Mysql 删除重复数据 只保留一条数据
自己建个如下表
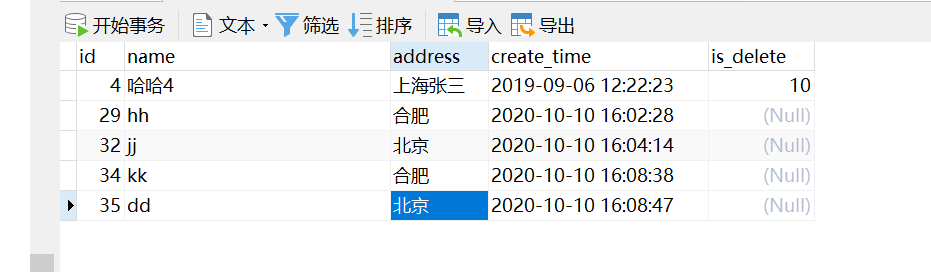
直接上sql 亲自测试 真实有效
----针对单个字段重复数据
delete FROM test a WHERE a.address in ( select s.address from ( SELECT t.address
FROM test t
GROUP BY t.address
HAVING COUNT( * ) >1) s )
and a.id not in (select u.id from (select min(d.id) as id from test d group by d.address having count(* )>1) u )
------针对多个字段重复数据
delete FROM test a WHERE (a.address,a.name) in ( select s.address,s.name from ( SELECT t.address,t.name
FROM test t
GROUP BY t.address,t.name
HAVING COUNT( * ) >1) s )
and a.id not in (select u.id from (select min(d.id) as id from test d group by d.address,d.name having count(* )>1) u )
那么orcal数据库怎么做呢 可以利用orcal的伪列 rowid 来处理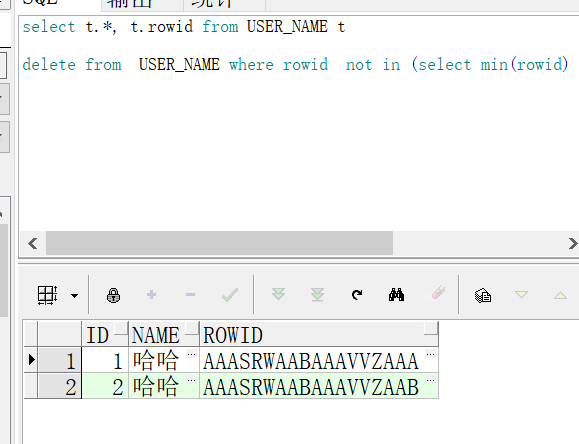
delete from USER_NAME where rowid not in (select min(rowid) from USER_NAME group by name)
快乐的吃干货

 浙公网安备 33010602011771号
浙公网安备 33010602011771号