Python第三方库的安装、调试程序、
一、Python第三方库的安装
之前已经说过,之所以python能比用其他更多语言写出更简洁的代码,一个原因是python高层抽象的简洁的语法,另一个重要原因就是其丰富的内置库和海量优秀的第三方库。第三方库和内置库唯一的区别是,前者不是python解释器安装包内置的。但是第三方库安装好以后,其导入使用的方式和内置库、自己开发的库(包括包和模块)没有任何区别
1.1.Pip安装第三方库
在python中,安装第三方库,现在基本使用pip工具。这个工具会从网络上的python库网站下载第三方库安装包进行安装。其过程有点像yun和apt-get,python2版本在python2.7.9以上python3版本在3.4以上的安装包,已经包含了pip工具
直接执行
pip install <第三方库名字>
例如,安装著名的web框架Django,只需要执行pip install Django就可以了,安装好的包基本上都放在python的lib/site-packages目录下
1.2.Pycharm安装
在File菜单,在下拉菜单中选择settings,其次在project interpreter(项目解释器)中点击“+”号
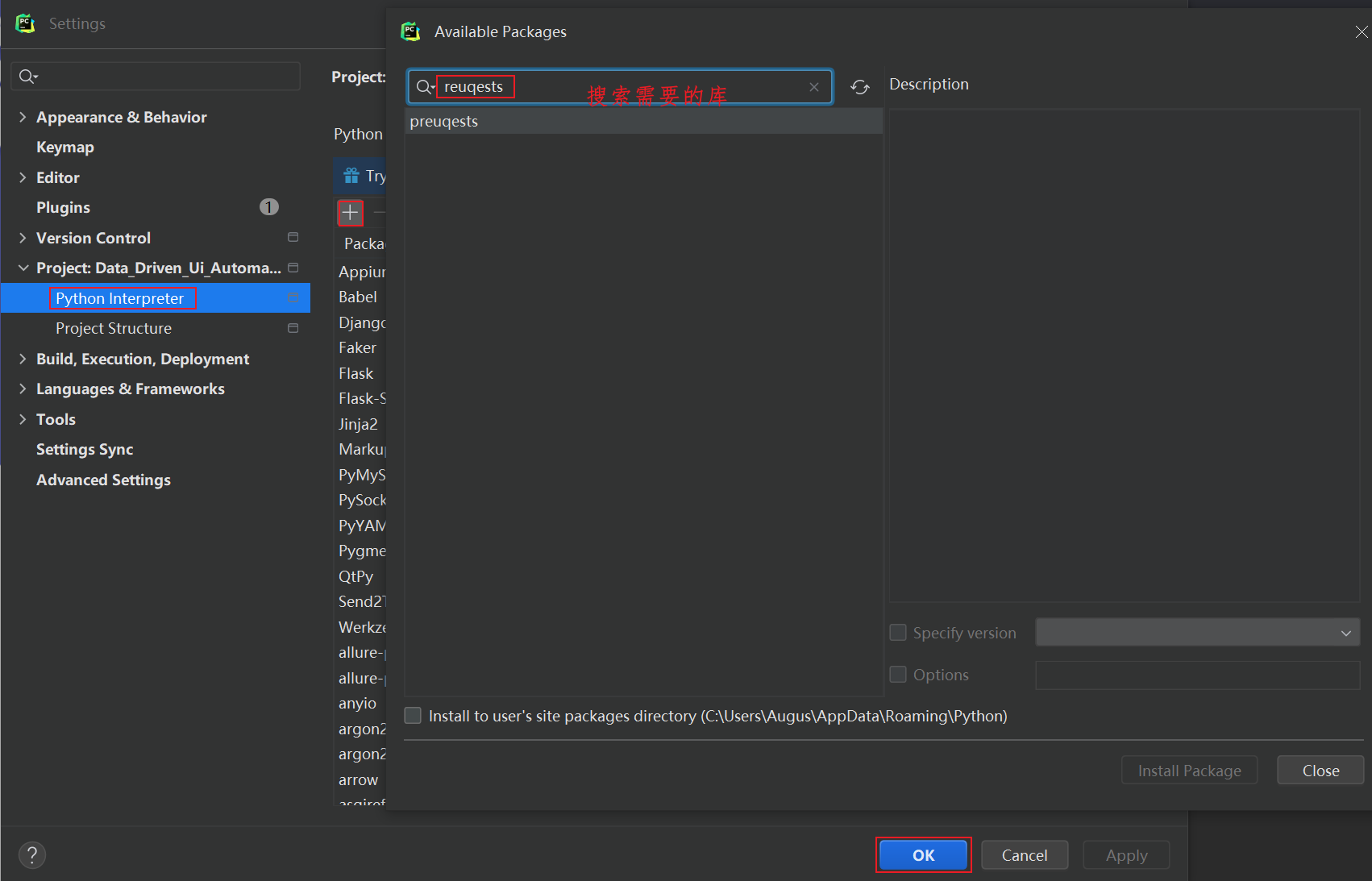
然后在搜索框中输入所要添加的库名称,然后在左下角点击Install Package,安装完成之后就会有提示,关闭重启即可使用该库
二、调试程序
为什么要调试?
当程序复杂一点,我们经常会发现程序并没有按照我们设想的那样工作。那么问题来了,我们可能一步步的自信检查代码,如果还是不能发现原因,这时候需要进行调试,调试方法简单来说,就是逐步缩小,怀疑出现问题的区域,直到发现问题所在
- 简单调试可以用直接加print语句
- 如果有必要可以借助集成开发环境的调试工具箱
2.1.print语句调试
刚才说过,简单调试可以用直接加print语句的方法,逐步缩小出现问题的区域
假设我们现在有一个数据文件,记录每个班学生的年龄
Augus:15,Tom:18,Mike:16,Lrin:16,Wall:13
我们读取里面的数据,需要计算出那个年龄段学生最多,可以先读取出来,存放在列表中:
['Augus:15,Tom:18,Mike:16,Lrin:16,Wall:13']
然后进行切片,找出年龄段人数最多的学生
fp = open('test.txt') list_num = fp.read() fp.close() studentinfo = {} for one in list_num.split(','): name,age = one.split(':') if age in studentinfo: studentinfo[age].append(name) else: studentinfo[age] = [name] curMax = 0 maxCountAge = 0 #找到学生最多的年龄段 for age,names in studentinfo.items(): countName = len(names) if countName >= curMax: curMax = countName maxCountAge = age print("%s岁的学生年龄最多,人数为%s" % (maxCountAge,curMax))
上述方法中,我们可以用print语句吧三个步骤的计算结果打印出来,看看问题在哪里;
2.2.集成开发环境调试
在现实的工作中,我们代码量往往比较大,这时光靠print语句打印输出有问题的地方会非常麻烦,需要添加很多print语句来打印怀疑有问题的地方很麻烦,需要添加很多多print语句,添加完成后,还有删除对应的print语句,这时候我们往往会需要集成开发环境(IDE)的调试功能。python的集成开发环境目前推荐使用pycharm,最常用的调试技巧是加断点,单步跨行(夸函数,进函数),查看变量内容,查看函数的调用栈。
三、中文字符集与编码
3.1.基本概念
字符集(character Set):字符集是用来表示语言符合的数字的集合。注意了这里说的只是数字,没有任何说明用什么方法来存储数字,常见的字符集有:
- ASCII 字符集
- Uncode
- gb2312、gbk、gbk 18030
字符编码(Encoding)和解码(Decoding):字符编码是指怎么把字符集里面的字符对应的数字存储(比如磁盘)下拉的方法,常见的字符编码有:
- ASCII
- UTF-8
- gb2312、gbk、gbk18030

字符解码是字符编码的逆向过程,从编码好的内容还原成数值形式。比如utf8编码好的字符串可以还原成Unicode数值形式
3.2.字形和字体
要把字符显示在显示器或者打印机上,我们必须定义一个给定的字符怎么显示的方式,一个文字的字形显示,英文叫做glyph,它通过点阵或者矢量图的方式显示字体,字体文件就是存储了一种字符编码里面所有文字到字形的集合,总结一下前面的分析,文字显示应该是这样:
- 步骤1:文字首先以某种编码保存在文件中
- 步骤2:程序读取文件中的文字并且解码到Unicode
- 步骤3:程序调用操作系统Windows服务,安装Unicode在字体文件中查找字体图像,画到窗口上
3.3.python代码里面加入中文
代码文件既然是存储在磁盘上的文件,就一定是以某种编码格式保存的,比如utf8,gbk等
首先强调一点,python3中解释器加载代码文件的时候,默认是认为文件的编码格式是utf8。这和python2不同,python默认是ASCII码的,而IDE,比如pycharm创建代码文件的时候,确实也就是用utf8保存文件的,所以在python3运行代码的时候,如果代码文件就是utf编码的情况下,无需特别处理,代码里可以直接使用中文
#中文 print('欧耶')
运行一下,发现可以正常执行。
但是,如果代码文件不是utf8编码,而不是gbk编码,就不行了。我们可以用pycharm打开上述代码文件,在右下角这里,选择gbk编码,选择好之后,弹出的对话框中,选择convert。再次运行代码,就会出现错误, 要解决这个问题,就必须告诉解释器,这个代码不是utf8编码的,而是GBK编码的。像下面这样:
#coding = gbk #中文 print('abc')
在代码的第一行或者第二行显示的加上一个注释#coding=utf-8 指明代码文件的编码方式,当然我们也可以指明请其他编码方式,比如gbk等
注意:指明编码方式一定要和你真正的文件编码方式一致。所以我们建议使用notepad++,或者pycharm这种编码处理比较好的文本编辑器,而且我们建议,为了避免不必要的麻烦,python代码文件均应该使用utf8的编码方式

 浙公网安备 33010602011771号
浙公网安备 33010602011771号