MySQL引起的CPU消耗过大,如何优化?
目录
谁在消耗cpu?祸首是谁?
- 用户
- IO等待
- 产生影响
- 减少等待
- 减少计算
- 升级cpu
谁在消耗CPU?
用户+系统+IO等待+软硬中断+空闲
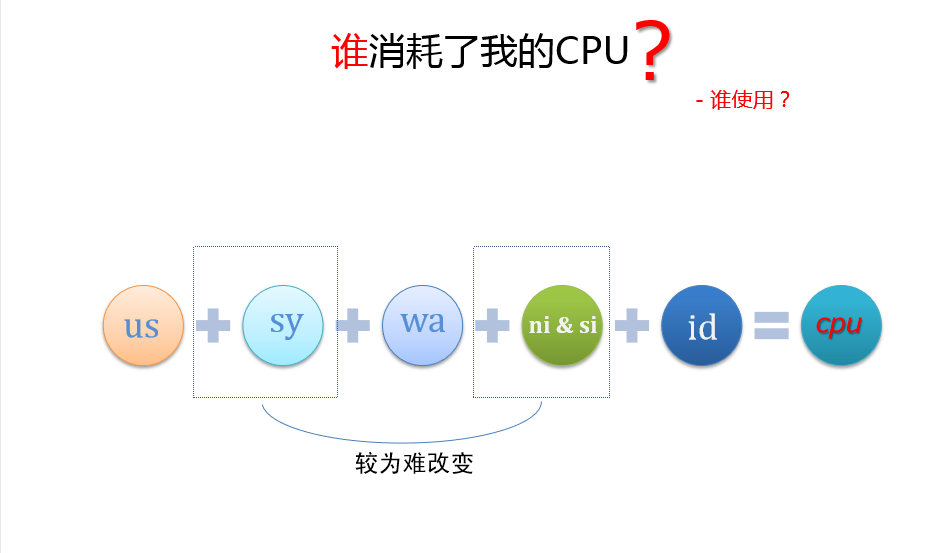
祸首是谁?
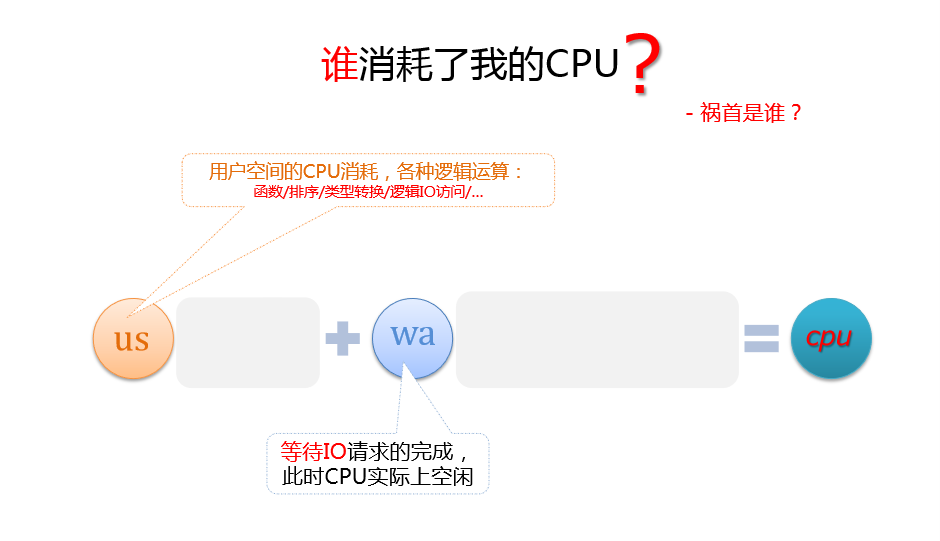
用户
用户空间CPU消耗,各种逻辑运算正在进行大量tps用户空间消耗大量cpu,产生的系统调用是什么?那些函数使用了cpu周期?
函数/排序/类型转化/逻辑IO访问…
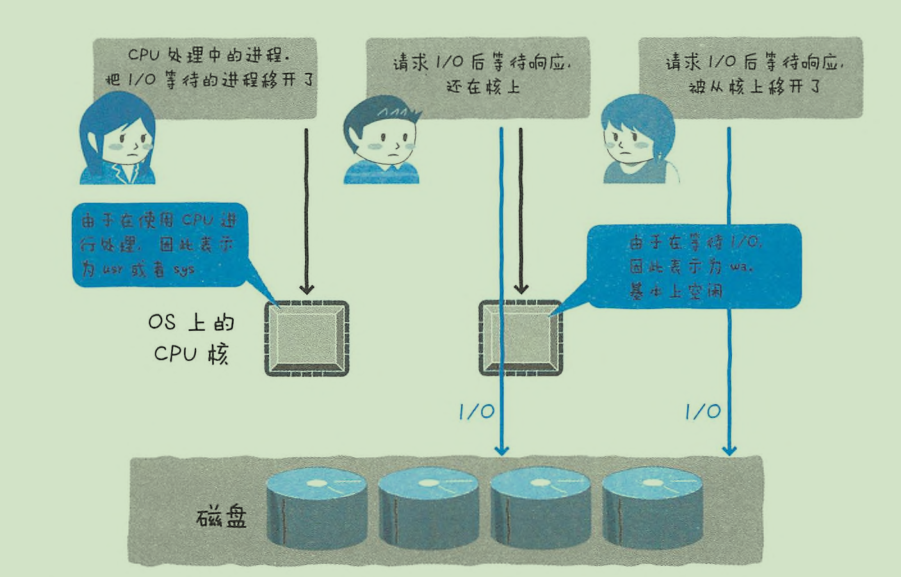
IO等待
等待IO请求的完成此时CPU实际上空闲
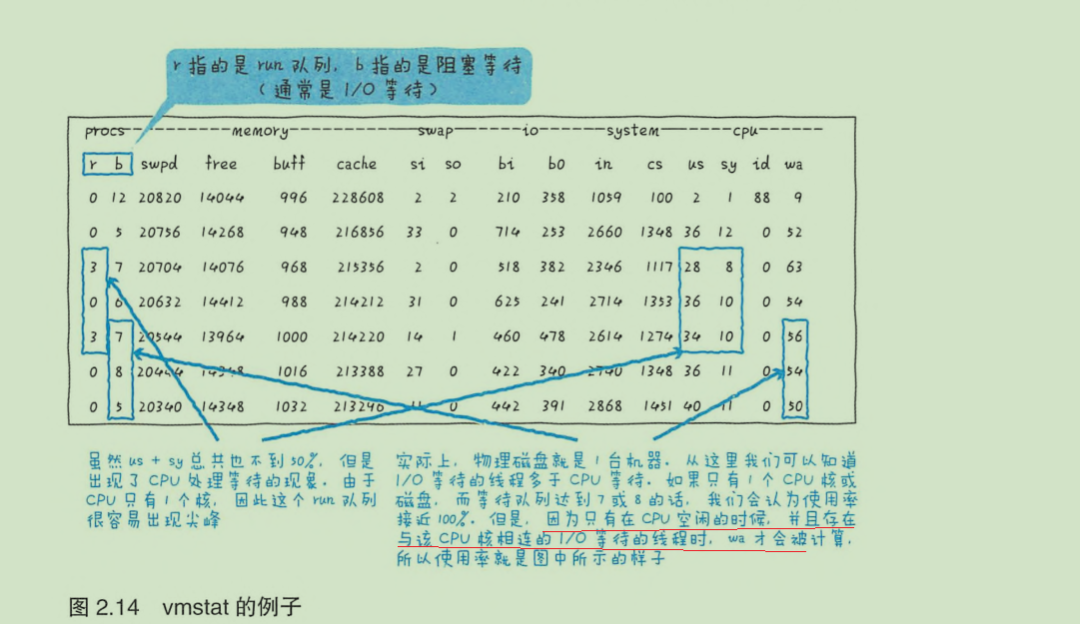
如vmstat中的wa 很高。但IO等待增加,wa也不一定会上升(请求I/O后等待响应,但进程从核上移开了)
产生影响
用户和IO等待消耗了大部分cpu- 吞吐量下降(tps)
- 查询响应时间增加
- 慢查询数增加
- 对mysql的并发陡增,也会产生上诉影响
如何减少CPU消耗?
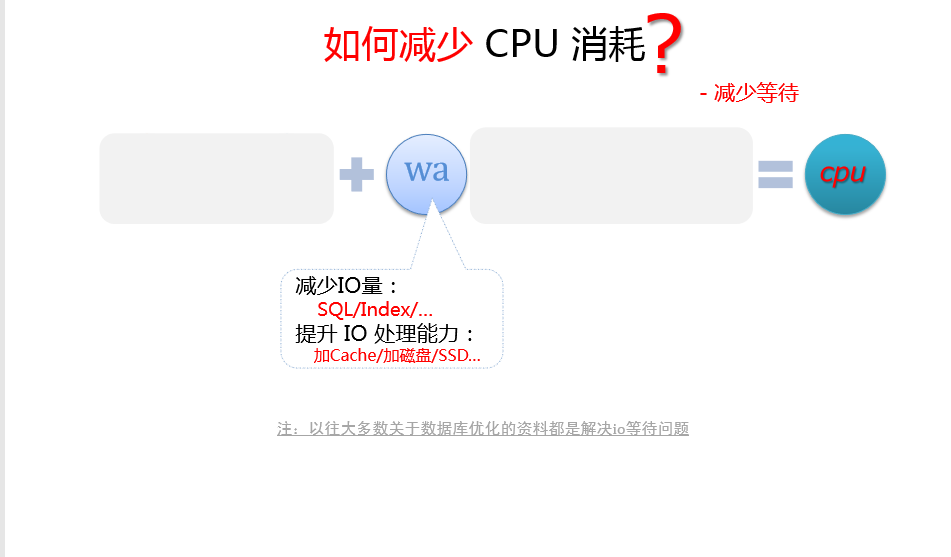
减少等待
减少IO量SQL/index,使用合适的索引减少扫描的行数(需平衡索引的正收益和维护开销,空间换时间)提升IO处理能力加cache/加磁盘/SSD
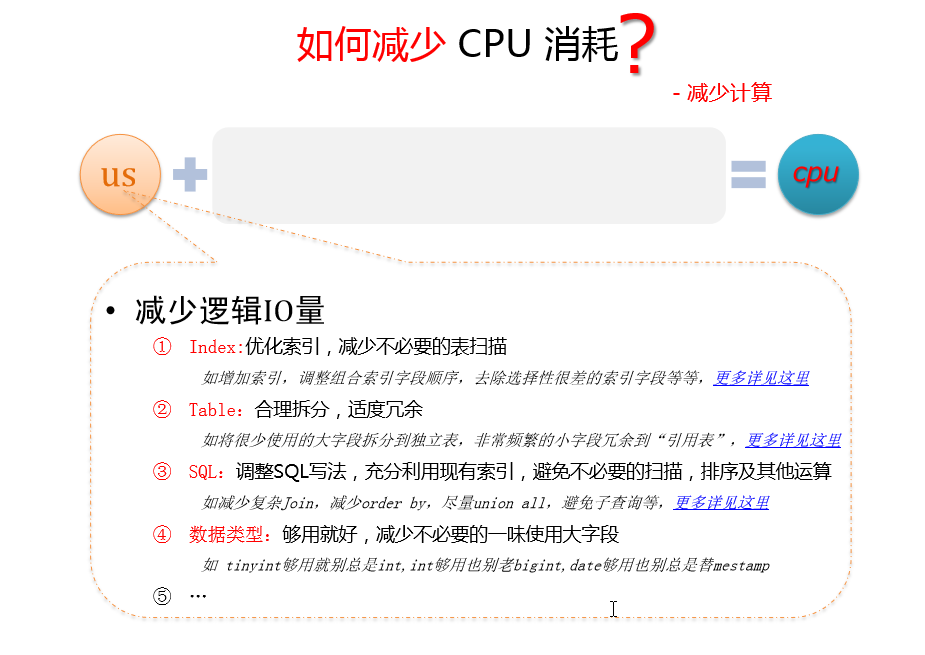
减少计算
减少逻辑运算量-
避免使用函数,将运算转移至易扩展的应用服务器中
如substr等字符运算,dateadd/datesub等日期运算,abs等数学函数 -
减少排序,利用索引取得有序数据或避免不必要排序
如union all代替 union,order by 索引字段等 -
禁止类型转换,使用合适类型并保证传入参数类型与数据库字段类型绝对一致
如数字用tiny/int/bigint等,必需转换的在传入数据库之前在应用中转好 -
简单类型,尽量避免复杂类型,降低由于复杂类型带来的附加运算。更小的数据类型占用更少的磁盘、内存、cpu缓存和cpu周期
-
….
- index,优化索引,减少不必要的表扫描
如增加索引,调整组合索引字段顺序,去除选择性很差的索引字段等等 - table,合理拆分,适度冗余
如将很少使用的大字段拆分到独立表,非常频繁的小字段冗余到“引用表” - SQL,调整SQL写法,充分利用现有索引,避免不必要的扫描,排序及其他操作
如减少复杂join,减少order by,尽量union all,避免子查询等 - 数据类型,够用就好,减少不必要使用大字段
如tinyint够用就别总是int,int够用也别老bigint,date够用也别总是timestamp - ….
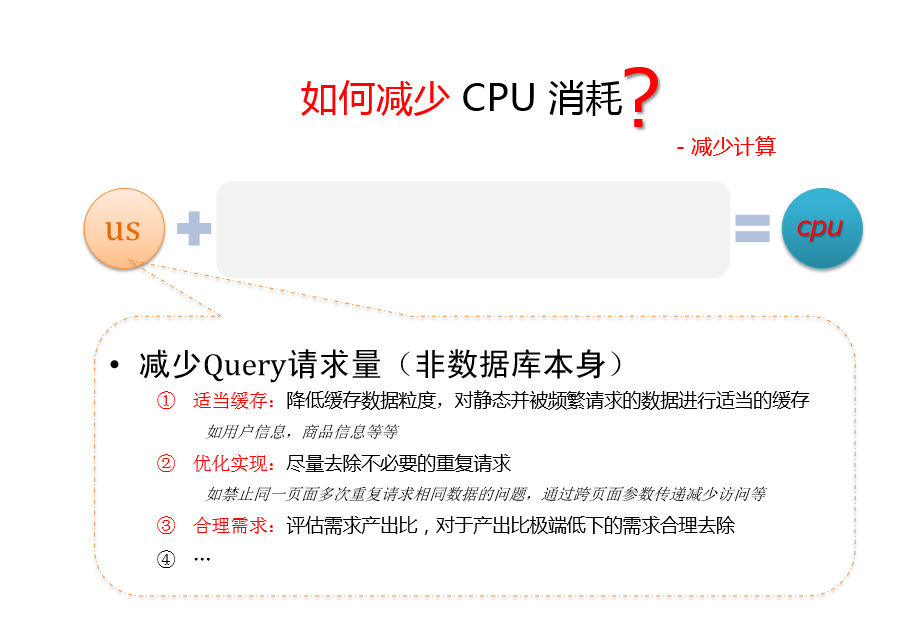
减少query请求量(非数据库本身)
- 适当缓存,降低缓存数据粒度,对静态并被频繁请求的数据进行适当的缓存
如用户信息,商品信息等 - 优化实现,尽量去除不必要的重复请求
如禁止同一页面多次重复请求相同数据的问题,通过跨页面参数传递减少访问等 - 合理需求,评估需求产出比,对产出比极端底下的需求合理去除
- ….
升级cpu
若经过减少计算和减少等待后还不能满足需求,cpu利用率还高T_T是时候拿出最后的杀手锏了,升级cpu,是选择更快的cpu还是更多的cpu了?- 低延迟(快速响应),需要更快的cpu(每个查询只能使用一个cpu)
- 高吞吐,同时运行很多查询语句,能从多个cpu处理查询中收益
参考
《高性能MySQL》
《图解性能优化》
《MySQL Tuning For CPU Bottleneck》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号