【专题】字符串问题
📃 KMP模式匹配
基本用途:判断长度为N的字符串A是否是长度为M字符串B的子串,并求得每次出现的位置
时间复杂度:O(N+M)
先上模板题
P3375 【模板】KMP字符串匹配
https://www.luogu.com.cn/problem/P3375
#include <bits/stdc++.h> using namespace std; const int N=1e6+5; int nxt[N]; int n,m; char s1[N],s2[N]; //kmp //统计s2在s1中出现的首字母位置 int main() { scanf("%s",s1+1); scanf("%s",s2+1); n=strlen(s1+1); //记得要+1e6 m=strlen(s2+1); //求s2的前缀数组 for(int i=2,j=0;i<=m;i++) { while(j&&s2[i]!=s2[j+1]) j=nxt[j]; if(s2[i]==s2[j+1]) j++; nxt[i]=j; } //匹配 for(int i=1,j=0;i<=n;i++) { while(j&&s1[i]!=s2[j+1]) j=nxt[j]; if(s1[i]==s2[j+1]) j++; if(j==m)//s2被匹配完 { printf("%d\n",i-m+1); j=nxt[j]; } } for(int i=1;i<=m;i++) { printf("%d ",nxt[i]); } return 0; }
核心思想就是先求子字符串s2的前缀数组,然后再进行匹配,匹配的过程中可以用前缀数组进行优化,就不用每次匹配错误时再从头找起。很妙的一点是因为定义是差不多的,所以求前缀数组的流程和匹配是类似的。
重要定义
next[i]: 表示A中以i结尾的非前缀子串(子串的后缀)与A的前缀能匹配的最长长度
我理解的意思是,下一次从next[i]这里开始匹配
f[i]: 表示B中以i结尾的子串与A的前缀能够匹配的最长长度
CF1200E Compress Words
https://www.luogu.com.cn/problem/CF1200E
#include <bits/stdc++.h> using namespace std; const int N=1e6+5; int nxt[N]; int n; string s,ans; void kmp(string s) { int l=s.length(); s=" "+s; //加空格是为了从1开始,而不是从0开始 nxt[0]=nxt[1]=0; //初始化nxt数组 //求s的前缀数组 for(int i=2,j=0;i<=l;i++) { while(j&&s[i]!=s[j+1]) j=nxt[j]; if(s[i]==s[j+1]) j++; nxt[i]=j; } } int main() { scanf("%d",&n); cin>>ans;//ans作为答案串 for(int i=1;i<n;i++) { cin>>s; int l=min(s.length(),ans.length()); //这里是一个优化,匹配的只可能是两段字符串中短的那个 string tmp=s+"~~~~~accepted"+ans.substr(ans.size()-l,l);//注意这里要加奇怪一点,只有accepted是不行的 kmp(tmp); //ans也只需要拼接原来ans后面l长度的部分就可以了 //将新的s拼接在已有的答案串前,这样就实现了后面字符串和前面字符串的匹配 //但这里有一个bug,就是将两个拼接起来后,可能最长前缀跨越了两个字符串,所以需要在中间再加一个字符串 //求一遍kmp后能获得nxt[ans.length()-1],即ans后缀能匹配的最长s前缀 //那就从这个位置开始往后,一直到s的长度,就是不匹配的部分,需要加上去 for(int j=nxt[tmp.length()];j<s.length();j++) { ans+=s[j]; } } cout<<ans; //输出最终的答案串 return 0; }
细节题,需要在两个字符拼接的中间加上一个奇奇怪怪的字符串(只有accepted甚至会wa4,只能说和出题人想到一块去了)+ 基于KMP的优化
P4824 [USACO15FEB] Censoring S
https://www.luogu.com.cn/problem/P4824
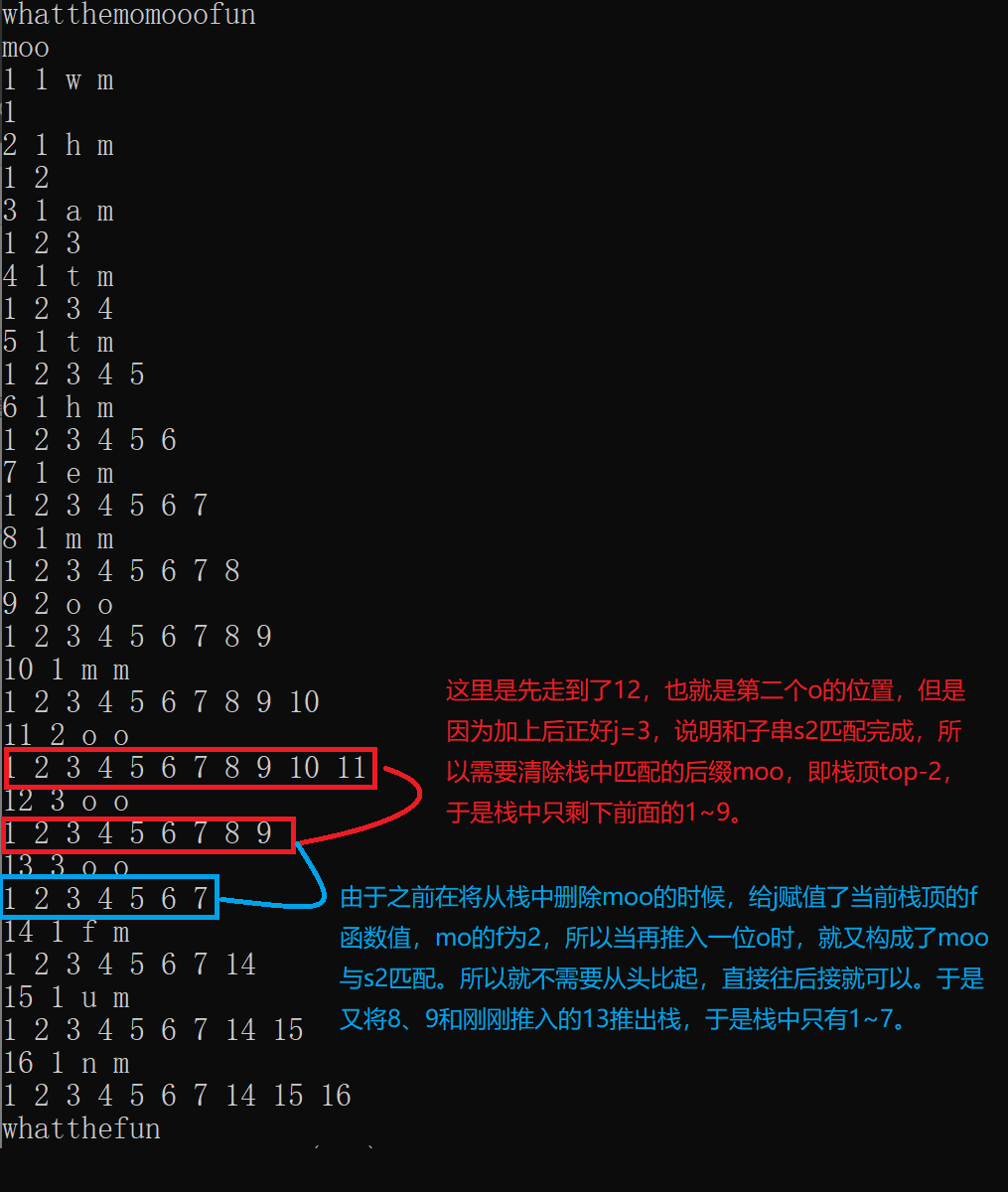
#include <bits/stdc++.h> using namespace std; const int N=1e6+5; int nxt[N],f[N]; char s1[N],s2[N]; int l1,l2; int st[N];//数组模拟栈 int top=0;//栈顶 int main() { scanf("%s",s1+1); scanf("%s",s2+1); l1=strlen(s1+1); l2=strlen(s2+1); //先s2自我匹配 for(int i=2,j=0;i<=l2;i++) { while(j&&s2[i]!=s2[j+1]) j=nxt[j]; if(s2[i]==s2[j+1]) j++; nxt[i]=j; } //s1与s2匹配 for(int i=1,j=0;i<=l1;i++) { while(j&&s1[i]!=s2[j+1]) j=nxt[j]; //cout<<i<<" "<<j+1<<" "<<s1[i]<<" "<<s2[j+1]<<endl; if(s1[i]==s2[j+1]) j++; f[i]=j; st[++top]=i;//入栈 if(j==l2) { top-=l2; j=f[st[top]]; } /* for(int k=1;k<=top;k++) { cout<<st[k]<<" "; } cout<<endl; */ } for(int i=1;i<=top;i++) { printf("%c",s1[st[i]]); } return 0; }
如果把注释掉的两段输出取消,会得到以下结果
🌲 Trie树
基本用途:高效的存储和查询字符串
时间复杂度:所有字符串长度之和为n,构建字典树的时间复杂度为O(n)。要查找的字符串长度为k,查找的时间复杂度为O(k)。
int trie[N][26]; //trie[i][j]表示的是第i个节点,第j个字母的下一个节点号 int tot=1; //记录当前编到的节点号 bool ed[N]; //ed[i]表示以i节点为结尾的 //Trie树有两种基本操作: //插入 void _insert(char *str) { int len=strlen(str),p=1; for(int i=0;i<len;i++) { int ch=str[i]-'a'; if(trie[p][ch]==0) trie[p][ch]=++tot; p=trie[p][ch]; //这里是先找有没有,如果没有就往后指 } ed[p]=true; } //查询 bool _search(char *str) { int len=strlen(str),p=1; for(int i=0;i<len;i++) { int ch=str[i]-'a'; p=trie[p][ch]; //注意这里和上一段有顺序的区别,先往后指,再判断有没有 if(p==0) return false; //如果这个字符就不存在 } return ed[p]; //看这个节点是不是结束 }
Acwing 835. Trie字符串统计
https://www.acwing.com/problem/content/837/
#include <bits/stdc++.h> using namespace std; const int N=2e4+5; int son[N][26],cnt[N],idx; //son[i][j]=x:第i个节点下连了字母为j的x节点 //cnt:和传统的ed[]记录是否可作为字符串结尾不同,这里的给节点计数 void insert(string s) { int t=0;//当前节点 for(int i=0;s[i];i++) { int x=s[i]-'a'; if(!son[t][x]) son[t][x]=++idx; //t节点下面没有字母为x的节点,添加新节点 t=son[t][x]; } cnt[t]++; } int query(string s) { int t=0;//当前节点 for(int i=0;s[i];i++) { int x=s[i]-'a'; if(!son[t][x]) return 0; //t节点下面没有字母为x的节点,返回 t=son[t][x]; } return cnt[t]; } int main() { int n; cin>>n; while(n--) { char dem; string s; cin>>dem>>s; if(dem=='I') insert(s); else cout<<query(s)<<endl; } return 0; }
P2580 于是他错误的点名开始了
#include <bits/stdc++.h> using namespace std; const int N=3e5+5; //应该是1e4*26 map<string,bool> vis; int trie[N][26],tot=1; int n,m; bool ed[N]; //插入 void _insert(string str) //这里用指针代替了字符数组 { int len=str.length(),p=1; for(int i=0;i<len;i++) { int ch=str[i]-'a'; if(trie[p][ch]==0) trie[p][ch]=++tot; p=trie[p][ch]; } ed[p]=true; } //查询 bool _search(string str) { int len=str.length(),p=1; for(int i=0;i<len;i++) { int ch=str[i]-'a'; p=trie[p][ch]; //注意这里和上一段有顺序的区别,先往后指,再判断有没有 if(p==0) return false; } return ed[p]; } int main() { //构建trie树 scanf("%d",&n); for(int i=0;i<n;i++) { string tmp; cin>>tmp; _insert(tmp); } //查询 scanf("%d",&m); for(int i=0;i<m;i++) { string tmp; cin>>tmp; if(vis[tmp]) { cout<<"REPEAT"<<endl; } else { if(_search(tmp)) { cout<<"OK"<<endl; vis[tmp]=true; } else { cout<<"WRONG"<<endl; } } } return 0; }
💬 字符串Hash
基本用途:用数字表示字符串
时间复杂度:O(N)预处理字符串前缀Hash值,O(1)查询任意子串的Hash值
基本思想:取一固定值P(一般是131或13331),把字符串看出P进制数。取一固定值M,求出该P进制数对M的余数,作为该字符串的Hash值,这一步由直接使用unsigned long long类型存储这个Hash值代替,相当于自动取余。
重点在于几个计算公式:
#define ull unsigned long long const int base=131; //取131为固定值 ull h[N],p[N]; //h记录Hash值,p记录进制数 //返回l~r区间内的hash值 ull gethash(ull h[],int l,int r) { return h[r]-h[l-1]*p[r-l+1]; } h[i]=h[i-1]*base+(s[i]-'a'); //计算hash值 p[i]=p[i-1]*base; //求p数组
P2957 [USACO09OCT]Barn Echoes G
#include <bits/stdc++.h> #define ull unsigned long long using namespace std; const int N=105,base=131; char s1[N],s2[N]; int l1,l2; ull h1[N],h2[N],p[N]; //h1,h2记录Hash值 ull gethash(ull h[],int l,int r) //返回l~r区间内的hash值 { return h[r]-h[l-1]*p[r-l+1]; } int main() { scanf("%s",s1+1); scanf("%s",s2+1); l1=strlen(s1+1); l2=strlen(s2+1); p[0]=1; //求s1和s2前缀串的hash值,以及p数组 for(int i=1;i<=l1;i++) { h1[i]=h1[i-1]*base+(s1[i]-'a'); } for(int i=1;i<=l2;i++) { h2[i]=h2[i-1]*base+(s2[i]-'a'); } for(int i=1;i<=max(l1,l2);i++) { p[i]=p[i-1]*base; } //计算 int ans=0; for(int i=1;i<=min(l1,l2);i++) { //判断s1的前缀哈希和s2的后缀哈希是否相等 if(gethash(h1,1,i)==gethash(h2,l2-i+1,l2)) ans=max(i,ans); //判断s1的后缀哈希和s2的前缀哈希是否相等 if(gethash(h1,l1-i+1,l1)==gethash(h2,1,i)) ans=max(i,ans); } printf("%d",ans); return 0; }
💻Bye~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号