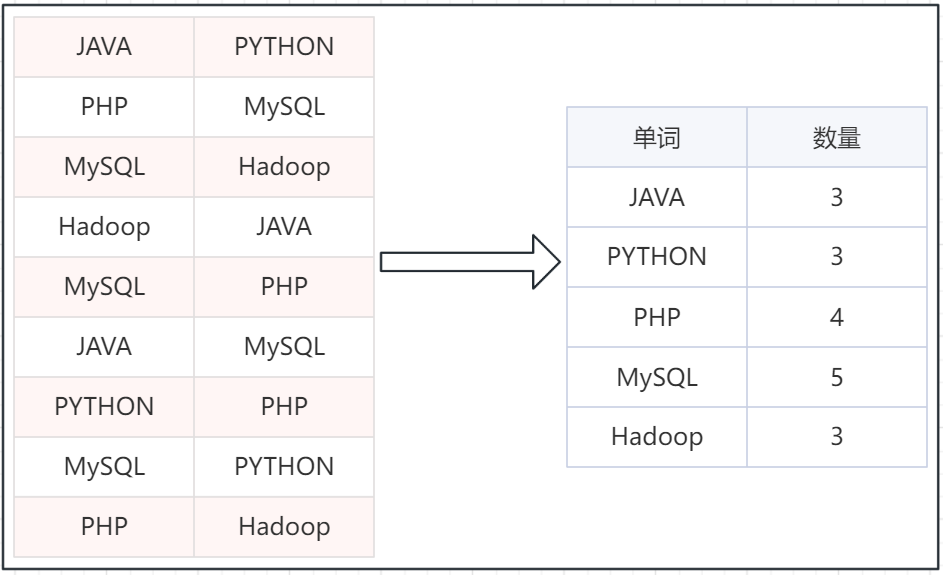
假定有4台服务器用以执行MapReduce任务,可以3台服务器执行Map,1台服务器执行Reduce

将任务分解为:3个Map(分散) Task(任务)、 1个Reduce(汇总) Task
2.3.MapReduce底层原理
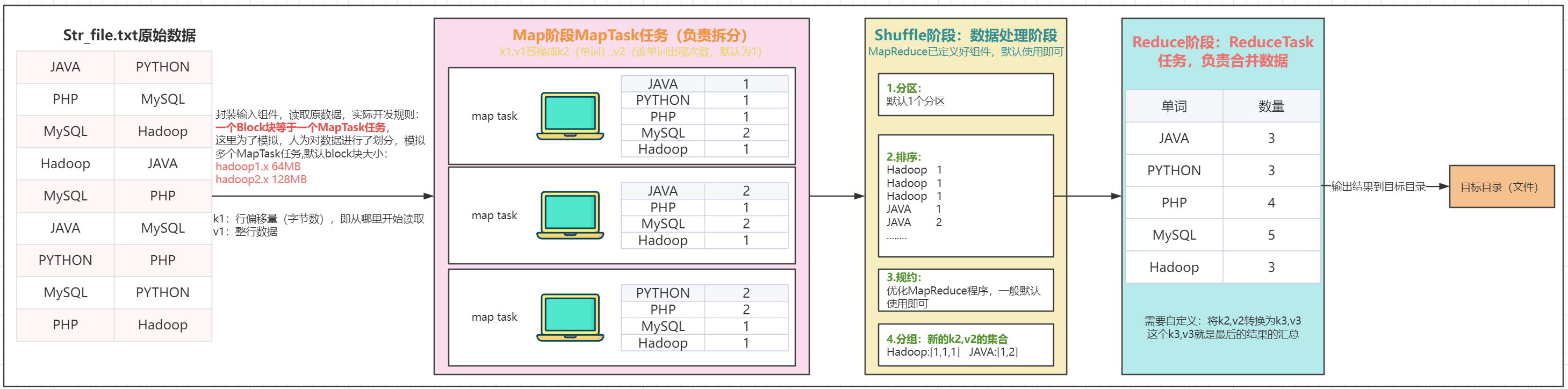
MapReduce核心8步详解:
①.封装输入组件,读取源数据,读取源数据的的过程,需要对源数据进行逻辑切片,每128M为1片 => MapTask
- k1:行偏移量,即从哪里开始读取
- v1:整行数据
②.Map Task任务阶段,即MapTask任务,调用map()负责对数据进行拆分,把k1, v1 => k2, v2, 过程需要自定义
- k2:单词
- v2:该单词出现次数,默认为1
Shuffle阶段
- ③.分区:即:表示该数据交给哪个Reduce处理
- ④.排序:默认按照字典顺序,升序排列 (a-z)
- ⑤.规约:用来优化MR程序,提高效率的
- ⑥.分组:即把k2相同的数据分配到一组,获取新的k2, V2的集合
⑦. Reduce阶段,即Reduce Task任务,调用reduce()方法负责对数据进行合并,把k2, v2的集合 => k3, v3 (最终结果)需要自定义
⑧.封装输出组件,把结果(k3,v3)写到目的地文件中
2.4.MapReduce执行底层原理(面试)
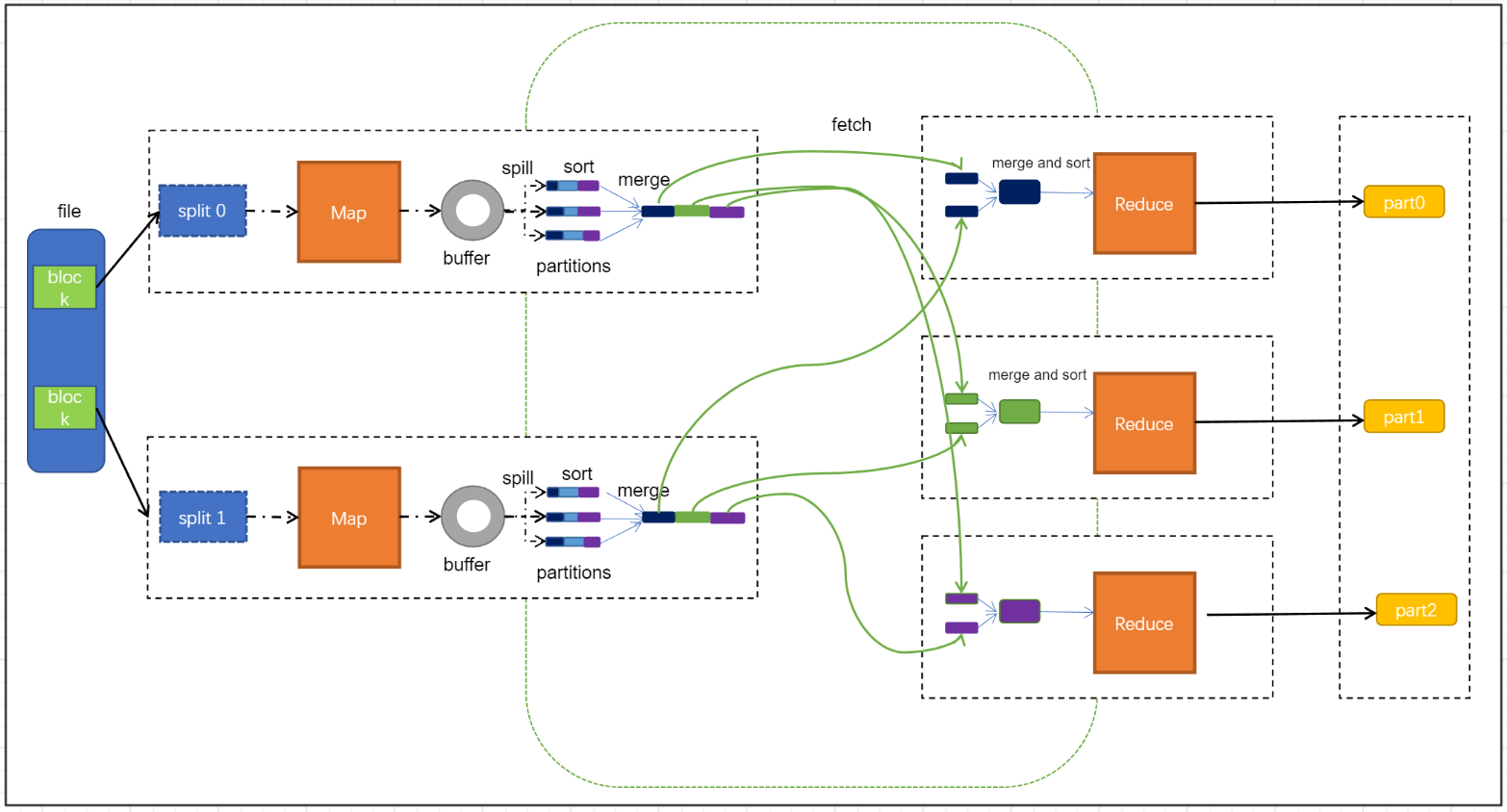
⑴.map阶段:
- 第一阶段是把输入目录下文件按照一定的标准逐个进行逻辑切片,形成切片规划。默认情况下Split size 等于 Block size。每一个切片由一个MapTask处理(当然也可以通过参数单独修改split大小)
- 第二阶段是对切片中的数据按照一定的规则解析成对。默认规则是把每一行文本内容解析成键值对。key是每一行的起始位置(单位是字节),value是本行的文本内容。(TextInputFormat)
- 第三阶段是调用Mapper类中的map方法。上阶段中每解析出来的一个,调用一次map方法。每次调用map方法会输出零个或多个键值对
- 第四阶段是按照一定的规则对第三阶段输出的键值对进行分区。默认是只有一个区。分区的数量就是Reducer任务运行的数量。默认只有一个Reducer任务
- 第五阶段是对每个分区中的键值对进行排序。首先,按照键进行排序,对于键相同的键值对,按照值进行排序。比如三个键值对<2,2>、<1,3>、<2,1>,键和值分别是整数。那么排序后的结果是<1,3>、<2,1>、<2,2>。
- 如果有第六阶段,那么进入第六阶段;如果没有,直接输出到文件中
- 第六阶段是对数据进行局部聚合处理,也就是combiner处理。键相等的键值对会调用一次reduce方法。经过这一阶段,数据量会减少。本阶段默认是没有的。
- shuffle是Mapreduce的核心,它分布在Mapreduce的map阶段和reduce阶段。一般把从Map产生输出开始到Reduce取得数据作为输入之前的过程称作shuffle。
- Collect阶段:将MapTask的结果输出到默认大小为100M的环形缓冲区,保存的是key/value,Partition分区信息等
- Spill阶段:当内存中的数据量达到一定的阀值(80%)的时候,就会将数据写入本地磁盘,在将数据写入磁盘之前需要对数据进行一次排序的操作,如果配置了combiner,还会将有相同分区号和key的数据进行排序
- Merge阶段:把所有溢出的临时文件进行一次合并操作,以确保一个MapTask最终只产生一个中间数据文件
- Copy阶段: ReduceTask启动Fetcher线程到已经完成MapTask的节点上复制一份属于自己的数据,这些数据默认会保存在内存的缓冲区中,当内存的缓冲区达到一定的阀值的时候,就会将数据写到磁盘之上
- Merge阶段:在ReduceTask远程复制数据的同时,会在后台开启两个线程对内存到本地的数据文件进行合并操作。
- Sort阶段:在对数据进行合并的同时,会进行排序操作,由于MapTask阶段已经对数据进行了局部的排序,ReduceTask只需保证Copy的数据的最终整体有效性即可。
- 第一阶段是Reducer任务会主动从Mapper任务复制其输出的键值对。Mapper任务可能会有很多,因此Reducer会复制多个Mapper的输出。
- 第二阶段是把复制到Reducer本地数据,全部进行合并,即把分散的数据合并成一个大的数据。再对合并后的数据排序。
- 第三阶段是对排序后的键值对调用reduce方法。键相等的键值对调用一次reduce方法,每次调用会产生零个或者多个键值对。最后把这些输出的键值对写入到HDFS文件中。
三、YARN概述
3.1.MapReduce和YARN的关系
MapReduce是基于YARN运行的,没有YARN则是无法运行MapReduce程序
3.2.什么资源调用,为什么需要资源调度?
资源调度
- 资源:服务器硬件资源,如:CPU、内存、硬盘、网络等
- 资源调度:管控服务器硬件资源,提供更好的利用率
- 分布式资源调用:管控整个分布式服务器集群的全部资源,整合进行统一调度
服务器会运行多个程序, 每个程序对资源(CPU内存等)的使用都不同,程序没有节省的概念,有多少就会用多少。所以,为了提高资源利用率,进行调度就非常有必要了。将服务器上的资源进行划分,对程序实行申请制度,需要多少申请多少
对于服务器集群亦可使用这种思路调度整个集群的资源
3.3.YARN的作用是什么?程序如何在YARN内运行
YARN是Hadoop的一个组件,用以做集群的资源(内存、CPU等)调度,程序向YARN申请所需资源,YARN为程序分配所需资源供程序使用
3.4.YARN资源调度
YARN 管控整个集群的资源进行调度, 那么应用程序在运行时,就是在YARN的监管(管理)下去运行的。这类似:全部资源都是公司(YARN)的,由公司分配给个人(具体的程序)去使用。
比如,一个具体的MapReduce程序会将任务分解为若干个Map任务和Reduce任务。假设,有一个MapReduce程序, 分解了3个Map任务,和1个Reduce任务,那么如何在YARN的监管(管理)下运行呢?
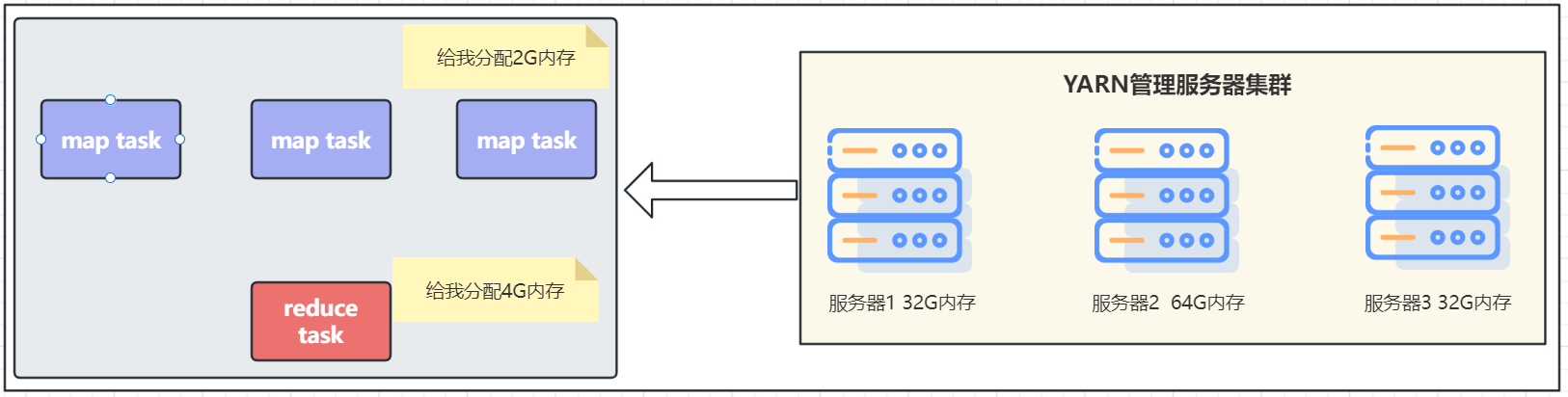
注意:MapReduce程序向YARN申请使用资源,YARN分配好资源后运行,空闲资源可供其它程序使用
四、YARN架构
4.1.YARN核心架构
4.1.1.YARN角色说明
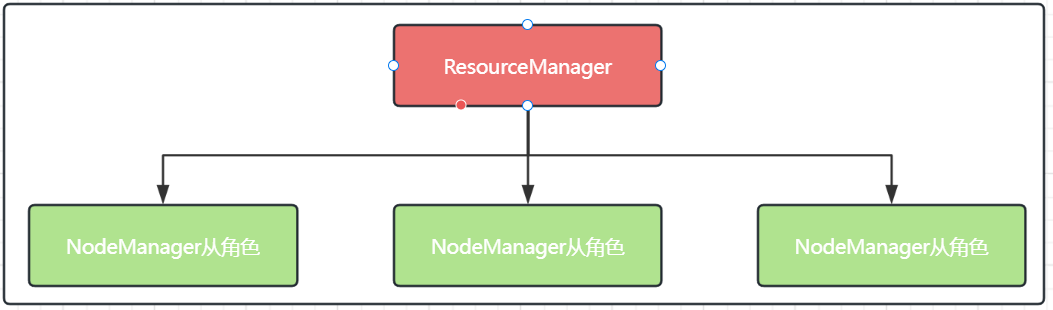
YARN,主从架构,有2个角色
- 主(Master)角色:ResourceManager,整个集群的资源调度者, 负责协调调度各个程序所需的资源。
- 从(Slave) 角色:NodeManager,单个服务器的资源调度者,负责调度单个服务器上的资源提供给应用程序使用。
分配资源如下:
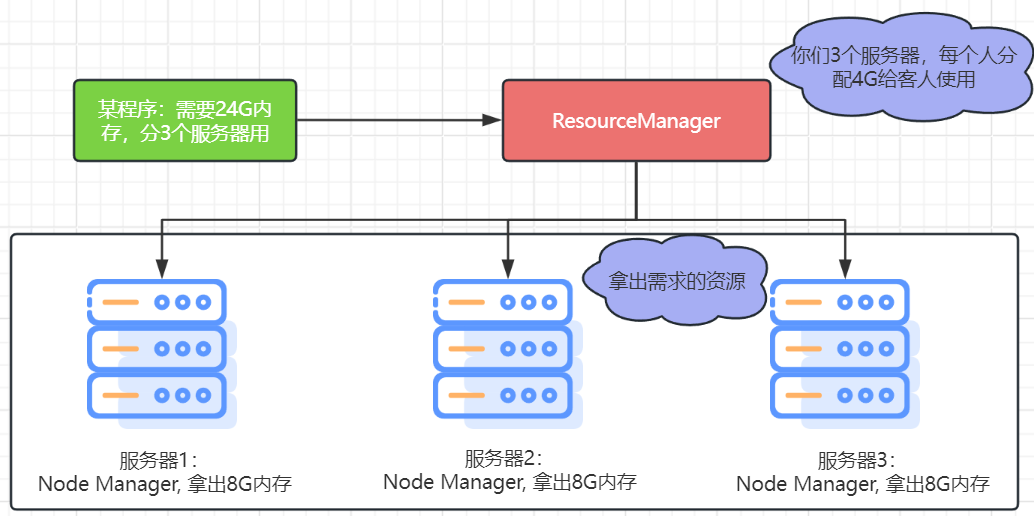
上图中是如何实现服务器上精准分配如下的硬件资源呢?
4.1.2.YARN容器
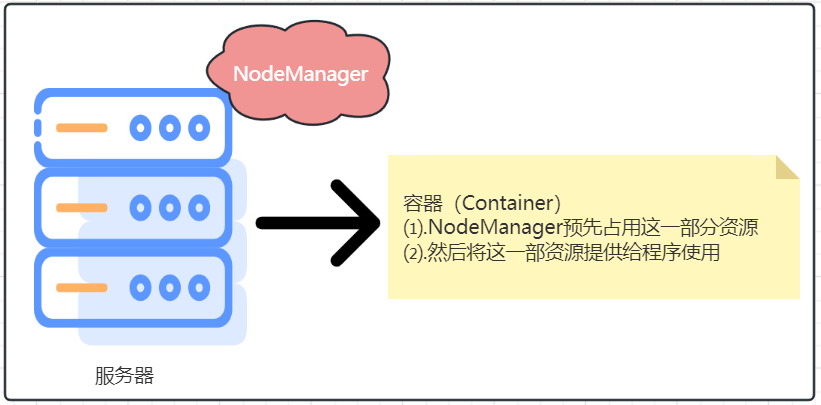
容器(Container)是YARN的NodeManager在所属服务器上分配资源的手段,创建一个资源容器,即由NodeManager占用这部分资源,然后应用程序运行在NodeManager创建的这个容器内,应用程序无法突破容器的资源限制,

4.2.辅助架构
4.2.1.YARN辅助角色
YARN 的架构中除了核心角色,即:
- ResourceManager :集群资源总管家
- NodeManager :单机资源管家
还可以搭配 2 个辅助角色使得 YARN 集群运行更加稳定
- 代理服务器 (ProxyServer) : Web Application Proxy Web 应用程序代理
- 历史服务器 (JobHistoryServer) : 应用程序历史信息记录服务
4.2.2.代理服务器
代理服务器,即 Web 应用代理是 YARN 的一部分。默认情况下,它将作为资源管理器 (RM) 的一部分运行,但是可以配置为在独立模式下运行。使用代理的原因是为了减少通过 YARN 进行基于网络的攻击的可能性。这是因为, YARN 在运行时会提供一个 WEB UI 站点(同 HDFS 的 WEB UI 站点一样)可供用户在浏览器内查看 YARN 的运行信息
对外提供 WEB 站点会有安全性问题, 而代理服务器的功能就是最大限度保障对 WEB UI 的访问是安全的。 比如:
- 警告用户正在访问一个不受信任的站点
- 剥离用户访问的 Cookie 等
开启代理服务器,可以提高 YARN 在开放网络中的安全性 (但不是绝对安全只能是辅助提高一些)
代理服务器默认集成在了 ResourceManager 中也可以将其分离出来单独启动,如果要分离代理服务器
⑴.在 yarn-site.xml 中配置 yarn.web-proxy.address 参数即可 (部署环节会使用到)
<property>
<name>yarn.web-proxy.address</name>
<value>node1:8089</value>
<description>代理服务器主机和端口</description>
</property>
⑵.并通过命令启动它即可 $HADOOP_YARN_HOME/sbin/yarn-daemon.sh start proxyserver (部署环节会使用到)
4.2.3.历史服务器
⑴.为什么需要历史服务器?
历史服务器的功能: 记录历史运行的程序的信息以及产生的日志并提供WEB UI站点供用户使用浏览器查看。
程序看日志不是日常操作吗? 为何需要一个单独的历史服务器?
回答这个问题要从YARN的运行机制说起。运行日志,产生在容器中,过于零散难以查看
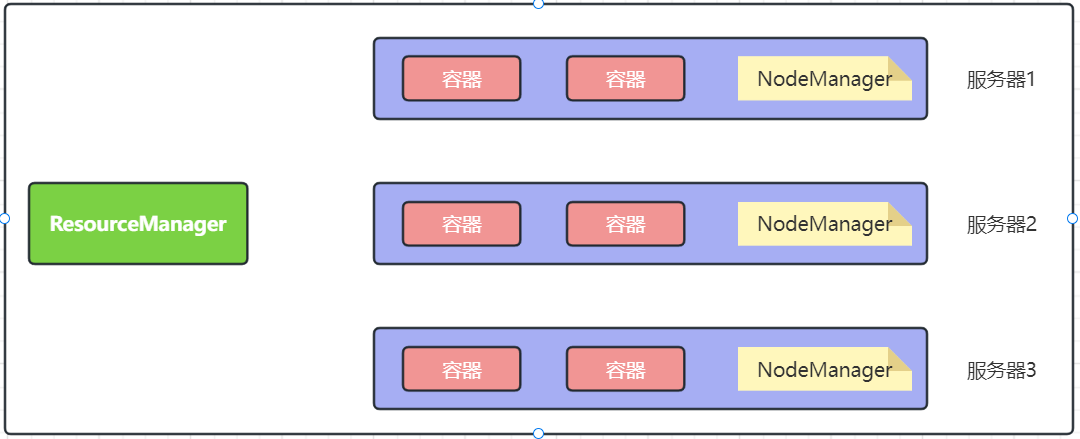
所以需要统一收集到 HDFS ,由历史服务器托管为WEB UI 供用户在浏览器统一查看
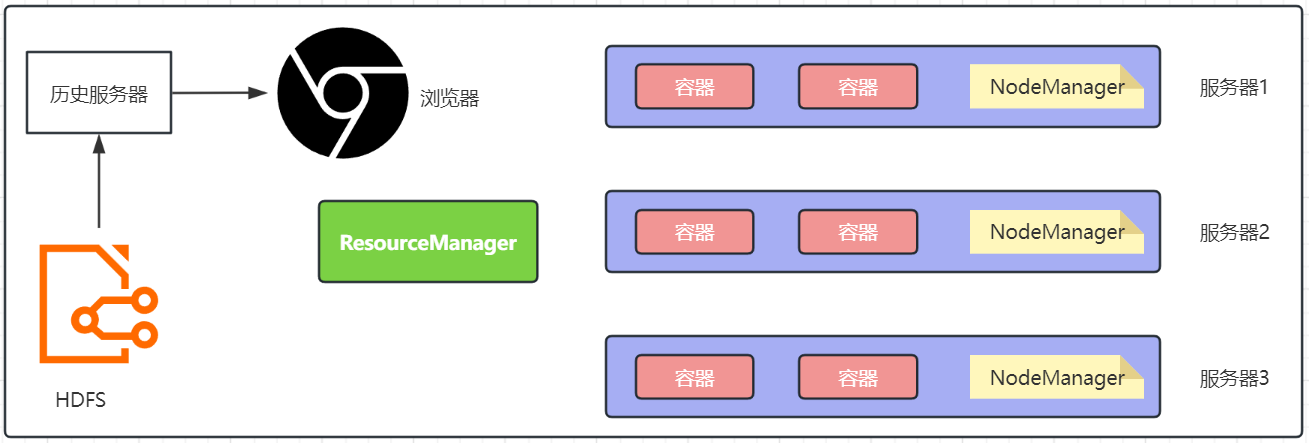
⑵.历史服务器配置
JobHistoryServer 历史服务器功能:
- 提供 WEB UI 站点,供用户在浏览器上查看程序日志
- 可以保留历史数据,随时查看历史运行程序信息
JobHistoryServer 需要配置:
开启日志聚合,即从容器中抓取日志到 HDFS 集中存储
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description>开启日志聚合</description>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/tmp/logs</value>
<description>程序日志HDFS的存储路径</description>
</property>
配置历史服务器端口和主机
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
<description>历史服务器web端口为node1的19888</description>
</property>
历史服务器配置和启动,在后续部署YARN集群环节讲解
五、MapReduce和YARN的部署
5.1.部署说明
Hadoop HDFS分布式文件系统,我们会启动:
- NameNode进程作为管理节点
- DataNode进程作为工作节点
- SecondaryNamenode作为辅助
同理,Hadoop YARN分布式资源调度,会启动:
- ResourceManager进程作为管理节点
- NodeManager进程作为工作节点
- ProxyServer、JobHistoryServer这两个辅助节点
那么,MapReduce怎么启动呢?
MapReduce运行在YARN容器内,无需启动独立进程
所以关于MapReduce和YARN的部署,其实就是2件事情:
- 关于MapReduce: 修改相关配置文件,但是没有进程可以启动
- 关于YARN: 修改相关配置文件, 并启动ResourceManager、NodeManager进程以及辅助进程(代理服务器、历史服务器)
汇总说明:
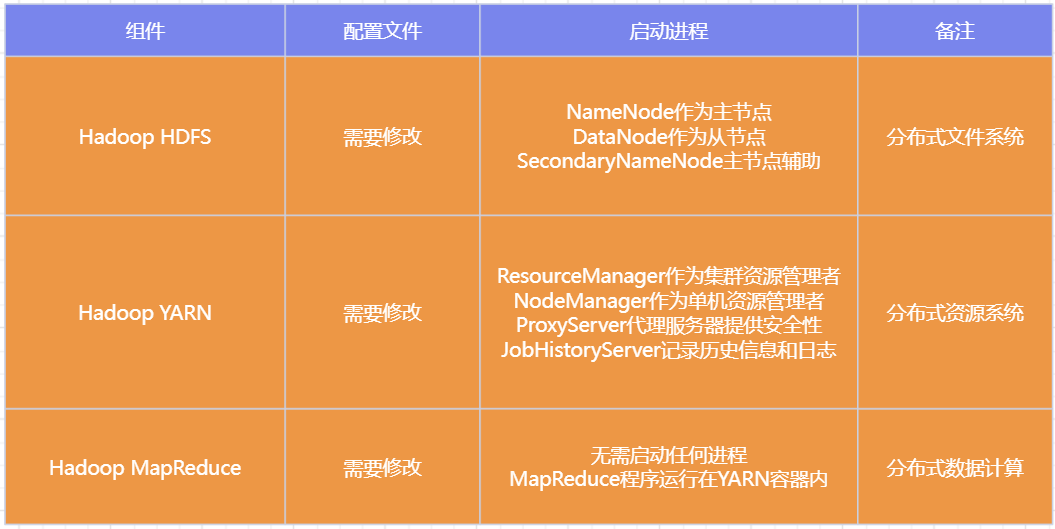
5.3.集群规划
有3台服务器,其中node1配置较高,集群规划如下:
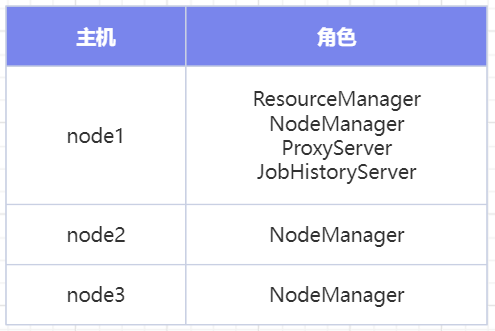
5.4.MapReduce配置文件
5.4.1.MapReduce配置文件
在 $HADOOP_HOME/etc/hadoop 文件夹内,修改
- mapred-env.sh文件,添加如下环境变量
#设置JDK路径 export JAVA_HOME=/export/server/jdk #设置JobHistoryServer进程内存为1G export HADOOP_JOB_HISTORYSERVER_HEAPSIZE=1000 #设置日志级别为INFO export HADOOP_MAPRED_ROOT_LOGGER=INFO,RFA
- mapred-site.xml文件,添加如下配置信息
<configuration> <!-- 设置MapReduce的运行框架为YARN --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> <description>MapReduce的运行框架设置为YARN</description> </property> <!-- 历史服务器通讯端口 --> <property> <name>mapreduce.jobhistory.address</name> <value>node1:10020</value> <description>历史服务器通讯端口为node1:10020</description> </property> <!-- 历史服务器web端口 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>node1:19888</value> <description>历史服务器web端口为node1的19888</description> </property> <!-- 历史信息在HDFS的记录临时路径 --> <property> <name>mapreduce.jobhistory.intermediate-done-dir</name> <value>/data/mr-history/tmp</value> <description>历史信息在HDFS的记录临时路径</description> </property> <!-- 历史信息在HDFS的记录路径 --> <property> <name>mapreduce.jobhistory.done-dir</name> <value>/data/mr-history/done</value> <description>历史信息在HDFS的记录路径</description> </property> <!-- MapReduce Application Master的环境变量设置 --> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value> <description>MapReduce HOME设置为HADOOP_HOME</description> </property> <!-- Map任务的环境变量设置 --> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value> <description>MapReduce HOME设置为HADOOP_HOME</description> </property> <!-- Reduce任务的环境变量设置 --> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value> <description>MapReduce HOME设置为HADOOP_HOME</description> </property> </configuration>
5.4.2.YARN配置文件
在 $HADOOP_HOME/etc/hadoop 文件夹内,修改:
- yarn-env.sh文件,添加如下4行环境变量内容:
# 设置JDK路径的环境变量 export JAVA_HOME=/export/server/jdk # 设置HADOOP_HOME的环境变量 export HADOOP_HOME=/export/server/hadoop # 设置配置文件路径的环境变量 export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop # 设置日志文件路径的环境变量 export HADOOP_LOG_DIR=$HADOOP_HOME/logs
- yarn-site.xml文件,配置如图属性
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
<description>ResourceManager设置在node1节点</description>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data/nm-local</value>
<description>NodeManager中间数据本地存储路径</description>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/data/nm-log</value>
<description>NodeManager数据日志本地存储路径</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>为 MapReduce程序开启Shuffle服务 </description>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://node1:19888/jobhistory/logs</value>
<description>历史服务器 URL</description>
</property>
<property>
<name>yarn.web-proxy.address</name>
<value>node1:8089</value>
<description>代理服务器主机和端</description>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description>开启日志聚合</description>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/tmp/logs</value>
<description>程序日志HDFS的存储路径</description>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
<description>选择公平调度器</description>
</property>
5.4.3.分发配置文件
MapReduce和YARN的配置文件修改好后,需要分发到其它的服务器节点中。
scp mapred-env.sh mapred-site.xml yarn-env.sh yarn-site.xml node2:`pwd`/
scp mapred-env.sh mapred-site.xml yarn-env.sh yarn-site.xml node3:`pwd`/
分发完成配置文件,就可以启动YARN的相关进程啦。
5.4.4开始启动YARN集群
在node1服务器,以hadoop用户执行
⑴.首先执行:$HADOOP_HOME/sbin/start-yarn.sh,一键启动所需的:
- ResourceManager
- NodeManager
- ProxyServer(代理服务器)
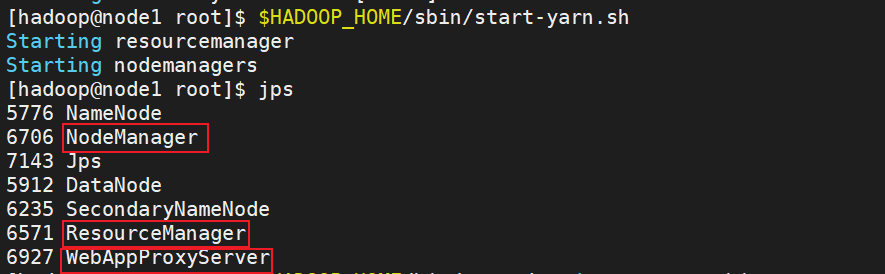
⑵.其次执行:$HADOOP_HOME/bin/mapred --daemon start historyserver 启动: HistoryServer(历史服务器)

5.4.6查看YARN的WEB UI页面
打开 http://node1:8088 即可看到YARN集群的监控页面(ResourceManager的WEB UI)
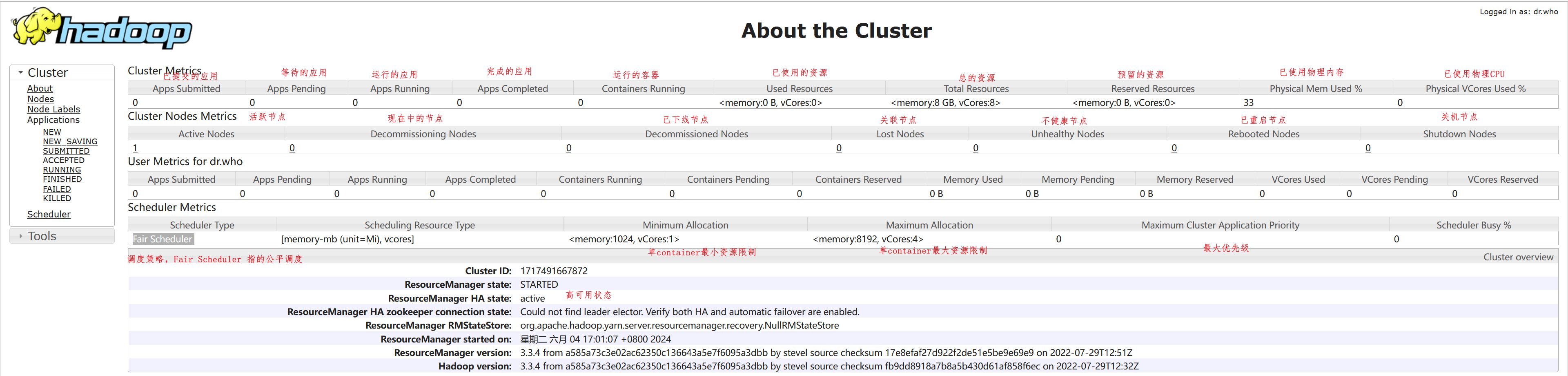
⑴.节点信息详解(Nodes)
Yarn 的集群节点的情况,从 Active Nodes 下面的数字点击进去,可以看到具体的节点列表信息。里面包含了所在机架、运行状态、节点地址、最后健康上报上报时间、运行的容器个数、使用内存CPU 等信息,还有版本号。如下图。

说明:
- Node Lables:节点标签,通过对节点打标签,可以控制任务运行在特定类型的标签节点上
- Rack:机架,可以通过机架感知机制与配置
- Node State:节点状态信息,Running表示运行正常
- Node Address: NodeManager的ip地址和访问端口
- Node HTTP Address:NodeManager的web应用HTTP访问地址
- Last health-update:节点健康汇报时间
- Health-report:心跳报告的存储路径
- Containers:节点内正在运行的Containers个数
- Mem Used:节点已用内存
- Mem Avail:节点可用的总内存(默认是8G yarn.nodemanager.resource.memory-mb配置)
- Vcore Used:节点正在运行作业所占用的CPU核数
- Vcores Avail:节点可用的总虚拟CPU核数(yarn.nodemanager.resource.cpu-vcores配置)
⑵.应用列表信息(applications)

包括以下内容:
- 任务的ID
- 任务的名字
- 应用的类型和所在队列
- 任务的开始、启动时间和结束时间
- 任务当前的状态和最终状态。
- 任务占用的相关资源。
- 任务的应用类型主页。如果是 spark 任务的话,显示的是 spark 的 ui 页面
六、MapReduce和YARN的使用
6.1.集群启动命令介绍
常用的进程启动命令如下:
⑴.一键启动YARN集群: $HADOOP_HOME/sbin/start-yarn.sh
- 会基于yarn-site.xml中配置的yarn.resourcemanager.hostname来决定在哪台机器上启动resourcemanager
- 会基于workers文件配置的主机启动NodeManager
⑵.一键停止YARN集群: $HADOOP_HOME/sbin/stop-yarn.sh
⑶.在当前机器,单独启动或停止进程
- $HADOOP_HOME/bin/yarn --daemon start|stop resourcemanager|nodemanager|proxyserver
- start和stop决定启动和停止
- 可控制resourcemanager、nodemanager、proxyserver三种进程
⑷.历史服务器启动和停止
- $HADOOP_HOME/bin/mapred --daemon start|stop historyserver
6.2.提交MapReduce程序至YARN运行
6.2.1.语法说明
在部署并成功启动YARN集群后,我们就可以在YARN上运行各类应用程序了。YARN作为资源调度管控框架,其本身提供资源供许多程序运行,常见的有:
- MapReduce程序
- Spark程序
- Flink程序
Spark和Flink是大数据的内容,我们目前先来体验一下在YARN上执行MapReduce程序的过程。
Hadoop官方内置了一些预置的MapReduce程序代码,我们无需编程,只需要通过命令即可使用。常用的有2个MapReduce内置程序:
- wordcount:单词计数程序。统计指定文件内各个单词出现的次数
- pi:求圆周率,通过蒙特卡罗算法(统计模拟法)求圆周率
这些内置的示例MapReduce程序代码,都在下面文件内:
$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar
可以通过 hadoop jar 命令来运行它,提交MapReduce程序到YARN中。语法:
hadoop jar 程序文件 java类名 [程序参数] ... [程序参数]
6.2.2.案例
6.2.2.1.提交wordcount示例程序
单词计数示例程序很简单:
- 给定数据输入的路径(HDFS)、给定结果输出的路径(HDFS)
- 将输入路径内的数据中的单词进行计数,将结果写到输出路径
⑴.准备一份数据文件,并上传到HDFS中。
Hello, this is a sample input file for word count.
We will use this file to demonstrate the word count example.
⑵.将左侧内容保存到Linux中为words.txt文件,并上传到HDFS
# 在HDFS中创建文件夹/input/wordcount,用于存放统计文件
hadoop fs -mkdir -p /input/wordcount
# 用于存储统计出来的结果
hadoop fs -mkdir /output
# 上传到HDFS
hadoop fs -put words.txt /input/wordcount/
⑶.执行如下命令,提交示例MapReduce程序WordCount到YARN中执行
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar wordcount hdfs://node1:8020/input/wordcount/ hdfs://node1:8020/output/wc1
注意:
- 参数wordcount,表示运行jar包中的单词计数程序(Java Class)
- 参数1是数据输入路径(hdfs://node1:8020/input/wordcount/)
- 参数2是结果输出路径(hdfs://node1:8020/output/wc1), 需要确保输出的文件夹不存在
⑷.提交程序后,可以在YARN的WEB UI页面看到运行中的程序(http://node1:8088/cluster/apps)
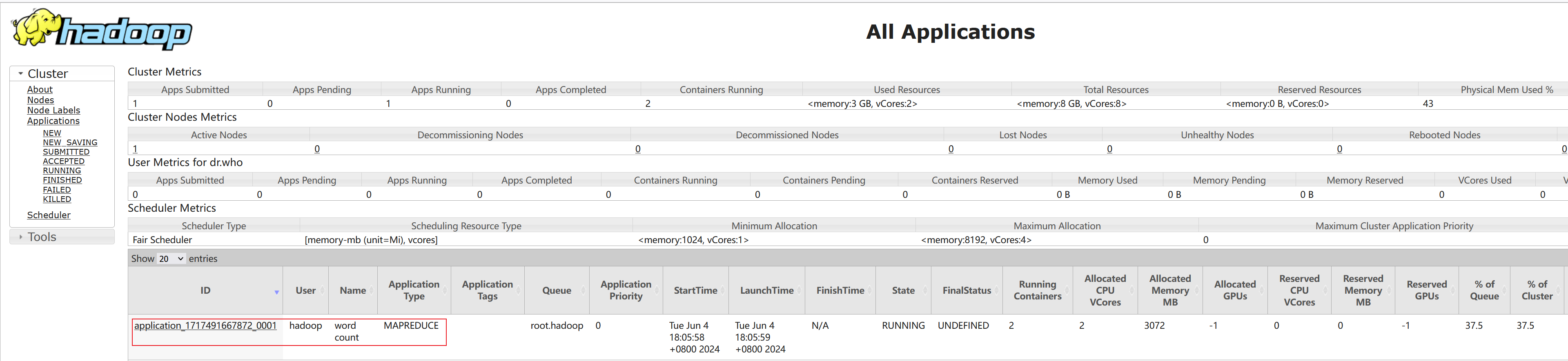
⑸.执行完成后,可以查看HDFS上的输出结果
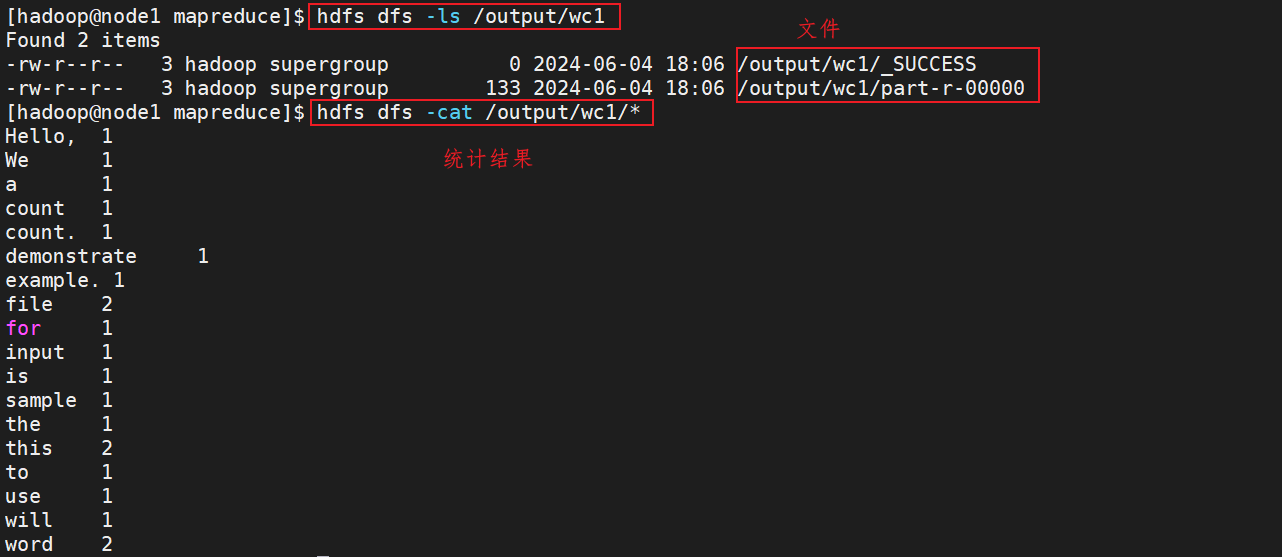
说明:
- _SUCCESS文件是标记文件,表示运行成功,本身是空文件
- part-r-00000,是结果文件,结果存储在以part开头的文件中
⑹.执行完成后,可以借助历史服务器查看到程序的历史运行信息
ps:如果没有启动历史服务器和代理服务器,此操作无法完成(页面信息由历史服务器提供,鼠标点击跳转到新网页功能由代理服务器提供)

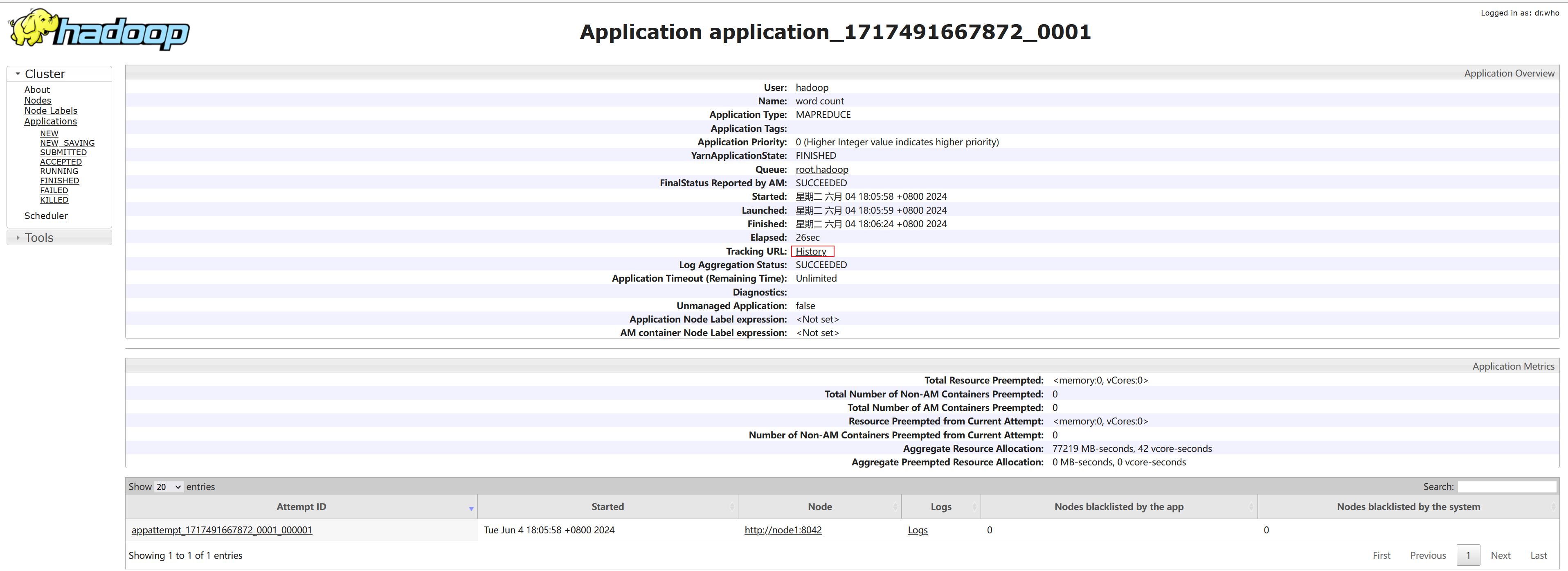
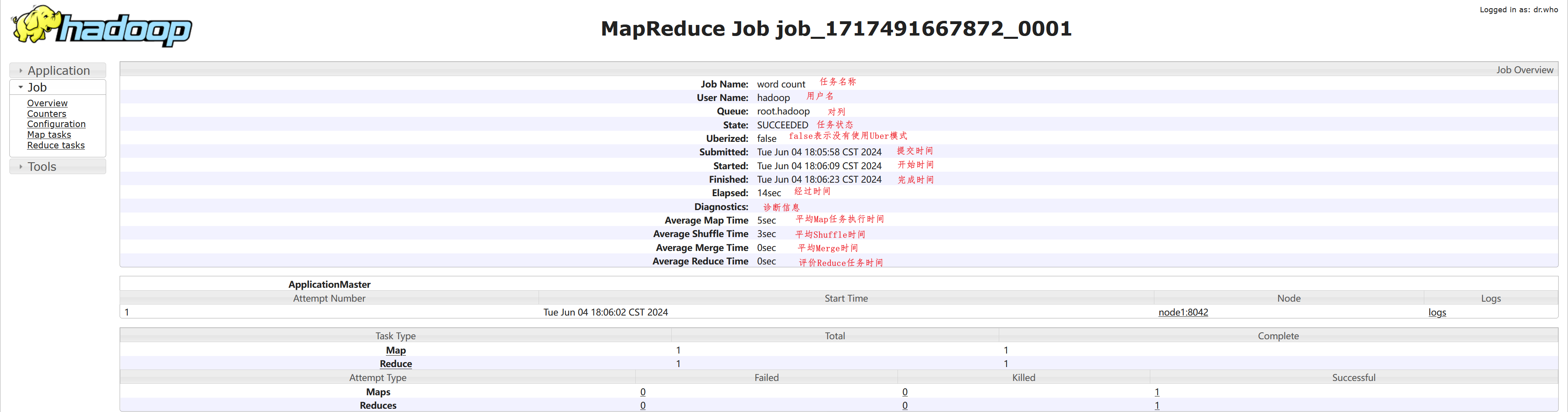
这是一个关于Hadoop任务的执行摘要说明:
-
Job Name: 任务名称,这里是 "word count",表示这个任务是用来进行单词统计的。
-
User Name: 用户名称,这里是 "hadoop",表示这个任务是由用户 "hadoop" 提交的。
-
Queue: 队列,这里是 "root.hadoop",表示这个任务被提交到了名为 "hadoop" 的队列中。
-
State: 任务状态,这里是 "SUCCEEDED",表示任务执行成功完成。
-
Uberized: 是否使用了Uber任务模式,这里是 "false",表示任务没有使用Uber模式。
-
Submitted: 提交时间,这里是 "Tue Jun 04 18:05:58 CST 2024",表示任务在2024年6月4日18点5分58秒被提交。
-
Started: 开始时间,这里是 "Tue Jun 04 18:06:09 CST 2024",表示任务在2024年6月4日18点6分9秒开始执行。
-
Finished: 完成时间,这里是 "Tue Jun 04 18:06:23 CST 2024",表示任务在2024年6月4日18点6分23秒执行完成。
-
Elapsed: 经过时间,这里是 "14sec",表示任务执行总共耗时14秒。
-
Diagnostics: 诊断信息,这里是空白,通常用于记录任务执行过程中的错误信息或警告。
-
Average Map Time: 平均Map任务执行时间,这里是 "5sec",表示平均每个Map任务执行耗时5秒。
-
Average Shuffle Time: 平均Shuffle时间,这里是 "3sec",表示平均每个Shuffle操作耗时3秒。
-
Average Merge Time: 平均Merge时间,这里是 "0sec",表示平均每个Merge操作耗时0秒。
-
Average Reduce Time: 平均Reduce任务执行时间,这里是 "0sec",表示平均每个Reduce任务执行耗时0秒。
⑺.查看运行日志
点击logs即可查看日志
日志如下:
点击logs链接,可以查看到详细的运行日志信息。此功能基于:
1. 配置文件中配置了日志聚合功能,并设置了历史服务器
<property> <name>yarn.log.server.url</name> <value>http://node1:19888/jobhistory/logs</value> <description></description> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> <description>Configuration to enable </description> </property>
2. 启动了代理服务器和历史服务器
3. 历史服务器进程会将日志收集整理,形成可以查看的网页内容供我们查看。
所以,如果发现无法查看程序运行历史以及无法查看程序运行日志信息,请检查上述1、2、3是否都正确设置。
6.2.2.2.提交求圆周率示例程序
可以执行如下命令,使用蒙特卡罗算法模拟计算求PI(圆周率)
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar pi 3 10000
说明:
- 参数pi表示要运行的Java类,这里表示运行jar包中的求pi程序
- 参数3,表示设置几个map任务
- 参数10000,表示模拟求PI的样本数(越大求的PI越准确,但是速度越慢)
执行如下:

七、YARN(面试)
7.1YARN组成
- 物理层面两大角色:Resource Manager、Node Manager
详细说明:
① Resource Manager :负责资源的分配与调度,接收客户端请求、监控NodeManager以及AppMaster
② Node Manager :NM,管理本机资源,处理Resource Manager与AppMaster相关命令
③ AppMaster :全称Application Master,运行在NodeManager节点中,负责向RM申请资源并分配给内部任务,负责任务的监控、容错以及销毁等工作(每个Job任务都有一个对应的AppMaster)
角色之间关系:
① 客户端提交任务到Yarn集群中的RM。Yarn集群接收到这个任务后,会从各个nodemanager(NM)节点中, 随机找到一台有资源的节点, 用于启动AppMaster程序, 启动后, AppMaster汇报给resourcemanager(RM),并建立心跳机制
② AppMaster会根据任务的需求,主动向resourcemanager(RM)申请资源, RM根据各个NM节点的情况,准备好相关的资源信息, 等待AppMaster的拉取
③ AppMaster程序获取到了相关的资源后, 连接对应nodemanager(NM)节点, 让其创建任务所需的资源容器(Container),然后让其在容器中启动对应的MapTask和ReduceTask,同时反向注册回AppMaster(建立心跳机制,让AppMaster可以时刻感知到任务执行状态)。
④ 接下来AppMaster开始监控任务的执行,各个任务定时向AppMaster汇报自己的状态和进度,以便当任务失败时可以重启任务;当任务执行结束,AppMaster也会通知RM回收所有的资源与自己。
7.2.YARN执行MapReduce流程
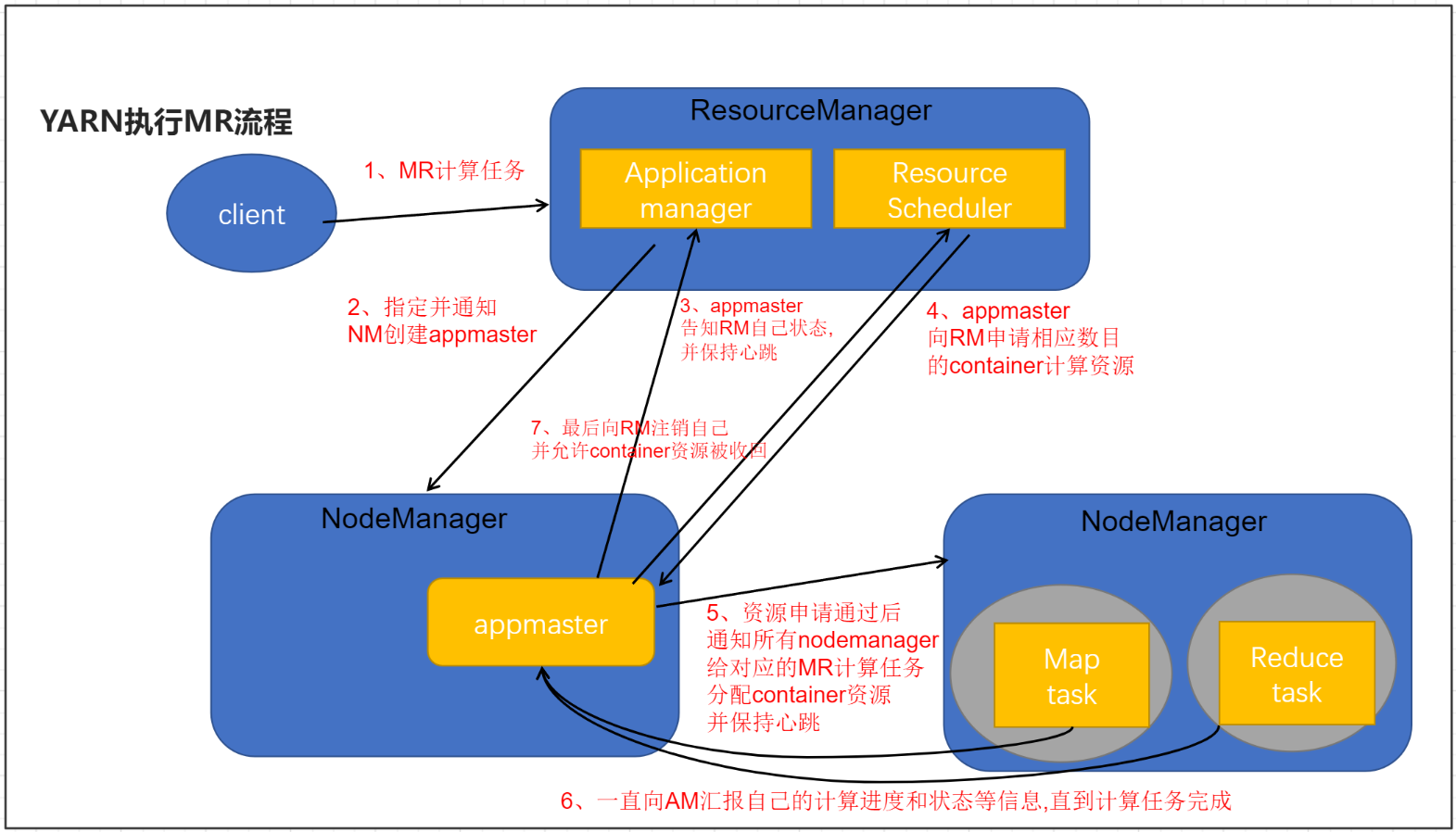
执行流程如下:
- 客户端提交一个MR程序给ResourceManager(校验请求是否合法...)
- 如果请求合法,ResourceManager随机选择一个NodeManager用于生成appmaster(应用程序控制者,每个应用程序都单独有一个appmaster)
- appmaster会主动向ResourceManager应用管理器(application manager)注册自己,告知自己的状态信息,并且保持心跳
- appmaster会根据任务情况计算自己所需要的container资源(cpu,内存),主动向ResourceManager资源调度器(resource scheduler)申请并获取这些container资源
- appmaster获取到container资源后,把对应指令和container分发给其他NodeManager,让NodeManager启动task任务(maptask,reducetask)
- NodeManager要和appmaster保持心跳,把自己任务计算进度和状态信息等同步给appmaster,(注意当maptask任务完成后会通知appmaster,appmaster接到消息后会通知reducetask去maptask那儿拉取数据)直到最后任务完成
- appmaster会主动向ResourceManager注销自己(告知ResourceManager可以把自己的资源进行回收了,回收后自己就销毁了)
八、YARN的三大调度器(面试)
yarn提供了三大调度器分别为:
- 先进先出调度器: FIFO Scheduler
- 公平调度器:Fair Scheduler
- 容量调度器: Capacity Scheduler
调度器的配置在yarn-site.xml查找,如果没有就去yarn-default.xml中找
网址: https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
配置项和默认值如下:
yarn.resourcemanager.scheduler.class=org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler
8.1.先进先出调度器: FIFO Scheduler
FIFO Scheduler 把应用按提交的顺序排成一个队列,在进行资源分配的时候,先给队列中最头上的应用进行分配资源,待最头上的应用需求满足后再给下一个分配,以此类推。
- 优点:能够保证每一个任务都能拿到充足的资源, 对于大任务的运行非常有好处
- 缺点:如果先有大任务后有小任务,会导致后续小任务无资源可用, 长期处于等待状态

8.2.公平调度器:Fair Scheduler
Fair Scheduler 不需要保留集群的资源,因为它会动态在所有正在运行的作业之间平衡资源
Fair Scheduler 当一个大job提交时,只有这一个job在运行,此时它获得了所有集群资源;当后面有小任务提交后,Fair调度器会分配一半资源给这个小任务,让这两个任务公平的共享集群资源。
- 好处:保证每个任务都有资源可用, 不会有大量的任务等待在资源分配上
- 弊端:如果大任务非常的多, 就会导致每个任务获取资源都非常的有限, 也会导致执行时间会拉长

8.3.容量调度器: Capacity Scheduler
Capacity Scheduler 为每个组织分配专门的队列和一定的集群资源,这样整个集群就可以通过设置多个队列的方式给多个组织提供服务了。在每个队列内部,资源的调度是采用的是先进先出(FIFO)策略。
- 好处:可以保证多个任务都可以使用一定的资源, 提升资源的利用率
- 弊端:如果遇到非常的大的任务, 此任务不管运行在那个队列中, 都无法使用到集群中所有的资源, 导致大任务执行效率比较低,当任务比较繁忙的时候, 依然会出现等待状态
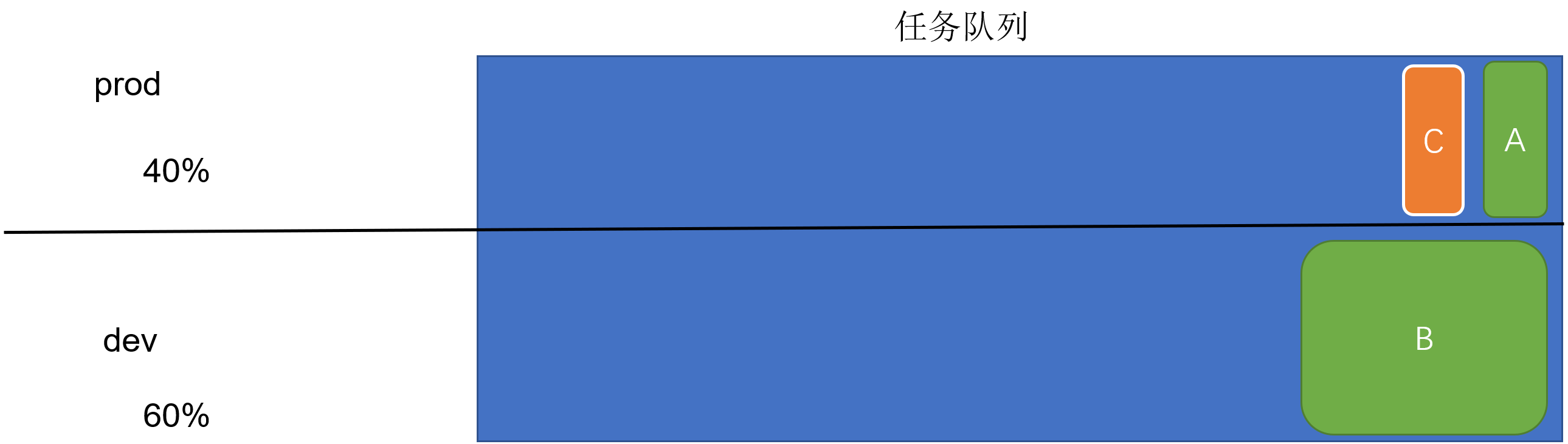
调度器的使用是通过yarn-site.xml配置文件中的yarn.resourcemanager.scheduler.class参数进行配置的,默认采用Capacity Scheduler调度器
下面是一个简单的Capacity调度器的配置文件,文件名为capacity-scheduler.xml。
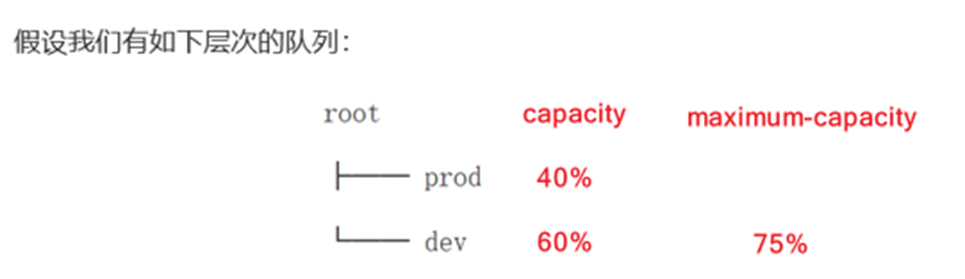
在这个配置中,在root队列下面定义了两个子队列prod和dev,分别占40%和60%的容量、
<property> <!-- 队列分为两份 prod 和 dev --> <name>yarn.scheduler.capacity.root.queues</name> <value>prod,dev</value> </property> <property> <!--prod占比 40%--> <name>yarn.scheduler.capacity.root.prod.capacity</name> <value>40</value> </property> <property> <!--dev占比 60%--> <name>yarn.scheduler.capacity.root.dev.capacity</name> <value>60</value> </property> <property> <!-- dev的最大占比 75%--> <name>yarn.scheduler.capacity.root.dev.maximum-capacity</name> <value>75</value> </property>
prod由于没有设置maximum-capacity属性,它有可能会占用集群全部资源。dev的maximum-capacity属性被设置成了75%,所以即使prod队列完全空闲dev也不会占用全部集群资源,也就是说,prod队列仍有25%的可用资源用来应急。
8.4.总结
FIFO scheduler: 先进先出的调度器 (一般不使用, 除非整个集群就你自己用)
- 措施: 将提交过来任务全部放置到一个队列, 然后按照先进先出的特点进行资源分配, 会先满足第一个任务, 满足后, 接着在满足第二个, 以此类推
- 弊端: 如果第一个任务比较大, 有可能将整个集群中所有的资源都占用了, 导致后续的任务长时间等待, 这样是非常不友好
- 好处: 保证每一个任务拿到最大的资源
Capacity Scheduler : 容量调度器 (apache官方版本 默认采用容量调度方案)
- 措施: 可以提前定义多个队列(每个队列依然是FIFO特性), 每个队列可以使用集群中部分资源, 可以通过设置每个队列的比例, 当提交任务的时候, 需要指定将任务提交到那个队列中来, 还支持资源抢占模式
- 好处:可以让多个任务都拥有一部分资源, 不会因为某个任务将全部资源占用, 而导致其他任务没有资源可用, 同时通过资源抢占, 可以让大的任务拥有更多的一些资源(一般拿不到100%资源)
- 弊端:如果遇到超大任务, 由于无法获取到资源中所有资源, 可能会导致任务执行效率会有所降低
Fair Scheduler: 公平调度器 (CDH(cloudera)商业版本hadoop默认采用调度方案)
- 措施: 当任务到达队列后, 集群会将所有的资源都交给第一个任务, 让其获取最大的资源 以达到快速运行, 在此运行过程中, 如果有了新的任务到来, 会让其先前释放出最多50%资源, 交给下一个任务来运行, 当下一个任务执行完成后, 如果发现上一个任务依然没有跑完, 还会在此将资源交给上一个任务
- 注意: 在找上一个任务获取资源的时候, 采用 先等待 后强制措施
- 好处:可以保证让所有任务都拿到相对公平的资源, 保证大家都可以运行
- 弊端:如果任务量比较庞大, 就会导致每个任务获取资源都非常的有限, 也会导致执行时间会拉长
九、[扩展] 使用yarn命令查看日志信息
9.1.yarn日志查看
1)查看所有yarn日志
yarn application -list -appStates ALL Total number of applications (application-types: [], states: [NEW, NEW_SAVING, SUBMITTED, ACCEPTED, RUNNING, FINISHED, FAILED, KILLED] and tags: []):1 Application-Id Application-Name Application-Type User Queue State Final-State Progress Tracking-URL application_1673666139292_0001 word count MAPREDUCE root default FINISHED SUCCEEDED 100% http://node1:19888/jobhistory/job/job_1673666139292_0001
2)查看具体某个任务信息
yarn logs -applicationId application_1673666139292_0001
9.2.yarn日志存储位置:(远程存储yarn日志)
1)查看yarn-site.xml,确定log配置目录
<property> <name>yarn.nodemanager.remote-app-log-dir</name> <value>/app-logs</value> </property>
说明:以上配置完成后,上传到node2、node3,然后重启整个集群
scp yarn-site.xml node2:$PWD
scp yarn-site.xml node3:$PWD
2)查看日志文件信息(注意日期和时间)
[hdfs@node1 root]$ hdfs dfs -ls /app-logs/root/bucket-logs-tfile/0001
Found 1 items
drwxrwx--- - hdfs hadoop 0 2022-05-02 04:18 /app-logs/root/bucket-logs-tfile/0001/application_1673668518162_0001
3)查看日志详情
yarn logs -applicationId application_1673668518162_0001

 浙公网安备 33010602011771号
浙公网安备 33010602011771号