MySQL-基础(二)
DQL中的函数
4.1 单行函数
函数都是数据库提前给我们准备好的,所以我们可以直接调用,使用函数可以让指定的列计算出我们需要的数据
单行函数 : 指的是操作一行数据返回一行数据,操作10行数据返回10行数据
字符串函数
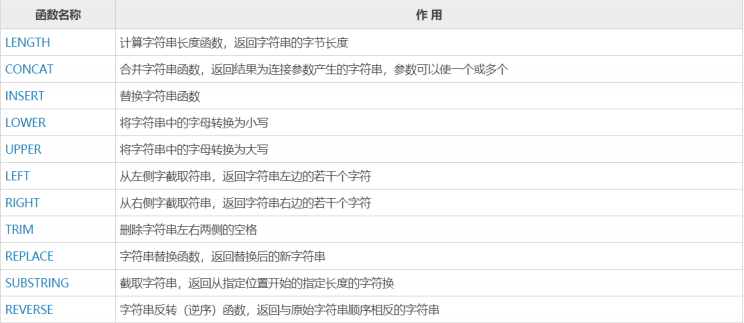
-- 长度
- select ename,length(ename) from emp;
-- 截取
- select ename,SUBSTR(ename,1,3) from emp;
- select * from emp where substr(ename,5,1)='S';
-- 大小写
- select ename, upper(ename),lower(ename) from emp;
-- 拼接
- select CONCAT(empno,'=',ename) from emp;
-- 替换
- select ename,REPLACE(ename,'T','—') from emp
日期函数
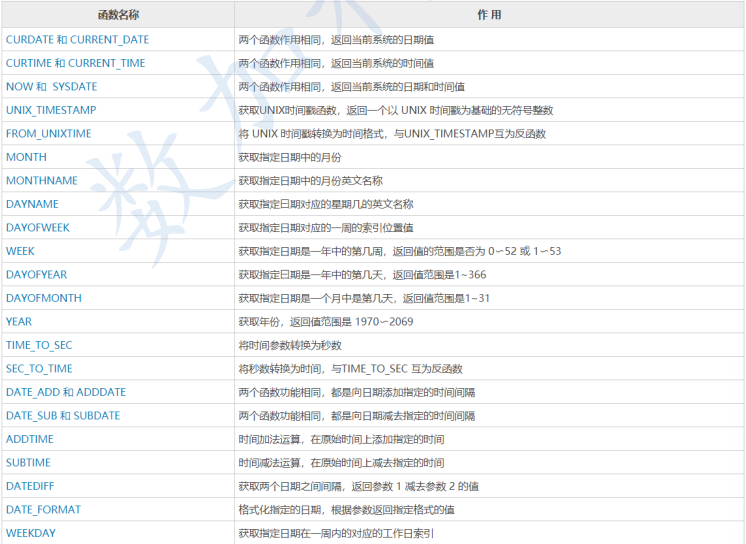
-- 获取当前系统时间
- select hiredate,sysdate() from emp;
- select hiredate,CURRENT_DATE(),CURRENT_TIME(),CURRENT_TIMESTAMP() from emp;
-- 日期转换
- select DATE_FORMAT(sysdate(),'%Y-%m-%d %H:%i:%s')
- select hiredate, date_format(now(),'%Y年%m月%d日 %H时%i分%s秒') from emp;
-- 分别获取 年月日 时分秒 星期
- select
- SECOND MINUTE HOUR DAY WEEK MONTH YEAR
-- 日期的加减操作
- select hiredate,ADDDATE(hiredate,9),ADDDATE(hiredate,-9) from emp;
- select DATE('2022-05-02') ;
数字函数
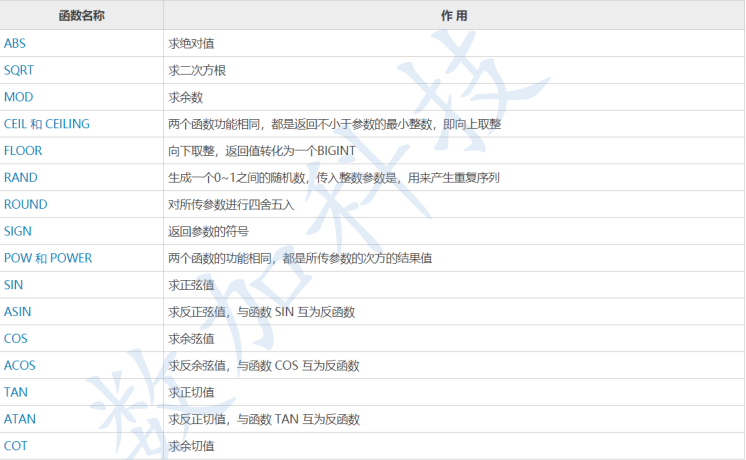
-- 向上取整 向下取整
- select ceil(12,1),floor(12.9)
-- mod abs pow PI rand round TRUNCATE(直接进行截取,不进行四舍五入)
-- 保留多少位有效数字
- select round(1.4999999,2),round(1.4999999),round(1.4999999,-1)
- select TRUNCATE(1.4999999,2)
转换函数 ·
-- 日期--》字符串
- date_format(date,expr)
- select DATE_FORMAT(sysdate(),'%Y-%m-%d %H:%i:%s');
-- 字符串--》日期
- 要注意字符串和格式的匹配
- select STR_TO_DATE('2020-4-16 17:15:24','%Y-%c-%d %H:%i:%s');
-- 数字--》字符串
- 直接拼接一个字符串即可,可以自动转换
-- 字符串--》数字
- 依靠函数提供的参数
其他函数
-- 空值的处理
if null(exp1,exp2) exp1!=null?exp1:exp2
select IFNULL(comm,888) from emp;
-- 加密算法
select MD5('123456');
select AES_ENCRYPT('123456','abcd'),AES_DECRYPT(AES_ENCRYPT('123456','abcd'),'abcd');
4.2 多行函数
不管函数处理多少条,只返回一条记录
如果你的数据可以分为多个组,那么返回的数据条数和组数相同
每个部门的平均薪资
10 20 30 --> 3
常用的多行函数有5个
max 最大值: 如果处理的值是字符串,将会把值按照字典序排序
min 最小值: 如果处理的值是字符串,将会把值按照字典序排序
avg 平均值: 只能用于数值型数据,求平均值
sum 求和: 如果求和过程中有null,那么不会计算在内
count 求总数: 如果统计的数据中有null,不会把null统计在内
经典的错误
--查询公司最低薪资的员工是谁?
select min(sal) ,ename from emp;
mysql语法可行
oracle不可行
将来工作的时候不能把普通列和组函数写在一起,虽然mysql语法不会报错,但是给的结果是错误的
4.3 数据分组
按照某一个条件进行分组,每一组返回对应的结果
group by 可以对指定的列进行分组,列尽量有相同的
having可以对分组之后的数据进行过滤,所以能出现在having中的比较项一定是被分组的列或者是组函数
底层(注意!!!)
where称之为行级过滤,处理的是表中每一行数据的过滤
having称之为组级过滤,处理的是分组之后的每一组数据
能使用where的,尽量不要使用having
--查询每种工作的平均薪资
select job,avg(sal) from emp group by job;
--查询每个部门的最高薪资和最低薪资
select max(sal),min(sal) from emp;
select deptno,max(sal),min(sal) from emp group by deptno;
--查询每个部门的人数和每月工资总数
select deptno,count(empno),sum(sal) from emp group by deptno;
--查询每个部门,每种工作的平均薪资
select deptno,job , avg(sal) from emp group by deptno,job;
select deptno,job , avg(sal) from emp group by deptno,job order by depto,job;
--查询个人姓名的平均薪资--尽量对多数据进行分组
select ename, max(sal),min(sal) from emp group by ename;
--查询平均薪资高于2500的部门
select deptno,avg(sal) from emp group by deptno having avg(sal)>=2500;
select deptno,avg(sal) from emp group by deptno having ename like '%A%';
--查询20部门的平均薪资
select deptno,avg(sal) from emp group by deptno having deptno = 20;
select deptno,avg(sal) from emp where deptno = 20 group by deptno;
--查询10 20部门中,并且在二月份入职员工中,每个部门中平均薪资高于1500的工作是什么,并按照
部门,工作平均薪资进行排序
select * from emp where deptno in (10,20) ;
select deptno ,job ,avg(sal) from emp where deptno in (10,20) group by deptno ,job having avg(sal)>1500 ;
select deptno ,job ,avg(sal) from emp where deptno in (10,20) group by deptno ,job having avg(sal)>1500 order by deptno ,avg(sal);
--美观写法
SELECT
deptno,
job,
avg( sal ) '平均薪资'
FROM
emp
WHERE
deptno IN ( 10, 20 )
GROUP BY
deptno,
job
HAVING
avg( sal )> 1500
ORDER BY
deptno,
avg( sal );
4.4 DQL单表关键字执行顺序
select: 我们要显示那些列的数据
from: 从那张表中获取数据
where: 从表中获取数据的时候进行行级的数据过滤
group by: 对数据进行分组处理,一组获取对应的结果
having: 组级过滤,组级过滤的数据必须是分组条件或者是组函数
order by: 排序 asc desc
执行的顺序(面试题)
from --> where -->group by -->having-->select -->order by
4.5 多表查询
a. 查询的两张表如果出现同名的列,我们需要将表名标注到列名前面
b. 如果是非同名的列,表名可加可不加,推荐加上
为了书写方便,可以给表添加别名
一般情况下取首字母,特殊情况下取它所代表的含义
表的别名只在本次查询中生效
c. 如果表与表进行关联查询的时候,如果不添加关联条件,查询的总记录数就是a*b = 笛卡尔积
a 15 b 10 c 10 -->1500条
d. 多表查询的时候必须要加条件
等值
非等值
--查询每个员工所在的部门名称
select ename,deptno from emp;
select deptno,dname from dept;
select emp.ename,emp.deptno,dept.deptno,dept.dname from emp,dept;
--等值关联查询
select emp.ename,emp.deptno,dept.deptno,dept.dname from emp,dept where emp.deptno = dept.deptno;
select emp.ename,dept.dname from emp , dept where emp.deptno 4= dept.deptno;
--添加别名
select e.ename,d.dname from emp e,dept d where e.deptno = d.deptno;
4.6 表与表关联的方式
因为表的关联条件和业务查询条件放在了一起,为了防止混淆于是提供了下面三种方式
自然连接
-- 会自动选择列名相同并且类型相同的列
--查询薪资大于2000的员工姓名和部门名称
select e.ename,d.dname from emp e ,dept d where e.deptno = d.deptno and e.sal >2000;
--自然连接
select e.ename,d.dname from emp e natural join dept d ;
select e.ename,d.dname from emp e natural join dept d where e.sal > 2000 ;
using
-- 不需要mysql帮我们选择等值连接的列,现在我们指定等值连接的列
----查询薪资大于2000的员工姓名和部门名称 using
select e.ename,d.dname from emp e join dept d using(deptno);
select e.ename,d.dname from emp e join dept d using(deptno) where e.sal > 2000;
on
-- 我们可以指定两张表关联的条件,可以是非等值的操作
----查询薪资大于2000的员工姓名和部门名称 using
select e.ename,d.dname from emp e join dept d on(e.deptno = d.deptno);
select e.ename,d.dname from emp e join dept d on(e.deptno = d.deptno) where e.sal > 2000;
--查询每个员工所对应的薪资登记
select e.ename,s.grade from emp e,salgrade s where e.sal between s.losal and s.hisal;
select e.ename,s.grade from emp e join salgrade s on(e.sal between s.losal and s.hisal);
查询名字中带有A字母的员工姓名,部门名称和薪资等级
-- 第一种写法
SELECT
e.ename,
d.dname,
s.grade
FROM
emp e,
dept d,
salgrade s
WHERE
e.deptno = d.deptno
AND e.sal BETWEEN s.losal AND s.hisal
AND e.ename LIKE '%A%';
-----------------------------------------
-- 第二种写法
SELECT
e.ename,
d.dname,
s.grade
FROM
emp e
JOIN dept d USING ( deptno )
JOIN salgrade s ON (e.sal BETWEEN s.losal AND s.hisal)
WHERE
e.ename LIKE '%A%';
4.7 表与表的外连接
当我们对两张表进行关联查询的时候,基于数据的原因导致其中一张表中的数据没办法被完全查询出来
外连接可以让没查询出来的数据也显示出来
因为我们写SQL的时候表总有左右之分 ,外连接也分为
左外连接:显示左面表所有的数据
右外连接:显示右面表所有的数据
--统计每个部门的人数
select deptno,count(empno) from emp group by deptno;
select * from emp e join dept d using(deptno);
select * from emp e left join dept d using(deptno);
select * from emp e right join dept d using(deptno);
select deptno,count(e.empno) from emp e right join dept d using(deptno) group by deptno;
-------------------------全外连接
SELECT
deptno,
e.ename,
d.dname
FROM
emp e RIGHT JOIN dept d USING ( deptno )
UNION
SELECT
deptno,
e.ename,
d.dname
FROM
emp e LEFT JOIN dept d USING ( deptno );
-------------------------Oracle的全外连接使用 Full Join
4.8 表与表的自连接
我们要查询的两个字段同时处于一张表上,我们只能将一张表当做含有不同意义的两张表去处理
给相同的表取不同的简称(按照所代表的含义去取)
--查询每个员工与其直属领导的名字
select e.ename,m.ename from emp e,emp m where e.mgr = m.empno;
select e.ename,m.ename from emp e join emp m on(e.mgr = m.empno);
4.9 表与表的子连接(常用!!)
-- 把一个SQL语句的查询结果当成另外一个SQL语句的查询条件
--查询公司中薪资最低的员工姓名
select ename,sal from emp where sal = (select min(sal) from emp);
--查询公司中谁的薪资高于平均薪资
select ename,sal from emp where sal > (select avg(sal) from emp);
--谁的薪资高于20部门员工的薪资
select ename,sal from emp where sal > all(select sal from emp where deptno = 20 );
select ename,sal from emp where sal > some(select sal from emp where deptno = 20 );
select ename,sal from emp where sal in (select sal from emp where deptno = 20 );
4.10 表与表的伪表查询
如果我们所需要的查询条件 需要别的SQL语句提供
如果只需要一个条件,那么可以使用子查询来完成
如果需要多个查询条件,这是就要将所有的查询结果当做伪表进行管理
我们需要把一些含有特殊符号的列名设置别名,然后给伪表设置一个别名(见名知意)
--查询高于自己部门平均薪资的员工信息
select deptno,avg(sal) avgsal from emp group by deptno;
SELECT
e.ename,
e.sal,
e.deptno
FROM
emp e,
( SELECT deptno, avg( sal ) avgsal FROM emp GROUP BY deptno ) d
WHERE
e.deptno = d.deptno
AND e.sal > d.avgsal;
五、SQL-DML
5.1 SQL-DML插入
1、insert into 表名 values();
insert into dept values(50,'sxt','shanghai');
要求插入数据的数量,类型要和定义的表结构一致
insert into dept values(50,'sxt','hefei','liyi'); insert into dept values(50,'sxt'); insert into dept values('abcd',50.'sh');2、insert into 表名(列名) values(值...);
insert into emp(empno,ename,deptno) values(6666,'ly',50); -- 要求插入数据的数量顺序和表名后的列要一致3、insert into 表名(列名) select ....
create table dp as select * from dept where 1<>1; insert into dept(deptno,dname) select empno ,ename from emp;
5.2 SQL-DML删除
delete from 表名
delete from dept;delete from 表名 where 条件
delete from emp where comm is null; -- 这属于一种物理删除,删完之后理论上不能再找回,短时间内紧急联系网管truncate table emp;
截断表--不要使用--不要使用
5.3 SQL-DML修改
update 表名 set 列名=value ,列名=value
update salgrade set losal = 888 ,hisal = 999;update 表名 set 列名=value ,列名=value where 条件
update salgrade set losal = 666 ,hisal = 1888 where grade = 3;
5.4 数据库事务
数据库管理系统执行过程中的一个逻辑单位,由一个有限的数据库操作序列构成
事务指的是数据库一种保护数据的方式
事务一般由增删改操作自动调用,事务根据数据库不同提交的时机也是不同的
mysql数据库默认执行增删改就会提交事务
我们可以设置为 手动提交 begin 或者 start transaction;
事务的特征
ACID原则
原子性
事务是操作数据的最小单元,不可以再分
一致性
事务提交之后,整个数据库所看到数据都是最新的数据
所有人看到的数据都是一致的
隔离性
别人无法访问到我们未提交的数据,而且一旦这个数据被我修改,别人也无法进行操作
持久性
事务一旦被提交,数据库就进入到一个全新的状态
数据在也不能返回到上一个状态
事务如何开启和提交?
开启
当我们执行增删改操作的时候就会默认开启一个事务
这个事务和当前操作的窗口有关,别人是无法共享这个事务的
提交
手动
显示
commit; 提交
rollback; 回滚
隐式
执行DDL操作,会默认提交当前的事务
用户退出,事务统一进行回滚(Mysql)
自动
mysql数据库执行DML操作之后会自动的提交事务
好处:
方便
坏处:
不能将多个SQL纳入到一个事务,不便于管理
当我们大批量插入数据的时候,数据库会频繁的开启关闭事务影响插入效率
5.5 事务的隔离级别
根据数据库的不同用途,我们可以对数据库的事务进行级别的设置
级别设置的越高,数据越安全,但是效率越低
读未提交
我们可以读取到别人未提交的数据
有可能产生脏读的问题
读已提交
只能读取别人提交后的数据
不能达到可重复读,但是可以避免脏读
有可能产生虚读或者幻读的情况
可重复读
当数据被我查询之后,别人就不能修改这个数据了
说明在我查询的时候已经有事务操作到这些数据,查询都会开启事务
但是不能防止别人查询别的数据
序列化
当前数据库只能存在一个事务,但我操作数据库的时候,别人是不能访问数据库的
这时对于用户来讲数据相当安全,一般在倒库的时候才会开启这种级别
脏读
读取别人未提交的数据,这个数据是不安全的
虚读
第一次读取的数据,第二次在读取的时候有可能被被人修改了
幻读
第一次读取的数据,第二次多了一条或者少了一条
-- 看看姓名的长度
select LENGTH(ename),ename from emp;
-- 字符串截取函数
select ename,SUBSTR(ename,2,2) from emp;
-- 判断第二个字符是否是A
select * from emp where ename like '_A%';
select * from emp where SUBSTR(ename,2,1)='A';
-- 转大小写
select UPPER(ename) from emp;
select LOWER(ename) from emp;
-- mysql5.7之后有一张伪表用于函数测试使用
select CONCAT('abc','--','qwe') from DUAL;
select concat(empno,'-',ename) as newline,EMPNO,ename,sal from emp;
-- 想把姓名中的A都换成S
select REPLACE(ename,'A','S'),ename from emp;
-- 第三个字符是A的进行替换
select concat(SUBSTR(ename,1,2),'S',substr(ename,4,length(ename)-3)),ename from emp where substr(ename,3,1)='A';
select RTRIM(' hello '),LTRIM(' hello '),TRIM(' hello ') from dual;
-- 数字函数
select abs(-12),floor(3.2),floor(3.6),floor(3.9),CEIL(3.2),CEIL(3.6),CEIL(3.9) from DUAL;
-- 四舍五入
select ROUND(3.2),round(3.4),ROUND(3.9) from dual;
-- 日期
select now() from dual;
select SYSDATE() from DUAL;
-- mysql5.7之后,只要字符串满足日期的格式,就会在日期函数中自动转换
select DATE_FORMAT('2022-5-5','%Y年%m月%d日 %H时%i分%s秒') from dual;
select ADDDATE(hiredate,-1),HIREDATE from emp;
select YEAR(hiredate),MONTH(HIREDATE),HIREDATE from emp;
select LAST_DAY(HIREDATE) from emp;
select STR_TO_DATE('5-5-2022','%d-%m-%Y %H-%i-%s');
select STR_TO_DATE('2020-4-16 17:15:24','%Y-%c-%d %H:%i:%s');
select 123+'123';
select concat(123,'','123');
select LPAD('qwe',2,'#');
-- 来做默认值的处理
select IFNULL(comm,888) from emp;
-- MD5不可逆加密
select MD5('123456'); -- e10adc3949ba59abbe56e057f20f883e
-- 加盐
select MD5('liyi123456');
select MD5(MD5('123456'));
select AES_ENCRYPT('123456','abcd'),AES_DECRYPT(AES_ENCRYPT('123456','abcd'),'abcd');
-- 多行函数(聚合函数)
select max(sal),min(sal),avg(sal),sum(sal),count(empno) from emp;
select max(ename),min(ename),avg(ename) from emp;
select min(SAL),ename from emp;
select min(sal),any_value(ename) from emp;
select * from emp;
select job as '工作名称',round(avg(SAL)) as '平均薪资' from emp group by job;
-- 查询每个部门的最高薪资和最低薪资
select deptno,max(sal),min(sal) from emp group by DEPTNO;
-- 查询每个部门的人数和每月工资总数
select deptno,count(empno),sum(sal) from emp group by deptno;
-- 查询每个部门,每种工作的平均薪资
select deptno,job,ROUND(avg(sal)) from emp group by deptno,job;
-- 查询平均薪资高于2500的部门
select deptno,avg(sal) from emp group by deptno having avg(sal)>2500;
-- 查询20部门的平均薪资(比较这两种,最终推荐第二种)
select avg(sal) from emp group by deptno having deptno = 20;
select avg(SAL) from emp where deptno = 20 group by deptno;
-- 查询10 20部门中,并且在二月份入职员工中,每个部门中平均薪资高于1500的工作是什么,并按照部门,工作平均薪资进行排序
select * from emp where deptno in (10,20);
select deptno,job,ROUND(avg(sal)) from emp where deptno in (10,20) group by deptno,job having avg(sal)>1500;
select e.*,d.DNAME,d.LOC from emp as e,dept as d where e.deptno=d.deptno;
select e.*,d.DNAME,d.LOC from emp e NATURAL JOIN dept d order by sal desc;
select e.*,d.DNAME,d.LOC from emp e join dept d USING(deptno);
select e.*,d.DNAME,d.LOC from emp e join dept d on (e.DEPTNO=d.deptno);
select e.*, s.GRADE from emp e,salgrade s where e.SAL BETWEEN s.LOSAL and s.HISAL;
select e.*,s.GRADE from emp e join salgrade s on(e.sal BETWEEN s.LOSAL and s.HISAL);
select e.*,d.DNAME,d.LOC from emp e join dept d on(e.DEPTNO=d.DEPTNO);
-- 左连接的结果以左表数据为准,左表的数据不会丢,即使是null,也查询出来
select e.*,d.DNAME,d.LOC from emp e left join dept d on(e.DEPTNO=d.DEPTNO);
-- 右连接的结果以右表数据为准,右表的数据不会丢,即使匹配的是null,也查询出来
select e.*,d.DNAME,d.LOC,d.DEPTNO from emp e RIGHT join dept d on(e.DEPTNO=d.DEPTNO);
-- 查看每个员工信息以及他的直属领导的名字
-- mysql中的自连接查询
select e1.*,e2.ENAME as 直属领导 from emp e1 join emp e2 on(e1.MGR=e2.EMPNO);
select e1.*,e2.ENAME as 直属领导 from emp e1,emp e2 where e1.MGR=e2.EMPNO;
-- 查询公司中薪资最低的员工姓名
select min(sal) as min_sal from emp;
-- mysql中的表子连接查询
select * from emp where sal = (select min(sal) as min_sal from emp);
-- 查询公司中谁的薪资高于平均薪资
select * from emp where sal > (select avg(sal) from emp);
-- 查询高于自己部门平均薪资的员工信息
-- 第一步:先查询出每个部门的平均薪资是多少(提示:根据部门进行分组)
select deptno,avg(sal) as deptavg_sal from emp group by deptno;
select e.ENAME,e.SAL,e.DEPTNO from emp e,(select deptno,avg(sal) as deptavg_sal from emp group by deptno) e2 where e.DEPTNO=e2.deptno and e.SAL>=e2.deptavg_sal order by e.DEPTNO;
-- 将查询的结果进行保存
-- 在企业开发最常用的做法
drop table result1;
create table result1 as select e.ENAME,e.SAL,e.DEPTNO from emp e,(select deptno,avg(sal) as deptavg_sal from emp group by deptno) e2 where e.DEPTNO=e2.deptno and e.SAL>=e2.deptavg_sal order by e.DEPTNO;
delete from result1;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号