

Kettle_Kettle的安装及简单使用
Kettle的安装及简单使用
一、kettle概述
1、什么是kettle
Kettle是一款开源的ETL工具,纯java编写,可以在Window、Linux、Unix上运行,绿色无需安装,数据抽取高效稳定。
2、Kettle工程存储方式
(1)以XML形式存储
(2)以资源库方式存储(数据库资源库和文件资源库)
3、Kettle的两种设计
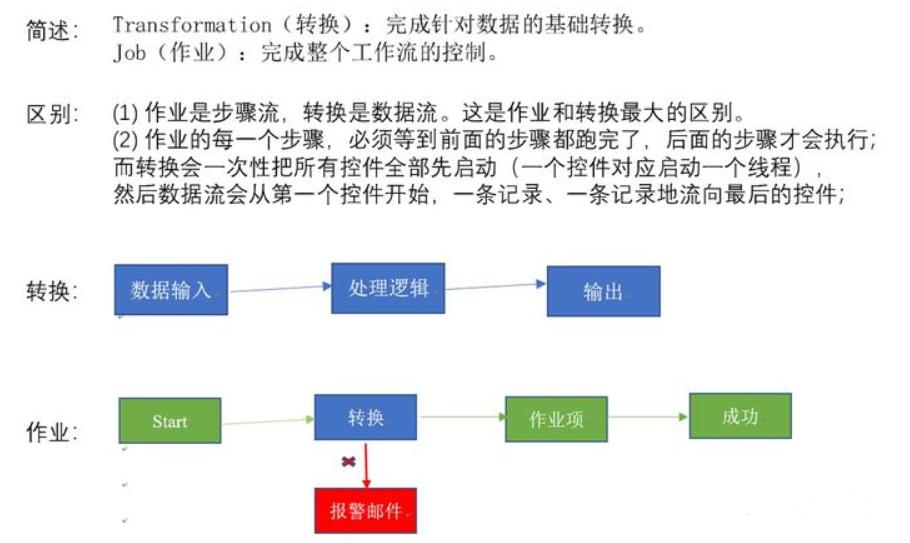
4、Kettle的组成

5、kettle特点

二、kettle安装部署和使用
Windows下安装
(1)概述
在实际企业开发中,都是在本地环境下进行kettle的job和Transformation开发的,可以在本地运行,也可以连接远程机器运行
(2)安装步骤
1、安装jdk
2、下载kettle压缩包,因kettle为绿色软件,解压缩到任意本地路径即可
3、双击Spoon.bat,启动图形化界面工具,就可以直接使用了
案例1:MySQL to MySQL
把stu1的数据按id同步到stu2,stu2有相同id则更新数据
1、在mysql中创建testkettle数据库,并创建两张表
create database testkettle;
use testkettle;
create table stu1(id int,name varchar(20),age int);
create table stu2(id int,name varchar(20));
2、往两张表中插入一些数据
insert into stu1 values(1001,'zhangsan',20),(1002,'lisi',18), (1003,'wangwu',23);
insert into stu2 values(1001,'wukong');
在data-integration\lib文件下添加mysql驱动
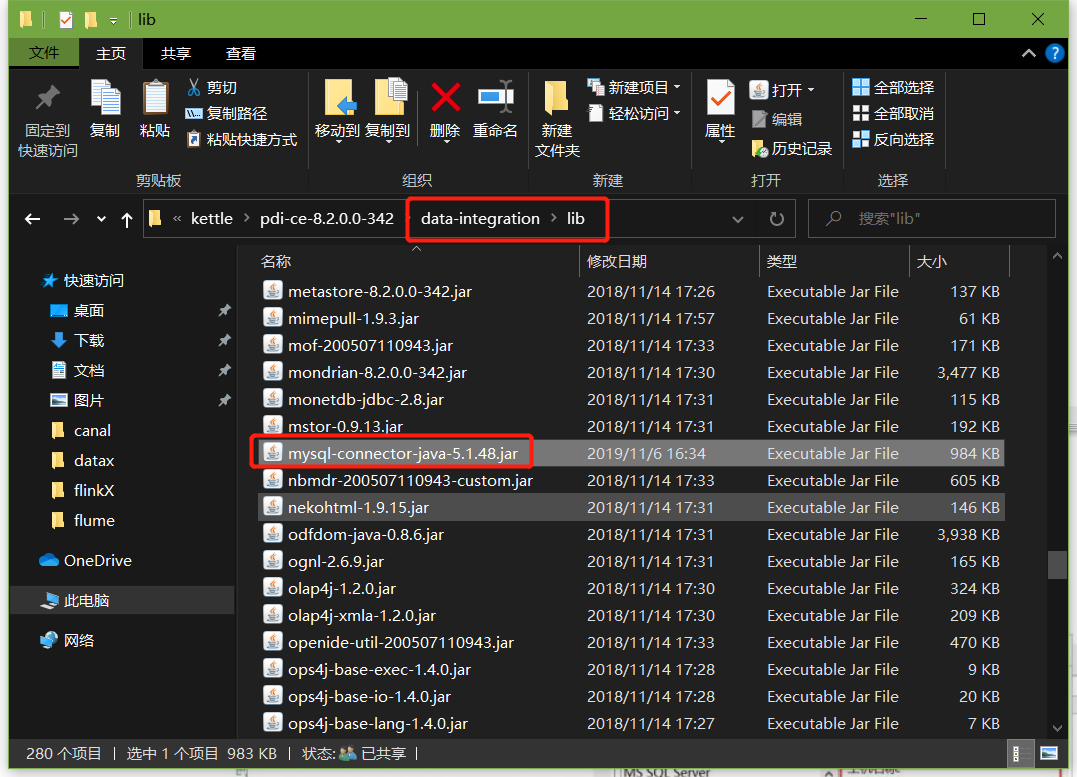
3、把pdi-ce-8.2.0.0-342.zip文件拷贝到win环境中指定文件目录,解压后双击Spoon.bat,启动图形化界面工具,就可以使用了
主界面:
在kettle中新建转换--->输入--->表输入-->表输入双击
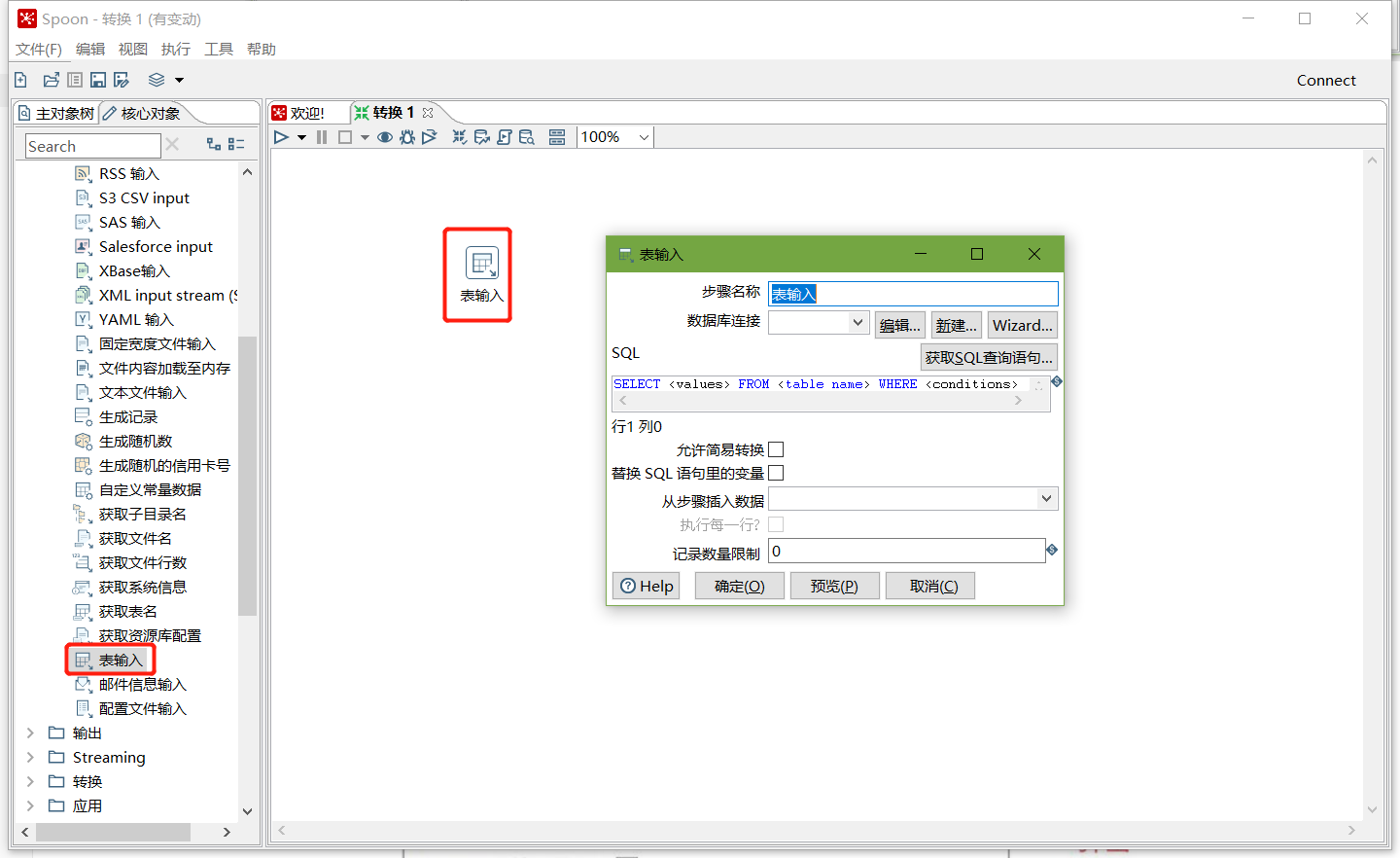
在数据库连接栏目点击新建,填入mysql相关配置,并测试连接
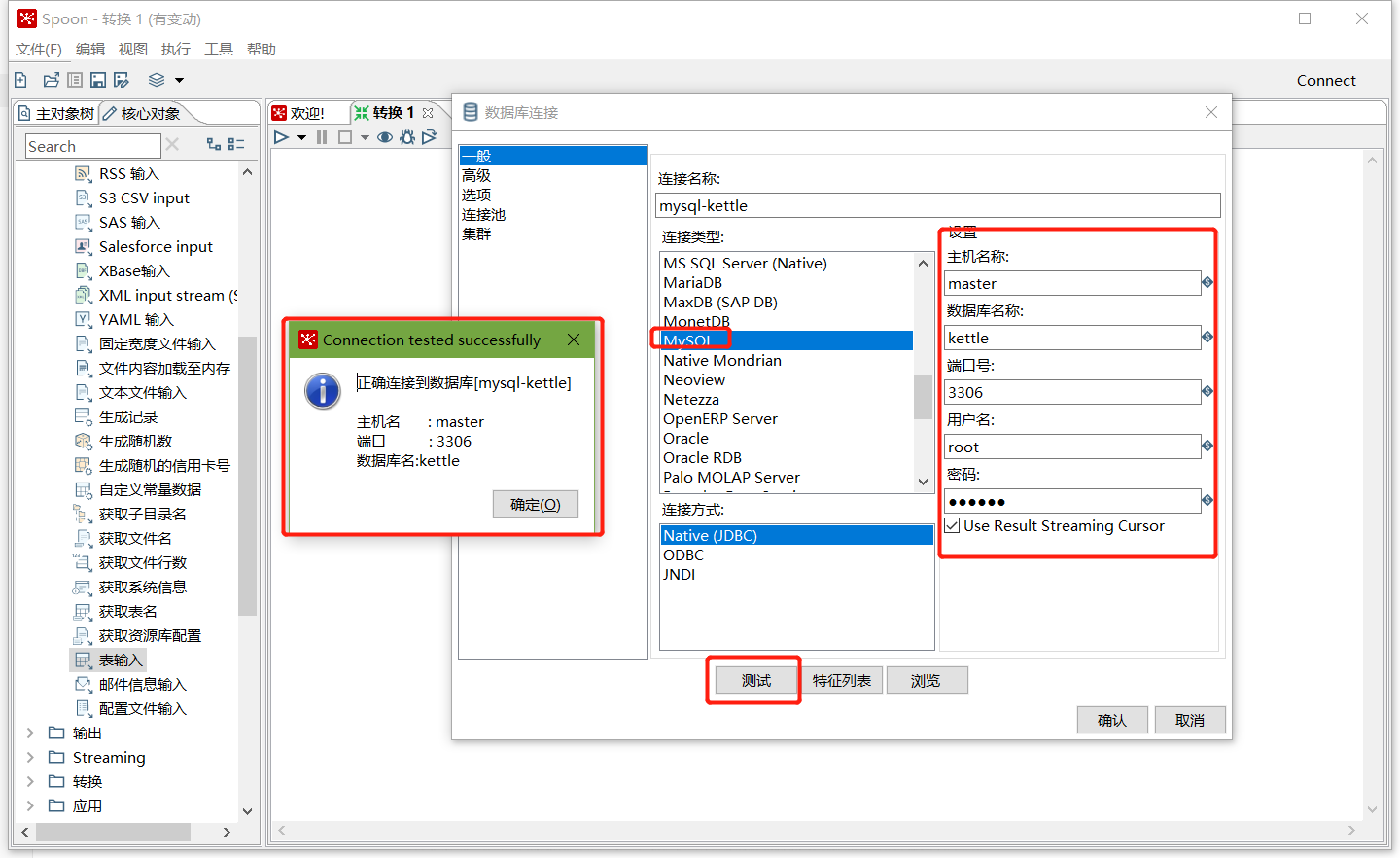
建立连接后,选择刚刚建好的连接,填入SQL,并预览数据:
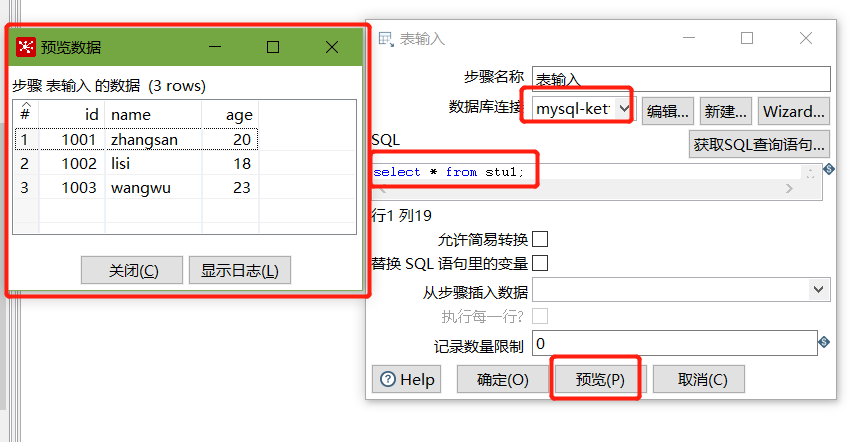
以上说明stu1的数据输入ok的,现在我们需要把输入stu1的数据同步到stu2输出的数据(ctrl+shift进行连线)
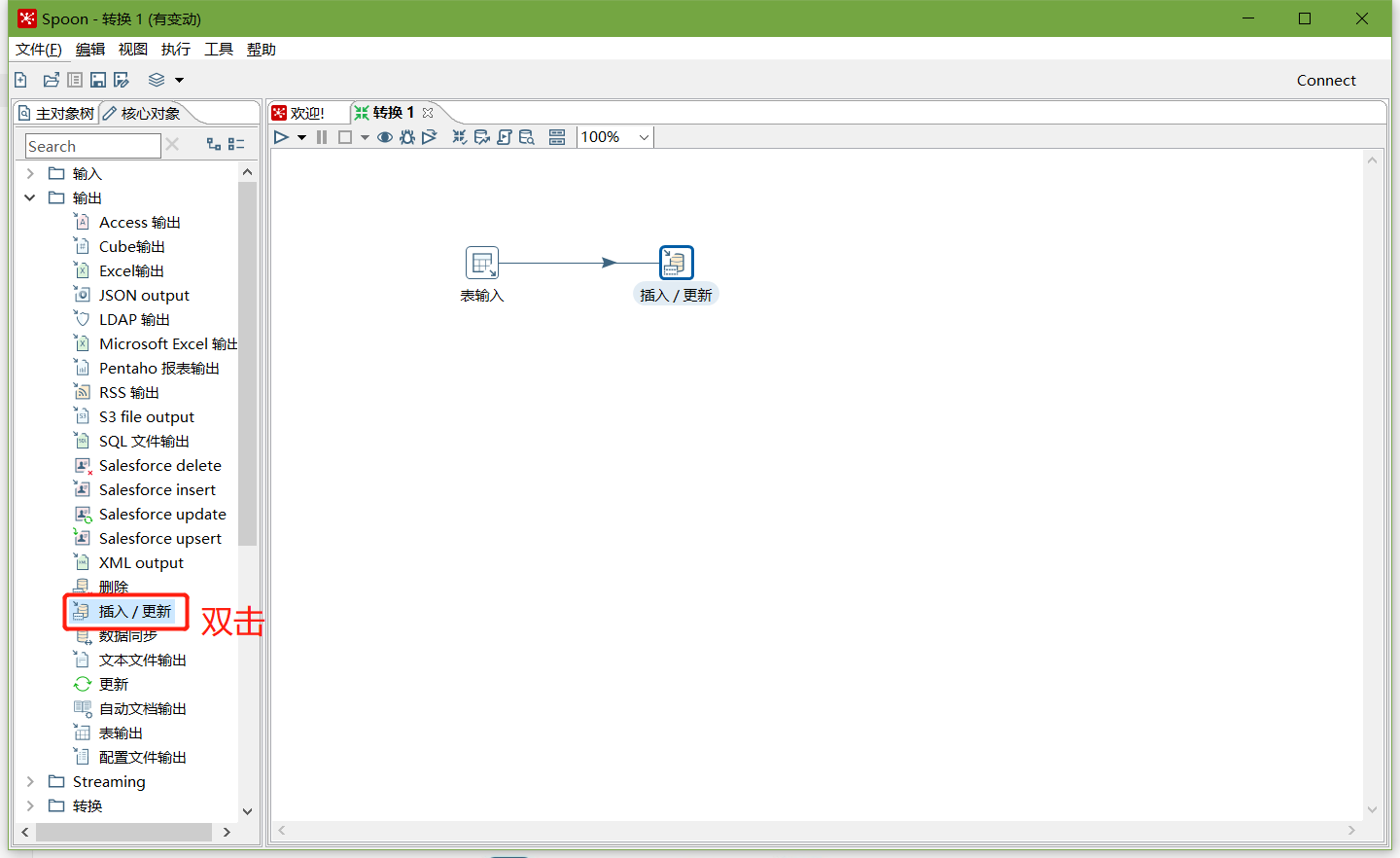
注意:拖出来的线条必须是深灰色才关联成功,若是浅灰色表示关联失败
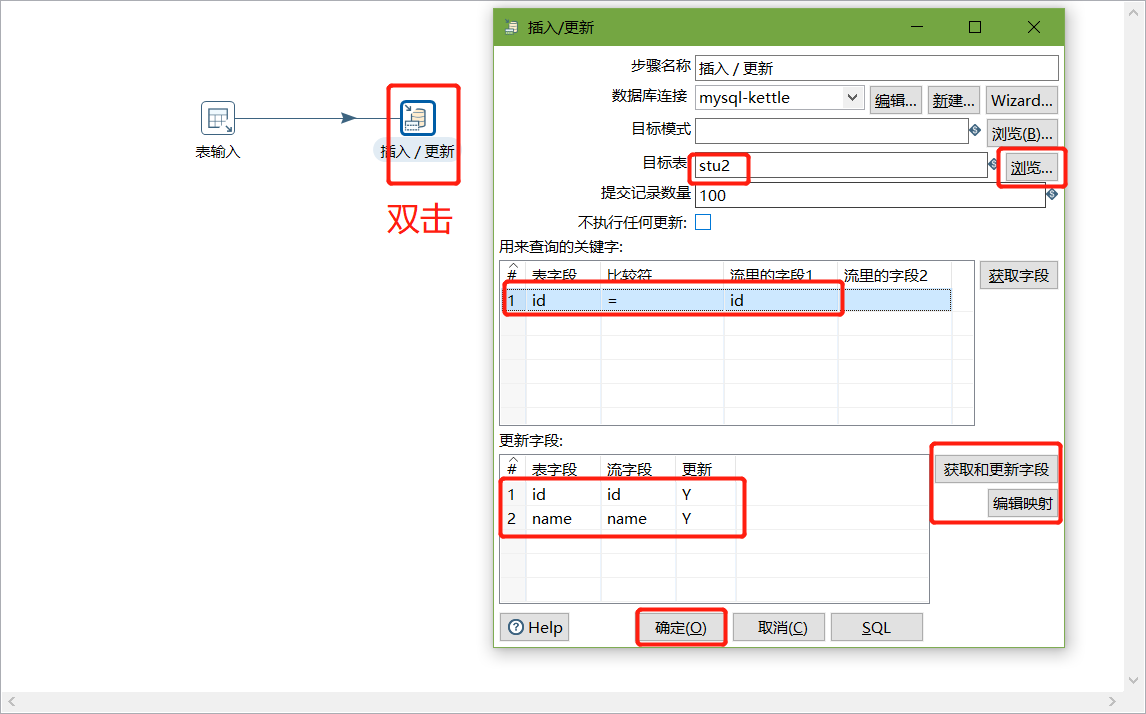
转换之前,需要做保存
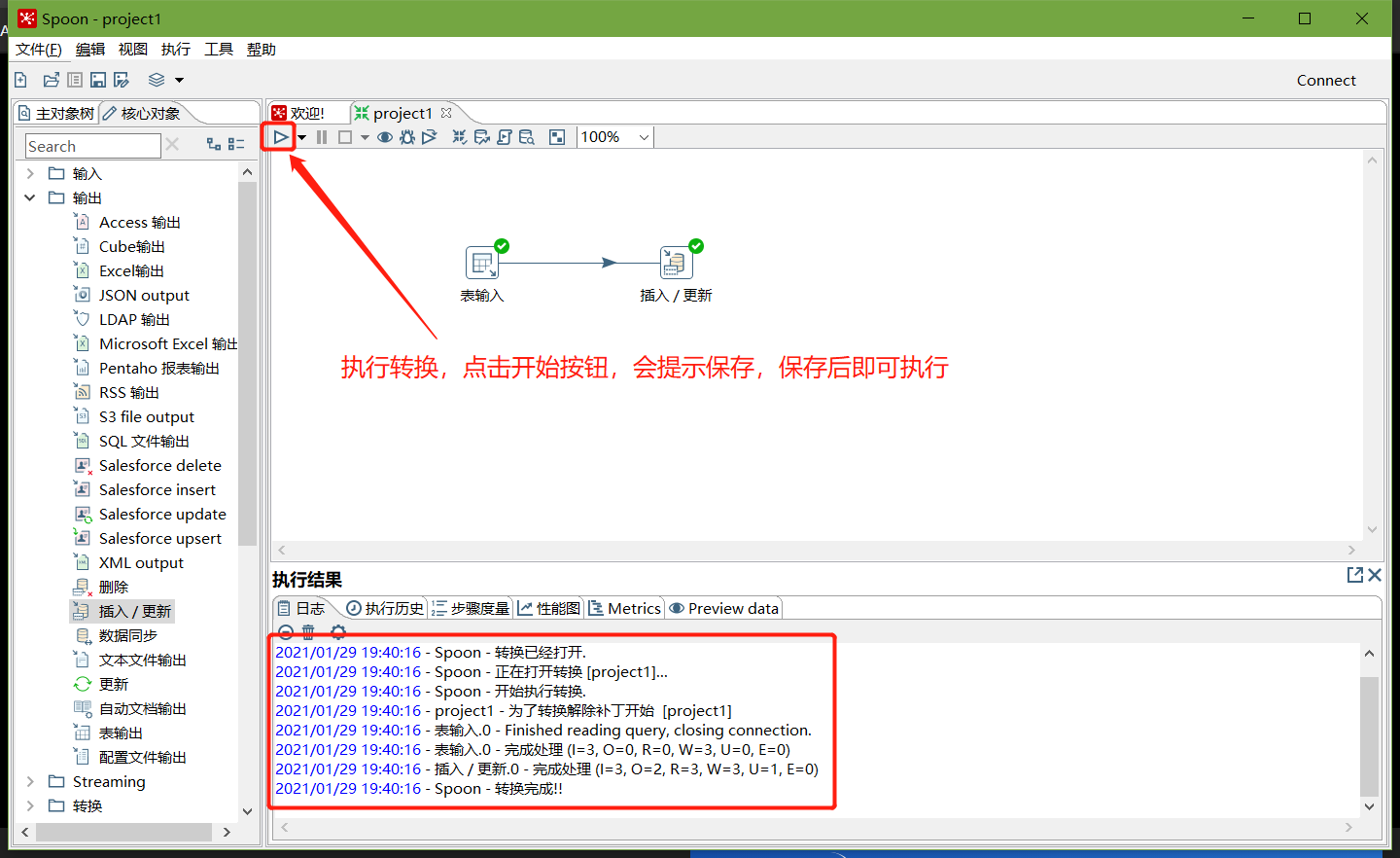
执行成功之后,可以在mysql查看,stu2的数据
mysql> select * from stu2;
+------+----------+
| id | name |
+------+----------+
| 1001 | zhangsan |
| 1002 | lisi |
| 1003 | wangwu |
+------+----------+
3 rows in set (0.00 sec)
案例2:使用作业执行上述转换,并且额外在表stu2中添加一条数据
1、新建一个作业
2、按图示拉取组件
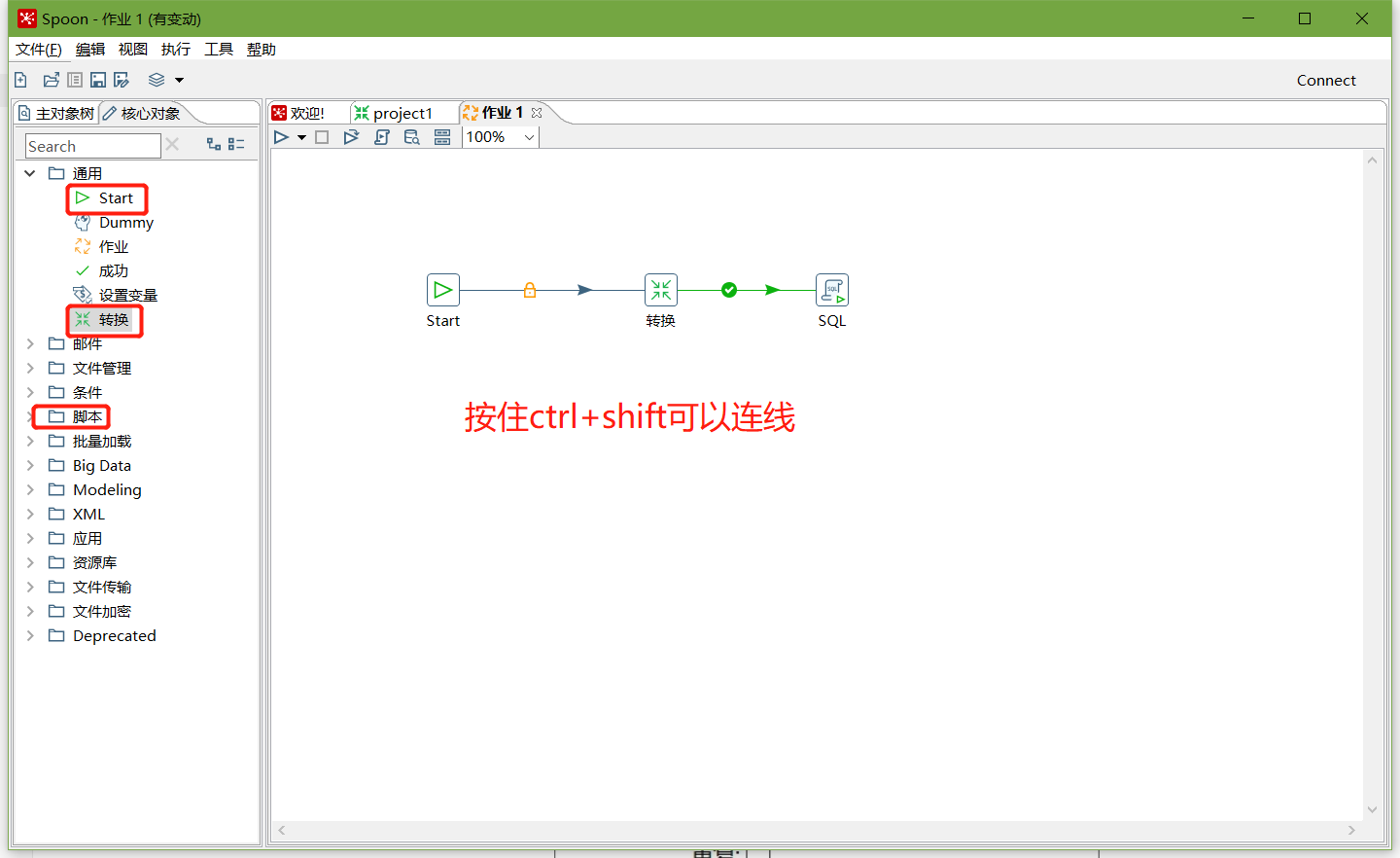
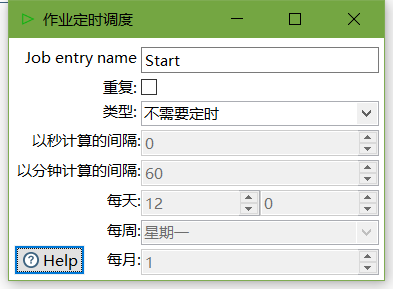
3、双击Start编辑Start
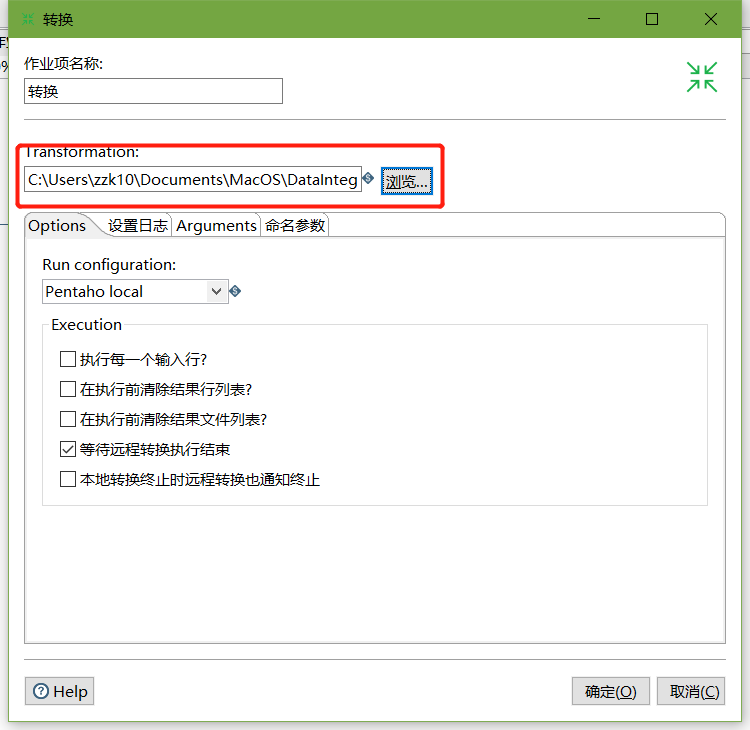
4、双击转换,选择案例1保存的文件
5、在mysql的stu1中插入一条数据,并将stu2中id=1001的name改为wukong
mysql> insert into stu1 values(1004,'stu1',22);
Query OK, 1 row affected (0.01 sec)
mysql> update stu2 set name = 'wukong' where id = 1001;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
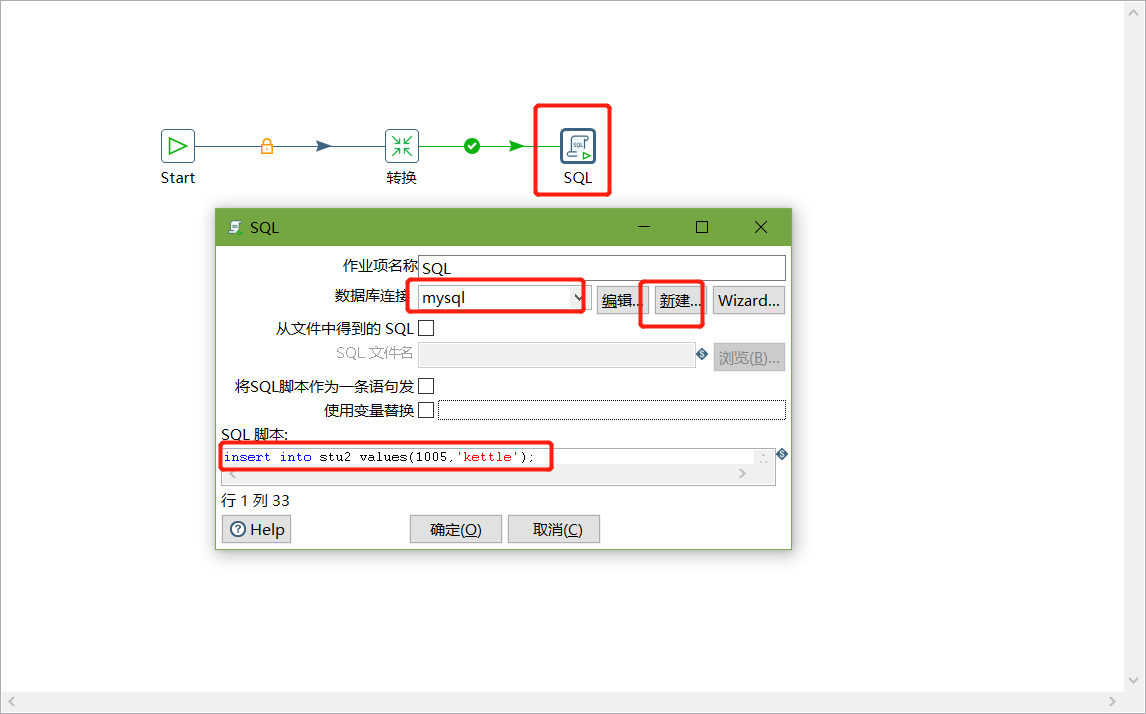
6、双击SQL脚本编辑
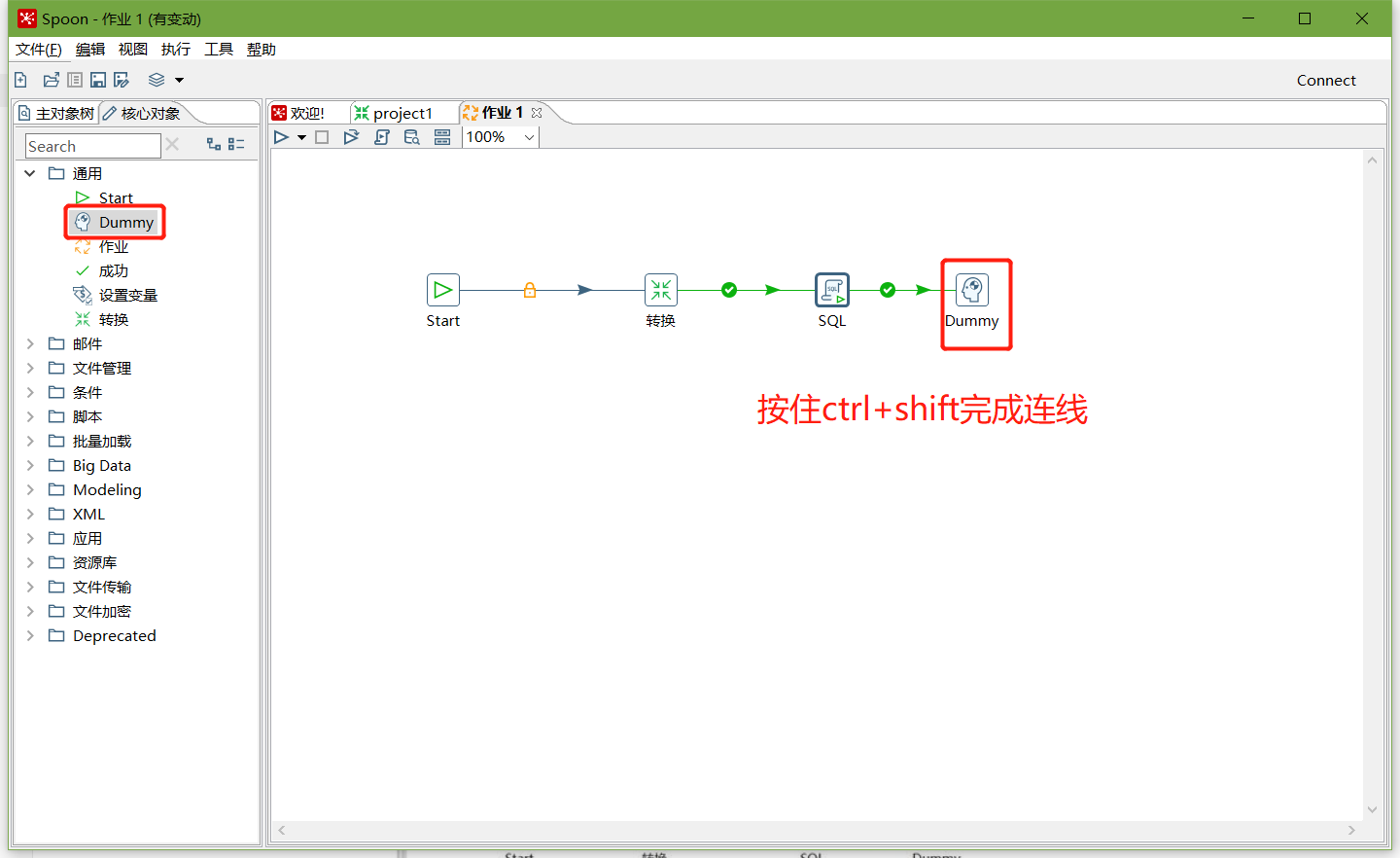
7、加上Dummy,如图所示:
8、保存并执行
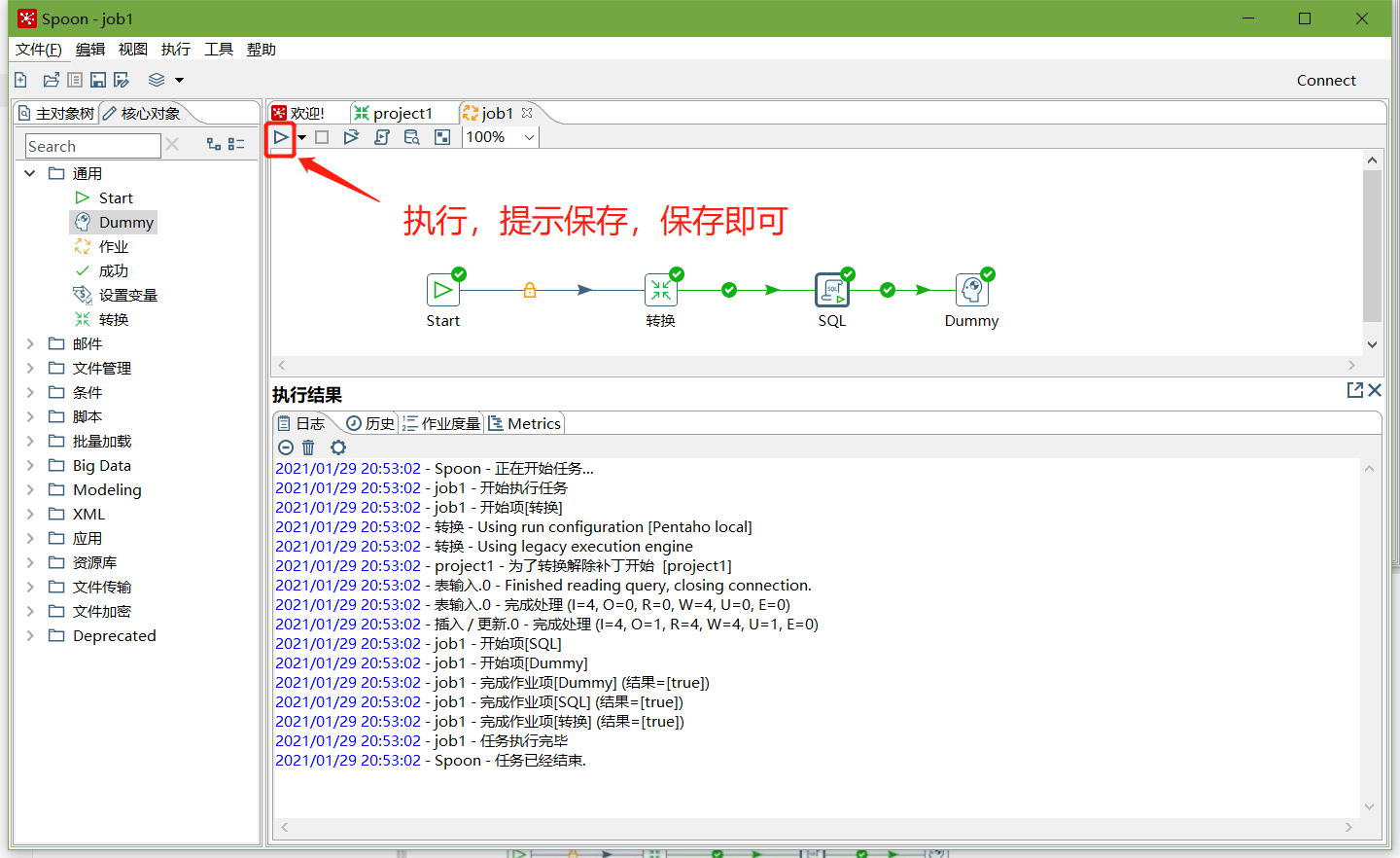
9、在mysql数据库查看stu2表的数据
mysql> select * from stu2;
+------+----------+
| id | name |
+------+----------+
| 1001 | zhangsan |
| 1002 | lisi |
| 1003 | wangwu |
| 1004 | stu1 |
| 1005 | kettle |
+------+----------+
5 rows in set (0.00 sec)
案例3:将hive表的数据输出到hdfs
1、因为涉及到hive和hbase的读写,需要修改相关配置文件
修改解压目录下的data-integration\plugins\pentaho-big-data-plugin下的plugin.properties,设置active.hadoop.configuration=hdp26,并将如下配置文件拷贝到data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations\hdp26下
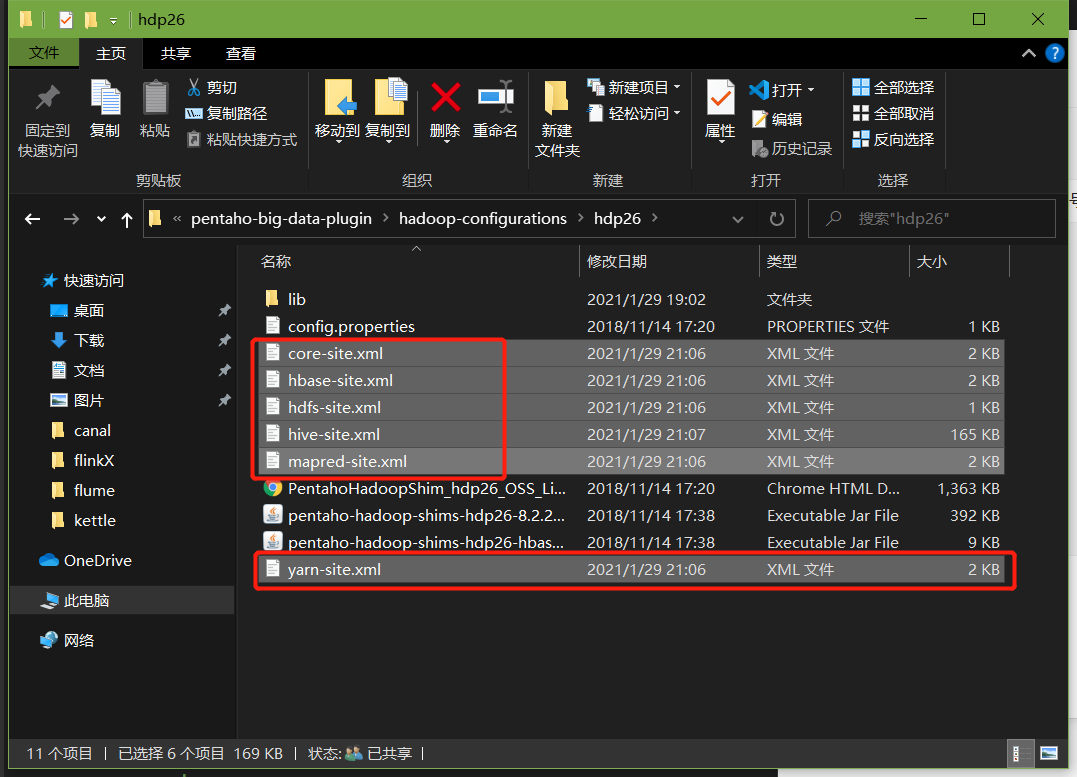
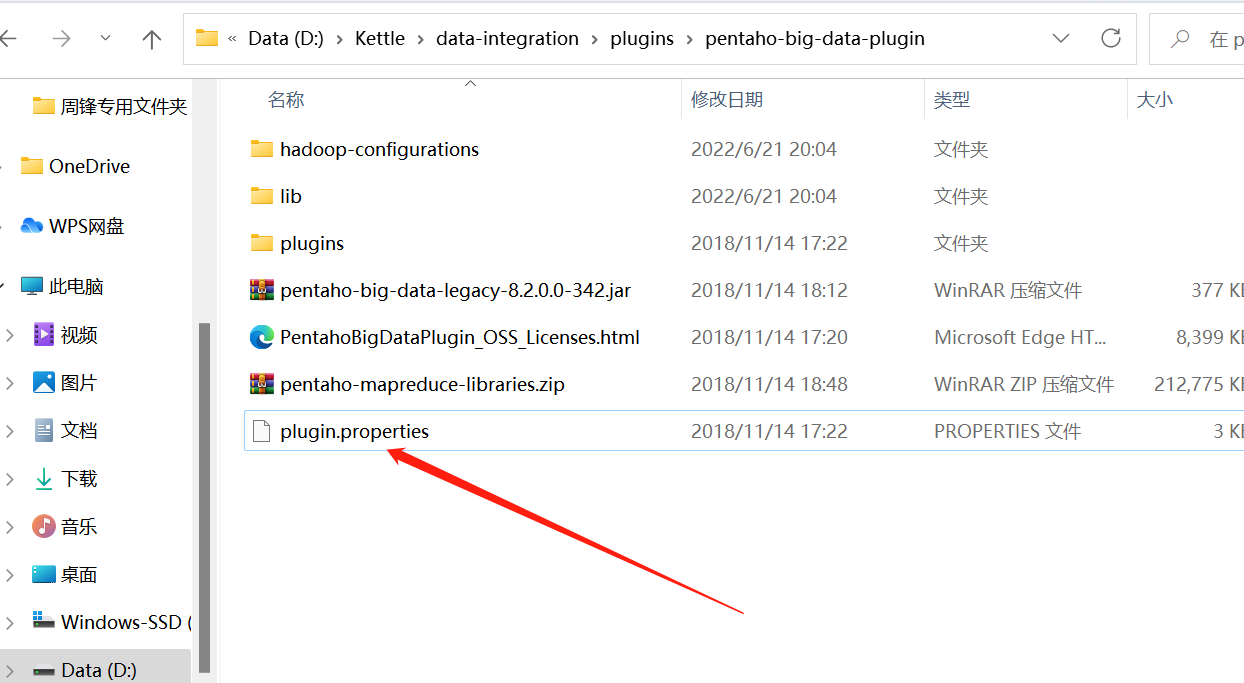
指定需要读取的configuration文件是谁

2、启动hadoop集群、hiveserver2服务
3、进入hive shell,创建kettle数据库,并创建dept、emp表
create database kettle;
use kettle;
CREATE TABLE dept(
deptno int,
dname string,
loc string
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
CREATE TABLE emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm int,
deptno int
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
4、插入数据
insert into dept values(10,'accounting','NEW YORK'),(20,'RESEARCH','DALLAS'),(30,'SALES','CHICAGO'),(40,'OPERATIONS','BOSTON');
insert into emp values(7369,'SMITH','CLERK',7902,'1980-12-17',800,NULL,20),(7499,'ALLEN','SALESMAN',7698,'1980-12-17',1600,300,30),(7521,'WARD','SALESMAN',7698,'1980-12-17',1250,500,30),(7566,'JONES','MANAGER',7839,'1980-12-17',2975,NULL,20);
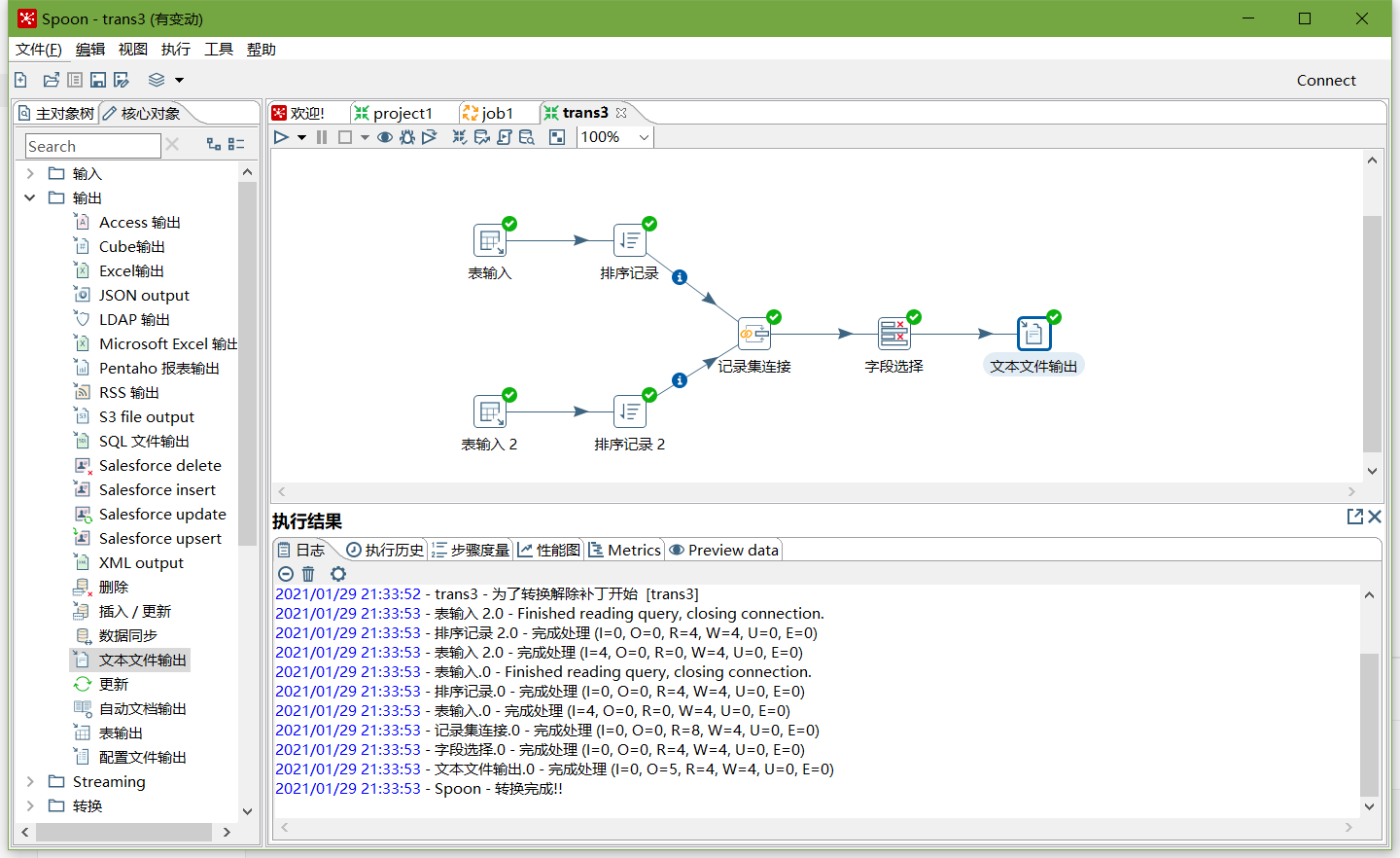
5、按下图建立流程图
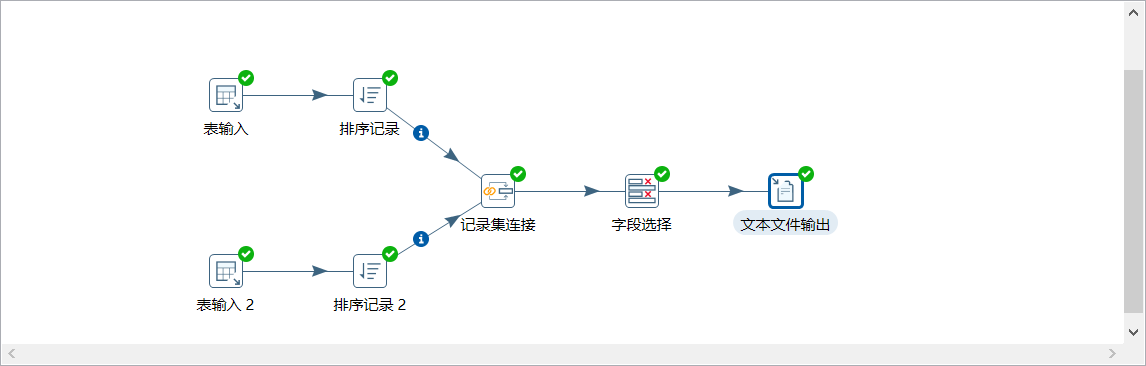
- 表输入
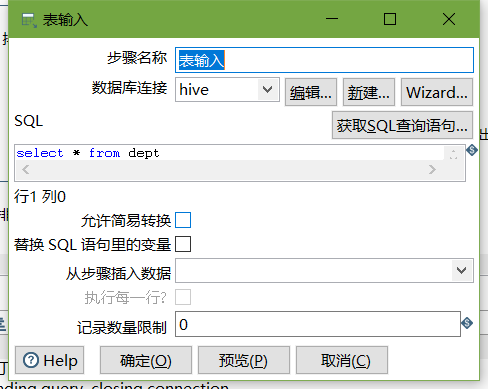
- 表输入2
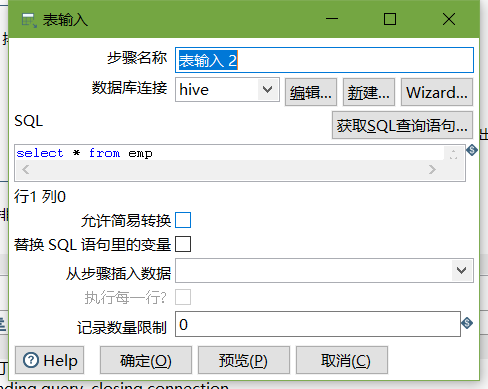
- 排序记录
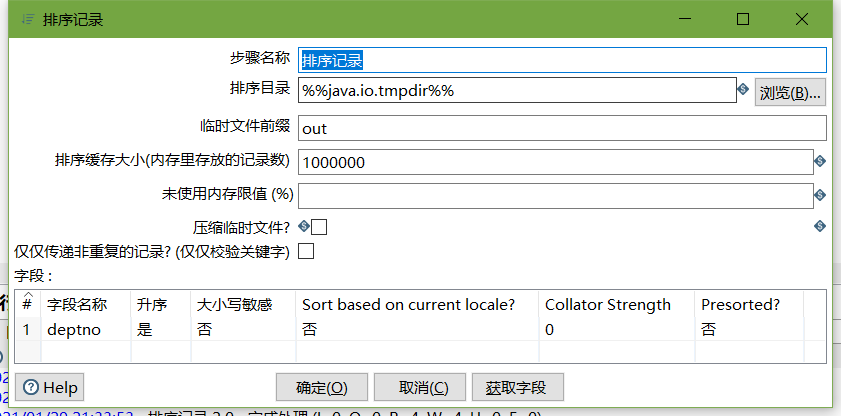
- 记录集连接
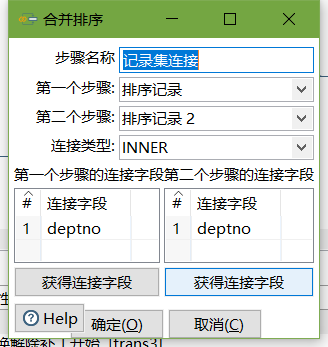
- 字段选择
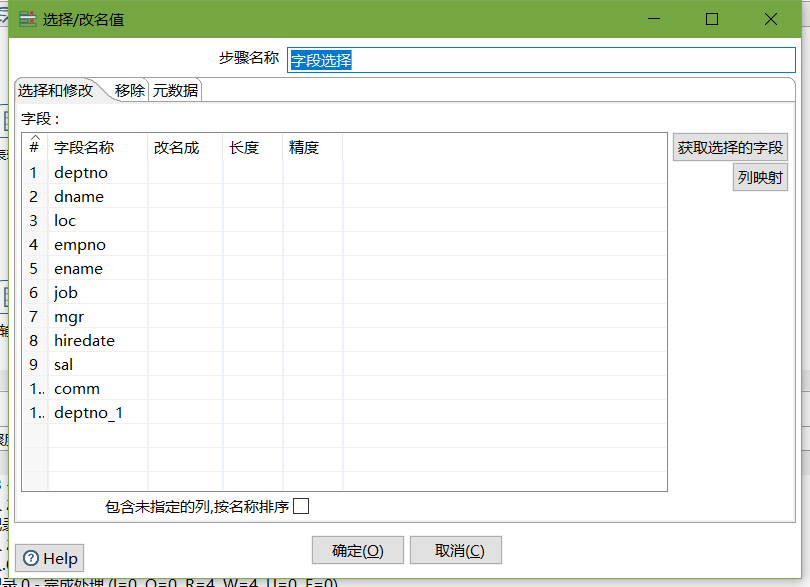
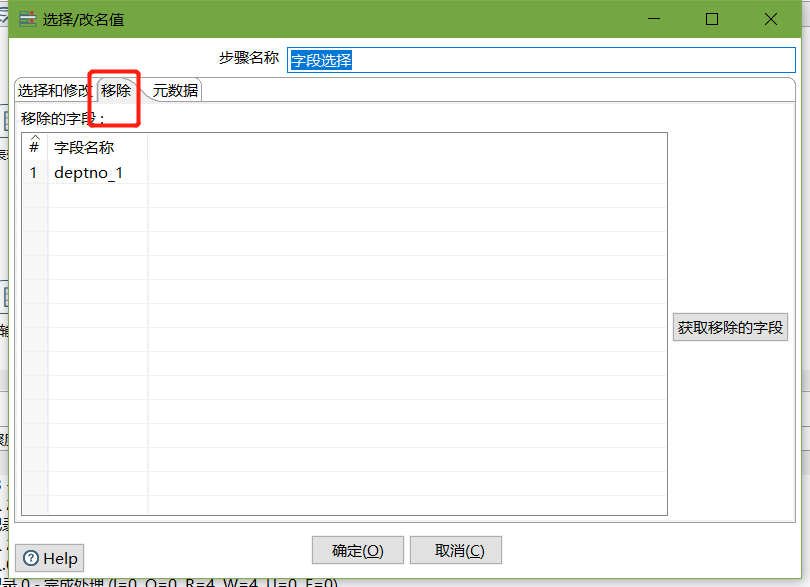
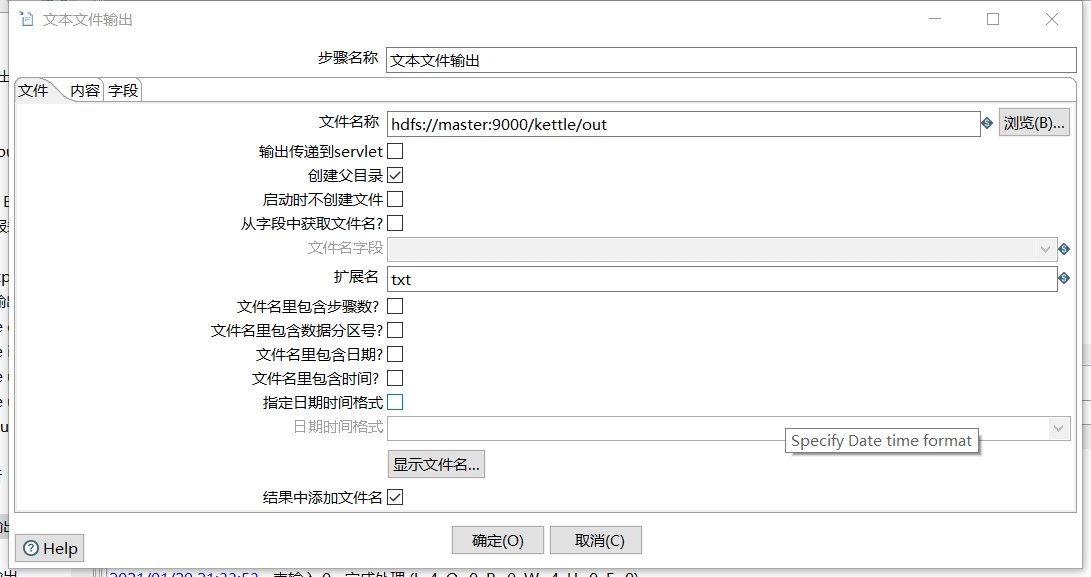
- 文本文件输出(设置最小宽度)
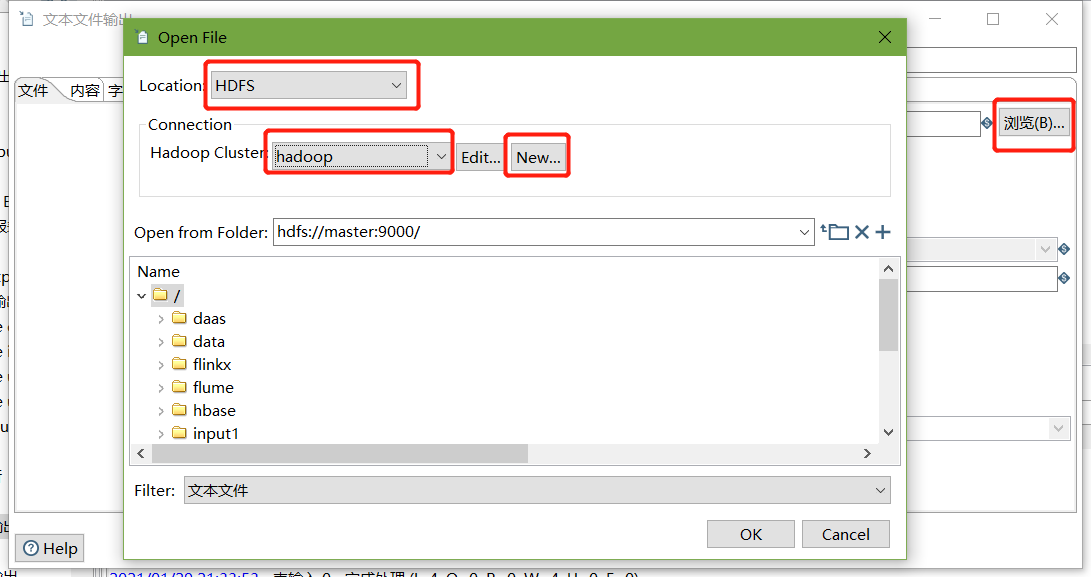
6、保存并运行查看hdfs
- 运行
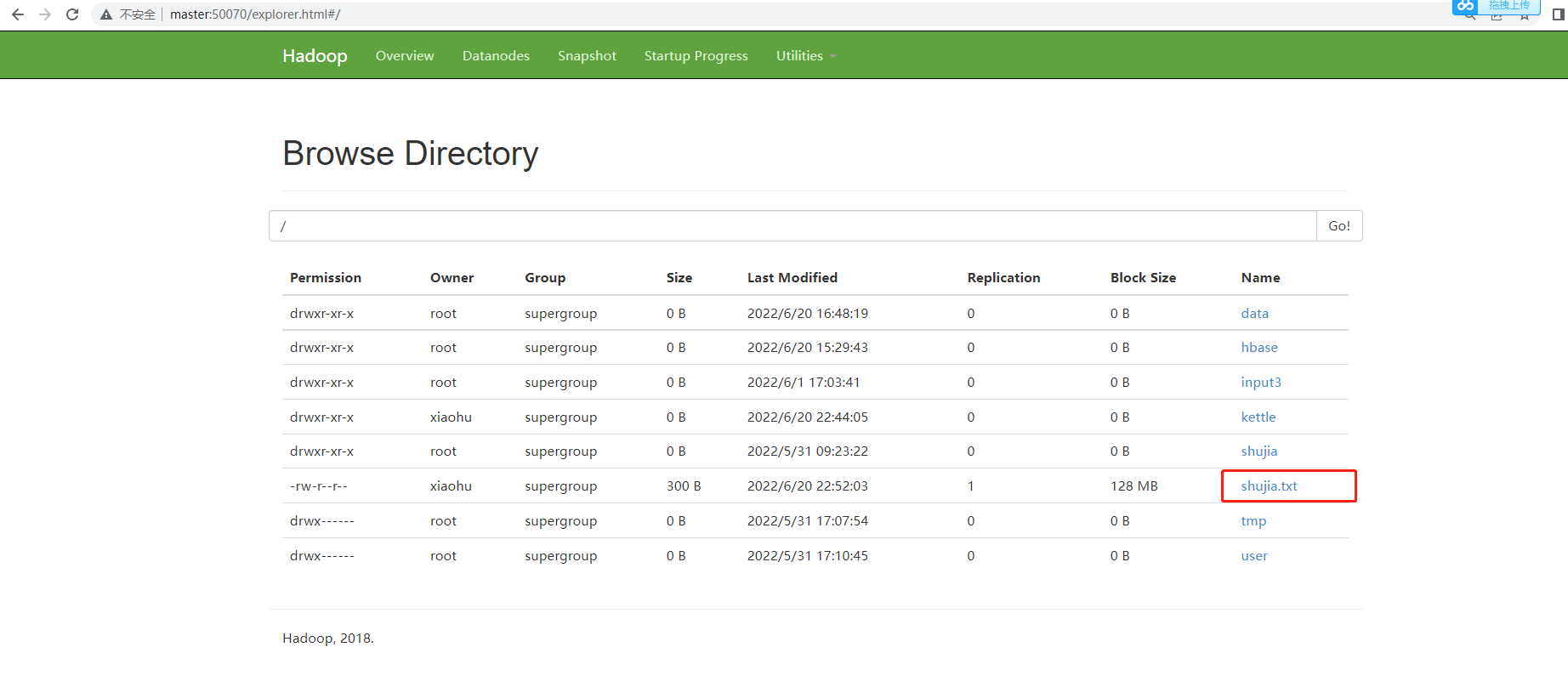
- 查看HDFS文件
案例4:读取hdfs文件并将sal大于1000的数据保存到hbase中
1、在HBase中创建一张people表
hbase(main):004:0> create 'people','info'
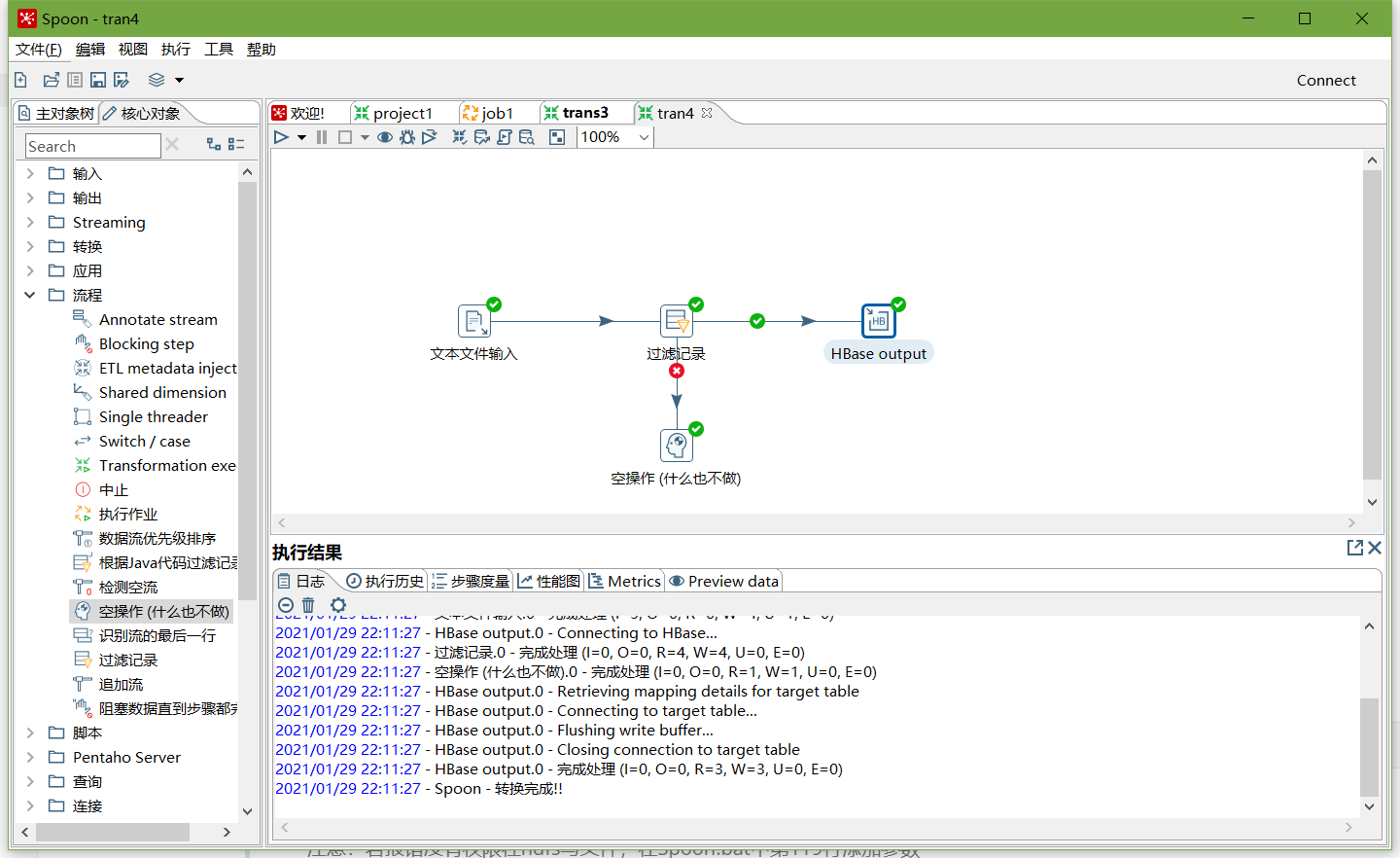
2、按下图建立流程图
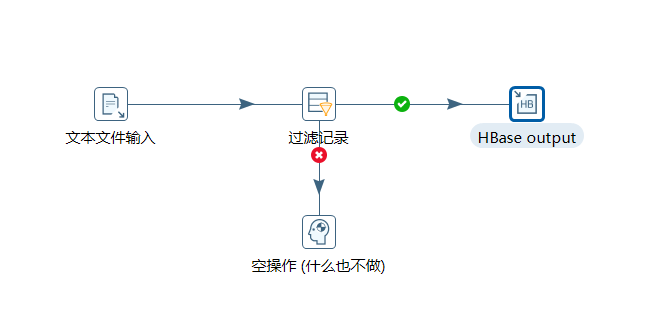
- 文本文件输入
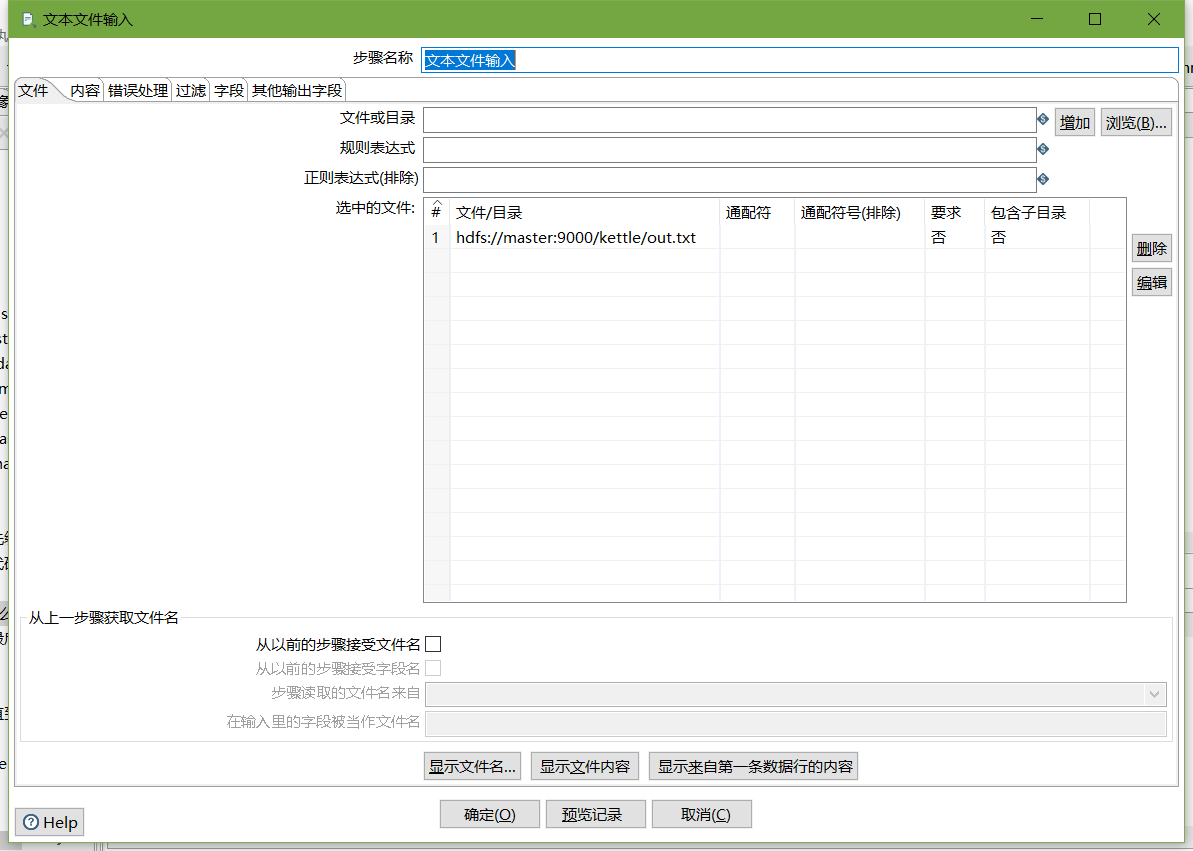
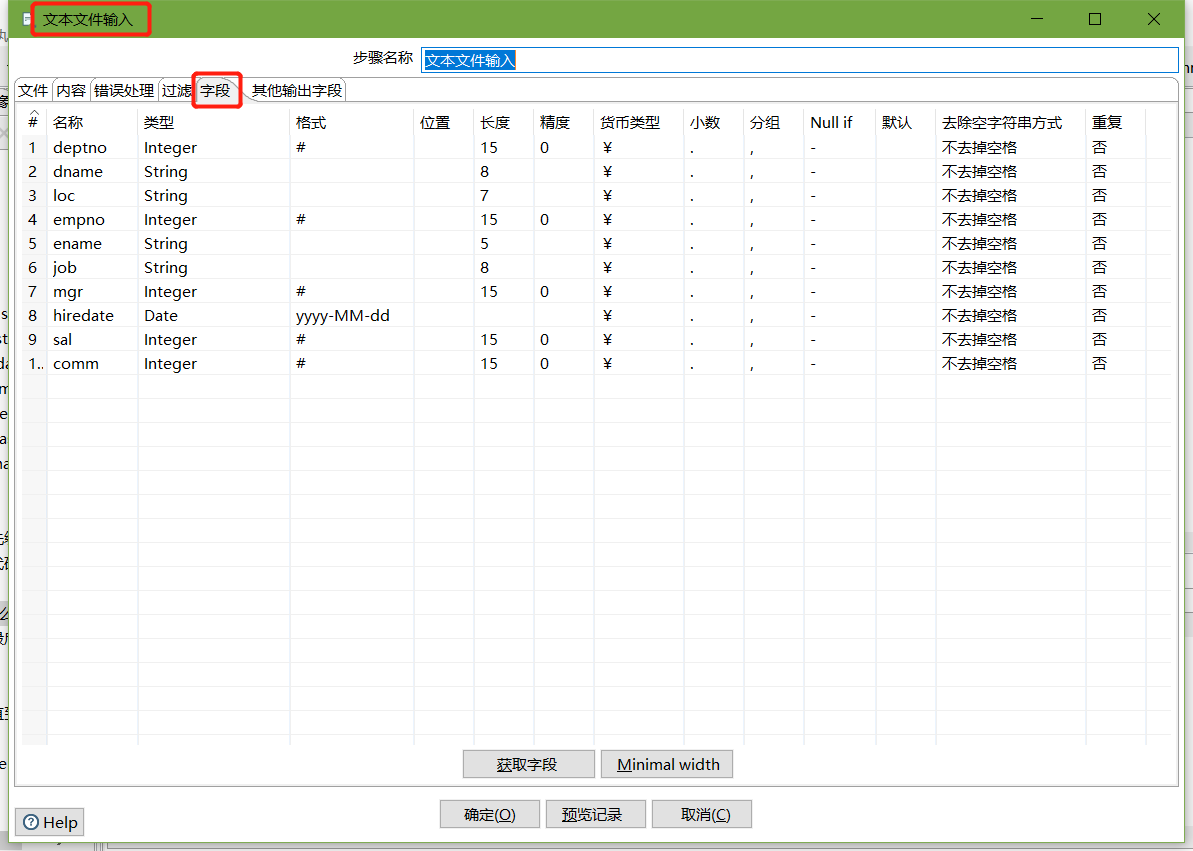
- 设置过滤记录
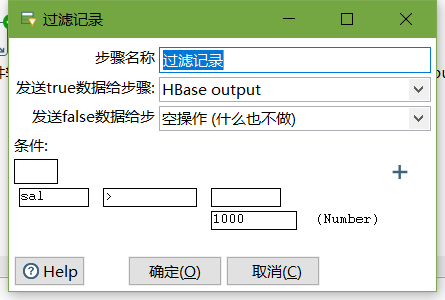
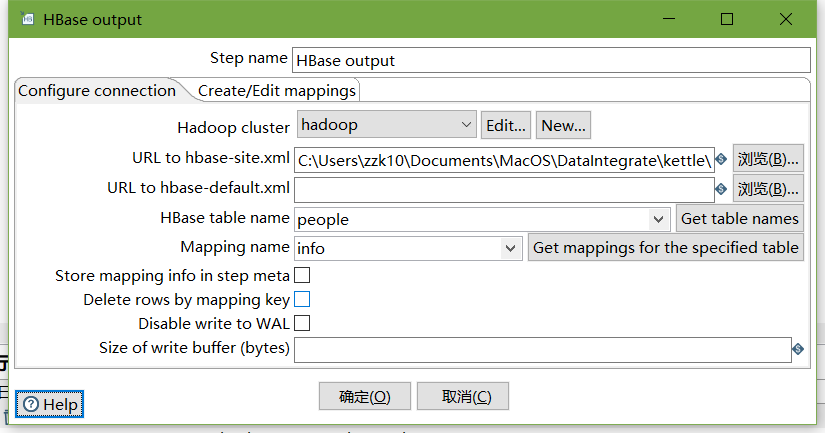
-
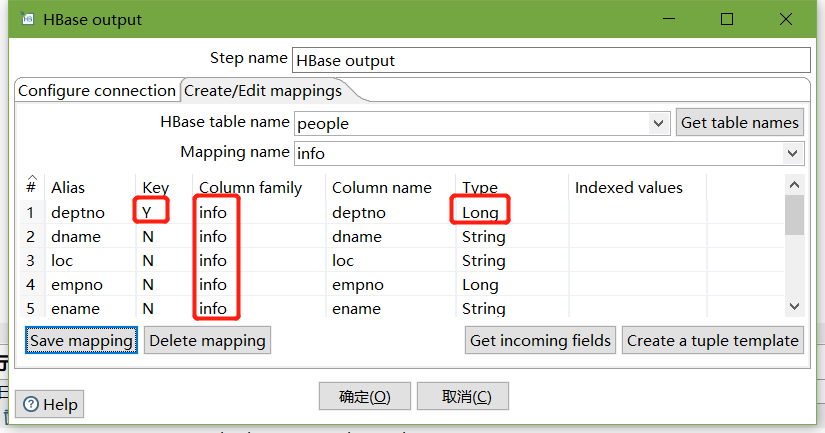
设置HBase output
编辑hadoop连接,并配置zookeeper地址
- 执行转换
-
查看hbase people表的数据
scan 'people'注意:若报错没有权限往hdfs写文件,在Spoon.bat中第119行添加参数
"-DHADOOP_USER_NAME=root" "-Dfile.encoding=UTF-8"

