
2022面向对象程序设计(福州大学)寒假作业3
| 这个作业属于哪个课程 | 2022面向对象程序设计 (福州大学) |
|---|---|
| 这个作业要求在哪里 | 2022面向对象程序设计(福州大学)寒假作业3 |
| 这个作业的目标 | 进一步优化寒假作业2的数据包分类算法,提高数据包分类的速度、减小时间和空间上的开销。 |
| 作业正文 | Github仓库请点击这里 其余内容请见下文 |
| 其他参考文献 | 基于非均匀切割的HiCuts分类算法 C++中头文件(.h)和源文件(.cpp)都应该写些什么 cpp文件写c语言,C++中头文件(.h)和源文件(.cpp)都应该写些什么 |
Github仓库请点击这里 C++的程序完整源代码均已上传到GitHub仓库
1.主要学习过程
先尝试阅读HiCuts算法的那篇论文,艰难地读了几遍后对于这个算法还是一知半解,无奈之下只好自己再百度了一些HiCuts算法的相关资料(已附在开头的表格)。这种算法的本质是对规则集文件进行处理,采用均匀或非均匀切割的方法将规则集分成决策树的若干层和若干分支(这样之后检索规则集的时候可以根据不同范围缩小历遍的范围,提高检索匹配速度),然后根据输入的数据包每条数据的信息在其所在范围的那部分规则里面检索最佳匹配的规则,以完成匹配任务。
2.优化代码过程
2.1 算法优化
由于我对于HiCuts算法的应用还非常不熟悉,就只先采用简单枚举的方法对规则集的目的端口按照非均匀切割的方式构建了1层31分支的简单决策树,编译完成脱离编译器直接运行exe文件的运行时间能够比优化前相同条件下缩短8.3%左右,这是非常笨的一种构建简单决策树的方式,空间上大约多了70行的代码,核心部分代码如下:
void rule::process_chain_table(rule* p)//访问并处理规则集链表数据
{
while (p->next)
{
for (int i = 0; i < 37; i++)//初始化链表字符数组
p->ip0bin[i] = p->ip1bin[i] = '\0';
IP_Switch_From_Dotted_DEC_To_BIN(p->ip01, p->ip02, p->ip03, p->ip04, p->ip0bin);//将源IP地址转换为二进制形式储存到链表相应的字符数组中
IP_Switch_From_Dotted_DEC_To_BIN(p->ip11, p->ip12, p->ip13, p->ip14, p->ip1bin);//将目的IP地址转换为二进制形式储存到链表相应的字符数组中
IP_Switch_From_CIDR_To_DEC_IP_address_block_Max_and_Min(p->ip0bin, p->ip0wei, &p->ip0max, &p->ip0min);//将源IP地址的CIDR地址块的最大IP地址和最小IP地址分别用十进制表示方式存储在链表的相应变量中
IP_Switch_From_CIDR_To_DEC_IP_address_block_Max_and_Min(p->ip1bin, p->ip1wei, &p->ip1max, &p->ip1min);//将目的IP地址的CIDR地址块的最大IP地址和最小IP地址分别用十进制表示方式存储在链表的相应变量中
Protocol_number_Switch_From_HEX_To_DEC(&p->x0, &p->x1, p->z0, p->z1);//将协议号上下范围分别转换为十进制表示方式存储到链表相应变量中
process_rule_class(&p, p->ip0min, p->ip0max, p->ip1min, p->ip1max, p->d01, p->d02, p->d11, p->d12, p->x0, p->x1);
p = p->next;
}
}
void rule::process_rule_class(class rule** p, unsigned int ip0min, unsigned int ip0max, unsigned int ip1min, unsigned int ip1max, int d01, int d02, int d11, int d12, int x0, int x1)
{
int oz;
if (d11 >= 0 && d11 <= 500 && d12 >= 0 && d12 <= 500)oz = 0;
else if (d11 > 500 && d12 > 500 && d11 <= 1000 && d12 <= 1000)oz = 1;
else if (d11 > 1000 && d12 > 1000 && d11 <= 1500 && d12 <= 1500)oz = 2;
else if (d11 > 1500 && d12 > 1500 && d11 <= 2000 && d12 <= 2000)oz = 3;
else if (d11 > 2000 && d12 > 2000 && d11 <= 2500 && d12 <= 2500)oz = 4;
else if (d11 > 2500 && d12 > 2500 && d11 <= 3000 && d12 <= 3000)oz = 5;
else if (d11 > 3000 && d12 > 3000 && d11 <= 3500 && d12 <= 3500)oz = 6;
else if (d11 > 3500 && d12 > 3500 && d11 <= 4000 && d12 <= 4000)oz = 7;
else if (d11 > 4000 && d12 > 4000 && d11 <= 4500 && d12 <= 4500)oz = 8;
else if (d11 > 4500 && d12 > 4500 && d11 <= 5000 && d12 <= 5000)oz = 9;
else if (d11 > 5000 && d12 > 5000 && d11 <= 5500 && d12 <= 5500)oz = 10;
else if (d11 > 5500 && d12 > 5500 && d11 <= 6000 && d12 <= 6000)oz = 11;
else if (d11 > 6000 && d12 > 6000 && d11 <= 6500 && d12 <= 6500)oz = 12;
else if (d11 > 6500 && d12 > 6500 && d11 <= 7000 && d12 <= 7000)oz = 13;
else if (d11 > 7000 && d12 > 7000 && d11 <= 7500 && d12 <= 7500)oz = 14;
else if (d11 > 7500 && d12 > 7500 && d11 <= 8000 && d12 <= 8000)oz = 15;
else if (d11 > 8000 && d12 > 8000 && d11 <= 8500 && d12 <= 8500)oz = 16;
else if (d11 > 8500 && d12 > 8500 && d11 <= 9000 && d12 <= 9000)oz = 17;
else if (d11 > 9000 && d12 > 9000 && d11 <= 9500 && d12 <= 9500)oz = 18;
else if (d11 > 9500 && d12 > 9500 && d11 <= 10000 && d12 <= 10000)oz = 19;
else if (d11 > 10000 && d12 > 10000 && d11 <= 15000 && d12 <= 15000)oz = 20;
else if (d11 > 15000 && d12 > 15000 && d11 <= 20000 && d12 <= 20000)oz = 21;
else if (d11 > 20000 && d12 > 20000 && d11 <= 25000 && d12 <= 25000)oz = 22;
else if (d11 > 25000 && d12 > 25000 && d11 <= 30000 && d12 <= 30000)oz = 23;
else if (d11 > 30000 && d12 > 30000 && d11 <= 35000 && d12 <= 35000)oz = 24;
else if (d11 > 35000 && d12 > 35000 && d11 <= 40000 && d12 <= 40000)oz = 25;
else if (d11 > 40000 && d12 > 40000 && d11 <= 45000 && d12 <= 45000)oz = 26;
else if (d11 > 45000 && d12 > 45000 && d11 <= 50000 && d12 <= 50000)oz = 27;
else if (d11 > 50000 && d12 > 50000 && d11 <= 55000 && d12 <= 55000)oz = 28;
else if (d11 > 55000 && d12 > 55000 && d11 <= 60000 && d12 <= 60000)oz = 29;
else if (d11 > 60000 && d12 > 60000 && d11 <= 65000 && d12 <= 65000)oz = 30;
else oz = 100;
(*p)->next_arr[oz] = NULL;
pr[oz]->next_arr[oz] = *p;
pr[oz] = *p;
}
void rule::visit_processed_chain_table(rule* p, ifstream& fp_packet, ofstream& fp_out)
{
unsigned int ip0, ip1, d0, d1, y, flag, oz;
while (fp_packet >> ip0 >> ip1 >> d0 >> d1 >> y)
{
if (d1 >= 0 && d1 <= 500)oz = 0;
else if (d1 <= 1000)oz = 1;
else if (d1 <= 1500)oz = 2;
else if (d1 <= 2000)oz = 3;
else if (d1 <= 2500)oz = 4;
else if (d1 <= 3000)oz = 5;
else if (d1 <= 3500)oz = 6;
else if (d1 <= 4000)oz = 7;
else if (d1 <= 4500)oz = 8;
else if (d1 <= 5000)oz = 9;
else if (d1 <= 5500)oz = 10;
else if (d1 <= 6000)oz = 11;
else if (d1 <= 6500)oz = 12;
else if (d1 <= 7000)oz = 13;
else if (d1 <= 7500)oz = 14;
else if (d1 <= 8000)oz = 15;
else if (d1 <= 8500)oz = 16;
else if (d1 <= 9000)oz = 17;
else if (d1 <= 9500)oz = 18;
else if (d1 <= 10000)oz = 19;
else if (d1 <= 15000)oz = 20;
else if (d1 <= 20000)oz = 21;
else if (d1 <= 25000)oz = 22;
else if (d1 <= 30000)oz = 23;
else if (d1 <= 35000)oz = 24;
else if (d1 <= 40000)oz = 25;
else if (d1 <= 45000)oz = 26;
else if (d1 <= 50000)oz = 27;
else if (d1 <= 55000)oz = 28;
else if (d1 <= 60000)oz = 29;
else if (d1 <= 65000)oz = 30;
else oz = 100;
for (p = head, flag = 0; p; p = p->next_arr[oz])
{
if (rule_match(ip0, ip1, d0, d1, y, p->ip0min, p->ip0max, p->ip1min, p->ip1max, p->d01, p->d02, p->d11, p->d12, p->x0, p->x1))
{
fp_out << p->num << endl;
flag = 1;
break;
}
}
if (!flag && oz != 100)
{
for (p = head, flag = 0; p; p = p->next_arr[100])
{
if (rule_match(ip0, ip1, d0, d1, y, p->ip0min, p->ip0max, p->ip1min, p->ip1max, p->d01, p->d02, p->d11, p->d12, p->x0, p->x1))
{
fp_out << p->num << endl;
flag = 1;
break;
}
}
}
if (!flag)fp_out << "-1\n";
}
}
int rule_match(unsigned int ip0, unsigned int ip1, int d0, int d1, int x, unsigned int ip0min, unsigned int ip0max, unsigned int ip1min, unsigned int ip1max, int d01, int d02, int d11, int d12, int x0, int x1)
{
/*最后的匹配过程,将五元组各个要素逐一检验,全部符合返回1,否则返回0*/
int c = 0;
if (ip0 >= ip0min && ip0 <= ip0max)c++;
else return 0;
if (ip1 >= ip1min && ip1 <= ip1max)c++;
else return 0;
if (d0 >= d01 && d0 <= d02)c++;
else return 0;
if (d1 >= d11 && d1 <= d12)c++;
else return 0;
if (x == x0 || x1 == 0)c++;
else return 0;
if (c == 5)return 1;
else return 0;
}
由于空间上增加了大量代码,运行时间的缩短也不是很多,因此从空间上和时间上综合来看,算法优化的效果不是很好,还有很大改进空间。
2.2 代码模块化的优化
在第二次寒假作业中,我没有将规则集的类相关内容很好地模块化成各个文件,本次作业中对于这个问题也进行了优化。将规则集类的链表相关内容单独存储到头文件Rule_class.h中,并在头尾添加预处理代码(预处理后运行时间可再缩短2.6%左右)然后将相关类成员函数具体内容另外存储在一个cpp文件中,最终代码总体时间优化率在10%左右


3.调试程序过程
在确认程序输出运行结果与所给参考答案一致后,通过脱离编译器直接在本地运行exe文件,每次固定输入寒假作业3中dataset1的rule.txt和packet1.txt进行匹配来比较优化前后的时间
3.1 优化前(寒假作业2的程序):
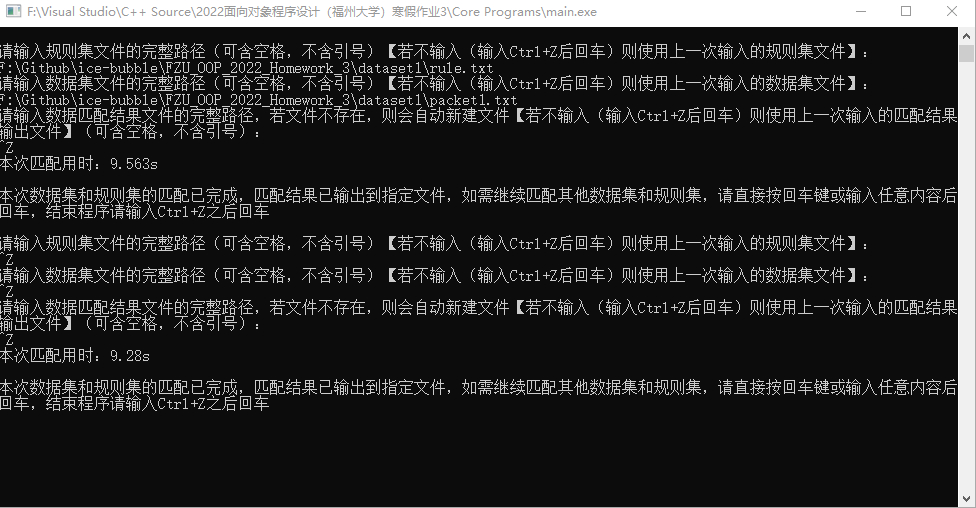
3.2 算法优化后:

3.3 规则集类独立成头文件并在头尾添加预处理代码后:

4.程序匹配所给的6给数据包以及和参考答案比较的过程(自制简易文件比较程序已在之前上传到寒假作业2的仓库)
dataset1的3个packet:
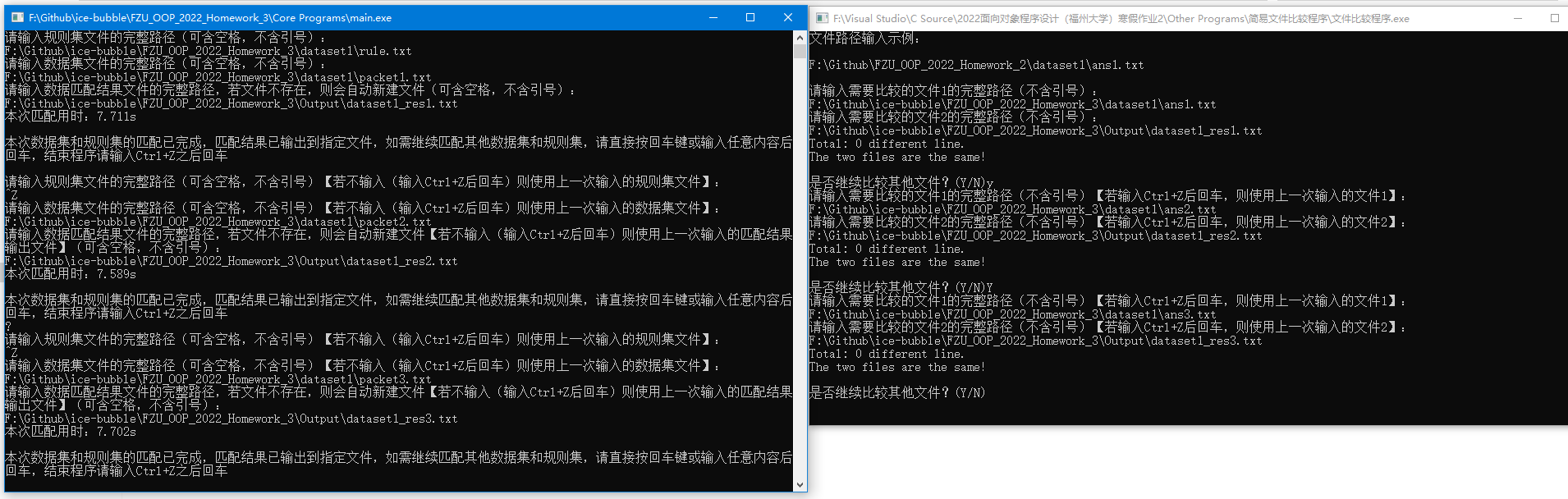
dataset2的3个packet:

总结
本次寒假作业的代码优化效果不是很理想,思考了进一步优化的方式:
1.继续对规则集的源端口、目的IP地址和源IP地址进行合理的非均匀切割,以构建更节约时间的决策树。
2.将文件流输入输出改为C风格的fscanf、fprintf、fgets、fputs等函数以缩短运行时间。
Github仓库链接已贴在本文开头。

