DataX的限速与调优
DataX的限速与调优
原文链接:
5、DataX(DataX简介、DataX架构原理、DataX部署、使用、同步MySQL数据到HDFS、同步HDFS数据到MySQL)-CSDN博客
前 言
众所周知,当一个程序需要传输数据的时候,它肯定会想尽办法占用掉设备的资源,但是,随着对DataX深入使用可以发现,DataX并不会全力吃掉资源,所以究竟DataX是如何做到限速的?传输缓慢到底是限速原因还是其他原因?本文来一起探讨下。
限 速
我们知道是在core.json文件里面的speed方法里面限速DataX的,可以通过record记录数和byte字节数来限速。
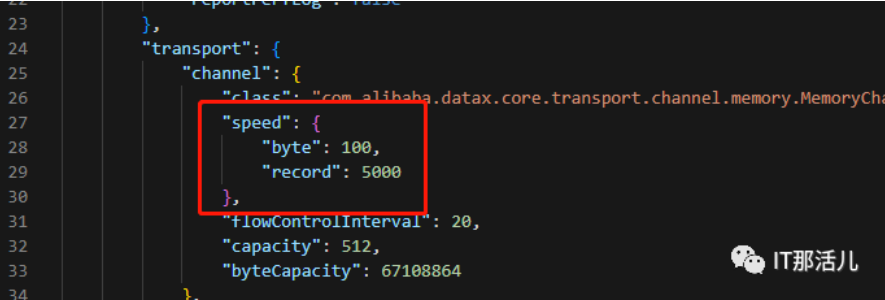
这个配置在CoreConstant类里面定义了:
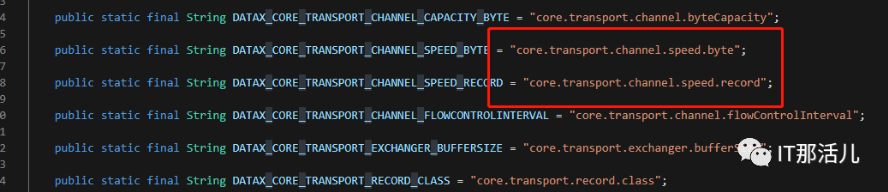
选中常量复制并查找,可以看到有两个地方调用了这个值:
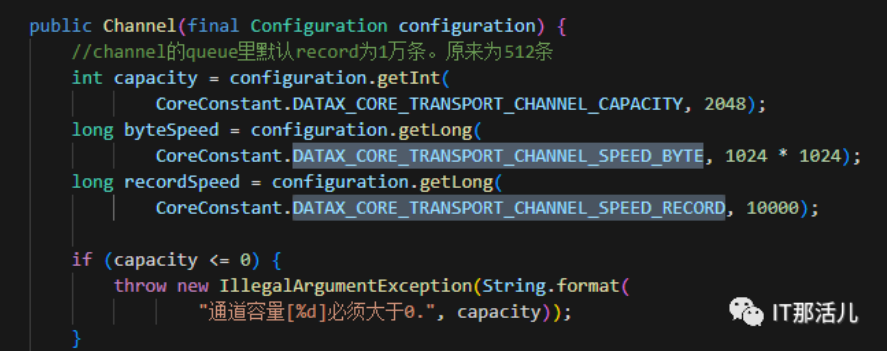
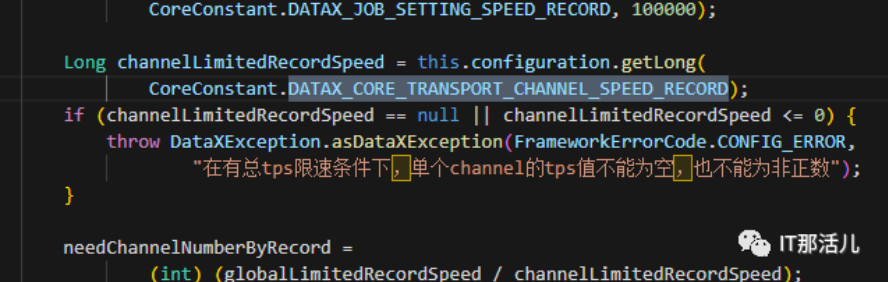
分别是初始化、求最大通道数的时候。
接下来,看看这两个配置在Channel类如何实现限速的。
Channel类里实现限速:
从下图,可以看到在Channel初始化时,顺带初始化了限速的记录数(recordSpeed)以及字节数(byteSpeed) ,接下来Control+F看看recordSpeed在哪里调用了。
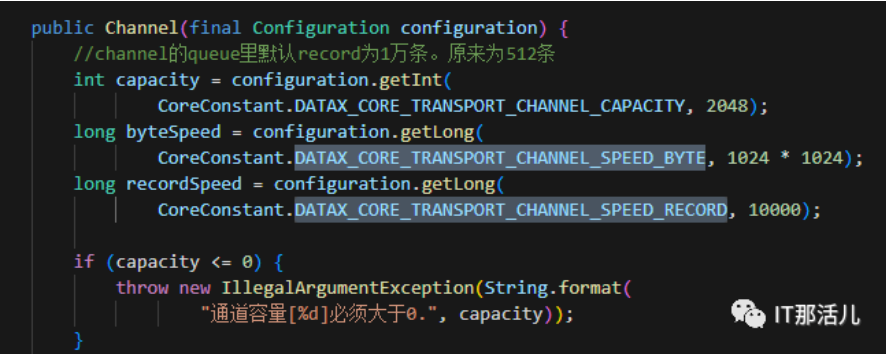
可以看到在statPush方法里面用到了:
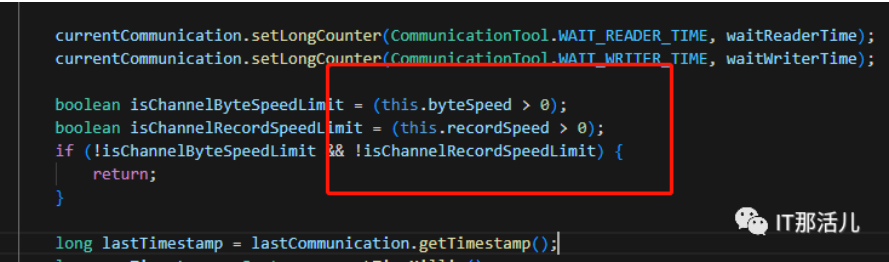
statPush整个流程的描述:
- 判断byteSpeed(bps)和recordSpeed(tps)是否都大于0?如果不是,则退出;
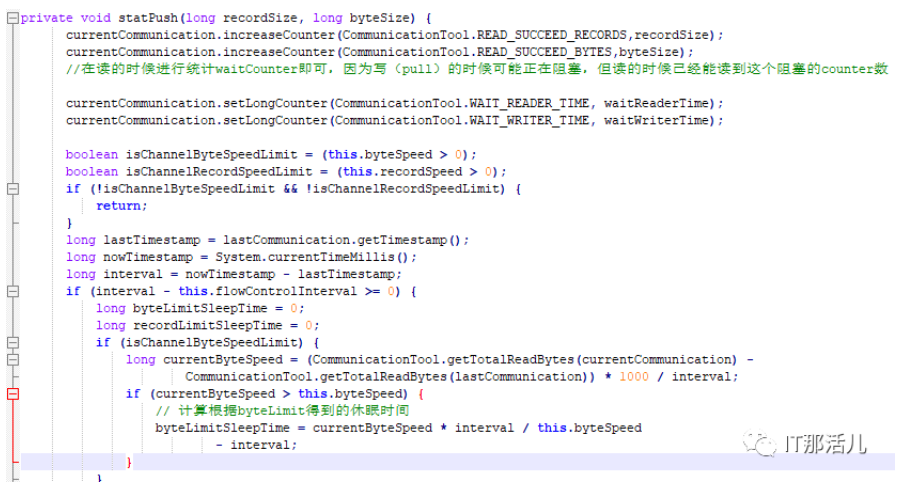
- 根据当前的byteSpeed和设定的byteSpeed对比,求出睡眠时间(公式:currentByteSpeed * interval this.byteSpeed- interval;)
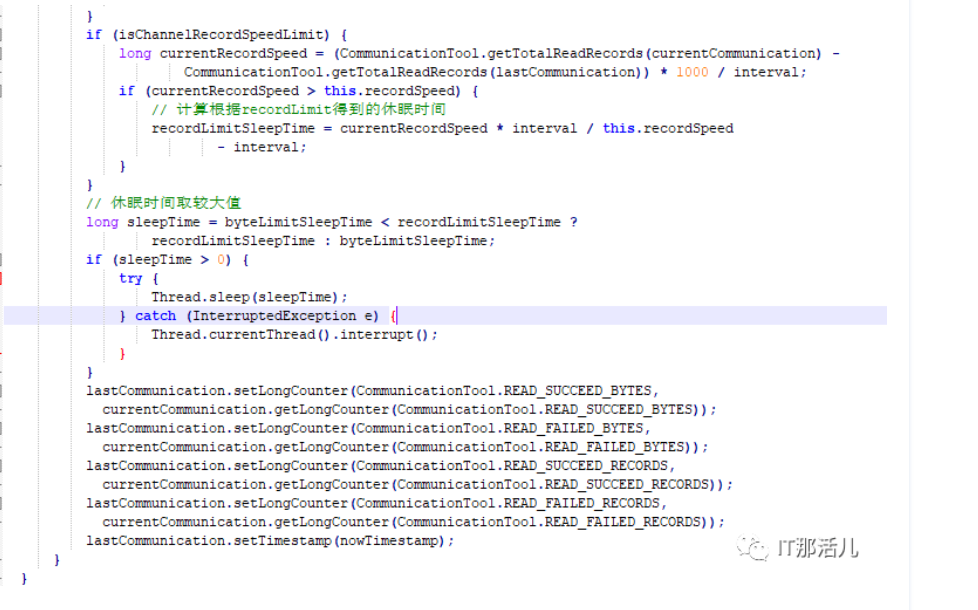
- 根据当前的recordSpeed和设定的recordSpeed对比,求出睡眠时间(公式:currentRecordSpeed * interval / this.recordSpeed - interval;)
- 取休眠时间最大值;
- Thread.sleep(sleepTime)来休眠;
- 实现限速。
下面贴上statPush的完整代码:
调 优
首先我们知道,传输受两个因素影响:
- 网络本身的带宽等硬件因素造成的影响;
- DataX本身的参数。
即当觉得DataX传输速度慢时,需要从上述两个个方面着手开始排查。
3.1 网络本身的带宽等硬件因素造成的影响
此部分主要需要了解网络本身的情况,即从源端到目的端的带宽是多少(实际带宽计算公式),平时使用量和繁忙程度的情况,从而分析是否是本部分造成的速度缓慢。以下提供几个思路:
- 可使用从源端到目的端scp,python http,nethogs等观察实际网络及网卡速度;
- 结合监控观察任务运行时间段时,网络整体的繁忙情况,来判断是否应将任务避开网络高峰运行;
- 观察任务机的负载情况,尤其是网络和磁盘IO,观察其是否成为瓶颈,影响了速度。
3.2 DataX本身的参数
1)全局
全局:提升每个channel的速度
在DataX内部对每个Channel会有严格的速度控制,分两种,一种是控制每秒同步的记录数,另外一种是每秒同步的字节数,默认的速度限制是1MB/s,可以根据具体硬件情况设置这个byte速度或者record速度,一般设置byte速度,比如:我们可以把单个Channel的速度上限配置为5MB,举例:

2)局部
局部::提升DataX Job内Channel并发数
并发数=taskGroup的数量每一个TaskGroup并发执行的Task数 (默认单个任务组的并发数量为5)。
提升job内Channel并发有三种配置方式:
- 配置全局Byte限速以及单Channel Byte限速,Channel个数 = 全局Byte限速 / 单Channel Byte限速。
- 配置全局Record限速以及单Channel Record限速,Channel个数 = 全局Record限速 / 单Channel Record限速。
- 直接配置Channel个数。
配置含义:
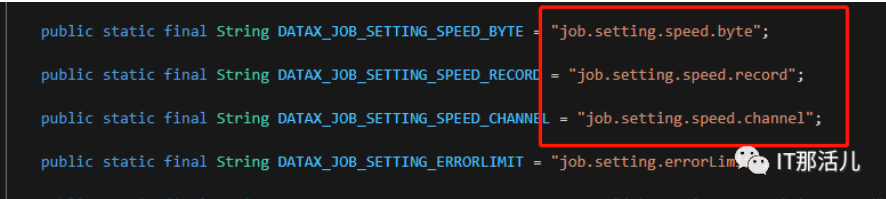
- job.setting.speed.channel : channel并发数;
- job.setting.speed.record : 全局配置channel的record限速;
- job.setting.speed.byte:全局配置channel的byte限速。
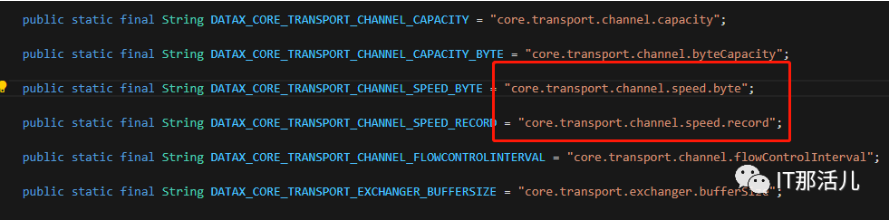
- core.transport.channel.speed.record:单channel的record限速;
- core.transport.channel.speed.byte:单channel的byte限速。
举例:

# channel增大,为防止OOM,需要修改datax工具的datax.py文件。
# 如下所示,可根据任务机的实际配置,提升-Xms与-Xmx,来防止OOM。
# tunnel并不是越大越好,过分大反而会影响宿主机的性能。

注意事项:
此处根据服务器配置进行调优,切记不可太大!否则直接Exception。以上为调优,应该是可以针对每个json文件都可以进行调优。
当提升DataX Job内Channel并发数时,调整JVM堆参数,原因如下:
- 当一个Job内Channel数变多后,内存的占用会显著增加,因为DataX作为数据交换通道,在内存中会缓存较多的数据。
- 例如Channel中会有一个Buffer,作为临时的数据交换的缓冲区,而在部分Reader和Writer的中,也会存在一些Buffer,为了防止jvm报内存溢出等错误,调大jvm的堆参数。
- 通常我们建议将内存设置为4G或者8G,这个也可以根据实际情况来调整。
- 调整JVM xms xmx参数的两种方式:一种是直接更改datax.py;另一种是在启动的时候,加上对应的参数,如下:python datax/bin/datax.py --jvm="-Xms8G -Xmx8G" XXX.json。
Channel个数并不是越多越好,原因如下:
- Channel个数的增加,带来的是更多的CPU消耗以及内存消耗。
- 如果Channel并发配置过高导致JVM内存不够用,会出现的情况是发生频繁的Full GC,导出速度会骤降,适得其反。
备注:
MysqlReader进行数据抽取时,如果指定splitPk,表示用户希望使用splitPk代表的字段进行数据分片,DataX因此会启动并发任务进行数据同步,这样可以大大提供数据同步的效能,splitPk不填写,包括不提供splitPk或者splitPk值为空,DataX视作使用单通道同步该表数据。
结语:
学习之路没有固定的,先了解原理,再根据原理及执行过程开始研究,DataX是开源软件,能直接看到开发者的思路,更能对其进行研究和修改,使其更适合我们的工作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号