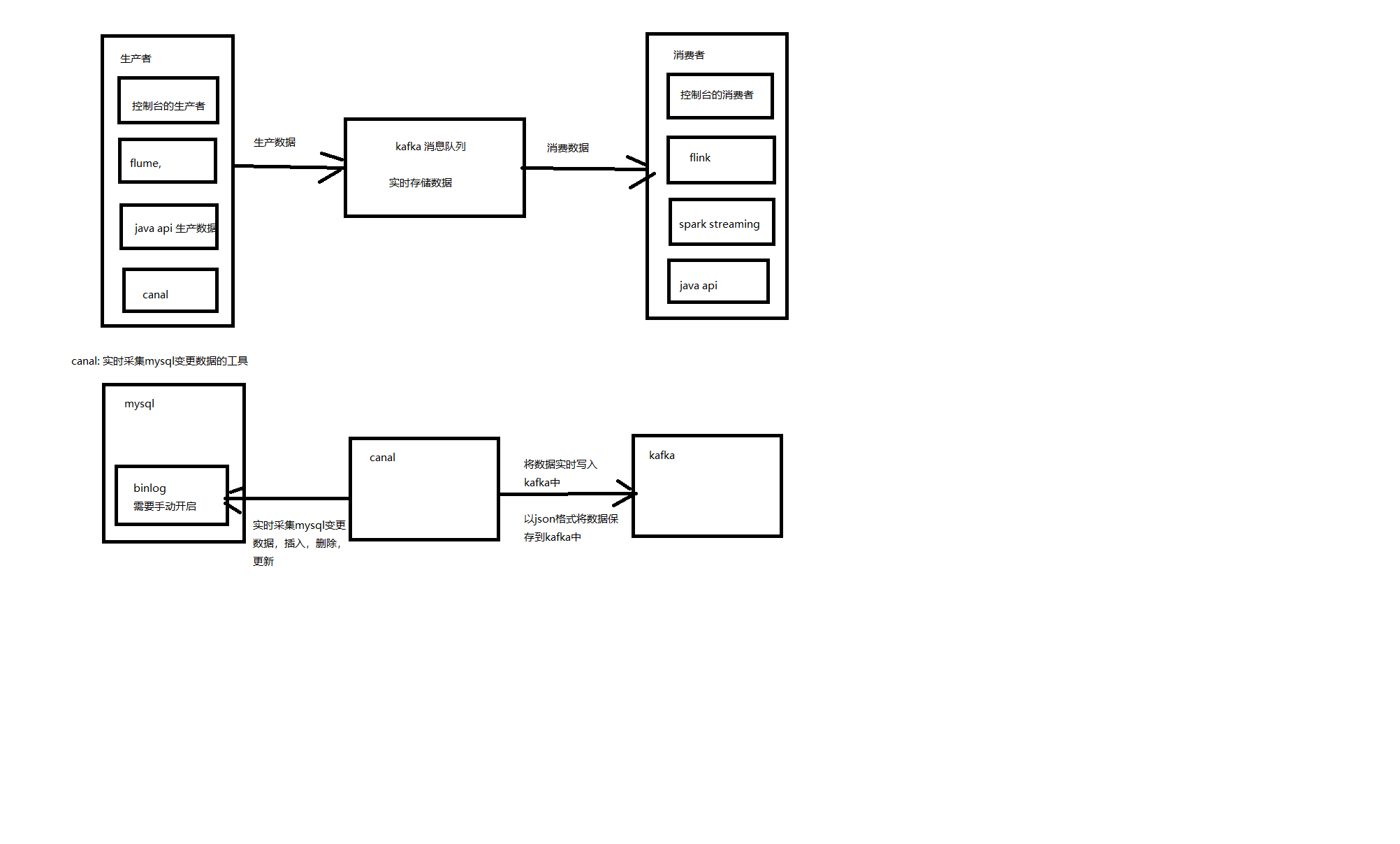
canal搭建-简单使用,flume配合kafka使用
canal搭建-简单使用,flume配合kafka使用
开启mysql binlog
默认没有开启
开启binlog之后mysql的性能会手动影响
1、修改mysql配置文件/etc/my.cnf
# 如果配置文件不存在,复制一个过来
cp /usr/share/mysql/my-medium.cnf /etc/my.cnf
vim /etc/my.cnf
# 在配置文件中增加二配置
# 需要将配置放在[mysqld]后面
# 打开binlog
log-bin=mysql-bin
# 选择ROW(行)模式
binlog-format=ROW
# 配置MySQL replaction需要定义,不要和canal的slaveId重复
server_id=1
2、重启mysql
service mysqld restart
# 查看mysql binlog文件
cd /var/lib/mysql
mysql-bin.000001
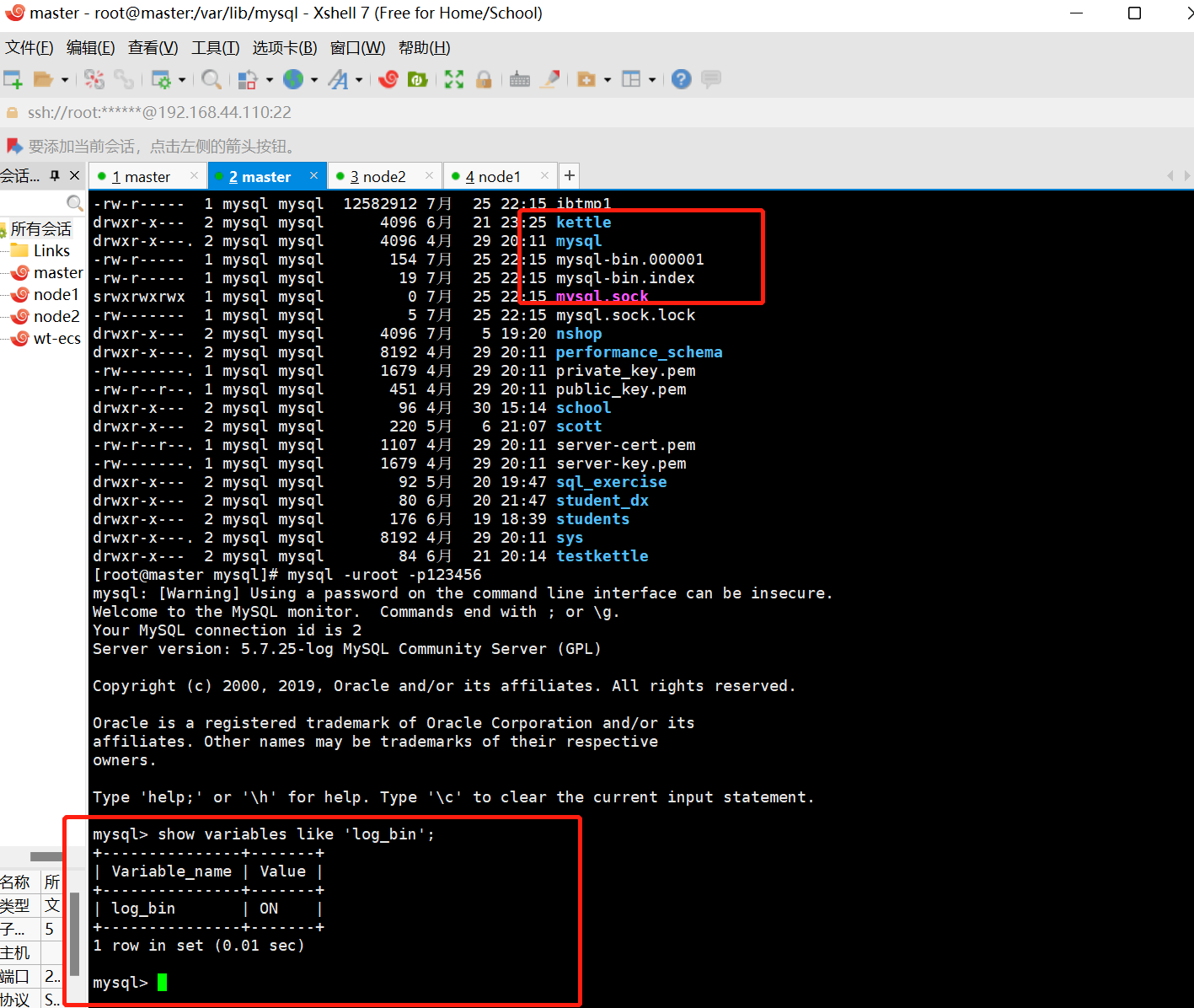
# 改了配置文件之后,重启MySQL,使用命令查看是否打开binlog模式:
mysql -uroot -p123456
show variables like 'log_bin';
搭建Canal
2、上传解压,上传到soft目录
# 创建解压目录
mkdir canal
# 解压到指定目录
tar -xvf canal.deployer-1.1.4.tar.gz -C canal
3、修改配置文件conf/example/instance.properties
vim conf/example/instance.properties
# mysql 地址
canal.instance.master.address=master:3306
# mysql用户名
canal.instance.dbUsername=root
# mysql密码
canal.instance.dbPassword=123456
# 数据写入kafka 的topic名称, 所有的数据写入同一个topic
canal.mq.topic=example
# 为每一个表自动创建一个topic
# 监控bigdata数据库,不同的表发送到表名的topic上, topic命令方式bigdata.student
canal.mq.dynamicTopic=bigdata\\..*
4、修改配置文件conf/canal.properties
vim conf/canal.properties
# zk地址
canal.zkServers = master:2181,node1:2181,node2:2181
# 数据保存到kafka
canal.serverMode = kafka
# kafka集群地址
canal.mq.servers = master:9092,node1:9092,node2:9092
5、启动canal
cd /usr/local/soft/canal/bin/
# 启动canal
./startup.sh
# 查看启动日志
cd /usr/local/soft/canal/logs
cat canal/*
cat example/*
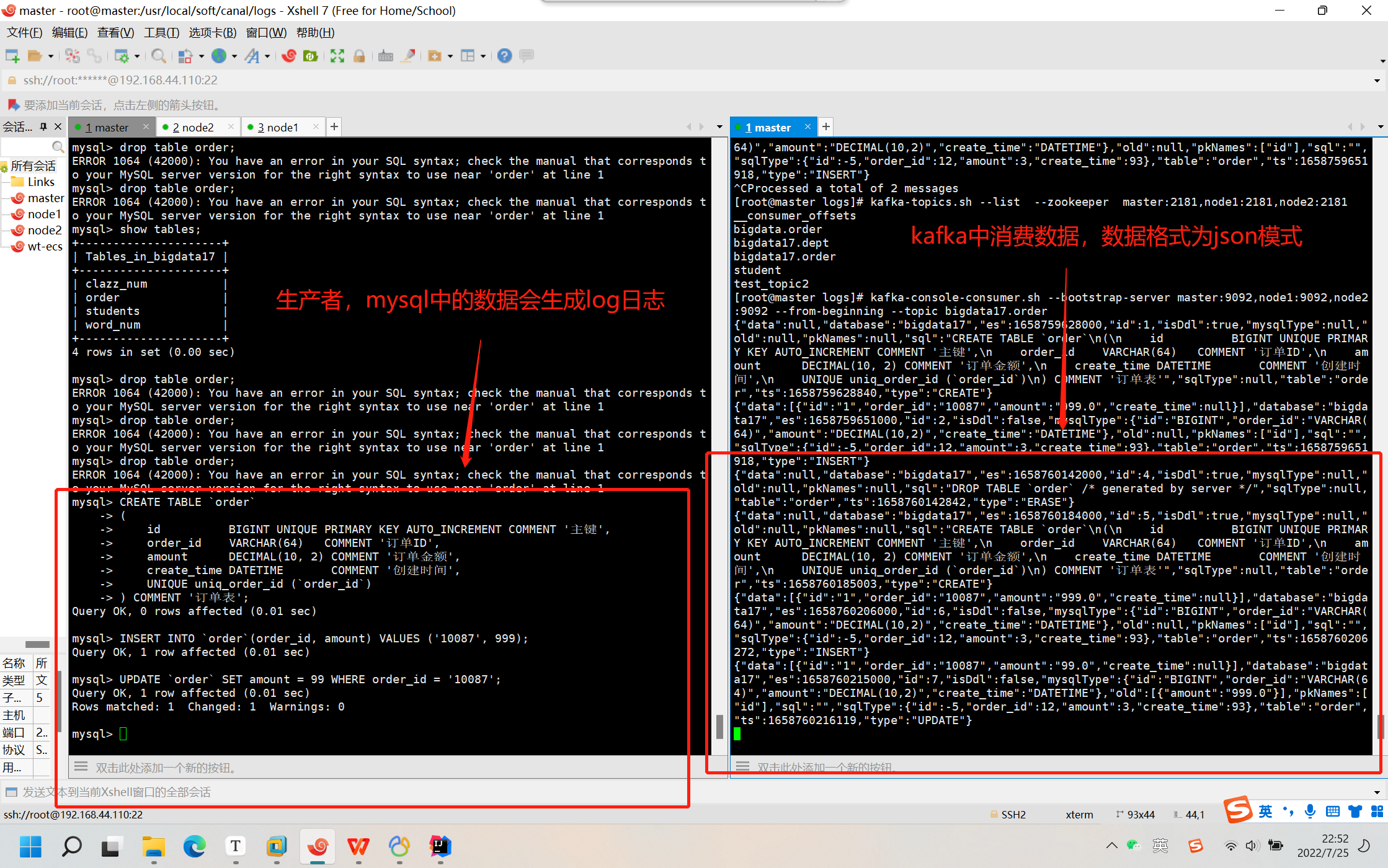
5、测试
在test数据库创建一个订单表,并且执行几个简单的DML:
-- 登录mysql
mysql -uroot -p123456
-- 切换数据库
use `bigdata`;
-- 创建表
CREATE TABLE `order`
(
id BIGINT UNIQUE PRIMARY KEY AUTO_INCREMENT COMMENT '主键',
order_id VARCHAR(64) COMMENT '订单ID',
amount DECIMAL(10, 2) COMMENT '订单金额',
create_time DATETIME COMMENT '创建时间',
UNIQUE uniq_order_id (`order_id`)
) COMMENT '订单表';
-- 插入数据
INSERT INTO `order`(order_id, amount) VALUES ('10087', 999);
UPDATE `order` SET amount = 99 WHERE order_id = '10087';
DELETE FROM `order` WHERE order_id = '10087';
6、可以利用Kafka的kafka-console-consumer消费数据
# 查看是否自动创建topic
kafka-topics.sh --list --zookeeper master:2181,node1:2181,node2:2181
# 消费数据
kafka-console-consumer.sh --bootstrap-server master:9092,node1:9092,node2:9092 --from-beginning --topic bigdata17.order
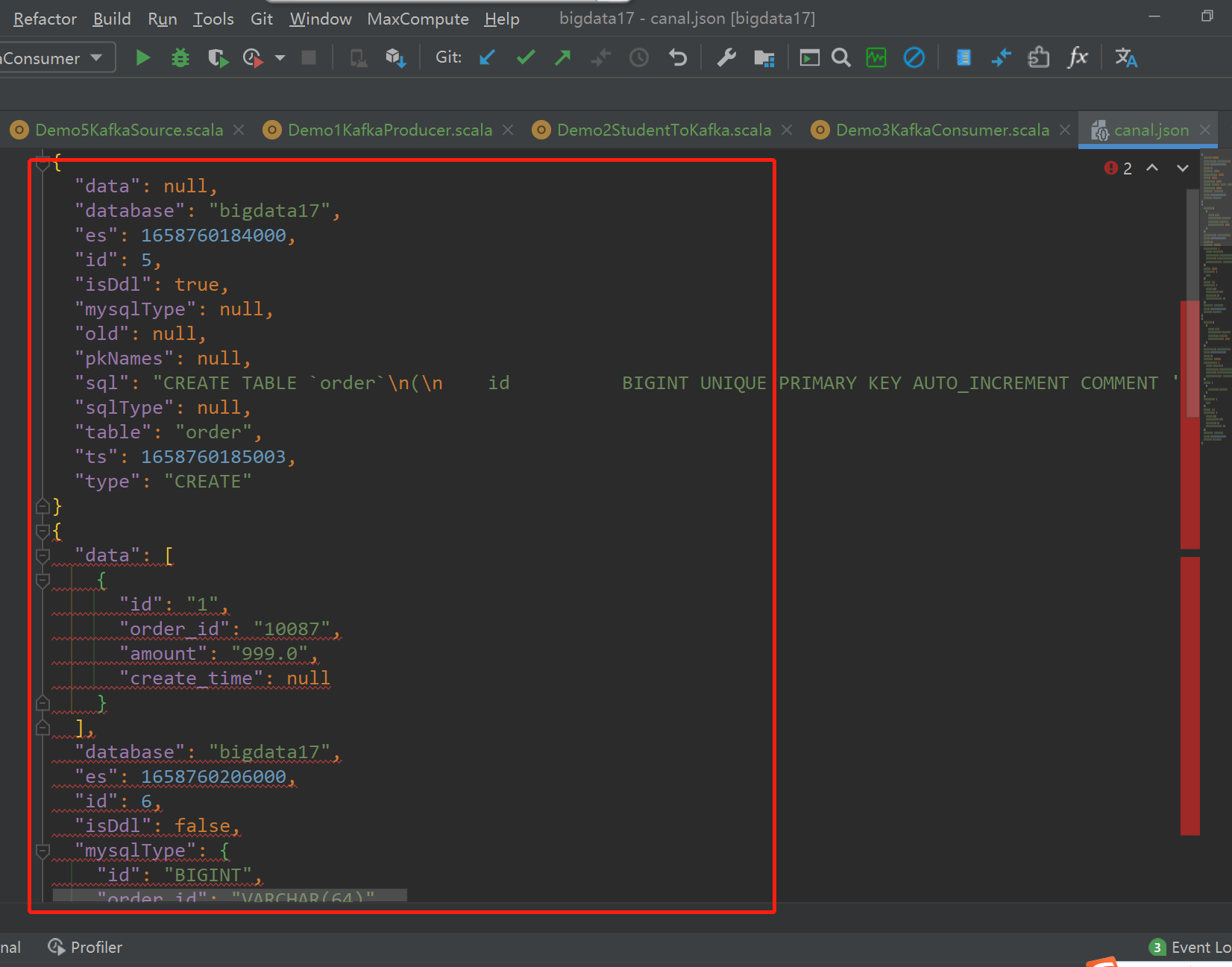
可以在idea中格式化json格式的数据 -- Ctrl+Alt+L
Flume监控文件打到kafka中
-
编写 . conf 配置文件
agent.sources=s1 agent.channels=c1 agent.sinks=k1 agent.sources.s1.type=exec #监听文件地址 agent.sources.s1.command=tail -F /usr/flume/log.log agent.channels.c1.type=memory agent.channels.c1.capacity=10000 agent.channels.c1.transactionCapacity=100 #设置Kafka接收器 agent.sinks.k1.type=org.apache.flume.sink.kafka.KafkaSink #设置Kafka的broker地址和端口号 agent.sinks.k1.brokerList=master:9092,node1:9092,node2:9092 #设置Kafka的Topic 如果topic不存在会自动创建一个topic,默认分区为1 副本为1 agent.sinks.k1.topic=flume #设置序列化方式 agent.sinks.k1.serializer.class=kafka.serializer.StringEncoder #将三个主件串联起来 agent.sources.s1.channels=c1 agent.sinks.k1.channel=c1 #mkdir /tmp/flume #echo 'java' >> /usr/flume/log.log #flume-ng agent -n agent -f ./FlumeToKafka.properties -Dflume.root.logger=DEBUG,console #kafka-console-consumer.sh --zookeeper master:2181,node1:2181,node2:2181 --from-beginning --topic flume -
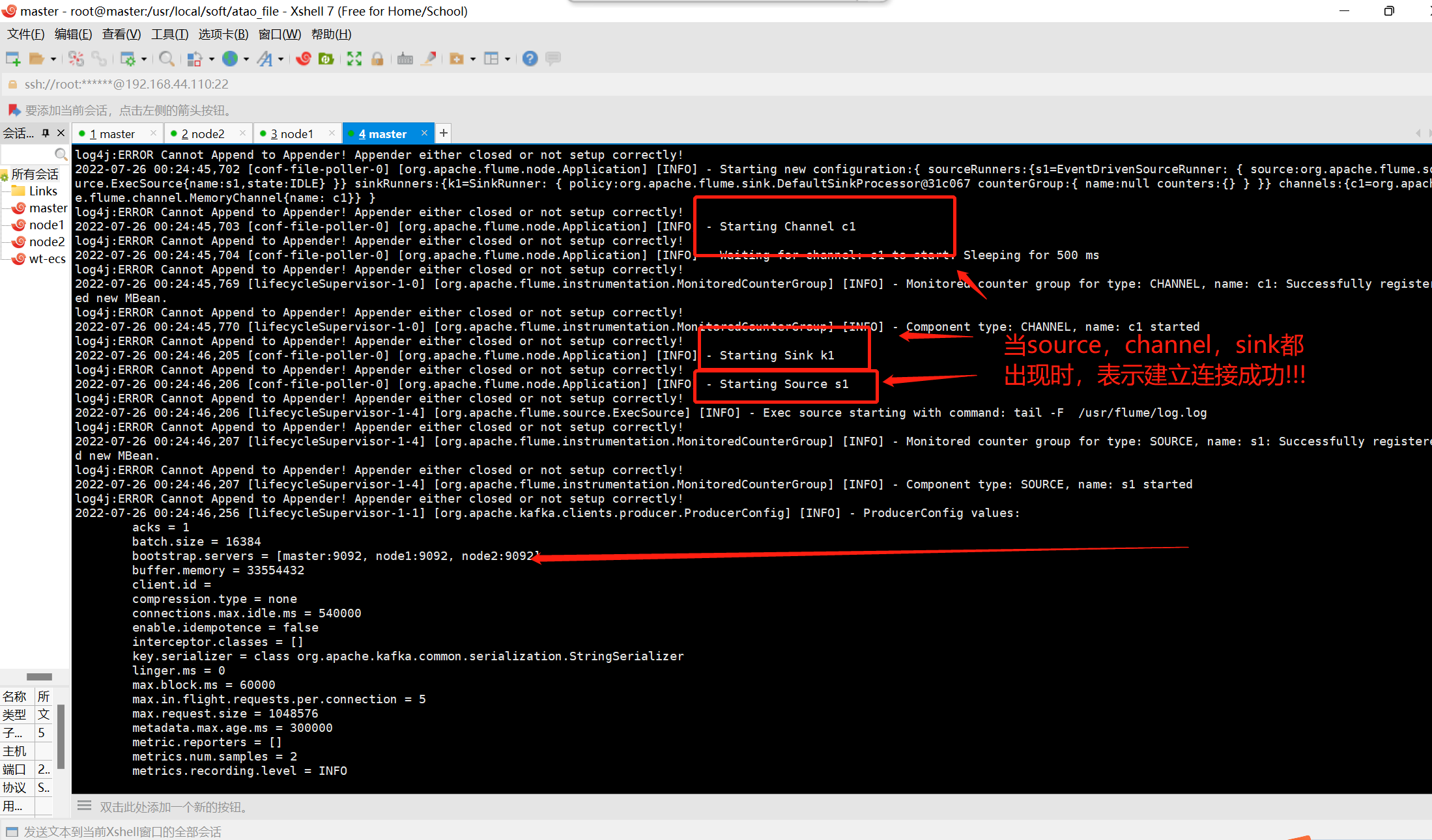
查看flume是否启动成功!
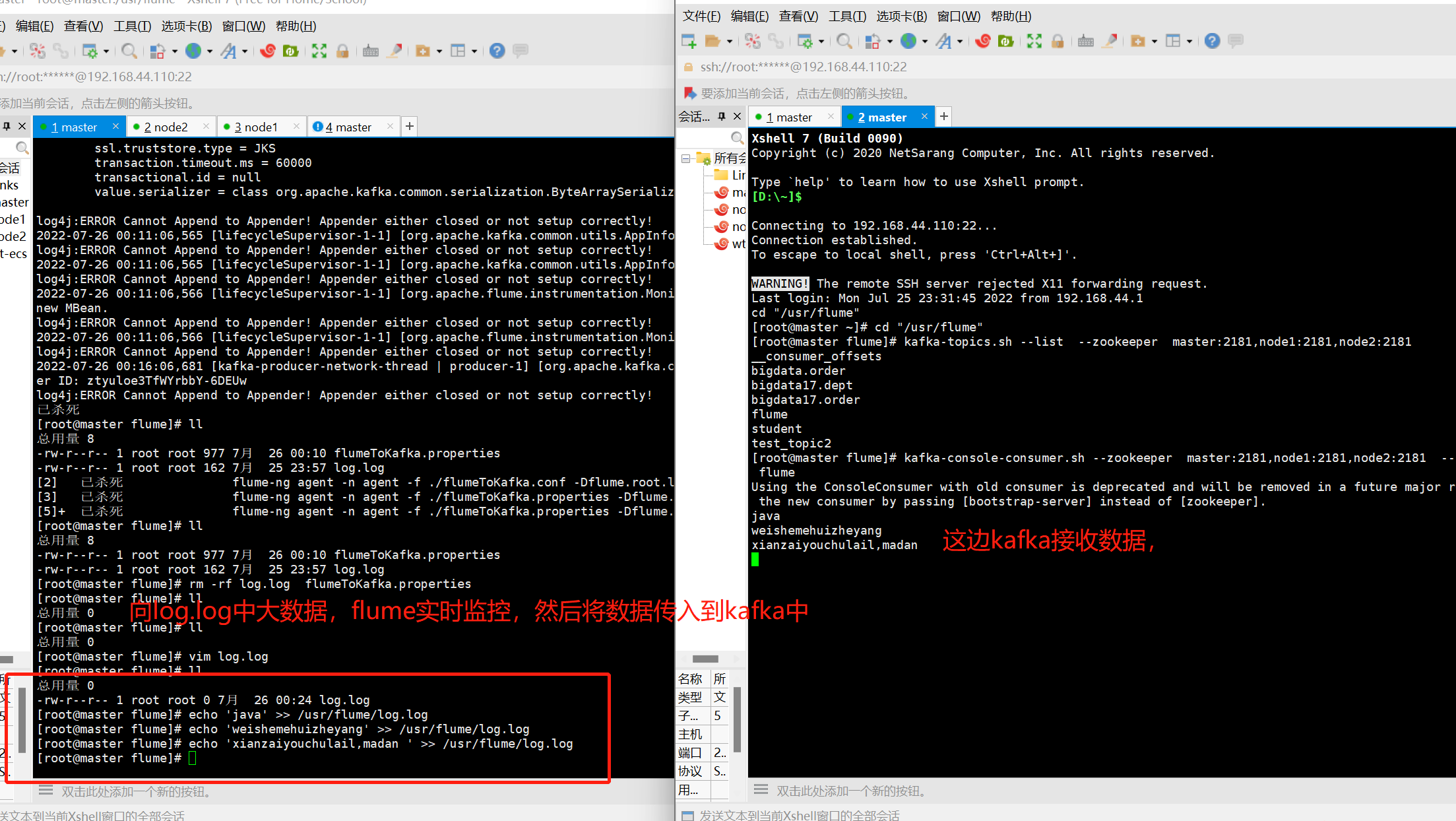
- 向log.log文件中echo数据,查看结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号