


容器学习笔记
容器:
程序中的“容器”也被用来容纳和管理数据。
数组作为一种容器,可以快速地访问数组元素,效率高。但是,容量需要事先定义好,不能随着需求的变化而扩容。
容器接口的层次:
1.Collection接口
List子接口(有序可重复):ArrayList,LinkedList,Vector
Set子接口(无序不可重复):Hashset,Treeset
2.Map接口(存储键值对)
Hashmap,Treemap,HashTable、Properties等
泛型:
形象地说,泛型就是容器的标签。我们可以把“泛型”理解为数据类型的一个占位符(形式参数),即告诉编译器,在调用泛型时必须传入实际类型。
我们可以在类的声明处增加泛型列表,如:<T,E,V>。泛型E像一个占位符一样表示“未知的某个数据类型”,我们在真正调用的时候传入这个“数据类型”。
具体格式:
定义类时:class 类名 <E> { }
根据类创建对象时(String也可根据需要换成其他类型):类名 <String> 对象名 = new 类名 <String> ()
在类中写方法时,也要根据需要传入泛型,作为形参。调用该方法时,再具体化。
Collection:
Collection接口的两个子接口是List、Set接口。
Collection接口中定义的方法:(List、Set通用)
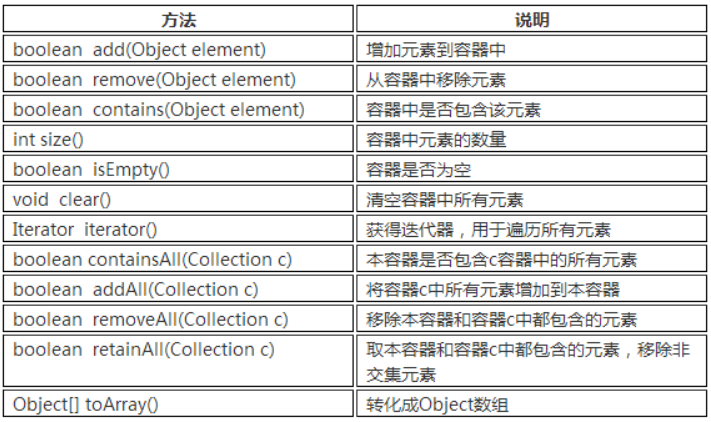
List:
List是有序(每个元素都有索引标记)、可重复(允许加入重复的元素,即equals为true)的容器。
因此,List有一些专属的关于索引的方法:
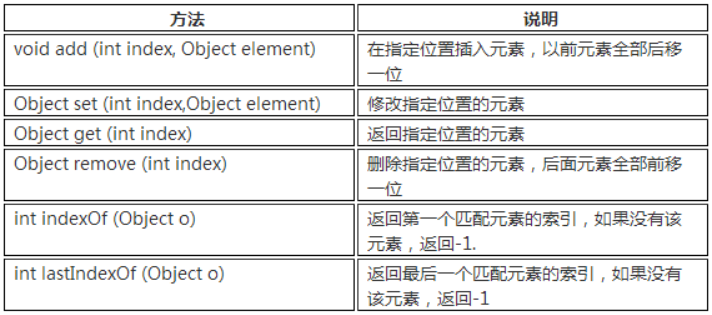
ArrayList:
底层是用数组实现的存储。 特点:查询效率高,增删效率低,线程不安全。
手工实现ArraryList(见代码):重点掌握利用数组拷贝方法arraycopy()实现add,remove,toString重写,get等方法。
LinkedList:
用双向链表实现的存储。特点:查询效率低,增删效率高,线程不安全。
双向链表也叫双链表,是链表的一种,它的每个数据节点中都有两个指针,分别指向前一个节点和后一个节点。 所以,从双向链表中的任意一个节点开始,都可以很方便地找到所有节点。
每个节点的内容:1.前一个节点
2.后一个节点
3.本节点保存的数据
手工实现LinkedList(见代码):重点掌握在创建Node类的基础上,根据双链表的思路实现add,remove,toString重写,get等方法。
Vector:
Vector底层是用数组实现的List,相关的方法都加了同步检查,因此“线程安全,效率低”。 比如,indexOf方法就增加了synchronized同步标记。
List总结:
1. 需要线程安全时,用Vector。
2. 不存在线程安全问题时,并且查找较多用ArrayList(一般使用它)。
3. 不存在线程安全问题时,增加或删除元素较多用LinkedList。
Map接口:
Map用来存储“键(key)-值(value) 对”。 Map类中存储的“键值对”通过键来标识,所以“键对象”不能重复。如果发生重复,新的键值对会替换旧的键值对。
Map接口常见方法:
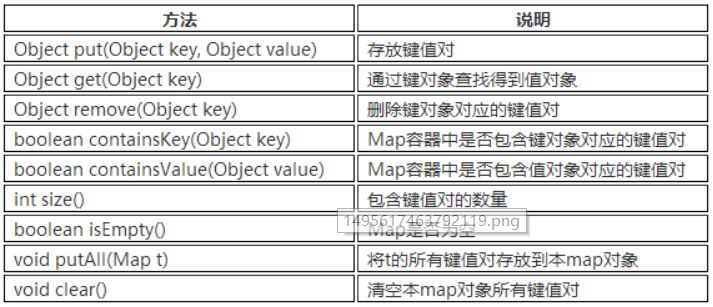
HashMap:
HashMap结构上使用了“哈希表”。哈希表的本质就是“数组+链表”。结合了数组(查询快)和链表(增删效率高)的优点。
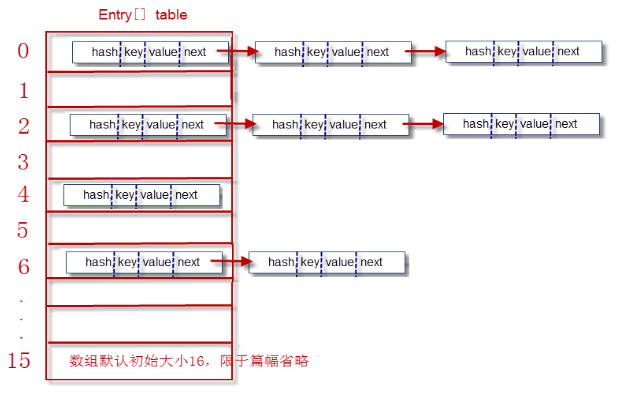
Entry[ ] table 是HashMap的核心数组结构,我们也称之为“位桶数组”。
简单地来说,Entry[ ] table 数组(默认长度为16)的每一个元素都是一个单项链表。而每一个单项链表中可存储0到多个节点,每一个节点都是一个Entry对象。
一个Entry对象包括3部分内容:
1. key:键对象 value:值对象
2. next:下一个节点
3. hash: 键对象的hash值(与hashcode不同)
存储数据过程 put(key,value):
1.计算得到当前对象的Hashcode。
2.用一定的计算方法得到hash值,决定该对象放到数组的哪一层(0~15),同一个链表上的Hash值相同。
(1)极端方法1:全部放在0层中,则哈希表退化为一个单向链表
(2)极端方法2:一层只放一个对象,对象数等于数组长度,则哈希表退化为一个普通数组
(3)常用方法:除以16取余,均匀分布(但是除法效率较低)
(4)常用方法之改进版:约定数组长度必须为2的整数幂,这样采用位运算即可实现取余的效果:hash值 = hashcode&(数组长度-1)。
(5)再次改进版:当链表长度大于8时,每一层的链表就转换为红黑树,这样又大大提高了查找的效率。
取数据过程get(key):
1.计算得到当前对象的Hashcode。
2.用一定的计算方法得到hash值,找到该对象放到数组的层数(0~15)。
3. 在链表上挨个比较key对象。 调用equals()方法,将key对象和链表上所有节点的key对象进行比较,直到碰到返回true的节点对象为止。
4.返回equals()为true的节点对象的value对象。
两个内容相同(equals()为true)的对象的hashCode必然是相等的。
扩容问题:
HashMap的位桶数组,初始大小为16。实际使用时,显然大小是可变的。如果位桶数组中的元素达到(0.75*数组 length), 就重新调整数组大小变为原来2倍大小。
扩容很耗时。扩容的本质是定义新的更大的数组,并将旧数组内容挨个拷贝到新数组中。
TreeMap:
TreeMap在HashMap的基础上利用红黑树增加了自动排序的功能。HashMap效率高于TreeMap,在需要排序的Map时才选用TreeMap。
排序规则:根据key值从小到大排序。
自定义排序:自定义类,实现Comparable接口,重写compareTo(类名 o)方法。通过返回-1(当前对象小于指定对象),0当前对象等于指定对象),1(当前对象大于指定对象)来自定义排序规则。
HashTable:
HashTable类和HashMap用法几乎一样,底层实现几乎一样,只不过HashTable的方法添加了synchronized关键字确保线程同步检查,效率较低,且不允许key或value为null。
Set接口:
Set接口继承自Collection,方法和Collection保持完全一致。
Set容器特点:无序、不可重复。无序指Set中的元素没有索引,我们只能遍历查找;不可重复指不允许加入重复的元素。更确切地讲,新元素如果和Set中某个元素通过equals()方法对比为true,则不能加入;甚至,Set中也只能放入一个null元素,不能多个。
HashSet:
HashSet本质上是HashMap的简化版。HashSet中的所有内容均为key,因此不可重复。
TreeSet:
TreeSet本质上是TreeeMap的简化版,也可用来排序。TreeSet中通过TreeeMap的key来存储Set的元素,因此不可重复。且不可放入null元素。
类似地,对应的类需要实现Comparable接口。这样,才能根据compareTo()方法比较对象之间的大小,才能进行内部排序。
Iterator迭代器:
Collection(List&Set):
for(Iterator<数据类型>迭代器对象变量名称=容器对象名称.iterator();迭代器对象变量名称.hasNext();) {
String 打印元素变量名 = 迭代器对象变量名称.next();
System.out.println(打印元素变量名);
Map方法1:
Set<Entry<key数据类型,value数据类型>>位桶数组名称=容器对象名称.entrySet();
for(Iterator<Entry<Integer,Object>>迭代器对象变量名称=位桶数组名称.iterator();迭代器对象变量名称.hasNext();) {
Entry<Integer,Object> 数组变量名 = 迭代器对象变量名称.next();
System.out.println(数组变量名.getKey()+"--"+数组变量名.getValue());
}
Map方法2:
Set<key数据类型>位桶数组名称=容器对象名称.keySet();
for(Iterator<key数据类型>迭代器对象变量名称=位桶数组名称.iterator();迭代器对象变量名称.hasNext();) {
key数据类型 key变量名 = 迭代器对象变量名称.next();
System.out.println(key变量名+"--"+容器对象名称.get(key变量名));
}
Collections工具类:
提供了对Set、List、Map进行排序、填充、查找元素的辅助方法。
1. void sort(List) 对List容器内的元素排序,排序的规则是按照升序进行排序。
2. void shuffle(List) 对List容器内的元素进行随机排列。
3. void reverse(List) 对List容器内的元素进行逆序排列 。
4. void fill(List, Object) 用一个特定的对象重写整个List容器。
5. int binarySearch(List, Object) 对于顺序的List容器,采用折半查找的方法查找特定对象。
表格数据存储:
1.每组信息用HashMap存放,总体用ArrayList存放
步骤:(1)创建n个HashMap对象
(2)创建1个ArrayList对象,把第1步中的n个map对象放入其中
(3)遍历打印:
for(Map<key数据类型,value数据类型> 遍历单位变量名称:List对象名称) { //需要遍历的单位是map,总体是ArrayList对象table
Set<String> 存放key的set名称 = 遍历单位变量名称.keySet(); //获取所有的key值,存放于容易set中,名字为keyset
for(String key:存放key的set名称) { //遍历keyset,打印每个key值
System.out.print(key+":"+遍历单位变量名称.get(key)+"\t"); //打印map对象中的key值
}
System.out.println(); //打完一个完整的HashMap,换行
}
2.每组信息用Javabean存放,总体用List/Map存放
步骤:(1)创建1个Javabean(必须拥有getters与setters,以及一个无参的构造方法,一个有参的构造方法)
(2)创建n个Javabean对象,写入相关内容
(3)创建一个list/map对象,把n个javabean对象放入
(4)遍历打印list/map中的元素

